Малюнок 2.7. Програма як діалектичне заперечення проблеми 3 страница
Наступне поняття в пентаді – композиція, яке уточнимо в рамках композиційної системи Cm(Z)=<D, F, C>, де CÍ(Z  F) F. Тут Z виступає як множина імен аргументів композицій.
F) F. Тут Z виступає як множина імен аргументів композицій.
Нарешті, формалізуємо поняття дескрипції. Насамперед зазначимо, що наявність композицій дозволяє ієрархічну побудову програм із деяких базових функцій багатократним застосуванням композицій. Тому дескрипції визначаються індуктивно. Інша обставина – дескрипції також будемо трактувати як відображення відповідно до теоретико-функціонального підходу. Тому для побудови дескрипцій необхідні множини імен базових функцій FN, композицій CN і аргументів композицій Z. Множина інфінітарних стандартних дескрипцій StDes задається індуктивно:
1) StDes(0)=FN,
2) StDes(i+1)={[cna  ]| cnÎCN, ÎZ
]| cnÎCN, ÎZ  StDes(i)}, iÎw.
StDes(i)}, iÎw.
Тоді StDes =  (i) .
(i) .
Наведене визначення використовує довільні відображення імен аргументів у множину раніше побудованих дескрипцій. Це дозволяє задавати дуже загальні, в тому числі й інфінітарні (нескінченні) дескрипції. В програмуванні звичайно обмежуються використанням фінітарных дескрипцій. Для виділення спеціальних класів стандартних дескрипцій введемо відповідну програмну систему Ds(Z)=<FN, CN, Ds>, де DsÍStDes, яку назвемо стандартною дескриптивною системою.
Відношення денотації конкретизується як відображення den: Ds F. В силу індуктивної побудови дескрипцій, досить задати відношення денотації для імен базових функцій та імен композицій: den_fn: FN F та den_cn: CN C. Тоді значення den на dsÎDs задається індуктивно:
|
|
|
1) якщо ds=fn, fnÎFN, то den(ds)=den_fn(fn) ,
2) якщо ds=[cna  ], де
], де  =[ziadsi| ziÎZ, dsiÎDs, iÎI] ,
=[ziadsi| ziÎZ, dsiÎDs, iÎI] ,
то den(ds)=(den_cn(cn))([ziaden(dsi)| iÎI]) .
В цьому випадку систему денотації можна задати як пару BDn=<den_cn, den_fn>. Тому функціонально-номінативна система конкретизується як композиційно-дескриптивна система CDS=<Cm(Z), Ds(Z), BDn>.
Зазначимо, що можна розглядати нестандартні дескриптивні системи, але для того, щоб визначити денотати таких дескрипцій будемо вважати, що є відображення нестандартних дескрипцій у стандартні. Таке відображення будемо називати відображенням аналізу, а дескриптивні системи з заданим відображенням аналізу будемо називати аналізовними дескриптивними системами.
Приведені уточнення програмних понять можна розглядати як перший, найбільш абстрактний оберт спіралі розвитку поняття програми. Подальші конкретизації фактично починають другий оберт спіралі.
3.4 Рівні конкретизації програмних систем
Розгляд рівнів почнемо з конкретизацій поняття даного.
Рівні конкретизації даних. Як відзначалось раніше, треба будувати програмні поняття різних рівнів абстракції. Це стосується і даних. В цьому розділі розглянемо конкретизації даних, які фактично індуковані розвитком поняття даного в програмній пентаді (дане – ім'я – дескрипція). Інші конкретизації розглянемо пізніше. Програмна пентада фактично вказує на три рівні розгляду даних. Перший рівень – абстрактний, коли ніяких властивостей даних не виділяється і дані розглядаються як елементи деякої абстрактної множини. Другий рівень визначається тим, що виділяються деякі специфічні дані. Звичайно такі дані застосовуються як логічні константи, тому назвемо другий рівень булевим рівнем. Нарешті, на третьому рівні є можливість виділяти компоненти даних. З огляду на те, що таке виділення компонент звичайно робиться за допомогою відношень іменування (номінації), назвемо третій рівень номінативним рівнем. Можна також охарактеризувати дані на абстрактному рівні як чорні (непрозорі) скриньки, константи булевого рівня – як білі (прозорі) скриньки, а дані номінативного рівня як сірі (частково прозорі) скриньки.
