Методы поиска, основанные на сравнении ключей
Последовательный поиск
Последовательный (или другими словами линейный) поиск является одним из самых очевидных и понятных методов отыскания данных в массиве. Суть метода можно описать так: начать поиск с первого элемента массива, последовательно проверять элементы до тех пор, пока не будет найден искомый ключ.
Достоинством метода является отсутствие необходимости предварительной сортировки данных.
Несмотря на всю очевидность и однозначность, последовательный поиск имеет так называемую быструю реализацию, которая на данных большой размерности позволяет в разы сократить время поиска.
Оценка вычислительной эффективности
В лучшем случае элемент будет найден за 1 итерацию; в среднем линейный поиск требует  сравнений; в худшем случае число сравнений может достигать
сравнений; в худшем случае число сравнений может достигать  . Для массивов большой размерности время последовательного поиска велико –
. Для массивов большой размерности время последовательного поиска велико –  , в связи с чем его редко применяют на практике.
, в связи с чем его редко применяют на практике.
Бинарный поиск
Бинарный поиск требует предварительной сортировки данных в порядке возрастания ключей

На первом шаге ключ  сравнивается с центральным элементом множества. Номер центрального элемент определяется по формуле:
сравнивается с центральным элементом множества. Номер центрального элемент определяется по формуле:
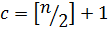 .
.
 – целая часть от деления .
– целая часть от деления .
Если:
·  – искомый элемент найден;
– искомый элемент найден;
·  – поиск продолжается в правой половине подмассива (
– поиск продолжается в правой половине подмассива (  );
);
·  – поиск продолжается в левой половине подмассива (
– поиск продолжается в левой половине подмассива (  ).
).
Пример 5.1: Задано упорядоченное множество, состоящее из  элементов c ключами
элементов c ключами

Требуется найти в множестве элемент с ключом 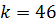 .
.
Найдем индекс центрального элемента:  .
.
Ключ центрального элемента  , что меньше ключа поиска :
, что меньше ключа поиска :
 .
.
Следовательно, дальнейший поиск следует производить в подмассиве, расположенном справа от центрального элемента (  ).
).
Для нового подмассива 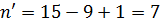 . Найдем индекс центрального элемента:
. Найдем индекс центрального элемента:  .
.
Ключ центрального элемента  , что больше ключа поиска :
, что больше ключа поиска :
 .
.
Это означает, что следующий подмассив будет располагаться левее текущего центрального элемента.
На итерации 3 центральный элемент совпадает с ключом поиска, поэтому алгоритм завершает работу.
Иллюстрация шагов бинарного поиска приведена на рисунке 5.11.
Итерация 1: 
Итерация 2: 
Итерация 3: 
Рис. 5.11. Пример бинарного поиска
 - центральный элемент массива;
- центральный элемент массива;
 - диапазон поиска на текущей итерации
- диапазон поиска на текущей итерации
Оценка вычислительной эффективности
В лучшем случае поиск завершится за 1 итерацию.
На каждой итерации количество элементов в подмассиве сокращается в 2 раза. В худшем случае поиск будет продолжаться до тех пор, пока в массиве не останется всего один элемент. Потребуется таких делений (то есть итераций).


Знаменатель может быть представлен в виде 


Тогда
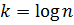
На каждой итерации производится 1 сравнение ключа поиска с найденным центральным элементом. Следовательно, в худшем случае оценка вычислительной сложности будет представлять  .
.
Уже при  бинарный поиск в разы превзойдет линейный по времени выполнения.
бинарный поиск в разы превзойдет линейный по времени выполнения.
Интерполяционный поиск
Это – метод поиска в отсортированном массиве в основу которого положена операция интерполяции. По принципу действия интерполяционный поиск схож с бинарным: в нем также выделяется некоторая подобласть поиска, которая сужается на каждой последующей итерации. Но в отличии от бинарного, интерполяционный поиск не делит массив на две равные части. На каждой итерации делается попытка рассчитать приблизительное расположение ключа в массиве.
Если проводить аналогию с поиском в реальной жизни, то интерполяционный поиск можно сравнить с поиском в телефонном справочнике – если нужно найти абонента с фамилией на букву «В» или «Г», то разумно начинать поиск в начале справочника, а не с середины или конца.
Центральный элемент  в интерполяционном методе ищется по следующей формуле:
в интерполяционном методе ищется по следующей формуле:

Здесь – ключ поиска;  ,
, 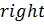 – номера левого и правого элементов границ диапазона поиска;
– номера левого и правого элементов границ диапазона поиска;  – значения левого и правого элементов границ диапазона поиска; означают целую часть от операции деления.
– значения левого и правого элементов границ диапазона поиска; означают целую часть от операции деления.
Пример 5.2: Задано упорядоченное множество, состоящее из элементов c ключами
Требуется найти в множестве элемент с ключом .
Найдем индекс центрального элемента:


Ключ центрального элемента  , что меньше ключа поиска :
, что меньше ключа поиска :
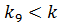 .
.
Следовательно, дальнейший поиск следует производить в подмассиве, расположенном справа от центрального элемента (  ).
).
Найдем индекс центрального элемента:

На итерации 2 центральный элемент совпадает с ключом поиска, поэтому алгоритм завершает работу.
Иллюстрация шагов интерполяционного поиска приведена на рисунке 5.12.
Итерация 1: 
Итерация 2: 
Рис. 5.12. Пример интерполяционного поиска
- центральный элемент массива;
- диапазон поиска на текущей итерации
Интерполяционный поиск показывает хорошие результаты на массивах где данные распределены равномерно. Доказано, что интерполяционный поиск реализует менее, чем  сравнений. Эта функция характеризуется очень медленными темпами роста, поэтому ее можно считать постоянной. Так, при
сравнений. Эта функция характеризуется очень медленными темпами роста, поэтому ее можно считать постоянной. Так, при  , значение
, значение  . Для небольших значений
. Для небольших значений  , функция
, функция  по своим значениям близка к значениям функции
по своим значениям близка к значениям функции  , поэтому реализация интерполяционного поиска в массивах небольшой размерности неоправдана. Зачастую интерполяционный поиск используется на первых шагах операции поиска в массивах большой размерности, а последующие шаги выполняются бинарным или линейным поиском.
, поэтому реализация интерполяционного поиска в массивах небольшой размерности неоправдана. Зачастую интерполяционный поиск используется на первых шагах операции поиска в массивах большой размерности, а последующие шаги выполняются бинарным или линейным поиском.
Хэширование
Хэширование (hashing – перемешивание) – вариант поиска с использованием индексирования по ключу. При таком поиске преобразованные с помощью арифметических действий значения ключей элементов используются в качестве индексов массива (хэш-таблицы), а не участвуют в сравнениях (в отличие от методов, рассмотренных в разделе 5.2.1).
Хэширование дает результат поиска, который в корне отличается от результатов, получаемых методами, основанными на сравнении. Здесь вместо перемещения по структуре массива и сравнения ключей поиска, реализуется попытка обращения непосредственно к элементам за счет выполнения арифметических операций преобразования ключей в адреса таблицы.
Алгоритмы поиска, основой которых является функция хэширования, состоят из двух шагов:
1. Вычисление хэш-функции, которая преобразует ключ поиска в адрес элемента.
2. Разрешение конфликтов – коллизий.
Необходимость выполнения шага 2 связана с неоднозначностью, которая может произойти при выполнении шага 1. Эта неоднозначность связана с возможностью, что два и более ключа могут быть преобразованы в один и тот же адрес хэш-таблицы, что является недопустимым.
Хэш-таблица – это абстрактный тип данных, в котором должна быть реализована возможность добавления, поиска и удаления элемента.
Хэш-функция (или функция хэширования) – функция, отображающая ключи элементов данных во множество целых чисел (индексы в хэш-таблице). Функция имеет вид

