Алгоритмы декодирования сверточных кодов
Здесь мы опишем лишь один алгоритм декодирования сверточного кода, который широко применяется в современных системах связи с подвижными объектами. Этот алгоритм существенно опирается на понятие решетчатой диаграммы сверточного кода, которая была в предыдущем разделе использована для кодирования сверточным кодом (7, 5). Алгоритм декодирования здесь изложим также на примере этого кода.
Цель декодирования – выделение информационных символов из последовательности символов 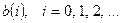 , поступающих на вход декодера с выхода демодулятора. Будем предполагать, что демодулятор формирует оценки кодовых символов, которые принимают значения из алфавита
, поступающих на вход декодера с выхода демодулятора. Будем предполагать, что демодулятор формирует оценки кодовых символов, которые принимают значения из алфавита 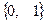 . Из-за наличия помех в канале передачи эти оценки могут отличаться от переданных кодовых символов
. Из-за наличия помех в канале передачи эти оценки могут отличаться от переданных кодовых символов 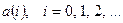 , т.е. содержать 1 вместо 0 и наоборот. Если число ошибок в принятой последовательности невелико (в среднем 2 ошибки в каждой сотне переданных кодовых символов), то есть надежда, что при декодировании эти ошибки будут исправлены.
, т.е. содержать 1 вместо 0 и наоборот. Если число ошибок в принятой последовательности невелико (в среднем 2 ошибки в каждой сотне переданных кодовых символов), то есть надежда, что при декодировании эти ошибки будут исправлены.
Рассмотрим сначала конечную последовательность принятых символов 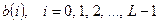 . Сущность рассматриваемого здесь способа декодирования состоит в том, чтобы на решетчатой диаграмме, содержащей
. Сущность рассматриваемого здесь способа декодирования состоит в том, чтобы на решетчатой диаграмме, содержащей 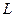 тактов, найти путь, определяющий кодовую последовательность
тактов, найти путь, определяющий кодовую последовательность 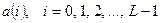 , на выходе кодера, наиболее близкую к данной принятой последовательности. Для этого сначала вводят понятие расстояния между двумя произвольными последовательностями, элементы которых могут принимать значения 0 или 1. Обычно в качестве такой меры принимают расстояние Хэмминга
, на выходе кодера, наиболее близкую к данной принятой последовательности. Для этого сначала вводят понятие расстояния между двумя произвольными последовательностями, элементы которых могут принимать значения 0 или 1. Обычно в качестве такой меры принимают расстояние Хэмминга 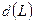 – число несовпадающих символов в этих последовательностях. Например, если последовательность на выходе кодера имеет вид 11 10 11 11 01, а последовательность на выходе демодулятора 10 10 11 10 01, то расстояние Хэмминга между ними равно
– число несовпадающих символов в этих последовательностях. Например, если последовательность на выходе кодера имеет вид 11 10 11 11 01, а последовательность на выходе демодулятора 10 10 11 10 01, то расстояние Хэмминга между ними равно 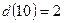 . Если рассматриваемые последовательности имеют длину , то число разных путей в решетке, содержащей тактов, равно
. Если рассматриваемые последовательности имеют длину , то число разных путей в решетке, содержащей тактов, равно 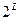 и при больших значениях оказывается достаточно большим. В результате поиск соответствующего пути оказывается задачей с довольно высокой вычислительной сложностью. Поэтому был предложен последовательный алгоритм поиска такого пути, который при некоторых дополнительных условиях с большой вероятностью позволяет найти требуемый путь в результате выполнения последовательности вычислений значительно меньшей сложности. Этот алгоритм декодирования был предложен в 1967 г. ученым США А. Витерби. Изложим этот алгоритм для рассматриваемого здесь сверточного кода (7, 5).
и при больших значениях оказывается достаточно большим. В результате поиск соответствующего пути оказывается задачей с довольно высокой вычислительной сложностью. Поэтому был предложен последовательный алгоритм поиска такого пути, который при некоторых дополнительных условиях с большой вероятностью позволяет найти требуемый путь в результате выполнения последовательности вычислений значительно меньшей сложности. Этот алгоритм декодирования был предложен в 1967 г. ученым США А. Витерби. Изложим этот алгоритм для рассматриваемого здесь сверточного кода (7, 5).
