Использование фиктивных переменных при построении уравнения множественной линейной регрессии
В ряде случаев, при построении уравнения регрессии, может возникнуть необходимость включения факторов, которые носят качественный характер. Это могут быть такие признаки как профессия, пол, образование, климатические условия, принадлежность к определенному региону и т.п. Для того чтобы включить подобные факторы в регрессионную модель им надо присвоить либо число 0, либо 1. Такого рода сконструированные переменные принято называть фиктивными переменными или манекенами.
Качественные признаки могут приводить к неоднородности исследуемой совокупности, что может быть учтено при моделировании двумя путями:
1) регрессия строится для каждой качественно отличной группы единиц совокупности, т.е. для каждой группы в отдельности, чтобы преодолеть неоднородность единиц общей совокупности;
2) общая регрессионная модель строится для совокупности в целом, учитывающей неоднородность данных. В этом случае в регрессионную модель вводятся фиктивные переменные, т.е. строится регрессионная модель с переменной структурой, отражающей неоднородность данных. Причем, существует правило: если качественная переменная имеет k альтернативных значений, то при моделировании используются только ( k -1) фиктивная переменная.
Проверка адекватности модели регрессии
Действия, выполняемые в данном случае, представляют собой процесс (этап) верификации модели регрессии, т.е. процесс, в ходе которого подвергается анализу качество полученной модели. С этой целью анализируется остаточная компонента 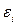 . Качество регрессионной модели характеризуется выполнением определенных статистических свойств и точностью, т.е. степенью близости к фактическим данным. Модель считается хорошей со статистической точки зрения, если она адекватна и достаточно точна.
. Качество регрессионной модели характеризуется выполнением определенных статистических свойств и точностью, т.е. степенью близости к фактическим данным. Модель считается хорошей со статистической точки зрения, если она адекватна и достаточно точна.
Теоретически доказано, что свойства оценок коэффициентов регрессии, а, следовательно, и качество построенной регрессии существенно зависят от свойств случайной составляющей . Для получения по МНК наилучших результатов необходимо, чтобы выполнялся ряд предпосылок относительно случайного отклонения .
Предпосылки применимости метода МНК (условия Гаусса-Маркова):
1. Математическое ожидание . равно нулю: М ( .) = 0.
Данное условие означает, что случайное отклонение в среднем не оказывает влияния на зависимую переменную. В каждом конкретном случае случайный член может быть либо положительным, либо отрицательным, но он не должен иметь систематического смещения. Выполнимость М ( .) = 0 влечет выполнимость  .
.
2. Дисперсия . постоянна: D( .) = 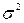 для всех i; данное условие подразумевает, что несмотря на то, что при каждом конкретном наблюдении случайное отклонение может быть большим, либо меньшим, не должно быть априорной причины , вызывающей большую ошибку (отклонение). Выполнимость данной предпосылки называется гомоскедастичностью (постоянством дисперсии отклонений). Невыполнимость данной предпосылки называется гетероскедастичностью (непостоянством дисперсий отклонений).
для всех i; данное условие подразумевает, что несмотря на то, что при каждом конкретном наблюдении случайное отклонение может быть большим, либо меньшим, не должно быть априорной причины , вызывающей большую ошибку (отклонение). Выполнимость данной предпосылки называется гомоскедастичностью (постоянством дисперсии отклонений). Невыполнимость данной предпосылки называется гетероскедастичностью (непостоянством дисперсий отклонений).
3. Значения . независимы между собой. Откуда вытекает, в частности, что

Выполнимость данной предпосылки предполагает, что отсутствует систематическая связь между любыми случайными отклонениями. Другими словами, величина и знак любого случайного отклонения не должны быть причинами величины и знака любого другого отклонения.
Если данное условие выполняется, то говорят об отсутствии автокорреляции остатков уравнения регрессии.
4. Величина . должна быть независима от объясняющих переменных: 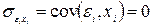 .
.
Выполнимость этой предпосылки не столь критична для эконометрических моделей.
Известно, что, если условия 1)-4) выполняются, то оценки, сделанные с помощью МНК, обладают следующими свойствами:
1) Оценки являются несмещенными, т.е. математическое ожидание оценки каждого параметра равно его истинному значению: М(а) =a; М(b)=b. Это вытекает из того, что М( .) = 0, и говорит об отсутствии систематической ошибки в определении положения линии регрессии.
2) Оценки состоятельны, так как дисперсия оценок параметров при возрастании числа наблюдений стремится к нулю:
 ;
;  .
.
