Построение уравнения регрессии
Лекция 7. КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
Каждой величине, которую получают в результате проведения эксперимента, присущий элемент случайности, оказывается большей или меньшей степени в зависимости от ее природы.
При совместном появлению двух и более величин в результате проведения эксперимента исследователь имеет основания для установления определенной зависимости между ними, связи. Идея связи между переменными величинами имеет особое, принципиальное значение в исследованиях, где осуществляется проверка на адекватность созданных математических моделей реальным процессам, в которых соотношение между переменными связаны функциональной зависимостью.
Строгой функциональной зависимости между переменными, в буквальном смысле этого слова, в реальном мире не существует, потому что они находятся под влиянием случайных факторов, последствия которого предвидеть практически невозможно. Поэтому между переменными существует особая форма связи, которую называют стохастической и которая в математической статистике трансформируется, не меняя своей сущности, в статистическую зависимость.
Показателем, который измеряет стохастический связь между переменными, является коэффициент корреляции, который свидетельствует с определенной степенью вероятности, насколько связь между переменными близок к строгой линейной зависимости.
Значительно увеличивается ценность коэффициента корреляции для случайных переменных, имеющих закон распределения вероятностей, близкий к нормальному. Для таких величин отсутствие корреляции одновременно означает и отсутствие какой-либо зависимости между ними. Кроме этого, как и в дисперсионном анализе, корреляционный анализ оценивает, насколько значительные случайно переменные в случайных величинах в процессе проведения эксперимента.
|
|
|
При наличии корреляционной связи между переменными необходимо выявить его форму функциональной зависимости (линейная или нелинейная), а именно
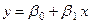 (1)
(1)
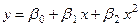 (2)
(2)
 (3)
(3)
Приведенные зависимости между переменными 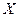 и
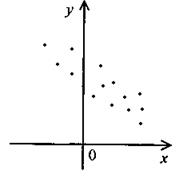
и 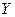 (1) – (3) называют функциями регрессии. Форму связи между переменными и можно установить, применяя корреляционные поля, которые изображены на рисунках 1 – 3.
(1) – (3) называют функциями регрессии. Форму связи между переменными и можно установить, применяя корреляционные поля, которые изображены на рисунках 1 – 3.

| 
| 
|
| Рис. 1. | Рис. 2. | Рис. 3. |
|
|
|
Итак, на основе размещения точек корреляционного поля исследователь имеет основания для гипотетического предположения о линейные или нелинейные зависимости между признаками и .
Для двумерного статистического распределения выборки признаков  понятие статистической зависимости между признаками та имеет следующее определение:
понятие статистической зависимости между признаками та имеет следующее определение:
Статистической зависимостью от называют такую, при которой при изменении значений признака 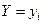 , изменяется условное статистическое распределение признака .
, изменяется условное статистическое распределение признака .
Статистической зависимостью признака от называют такую, при которой при изменении значений признака 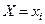 , изменяется условное статистическое распределение признака .
, изменяется условное статистическое распределение признака .
В случае изменения условных статистических распределений меняться и условные числовые характеристики. Отсюда следует определение корреляционной зависимости между признаками и .
Корреляционной зависимостью признака от называется функциональная зависимость условного среднего 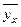 от аргумента
от аргумента 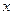 , которую можно записать так:
, которую можно записать так: 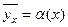 .
.
Аналогично,
Корреляционной зависимостью признака от называется функциональная зависимость условного среднего 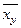 от аргумента
от аргумента 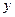 , которую можно записать так:
, которую можно записать так: 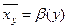 .
.
|
|
|
Между признаками и может существовать статистическая зависимость и при отсутствии корреляционной. Но когда существует корреляционная зависимость между признаками, то обязательно между ними будет существовать и статистическая зависимость.
Понятие парной регрессии.
Регрессией в теории вероятностей и математической статистике принято называть зависимость среднего значения какой-либо величины (y) от некоторой другой величины или от нескольких величин 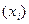 .