где – преобразуемый ключ;  – позиция элемента в хэш-таблице.
– позиция элемента в хэш-таблице.
На основании рассчитанных по значению ключа адресов, искомый элемент занимает место в хэш-таблице. Хорошей хэш-функцией считается такая, которая минимизирует количество коллизий и распределяет данные равномерно по таблице. Немаловажным требованием, предъявляемом к хэш-функциям, является простота их вычисления.
Хэш-функция обладает 2 важными свойствами:
1. Необратимость. Так как хэш-функция порождает коллизии, восстановление по ней ключа не представляется возможным. Следовательно, ключ поиска обязательно должен являться полем хэш-таблицы.
2. Детерминированность. Для одного и того же значения ключа должен получаться один и тот же индекс в хэш-таблице (вероятностный фактор в хэш-функции недопустим).
На рисунке 5.13 представлена схема процедуры хэширования. Здесь  – размер хэш-таблицы (количестов строк в ней).
– размер хэш-таблицы (количестов строк в ней).
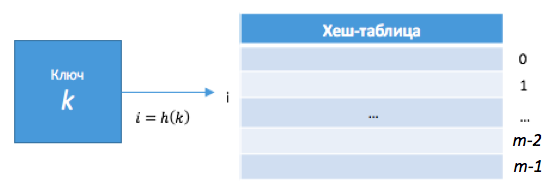
Рис. 5.13. Схема хэширования
Важным этапом метода является определение хэш-функции. Если ключи заранее неизвестны, то определить какая функция покажет наилучший результат невозможно. Однако, зачастую известны некоторые свойства ключей, которые могут помочь определиться с типом хэш-функции.
Методы задания хэш-функций
Метод прямого доступа
Является простейшим способом реализации хэш-таблицы. В нем в качестве индексов хэш-таблицы используются сами ключи элементов поиска (возможно, преобразованные). Диапазон индексов таблицы совпадает с диапазоном чисел ключей. В данном методе не допускается возникновение коллизий, так как никакие два ключа не могут быть преобразованы в один индекс.
Метод позволяет всего за одну проверку определить имеется ли элемент поиска в таблице. Размещение элемента в таблице так же реализуется за один шаг.
Недостатком метода является необходимость выделения большого объема памяти, большая часть которого не будет использована. Например, если ключами поиска являются фамилии, состоящие максимум из 10 букв русского алфавита, то метод потребует выделение памяти для хранения  возможных ключей. Естественно, фактическое значение возможных ключей значительно меньше такого количества.
возможных ключей. Естественно, фактическое значение возможных ключей значительно меньше такого количества.
Ввиду указанного выше недостатка, метод практически не применяется на практике.
Метод деления
Индекс элемента в хэш-таблице определяется как остаток от деления ключа на число элементов хэш-таблицы  :
:

Здесь операция  означает взятие целочисленного остатка от деления.
означает взятие целочисленного остатка от деления.
Например, при  , хэш-функция будет возвращать последний разряд числа:
, хэш-функция будет возвращать последний разряд числа:
для  ,
, 
для  ,
, 
для  ,
, 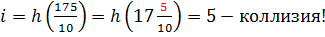
Размер хэш-таблицы может быть любым, но минимальное количество коллизий обеспечиваеся в случаях, когда является простым числом. Худшим вариантом является ситуация, когда является степенью числа 2 (  ). В этом случае результатом деления будут последние
). В этом случае результатом деления будут последние  разрядов ключа, что приводит к большому количеству коллизий. Поэтому принято выбирать простым числом, максимально далеким от степеней 2.
разрядов ключа, что приводит к большому количеству коллизий. Поэтому принято выбирать простым числом, максимально далеким от степеней 2.
Дата добавления: 2020-01-07; просмотров: 4307; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!