|
|
|
Три виділених рівні приводять до трьох класів систем даних. Абстрактна система даних (визначена раніше) – ADS =<D>. Система даних булевого рівня в загальному випадку має вигляд BDS =<D, c1, c2, ...> , де c1, c2, ... – деякі виділені елементи (константи) з D. Можна виділити три типи систем: перед-булеву систему <D, true>, булеву систему <D, true, false> та пост-булеву систему <D, c 1, ..., ck>.
|
|
|
На номінативному рівні дані розглядаються як номінативні дані. Клас ND інфінітарних номінативних даних будується індуктивно на основі деяких множин імен V і значень W:
1) ND(0) =W,
2) ND(i+1)=V ND(i), iÎw.
Тоді ND = 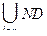 (i) .
(i) .
Таким чином, номінативні дані фактично є ієрархічно побудованими відображеннями, область визначення яких є множина імен, а область значень – номінативні дані.
Система даних номінативного рівня може бути задана як кортеж NDS=<V, W, D>, де DÍND.
Зазначимо, що вищенаведене індуктивне визначення номінативних даних може бути подане у виді наступного рекурсивного визначення:
ND=WÈ(V ND) .
Ці визначення допускають інфінітарні (нескінченні) номінативні дані. У програмуванні клас номінативних даних обмежується класом ієрархічно побудованих скінченних реляційних відображень. Тому виділимо наступні основні класи номінативних даних:
· однозначні номінативні дані (скінченні однозначні відображення), які називаються іменними даними [6],
· багатозначні номінативні дані (скінченні багатозначні реляційні відображення), які називаються просто номінативними даними [5].
|
|
|
Іменні дані дозволяють формалізувати структури даних, які використовуються в програмуванні та характеризуються однозначністю іменування своїх компонент. Це такі структури даних, як записи, масиви, файли, реляції і т.ін. [14]. Номінативні дані дозволяють задавати структури даних, яким властива неоднозначність іменування своїх компонент, такі як множини, мультимножини, сукупності і т.ін. [5]. Наприклад, множину вигляду {s1, s2, ..., sn} можна представити номінативним даним [1 as1, 1 as2, ..., 1 asn] , де 1 обрано в якості стандартного імені елементів множини. Для роботи з такими даними повинні бути введені спеціальні функції, які відображають рівень абстракції даних. Важливо відзначити, що всі такі функції є конкретизаціями абстрактних функцій опрацювання номінативних даних, що істотно зменшує загальне число функцій та спрощує їх дослідження. Зазначимо також, що розгляд даних як спеціальних функцій має давні традиції в програмуванні [22].
Рівні конкретизації функцій. Кожен з рівнів конкретизації даних індукує відповідний рівень розгляду функцій. Абстрактному рівню відповідає абстрактний (нетипізований) клас функцій з D в D. Булевому рівню відповідають такі класи, як часткові характеристичні функції – часткові відображення на D, що приймають лише значення true (перед-булевий рівень), предикати – часткові відображення з D у Bool (булевий рівень), і часткові скінченнозначні відображення з D у {c 1, ..., ck} (пост-булевий рівень). Природно, що найбільш багаті класи функцій можна виділити на номінативному рівні. Фактично такі класи визначають класи функцій над різними структурами даних. В цьому випадку системи функцій конкретизуються як типізовані системи. Серед функцій номінативного рівня основними будуть різні типізовані функції іменування, розіменування, накладення, видалення компонент і та інші [5,14].
Рівні конкретизації композицій. Як і в попередньому випадку, доцільно виділити три рівні композицій. Обмежимося тут розглядом композицій як однозначних відображень. У цьому випадку [5] на абстрактному рівні можна виділити лише одну нетривіальну композицію – послідовне виконання (яку звичайно називають функціональною композицією). Однак цього вже досить щоб почати розвиток теорії категорій, для якої множення функцій є основною досліджуваною операцією [23]. На булевому рівні можна додатково визначити такі композиції, як умовні оператори та цикли різних видів [14]. Тому до булевого рівня можна віднести системи структурного програмування та системи алгоритмічних алгебр [24]. Найбільш багатий композиціями номінативний рівень. Тут визначають наступні основні засоби конструювання програм: різні суперпозиції, розіменування, присвоювання і т.ін. Зазначимо, що введене поняття композиційної системи дозволяє дати опис повних класів композицій на різних рівнях абстракції [5, 14].