Иначе говоря, если п достаточно велико, то практически наверняка а близко к a, а b близко к b: надежность оценки при увеличении выборки растет.
3) Оценки эффективны, они имеют наименьшую дисперсию по сравнению с любыми другими оценками данного параметра, линейными относительно результативного признака у . В англоязычной литературе такие оценки называются BLUE (Best Linear Unbiased Estimators - наилучшие линейные несмещенные оценки).
Перечисленные свойства не зависят от конкретного вида распределения величин ., тем не менее, обычно предполагается, что они распределены нормально. Эта предпосылка необходима для проверки статистической значимости сделанных оценок и определения для них доверительных интервалов. При ее выполнении оценки МНК имеют наименьшую дисперсию не только среди линейных, но среди всех несмещенных оценок.
Если свойства 3) и 4) нарушены, то есть дисперсия возмущений непостоянна и/или значения є связаны друг с другом, то свойства несмещенности и состоятельности сохраняются, но свойство эффективности - нет.
Наряду с выполнением указанных предпосылок МНК при построении классических регрессионных моделей предполагается:
1) объясняющие переменные не являются случайными величинами;
2) случайные отклонения имеют нормальные распределения;
3) отсутствуют ошибки классификации;
4) отсутствует совершенная мультиколлинеарность.
Проверка предпосылок МНК осуществляется следующим образом:
1. Математическое ожидание е i . равно нулю: М (е i ) = 0.
Равенство нулю математического ожидания ряда остатков означает выполнение следующего соотношения:
 .
.
Однако в случае применения метода наименьших квадратов такая проверка является излишней, поскольку использование МНК предполагает выполнение равенства  , откуда безусловным образом следует равенство нулю математического ожидания значений остаточного ряда.
, откуда безусловным образом следует равенство нулю математического ожидания значений остаточного ряда.
В общем, проверку условия 1 можно выполнить по t-критерию Стьюдента. Если расчетное значение статистики Стьюдента меньше табличного (критического) значения статистики Стьюдента (tрасч<tтабл), то с вероятностью α принята гипотеза H0, следовательно математическое ожидание остатков уравнения регрессии равно нулю и предпосылка выполняется.
2. Дисперсия . постоянна: D(е i ) = для всех i.
Равенство дисперсий подразумевает, что, несмотря на то, что при каждом конкретном наблюдении случайное отклонение может большим либо маленьким, положительным либо отрицательным, не должно быть некой априорной причины, вызывающей большую ошибку (отклонение) при одних наблюдениях и меньшую – при других.
Однако на практике гетероскедастичность не так уж и редка. Зачастую есть основания считать, что вероятностные распределения случайных отклонений при различных наблюдениях будут различными. Это не означает, что случайные отклонения обязательно будут большими при определенных условиях и малыми – при других, но это означает, что априорная вероятность этого велика.
На рис. 4.1 представлен пример линейной регрессии - зависимости потребления y от дохода х. На рис. А) дисперсия потребления остается одной и той же для различных уровней дохода, на рис. 4.1б при аналогичной зависимости среднего потребления от дохода дисперсия потребления не остается постоянной, а увеличивается с ростом дохода.
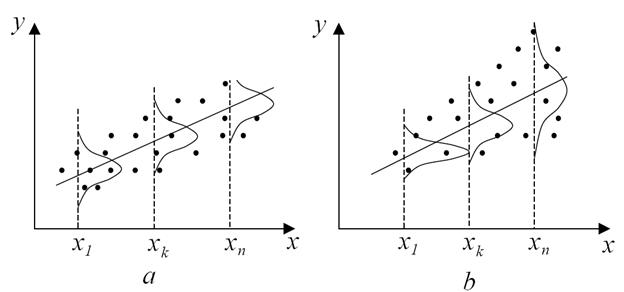
Рисунок 4.1 – Изучение гомоскедастичности а) и гетероскедастичности б)
Фактически это означает, что во втором случае субъекты с большим доходом в среднем потребляют больше, чем субъекты с меньшим доходом, и, кроме того, разброс в их потреблении более существенен для большего уровня дохода. Фактически люди с большими доходами имеют больший простор для распределения своего дохода. Реалистичность данной ситуации не вызывает сомнений. Разброс значений потребления вызывает разброс точек наблюдения относительно линии регрессии, что и определяет дисперсию случайных отклонений.
Проблема гетероскедастичности в большей степени характерна для пространственных данных и довольно редко встречается при рассмотрении временных рядов.
