Прогностическое моделирование (Predictive Modeling)
Здесь, на второй стадии ИАД, используются плоды работы первой, то есть найденные в БД закономерности применяются для предсказания неизвестных значений:
· при классификации нового объекта мы можем с известной уверенностью отнести его к определенной группе результатов рассмотрения известных значений его атрибутов;
· при прогнозировании динамического процесса результаты определения тренда и периодических колебаний могут быть использованы для вынесения предположений о вероятном развитии некоторого динамического процесса в будущем.
Возвращаясь к рассмотренным примерам, продолжим их на данную стадию. Зная, что некто Иванов - программист, можно быть на 61% уверенным, что его возраст <=30 годам, и на 98% - что он <=60 годам. Аналогично, можно сделать заключение о 84% вероятности того, что некоторое новое юридическое лицо будет находиться в муниципальной собственности, если его основной вид деятельности - "Общеобразовательные детские школы".
Следует отметить, что свободный поиск раскрывает общие закономерности, т. е. индуктивен, тогда как любой прогноз выполняет догадки о значениях конкретных неизвестных величин, следовательно, дедуктивен. Кроме того, результирующие конструкции могут быть как прозрачными, т. е. допускающими разумное толкование (как в примере с произведенными логическими правилами), так и нетрактуемыми - "черными ящиками" (например, про построенную и обученную нейронную сеть никто точно не знает, как именно она работает).
Анализ исключений (Forensic Analysis)
Предметом данного анализа являются аномалии в раскрытых закономерностях, то есть необъясненные исключения. Чтобы найти их, следует сначала определить норму (стадия свободного поиска), вслед за чем выделить ее нарушения. Так, определив, что 84% общеобразовательных школ отнесены к муниципальной форме собственности, можно задаться вопросом - что же входит в 16%, составляющих исключение из этого правила? Возможно, им найдется логическое объяснение, которое также может быть оформлено в виде закономерности. Но может также статься, что мы имеем дело с ошибками в исходных данных, и тогда анализ исключений может использоваться в качестве инструмента очистки сведений в хранилище данных.
Методы ИАД
Все методы ИАД подразделяются на две большие группы по принципу работы с исходными обучающими данными.
В первом случае исходные данные могут храниться в явном детализированном виде и непосредственно использоваться для прогностического моделирования и/или анализа исключений; это так называемые методы рассуждений на основе анализа прецедентов. Главной проблемой этой группы методов является затрудненность их использования на больших объемах данных, хотя именно при анализе больших хранилищ данных методы ИАД приносят наибольшую пользу.
Во втором случае информация вначале извлекается из первичных данных и преобразуется в некоторые формальные конструкции (их вид зависит от конкретного метода). Согласно предыдущей классификации, этот этап выполняется на стадии свободного поиска, которая у методов первой группы в принципе отсутствует. Таким образом, для прогностического моделирования и анализа исключений используются результаты этой стадии, которые гораздо более компактны, чем сами массивы исходных данных. При этом полученные конструкции могут быть либо "прозрачными" (интерпретируемыми), либо "черными ящиками" (нетрактуемыми).
Две эти группы и примеры входящих в них методов представлены на рисунке 3.
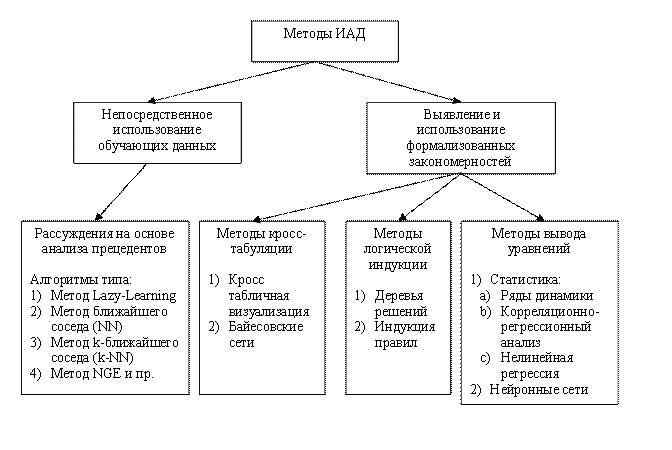
Рисунок 3. Классификация технологических методов ИАД
Дата добавления: 2019-03-09; просмотров: 305; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!