Общий синтаксис таблиц стилей
Таблицы стилей строятся в соответствии с определенным порядком (синтаксисом), в противном случае они не могут нормально работать. Таблицы стилей составляются из определенных частей (рис. 1):

• Селектор (Selector). Селектор — это элемент, к которому будут применяться назначаемые стили. Это может быть тег, класс или идентификатор объекта гипертекстового документа.
• Свойство (Property). Свойство определяет одну или несколько характеристик селектора. Свойства задают формат отображения селектора: отступы, шрифты, выравнивание, размеры и т.д.
• Значение (Value). Значения — это фактические числовые или строковые константы, определяющие свойство селектора.
• Описание (Declaration). Совокупность свойств и их значений.
• Правило (Rule). Полное описание стиля (селектор + описание).
Таким образом, таблица стилей — это набор правил, задающих значения свойств селекторов, перечисленных в этой таблице. Общий синтаксис описания правила выглядит так:
селектор[, селектор[, ...]] {свойство: значение;}
Регистр символов значения не имеет, порядок перечисления селекторов в таблице и свойств в определении не регламентирован.
Правила CSS
Итак, каскадная таблица стилей — это набор правил форматирования тегов HTML. Приведем несколько примеров написания таких правил:
1. Основной текст с выравниванием по ширине, абзацный отступ 30px, гарнитура (шрифт) — Serif, кегль (размер шрифта) — 14px:
p {
text-align: justify; text-indent: 30px; font-family: Serif; font-size: 14px;
}
Это правило будет применено ко всем тегам <p>.
2. Синий цвет для заголовков с первого по третий уровень:
h1, h2, h3 {
color: blue; /* тоже самое, что и #0000FF */
}
3. Таблицы и изображения выводить без обрамления:
table, img {border: none;}
4. Ссылки в элементах списков показывать без подчеркивания:
li a {text-decoration: none;}
5. Внутренние отступы слева и справа для блоков (<div>), заголовков таблиц и ячеек таблиц установить в 10px и залить фон желтым цветом:
div, th, td {
padding-left: 10px; padding-right: 10px; background-color: yellow;
}
6. Все ссылки в документе отображать черным цветом и полужирным шрифтом, а в основном тексте и списках — обычным, а также выделять их зеленым цветом и подчеркивать только при наведении курсора (в описании правил использован псевдоэлемент a:hover).
a {color: black; font-weight: bold;}
p a, li a {font-weight: normal; text-decoration: none;} p a:hover, li a:hover {
color: #00FF00; text-decoration: underline;
}
Классы
Стандарт CSS представляет возможности создания именованных стилей — стилевых классов. Это позволяет ответить на такой, например, вопрос: Как применить разные стили к одному и тому же селектору?
Предположим, что в документе вам нужны два различных вида основного текста — один без отступа, второй — с левым отступом и шрифтом красного цвета. Для этого нужно создать правила для каждого из них, например так:
p {margin-left: 0;}
p.warn {margin-left: 40px; color: #FF00;}
Для применения созданного класса его имя нужно указать в атрибуте class для выбранных абзацев:
<p class=”warn”>Красный текст с отступом слева<^>
Общий синтаксис описания класса:
селектор.имя_класса {описание}
При создании класса селектор можно не указывать, тогда это правило можно применять к любому селектору, поддерживающему тот же набор свойств.
Вот несколько примеров:
Правило:
.solid_blue {color: blue;}
Использование:
<p class=”solid_blue”>Синий текст абзаца<^>
<li class=”solid_blue”>Синий текст элемента списка</^>
Правило:
h1.bigsans {font-family: Sans; font-size: 1.5em;}
h1.smallserif {font-family: Serif; font-size: .84em;}
Использование:
<h1 class=”bigsans”>Большой, но рубленый</1п1>
<h1 class=”smallserif”>Маленький, но с засечками</1п1>
Идентификаторы
В качестве селектора может выступать идентификатор элемента гипертекста, указанный в атрибуте id. Для назначения стилей таким элементам используется синтаксис, аналогичный описанию классов, но вместо точки ставится знак # (“решетка”). Например:
div#content {
position: absolute; top: 10px; left: 10%; right: 10%;
border: solid 1px silver;
}
<div id="content">Текст</div>
Следует помнить, что идентификаторы элементов должны быть уникальны в пределах документа.
Группировка свойств
Группировка (grouping) состоит в объединении значений родственных свойств. При этом таблица стилей становится более компактной, но предъявляются более жесткие требования к описанию правил. Ниже приведен пример обычного стиля, задающего отступы:
div {
margin-left: 10px; margin-top: 5px; margin-right: 40px; margin-bottom: 15px;
}
Это же правило можно переписать с группировкой в следующем виде:
div {margin: 5px 40px 15px 10px;} /*порядок: top right bottom left*/
Оба стиля будут отображаться одинаково.
Группировка может применяться для таких свойств, как padding, font, border, background и еще некоторых (см. документацию CSS)
Использование в веб-страницах
Существует три способа применения таблицы стилей к документу HTML:
• • Встраивание (Inline). Этот метод позволяет применить стиль к заданному тегу HTML.
• Внедрение (Embedded). Внедрение позволяет управлять стилями страницы целиком.
• Связывание (Linked или External). Связанная таблица стилей позволяет вынести описание стилей во внешний файл, ссылаясь на который можно контролировать отображение всех страниц сайта.
