Принципы работы OLAP -клиентов
Рассмотрим процесс создания OLAP-приложения с помощью клиентского инструментального средства (рис. 1).
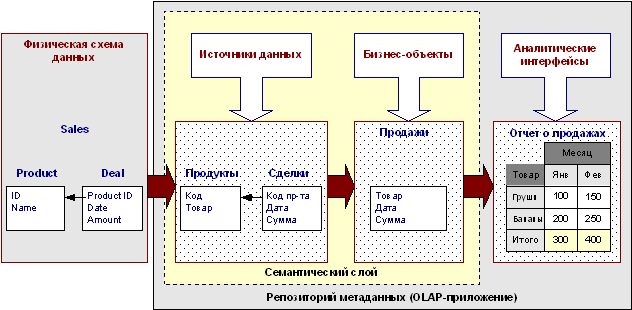
Рисунок 1. Создание OLAP-приложения с помощью клиентского ROLAP-средства
Принцип работы ROLAP-клиентов – предварительное описание семантического слоя, за которым скрывается физическая структура исходных данных. При этом источниками данных могут быть: локальные таблицы, РСУБД. Список поддерживаемых источников данных определяется конкретным программным продуктом. После этого пользователь может самостоятельно манипулировать понятными ему объектами в терминах предметной области для создания кубов и аналитических интерфейсов.
Принцип работы клиента OLAP-сервера иной. В OLAP-сервере при создании кубов пользователь манипулирует физическими описаниями БД. При этом в самом кубе создаются пользовательские описания. Клиент OLAP-сервера настраивается только на куб.
При создании семантического слоя источники данных – таблицы Sales и Deal – описываются понятными конечному пользователю терминами и превращаются в «Продукты» и «Сделки». Поле «ID» из таблицы «Продукты» переименовывается в «Код», а «Name» - в «Товар» и т.д.
Затем создается бизнес-объект «Продажи». Бизнес-объект – это плоская таблица, на основе которой формируется многомерный куб. При создании бизнес-объекта таблицы «Продукты» и «Сделки» объединяются по полю «Код» товара. Поскольку для отображения в отчете не потребуются все поля таблиц – бизнес-объект использует только поля «Товар», «Дата» и «Сумма».
|
|
|
Далее на базе бизнес-объекта создается OLAP-отчет. Пользователь выбирает бизнес-объект и перетаскивает его атрибуты в области колонок или строк таблицы отчета.
В нашем примере на базе бизнес-объекта «Продажи» создан отчет по продажам товаров по месяцам.
При работе с интерактивным отчетом пользователь может задавать условия фильтрации и группировки такими же простыми движениями «мышью». В этот момент ROLAP-клиент обращается к данным в кэше. Клиент же OLAP-сервера генерирует новый запрос к многомерной базе данных. Например, применив в отчете о продажах фильтр по товарам, можно получить отчет о продажах интересующих нас товаров.
Все настройки OLAP-приложения могут храниться в выделенном репозитории метаданных, в приложении или в системном репозитории многомерной базы данных. Реализация зависит от конкретного программного продукта.
Все, что включается в состав этих приложений, представляет собой стандартный взгляд на интерфейс, заранее определенные функции и структуру, а также быстрые решения для более или менее стандартных ситуаций. Например, популярны финансовые пакеты. Заранее созданные финансовые приложения позволят специалистам использовать привычные финансовые инструменты без необходимости проектировать структуру базы данных или общепринятые формы и отчеты.
|
|
|
Интернет является новой формой клиента. Кроме того, он несет на себе печать новых технологий; множество интернет-решений существенно отличаются по своим возможностям в целом и в качестве OLAP-решения - в частности. Существует масса преимуществ в формировании OLAP-отчетов через Интернет. Наиболее существенным представляется отсутствие необходимости в специализированном программном обеспечении для доступа к информации. Это экономит предприятию кучу времени и денег.
Выбор архитектуры OLAP-приложения
При реализации информационно-аналитической системы важно не ошибиться в выборе архитектуры OLAP-приложения. Дословный перевод термина On-Line Analytical Process — «оперативная аналитическая обработка» — часто воспринимается буквально в том смысле, что поступающие в систему данные оперативно анализируются. Это заблуждение — оперативность анализа никак не связана с реальным временем обновления данных в системе. Эта характеристика относится к времени реакции OLAP-системы на запросы пользователя. При этом зачастую анализируемые данные представляют собой снимок информации «на вчерашний день», если, например, данные в хранилищах обновляются раз в сутки.
|
|
|
В этом контексте более точен перевод OLAP как «интерактивная аналитическая обработка». Именно возможность анализа данных в интерактивном режиме отличает OLAP-системы от систем подготовки регламентированных отчетов.
