Множественная регрессия и корреляция
Теоретическое введение
Множественная регрессия – уравнение связи с несколькими независимыми переменными:  , где у – зависимая переменная (результативный признак); х1, х2,…, хp – независимые переменные (факторы).
, где у – зависимая переменная (результативный признак); х1, х2,…, хp – независимые переменные (факторы).
Для построения уравнения множественной регрессии чаще используются следующие функции:
· линейная –  ;
;
· степенная –  ;
;
· экспонента –  ;
;
· гипербола –  .
.
Можно использовать и другие функции, приводимые к линейному виду.
Для оценки параметров уравнения множественной регрессии применяют метод наименьших квадратов (МНК). Для линейных уравнений и нелинейных уравнений, приводимых к линейным, строится следующая система нормальных уравнений, решение которой позволяет получить оценки параметров регрессии:

Для ее решения может быть применен метод определителей:
 ,
,  ,…,
,…,  ,
,
где  – определитель системы;
– определитель системы;
 – частные определители, которые получаются путем замены соответствующего столбца матрицы определителя системы данными левой части системы.
– частные определители, которые получаются путем замены соответствующего столбца матрицы определителя системы данными левой части системы.
Другой вид уравнения множественной регрессии – уравнение регрессии в стандартизированном масштабе:
 ,
,
где  ,
,  – стандартизированные переменные;
– стандартизированные переменные;  – стандартизированные коэффициенты регрессии.
– стандартизированные коэффициенты регрессии.
К уравнению множественной регрессии в стандартизированном масштабе применим МНК. Стандартизированные коэффициенты регрессии (b-коэффициенты) определяются из следующей системы уравнений:
 .
.
Связь коэффициентов множественной регрессии bi со стандартизированными коэффициентами  описывается соотношением
описывается соотношением
|
|
|
 .
.
Параметр а определяется как  .
.
Средние коэффициенты эластичности для линейной регрессии рассчитываются по формуле
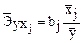 .
.
Для расчета частных коэффициентов эластичности применяется следующая формула:
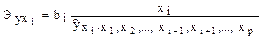 .
.
Тесноту совместного влияния факторов на результат оценивает индекс множественной корреляции:
 .
.
Значение индекса множественной корреляции лежит в пределах от 0 до1 и должно быть больше или равно максимальному парному индексу корреляции:
 .
.
Индекс множественной корреляции для уравнения в стандартизированном масштабе можно записать в виде
 .
.
При линейной зависимости коэффициент множественной корреляции можно определить через матрицу парных коэффициентов корреляции:
 ,
,
где  – определитель матрицы парных коэффициентов корреляции;
– определитель матрицы парных коэффициентов корреляции;
 – определитель матрицы межфакторной корреляции.
– определитель матрицы межфакторной корреляции.
Частные коэффициенты (или индексы) корреляции, измеряющие влияние на у фактора хi при неизменном уровне других факторов, можно определить по формуле