Встроенные стили
Встраивание стилей предоставляет максимальный контроль над всеми элементами веб-страницы. Встроенный стиль применяется к любому тегу HTML с помощью атрибута style следующим образом:
<p style="font: 12pt Courier"^™ текст с кеглем 12 точек и гарнитурой Courier</P>
Пример:
<div style="font-family: Garamond; font-size: 18 pt;>"
Весь текст в этом разделе имеет размер 18 точек и шрифт Garamond.
<span style="color:#ff3300;">
А этот фрагмент еще и выделен красным цветом.</span>
</div>
Встроенные стили полезны, когда необходима тонкая настройка отображения некоторого элемента страницы или небольшой веб-страницы.
Внедренные стили
Внедренные стили используют тег <style>, который обычно размещают в заголовке HTML-документа (<head>...</head>):
<html>
<head>
<style>
правила CSS
</style>
</head>
<body>
Связанные таблицы стилей
Связанные (linked), или внешние (external) таблицы стилей — наиболее удобное решение, когда речь идет об оформлении целого сайта. Описание правил помещается в отдельный файл (обычно, но не обязательно, с расширением .css). С помощью тега <link> выполняется связывание этой таблицы стилей с каждой страницей, где ее необходимо применить, например так:
<link rel=stylesheet href="sample.css" type="text/css">
Любая страница, содержащая такую связь, будет оформлена в соответствии со стилями, указанными в файле sample.css. Следует отметить, что файл со стилями физически может находиться на другом веб-сервере, тогда в href нужно указать абсолютный путь к нему.
Проблемы с браузерами
Обязательно просматривайте страницы с таблицами стилей в различных браузерах. Это связано с тем, что разные браузеры могут по разному интерпретировать одно и то же правило, а некоторые свойства и/или значения и вовсе не поддерживать. Следует также тестировать страницы с отключенными стилями (например, в текстовых браузерах), чтобы убедиться, что страница читабельна.
И снова каскадирование
Если вам нужна сотня-другая-третья страниц HTML — используйте внешнюю, глобальную, таблицу стилей. Если некоторые из этих страниц требуют корректировки общего оформления — используйте внедренный стиль. А если на странице нужно явно изменить оформление одного-двух элементов, то применяйте встроенные стили. Именно в таком порядке происходит перекрытие стилей при каскадировании, схематично это можно представить так: связанные стили -> внедренные стили -> встроенные стили
Аппаратно-зависимые стили
Таблицы стилей могут применяться для управления отображением содержимого в зависимости от используемого устройства вывода (монитор, проектор, устройство печати, звуковой синтезатор и т.п.). Для этого в описание стилей включить тип устройства, например так:
@media print {/* печатающее устройство */
BODY { font-size: 10pt; }
}
@media screen { /* монитор */
BODY { font-size: 12pt; }
}
@media screen, print {
BODY { line-height: 1.2; }
}
@media all {
BODY { margin: 1pt; }
}
Как видно из примера, вся таблица разбивается на секции, каждая из которых начинается со слова @media, за которым следует название класса устройств и далее, в фигурных скобках, непосредственно описание стилей.
Можно разделить таблицы стилей иначе, указав тип устройства в теге <link>:
<link rel=stylesheet href="sample.css" type="text/css" media=”screen”>
Лекция 4. Динамический HTML. DOM и клиентские скрипты
(6-7 неделя, 2 часа)
По мере развития индустрии создания Web-сайтов возникла потребность расширить возможности использовать мультимедиа как инструмента Web-дизайнера при создании Web-страниц.
Эту проблему решает динамический язык HTML (DHTML).
DHTML дает возможность создавать элементы Web-страниц (типа текста и графики) интерактивными и динамическими. При этом Web-страницы DHTML загружаются просто мгновенно.
Все последние версии программного обеспечения Web-броузеров Microsoft и Netscape поддерживают язык DHTML.
Теперь в распоряжении Web-дизайнеров есть целая куча новых интерактивных эффектов, включая возможности организации текста и графики в виде презентаций типа телевизионных заставок.
Эффекты DHTML создаются с помощью трех технологий: HTML, каскадных таблиц стилей и сценариев.
Хотя все эти технологии существовали уже долгое время, сейчас они используются вместе и предоставляют дизайнерам возможности создания Web-страниц, которые выглядят и работают лучше, чем когда-либо прежде.
Самое главное - это научиться мыслить динамически!
HTML служит основой для эффектов DHTML.
Каскадные таблицы стилей (CSS) предоставляют возможности точной установки графических элементов на Web-страницах ).
Кроме того, существуют эффекты изменения внешнего вида текста и графики на странице - называемые "фильтры". Фактические возможности фильтров определяются компонентами Web-браузера.
Существуют статические и динамические фильтры.
Статические фильтры просто изменяют внешний вид элемента. Динамические фильтры позволяют изменить графический элемент со скоростью, задаваемой пользователем. Работа динамических фильтров основана на сценариях.
Создание сценариев
С помощью CSS каждый элемент Web-страницы можно не только точно установить в определенное место, но также сделать доступным для применения специальных операций и задания нужных свойств. Эти свойства управляются с помощи сценариев (scripts). Сценарий делает элементы Web-страницы динамическими - кнопки "нажимаются", текст появляется и исчезает, а изображения просто летают по экрану.
