ОПРЕДЕЛЕНИЕ ИНТЕРВАЛЬНЫХ ОЦЕНОК НЕИЗВЕСТНЫХ
ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЙ
Цель и задачи работы
Научиться определять интервальные оценки с заданным уровнем доверия (доверительные интервалы) для неизвестных параметров распределений.
Порядок выполнения работы
- ознакомится с теоретическими сведениями;
- выполнить задание;
- оформить отчет;
- ответить на контрольные вопросы, заданные преподавателем.
Оформление отчета
Отчет должен содержать: титульный лист, цель работы, описание пунктов выполнения лабораторной работы в соответствии с заданием, ответы на контрольные вопросы и выводы по работе.
Теоретические сведения
В ряде задач требуется не только найти для параметра θ подходящую оценку, но и указать, к каким ошибкам может привести замена параметра его оценкой. Другими словами, требуется оценить точность и надежность оценки. Такого рода задачи особенно актуальны при малом числе наблюдений, когда точечная оценка в значительной мере случайна и приближенная замена этой оценкой истинного значения параметра θ может привести к серьезным ошибкам.
Для определения точности оценки θ в математической статистике пользуются доверительными интервалами, а для определения надежности – доверительными вероятностями.
Интервал (θ1,θ2) называется α – доверительным интервалом или доверительным интервалом с доверительной вероятностью 1−α, если
|
|
|
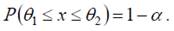
Рассмотрим задачу построения доверительных интервалов для неизвестных математического ожидания и дисперсии. Как известно, α – доверительный интервал для математического ожидания a выглядит следующим образом:

где s1 – среднеквадратическое отклонение (корень квадратный из исправленной выборочной дисперсии), Δn−1,α находится из таблицы для вероятностей P(tn−1>Δn−1,α)=α распределения tn−1 (распределение Стьюдента с n-1 степенью свободы).
Вводим в первый столбец, например, ячейки А1…А25 исходные данные. Задаем уровень значимости α=0.05. Далее для получения результатов подписываем ячейки, как на рис. 1.
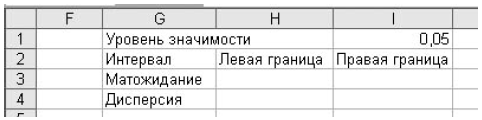
Рисунок 1 – Пример подписи ячеек для получения результатов
Для вычисления величины 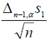 служит функция ДОВЕРИТ категории СТАТИСТИЧЕСКИЕ с тремя параметрами «Альфа» – уровень значимости α, «Станд. откл» – s1 – среднеквадратическое отклонение (корень квадратный из исправленной выборочной дисперсии), «Размер» – объем выборки n.
служит функция ДОВЕРИТ категории СТАТИСТИЧЕСКИЕ с тремя параметрами «Альфа» – уровень значимости α, «Станд. откл» – s1 – среднеквадратическое отклонение (корень квадратный из исправленной выборочной дисперсии), «Размер» – объем выборки n.
Таким образом, вводим в ячейку Н3 функцию:
=СРЗНАЧ(А1:А25)-ДОВЕРИТ(I1;СТАНДОТКЛОН(А1:А25);25)
а в ячейку I3 функцию:
=СРЗНАЧ(А1:А25)+ДОВЕРИТ(I1;СТАНДОТКЛОН(А1:А25);25).
Как известно, α – доверительный интервал для дисперсии σ2 выглядит следующим образом:
|
|
|

Нам потребуется функция ХИ2ОБР (категория СТАТИСТИЧЕСКИЕ), которая вычисляет обратное значение xn−1,p односторонней вероятности распределения хи-квадрат P( χ2n−1>xn−1,p)=p.
В данном конкретном случае 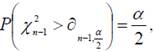
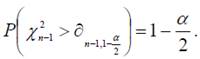
ХИ2ОБР имеет два параметра: первый «Вероятность» содержит доверительную вероятность соответственно α/2 и 1−α/2, второй – степень свободы n-1.
Вводим в соответствии с формулой для доверительного интервала σ2 в ячейку Н4 запись:
=ДИСП(A1:A25)*24/ХИ2ОБР(0,025;24),
а в ячейку I4 запись:
=ДИСП(A1:A25)*24/ХИ2ОБР(0,975;24).
Получаем значения границ доверительных интервалов для σ2.