|
|
|
Прежде всего обратим внимание на то, что начиная с 3-го такта в каждый узел решетки на рис. 4, изображающий состояние кодера, входят два пути. Начиная с этого такта структура решетки периодически повторяется, так что соответствующие пути совпадают. Поэтому при декодировании на третьем такте декодер вполне может принять решение для каждого узла - из двух входящих в него путей выбрать один, отбросив второй; это можно сделать для каждого узла на третьем такте; после того как это сделано, аналогичная процедура может быть повторена для следующего такта и т.д. Именно таким образом должны реализовываться вычисления в соответствии с алгоритмом Витерби. В соответствии с этим алгоритмом на каждом такте сравниваются два пути, входящие в каждый узел, и сохраняется для следующего такта лишь один из них, метрика которого оказывается лучше. Другой путь исключается из последующего рассмотрения, поскольку при любых принятых в последствии данных его метрика не может оказаться лучшей. Оставшиеся пути называют выжившими. Для рассматриваемого кода после каждого такта декодирования будет оставаться по 4 выживших пути.
|
|
|
В качестве примера приведем здесь вычисления при декодировании с помощью алгоритма Витерби для случая, когда на выходе кодера сформирована последовательность, все кодовые символы которой нули, т.е. 00 00 00 00 00 …, а на выходе демодулятора получена принятая кодовая последовательность 10 00 10 00 00 …, содержащая две ошибки.
|
|
|
На рис. 5а изображены пути решетки для двух тактов. Около каждого узла второго такта указаны числа (метрики) – расстояния Хэмминга между возможными кодовыми последовательностями на выходе кодера, представляемыми этими путями, и первыми символами 10 00 принятой последовательности. На рис. 5б изображены все возможные пути (т.е. все возможные последовательности на выходе кодера) для трех тактов; однако теперь символы на выходе кодера здесь не указаны; в каждый узел на третьем такте входят два пути, на которых указаны их метрики. В соответствии с алгоритмом Витерби для каждого узла из двух входящих путей теперь необходимо выбрать путь с меньшей метрикой, оставив его для дальнейших вычислений; пути с большими значениями метрик отбрасываются. На рис. 5в изображены выжившие пути после третьего такта, а около каждого узла указано значение метрики, накопленное этим путем после соответствующего такта.
Отметим, что после третьего такта число выживших путей равно четырем. Указанные здесь вычисления повторяются для каждого следующего принимаемого ребра. На рис. 5г изображены выжившие пути после пятого такта. Заметим, что на пятом такте метрика нулевого пути имеет лучшее значение, чем метрики любого другого пути.
|
|
|
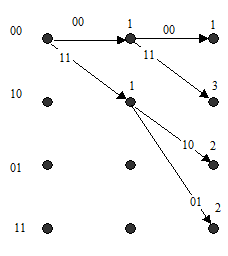
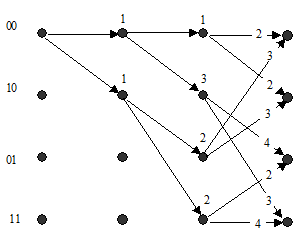
А) б)
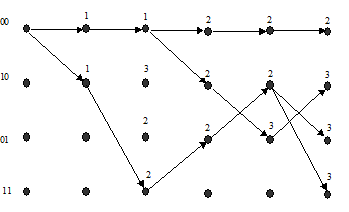
в) г)
Рис. 5. Пример декодирования с помощью алгоритма Витерби
После пятого такта декодированными считаются 5 информационных символов. Чтобы определить их значения необходимо выбрать лучший из выживших на пятом такте путей, т.е. путь с наименьшим значением метрики. Таковым в нашем примере является нулевой путь, который может быть получен на выходе кодера при подаче на его вход информационной последовательности 0 0 0 0 0 . Эта информационная последовательность выдается на выход декодера как результат декодирования. В данном случае эта последовательность совпала с переданной последовательностью, т.е. две ошибки в принятой последовательности исправлены.
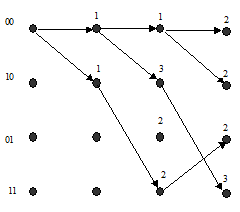
В реальных системах сверточное кодирование осуществляется непрерывно для практически бесконечных последовательностей на входе кодера. Поэтому декодирование также необходимо выполнять непрерывно во времени. Здесь мы продолжим вычисления для случая, когда на вход декодера продолжает поступать нулевая последовательность 00 00 00 00 00 00 00 00 00 00 … На рис. 6а и рис. 6б представлены выжившие пути после 9 и 10 тактов декодирования. После десятого такта декодирования первые восемь ребер четырех выживших путей совпали (все выжившие пути выходят из одной вершины) и на следующих тактах декодирования изменений на этих ребрах быть не может. Следовательно, в этот момент можно принять решение о символах, декодированных на первых восьми тактах: 0 0 0 0 0 0 0 0.