DHTML можно реализовывать с помощью двух языков сценариев: VBScript (Visual Basic Scripting ) и JavaScript. Visual Basic Scripting и является упрощенной версией языка программирования Microsoft Visual Basic. JavaScript - это версия языка программирования Java (от фирмы Sun Microsystems) для создания сценариев.
Что такое JavaScript?
JavaScript это разработанный корпорацией Netscape межплатформенный объектно-ориентированный язык скриптинга (сценариев). Ядро JavaScript содержит набор основных объектов, таких как Array, Date и Math, и основной набор элементов языка, таких как операции, управляющие структуры и операторы.
Ядро JavaScript может быть расширено путём предоставления дополнительных объектов; например:
• Клиентский JavaScript расширяет ядро языка за счёт объектов, управляющих браузером (Navigator или другой подобный web-браузер) и его Document Object Model (DOM). Например, клиентские расширения позволяют приложению размещать элементы на HTML-форме и отвечать на пользовательские события, такие как щелчок мышью, ввод данных в форму и навигация по страницам.
• Серверный JavaScript расширяет ядро языка за счёт объектов, имеющих отношение к работе JavaScript на сервере. Например, серверные расширения позволяют подключиться к реляционной БД, поддерживать непрерывность информации между вызовами приложения или работать с файлами на сервере.
JavaScript даёт Вам возможность создавать приложения, работающие в Internet. Клиентские приложения работают в браузере, таком как Netscape Navigator, а серверные приложения запускаются на сервере, таком как Netscape Enterprise Server. Используя JavaScript, Вы можете создавать динамические HTML-страницы, которые обрабатывают пользовательский ввод и работают с данными через использование специальных объектов, файлов и реляционных баз данных.
С помощью функциональности LiveConnect Вы можете дать возможность коду Java и JavaScript взаимодействовать. Из JavaScript Вы можете инстанциировать Java-объекты и получить доступ к их public-методам и полям. Из Java Вы можете иметь доступ к объектам, методам и свойствам JavaScript.
Ядро, клиентский и серверный JavaScript
Компоненты JavaScript показаны на этом рисунке.

Рисунок 1.1 Язык JavaScript
Следующие разделы являются введением в JavaScript на клиенте и на сервере. Ядро JavaScript
Клиентский и серверный JavaScript имеют следующие общие элементы:
• Ключевые слова
• Синтаксис и грамматику операторов
• Требования к выражениям, переменным и литералам
• Объектную модель (хотя клиентский и серверный JavaScript имеют разные наборы предопределённых объектов)
• Предопределённые объекты и функции, такие как Array, Date и Math
Клиентский JavaScript
Web-браузеры, такие как Navigator (2.0 и более поздние версии), могут интерпретировать операторы клиентского JavaScript, внедрённые в HTML-страницу. Если браузер (или клиент) запрашивает такую страницу, сервер высылает полное содержимое документа, включая HTML и операторы JavaScript, клиенту по сети. Браузер читает страницу сверху вниз, отображая результирующий HTML и выполняя операторы JavaScript по мере из обнаружения. Этот процесс, показанный на следующем рисунке, выдает пользователю конечный результат.
Операторы клиентского JavaScript, внедрённые в HTML-страницу, могут реагировать на пользовательские события, такие как щелчок мыши, ввод данных в форму и навигация по странице. Например, Вы можете написать функцию JavaScript для проверки правильности введённой пользователем в форму информации - номера телефона или zip-кода. Без передачи по сети, JavaScript, внедрённый на HTML-страницу, может проверить введённые данные и вывести диалоговое окно, если пользователь ввёл неправильные данные.
Разные версии JavaScript работают с конкретными версиями Navigator^. Например, JavaScript 1.2 предназначен для Navigator 4.0. Некоторые возможности JavaScript 1.2 недоступны в JavaScript 1.1 и, следовательно, недоступны в Navigator 3.0. О версиях JavaScript и Navigator Серверный JavaScript
Серверный JavaScript также встраивается в HTML-страницы. Серверные операторы могут подключать к реляционным БД разных производителей, предоставлять информацию в совместное использование несколькими потребителями, давать доступ к файловой системе сервера или взаимодействовать с другими приложениями через LiveConnect и Java. HTML-страницы с серверным JavaScript могут также содержать клиентский JavaScript.

Рисунок 1.2 Клиентский JavaScript
В отличие от страниц, написанных на чисто клиентском JavaScript, HTML-страницы с серверным JavaScript компилируются в байт-код исполняемых файлов.

Рисунок 1.3 Серверный JavaScript в процессе разработки
Эти исполняемые файлы запускаются web-сервером, имеющим машину выполнения JavaScript. Поэтому создание приложений JavaScript это процесс из двух этапов.
На первом этапе, показанном на Рисунке 1.3. Вы создаёте HTML-страницы (которые могут содержать операторы клиентского и серверного JavaScript) и JavaScript-файлы. Затем Вы компилируете все эти файлы в единый исполняемый файл.
На втором этапе, показанном на Рисунке 1.4, страница приложения запрашивается клиентским браузером. Машина выполнения использует исполняемый файл приложения для поиска исходной страницы и динамически генерирует возвращаемую клиенту HTML-страницу. Машина запускает на выполнение операторы серверного JavaScript, найденные на странице. В результате этого на HTML-страницу могут быть добавлены новый HTML или операторы JavaScript. Машина выполнения высылает результирующую страницу по сети Navigator'у-клиенту, который запускает на выполнение клиентский JavaScript и выводит результаты.