Рівні конкретизації дескрипцій. Різноманіття типів даних, функцій та композицій індукує різні типізовані дескриптивні системи. Поряд з стандартними дескрипціями, визначеними раніше, використовуються спеціальні класи дескрипцій, зокрема, якщо композиції є скінченно-арними відображеннями, то імена їх аргументів є натуральними числами та їх впорядкованість можна використовувати для уявлення дескрипцій як послідовностей символів (слів у деякому алфавіті). Звичайно для визначення таких лінійно впорядкованих дескрипцій використовують породжуючі граматики. Ці граматики будуть детальніше розглянуті у наступному розділі.
Інтеграція композиційних і дескриптивних систем номінативного рівня за допомогою відображень денотації дозволяє дати цілісний опис різноманітних мов програмування і баз даних [5,14]. Такі композиційно-дескриптивні системи номінативного рівня будемо називати композиційно-номінативними системами. Ці системи дозволяють також адекватно описувати семантику різних логічних мов [26] і мов специфікацій прикладних областей [27].
Висновки
У розділі розглянуто підходи до формалізації програмних понять. Сформульовано принцип про важливість теоретико-функціональної формалізації поняття програми, при якій програми уточнюються як функції, що розглядаються на різних рівнях абстракції. Введено різні класи функцій. Розглянуто приклад формалізації програми. Введено поняття програмної системи та розглянуто системи різного рівня абстракції. Визначені програмні системи абстрактного, булевого і номінативного рівнів. Програмні системи номінативного рівня і різні їх конкретизації, які називаються композиційно-номінативними системами, є основним формалізмом опису програм. Будучи порівняно простими в побудові, ці системи проте мають велику потужність і дозволяють адекватно уточнити і досліджувати основні властивості програм мов програмування.
Контрольні питання.
1. Розкрийте зміст принципу теоретико-функціональної формалізації поняття програми.
2. Визначте різні класи функцій.
3. Визначте програмні системи різного рівня абстракції.
4. Дайте визначення класу номінативних даних.
4. Синтактика: формальні мови та граматики
4.1 Розвиток понять формальної мови та породжучої граматики
Мови програмування є штучними мовами, спеціально створеними для запису програм. На відміну від природних мов, які є багатоаспектними, неоднозначними, відкритими, відносно швидко змінюються, штучні мови значно бідніші, від них вимагають фіксованості смислу та однозначності.
Синтаксичний аспект є одним з основних аспектів програм. За визначенням, він пов’язаний з формами подання програм в абстракції від інших їх аспектів (дивись малюнок 4.1).

Малюнок 4.1. Абстрагування синтаксичного аспекту від інших аспектів програм
Момент абстракції синтаксичного аспекту від інших аспектів програм є дуже важливим. Це означає, що на першому етапі розвиток синтактики – науки про синтаксичний аспект, визначається головним чином лише відношенням знаків між собою. Разом з тим, не слід абсолютизувати цей момент абстрагування від інших аспектів, бо на другому етапі синтаксис програм має буде узгоджений з іншими їх аспектами.
Наведені твердження сформулюємо як принцип абстрагування та єдності синтаксичного аспекту з іншими аспектами програм.
Уточнення синтаксичного аспекту штучних мов здійснюється на основі поняття формальної мови. Як уже говорилось, це абстрактне поняття, що відображає перші (синтаксичні) характеристики мови. Тому термін «формальний» тлумачиться не тільки як «точно заданий», але і як «абстрактний».
Хоча синтаксичний аспект пов'язаний з багатьма аспектами програм, найтісніший зв'язок є з семантичним аспектом. Зупинимось на цьому зв’язку детальніше. Синтаксичний та семантичний аспекти є подальшою конкретизацією категорій форми та змісту. Тому вивчаючи синтаксис (теорію формальних мов), ми все ж не повинні забувати, що він є похідним від семантичного аспекту, і саме ця обставина і визначає методи експлікації (уточнення) та напрями дослідження синтаксису. Щоб обгрутувати вторинність синтаксичного аспекту, треба розглянути зовнішні аспекти програм, і в першу чергу аспект адекватності програми проблемі. Зрозуміло, що в проблемі нас цікавить не стільки її форма, як її зміст. Це фактично означає, що семантика буде провідним аспектом, а синтаксис – похідним від семантики.
