Погрешности измерений. 2 страница
1. Факторы, постоянные или закономерно изменяющиеся в процессе измерительного эксперимента, например плавные изменения влияющих величин или погрешности применяемых при измерениях образцовых мер. Составляющие суммарной погрешности (1), определяемые действием факторов этой группы, называются систематическими погрешностями измерения. Их отличительная особенность в том, что они остаются постоянными или закономерно изменяются при повторных измерениях одной и той же величины. До тех пор, пока систематические погрешности больше случайных, их зачастую можно вычислить или исключить из результатов измерений надлежащей постановкой опыта.
2. Факторы, проявляющиеся весьма нерегулярно и столь же неожиданно исчезающие или проявляющиеся с интенсивностью, которую трудно предвидеть. К ним относятся, например, перекосы элементов приборов в их направляющих, нерегулярные изменения моментов трения в опорах, малые флюктуации влияющих величин, изменения внимания операторов и др.
Доля, или составляющая, суммарной погрешности измерения (1), определяемая действием факторов этой группы, называется случайной погрешностью измерения. Ее основная особенность в том, что она случайно изменяется при повторных измерениях одной и той же величины.
При создании измерительной аппаратуры и организации процесса измерения в целом интенсивность проявления большинства факторов данной группы удается свести к общему уровню, так что все они влияют более или менее одинаково на формирование случайной погрешности. Однако некоторые из них, например внезапное падение напряжения в сети электропитания, могут проявиться неожиданно сильно, в результате чего погрешность примет размеры, явно выходящие за границы, обусловленные ходом эксперимента в целом. Такие погрешности в составе случайной погрешности называются грубыми. К ним тесно примыкают промахи - погрешности, зависящие от наблюдателя и связанные с неправильным обращением со средствами измерений, неверным отсчетом показаний или ошибками при записи результатов.
|
|
|
Таким образом, мы имеем два типа погрешностей измерения:
- систематические погрешности, остающиеся постоянными или закономерно изменяющиеся при повторных измерениях.
- случайные (в том числе грубые погрешности и промахи), изменяющиеся случайным образом при повторных измерениях одной и той же величины;
В процессе измерения оба вида погрешностей проявляются одновременно, и погрешность измерения можно представить в виде суммы:

| (3.1) |
где  с- случайная, а - систематическая погрешности.
с- случайная, а - систематическая погрешности.
Для получения результатов, минимально отличающихся от истинных значений величин, проводят многократные наблюдения за измеряемой величиной с последующей математической обработкой опытных данных. Поэтому наибольшее значение имеет изучение погрешности как функции номера наблюдения, т. е. времени D(t). Тогда отдельные значения погрешностей можно будет трактовать как набор значений этой функции:
|
|
|
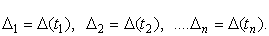
| (3.2) |
В общем случае погрешность является случайной функцией времени, которая отличается от классических функций математического анализа тем, что нельзя сказать, какое значение она примет в момент времени t. Можно указать лишь вероятности появления ее значений в том или ином интервале.
Предположим, что (ti)=0, т.е. систематические погрешности тем или иным способом исключены из результатов наблюдений, и будем рассматривать только случайные погрешности, средние значения которых равны нулю в каждом сечении. Предположим далее, что случайные погрешности в различных сечениях не зависят друг от друга, т.е. знание случайной погрешности в одном сечении как ординаты одной реализации не дает нам никакой дополнительной информации о значении, принимаемом этой реализацией в любом другом сечении. Тогда случайную погрешность можно рассматривать как случайную величину, а ее значения при каждом из многократных наблюдений одной и той же физической величины - как ее эмпирические проявления, т.е. как результаты независимых наблюдений над ней.
|
|
|
В этих условиях случайная погрешность измерений dc определяется как разность между исправленным результатом Х измерения и истинным значением А измеряемой величины:

| (3.3) |
причем исправленным будем называть результат измерений, из которого исключены систематические погрешности.
При проведении измерений целью является оценка истинного значения измеряемой величины, которое до опыта неизвестно. Результат измерения включает в себя помимо истинного значения еще и случайную погрешность, следовательно, сам является случайной величиной. В этих условиях фактическое значение случайной погрешности, полученное при поверке, еще не характеризует точности измерений, поэтому не ясно, какое же значение принять за окончательный результат измерения и как охарактеризовать его точность.
Ответ на эти вопросы можно получить, используя при метрологической обработке результатов измерения методы математической статистики, имеющей дело именно со случайными величинами.
КРАТКИЕ СВЕДЕНИЯ ИЗ ТЕОРИИ ВЕРОЯТНОСТИ.
|
|
|
Следует считать, что если событие может произойти, то оно обязательно произойдет. Все решает только вопрос времени. Возможность происхождения события в данный момент характеризуется вероятностью происхождения события – р. Если, например, событие А может происходить независимо от всех других событий – оно называется независимым, обозначается р(А) и не может превышать 1.

Вероятность осуществления события А называется в этом случае безусловной вероятностью.
Вероятность того, что событие А не произойдет, обозначается р( ).
).
р()=1-р(А).
Если событие А не может произойти вне зависимости от события В, то оно называется зависимым.
Вероятность осуществления события А при условии, что произошло событие В, обозначается р(A/B) и называется условной вероятностью события А.
Если события А и В независимы друг от друга, то имеет место математическая запись:

Степень зависимости событий оценивается коэффициентами регрессии и корреляции.
Коэффициент регрессии события А относительно события В записывается как:
r(А,В)=р(А/В)-р(А/  )
)
Коэффициент регрессии события В относительно события А записывается как:
r(В,А)=р(В/А)-р(В/ ).
Коэффициент корреляции (совпадений) событий А и В выражается формулой:
К(А,В)= 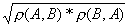
В том случае, если результаты опыта сводятся к схеме случая и общее число случаев (опытов) равно N, то вероятность события А выражается как:
р(А)=NA/N,
где NA-число случаев благоприятных событию А (или число случаев, при которых событие А произошло).
Для достоверной оценки вероятности проявления события необходимо провести ряд опытов, количество которых определяет степень достоверности результата. В метрологии принято считать, что если произведено 30 или более опытов, то ряд называется репрезентативным или представительным. Если опытов было меньшее количество, то ряд называют нерепрезентативным (не представительным).
Описание случайных погрешностей с помощью функций распределения
Рассмотрим результат наблюдений Х за постоянной физической величиной Q как случайную величину, принимающую различные значения Z, в различных наблюдениях за ней. Значения  будем называть результатами отдельных наблюдений.
будем называть результатами отдельных наблюдений.
Наиболее универсальный способ описания случайных величин заключается в отыскании их интегральных или дифференциальных функций распределения.
Под интегральной функцией распределения результатов наблюдений понимается зависимость вероятности того, что результат наблюдения в i -м опыте окажется меньшим некоторого текущего значения х, от самой величины х:

| (3.4) |
Здесь и в дальнейшем большие буквы используются для обозначения случайных величин, а маленькие - значений, принимаемых случайными величинами. Поскольку функция распределения вероятности представляет собой вероятность, то она удовлетворяет следующим свойствам:

На рисунке 3.1 показаны примеры функций распределения вероятности.

Рис. 3.1.
Более наглядным является описание свойств результатов наблюдений и случайных погрешностей с помощью дифференциальной функции распределения, иначе называемой плотностью распределения вероятностей:

| (3.5) |
Физический смысл f(x) состоит в том, что произведение f(x)dx представляет вероятность попадания случайной величины Х в интервал от х до х + x, т.е.
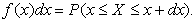
Свойства плотности распределения вероятности:
 -вероятность достоверного события равна 1;иными словами, площадь, заключенная между кривой дифференциальной функции распределения и осью абсцисс, равна единице;
-вероятность достоверного события равна 1;иными словами, площадь, заключенная между кривой дифференциальной функции распределения и осью абсцисс, равна единице;
 - вероятность попадания случайной величины в интервал от
- вероятность попадания случайной величины в интервал от  до
до  .
.
От дифференциальной функции распределения легко перейти к интегральной путем интегрирования:

| (3.6) |
Размерность плотности распределения вероятностей, как это следует из формулы, обратна размерности измеряемой величины, поскольку сама вероятность - величина безразмерная.
Используя понятия функций распределения, легко получить выражения для вероятностей того, что результат наблюдений Х или случайная погрешность  примет при проведении измерения некоторое значение в интервале
примет при проведении измерения некоторое значение в интервале  или
или  .
.
В терминах интегральной функции распределения имеем:


т.е. вероятность попадания результата наблюдений или случайной погрешности в заданный интервал равна разности значений функции распределения на границах этого интервала.
Заменяя в полученных формулах интегральные функции распределения на соответствующие плотности распределения вероятностей согласно выражению, получим формулы для искомой вероятности в терминах дифференциальной функции распределения:


Таким образом, вероятность попадания результата наблюдения или случайной погрешности в заданный полуоткрытый интервал равна площади, ограниченной кривой распределения, осью абсцисс и перпендикулярами к ней на границах этого интервала. Необходимо отметить, что результаты наблюдений в значительной степени сконцентрированы вокруг истинного значения измеряемой величины и по мере приближения к нему элементы вероятности их появления возрастают. Это дает основание принять за оценку истинного значения измеряемой величины координату центра тяжести фигуры, образованной осью абсцисс и кривой распределения, и называемую математическим ожиданием результатов наблюдений:

| (3.7) |
В заключение можно дать более строгое определение постоянной систематической и случайной погрешностей.
Систематической постоянной погрешностью называется отклонение математического ожидания результатов наблюдений от истинного значения измеряемой величины:

| (3.8) |
а случайной погрешностью - разность между результатом единичного наблюдения и математическим ожиданием результатов

| (3.9) |
В этих обозначениях истинное значение измеряемой величины составляет

| (3.10) |
Виды распределения результатов наблюдения и случайных погрешностей
Случайная погрешность измерения образуется под влиянием большого числа факторов, сопутствующих процессу измерения. В каждой конкретной ситуации работает свой механизм образования погрешности. Поэтому естественно предположить, что каждой ситуации должен соответствовать свой тип распределения погрешности. Однако во многих случаях имеются возможности еще до проведения измерений сделать некоторые предположения о форме функции распределения, так что после проведения измерений остается только определить значения некоторых параметров, входящих в выражение для предполагаемой функции распределения.
Случайная погрешность характеризует неопределенность наших знаний об истинном значении измеряемой величины, полученных в результате проведенных наблюдений. Согласно К. Шеннону мерой неопределенности ситуации, описываемой случайной величиной X, является энтропия:

| (4.1) |
являющаяся функционалом дифференциальной функции распределения  . Можно предположить, что любой процесс измерения формируется таким образом, что неопределенность результата наблюдений оказывается наибольшей в некоторых пределах, определяемых допускаемыми значениями погрешности. Поэтому наиболее вероятными должны быть такие распределения , при которых энтропия обращается в максимум.
. Можно предположить, что любой процесс измерения формируется таким образом, что неопределенность результата наблюдений оказывается наибольшей в некоторых пределах, определяемых допускаемыми значениями погрешности. Поэтому наиболее вероятными должны быть такие распределения , при которых энтропия обращается в максимум.
Для выявления вида наиболее вероятных распределений рассмотрим несколько наиболее типичных случаев.
1. В классе распределений результатов наблюдений , обладающих определенной зоной рассеивания между значениями х = b и х = а шириной b-а=2а, найдем такое, которое обращает в максимум энтропию  при наличии ограничивающих условий:
при наличии ограничивающих условий:
 ,
,
 ,
,
 , где
, где 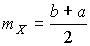 - математическое ожидание результатов наблюдений. Решение поставленной задачи находится методом множителей Лагранжа.
- математическое ожидание результатов наблюдений. Решение поставленной задачи находится методом множителей Лагранжа.
Искомая плотность распределения результатов наблюдений описывается выражением

Такое распределение результатов наблюдений называется равномерным.
Значения дифференциальной функции распределения равномерной распределенной случайной погрешности постоянны в интервале [- а; + а], а вне этого интервала равны нулю (см рисунок 4.1).
 Рис. 4.1
Рис. 4.1
Поэтому выражение для дифференциальной функции распределения случайной погрешности можно записать в виде

