Логический вывод решений с помощью исчисления предикатов
Для получения новых знаний и решений необходимы знания, представленные в виде предикатов в той или иной форме, преобразовать, т.е. доказать некоторые соотношения. Доказательство демонстрирует, что некоторая правильно построенная формула является теоремой на заданном множестве аксиом, т.е. результатом, логически выводимым из аксиом. Однако алгоритмы, принятые в реальной действительности, описывают доказательство в несколько измененном виде [17, 20].
Положим, что  есть множество, состоящее из
есть множество, состоящее из  и пусть формула, для которой требуется выяснить, является ли она теоремой, есть В. В таком случае доказательство показывает справедливость
и пусть формула, для которой требуется выяснить, является ли она теоремой, есть В. В таком случае доказательство показывает справедливость
 (4.38)
(4.38)
при любой ее интерпретации. Можно сказать и по-иному: такое определение эквивалентно тому, что отрицание формулы (4.38), т.е.
 (4.39)
(4.39)
не выполняется (является ложью) при любой интерпретации. Поскольку формула (4.39) является правильно построенной формулой, то ее можно преобразовать в форму клаузального множества, используя для этого описанный выше алгоритм. Пусть это преобразование есть S. Метод резолюции является одним из методов доказательства возможности преобразования, однако его основная идея состоит в проверке того:
- содержит или не содержит S пустое предложение;
- выводится или не выводится пустое предложение из S, если
пустое предложение в S отсутствует.
|
|
|
Любое предложение C1 из которого образуется S, является совокупностью атомарных предикатов или их отрицаний (предикат и его отрицание вместе называются литералом), соединенных символом дизъюнкции, вида:
 (4.40)
(4.40)
Само же S является конъюнктивной формой, т.е. имеет вид:
 (4.41)
(4.41)
Следовательно, условием истинностиSи является условие истинности всех Сі в совокупности, и наоборот, условием ложности S является ложность, по крайней мере, одного Ci. Однако, Ci имеет вид (4.40), и поэтому условием того, что Сi в какой-нибудь интерпретации будет ложным, является то, что множество {Pi1,….Pim} будет пустым. Это видно из следующего. Положим, что это не так, тогда среди всех всевозможных интерпретаций имеется такая, что какой-нибудь из литералов Pi1, ... Рim или все они будут истиной, и поэтому Сi в общем случае не будет ложью. Следовательно, если S содержит пустое предложение, формула (4.39) является ложью, поэтому является ложью и предыдущая формула (4.38), а это показывает, что B выводится из группы предикатов А1, А2,…, Аn т.е. из Σ. Второй шаг (2) -проверка наличия пустого предложения в S означает проверку этого результата после того, как будут выполнены преобразования с помощью правил вывода в S .
|
|
|
Рассмотрим вначале применение метода резолюций для высказываний, так как предикат , который не содержит переменных, совпадает с высказыванием. Положим, что во множестве предложений имеются дополнительные литералы (литералы, которые взаимно отличаются только символом отрицаний - в данном случае z и 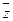 ) вида:
) вида:
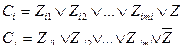 (4.42)
(4.42)
Исключим из этих двух предложений дополнительные литералы и представим оставшуюся часть в дизъюнктивной форме (такое представление называется резольвентой Сi и Cj ) ;
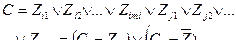 (4.43)
(4.43)
После проведения этой операции можно увидеть, что С является логическим заключением из Ci и Сj. Следовательно, добавление С к множеству S не влияет на вывод об истинности или ложности S . Если выполняется Cj=z, Cj= 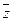 то С пусто. Тот факт, что С является логическим заключением из S и С - пусто, указывает на ложность исходной логической формулы. Рассмотрим пример:
то С пусто. Тот факт, что С является логическим заключением из S и С - пусто, указывает на ложность исходной логической формулы. Рассмотрим пример:
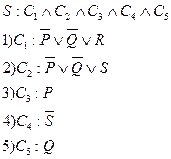
Получение следующего доказательства принципом резолюции:
6)  резольвента (2) и (3);
резольвента (2) и (3);
7) 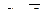 резольвента (4) и (6);
резольвента (4) и (6);
8) 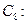 □ резольвента (5) и (7);
□ резольвента (5) и (7);
|
|
|
□ - пустое предложение.