Оборудование
Персональный компьютер с установленной операционной системой Windows XP/7/8, браузер (Например, Internet Explorer, Google Chrome, Opera), OOo Writer (MS Word), Ооо Calc (MS Excel) пакет офисных приложений «Мой офис».
Задание на работу
1. Станок производит детали, измерения которых приведено ниже. С доверительной вероятностью 0.95 построить доверительные интервалы для математического ожидания и дисперсии размера деталей.
Вариант 1
| 43.8 | 43.9 | 46.3 | 44.6 | 47.5 | 42.0 | 44.5 | 45.0 | 46.8 | 45.3 | 41.8 | 42.3 | 47.9 | 45.5 | 44.4 | 43.1 | 42.8 |
| 41.9 | 42.8 | 46.0 | 45.3 | 41.8 | 42.3 | 47.9 | 45.5 | 46.3 | 44.6 | 47.5 | 42.0 | 44.5 | 43.8 | 43.9 | 46.3 | 44.6 |
Вариант 2
|
|
|
| 49.0 | 48.8 | 49.2 | 50.2 | 49.5 | 49.8 | 49.9 | 49.3 | 49.6 | 49.5 | 49.7 | 49.0 | 48.8 | 51.8 | 49.1 | 48.3 | 50.0 |
| 49.0 | 48.4 | 48.5 | 49.6 | 49.5 | 49.7 | 49.0 | 48.8 | 51.8 | 49.5 | 49.8 | 49.9 | 49.3 | 49.6 | 48.8 | 49.2 | 50.2 |
Вариант 3
| 42.1 | 41.9 | 42.3 | 43.1 | 42.5 | 42.7 | 42.9 | 42.3 | 42.6 | 42.5 | 42.7 | 42.0 | 41.9 | 44.5 | 42.2 | 41.5 | 42.9 |
| 42.1 | 41.5 | 41.6 | 41.9 | 42.3 | 43.1 | 42.5 | 42.7 | 42.9 | 42.3 | 42.6 | 42.5 | 42.7 | 42.0 | 42.3 | 43.1 | 42.5 |
Вариант 4
| 25.6 | 25.5 | 25.5 | 24.7 | 25.0 | 25.8 | 25.2 | 25.0 | 25.0 | 25.3 | 25.4 | 25.1 | 25.2 | 25.3 | 24.8 | 25.1 | 24.6 |
| 25.2 | 25.8 | 24.8 | 25.5 | 24.7 | 25.0 | 25.8 | 25.2 | 25.0 | 25.0 | 25.3 | 25.4 | 25.1 | 25.2 | 25.0 | 25.0 | 25.3 |
Вариант 5
| 51.2 | 49.9 | 50.7 | 52.3 | 51.3 | 51.2 | 52.4 | 51.6 | 51.5 | 51.0 | 51.8 | 50.9 | 50.7 | 52.0 | 50.2 | 51.1 | 51.0 |
| 51.2 | 52.0 | 49.9 | 50.7 | 52.3 | 51.3 | 51.2 | 52.4 | 51.6 | 51.5 | 51.0 | 51.8 | 50.9 | 50.7 | 52.4 | 51.6 | 51.5 |
Вариант 6
| 21.8 | 21.6 | 21.7 | 20.8 | 20.8 | 20.8 | 21.2 | 20.7 | 19.8 | 22.2 | 21.9 | 21.5 | 20.9 | 20.9 | 20.9 | 21.6 | 21.2 |
| 22.2 | 20.6 | 21.7 | 20.8 | 20.8 | 20.8 | 21.2 | 20.7 | 19.8 | 22.2 | 21.9 | 21.5 | 20.9 | 20.9 | 20.9 | 21.8 | 21.6 |
Вариант 7
| 22.7 | 25.7 | 25.5 | 25.2 | 22.7 | 23.6 | 26.4 | 24.2 | 23.7 | 23.5 | 24.7 | 24.8 | 24.0 | 24.3 | 24.7 | 23.1 | 24.0 |
| 22.1 | 24.4 | 26.5 | 25.7 | 25.5 | 25.2 | 22.7 | 23.6 | 26.4 | 24.2 | 23.7 | 23.5 | 22.7 | 25.7 | 25.5 | 25.2 | 22.7 |
Вариант 8
| 49.5 | 49.5 | 46.7 | 47.2 | 49.1 | 48.7 | 51.2 | 46.1 | 50.5 | 48.9 | 49.3 | 50.4 | 47.2 | 48.5 | 49.4 | 48.8 | 50.1 |
| 46.5 | 51.2 | 46.2 | 46.1 | 50.5 | 49.5 | 48.7 | 51.2 | 47.2 | 49.1 | 49.5 | 46.7 | 47.2 | 49.1 | 48.7 | 47.2 | 49.1 |
Вариант 9
|
|
|
| 31.6 | 31.4 | 31 | 31.4 | 33.1 | 33.0 | 32.9 | 31.4 | 31.9 | 33.5 | 32.3 | 32.0 | 31.9 | 32.6 | 32.7 | 32.2 | 32.3 |