Рисунок 1.4 Серверный JavaScript на этапе прогона
В отличие от стандартных программ Common Gateway Interface (CGT), весь исходный JavaScript интегрируется непосредственно в HTML-страницы, ускоряя разработку и облегчая обслуживание. Служба Session Management Service серверного JavaScript содержит объекты, которые Вы можете использовать для обслуживания данных, существующих в промежутке между клиентскими запросами, нескольких клиентов и нескольких приложений. Служба LiveWire Database Service серверного JavaScript предоставляет объекты для доступа к БД, являясь интерфейсом для Structured Query Language (SQD-серверов БД.
Лекция 5. Сценарный язык программирования JavaScript, библиотека jQuery
(8-9 неделя, 2 часа)
Лекция 6. Основы серверных технологий (Node.js, HTTP, базы данных)
(6-7 неделя, 2 часа)
Понимание серверной стороны приложения потребует от вас более глубого изучения модели «клиент — сервер», протокола HTTP и Node.js. Замечу, что Node.js — относительно новая (и превосходная!) технология, которая позволяет создавать событийно-управляемые серверы с помощью JavaScript.
Настройка рабочего окружения
Настройка рабочего окружения с поддержкой приложений, управляемых базами данных, может быть непростой задачей, и описание этой процедуры для Windows, Mac OS и Linux выходит за рамки книги. Для упрощения процесса я создал набор сценариев, которые помогут вам приступить к работе с использованием VirtualBox и Vagrant достаточно быстро.
Vagrant — это инструмент для настройки рабочего окружения на виртуальной машине. Вы можете думать о виртуальных машинах как об отдельных компьютерах, работающих полностью в пределах вашего компьютера. Мы поговорим о них подробнее в разделе «Ментальные модели». А сейчас просто запомните, что мы будем использовать Vagrant и VirtualBox для настройки виртуального рабочего окружения на серверной стороне. Это окружение будет включать в себя большинство инструментов, которые понадобятся нам в оставшейся части книги.
В общем-то, часть этого процесса связана в большей степени с удобством: хотя установка рабочего окружения Node.js на вашей локальной машине совсем не сложна (и в конце главы я буду рекомендовать вам сделать это самостоятельно), добавление набора инструментов для сервера, включая MongoDB и Redis, довольно нетривиально и требует много времени и терпения.
Клиенты и серверы
В области компьютерных сетей о программах обычно говорят либо как о серверных, либо как о клиентских. Традиционно серверная программа рассматривает какой-либо ресурс как сеть, в которую могут получить доступ несколько клиентских программ. Например, кому-либо может понадобиться переместить файлы с удаленного компьютера на локальный. FTP-сервер — это программа, которая предоставляет протокол передачи файлов (File Transfer Protocol), позволяющий пользователям сделать это. А FTP-клиент — это программа, которая устанавливает связь с FTP-сервером и передает файлы. Самая общая модель «клиент — сервер» представлена на рис. 6.6.
|
Рис. 6.6. Модель «клиент — сервер» |
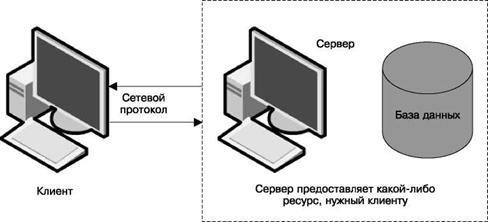
Многое из происходящего сейчас в мире компьютерных сетей является второстепенным для разработки веб-приложений, но нужно разобраться в некоторых важных вещах.
Во-первых, тот факт, что (в большинстве случаев) клиент — это браузер, а сервер — удаленная машина, которая опосредованным образом предоставляет ресурсы через протокол передачи гипертекста HTTP (Hypertext Transfer Protocol). Хотя изначально он был разработан для обмена HTML-документами между компьютерами, этот протокол может использоваться также для передачи различных типов ресурсов с удаленного компьютера (в частности, документы, базы данных или другие типы представлений). В дальнейшем нам придется немало говорить об HTTP, а пока просто запомните: это протокол, который мы используем, чтобы с помощью браузера связаться с удаленным компьютером.
Наши серверы HTTP будут использоваться для доставки клиентской части приложения, которую сможет интерпретировать браузер. В частности, все HTML, CSS и JavaScript, изученные нами к этому моменту, будут доставляться браузеру через сервер. Клиентская часть программы, запущенная в браузере, будет отвечать за получение информации с сервера и отправку информации на него, как правило, с помощью AJAX.
Хосты и гости
Обычно HTTP-сервер запускается на удаленной машине (позднее в этой книге мы проделаем это самостоятельно). Из-за этого у разработчиков возникают некоторые проблемы — если код запускается на удаленном сервере, приходится или редактировать код на удаленном сервере, а затем перезагружать его, или редактировать код локально и отправлять его на сервер всякий раз, когда нужно попробовать изменения. Это может быть нерационально.
