Проверка соответствия полученных данных нормальному закону распределения
Типы данных.
Математическая статистика. Установление закономерностей, которым подчинены массовые случайные явления, основано на изучении статистических данных – результатах наблюдений. Первая задача математической статистики – указать способы сбора и группировки статистических сведений. Вторая задача математической статистики – разработать методы анализа статистических данных, в зависимости от целей исследования. Т.е. задача математической статистики состоит в создании методов сбора и обработки статистических данных для получения научных и практических выводов.
Типы статистических данных.
Статистические данные представляют собой наблюдаемые или измеряемые значение одного или нескольких признаков обследуемой совокупности объектов.
Различают качественные и количественные признаки. Количественные признаки могут быть непрерывными (вес, рост, цена) или дискретными (кол - во детей, количество лейкоцитов в поле зрения). Часто непрерывные количественные данные рассматривают в виде интервальных оценок: возраст в полных годах, рост с точностью до 1 см, вес с точностью до 1 кг. Таким образом, осуществляется переход от непрерывной шкалы к дискретной. С другой стороны, «количество эритроцитов в 1 мл крови» - дискретный параметр (т.к. клетка не делима), но его значение исчисляется в млн и может рассматриваться как непрерывный. В подобных случаях говорят о квазидискретных и квазинепрерывных параметрах.
Качественные признаки: пол, семейное положение, цвет глаз, диагноз и т.д.. Качественные признаки: номинальные (номинативные, классификационные) и порядковые (ординальные). Говорят, что соответственные признаки измеряют в номинальной или порядковой шкале.
Признак измеряемый в номинальной шкале принимает одно значение из конечного числа установленных градаций: пол (м/ж), цвет кожных покровов, диагноз основного заболевания по коду МКБ и прочие. Особое внимание следует уделить номинативным признакам с 2 вариантами значения: пол мужской/женский, состояния здоров/болен, маркер выявлен/не выявлен. Такие признаки называют бинарными.
Значения качественных признаков, измеряющихся в порядковой (ординальной) шкале, могу быть упорядочены. Примеры: баллы тяжести состояния новорожденных по шкале Апгар, оценки комы по шкале Глазго, оценка сознания пациента (ясное, спутанное, глушение, сопор/ступор, кома 1, кома 2, кома 3) качество условий жизни (очень хорошее, хорошее, удовлетворительное, плохое). Для представления таких признаков используется ранг, т.е. число, которое сопоставляет номеру признака в ряду.
В ряде случаев удобно использовать вместо количественных признаков качественные: например вместо количественного параметра ИМТ, качественный, характеризующий нормальность массы тела: дефицит веса, нормальный вес, избыточный вес, ожирение 1 степени, ожирение 2 степени, ожирение 3 степени., или вместо содержания гемоглобина в крови – выраженность анемии.
| Ранг (п.п.) | Качественный параметр «Ожирение» | Количественный параметр ИМТ кг/м2 |
| 1 | Дефицит массы | <18.5 |
| 2 | Норма | 18.5-25 |
| 3 | Избыточная масса тела | 25-30 |
| 4 | Ожирение 1 ст. | 30-35 |
| 5 | Ожирение 2 ст. | 35-40 |
| 6 | Ожирение 3 ст. | >40 |
| Ранг (п.п.) | Качественный параметр «Анемия» | Количественный параметр «гемоглобин». г/л |
| 1 | Выше нормы | >160 (муж) >140(жен) |
| 2 | анемия отсутствует (норма) | 130-160 (муж) 120-140(жен) |
| 3 | Лёгкая | 90-130 (муж) 90-120 (жен) |
| 4 | Средняя | 70-90 |
| 5 | Тяжёлая | <70 |
Для обработки данных, представленных в ординальной и номинальных шкалах, разработаны специальные методы, например, ранговая корреляция, можно проводить проверку гипотез о виде распределений, дисперсионный анализ и пр. Представление данных в виде гистограмм, полигонов и эмпирических функций распределения дает информацию о распределении генеральной совокупности. Но часто требуется охарактеризовать генеральную совокупность по количественным показателям, которые определяют положение центра распределения, рассеяние (разброс) данных, ассиметрию. Это дает возможность сравнить одну совокупность данных с другой.