| 32.6 | 31.6 | 32.1 | 32.9 | 31.4 | 31.9 | 33.5 | 32.3 | 32.0 | 31.6 | 31.4 | 31 | 31.4 | 33.1 | 33.0 | 32.9 | 31.4 |
Вариант 10
| 36.2 | 35.9 | 36.1 | 34.5 | 34.5 | 34.6 | 35.2 | 34.3 | 32.8 | 36.9 | 36.4 | 35.8 | 34.6 | 34.7 | 34.8 | 35.9 | 35.3 |
| 37 | 34.3 | 36.0 | 36.2 | 35.9 | 36.1 | 34.5 | 34.5 | 34.6 | 35.2 | 34.3 | 32.8 | 36.9 | 36.4 | 34.5 | 34.6 | 35.2 |
Контрольные вопросы
1. Дать определение интервальной оценки, что позволяют установить интервальные оценки?
2. Дать определение доверительной вероятности, каковы наиболее часто задаваемые ее значения?
3. Дать определение доверительного интервала. Кто разработал метод доверительных интервалов?
Лабораторная работа №4
КОРРЕЛЯЦИОННО-РЕГРЕССИОННЫЙ АНАЛИЗ
Цель и задачи работы
Научиться аппроксимировать набор наблюдений линейной функцией.
Порядок выполнения работы
- ознакомится с теоретическими сведениями;
- выполнить задание;
- оформить отчет;
- ответить на контрольные вопросы, заданные преподавателем.
Оформление отчета
Отчет должен содержать: титульный лист, цель работы, описание пунктов выполнения лабораторной работы в соответствии с заданием, ответы на контрольные вопросы и выводы по работе.
Теоретические сведения
Цель регрессионного анализа состоит в определении общего вида уравнения регрессии, построении оценок неизвестных параметров, входящих в уравнение регрессии, и проверке статистических гипотез о регрессии. В зависимости от формы связи между переменными различают линейную и нелинейную регрессию. Наиболее простым является случай, когда регрессия линейна.
Рассмотрим задачу наилучшей аппроксимации набора наблюдений  линейной функцией f(X)=a+bX в смысле минимизации функционала
линейной функцией f(X)=a+bX в смысле минимизации функционала
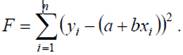
Запишем необходимые условия экстремума:
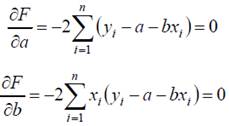
или
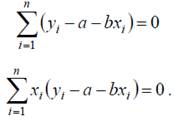
Раскрыв скобки, получим:
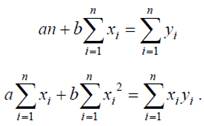
Решая систему уравнений, находим неизвестные a и b:
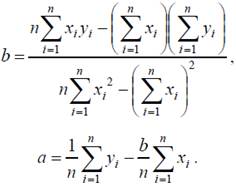
Добавим к постановке задачи некоторые статистические данные и запишем линейное регрессионное уравнение в виде:

где Xi – неслучайная (детерминированная) величина, Yi, εi – случайные величины, εi – ошибки регрессии.
Основные гипотезы:
1. 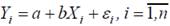 – спецификация модели.
– спецификация модели.
2. Xi – детерминированная величина; вектор (X1, X2, ..., Xn) не коллинеарен вектору (1,1,...,1).
3. M (ε i )=0, D (ε i )=σ2,  M (ε i ,ε j )=0, i ≠ j.
M (ε i ,ε j )=0, i ≠ j.
Часто добавляется условие:
4. εi – нормально распределенная случайная величина, M(εi) = 0, D(εi)=σ2.