Мы можем обойти эту проблему, запустив сервер на своей машине локально. Фактически мы делаем таким образом шаг вперед. Вместо того чтобы локально запустить программу сервера и все программное обеспечение, мы создаем внутри своего компьютера виртуальную машину, на которой запускается сервер. Для человека это выглядит так же, как удаленная машина (в том смысле, что мы подключаемся к ней через SSH, тем же способом, что и к удаленной машине). Но поскольку машина работает внутри нашего компьютера, можем просто предоставить локальной машине права доступа к папке с рабочими файлами и таким образом редактировать их.
Локальный компьютер, на котором запущена виртуальная машина, является хостом (хозяином). Виртуальная машина является гостем. В оставшейся части главы они оба будут запущены, и я буду четко разделять их.
Протокол HTTP
HTTP (HyperText Transfer Protocol — протокол передачи гипертекста) — символьно-ориентированный клиент-серверный протокол прикладного уровня без сохранения состояния, используемый сервисом World Wide Web.
Основным объектом манипуляции в HTTP является ресурс, на который указывает URI (Uniform Resource Identifier) - уникальный идентификатор ресурса) в запросе клиента. Основными ресурсами являются хранящиеся на сервере файлы, но ими могут быть и другие логические (напр. каталог на сервере) или абстрактные объекты (напр. ISBN). Протокол HTTP позволяет указать способ представления (кодирования) одного и того же ресурса по различным параметрам: mime-типу, языку и т. д. Благодаря этой возможности клиент и веб-сервер могут обмениваться двоичными данными, хотя данный протокол является текстовым.
Структура протокола
Структура протокола определяет, что каждое HTTP-сообщение состоит из трёх частей (рис. 1), которые передаются в следующем порядке:
1. Стартовая строка (англ. Starting line) — определяет тип сообщения;
2. Заголовки (англ. Headers) — характеризуют тело сообщения, параметры передачи и прочие сведения;
3. Тело сообщения (англ. Message Body) — непосредственно данные сообщения. Обязательно должно отделяться от заголовков пустой строкой.

Стартовая строка HTTP
Стартовая строка является обязательным элементом, так как указывает на тип запроса/ответа, заголовки и тело сообщения могут отсутствовать.
Стартовые строки различаются для запроса и ответа. Строка запроса выглядит так:
Метод URI HTTP/Версия протокола
Пример запроса:
GET /web-programming/index.html HTTP/1.1
Стартовая строка ответа сервера имеет следующий формат:
HTTP/Версия КодСостояния [Пояснение]
Например, на предыдущий наш запрос клиентом данной страницы сервер ответил строкой:
HTTP/1.1 200 Ok
Методы протокола
Метод HTTP (англ. HTTP Method) — последовательность из любых символов, кроме управляющих и разделителей, указывающая на основную операцию над ресурсом. Обычно метод представляет собой короткое английское слово, записанное заглавными буквами (Табл. 1). Названия метода чувствительны к регистру.
| Метод | Краткое описание |
| OPTIONS | Используется для определения возможностей веб-сервера или параметров соединения для конкретного ресурса. Предполагается, что запрос клиента может содержать тело сообщения для указания интересующих его сведений. Формат тела и порядок работы с ним в настоящий момент не определён. Сервер пока должен его игнорировать. Аналогичная ситуация и с телом в ответе сервера. Для того чтобы узнать возможности всего сервера, клиент должен указать в URT звёздочку — «*». Запросы «OPTIONS * HTTP/1.1» могут также применяться для проверки работоспособности сервера (аналогично «пингованию») и тестирования на предмет поддержки сервером протокола HTTP версии 1.1. Результат выполнения этого метода не кэшируется. Используется для запроса содержимого указанного ресурса. С помощью метода GET можно также начать какой-либо процесс. В этом случае в тело ответного сообщения следует включить информацию о ходе выполнения процесса. Клиент может передавать параметры выполнения запроса в URT целевого ресурса после символа «?»: GET /path/resource?param1=value1^m2=value2 HTTP/1.1 |
| GET | Согласно стандарту HTTP, запросы типа GET считаются идемпотентными[4] — многократное повторение одного и того же запроса GET должно приводить к одинаковым результатам (при условии, что сам ресурс не изменился за время между запросами). Это позволяет кэшировать ответы на запросы GET. Кроме обычного метода GET, различают ещё условный GET и частичный GET. Условные запросы GET содержат заголовки Tf-Modified-Since, Tf-Match, Tf-Range и подобные. Частичные GET содержат в запросе Range. Порядок выполнения подобных запросов определён стандартами отдельно. |
| HEAD | Аналогичен методу GET, за исключением того, что в ответе сервера отсутствует тело. Запрос HEAD обычно применяется для извлечения метаданных, проверки наличия ресурса (валидация URL) и чтобы узнать, не изменился ли он с момента последнего обращения. Заголовки ответа могут кэшироваться. При несовпадении метаданных ресурса с соответствующей информацией в кэше копия ресурса помечается как устаревшая. |
