Задачи для самостоятельного решения
1. Закодировать сообщение «РоссийскаяСистемаВысшегоТехническогоОбразования» методом Шеннона-Фано.
2. Пусть алфавит источника содержит шесть элементов {А, Б, В, Г, Д, Е}, появляющихся с вероятностями Р(А)=0,15, Р(В)=0,1, Р(Б)=0,25, Р(Г)=0,13, Р(Д)=0,25, Р(Е)=0,12. Найти энтропию такого источника, среднее число символов на одну букву при кодировании методом Ш-Ф.
3. Закодировать методом Шеннона-Фано блоки «мы все учились понемногу чему-нибудь и как-нибудь».
| блок | мы | все | учились | понемногу | чему | нибудь | и | как | - |
| вероятность | 0,37 | 0,13 | 0,125 | 0,08 | 0.06 | 0,052 | 0,023 | 0,11 | 0,05 |
Каково среднее число символов на знак?
4. Сообщение состоит из последовательности букв А, B и С, вероятности которых не зависят от предыдущего сочетания букв и равны Р(А)=0,7, Р(В)=0,2, Р(С)=0,1. Провести кодирование по алгоритму Шеннона-Фано отдельных букв и двухбуквенных сочетаний. Сравнить коды по их эффективности и избыточности.
5. Закодировать сообщение методом Шеннона-Фано «Теория информацииКодированияМодуляции».
6. Построить код Шеннона-Фано для системы из семи букв: A, B, C, D, E, F, G, вероятности появления которых соответственно 0,1, 0,2, 0,05, 0,3, 0,05, 0,15, 0,15. Определить среднее количество разрядов на одну букву. Декодировать этим кодом последовательность:
10011101001000111101110101111000.
7. Провести эффективное кодирование ансамбля из восьми знаков (m=8), используя метод Шеннона-Фано.
|
|
|
8. Построить код Шеннона-Фано двумя способами разбиения множества групп на подгруппы для символов источника сообщений, появляющихся с вероятностями, заданными таблицей:

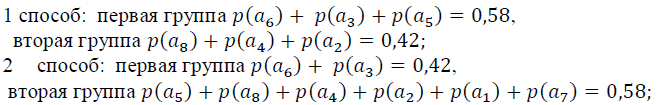
Провести сравнительный анализ результатов решения двумя способами.
9. Построить оптимальный код сообщения, состоящего из 5,6 7, 8 равновероятных букв. Дать оценку эффективности построенных кодов. В каких случаях код, построенный для первичного алфавита с равновероятным появление букв, окажется самым эффективным?
10. Построить код Хаффмана для ансамбля сообщений с вероятностями

11. Задан алфавит из трех символов с вероятностями 0,75, 0,1, 0,15. Произвести кодирование отдельных букв и двухбуквенных сочетаний по методу Хаффмана. Для полученных кодов найти средние длины и коэффициенты оптимальности.
12. Первичный алфавит состоит из букв А и В. Построить код по методу Хаффмана для передачи сообщений, если кодировать по одной, две, три буквы в блоке. Сравнить эффективность полученных кодов. Вероятности появления букв первичного алфавита имеют следующие значения: р(А)=0,87, р(В)=0,13.
13. Первичный алфавит состоит из букв А, В и С. Построить код по методу Хаффмана для передачи сообщений, если кодировать по одной, две, три буквы в блоке. Сравнить эффективность полученных кодов. Вероятности появления букв первичного алфавита имеют следующие значения: р(А)=0,6, р(В)=0,3, р(С)=0,1.
|
|
|
14. Символы источника

кодируются двоичными последовательностями:
a) 1, 01, 001, 0001; b) 1, 10, 100, 1000.
Являются ли данные коды префиксными, оптимальными? Какова средняя длина кодового слова?
15. Определить среднюю длину кодового слова и избыточность кода при кодировании по методу Фано, Шеннона, Хаффмана знаков ансамбля, приведенного ниже:

16. Источник информации задан вероятностной схемой:

Закодировать двоичными последовательностями ансамбль сообщений: 1) кодом Шеннона-Фано, 2) кодом Шеннона; 3) кодом Хаффмана, 4) равномерным двоичным кодом. Определить среднюю длину кодового слова и избыточность кода.
Дата добавления: 2021-07-19; просмотров: 928; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!