Как утверждает теорема Гаусса-Маркова, в этих предположениях оценки неизвестных параметров модели
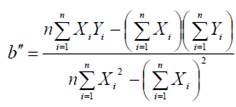
и
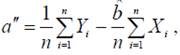
полученные по МНК, имеют наименьшую дисперсию в классе всех линейных несмещенных оценок.
Непосредственно из 1) - 4) следует, что Yi – нормально распределенная случайная величина, M(Yi)=a+bXi, D(Yi)=σ2.
Нетрудно проверить, что 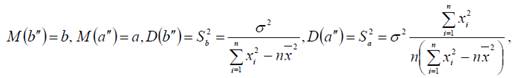
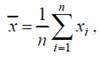
поэтому

Обозначим через 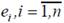 разницу между действительным значением переменной Y и модельным значением этой переменной, то есть
разницу между действительным значением переменной Y и модельным значением этой переменной, то есть

Несмещенной оценкой дисперсии ошибок σ2 является:
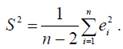
Нетрудно показать, что S2 независима с a′′ и b′′, 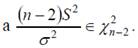
Построим статистику для проверки гипотезы H0: b=b0 против альтернативной гипотезы H1: b ≠ b0.
Поскольку 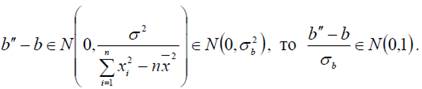 Из условия
Из условия  , следует что
, следует что 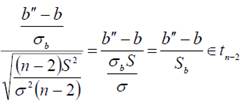 (распределению Стьюдента с n−2 степенями свободы).
(распределению Стьюдента с n−2 степенями свободы).
Таким образом, для проверки гипотезы H0: b=b0 против альтернативной гипотезы H1: b ≠ b0 будет использоваться статистика 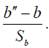
Построим доверительный интервал для b, используя распределение tn−2 и его двусторонние квантили tn−2,α, которые находятся из таблицы для вероятностей Ρ(|tn−2|≤ tn−2,α) =1−α, или Ρ(|tn−2|> tn−2,α)=α:
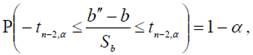
откуда следует 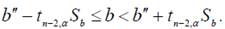
Если b0 принадлежит отрезку [b′′−tn−2,α Sb, b′′+ tn−2,α Sb], то принимается гипотеза H0 , в противном случае принимается гипотеза H1.
Если требуется проверить наличие связи между переменными X и Y, то используется статистика b′′/Sb, тем самым проверяется равенство нулю коэффициента b. Если в границы построенного при этом доверительного интервала попадает ноль, (то есть нижняя граница доверительного интервала отрицательна, а верхняя положительна), то коэффициент b принимается равным нулю и делается вывод об отсутствии связи между переменными X и Y. Другими словами, при  делается вывод о достоверной связи между переменными X и Y, при
делается вывод о достоверной связи между переменными X и Y, при 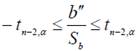 делается вывод об ее отсутствии.
делается вывод об ее отсутствии.
Можно показать, что
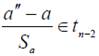
и использовать эту статистику для проверки аналогичных гипотез относительно коэффициента a.
Рассмотрим статистику 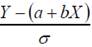 , которая принадлежит стандартному нормальному распределению – N(0,1). При известной σ2 (дисперсии ошибок) можно было бы использовать N(0,1) для прогнозирования значений Y в виде доверительных интервалов.
, которая принадлежит стандартному нормальному распределению – N(0,1). При известной σ2 (дисперсии ошибок) можно было бы использовать N(0,1) для прогнозирования значений Y в виде доверительных интервалов.
Поскольку σ2 неизвестно, то будем использовать ее оценку S2, для которой известно, что 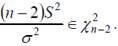
Таким образом,

и используется для построения доверительных интервалов с целью прогнозирования значений Y:

Количественным показателем качества построенной линейной модели является коэффициент детерминации
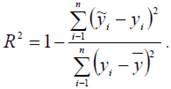
Коэффициент детерминации показывает, какая доля общей дисперсии Y объясняется уравнением регрессии:
0 ≤ R2 ≤1.
Чем ближе R2 к 1, тем лучше построенная регрессионная модель согласуется с исходными данными.
Для построения регрессии в Excel, создаем файл исходных входных и выходных данных и начинаем с построения корреляционного поля, позволяющего визуализировать наличие связи между этими данными.