Если условие гомоскедастичности не выполняется, то имеет место гетероскедастичность. Гетероскедастичность в отдельных случаях может привести к смещенности оценок коэффициентов уравнения регрессии.
Гетероскедастичность будет сказываться на эффективности коэффициентов уравнения регрессии. Нельзя использовать формулу стандартной ошибки коэффициентов регрессии , так как она предполагает единую дисперсию остатков для любых значений фактора.
Практически нарушение гомоскедастичности означает, что 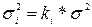 . При этом величина ki может меняться при переходе от одного значения фактора к другому, т.е. при наличии гетероскедастичности сумма квадратов отклонений имеет вид:
. При этом величина ki может меняться при переходе от одного значения фактора к другому, т.е. при наличии гетероскедастичности сумма квадратов отклонений имеет вид: 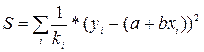 . Задача состоит в том, чтобы определить величину ki , т.е. внести поправку в исходные переменные. С этой целью рекомендуется использовать обобщенный МНК, который эквивалентен обычному МНК, примененному к преобразованным данным.
. Задача состоит в том, чтобы определить величину ki , т.е. внести поправку в исходные переменные. С этой целью рекомендуется использовать обобщенный МНК, который эквивалентен обычному МНК, примененному к преобразованным данным.
Наличие гетероскедастичности можно наглядно установить с помощью графического метода. Выводы о наличии гетероскедастичности будут более надежными, если использовать графики зависимости  или
или 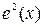 в случае парной регрессии и график зависимости
в случае парной регрессии и график зависимости 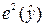 в случае множественной линейной регрессии.
в случае множественной линейной регрессии.
На рис. 4.2.а) все отклонения находятся внутри полуполосы постоянной ширины, параллельной оси абсцисс. Это говорит о независимости дисперсий от значений переменной и их постоянстве, т.е. этот случай соответствует гомоскедастичности.
На рис. 4.2 б) – г) наблюдаются некие систематические изменения в соотношениях между значениями переменной и квадратами отклонений, что отражает проявление гетероскедастичности.
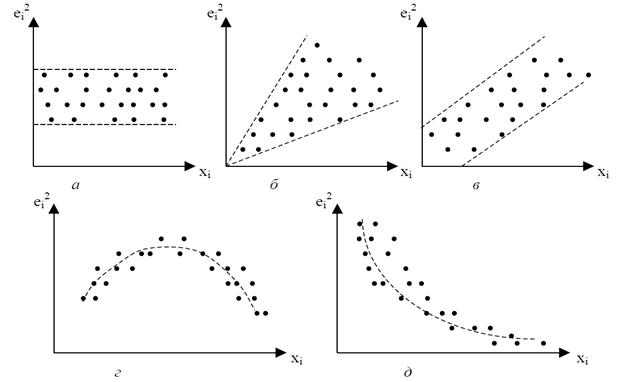
Рисунок 4.2 – Изучение графика остатков
Графический анализ отклонений является удобным и достаточно надежным в случае парной регрессии. При множественной регрессии графический анализ возможен для каждой отдельной объясняющей переменной. Чаще же вместо объясняющих переменных по оси абсцисс откладывают значения  (рис. 4.3).
(рис. 4.3).
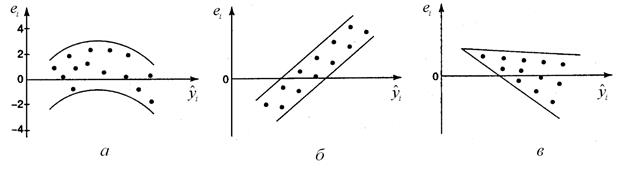
Рисунок 4.3 - Изучение графика остатков для множественной регрессии:
а – остатки неслучайны, б - остатки носят систематический характер,
в – остатки не имеют постоянной дисперсии
При малом объеме выборки для оценки гетероскедастичности можно использовать метод Голдфельда – Квандта. Но он применяется в том случае, если ошибки регрессии можно считать нормально распределенными случайными величинами. При обнаружении гетероскедастичности остатков уравнения регрессии ставится цель ее устранения, чему служит применение обобщенного метода наименьших квадратов (ОМНК). ОМНК применяется к преобразованным данным и позволяет получить оценки, которые обладают не только свойством несмещенности, но и имеют наименьшие выборочные дисперсии.
3. Значения е i независимы между собой.
Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при анализе временных рядов. При использовании пространственных данных наличие автокорреляции встречается довольно редко.