Другой особенностью интерактивной обработки в формулировке родоначальника OLAP Э. Кодда является возможность «объединять, просматривать и анализировать данные с точки зрения множественности измерений, т. е. самым понятным для корпоративных аналитиков способом». У самого Кодда термин OLAP обозначает исключительно конкретный способ представления данных на концептуальном уровне — многомерный. На физическом уровне данные могут храниться в реляционных базах данных, однако на деле OLAP-инструменты, как правило, работают с многомерными базами данных, в которых данные упорядочены в виде гиперкуба (рис. 1).
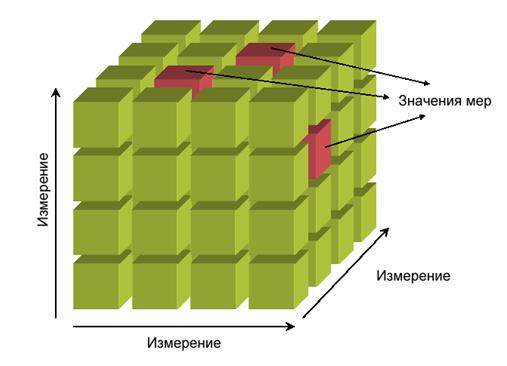
Рисунок 1. OLAP – куб (гиперкуб, метакуб)
При этом актуальность этих данных определяется моментом наполнения гиперкуба новыми данными.
Очевидно, что время формирования многомерной базы данных существенно зависит от объема загружаемых в нее данных, поэтому разумно ограничить этот объем. Но как при этом не сузить возможности анализа и не лишить пользователя доступа ко всей интересующей информации? Существует два альтернативных пути: Analyze then query («Сначала проанализируй — затем запроси дополнительную информацию») и Query then analyze («Сначала запроси данные — затем анализируй»).
|
|
|
Последователи первого пути предлагают загружать в многомерную базу данных обобщенную информацию, например, месячные, квартальные, годовые итоги по подразделениям. А при необходимости детализации данных пользователю предлагается сформировать отчет по реляционной базе, содержащей требуемую выборку, например, по дням для данного подразделения или по месяцам и сотрудникам выбранного подразделения.
Сторонники второго пути, напротив, предлагают пользователю, прежде всего, определиться с данными, которые он собирается анализировать и именно их загружать в микрокуб — небольшую многомерную базу данных. Оба подхода отличаются на концептуальном уровне и имеют свои достоинства и недостатки.
К достоинствам второго подхода следует отнести «свежесть» информации, которую пользователь получает в виде многомерного отчета — «микрокуба». Микрокуб формируется на основе только что запрошенной информации из актуальной реляционной базы данных. Работа с микрокубом осуществляется в интерактивном режиме — получение срезов информации и ее детализация в рамках микрокуба осуществляется моментально. Другим положительным моментом является то, что проектирование структуры и наполнение микрокуба осуществляется пользователем «на лету», без участия администратора баз данных. Однако подход страдает и серьезными недостатками. Пользователь, не видит общей картины и должен заранее определяться с направлением своего исследования. В противном случае запрошенный микрокуб может оказаться слишком мал и не содержать всех интересующих данных, а пользователю придется запрашивать новый микрокуб, затем новый, затем еще и еще. Подход Query then analyze реализует инструментальное средство BusinessObjects одноименной компании и инструментальные средства платформы Контур компании Intersoft Lab.
При подходе Analyze then query объем данных, загружаемых в многомерную базу данных, может быть достаточно велик, наполнение должно выполняться по регламенту и может занимать достаточно много времени. Однако все эти недостатки окупаются впоследствии, когда пользователь имеет доступ практически ко всем необходимым данным в любой комбинации. Обращение к исходным данным в реляционной базе данных осуществляется лишь в крайнем случае, когда необходима детальная информация, например, по конкретной накладной.
На работе единой многомерной базы данных практически не сказывается количество обращающихся к ней пользователей. Они лишь читают имеющиеся там данные в отличие от подхода Query then analyze, при котором количество микрокубов в предельном случае может расти с той же скоростью, что и количество пользователей.
При данном подходе увеличивается нагрузка на ИТ-службы, которые кроме реляционных вынуждены обслуживать еще и многомерные базы данных. Именно эти службы несут ответственность за своевременное автоматическое обновление данных в многомерных базах данных.
Наиболее яркими представителями подхода «Analyze then query» являются инструментальные средства PowerPlay и Impromptu компании Cognos.
Выбор и подхода, и инструмента его реализующего, зависит в первую очередь от преследуемой цели: всегда приходится балансировать между экономией бюджета и повышением качества обслуживания конечных пользователей. При этом надо учитывать, что в стратегическом плане создание информационно-аналитических систем преследует цели достижения конкурентного преимущества, а не избежания расходов на автоматизацию. Например, корпоративная информационно-аналитическая система может предоставлять необходимую, своевременную и достоверную информацию о компании, публикация которой для потенциальных инвесторов обеспечит прозрачность и предсказуемость данной компании, что неизбежно станет условием ее инвестиционной привлекательности.
Дата добавления: 2019-03-09; просмотров: 327; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!