| POST | Применяется для передачи пользовательских данных заданному ресурсу. Например, в блогах посетители обычно могут вводить свои комментарии к записям в HTML-форму, после чего они передаются серверу методом POST и он помещает их на страницу. При этом передаваемые данные (в примере с блогами — текст комментария) включаются в тело запроса. Аналогично с помощью метода POST обычно загружаются файлы.В отличие от метода GET, метод POST не считается идемпотентным[4], то есть POST многократное повторение одних и тех же запросов POST может возвращать разные результаты (например, после каждой отправки комментария будет появляться одна копия этого комментария). При результатах выполнения 200 (Ok) и 204 (No Content) в тело ответа следует включить сообщение об итоге выполнения запроса. Если был создан ресурс, то серверу следует вернуть ответ 201 (Created) с указанием URI нового ресурса в заголовке Location. Сообщение ответа сервера на выполнение метода POST не кэшируется. |
| PUT | Применяется для загрузки содержимого запроса на указанный в запросе URI. Если по заданному URI не существовало ресурса, то сервер создаёт его и возвращает статус 201 (Created). Если же был изменён ресурс, то сервер возвращает 200 (Ok) или 204 (No Content). Сервер не должен игнорировать некорректные заголовки Content-* передаваемые клиентом вместе с сообщением. Если какой-то из этих заголовков не может быть распознан или не допустим при текущих условиях, то необходимо вернуть код ошибки 501 (Not Implemented). Фундаментальное различие методов POST и PUT заключается в понимании предназначений URI ресурсов. Метод POST предполагает, что по указанному URI будет производиться обработка передаваемого клиентом содержимого. Используя PUT, клиент предполагает, что загружаемое содержимое соответствуют находящемуся по данному URI ресурсу. Сообщения ответов сервера на метод PUT не кэшируются. |
| PATCH | Аналогично PUT, но применяется только к фрагменту ресурса. |
| DELETE | Удаляет указанный ресурс |
Заголовки HTTP
Заголовок HTTP (HTTP Header) — это строка в HTTP-сообщении, содержащая разделённую двоеточием пару вида «параметр-значение». Формат заголовка соответствует общему формату заголовков текстовых сетевых сообщений ARPA (RFC 822). Как правило, браузер и веб-сервер включают в сообщения более чем по одному заголовку. Заголовки должны отправляться раньше тела сообщения и отделяться от него хотя бы одной пустой строкой (CRLF).
Название параметра должно состоять минимум из одного печатного символа (ASCII-коды от 33 до 126). После названия сразу должен следовать символ двоеточия. Значение может содержать любые символы ASCII, кроме перевода строки (CR, код 10) и возврата каретки (LF, код 13).
Пробельные символы в начале и конце значения обрезаются. Последовательность нескольких пробельных символов внутри значения может восприниматься как один пробел. Регистр символов в названии и значении не имеет значения (если иное не предусмотрено форматом поля).
Пример заголовков ответа сервера:
Server: Apache/2.2.3 (CentOS)
Last-Modified: Wed, 09 Feb 2011 17:13:15 GMT
Content-Type: text/html; charset=UTF-8
Accept-Ranges: bytes
Date: Thu, 03 Mar 2011 04:04:36 GMT
Content-Length: 2945
Age: 51
X-Cache: HIT from proxy.omgtu Via: 1.0 proxy.omgtu (squid/3.1.8)
Connection: keep-alive
200 OK
Все HTTP-заголовки разделяются на четыре основных группы:
1. General Headers (Основные заголовки) — должны включаться в любое сообщение клиента и сервера.
2. Request Headers (Заголовки запроса) — используются только в запросах клиента.
3. Response Headers (Заголовки ответа) — присутствуют только в ответах сервера.
4. Entity Headers (Заголовки сущности) — сопровождают каждую сущность сообщения.
Сущности (entity, в переводах также встречается название "объект") — это полезная информация, передаваемая в запросе или ответе. Сущность состоит из метаинформации (заголовки) и непосредственно содержания (тело сообщения).
В отдельный класс заголовки сущности выделены, чтобы не путать их с заголовками запроса или заголовками ответа при передаче множественного содержимого (multipart/*). Заголовки запроса и ответа, как и основные заголовки, описывают всё сообщение в целом и размещаются только в начальном блоке заголовков, в то время как заголовки сущности характеризуют содержимое каждой части в отдельности, располагаясь непосредственно перед её телом.
Тело сообщения
Тело HTTP сообщения (message-body), если оно присутствует, используется для передачи сущности, связанной с запросом или ответом. Тело сообщения (message-body) отличается от тела сущности (entity-body) только в том случае, когда при передаче применяется кодирование, указанное в заголовке Transfer-Encoding. В остальных случаях тело сообщения идентично телу сущности.
Заголовок Transfer-Encoding должен отправляться для указания любого кодирования передачи, примененного приложением в целях гарантирования безопасной и правильной передачи сообщения. Transfer-Encoding - это свойство сообщения, а не сущности, и оно может быть добавлено или удалено любым приложением в цепочке запросов/ответов.
Присутствие тела сообщения в запросе отмечается добавлением к заголовкам запроса поля заголовка Content-Length или Transfer-Encoding. Тело сообщения (message-body) может быть добавлено в запрос только когда метод запроса допускает тело объекта (entity-body).
Все ответы содержат тело сообщения, возможно нулевой длины, кроме ответов на запрос методом HEAD и ответов с кодами статуса 1xx (Информационные), 204 (Нет содержимого, No Content), и 304 (Не модифицирован, Not Modified).
Лекция 7. Язык разметки XML. Технологии на основе XML
(12 неделя, 1 час)
Что такое XML?
