Кодирование текстовой информации
СоставительГаниева Л., гр. 6161-52
Обновление 6_01_18
Введение
Одно из основных достоинств компьютера связано с тем, что это удивительно универсальная машина. Каждый, кто хоть когда-нибудь с ним сталкивался, знает, что занятие арифметическими подсчетами составляет совсем не главный метод использования компьютера. Компьютеры прекрасно воспроизводят музыку и видеофильмы, с их помощью можно организовывать речевые и видеоконференции в Интернет, создавать и обрабатывать графические изображения, а возможность использования компьютера в сфере компьютерных игр на первый взгляд выглядит совершенно несовместимой с образом суперарифмометра, перемалывающего сотни миллионов цифр в секунду.
Составляя информационную модель объекта или явления, мы должны договориться о том, как понимать те или иные обозначения. То есть договориться о виде представления информации.
Человек выражает свои мысли в виде предложений, составленных из слов. Они являются алфавитным представлением информации. Основу любого языка составляет алфавит - конечный набор различных знаков (символов) любой природы, из которых складывается сообщение.
Одна и та же запись может нести разную смысловую нагрузку. Например, набор цифр 251299 может обозначать: массу объекта; длину объекта; расстояние между объектами; номер телефона; запись даты 25 декабря 1999 года.
Для представления информации могут использоваться разные коды и, соответственно, надо знать определенные правила - законы записи этих кодов, т.е. уметь кодировать.
|
|
|
Код- набор условных обозначений для представления информации.
Кодирование- процесс представления информации в виде кода.
Для общения друг с другом мы используем код - русский язык. При разговоре этот код передается звуками, при письме - буквами. Водитель передает сигнал с помощью гудка или миганием фар. Вы встречаетесь с кодированием информации при переходе дороги в виде сигналов светофора. Таким образом, кодирование сводиться к использованию совокупности символов по строго определенным правилам.
Кодировать информацию можно различными способами: устно; письменно; жестами или сигналами любой другой природы.
Кодирование данных двоичным кодом.
По мере развития техники появлялись разные способы кодирования информации. Во второй половине XIX века американский изобретатель Сэмюэль Морзе изобрел удивительный код, который служит человечеству до сих пор. Информация кодируется тремя символами: длинный сигнал (тире), короткий сигнал (точка), нет сигнала (пауза) - для разделения букв.
Своя система существует и в вычислительной технике - она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами, по-английски - binary digit или сокращенно bit(бит).
|
|
|
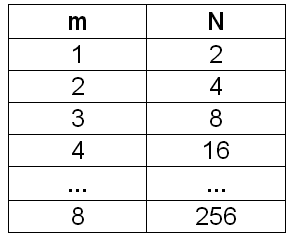
Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т.п.). Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия:
00 01 10 11
Тремя битами можно закодировать восемь различных значений:
000 001 010 011 100 101 110 111
Увеличивая на единицу количество разрядов в системе двоичного кодирования, мы увеличиваем в два раза количество значений, которое может быть выражено в данной системе, то есть общая формула имеет вид:
N = 2m,
где N — количество независимых кодируемых значений;
m — разрядность двоичного кодирования, принятая в данной системе.
Кодирование целых и действительных чисел
Кодирование целых чисел производиться через их представление в двоичной системе счисления: именно в этом виде они и помещаются в ячейке. Один бит отводиться при этом для представления знака числа (нулем кодируется знак "плюс", единицей - "минус").
Для кодирования действительных чисел существует специальный формат чисел с плавающей запятой. Число при этом представляется в виде:
|
|
|
где M - мантисса, p - порядок числа N, q -основание системы счисления. Если при этом мантисса M удовлетворяет условию, то число N называют нормализованным.
Мантисса и порядок числа при записи его в ячейке памяти представляются определенными группами битов. Два разряда отводятся под знаки мантиссы (числа) и порядка.
Кодирование текстовой информации
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Для хранения двоичного кода одного символа выделен 1 байт = 8 бит.
Учитывая, что каждый бит принимает значение 0 или 1, количество их возможных сочетаний в байте равно 28 = 256. Значит, с помощью 1 байта можно получить 256 разных двоичных кодовых комбинаций и отобразить с их помощью 256 различных символов. Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и заглавные буквы русского и латинского алфавита, цифры, знаки, графические символы и т.д.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
|
|
|
Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется в кодовой таблице. Кодирование текстовой информации с помощью байтов опирается на несколько различных стандартов, но первоосновой для всех стал стандарт ASCII (American Standart Code for Information Interchange), разработанный в США в Национальном институте ANSI (American National Standarts Institute). В системе ASCII закреплены две таблицы кодирования - базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 33 кода (с 0 до 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и т. д.).
Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Коды с 128 по 255 являются национальными, т.е. в национальных кодировках одному и тому же коду соответствуют различные символы. В настоящее время существует много различных кодовых таблиц для русских букв (КОИ-8, СР1251, СР866, Mac, ISO),поэтому тексты, созданные в одной кодировке , могут не правильно отображаться в другой.
Дата добавления: 2018-02-15; просмотров: 383; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!