Приведем пример. Пусть исследуется спрос на прохладительные напитки от дохода по ежемесячным данным. Трендовая зависимость, отражающая увеличение спроса с ростом дохода, может быть представлена линейным уравнением, изображенным на рис. 4.4. Фактические точки наблюдений превышают трендовую линию в летние периоды и будут ниже в зимние. Это случай положительной автокорреляции.
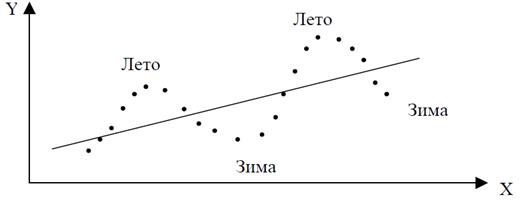
Рисунок 4.4 - Исследование спроса на прохладительные напитки Y от дохода X по месячным данным - случай положительной автокорреляции остатков уравнения регрессии
Отрицательная корреляция фактически означает, что за положительным отклонением имеет место отрицательное и наоборот. Возможная схема рассеивания точек в этом случае представлена на рис. 4.5. Такая ситуация может иметь место, например, если ту же зависимость между спросом на прохладительные напитки и доходами рассматривать по сезонным данным (зима – лето), а не помесячным, как это было в предыдущем примере с положительной автокорреляцией.
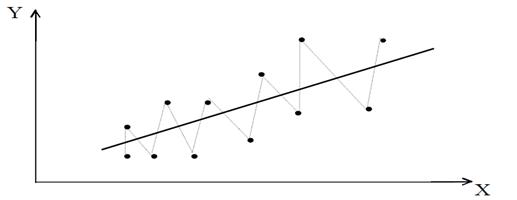
Рисунок 4.5 - Исследование спроса на прохладительные напитки Y от дохода X по сезонным (квартальным) данным - случай отрицательной автокорреляции остатков уравнения регрессии
Причинами автокорреляции являются: 1) ошибки спецификации, 2) инерция, 3) эффект паутины, 4) сглаживание данных.
Наличие автокорреляции в остатках приводит к тому, что оценки параметров перестают быть эффективными, оценки дисперсии становятся смещенными и заниженными, что влечет за собой увеличение t-статистик и признание статистической значимости уравнения регрессии, тогда как в действительности оно таковым не является и, следовательно, модель нельзя использовать для прогноза.
Возможно графическое определение автокорреляции путем построения и анализа последовательно-временных графиков зависимостей отклонений от моментов их получения (рис. 4.6).

Рисунок 4.6 – Исследование автокорреляции остатков уравнения регрессии
На рис. 4.6 а - г имеются определенные связи между отклонениями, т.е. автокорреляция имеет место. Отсутствие зависимости на рис. 4.6 д, скорее всего, свидетельствует об отсутствии автокорреляции.
На практике для анализа коррелированности отклонений используется статистика Дарбина-Уотсона. Расчетное значение DW рассчитывается по формуле:
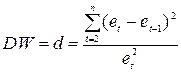 ,
,
где  - остатки уравнения регрессии (последующего и предыдущего номеров выборки),
- остатки уравнения регрессии (последующего и предыдущего номеров выборки),
n - объем выборки.
Значения статистики Дарбина-Уотсона находятся в пределах:
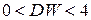 .
.
Табличное значение Дарбина-Уотсона находится по специальным таблицам, позволяющим при данном числе наблюдений n, количестве объясняющих переменных m, заданном уровне значимости α определить границы приемлемости гипотезы о наличии или отсутствии автокорреляции остатков. А именно по таблицам можно определить  - нижнюю границу и
- нижнюю границу и 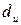 - верхнюю границу зоны неопределенности, в которой ничего нельзя сказать о наличии или отсутствии автокорреляции остатков:
- верхнюю границу зоны неопределенности, в которой ничего нельзя сказать о наличии или отсутствии автокорреляции остатков:
1) если 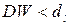 , то это свидетельствует о наличии положительной автокорреляции остатков уравнения регрессии.
, то это свидетельствует о наличии положительной автокорреляции остатков уравнения регрессии.
2) если 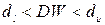 , то расчетное значение статистики Дарбина-Уотсона находится в зоне неопределенности, где об автокорреляции ничего сказать нельзя.
, то расчетное значение статистики Дарбина-Уотсона находится в зоне неопределенности, где об автокорреляции ничего сказать нельзя.
3) если 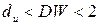 , то автокорреляция считается отсутствующей с вероятностью
, то автокорреляция считается отсутствующей с вероятностью  .
.
4) если 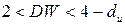 , то автокорреляция считается отсутствующей с вероятностью .
, то автокорреляция считается отсутствующей с вероятностью .