XML (англ. extensible Markup Language — расширяемый язык разметки) — рекомендованный W3C универсальный язык разметки, предназначенный для описания структурированных данных, обмена информацией между программами и создания специализированных языков разметки (XML-словарей). Целью создания XML было обеспечение совместимости при передаче структурированных данных между разными системами обработки информации, особенно при передаче таких данных через Интернет.
Словари, основанные на XML (например, RDF, RSS, MathML, XHTML, SVG), сами по себе формально описаны на том же XML, что позволяет программно изменять и проверять документы на основе этих словарей, не зная их семантики, то есть не зная смыслового значения элементов. Важной особенностью XML также является применение так называемых пространств имён (англ. namespace).
Годом рождения XML можно считать 1996 год, в конце которого появился черновой вариант спецификации языка, или 1998 года, когда эта спецификация была утверждена. А началось всё с появления в 1986 году языка SGML (англ. Standard Generalized Markup Language — стандартный обобщённый язык разметки) - гибкого и всеохватывающего мета-языка для создания языков разметки. Этот язык настолько универсален, что включает такие возможности, которые крайне редко используются. Ценой универсальности является сложность и, как следствие, дороговизна применения языка в практических разработках. В итоге большинство возможностей SGML попросту не востребованы.
Однако SGML нашел свое применение в качестве основы для создания других языков разметки, в частности HTML - не в пример более простого и легкого в освоении языка. Но, по мере роста количества и изменения качества документов в Сети, росли и предъявляемые к ним требования, и простота HTML превратилась в его главный недостаток. Ограниченность количества тегов и полное безразличие к структуре документа побудили разработчиков в лице консорциума W3C к созданию такого языка разметки, который был бы не столь сложен, как SGML, и не настолько примитивен, как HTML. В результате на свет появился язык XML, сочетающий в себе простоту HTML, логику SGML и удовлетворяющий требованиям Интернета.
• Правильно построенный (Well-formed). Правильно построенный документ соответствует всем общим правилам синтаксиса XML, применимым к любому XML-документу. И если, например, начальный тег не имеет соответствующего ему конечного тега, то это неправильно построенный документ XML. Документ, который неправильно построен, не может считаться документом XML; XML-процессор (парсер) не должен обрабатывать его обычным образом и обязан классифицировать ситуацию как фатальная ошибка.
• Действительный (Valid). Действительный документ дополнительно соответствует некоторым семантическим правилам. Это более строгая дополнительная проверка корректности документа на соответствие заранее определённым, но уже внешним правилам, в целях минимизации количества ошибок, например, структуры и состава данного, конкретного документа или семейства документов.
Эти правила могут быть разработаны как самим пользователем, так и сторонними разработчиками, например, разработчиками словарей или стандартов обмена данными. Обычно такие правила хранятся в специальных файлах — схемах, где самым подробным образом описана структура документа, все допустимые названия элементов, атрибутов и многое другое. И если документ, например, содержит не определённое заранее в схемах название элемента, то XML-документ считается недействительным; проверяющий XML-процессор (валидатор) при проверке на соответствие правилам и схемам обязан (по выбору пользователя) сообщить об ошибке.
XML (eXtensible Markup Language) — это упрощенный диалект языка SGML, предназначенный для описания иерархических структур данных в World Wide Web. Он разрабатывается рабочей группой W3C с 1996 г.; в настоящее время принятой рекомендацией является вторая редакция языка XML 1.0 (октябрь 2000 г.), на которую и ориентируется дальнейшее изложение.
XML, несомненно, входит в обойму наиболее перспективных технологий WWW, чем объясняется интерес, который уделяется ему и корпорациями-разработчиками, и широкой публикой. Прежде чем перейти к его описанию, представляется уместным обсудить причины его появления и последующего бурного развития. Попытаемся для этого взглянуть на те проблемы WWW, которые должны быть решены средствами нового поколения Веб-технологий.
Чего не хватает HTML?
HTML не выражает смысла документов. Язык HTML был создан для описания структуры документов (название, заголовки, списки, абзацы и т. п.) и, в некоторой степени, правил их отображения (полужирный шрифт, курсивный шрифт и т. п.). Он ни в коей мере не предназначен для описания смысла написанных на нем документов, а во многих случаях именно данные составляют существо документа, будь-то биржевая сводка или научная публикация. Поэтому появилась необходимость в языке описания данных, причем данных, организованных в иерархические структуры.
HTML громоздок и негибок. За последние годы HTML превратился в нагромождение тегов, которые часто дублируют друг друга и отнюдь не вносят ясности в текст документа. Если добавить сюда еще и нестандартные расширения HTML, которыми грешат все разработчики обозревателей, то создание мало-мальски сложных HTML-документов становится серьезной задачей. С другой стороны, раз и навсегда зафиксированный набор тегов часто оказывается недостаточно гибким для выражения нужного нам содержания.
Концепция Веб-обозревателя слишком ограничена. С появлением Java-аплетов, сценарных языков и элементов ActiveX Веб-обозреватели перестали быть простыми "отображателями" HTML-документов; сегодня скорее они выглядят как программы, запускающие конкретные приложения. Тем не менее, сама концепция обозревателя накладывает излишние ограничения на пользователя; во многих случаях нам нужны Веб-ориентированные приложения, т. е. программы, способные читать специализированную информацию с Веб-узлов и выдавать нам ее в привычном виде, например, в виде электронных таблиц.