.
Парной регрессией называется модель, выражающая зависимость среднего значения зависимой переменной y от одной независимой переменной х
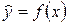 (2.1)
(2.1)
где у – зависимая переменная (результативный признак); х – независимая, объясняющая переменная (признак–фактор).
Парная регрессия применяется, если имеется доминирующий фактор, обуславливающий большую долю изменения изучаемой объясняемой переменной, который и используется в качестве объясняющей переменной.
Множественной регрессией называют модель, выражающую зависимость
среднего значения зависимой переменной y от нескольких независимых переменных 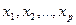 .
.
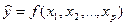 . (2.2)
. (2.2)
|
|
|
Множественная регрессия применяется в ситуациях, когда из множества факторов, влияющих на результативный признак, нельзя выделить один доминирующий фактор и необходимо учитывать одновременное влияние нескольких факторов.
Используя уравнение регрессии (2.1), соотношение между значениями переменными у и х (модель связи) можно записать как
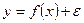 (2.3)
(2.3)
где первое слагаемое 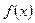 можно интерпретировать как ту часть значения y, которая объяснена уравнением регрессии (2.1), а второе слагаемое
можно интерпретировать как ту часть значения y, которая объяснена уравнением регрессии (2.1), а второе слагаемое 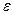 как необъясненную часть значения y (или возмущение). Соотношение между этими частями характеризует качество уравнения регрессии, его способность представлять зависимость между переменными х и y. При построении уравнения регрессии рассматривается как ошибка модели, представляющая собой случайную величину, удовлетворяющую определенным предположениям.
как необъясненную часть значения y (или возмущение). Соотношение между этими частями характеризует качество уравнения регрессии, его способность представлять зависимость между переменными х и y. При построении уравнения регрессии рассматривается как ошибка модели, представляющая собой случайную величину, удовлетворяющую определенным предположениям.
Наличие составляющей обусловлено такими причинами, как наличие дополнительных факторов, оказывающих влияние на переменную y, неверный
вид функциональной зависимости , ошибки измерения, выборочный характер исходных данных.
По виду аналитической зависимости различают линейные и нелинейные
регрессии.
Линейная парная регрессия описывается уравнением:
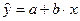 (2.4)
(2.4)
Примеры наиболее часто используемых нелинейных регрессий:
– полиномы разных степеней 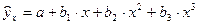 ,
,
– равносторонняя гипербола 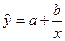 ,
,
– степенная 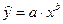 ,
,
– экспоненциальная 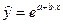 ,
,
– показательная  ,
,
– логистическая  .
.
Построение уравнения регрессии
Постановка задачи
Постановка задачи: по имеющимся данным n наблюдений за совместным изменением двух переменных показателей x и y 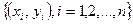 необходимо определить аналитическую зависимость
необходимо определить аналитическую зависимость 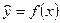 , наилучшим образом описывающую данные наблюдений.
, наилучшим образом описывающую данные наблюдений.
Результаты наблюдений удобно представлять в виде таблицы
Таблица 2.1
Данные наблюдений
| x | y | |
| 1 | 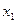
| 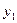
|
| 2 | 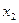
| 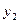
|
| … | … | … |
| n | 
| 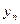
|
Каждая строка таблицы представляет собой результат одного наблюдения  .
.
Поясним понятие зависимости наилучшим образом описывающей данные наблюдений. Значения 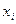 ,
,  из каждой строки можно рассматривать как координаты точки на координатной плоскости xy. Совокупность всех точек составляют, так называемое, поле корреляций (рис. 2.1).
из каждой строки можно рассматривать как координаты точки на координатной плоскости xy. Совокупность всех точек составляют, так называемое, поле корреляций (рис. 2.1).