Определим числовые характеристики равномерного распределения. Математическое ожидание случайной погрешности находим по формуле:
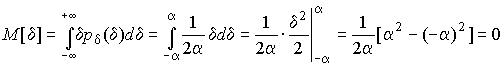
| (4.2) |
Дисперсию случайной равномерно распределенной погрешности можно найти по формуле:

| (4.3) |
В силу симметрии распределения относительно математического ожидания коэффициент асимметрии должен равняться нулю

| (4.4) |
Для определения эксцесса найдем вначале четвертый момент случайной погрешности:

| (4.5) |
поэтому

В заключение найдем вероятность попадания случайной погрешности в заданный интервал [  ], равный заштрихованной площади на рисунке.
], равный заштрихованной площади на рисунке.

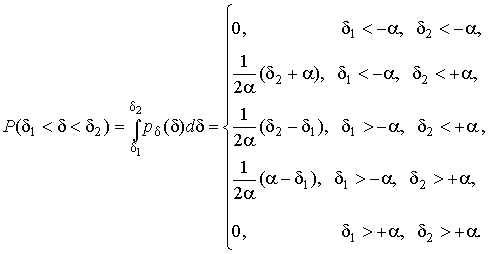
2. В классе распределений результатов наблюдений , обладающих определенной дисперсией  , найдем такое, которое обращает в максимум энтропию
, найдем такое, которое обращает в максимум энтропию  при наличии ограничений:
при наличии ограничений:
,  ,
,  ,
,  .
.
Решение этой задачи также находится методом множителей Лагранжа. Искомая плотность распределения результатов наблюдений описывается выражением

| (4.6) |
где  - математическое ожидание и
- математическое ожидание и  - среднеквадратическое отклонение результатов наблюдений.
- среднеквадратическое отклонение результатов наблюдений.
Учитывая, что при полном исключении систематических погрешностей 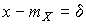 и
и  , для дифференциальной функции распределения случайной погрешности можно записать уравнение
, для дифференциальной функции распределения случайной погрешности можно записать уравнение

| (4.7) |
Распределение, описываемое этими уравнениями, называется нормальным или распределением Гаусса.
На рисунке изображены кривые нормального распределения случайных погрешностей для различных значений среднеквадратического отклонения  .
.

Из рисунка видно, что по мере увеличения среднеквадратического отклонения распределение все более и более расплывается, вероятность появления больших значений погрешностей возрастает, а вероятность меньших погрешностей сокращается, т.е. увеличивается рассеивание результатов наблюдений.
 Продолжение Л.4
Продолжение Л.4
Вычислим вероятность попадания результата наблюдения в некоторый заданный интервал  :
:

Заменим переменные:

после чего получим следующее выражение для искомой вероятности:
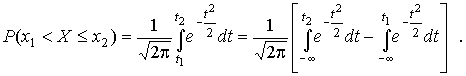
Интегралы, стоящие в квадратных скобках, не выражаются в элементарных функциях, поэтому их вычисляют с помощью так называемого нормированного нормального распределения с дифференциальной функцией

Далее приведены значения дифференциальной функции нормированного нормального распределения, а также интегральной функции этого распределения, определяемой как
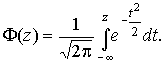
С помощью функции Ф(z) вероятность  находят как
находят как

При использовании данной формулы следует иметь в виду тождество

вытекающее непосредственно из определения функции Ф(z).
Широкое распространение нормального распределения погрешностей в практике измерений объясняется центральной предельной теоремой теории вероятностей, являющейся одной из самых замечательных математических теорем, в разработке которой принимали участие многие крупнейшие математики - Муавр, Лаплас, Гаусс, Чебышев и Ляпунов. Центральная предельная теорема утверждает, что распределение случайных погрешностей будет близко в нормальному всякий раз, когда результаты наблюдения формируются под влиянием большого числа независимо действующих факторов, каждый из которых оказывает лишь незначительное действие по сравнению с суммарным действием всех остальных.
1. Предположим, что результаты наблюдений распределены нормально, но их среднеквадратическое отклонение является величиной случайной, изменяющейся от опыта к опыту. Такое предположение более осторожное, чем предположение о неизменности в течение всего времени измерений. В этом случае, рассуждая таким же образом, как и прежде, легко найти, что энтропия обращается в максимум, если результаты наблюдений имеют распределение Лапласа с плотностью