Поскольку в логике предикатов внутри предикатов содержатся переменные, то алгоритм доказательства несколько усложняется. В этом случае перед тем, как применять описанный алгоритм, будет предварительно проведена некоторая подстановка в переменные и введено понятие унификации с помощью этой подстановки. Унификацию проиллюстрируем простым примером. Рассмотрим два предиката Z(x) и Z(α). Положим, что х – переменная, а – константа. В этих предикатах предикатные символы одинаковы, чего нельзя сказать о самих предикатах. Тем не менее подстановкой α в x эти предикаты можно сделать одинаковыми (эта подстановка называется унификацией). Целью унификации является обеспечение возможности применения описанного выше алгоритма доказательства для предикатов. Обобщив пример формулы (4.42) для предикатов, получим:
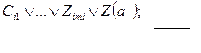
В данном случае 
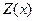 и
и 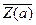 не находятся в дополнительных отношениях. При подстановке
не находятся в дополнительных отношениях. При подстановке  вместо
вместо 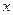 будет получено соответственно
будет получено соответственно 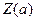 и , и эти предикаты находятся в дополнительных отношениях. Однако операция подстановки имеет ограничения.
и , и эти предикаты находятся в дополнительных отношениях. Однако операция подстановки имеет ограничения.
Подстановку t в x будем обозначать {t/x}. Поскольку в одну формулу может входить более одной переменной и можно произвести более одной подстановки, то эти подстановки записываются в виде множества упорядоченных пар:
|
|
|
{t1/x1,t2/x2,…,tn/xn} (4.45)
Условия, допускающие подстановку:
- 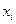 является переменной, a t1-термом (константа, пере-
является переменной, a t1-термом (константа, пере-
менная, символ функции), отличным от x 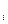 ;
;
- для любой пары элементов из группы подстановок, например
 и
и  в правых частях символов "//", не содержится оди-
в правых частях символов "//", не содержится оди-
наковыx переменных.
Обозначим группу подстановок { 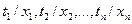
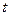 } через Ө. Когда для некоторого представления Z применяется подстановка содержащихся в ней переменных {
} через Ө. Когда для некоторого представления Z применяется подстановка содержащихся в ней переменных {  }, то результат подстановки, при котором переменные заменяются соответствующими им переменными t1,t2...tn принято обозначать ΖӨ. Если имеется группа различных выражений предиката Ζ, т.е. {Ζ1, Ζ2,…,Ζm}, то подстановка Ө (положим, что она существует) такая, что в результате все эти выражения становятся одинаковыми, т.е. Ζ1Ө=Ζ2Ө=…=ΖmӨ называется унификатором для {Ζ1,Z2…Zm}. Если подобная подстановка Ө существует, то говорят, что множество выражений {Z1, Z2 ...,Zm} унифицируемо. В предыдущем примере множество {Z(х), Z(а)} унифицируемо, при этом унификатором является подстановка {a/x} .
}, то результат подстановки, при котором переменные заменяются соответствующими им переменными t1,t2...tn принято обозначать ΖӨ. Если имеется группа различных выражений предиката Ζ, т.е. {Ζ1, Ζ2,…,Ζm}, то подстановка Ө (положим, что она существует) такая, что в результате все эти выражения становятся одинаковыми, т.е. Ζ1Ө=Ζ2Ө=…=ΖmӨ называется унификатором для {Ζ1,Z2…Zm}. Если подобная подстановка Ө существует, то говорят, что множество выражений {Z1, Z2 ...,Zm} унифицируемо. В предыдущем примере множество {Z(х), Z(а)} унифицируемо, при этом унификатором является подстановка {a/x} .
Для одной группы выражений унификатор не обязательно единственный. Для группы выражений{Z(х,у), Z(z, f(x))} подстановка Ө={x/z, f(x)/y} является унификатором, но является также унификатором и подстановка Ө={a/x, a/z, f(a)/y}. Здесь, как и ранее, является константой, а х - переменной. В таких случаях возникает естественная проблема, какую подстановку лучше всего выбрать в качестве унификатора.
Операцию подстановки можно провести не за один paз, а разделить ее на несколько этапов. Ее можно также разделить по группам переменных, проведя, например, подстановку в виде:
{ 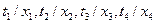 }
}
сначала для { 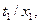
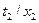 }, затем для {
}, затем для { 
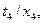 }. Допустимо также подстановку вида a / x разбить на две подстановки u / x и а/ u (принимается, что x и u переменные). Результат последовательного выполнения двух подстановок Ө и λ также является подстановкой. Такая подстановка является сложной и обозначается в виде
}. Допустимо также подстановку вида a / x разбить на две подстановки u / x и а/ u (принимается, что x и u переменные). Результат последовательного выполнения двух подстановок Ө и λ также является подстановкой. Такая подстановка является сложной и обозначается в виде 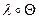 .
.
Если существует несколько унификаторов, то среди них найдется такая подстановка σ, что все другие унификаторы являются подстановками, выражаемыми в виде σ о λ, как сложная форма, включающая эту подстановку. В результате подстановки переменные будут замещены константами и описательная мощность формулы будет ограничена. Чтобы унифицировать два различных выражения предиката, необходима такая подстановка, при которой выражение с большей описательной мощностью согласуется с выражением, имеющим малую описательную мощность. Однако совсем нет необходимости ограничивать описательную мощность всеми другими подстановками. Подстановка является унификатором с самыми минимальными ограничениями подобного вида. В этом смысле ее принято называть "наиболее общим унификатором" (НОУ).