или по рекуррентной формуле:
 .
.
Частные коэффициенты корреляции изменяются в пределах
от –1 до 1.
Качество построенной модели в целом оценивает коэффициент (индекс) детерминации. Коэффициент множественной детерминации рассчитывается как квадрат индекса множественной корреляции:
|
|
|
 .
.
Скорректированный индекс множественной детерминации содержит поправку на число степеней свободы и рассчитывается по формуле
 ,
,
где n – число наблюдений;m – число факторов.
Значимость уравнения множественной регрессии в целом оценивается с помощью F-критерия Фишера:
 .
.
Частный F -критерий оценивает статистическую значимость присутствия каждого из факторов в уравнении. В общем виде для фактора xi частный F-критерий определяется как
 .
.
Оценка значимости коэффициентов чистой регрессии с помощью t-критерия Стьюдента сводится к вычислению значения
 ,
,
где  – средняя квадратичная шибка коэффициента регрессии bi, она может быть определена по следующей формуле:
– средняя квадратичная шибка коэффициента регрессии bi, она может быть определена по следующей формуле:
 .
.
При построении уравнения множественной регрессии может возникнуть проблема мультиколлинеарности факторов, их тесной линейной связанности.
Считается, что две переменные явно коллинеарны, т.е. находятся между собой в линейной зависимости, если  .
.
По величине парных коэффициентов корреляции обнаруживается лишь явная коллинеарность факторов. Наибольшие трудности в использовании аппарата множественной регрессии возникают при наличии мультиколлинеарности факторов. Чем сильнее мультиколлинеарность факторов, тем менее надежна оценка распределения суммы объясненной вариации по отдельным факторам с помощью метода наименьших квадратов.
|
|
|
Для оценки мультиколлинеарности факторов может использоваться определитель матрицы парных коэффициентов корреляции между факторами.
Если бы факторы не коррелировали между собой, то матрица парных коэффициентов корреляции между факторами была бы единичной матрицей, поскольку все недиагональные элементы  были бы равны нулю. Так, для включающего три объясняющих переменных уравнения
были бы равны нулю. Так, для включающего три объясняющих переменных уравнения 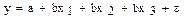 матрица коэффициентов корреляции меду факторами имела бы определитель, равный 1:
матрица коэффициентов корреляции меду факторами имела бы определитель, равный 1:
 ,
,
так как  и
и  .
.
Если же, наоборот, между факторами существует полная линейная зависимость и все коэффициенты корреляции равны 1, то определитель такой матрицы равен 0:
 .
.
Чем ближе к нулю определитель матрицы межфакторной корреляции, тем сильнее мультиколлинеарность факторов и ненадежнее результаты множественной регрессии. И наоборот, чем ближе к 1 определитель матрицы межфакторной корреляции, тем меньше мультиколлинеарность факторов.
|
|
|
Проверка мультиколлинеарности факторов может быть проведена методом испытания гипотезы о независимости переменных  . Доказано, что величина
. Доказано, что величина  имеет приближенное распределение χ2 с
имеет приближенное распределение χ2 с  степенями свободы. Если фактическое значение χ2 превосходит табличное (критическое)
степенями свободы. Если фактическое значение χ2 превосходит табличное (критическое)  , то гипотеза H0 отклоняется. Это означает, что
, то гипотеза H0 отклоняется. Это означает, что  , недиагональные нулевые коэффициенты корреляции указывают на коллинеарность факторов. Мультиколлинеарность считается доказанной.
, недиагональные нулевые коэффициенты корреляции указывают на коллинеарность факторов. Мультиколлинеарность считается доказанной.
Для применения МНК требуется, чтобы дисперсия остатков была гомоскедастичной. Это значит, что для каждого значения фактора xj остатки 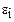 имеют одинаковую дисперсию. Если это условие не соблюдается, то имеет место гетероскедастичность.
имеют одинаковую дисперсию. Если это условие не соблюдается, то имеет место гетероскедастичность.
При нарушении гомоскедастичности мы имеем неравенства
 .
.
При малом объеме выборки для оценки гетероскедастичности может использоваться метод Гольдфельда-Квандта. Основная идея теста Гольдфельда-Квандта состоит в следующем:
1) упорядочение n наблюдений по мере возрастания переменной х;
2) исключение из рассмотрения С натуральных наблюдений; при этом (n-C): 2>p, где p – число оцениваемых параметров;
3) разделение совокупности из (n-C) наблюдений на две группы (соответственно с малыми и с большими значениями фактора х) и определение по каждой из групп уравнений регрессии;
4) определение остаточной суммы квадратов для первой (S1) и второй (S2) групп и нахождение их отношения: R=S1: S2.
При выполнении нулевой гипотезы о гомоскедастичности отношение R будет удовлетворять F-критерию со степенями свободы ((n-C-2p):2) для каждой остаточной суммы квадратов. Чем больше величина R превышает табличное значение F-критерия, тем более нарушена предпосылка о равенстве дисперсий остаточных величин.
Уравнения множественной регрессии могут включать в качестве независимых переменных качественные признаки (например, профессия пол, образование, климатические условия, отдельные регионы и т.д.). Чтобы ввести такие переменные в регрессионную модель, их необходимо упорядочить и присвоить им те или иные значения, т.е. качественные переменные преобразовать в количественные.
Такого вида сконструированные переменные принято в эконометрике называть фиктивными переменными. Например, включать в модель фактор «пол» в виде фиктивной переменной можно в следующем виде:

Коэффициент регрессии при фиктивной переменной интерпретируется как среднее изменение зависимой переменной при переходе от одной категории (женский пол) к другой (мужской пол) при неизменных значениях остальных параметров. На основе t–критерия Стьюдента делается вывод о значимости влияния фиктивной переменной, существенности расхождения между категориями.
Решение типовых задач
Постановка задачи 1
По 30 территориям России имеются данные, представленные в таблице 2.1.
Таблица 2.1. Исходные данные задачи 1
| Признак | Среднее значение | Среднее квадратическое отклонение | Линейный коэффициент парной корреляции |
| Среднедневной душевой доход, руб., у | 86,8 | 11,44 | – |
| Среднедневная плата одного работающего руб.,х1 | 54,9 | 5,86 | ryx1 = 0,8405 |
| Средний возраст безработного лет, х2 | 33,5 | 0,58 | ryx2 = – 0,2101 rx1х2= – 0,1160 |
Требуется:
1. Построить уравнение множественной регрессии в стандартизованной и естественной  форме; рассчитать частные коэффициенты эластичности, сравнить их с b1 и b2, пояснить различия между ними.
форме; рассчитать частные коэффициенты эластичности, сравнить их с b1 и b2, пояснить различия между ними.
2. Рассчитать линейные коэффициенты частной корреляции и коэффициент множественной корреляции, сравнить их с линейными коэффициентами множественной корреляции, пояснить различия между ними.
3. Рассчитать общий и частные F-критерии Фишера.
Решение задачи 1
1. Линейное уравнение множественной регрессии y от х1 и х2 имеет вид: у=a+b1x1+b2x2. Для расчета его параметров применим метод стандартизации переменных и построим искомое уравнение в стандартизованном масштабе: ty=b1tx1+b2tx2.
Расчет b-коэффициентов выполним по формулам
 ;
;
 .
.
Получим уравнение
ty=0,8273tx1+0,1141tx2.
Для построения уравнения в естественной форме рассчитаем b1 и b2, используя формулы для перехода от bi к bi:
 ;
;  ;
;
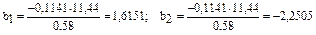 .
.
Значение a определим из соотношения
 ;
;
 .
.
Для характеристики относительной силы влияния x1 и x2 на y рассчитаем средние коэффициенты эластичности:

 .
.
С увеличением средней заработной платы x1 на 1% от её среднего уровня средний душевой доход у возрастает на 1,02% от всего среднего уровня; при повышении среднего возраста безработного x2 на 1% среднедушевой доход у снижается на 0,87% от всего среднего уровня. Очевидно, что сила влияния средней заработной платы x1 на средний душевой доход у оказалась большей, чем сила влияния среднего возраста безработного x2 . К аналогичным выводам о силе связи приходим при сравнении модулей значений b1 и b2:
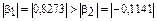 .
.
Различия в силе влияния фактора на результат, полученные при сравнении  и bj, объясняются тем, коэффициент эластичности происходит из соотношения средних:
и bj, объясняются тем, коэффициент эластичности происходит из соотношения средних:  , а b-коэффициент – из соотношения средних квадратических отклонений:
, а b-коэффициент – из соотношения средних квадратических отклонений:  .
.
2. Линейные коэффициенты частой корреляции здесь рассчитываются по рекуррентной формуле:
 ;
;
 ;
;
 .
.
Если сравнить значения коэффициентов парной и частной корреляции, то приходим к выводу, что из-за слабой межфакторной связи (  = –0,116) коэффициенты парной и частной корреляции отличаются незначительно: выводы о тесноте и направлении связи на основе коэффициентов парной и частной корреляции совпадают:
= –0,116) коэффициенты парной и частной корреляции отличаются незначительно: выводы о тесноте и направлении связи на основе коэффициентов парной и частной корреляции совпадают:

Расчёт линейного коэффициента множественной корреляции выполним с использованием коэффициентов ryxj и bj:
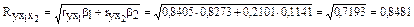 .
.
Зависимость у от х1 и х2 характеризуется как тесная, в которой 72% вариации среднего душевного дохода определяются вариацией учтённых в модели факторов: средней заработной платы и среднего возраста безработного. Прочие факторы, не включённые в модель, составляют соответственно 28% от общей вариации у.
3. Общий F-критерий проверяет гипотезу Н0 о статистической значимости уравнения регрессии и показателя тесноты связи (R2=0):
 ;
;
Fтабл=3,4; a=0,05.
Сравнивая Fфакт и Fтабл, приходим к выводу о необходимости отклонить гипотезу Н0, так как Fтабл=3,4 < Fфакт=34,6. С вероятностью
1-a=0,95 делаем заключение о статистической значимости уравнения в целом и показателя тесноты связи Ryx1x2, которые сформировались под неслучайным воздействием факторов х1 и х2.
Частные F-критерии – Fx1 и Fx2 оценивают статистическую значимость присутствия факторов х1 и х2 в уравнении множественной регрессии, оценивают целесообразность включения в уравнение одного фактора после другого фактора, то есть Fx1 оценивает целесообразность включения в уравнение одного фактора х1 после того, как в него был включён фактор х2. Соответственно Fx2 указывает на целесообразность включения в уравнение одного фактора х2 после фактора х1:
 .
.
Fтабл=4,21; a=0,05.
Сравнивая Fфакт и Fтабл, приходим к выводу о целесообразности включения в модель фактора х1 после фактора х2, так как
Fх1 факт = 64,9 > Fтабл. Гипотезу Н0 о несущественности прироста R2y за счёт включения дополнительного фактора х1 отклоняем и приходим к выводу о статистически подтверждённой целесообразности включении фактора х1 после фактора х2.
Целесообразность включения фактора х2 после фактора х1 проверяет Fx2:
 .
.
Низкое значение Fх2 факт (немногим больше 1) свидетельствует о статистической незначимости прироста r2yx1 за счёт включения фактора х2 после фактора х1. Следовательно, подтверждается нулевая гипотеза Н0 о нецелесообразности включения в модель фактора х2 (средний возраст безработного). Это означает, что парная регрессионная модель зависимости среднего дохода от средней заработной платы является достаточно статистически значимой, надёжной и что нет необходимости улучшать её, включая дополнительный фактор х2 (средний возраст безработного).
Постановка задачи 2
По 20 территориям России изучаются следующие данные: зависимость среднегодового дохода y (тыс. руб.) от доли занятых тяжелым физическим трудом в общей численности занятых x1 (%) и от доли экономически активного населения в численности всего населения x2 (%), представленные в таблице 2.2.
Таблица 2.2. Исходные данные задачи 2
| Признак | Среднее значение | Среднее квадратическое отклонение | Характеристика тесноты связи | Уравнение связи |
| y | 112,76 | 31,58 | Ryx1x2=0,773 | 
|
| x1 | 5,40 | 3,34 | ryx1=0,746 | 
|
| x2 | 50,88 | 1,74 | ryx2=0,507 rx1x2=0,432 | 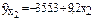
|
Требуется:
1. Составить таблицу дисперсионного анализа для проверки при уровне значимости a=0,05 статистической значимости уравнения множественной регрессии и его показателя тесноты связи.
2. С помощью частных F-критериев Фишера оценить, насколько целесообразно включение в уравнение множественной регрессии фактора x1 после фактора x2 и насколько целесообразно включение x2 после x1.
3. Оценить с помощью t-критерия Стьюдента статистическую значимость коэффициентов при переменных x1 и x2 множественного уравнения регрессии.
Решение задачи 2
1. Задача дисперсионного анализа состоит в проверке нулевой гипотезы H0 о статистической незначимости уравнения регрессии в целом и показателя тесноты связи.
Анализ выполняется при сравнении фактического и табличного (критического) значений F-критерия Фишера. Fфакт определяется из соотношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:
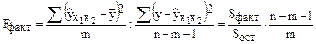 .
.
Результаты дисперсионного анализа представлены в таблице 2.3.
Таблица 2.3. Результаты дисперсионного анализа
| Вариация результата, y | Число степней свободы | Сумма квадратов отклонений, S | Дисперсия на одну степень свободы, S2 | Fфакт | Fтабл a=0,05, k1=2, k2=17 |
| Общая | df=n-1=19 | 19945,9 | – | – | – |
| Факторная | k1=m=2 | 11918,3 | 5959,15 | 12,62 | 3,59 |
| Остаточная | k2=n-m-1=17 | 8027,6 | 472,21 | – | – |