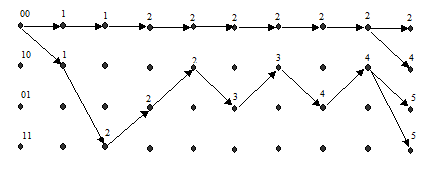
а)
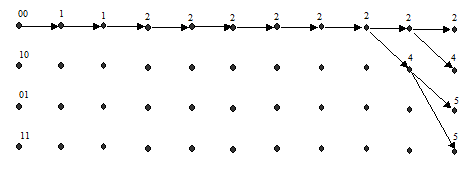
б)
Рис. 6. Выжившие пути и их метрики на 9-м (а) и 10-м (б) тактах декодирования
Из этих рисунков полезно сделать следующие полезные выводы:
1) с увеличением номера такта декодирования число выживших путей в прошлом уменьшается, поскольку ребра этих путей совпадают друг с другом;
2) с задержкой на несколько тактов, когда все выжившие пути выходят из одного узла, можно принять решения о результатах декодирования на этих тактах.
Глубина, на которой происходит слияние, не может быть вычислена заранее. Она является случайной величиной, значения которой зависят от возникших в канале передачи ошибок. Поэтому при практической реализации этого алгоритма декодирования не следует ожидать обязательного появления слияния ребер разных выживших путей. Можно лишь установить фиксированное значение задержки (глубину декодирования) для которой выносится решение о результатах декодирования. Каждый раз при обработке нового ребра решетки декодер выдает решение о самом старом символе одного из выживших путей. Оптимальное поведение здесь состоит в том, что решение принимается на основе пути с наименьшим значением метрики.
Таким образом, на каждом шаге декодирования в соответствии с алгоритмом Витерби производят однотипные операции:
- в каждом узле решетчатой диаграммы
: 1) вычисление метрик ребер, входящих в узел;
2) сложение метрик ребер каждого пути, входящего в узел;
3) сравнение метрик входящих путей и выбор пути с наименьшим значением метрики; если метрики путей совпадают, то случайным образом выбирается один из этих путей;
4) отбрасывание путей с большим значением метрик; оставшийся один путь будет продолжен на следующем шаге декодирования;
- среди всех выживших путей выбирается путь с наименьшим значением метрики и на глубине декодирования принимается решение о результате декодирования очередного информационного символа.
Фактически декодер прослеживает по кодовой решетке путь, имеющий минимальное расстояние от пути, полученного с выхода демодулятора. Типовая схема декодера содержит вычислитель метрик, подключаемый к выходу демодулятора, в котором вычисляются значения метрик очередных ребер, и процессор, в котором хранятся и обновляются значения метрик выживших путей, сравниваются эти метрики. Данные о выживших в результате такого сравнения путях хранятся в оперативной памяти процессора. Решения о принятых информационных символах выдаются на выход декодера. Структурную схему декодера, реализующего алгоритм декодирования Витерби, можно найти в [1].
Корректирующая способность сверточного кода зависит от так называемого свободного расстояния 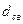 , которое определяется как минимальное число единиц пути на решетчатой диаграмме, начинающегося и заканчивающегося в нулевом узле. Для рассматриваемого здесь кода
, которое определяется как минимальное число единиц пути на решетчатой диаграмме, начинающегося и заканчивающегося в нулевом узле. Для рассматриваемого здесь кода 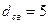 (см. решетчатую диаграмму на рис. 4).
(см. решетчатую диаграмму на рис. 4).
Исследования показывают, что с большой вероятностью через 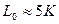 тактов первые ребра всех выживших путей начинают сливаться и на решетке начинает формироваться лишь один путь. Поэтому на некотором
тактов первые ребра всех выживших путей начинают сливаться и на решетке начинает формироваться лишь один путь. Поэтому на некотором 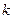 -том такте можно принять решение об информационном символе, который был принят на
-том такте можно принять решение об информационном символе, который был принят на 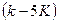 - такте.
- такте.
Для уменьшения объема памяти декодирующего устройства отрезки путей, по которым приняты решения, стираются. Для этого же из метрик всех узлов решетчатой диаграммы периодически вычитают минимальный на текущем такте вес.
Приложение 2
Дата добавления: 2020-04-25; просмотров: 143; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!