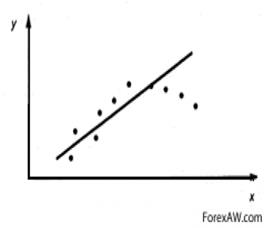
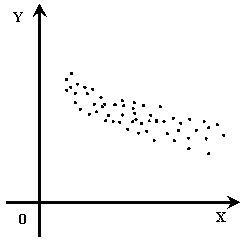
Рис. 2.1. Поле корреляций Рис. 2.2. Лучшая линейная регрессия
Зависимости соответствует некоторая кривая на плоскости. Чем ближе данная кривая подходит ко всем точкам поля корреляций, тем лучше зависимость описывает исходные данные.
Для формализации этого понятия рассмотрим разность между 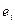 расчетными (теоретическими, модельными)
расчетными (теоретическими, модельными) 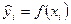 и наблюдаемыми значениями
и наблюдаемыми значениями 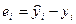 .
.
Наилучшей будем считать такую зависимость, для которой сумма квадратов отклонений принимает минимальное значение, т. е.
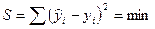 . (2.5)
. (2.5)
Построение уравнения регрессии предполагает решение двух задач (или, другими словами, осуществляется в два этапа):
1) спецификация модели (выбор вида аналитической зависимости );
2) оценка параметров выбранной модели (определение численных значений параметров на основе массива наблюдений).
Спецификация модели
Парная регрессия применяется для моделирования зависимости, если имеется доминирующий фактор, который и используется в качестве объясняющей переменной.
Для выбора вида аналитической зависимости можно использовать следующие методы:
– графический (вид зависимости определяется на основе анализа поля корреляций);
– аналитический (на основе качественного анализа изучаемой взаимосвязи);
– экспериментальный (построение нескольких моделей различного вида с выбором наилучшей согласно применяемому критерию качества).
Визуальный анализ поля корреляций (рис. 2.1) позволяет определить форму кривой регрессии, ее особенности. Зная типичный вид графиков различных функций можно подобрать соответствующую аналитическую зависимость.
Примером применения аналитического метода может служить зависимость между затратами (y) и объемом производства (x). Считая, что затраты прямо пропорциональны объему производства, зависимость между ними можно представить в виде линейной функции
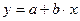 ,
,
где a– часть затрат, не зависящая от объема производства, b – дополнительные затраты на производство единицы продукции.
Разделив обе части последнего уравнения на объем производства x, получим зависимость удельных затрат (z = y/x) на производство единицы продукции от объема производства
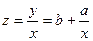
При построении модели зависимости спроса товар от его цены при выборе вида зависимости следует учитывать, что при увеличении цены спрос падает. В этом случае могут использоваться следующие зависимости:
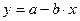 ,
, 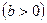 ;
;
 , ;
, ;
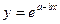 , .
, .
Если из соображений экономической теории следует, что величина изменения зависимой переменной y пропорциональна значению независимой переменной x, то можно выбрать полиномиальную, степенную или показательную зависимости (см. п. 2.1).
Если предполагается, что значение зависимой переменной y при увеличении значения независимой переменной x не может превысить некоторого предела, то можно выбрать гиперболическую или логистическую зависимости.
В случае, если в рассматриваемой области изменения фактора x результативная переменная y принимает минимальное или максимальное значение, в уравнение регрессии включают переменные x не только первой, но и второй степени, например
 .
.
В качестве критерия качества модели может использоваться либо средняя квадратическая ошибка модели 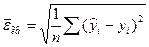 , либо остаточная дисперсия
, либо остаточная дисперсия  .
.
Этот подход легко реализуем при наличии соответствующих вычислительных средств. Но он не является определяющим, так как в эконометрике более важным является не способность модели соответствовать имеющемуся массиву данных наблюдений, а ее способность раскрывать существующие закономерности в экономических явлениях и процессах и интерпретация полученных с ее помощью результатов.
Дата добавления: 2020-11-27; просмотров: 75; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!