Билет 43.Метрики кластерного анализа
Возможны различные виды критериев (функционалов) разбиения множества на кластеры. Заметим, что эта задача тесно связана с определением некоторой метрики в пространстве признаков.
Рассмотрим наиболее широко используемые функционалы качества разбиения:
- Коэффициент разбиения F, который определяется следующим образом:
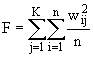 , (7.12)
, (7.12)
где  — некоторая степень принадлежности i–го объекта j–му кластеру. Диапазон изменения
— некоторая степень принадлежности i–го объекта j–му кластеру. Диапазон изменения 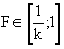 , где n — число объектов, K — число кластеров.
, где n — число объектов, K — число кластеров.
- Индекс четкости:
 ,
,  (7.13)
(7.13)
где K — число классов (кластеров); F — коэффициент разбиения. - Энтропия разбиения:
 . (7.14)
. (7.14)
- Нормализованная энтропия разбиения
 (7.15)
(7.15)
, где n — число точек;
- Модифицированная энтропия:
 ,
, 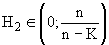 (7.16)
(7.16)
- Второй функционал Рубенса:
 (7.17)
(7.17)
- Третий функционал Рубенса (второй индекс четкости):
 (7.18)
(7.18)
Поскольку исходная информация задается в виде матрицы Х, то возникает проблема выбора метрики. Выбор метрики — наиболее важный фактор, влияющий на результаты кластер–анализа. В зависимости от типа признаков используются различные меры близости (метрики).
Пусть имеются образцы  и
и  в N–мерном пространстве признаков.
в N–мерном пространстве признаков.
Основные метрики, используемые при кластеризации, приводятся в таблице 1.
| Таблица 1 — Основные типы метрик при кластер-анализе | |||
| N | Наименование метрики | Тип признаков | Формула для оценки меры близости (метрики) |
| 1 | Эвклидово расстояние | Количественные | 
|
| 2 | Мера сходства Хэмминга | Номинальные (качественные) |  где где  — число совпадающих признаков у образцов и — число совпадающих признаков у образцов и
|
| 3 | Мера сходства Роджерса–Танимото | Номинальные шкалы |  где где  — число совпадающих единичных признаков у образцов и ; — число совпадающих единичных признаков у образцов и ;  , ,  — общее число единичных признаков у образцов и соответственно; — общее число единичных признаков у образцов и соответственно;
|
| 4 | Манхэттенская метрика | Количественные | 
|
| 5 | Расстояние Махалонобиса | Количественные |  , где W — ковариационная матрица выборки; , где W — ковариационная матрица выборки;  ; ;
|
| 6 | Расстояние Журавлева | Смешанные |  , где , где 
|
Существует большое число алгоритмов кластеризации, которые используют различные метрики и критерии разбиения. При этом число классов (кластеров) либо задается априори, либо определяется в процессе работы самого алгоритма.
|
|
|
Билет 44.Методы определения близости между кластерами.
Методы кластерного анализа можно разделить на две группы:
• иерархические;
• неиерархические.
Каждая из групп включает множество подходов и алгоритмов.
Используя различные методы кластерного анализа, аналитик может получить различные решения для одних и тех же данных. Это считается нормальным явлением. Рассмотрим иерархические и неиерархические методы подробно.
|
|
|
Иерархические методы кластерного анализа  Править
Править
Суть иерархической кластеризации состоит в последовательном объединении меньших кластеров в большие или разделении больших кластеров на меньшие.
Иерархические агломеративные методы (AgglomerativeNesting, AGNES) Эта группа методов характеризуется последовательным объединением исходных элементов и соответствующим уменьшением числа кластеров.
В начале работы алгоритма все объекты являются отдельными кластерами. На первом шаге наиболее похожие объекты объединяются в кластер. На последующих шагах объединение продолжается до тех пор, пока все объекты не будут составлять один кластер. Иерархические дивизимные (делимые) методы (DIvisiveANAlysis, DIANA) Эти методы являются логической противоположностью агломеративным методам. В начале работы алгоритма все объекты принадлежат одному кластеру, который на последующих шагах делится на меньшие кластеры, в результате образуется последовательность расщепляющих групп.