Алгоритм нахождения НОУ сравнительно прост. Он состоит в том, что сначала упорядочиваются выражения, которые подлежат унификации, (каждое выражение будет упорядочено в алфавитном или символьном порядке), среди них отыскивается такое, в котором соответствующие термы не совпадают между собой. Пусть при осмотре последовательно всех выражений в порядке слева направо несовпадающими термами явились x , t . Например, получено выражение {Ζ (a , t , f ( z )), Z( a , x , z )}. В этом случае, если:
1) х является переменной;
2) x не содержится в t,
к группе подстановок добавляется {t / x}.
Если повторением этих операций будет обозначено совпадение всех изначально заданных выражений, то они являются унифицируемыми, а группа полученных подстановок является НОУ.
В приведенном примере третий терм есть в одном случае z, а в другом f ( z ), условие I выполняется, однако условие II нарушается и поэтому подстановка является недопустимой. Если же в группе предикатных выражений остается хотя бы одно такое, для которого никакими подстановками нельзя получить совпадение с другими выражениями, такая группа выражений является неунифицируемой. Рассмотрим пример на нахождение НОУ:
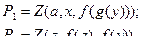 (4.46)
(4.46)
I. Самые первые несовпадающие члены при рассмотрении слева направо: {a , z }→ подстановка a / z . Из этого получается
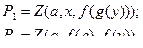
2. Самые первые несовпадающие члены при рассмотрении слева направо: {x , f ( a )} →подстановка { f ( a )/ x}.
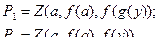
Подстановка: {а/ z , f ( a )/ x}.
3. Добавляется {g ( y )/ v}. Теперь оба выражения совпадают, поэтому унификация заканчивается НОУ: {a / z , f ( a )/ x , g ( y )/ v}.
Рассмотрим алгоритм доказательства методом резолюции в логике предикатов. Различие по сравнению исчисления высказываний в том, что здесь создаются дополнительные литералы с помощью операции подстановки. Применение метода резолюции рассмотрим для доказательства секвенций.
Допустим, что знания представлены логическими формулами A 1 ,…, Am , a последовательность этих формул обозначена буквой Г. Чтобы проверить, можно ли на основе этих знаний вывести новый факт В, представленный формулой, следует проверить возможность существования доказательства Г→В. Если доказательство существует, то говорят «выражение Г→В доказуемо» и записывают ├Г→В. В данном случае говорят также, что В доказуемо на основании Г и записывают Г├ В. Если Г - пустая последовательность (m = 0), то записывают ├В и говорят, что В доказуемо. Запись ├ Г→ означает, что Г - противоречивая последовательность, во всех других случаях говорят, что Г - непротиворечивая последовательность. Следовательно, если Г - противоречивая последовательность, то с помощью правила выводя →Т для любого С можно получить Г├ С. И наоборот, если все формулы доказуемы на основании Г, то можно записать Г├С, кроме того, поскольку Г ├ С, получаем доказательство Г→. Следовательно, доказуемость всех формул на основании Г можно трактовать как определение противоречивости. Другими словами, из противоречивых знаний можно вывести любой факт.