Сравнивая Fтабл и Fфакт, приходим к выводу о необходимости отклонить гипотезу H0 и сделать вывод о статистической значимости уравнения регрессии в целом и значения 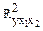 , так как они статистически надежны и сформировались под систематическим действием неслучайных причин. Вероятность того, что допускаются ошибки при отклонении нулевой гипотезы, не превышает 5%, и это является достаточно малой величиной.
, так как они статистически надежны и сформировались под систематическим действием неслучайных причин. Вероятность того, что допускаются ошибки при отклонении нулевой гипотезы, не превышает 5%, и это является достаточно малой величиной.
2. Частный F-критерий Фишера оценивает статистическую целесообразность включения фактора x1 в модель после того, как в нее включен фактор x2. Частный F-критерий Фишера строится как отношение прироста факторной дисперсии за счет дополнительно включенного фактора (на одну степень свободы) к остаточной дисперсии (на одну степень свободы), подсчитанной по модели с включенными факторами x1 и x2:

Результаты дисперсионного анализа представлены в таблице 2.4.
Таблица 2.4. Результаты дисперсионного анализа
| Вариация результата, y | Число степней свободы | Сумма квадратов отклонений, S | Дисперсия на одну степень свободы, S2 | Fфакт | Fтабл a=0,05, k1=2, k2=17 |
| Общая | df=n-1=19 | 19945,9 | – | – | – |
| Факторная В том числе: за счет x2 за счет дополнительно включенного x1 | k1=m=2 1 1 | 11918,3 5127,1 6791,2 | 5959,15 5127,1 6791,2 | 12,62 10,86 14,38 | 3,59 4,45 4,45 |
| Остаточная | k2=n-m-1 | 8027,6 | 472,21 | – | – |

Включение фактора x1 после фактора x2 оказалось статистически значимым и оправданным: прирост факторной дисперсии (в расчете на одну степень свободы) оказался существенным, т.е. следствием дополнительного включения в модель систематически действующего фактора x1, так как  = 14,38 > Fтабл = 4,45.
= 14,38 > Fтабл = 4,45.
Аналогично проверим целесообразность включения в модель дополнительного фактора x2 после включенного ранее фактора x1.Расчет выполним с использованием показателей тесноты связи  и
и 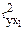 :
:
 .
.
В силу того что  = 1,73 < Fтабл = 4,45, приходим к выводу, что включение x2 после x1 оказалось бесполезным: прирост факторной дисперсии в расчете на одну степень свободы был несущественен, статистически незначим, т.е. влияние x2 не является устойчивым, систематическим. Вполне возможно было ограничиться построением линейного уравнения парной регрессии у от x1.
= 1,73 < Fтабл = 4,45, приходим к выводу, что включение x2 после x1 оказалось бесполезным: прирост факторной дисперсии в расчете на одну степень свободы был несущественен, статистически незначим, т.е. влияние x2 не является устойчивым, систематическим. Вполне возможно было ограничиться построением линейного уравнения парной регрессии у от x1.
3. Оценка с помощью t-критерия Стьюдента значимости коэффициентов b1 и b2 связана с сопоставлением их значений с величиной их случайных ошибок: mb1 и mb2. Расчет значений случайных ошибок достаточно сложен и трудоёмок. Поэтому предлагается более простой способ: расчет значения t-критерия Стьюдента для коэффициентов регрессии линейного уравнения как квадратного корня из соответствующего частного F-критерия Фишера:

Табличные (критические) значения t-критерия Стьюдента зависят от принятого уровня значимости a (обычно это 0,1; 0,05 или 0,01) и от числа степеней свободы (n-m-1), где n– число единиц совокупности, m – число факторов в уравнении.
В нашем примере a = 0,05; df = 20-3 = 17; tтабл = 2,10. Сравнивая tтабл и tфакт, приходим к выводу, что так как tb1 = 3,79 > 2,11 = tтабл, коэффициент b1 является статистически значимым, надежным, на него можно опираться в анализе и прогнозе. Так как tb2 = 1,32 < 2,10 = tтабл, приходим к заключению, что величина b2 является статистически незначимой, ненадежной в силу того, что она формируется преимущественно под воздействием случайных факторов. Еще раз подтверждается статистическая значимость влияния x1 (доли занятых тяжелым физическим трудом) на у (среднедушевой доход) и ненадежность, незначимость влияния х2 (доли экономически активного населения в численности всего населения).
Дата добавления: 2019-02-26; просмотров: 414; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!