Билет 42.Общая характеристика задач кластерного анализа.
Кластерный анализ — задача разбиения выборки объектов на подмножества, называемые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались.
Кластер — группа элементов, характеризуемых общим свойством, главная цель кластерного анализа — нахождение групп схожих объектов в выборке.
Задача кластер анализа состоит в выяснении по эмпирическим данным, насколько элементы «группируются» или распадаются на изолированные «кластеры» (от cluster (англ.) — гроздь, скопление). Иными словами, задача — выявление естественного разбиения на классы, свободного от субъективизма исследователя, а цель — выделение групп однородных объектов, сходных между собой, при резком отличии этих групп друг от друга.
Цели кластеризации
1. Понимание данныхпутём выявления кластерной структуры. Разбиение выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа (стратегия «разделяй и властвуй»).
2. Сжатие данных. Если исходная выборка избыточно большая, то можно сократить её, оставив по одному наиболее типичному представителю от каждого кластера.
3. Обнаружение новизны(англ.noveltydetection). Выделяются нетипичные объекты, которые не удаётся присоединить ни к одному из кластеров.
Формальная постановка задачи кластеризации
|
|
|
Пусть 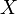 — множество объектов,
— множество объектов, 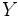 — множество номеров (имён, меток) кластеров. Задана функция расстояния между объектами
— множество номеров (имён, меток) кластеров. Задана функция расстояния между объектами 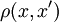 . Имеется конечная обучающая выборка объектов
. Имеется конечная обучающая выборка объектов 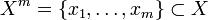 .
.
Требуется разбить выборку на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из объектов, близких по метрике 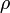 , а объекты разных кластеров существенно отличались. При этом каждому объекту
, а объекты разных кластеров существенно отличались. При этом каждому объекту 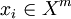 приписывается номер кластера
приписывается номер кластера 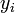 .
.
Алгоритм кластеризации — это функция 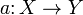 , которая любому объекту
, которая любому объекту 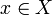 ставит в соответствие номер кластера
ставит в соответствие номер кластера 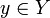 . Множество в некоторых случаях известно заранее, однако чаще ставится задача определить оптимальное число кластеров, с точки зрения того или иного критерия качества кластеризации.
. Множество в некоторых случаях известно заранее, однако чаще ставится задача определить оптимальное число кластеров, с точки зрения того или иного критерия качества кластеризации.
Кластеризация (обучение без учителя) отличается от классификации (обучения с учителем) тем, что метки исходных объектов изначально не заданы, и даже может быть неизвестно само множество .
Описание данных.
Исходными данными служат результаты исследования морфо-функционального состава слюны пациентов различных возрастных категорий. В исследовании участвовали 4 группы пациентов, которые были разбиты по следующим признакам:
- без патологии (группа контроля)
|
|
|
- обладающие патологией печени (цирроз)- 6 пациентов( 20-26).
- с заболеваниями желудочно-кишечного тракта
-пациенты, с диагностированной алкогольной зависимостью
В обследование каждого участника исследования входило изучение белкового состава слюны, анализ маркеров воспалительного процесса, а также установка индексов общего соматического состояния здоровья (индекс гигиены, индекс PMA).
Постановка задачи. Установить прогностическую значимость маркеров и параметров обследования - по имеющимся результатам обследования пациентов сформировать кластеры и установить распределение пациентов по классам, в зависимости от данных обследования (характеристик).
Алгоритм k-means
Для кластеризации данных будем использовать алгоритм k-means - наиболее популярный метод кластеризации. Был изобретён в 1950-х годах математикомГугоШтейнгаузоми почти одновременно Стюартом Ллойдом.
Действие алгоритма таково, что он стремится минимизировать суммарное квадратичное отклонение точек кластеров от центров этих кластеров:
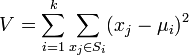
где 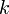 — число кластеров,
— число кластеров, 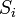 — полученные кластеры,
— полученные кластеры, 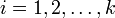 и
и 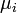 — центры масс векторов
— центры масс векторов 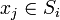 .
.
Алгоритм разбивает множествоэлементоввекторногопространствана заранее известное число кластеров k.
|
|
|
Основная идея заключается в том, что на каждой итерации перевычисляется центр массдля каждого кластера, полученного на предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с тем, какой из новых центров оказался ближе по выбранной метрике.
Алгоритм завершается, когда на какой-то итерации не происходит изменения кластеров. Это происходит за конечное число итераций, так как количество возможных разбиений конечного множество конечно, а на каждом шаге суммарное квадратичное уклонение V уменьшается, поэтому зацикливание невозможно (рисунок 1).
Дата добавления: 2018-04-15; просмотров: 746; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!