Рассмотрим теперь интерпретацию секвенции, которую будем рассматривать как формулу. Допустим, что существует некоторая секвенция S, и попытаемся определить ее интерпретацию J. Обозначим константы входящие в S, через C1 C2,.., Сk , функциональные символы – через f1,f 2 ,…, fm, а предикатные символы - через P1,P2,…,Pn.Для однозначного определения необходимо рассмотреть множество всех индивидумов, которые являются структурными элементами описываемой в данный момент предметной области. Это множество назовем универсумом U. U может быть любым не пустым множеством (например, множество технологических операций).Для определения J необходимо определить, какой элемент идентифицирует каждая константа Ci (1≤ i ≤ k ). Функциональный символ fi (1≤ i ≤ m ) интерпретируется как функция в предметной области. Например, fi• - функциональный j-местный символ. Тогда, если заданы j элементов a 1 ,а2,..,, а j множества U, то ее значение интерпретируется как функция, принимающая некоторое значение b в множестве U. Таких функций обычно много, но для определения J необходимо знать, какой функции соответствует каждое fi. И наконец, предикатный символ Pi (1≤ i ≤ n ) интерпретируется как отношение в предметной области U. Допустим теперь, что Pj- j-местный предикатный символ, тогда при установлении отношения R ( a 1 , a 2 ,..., aj ) между j элементами а1, а2,..., а j; множества U или неустановлении его, он интерпретируется как такое отношение. При этом, когда отношение установлено, предикатный символ называется истиной, в противном случае - ложью. Так как подобных отношений также множество, то для определения J устанавливается соответствие отношений для каждого Pi. Благодаря этому можно найти однозначную интерпретацию J секвенции S. Если интерпретация J определена, то очевидно, что все термы, не имеющие переменных в секвенции S, можно интерпретировать как элементы множества U. Аналогично атомарные (элементарные) высказывания, не имеющие переменных, определяются истиной или ложью в интерпретации J. Однако, при наличии переменных (поскольку, когда переменная принимает значение элемента множества U, определяется истина или ложь) любое атомарное высказывание определяется истиной или ложью и происходит замена на интерпретацию логического символа. Интерпретация логического символа не зависит от частной интерпретации J. Будем считать, что истина или ложь относительно логической связки аналогичны алгебре высказываний. Тогда если в части (  х)(...x…) переменной x соответствует некоторый элемент множества U (предметной области) и если формулу в скобках можно интерпретировать как истину, то и эта часть интерпретируется как истина. В любом другом случаe она интерпретируется как ложь. Рассмотрим применение свободных переменных. Обозначим свободные переменные секвенции S через x1,...,xm, тогда если (
х)(...x…) переменной x соответствует некоторый элемент множества U (предметной области) и если формулу в скобках можно интерпретировать как истину, то и эта часть интерпретируется как истина. В любом другом случаe она интерпретируется как ложь. Рассмотрим применение свободных переменных. Обозначим свободные переменные секвенции S через x1,...,xm, тогда если (  x1)...( xm)S в интерпретации J является истиной, то S называется достоверной в интерпретации J.
x1)...( xm)S в интерпретации J является истиной, то S называется достоверной в интерпретации J.
Если 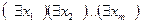 S - истина в интерпретации J, то S называется выполнимой в интерпретации J. Разумеется, если S достоверна в интерпретации J, то она выполнима в этой интерпретации. Кроме того, даже когда S - истинная секвенция, не содержащая свободных переменных, то ее можно назвать достоверной. Если S достоверна во всех интерпретациях, то она называется общезначимой. Если секвенция S доказуема, то она достоверна; верно и обратное: если секвенция S достоверна, то она доказуема. Этот факт означает, что для доказательства в системе выводов логики предикатов правильности всех секвенций не требуется других правил вывода (теорема Геделя о полноте).
S - истина в интерпретации J, то S называется выполнимой в интерпретации J. Разумеется, если S достоверна в интерпретации J, то она выполнима в этой интерпретации. Кроме того, даже когда S - истинная секвенция, не содержащая свободных переменных, то ее можно назвать достоверной. Если S достоверна во всех интерпретациях, то она называется общезначимой. Если секвенция S доказуема, то она достоверна; верно и обратное: если секвенция S достоверна, то она доказуема. Этот факт означает, что для доказательства в системе выводов логики предикатов правильности всех секвенций не требуется других правил вывода (теорема Геделя о полноте).
Таким образом, если в логике предикатов существует последовательность формул Г, то дли любой формулы, не содержащей свободных переменных, казалось бы, должна быть справедлива одна из записей – Г├ A или Г├ 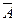 . К сожалению, это не так. Eли Г содержит аксиомы математической логики и является непротиворечивой, то существует формула A 1, не содержащая свободных переменных, такая, что оба приведенных выше выражения не выводимы (теорема о неполноте Гегеля-Росса). Теорема о неполноте означает возможность ситуаций, когда нет смысла определять истину или ложь в программе вывода, составленной на основании исчисления предикатов. Допустим, что в программе вывода доказывается формула A1 , такая, Г├А и Г├ не выполняются. В логике высказываний доказуемость или недоказуемость можно определить за конечное число шагов, но в логике предикатов такой метод не годится. Тем не менее это не является существенным недостатком с точки зрении представления знаний и получения выводов. И основным методом получения выводов в программах, основанных на логике предикатов, является метод резолюции. Допустим, имеются формулы А1, A 2 ,…, Am. (отражающие, например, технологические операции) и формула В1, для которых рассмотрим доказательство секвенций А1,…, Am → B. Доказательство основано на достоверности, выражения
. К сожалению, это не так. Eли Г содержит аксиомы математической логики и является непротиворечивой, то существует формула A 1, не содержащая свободных переменных, такая, что оба приведенных выше выражения не выводимы (теорема о неполноте Гегеля-Росса). Теорема о неполноте означает возможность ситуаций, когда нет смысла определять истину или ложь в программе вывода, составленной на основании исчисления предикатов. Допустим, что в программе вывода доказывается формула A1 , такая, