Оценка «нормальности» исходных данных
Выскажем гипотезу, что ИСД, представленные в таблице 1.1.1 подчинены нормальному закону и в качестве параметров нормального закона примем оценки математического ожидания и среднего квадратического отклонения (стандартного отклонения), представленные в таблице 1.2.1. «Нормальность» исходных данных весьма существенна для откликов, т.к. наличие этого свойства позволяет использовать дисперсионный анализ для оценки качества уравнений регрессии.
Функция плотности нормального закона имеет вид:
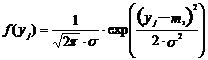
| (1) |
где:
yj- j-тый отклик (показатель эффективности);
m1 – математическое ожидание;
s - среднее квадратическое отклонение.
Для проверки гипотезы о соответствии распределения случайной величины какому-либо закону распределения в пакете Statistica 6.0, после ее запуска, необходимо выбрать пункт меню Statistics/Distribution Fitting, как показано на рис.1.3.1. Необходимо выбрать пункт проверки гипотезы о соответствии распределения случайной величины какому-либо закону распределения (Distribution Fitting) и запустить его, нажав на кнопку <OK>.

Рис.1.3.1. Окно выбора закона распределения в STATISTICA 6.0
Если количество экспериментальных значений, как в нашем случае, сравнительно невелико, используется критерий согласия Колмогорова-Смирнова, вычисляемый по формуле для всех имеющихся экспериментальных значений.
 , ,
| (2) |
где:
N – общее количество реализаций случайной величины;
|
|
|
F*(yj) – эмпирическое значение функции распределения;
F(yj) – гипотетическое значение функции распределения.
Щелкнув по кнопке <Plot of observedand expected distribution> вы сможете увидеть график функции распределения для выбранной величины (рис.1.3.2). В «шапке» графика указана величина критерия Колмогорова-Смирнова d =  = 0.14380 и степень доверия p = n.s. Степень доверия p = n.s. показывает, что статистические данные не противоречат гипотезе о их подчинении нормальному закону.
= 0.14380 и степень доверия p = n.s. Степень доверия p = n.s. показывает, что статистические данные не противоречат гипотезе о их подчинении нормальному закону.

Рис.1.3.2. График оценки “нормальности” переменной х1
Кластерный анализ
Часто возникает ситуация, когда необходимо разбить факторы на несколько групп. В этом случае проводится кластерный анализ. В строке меню из пункта Статистика выбирается модуль Многомерные исследовательские методы подмодуль Анализ кластеров (Cluster Analysis). Откроется стартовая панель модуля Анализ кластеров (Cluster Analysis):

Рис. 1.4.1 Стартовая панель модуля Кластерный анализ
Выбирается метод. В главной части панели находится список методов кластерного анализа, реализованных в STATISTICA 6.0. После выбора метода необходимо нажать кнопку  в правом верхнем углу панели. Например, диалоговое окно метода k-means(см. рис. 1.4.2):
в правом верхнем углу панели. Например, диалоговое окно метода k-means(см. рис. 1.4.2):

Рис. 1.4.2. Диалоговое окно метода k-means
|
|
|
Необходимо выбрать переменные для анализа. Нажать кнопку Variables (Переменные) в левом верхнем углу текущего окна и откроется диалоговое окно: Select variables for the analysis (Выбор переменных для анализа), выбрать переменные, а затем нажать кнопку  .
.

Рис.1.4.3. Выбор переменных для Кластерного анализа
После этого необходимо установить начальные значения. на поле, находящееся ниже кнопкиVariables (Переменные). Нажав на стрелку в поле Cluster (Кластер), можно выбрать кластеризацию по строкам или столбцам. В поле Number of clusters (Число кластеров) нужно определить число групп, на которые хотим разбить факторы.
· В строке Number of(iterations) (Число итераций) задается максимальное число итераций, используемых при построении классов.
Группа опций Начальные центры кластера (Initial cluster centres) позволяет задать начальные центры кластеров.
После того как все установки сделаны, необходимо нажать кнопку  в верхнем правом углу окнаk-means clustering (метод k-средних)и запустить вычислительную процедуру.
в верхнем правом углу окнаk-means clustering (метод k-средних)и запустить вычислительную процедуру.
В окне результатов в верхней части приведена следующая информация (см. рис. 1.4.4):
· Количество переменных (Number of variables) – 4;
· Число регистров (Number of cases) – 64;
· K-means clustering of cases – Метод кластеризации k-means clustering;
· Количество групп (Number of cluster) – 3;
|
|
|
· Solution was obtained after 3 iterations – Решение найдено после 3 итераций.

Рис. 1.4.4. Окно результатов кластеризации районов по методу средних
Для получения более подробной информации выбирается закладка Расширенный (Advanced). Данное диалоговое окно состоит из двух частей: верхней – информационной, и нижней, где содержатся функциональные кнопки, позволяющие всесторонне просмотреть результаты анализа.
Факторный анализ
Основная цель факторного анализа в том, чтобы обнаружить скрытые общие факторы, объясняющие связи между наблюдаемыми признаками (параметрами) объекта. Для этого в строке меню из пункта Статистиканеобходимо выбрать модуль Многомерные исследовательские методыи открыть модуль Факторный анализ или Анализ особенности (Factor Analysis), на экране появится стартовая панель модуля:

Рис. 1.5.1. Стартовая панель модуля Факторного анализа
Прежде всего, в строке Файл входных данных (Input File) указывается тип исходного файла, с которым будет идти работа. В модуле возможны следующие типы исходных данных:
Исходные данные – Raw Data.
Дата добавления: 2018-04-05; просмотров: 269; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!