Выбираем меню ВСТАВКА/ДИАГРАММА, тип диаграммы: ТОЧЕЧНАЯ вид: ТОЧЕЧНАЯ ДИАГРАММА. Нажимаем кнопку ДАЛЕЕ. В появившемся диалоговом окне указываем диапазон значений и расположение данных: В СТОЛБЦАХ. Нажимаем кнопку ДАЛЕЕ. В следующем диалоговом окне указываем название диаграммы, наименование осей. Нажимаем ДАЛЕЕ и ГОТОВО. Построенная таким образом диаграмма рассеяния представляет собой совокупность пар точек, абсциссами которых являются значения переменной X, а ординатами значения переменной Y.
В меню СЕРВИС выбираем АНАЛИЗ ДАННЫХ и РЕГРЕССИЯ. Указываем входной интервал Y (для примера А2: А26) и входной интервал X (для примера B2: B26), а также параметры вывода, остатки, нормальную вероятность как показано на рис. 1.
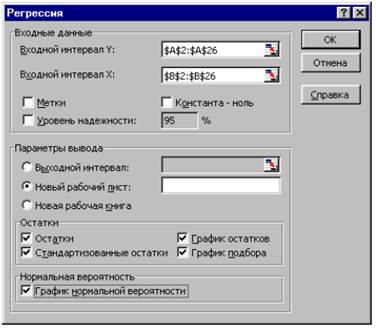
Рисунок 1 – Диалоговое окно Регрессия
В диалоговом окне задаются следующие параметры:
Входной интервал Y – диапазон ячеек, содержащий данные результативного признака;
Входной интервал Х – диапазон ячеек, содержащий данные факторного признака;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа-ноль – данный флажок необходимо установить, чтобы линия регрессии прошла через начало координат;
Уровень надежности – этот флажок необходимо использовать, если требуется уровень надежности отличный от 95%, принятый по умолчанию;
Выходной интервал – верхняя левая ячейка интервала, в который будут помещаться результаты вычислений.
Excel автоматически сгенерирует результаты по регрессионной статистике. Ниже в качестве примеров приведены возможные результаты и их расшифровки.
Регрессионная статистика
Множественный R 0,969525973
R‐квадрат 0,939980612
Нормированный R‐квадрат 0,935363736
Стандартная ошибка 14,22893673
Наблюдения 15.
Полученное значение коэффициента детерминации говорит об очень хорошей согласованности построенной регрессионной модели и исходных данных (соответственно об очень хорошей связи исследуемых факторов X и Y).
Результаты дисперсионного анализа будут представлены в виде:
| Дисперсионный анализ | |||||
| df | SS | MS | F | Значимость | |
| Регрессия | 1 | 41220,72106 | 41220,72106 | 203,5966782 | 2,55346E‐09 |
| Остаток | 13 | 2632,014326 | 202,4626405 | ||
| Итого | 14 | 43852,73538 | |||
| Коэффи- циенты | Стандартная ошибка | t- статис- тика | P- Значение | Нижние 95% | Верхние 95% | |
| Y – пересечение | 4,746 | 7,003 | 0,678 | 0,510 | ‐10,384 | 19,876 |
| Переменная X 1 | 9,595 | 0,672 | 14,269 | 0,000 | 8,142 | 11,048 |
df ⁺! степени свободы (degree of freedom);
SS ⁺! сумма квадратов отклонений (Sum of squares);
MS ⁺! средний квадрат отклонения (Mean square);
F ⁺! отношение дисперсий (факторной к остаточной).

Значимость F – критическое значение квантиля распределения Фишера, которое используется для проверки нулевой гипотезы, состоящей в том, что факторная и остаточная дисперсии равны. По сути дела, нулевая гипотеза означает, что на результативный признак Y в равной степени влияют и независимая (факторная) переменная X и необъясненные факторы. В таком случае уравнение регрессии не значимо. Чтобы уравнение регрессии было значимым необходимо, чтобы факторная дисперсия превышала остаточную дисперсию в несколько раз.
В примере, приведенном выше, F больше, чем Значимость F (критическое значение), значит регрессионная модель адекватна.
Регрессионная сумма SS=41220,72106 (объясненная регрессией) намного больше остаточной SS=2632,014326 (не объясненной регрессией, вызванной случайными факторами), что тоже говорит о хорошей регрессии.