| (5.1) |
где - математическое ожидание, - среднеквадратическое отклонение результатов наблюдения. Распределением Лапласа следует пользоваться в тех случаях, когда точностные характеристики заранее неизвестны или нестабильны во времени.
Дифференциальная функция распределения случайных погрешностей получается подстановкой  и
и  в предыдущее выражение:
в предыдущее выражение:

Асимметрия распределения равна нулю, поскольку распределение симметрично относительно нуля, а эксцесс составляет:

| (5.2) |
Таким образом, по сравнению с нормальным распределением (Ех = 0) равномерное распределение является более плосковершинным (Ех = -1.2), а распределение Лапласа - более островершинным (Ех=3).
Оценка с помощью интервалов
Смысл оценки параметров с помощью интервалов заключается в нахождении интервалов, называемых доверительными, между границами которых с определенными вероятностями (доверительными) находятся истинные значения оцениваемых параметров.
Вначале остановимся на определении доверительного интервала для среднего арифметического значения измеряемой величины. Предположим, что распределение результатов наблюдений нормально и известна дисперсия . Найдем вероятность попадания результата наблюдений в интервал  . Согласно формуле:
. Согласно формуле:

Но

и, если систематические погрешности исключены  ,
,

Это означает, что истинное значение Q измеряемой величины с доверительной вероятностью 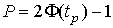 находится между границами доверительного интервала
находится между границами доверительного интервала  .
.
Половина длины доверительного интервала  называется доверительной границей случайного отклонения результатов наблюдений, соответствующей доверительной вероятности Р. Для определения доверительной границы (при выполнении перечисленных условий) задаются доверительной вероятностью, например Р=0.95 или Р=0.995 и по формулам
называется доверительной границей случайного отклонения результатов наблюдений, соответствующей доверительной вероятности Р. Для определения доверительной границы (при выполнении перечисленных условий) задаются доверительной вероятностью, например Р=0.95 или Р=0.995 и по формулам

определяют соответствующее значение  интегральной функции нормированного нормального распределения. Затем по данным находят значение коэффициента
интегральной функции нормированного нормального распределения. Затем по данным находят значение коэффициента 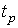 и вычисляют доверительное отклонение . Проведение многократных наблюдений позволяет значительно сократить доверительный интервал. Действительно, если результаты наблюдений
и вычисляют доверительное отклонение . Проведение многократных наблюдений позволяет значительно сократить доверительный интервал. Действительно, если результаты наблюдений  (i=l, 2,..., n) распределены нормально, то нормально распределены и величины
(i=l, 2,..., n) распределены нормально, то нормально распределены и величины  , а значит, и среднее арифметическое
, а значит, и среднее арифметическое  , являющееся их суммой. Поэтому имеет место равенство.
, являющееся их суммой. Поэтому имеет место равенство.

где  определяется по заданной доверительной вероятности Р.
определяется по заданной доверительной вероятности Р.
Полученный доверительный интервал, построенный с помощью среднего арифметического результатов n независимых повторных наблюдений, в  раз короче интервала, вычисленного по результату одного наблюдения, хотя доверительная вероятность для них одинакова. Это говорит о том, что сходимость измерений растет пропорционально корню квадратному из числа наблюдений.
раз короче интервала, вычисленного по результату одного наблюдения, хотя доверительная вероятность для них одинакова. Это говорит о том, что сходимость измерений растет пропорционально корню квадратному из числа наблюдений.
Половина длины нового доверительного интервала

| (5.3) |
называется доверительной границей погрешности результата измерений, а итог измерений записывается в виде
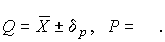
Теперь рассмотрим случай, когда распределение результатов наблюдений нормально, но их дисперсия неизвестна. В этих условиях пользуются отношением
Дата добавления: 2016-01-05; просмотров: 18; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!