Программная реализация алгоритмов кластерного анализа широко представлена в различных инструментах DataMining, которые позволяют решать задачи достаточно большой размерности. Например, агломеративные методы реализованы в пакете SPSS, дивизимные методы - в пакете Statgraf.
|
|
|
Иерархические методы кластеризации различаются правилами построения кластеров. В качестве правил выступают критерии, которые используются при решении вопроса о "схожести" объектов при их объединении в группу (агломеративные методы) либо разделения на группы (дивизимные методы).
Методы объединения или связи Править
Когда каждый объект представляет собой отдельный кластер, расстояния между этими объектами определяются выбранной мерой. Возникает следующий вопрос - как определить расстояния между кластерами? Существуют различные правила, называемые методами объединения или связи для двух кластеров.
Метод ближнего соседа или одиночная связь. Править
Здесь расстояние между двумя кластерами определяется расстоянием между двумя наиболее близкими объектами (ближайшими соседями) в различных кластерах. Этот метод позволяет выделять кластеры сколь угодно сложной формы при условии, что различные части таких кластеров соединены цепочками близких друг к другу элементов. В результате работы этого метода кластеры представляются длинными "цепочками" или "волокнистыми" кластерами, "сцепленными вместе" только отдельными элементами, которые случайно оказались ближе остальных друг к другу.
|
|
|
Метод наиболее удаленных соседей или полная связь. Править
Здесь расстояния между кластерами определяются наибольшим расстоянием между любыми двумя объектами в различных кластерах (т.е. "наиболее удаленными соседями"). Метод хорошо использовать, когда объекты действительно происходят из различных "рощ". Если же кластеры имеют в некотором роде удлиненную форму или их естественный тип является "цепочечным", то этот метод не следует использовать.
Метод Варда (Ward'smethod). Править
В качестве расстояния между кластерами берется прирост суммы квадратов расстояний объектов до центров кластеров, получаемый в результате их объединения (Ward, 1963). В отличие от других методов кластерного анализа для оценки расстояний между кластерами, здесь используются методы дисперсионного анализа. На каждом шаге алгоритма объединяются такие два кластера, которые приводят к минимальному увеличению целевой функции, т.е. внутригрупповой суммы квадратов. Этот метод направлен на объединение близко расположенных кластеров и "стремится" создавать кластеры малого размера.
Метод невзвешенного попарного среднего Править
(метод невзвешенного попарного арифметического среднего - unweightedpair-groupmethodusingarithmeticaverages, UPGMA (Sneath, Sokal, 1973)). В качестве расстояния между двумя кластерами берется среднее расстояние между всеми парами объектов в них. Этот метод следует использовать, если объекты действительно происходят из различных "рощ", в случаях присутствия кластеров "цепочного" типа, при предположении неравных размеров кластеров.
Метод взвешенного попарного среднего Править
(метод взвешенного попарного арифметического среднего - weightedpair-groupmethodusingarithmeticaverages, WPGM A (Sneath, Sokal, 1973)). Этот метод похож на метод невзвешенного попарного среднего, разница состоит лишь в том, что здесь в качестве весового коэффициента используется размер кластера (число объектов, содержащихся в кластере). Этот метод рекомендуется использовать именно при наличии предположения о кластерах разных размеров. Невзвешенный центроидный метод (метод невзвешенного попарного центроидного усреднения - unweightedpair-groupmethodusingthecentroidaverage (SneathandSokal, 1973)).
В качестве расстояния между двумя кластерами в этом методе берется расстояние между их центрами тяжести.
Взвешенный центроидный метод Править
метод взвешенного попарного центроидного усреднения -weightedpair-groupmethodusingthecentroidaverage, WPGMC (Sneath, Sokal 1973)). Этот метод похож на предыдущий, разница состоит в том, что для учета разницы между размерами кластеров (числе объектов в них), используются веса. Этот метод предпочтительно использовать в случаях, если имеются предположения относительно существенных отличий в размерах кластеров.
Дата добавления: 2018-04-15; просмотров: 2651; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!