Щоб зафіксувати ці положення у явній формі, сформулюємо їх у вигляді наступного принципу синтактики.
Принцип відокремлення, підпорядкування та єдності синтаксичного та семантичного аспектів: синтаксичний аспект програм є похідним від семантичного, він спочатку вивчається в абстракції від семантичного аспекту, а потім – у єдності з ним.
Наведений принцип фактично вказує лише на відношення синтаксичного аспекту до семантичного, але не дає ніякої характеристики синтаксичному аспекту. Подальший крок конкретизації полягає в тому, що будемо уточнювати синтаксичний аспект за допомогою поняття формальної мови. Елементи, які задаються формальною мовою, будемо називати реченнями. Відзначимо, що тут можна було б вжити замість терміна «речення» терміни «слово», «текст», або інші терміни, що характеризують основні структурні елементи мови; цей вибір залежить від цільової направленості дослідження.
Проаналізуємо тепер, на якому рівні абстракції розглядаються речення. Згідно принципу розвитку від абстрактного до конкретного будемо спочатку речення тлумачити абстрактно як цілісності. Яле цілісністі якого типу – «білої» чи «чорної» скриньки?
Неважко зрозуміти, що елементи формальних мов – речення – слід розглядати як «білі скриньки», тобто їх можна розпізнавати та відрізняти одне від одного.
Обгрунтування вибору такого тлумачення надає принцип відокремлення, підпорядкованості та єдності, який стверджує вторинність синтаксису від семантики, зокрема і те, що синтаксис речення повинен допомогти у встановленні його семантики. А це можливо лише тоді, коли синтаксис є видимим, зрозумілим, прозорим («білим»). Звідси випливає, що мова є множиною (а не абстрактною сукупністю) певних елементів (речень, слів). Саме елементи множини тлумачаться як «білі скриньки». Отже мова розглядається на конкретно-структурованому рівні, який позначимо L.S (Language is a Set).
Принцип теоретико-множинного тлумачення формальної мови: на найвищому рівні абстракції синтаксичний аспект програм подається у вигляді формальної мови, яка тлумачиться як множини речень.
Відзначимо, що цей принцип намічає певну відмінність між семантикою, яка тлумачиться у теоретико-функціональному сенсі, та синтаксисом, для якого більш адекватною є теоретико-множинна формалізація.
Отже, перша над-абстрактна модель мови – це деяка множина L={si | iÎI}. На цьому рівні абстракції нічого, крім теоретико-множинних понять немає, тому немає і власне теорії мов (а є теорія множин). Треба переходити на інший рівень абстракції, який має хоч би деякі специфічні характеристики мов. Цей перехід, як відомо з діалектичної логіки, є перехід від цілого до частин. Тут головне – виділити структуру, що пов’язує ціле з частинами. Щоб це зробити, треба конкретизувати структуру речень.
Оскільки ми абстрагувались від семантики (зокрема від функцій та композицій), то приходимо до висновку, що частини речення не мають ніякої специфіки і тому вони не типізовані. Це означає, що вони належать одному класу і розглядаються як рівноправні. Цей клас називають алфавітом, а його елементи – літерами (символами). Тут спостерігається деяке розходження у вживаній термінології, бо у природних мовах речення складаються із слів, а вже слова – із літер. Але не забуваємо, що відбулось абстрагування від семантики, і що ми розглядаємо формальні мови, тому не слід навантажувати вживані терміни додатковим семантичним смислом.
Яка ж структура пов’язує літери в речення? Оскільки ніякої додаткової інформації не маємо, то згідно принципу розвитку від абстрактного до конкретного, обираємо найбільш просту, абстрактну структуру. Це є структура послідовності.
Абстрагуючись від лінгвістичних конотацій та асоціацій будемо для таких послідовностей вживати терміни «ланцюжок», «слово» або «речення». Відзначимо, що в комп’ютерній термінології часто вживається термін «слово» (word), в лінгвистичній – «речення» (sentence).
Структура послідовності використовується і в природніх мовах, наприклад, друкування тексту на клавіатурі породжує саме послідовність літер. Крім того, усні розмови фактично визначають послідовності фонем.
Дата добавления: 2019-02-13; просмотров: 229; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!