5) если  , то расчетное значение статистики Дарбина-Уотсона находится в зоне неопределенности, где об автокорреляции ничего сказать нельзя.
, то расчетное значение статистики Дарбина-Уотсона находится в зоне неопределенности, где об автокорреляции ничего сказать нельзя.
6) если 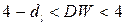 , это свидетельствует о наличии отрицательной автокорреляции остатков уравнения регрессии
, это свидетельствует о наличии отрицательной автокорреляции остатков уравнения регрессии
При наличии автокорреляции остатков построенное уравнение регрессии обычно считается неудовлетворительным.
4. Величина е i должна быть независима от объясняющих переменных , т.е. случайной переменной;
Пример выполнения условия 4: остатки е i не зависят от объясняющей переменной 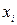 - рис. 4.7.
- рис. 4.7.
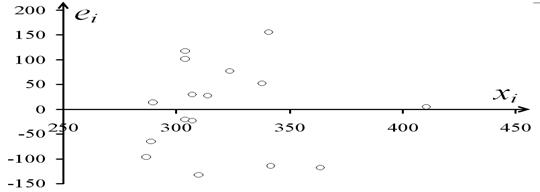
Рисунок 4.7 – Изучение изменения е i - пример случайных остатков
Если график показывает зависимость е i от величины , то модель не адекватна (рис. 4.8) . Причинами могут быть:
1) нарушена 3–я предпосылка МНК;
2) неправильная спецификация модели и в нее требуется ввести дополнительные члены , например, 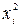 , или преобразовать значения y .
, или преобразовать значения y .
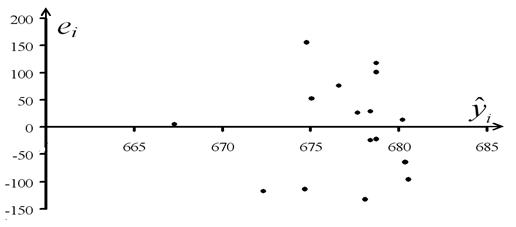
Рисунок 4.8 - Пример неслучайных остатков
Скопление точек в определенных участках значений фактора говорит о наличии систематической погрешности модели. Корреляция е i с позволяет проводить корректировку модели, в частности, использовать кусочно-линейные модели.
Необходимым для получения по МНК состоятельных оценок параметров регрессии является соблюдение 3–й и 4–й предпосылок.
Проверка случайности последовательности е i проводится с помощью критерия пиков (поворотных точек). Каждое значение ряда (е i) сравнивается с двумя, рядом стоящими. Точка считается поворотной, если она либо больше и предыдущего и последующего значения ( 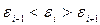 ), либо меньше и предыдущего и последующего значения (
), либо меньше и предыдущего и последующего значения ( 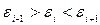 ).
).
В случайном ряду должно выполняться строгое неравенство: , (6.14)
 ,
,
где p - число поворотных точек;
[ ] - целая часть результата вычислений.
Нормальность распределения остатков можно проверить с помощью коэффициентов асимметрии и эксцесса. Последовательность проверки изложена в теоретической части к лабораторной №1.
Ниже изложена стандартная схема анализа регрессионных зависимостей:
1. Подбор начальной модели. Он осуществляется на основе экономической теории, предыдущих знаний об объекте исследования, опыта исследователя и его интуиции.
2. Оценка параметров модели на основе имеющихся статистических данных.
3. Осуществление тестов проверки качества модели (обычно используется статистика для коэффициентов регрессии, статистика для коэффициентов детерминации, статистика Дарбина-Уотсона для анализа остатков и ряд других тестов).
4. При наличии хотя бы одного неудовлетворительного ответа по какому-либо тесту модель совершенствуется с целью устранения выявленного недостатка.
5. При положительных ответах по всем проведенным тестам модель считается качественной. Она используется для анализа и прогноза зависимой переменной.
Однако не стоит абсолютизировать полученный результат. Даже качественная модель является подгонкой спецификации модели под имеющиеся данные. Поэтому бывает так, что разные исследователи строят разные модели для объяснения одной и той же переменной. Другая проблема заключается в том, что иногда хорошие с точки зрения диагностических тестов модели обладают весьма низкими прогнозными качествами.
Кроме того, до сих достаточно спорным является вопрос, как строить модель: начинать с самой простой и постепенно усложнять ее или же начинать с максимально сложной модели и упрощать ее на основе проводимых исследований. И тот и другой подход имеют как достоинства, так и недостатки.
Дата добавления: 2021-05-18; просмотров: 233; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!