Коэффициенты – значения коэффициентов;
Стандартная ошибка – стандартная ошибка коэффициентов;
t-статистика – значение статистики критерия;
Р-значение – уровень значимости отклонения гипотезы равенства коэффициента нулю (вероятность принять равенство коэффициента нулю);
Нижние 95% – нижняя граница доверительного интервала, в котором находится значение коэффициента;
Верхние 95% – верхняя граница доверительного интервала, в котором находится значение коэффициента.
Приведенные в качестве примера результаты позволяют проверить значимость коэффициентов регрессии: свободного члена и коэффициента при переменной X. Значение коэффициента при X 9,595 больше, чем его стандартная ошибка. К тому же этот коэффициент является значимым, о чем можно судить по значениям показателя Р-значение в таблице, которые меньше заданного уровня значимости α=0,05. Для свободного члена ситуация диаметрально противоположная. В построенный для него доверительный интервал попадает ноль, что говорит о том, что он незначим и может быть принят равным нулю.
Есть возможность вывести таблицу стандартных и простых остатков, где для каждого значения ряда выводится предсказанное значение, с которым сопоставляется остаток, представляющий разность между прогнозным и реальным значением.
Простым и наглядным способом проверки удовлетворительности регрессионной модели является графическое представление отклонений, которое Excel представляет в виде графика остатков. Если регрессионная модель близка к реальной зависимости, то отклонения будут носить случайный характер и их сумма будет близка к нулю. Если необходимо получить дополнительную информацию и графики остатков, установите соответствующие флажки в диалоговом окне.
Оборудование
Персональный компьютер с установленной операционной системой Windows XP/7/8, браузер (Например, Internet Explorer, Google Chrome, Opera), OOo Writer (MS Word), Ооо Calc (MS Excel) пакет офисных приложений «Мой офис».
Задание на работу
Построить уравнение регрессии Y=a+bx.
| Вариант 1 | Вариант 2 | Вариант 3 | ||||||
| № | X | Y | № | X | Y | № | X | Y |
| 1 | -1.132 | 1.554 | 1 | -0.132 | 1.791 | 1 | -0.332 | -1.65 |
| 2 | -0.204 | 4.601 | 2 | 0.796 | 1.51 | 2 | 0.596 | 2.31 |
| 3 | 0.858 | 2.943 | 3 | 1.858 | 4.17 | 3 | 1.658 | 4.953 |
| 4 | 1.715 | -1.157 | 4 | 2.715 | 3.007 | 4 | 2.515 | 8.62 |
| 5 | 2.494 | -6.048 | 5 | 3.494 | 5.875 | 5 | 3.294 | 7.49 |
| 6 | 4.013 | -1.194 | 6 | 5.013 | 7.187 | 6 | 4.813 | 6.09 |
| 7 | 4.964 | 11.465 | 7 | 5.964 | 9.005 | 7 | 5.764 | 11.958 |
| 8 | 6.167 | -6.257 | 8 | 7.167 | 14.865 | 8 | 6.967 | 14.975 |
| 9 | 7.658 | -11.07 | 9 | 8.658 | 12.008 | 9 | 8.458 | 18.518 |
| 10 | 8.243 | 10.243 | 10 | 9.243 | 11.718 | 10 | 9.043 | 21.794 |
| 11 | 9.296 | 10.995 | 11 | 10.296 | 16.744 | 11 | 10.096 | 17.245 |
| 12 | 10.259 | -11.17 | 12 | 11.259 | 18.789 | 12 | 11.059 | 20.881 |
| 13 | 11.275 | -10.84 | 13 | 12.275 | 12.863 | 13 | 12.075 | 18.787 |
| 14 | 12.202 | -9.78 | 14 | 13.202 | 20.862 | 14 | 13.002 | 16.334 |