Поиск документов возвращает слишком много ссылок. Все мы постоянно пользуемся поисковыми системами и постоянно клянем их за неудобство работы. Допустим, что мне нужны все тексты книг Сергея Довлатова, имеющиеся в Сети.
Попытка поиска по имени автора приведет к тому, что я получу список всех ссылок с этим именем, включая воспоминания о Довлатове, рецензии на его книги и т. д. Намного удобнее было бы воспользоваться специальным тегом <AUTHOR>, чтобы указать, что именно я ищу. Невозможно найти взаимосвязанные ресурсы.
Допустим теперь, что я все же нашел несколько рассказов Довлатова, которые явно составляют единый сборник. Хорошо, если они содержат ссылку на оглавление, но часто это не так. Поэтому необходим способ указания того, что данная группа страниц составляет единый ресурс и должна обрабатываться соответственно. Для этого необходима стандартизованная и развитая система метаописателей Веб-страниц.
Что предлагает XML?
XML — это попытка решить перечисленные проблемы путем создания простого языка разметки, описывающего произвольные структурированные данные. Точнее говоря, это метаязык, на котором пишутся специализированные языки, описывающие данные определенной структуры. Такие языки называются XML-словарями. В отличие от HTML, XML не содержит никаких указаний на то, как описанные в XML-документе данные должны отображаться. Способ отображения данных для различных устройств задается языком описания стилей XSL, который играет для XML примерно ту же роль, что CSS дл HTML. Другое принципиальное его отличие от HTML состоит в том, что XML может содержать любые теги, которые сочтут нужным использовать создатели XML-словаря. Приведем список лишь нескольких специализированных языков на базе XML, которые сегодня находятся в разных стадиях разработки рабочими группами W3C:
• MathML — язык математических формул;
• SMIL — язык интеграции и синхронизации мультимедийных средств;
• SVG — язык двумерной векторной графики;
• RDF — язык метаописаний ресурсов;
• XHTML — переформулировка HTML в терминах XML.
Процесс обработки XML-документа состоит в следующем. Его текст анализируется специальной программой, которая называется XML-процессором. XML-процессор ничего не знает о семантике данных в документе; он только производит синтаксический разбор (parsing) текста документа и проверяет его правильность с точки зрени правил XML. Если документ правильно оформлен (well- formed), то результаты разбора текста передаются XML-процессором прикладной программе, которая выполняет их содержательную обработку; если же документ оформлен неверно, т. е. содержит синтаксические ошибки, то XML-процессор должен сообщить о них пользователю.
Применения XML
Возникает вопрос: а какой смысл в использовании "пустого языка", лишенного собственного содержания? Дело в том, что, несмотря на внешнюю простоту, XML обладает достаточно изощренными механизмами контроля правильности данных, позволяет производить проверку иерархических отношений внутри документа, и, самое главное, устанавливает единый стандарт для документов, хранящих данные, какова бы ни была природа этих данных. Остановимся подробнее на некоторых сферах применения языка XML.
Традиционная обработка данных. Перечисленные выше возможности позволяют рассматривать XML как платформо-независимый стандарт хранения и представления информации, который в сочетании с другими современными технологиями (в частности, с технологиями Java) способен стать основой для создания любых машинно-независимых приложений, в т. ч. для обмена данными между сервером и клиентом. Кроме того, активно разрабатываемые сегодня языки запросов на базе XML могут составить серьезную конкуренцию языку SQL.
Программирование, управляемое документом. XML-документы могут служить контейнерами для построения приложений из существующих интерфейсов и компонентов. В этом случае документ состоит из ссылок на компоненты пользовательского интерфейса и модули обработки данных, которые связываются в процессе отображения страницы на экране.
Архивирование компонентов. Современное программирование базируется на использовании компонентов, которые в идеале должны легко собираться в единое целое с помощью несложного дополнительного кодирования. Основой для этого служит архивирование компонентов, которое, в свою очередь, требует единообразного подхода к их хранению и последующему использованию. Есть все основания полагать, что в ближайшем будущем XML-документы окажутся альтернативой распространенному сегодня хранению компонентов в виде двоичных модулей.
Внедрение данных. После того, как мы определили структуру данных XML, принципиально несложно написать генератор кода, обрабатывающего эти данные. По мере развития подобных программных средств вся рутинная обработка данных (включая проверку их правильности, представление в нужном формате и т. п.) может быть автоматизирована, позволяя разработчикам сосредоточиться на нестандартных частях создаваемого продукта.
Лекция 8. Основы облачного развертывания (Cloud Foundry)
(13-14 неделя, 2 часа)
Cloud Foundry
Cloud Foundry — это открытый ресурс PaaS, изначально разработанный VMWare. Вы можете прочитать больше об этом сервисе на его домашней странице, расположенной по адресу http://cloudfoundry.com(рис. 8.1). Ресурс предлагает бесплатное использование на 60 дней, в течение которых вы можете попробовать загрузить туда некоторые из примеров-приложений из этой книги
Регистрация
Чтобы начать, вам нужно создать учетную запись на http://www.cloudfoundry.com. Вы можете получить 60 дней бесплатного использования, щелкнув на ссылке в верхнем правом углу и набрав свой адрес электронной почты. В ответ получите информацию о том, как настроить учетную запись.
Дата добавления: 2018-02-28; просмотров: 718; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!