Статистическая обработка медицинских данных средствами пакета прикладных программ Statistica
Описание данных
Проверка соответствия полученных данных нормальному закону распределения
Прежде чем приступить к оценке статистической значимости различий между исследуемыми группами, необходимо определить, по какому закону распределены исходные данные. В клинической практике часто достаточно определить соответствие данных нормальному закону. В случае, когда значения наблюдаемых показателей распределены нормально, для дальнейшего анализа используется так называемая параметрическая статистика (критерии Стьюдента, корреляции Пирсона), в противном случае – непараметрическая (критерии Манна-Уитни, Вилкоксона, корреляции Спирмена).
Проверить соответствие полученных данных нормальному закону распределения можно двумя способами – «глазомерным» и критерием Колмогорова-Смирнова.
Для того, чтобы рассчитать критерии Колмогорова-Смирнова и заодно оценить визуально распределение исходных данных, необходимо воспользоваться модулем описательной статистики пакета Statistica. Для этого выполните последовательность команд Statistics à Basic Statistics/Tables à Descriptive Statistics à Normality. Выберите переменную (в нашем случае Var 1), изменение значений которой Вы хотите оценить, нажав на кнопку Variables. Затем нажмите на кнопку Histograms (рис.9)
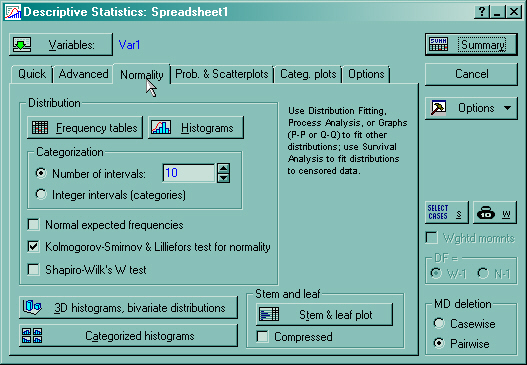
Рис. 9. Проверка соответствия распределения исходных данных нормальному закону.
Выполнение указанной последовательности действий приведет к появлению гистограммы (рис. 10). На гистограмме помимо столбцов показана кривая плотности нормального распределения, а также критерий Колмогорова-Смирнова. Статистика Колмогорова-Смирнова (K - S d) оказалась равной 0,08912, а вероятность ошибки принятия гипотезы о наличии различий – p>0,20.
Отклонение от нормального распределения считается существенным при значении р < 0,05.
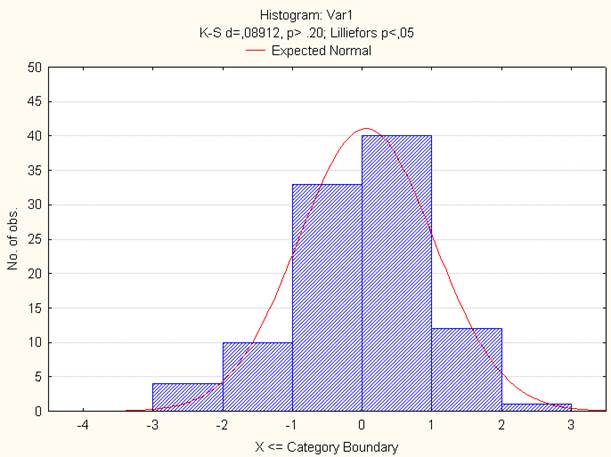
Рис. 10. Соответствие исходных данных нормальному закону распределения.
О нормальности распределения можно судить по графику на нормальной вероятностной бумаге. График можно построить при помощи опции Normal probability plots окна Prob . & Scatterplots модуля Descriptive Statistics (Описательные статистики) (рис. 11). Чем ближе распределение к нормальному закону, тем лучше значения ложатся на прямую линию.
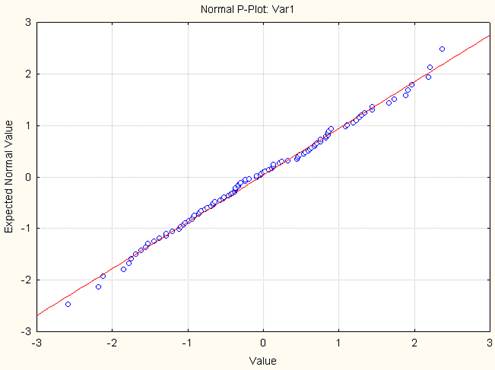
Рис. 11. «Глазомерный» метод оценки нормальности распределения.
Дата добавления: 2021-01-21; просмотров: 67; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!