| 15 | 12.687 | 15.066 | 15 | 13.687 | 15.309 | 15 | 13.487 | 28.613 |
| Вариант 4 | Вариант 5 | Вариант 6 | ||||||
| № | X | Y | № | Х | Y | № | X | Y |
| 1 | -3.132 | 0.412 | 1 | 1.868 | 12.669 | 1 | -4.132 | -4.539 |
| 2 | -2.204 | 2.204 | 2 | 2.796 | -9.23 | 2 | -3.204 | -3.306 |
| 3 | -1.142 | -1.282 | 3 | 3.858 | 0.753 | 3 | -2.142 | -2.018 |
| 4 | -0.285 | -2.529 | 4 | 4.715 | -2.106 | 4 | -1.285 | -1.223 |
| 5 | 0.494 | -2.995 | 5 | 5.494 | -4.044 | 5 | -0.506 | -0.739 |
| 6 | 2.013 | -0.325 | 6 | 7.013 | 1.903 | 6 | 1.013 | -0.823 |
| 7 | 2.964 | -5.018 | 7 | 7.964 | 5.065 | 7 | 1.964 | -1.873 |
| 8 | 4.167 | -6.295 | 8 | 9.167 | 3.807 | 8 | 3.167 | 1.055 |
| 9 | 5.658 | -3.773 | 9 | 10.658 | 3.374 | 9 | 4.658 | 0.989 |
| 10 | 6.243 | -6.772 | 10 | 11.243 | 0.563 | 10 | 5.243 | 0.116 |
| 11 | 7.296 | -5.079 | 11 | 12.296 | 2.511 | 11 | 6.296 | 6.213 |
| 12 | 8.259 | -5.519 | 12 | 13.259 | 1.934 | 12 | 7.259 | 0.856 |
| 13 | 9.275 | -6.505 | 13 | 14.275 | 4.609 | 13 | 8.275 | 0.743 |
| 14 | 10.202 | -7.864 | 14 | 15.202 | 9.673 | 14 | 9.202 | 5.137 |
| 15 | 10.687 | -8.578 | 15 | 15.687 | 6.565 | 15 | 9.687 | 2.209 |
| Вариант 7 | Вариант 8 | Вариант 9 | ||||||
| № | X | Y | № | X | Y | № | X | Y |
| 1 | 1.868 | 4.322 | 1 | -1.118 | 7.252 | 1 | 1.132 | 2.573 |
| 2 | 2.796 | 11.126 | 2 | -1.062 | 10.683 | 2 | 3.204 | 14.963 |
| 3 | 3.858 | 4.536 | 3 | 0.054 | 4.075 | 3 | 5.142 | 4.317 |
| 4 | 4.715 | 11.52 | 4 | 2.359 | 5.463 | 4 | 7.285 | 17.39 |
| 5 | 5.494 | 15.855 | 5 | 3.561 | 11.377 | 5 | 9.506 | 26.456 |
| 6 | 7.013 | 19.365 | 6 | 3.56 | 13.401 | 6 | 10.987 | 30.205 |
| 7 | 7.964 | 20.027 | 7 | 6.348 | 12.638 | 7 | 13.036 | 32.238 |
| 8 | 9.167 | 15.986 | 8 | 6.617 | 18.804 | 8 | 14.833 | 25.086 |
| 9 | 10.658 | 23.784 | 9 | 8.108 | 8.975 | 9 | 16.342 | 36.133 |
| 10 | 11.243 | 22.948 | 10 | 8.538 | 26.612 | 10 | 18.757 | 37.62 |
| 11 | 12.296 | 18.02 | 11 | 8.312 | 23.302 | 11 | 20.704 | 29.791 |
| 12 | 13.259 | 31.75 | 12 | 10.895 | 21.718 | 12 | 22.741 | 53.538 |
| 13 | 14.275 | 29.538 | 13 | 10.381 | 20.979 | 13 | 24.725 | 50.432 |
| 14 | 15.202 | 24.758 | 14 | 12.18 | 17.243 | 14 | 26.798 | 43.52 |
| 15 | 15.687 | 27.018 | 15 | 12.973 | 19.821 | 15 | 29.313 | 50.701 |
| Вариант 10 | ||
| № | X | Y |
| 1 | -1.121 | -4.575 |
| 2 | 0.391 | 3.839 |
| 3 | 0.587 | 1.864 |
| 4 | 2.114 | 2.832 |
| 5 | 3.131 | 17.286 |
| 6 | 4.528 | 7.376 |
| 7 | 4.806 | 6.239 |
| 8 | 6.165 | 17.959 |
| 9 | 7.464 | 13.944 |
| 10 | 7.454 | 17.99 |
| 11 | 9.392 | 27.978 |
| 12 | 9.685 | 22.938 |
| 13 | 11.138 | 25.206 |
| 14 | 11.684 | 26.74 |
| 15 | 12.627 | 36.957 |
Контрольные вопросы
1. Какова цель регрессионного анализа?
2. Какова формула для вычисления коэффициента детерминации.
3. Каким способом производится проверка удовлетворительности регрессионной модели?
Лабораторная работа №5
Дата добавления: 2021-07-19; просмотров: 95; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!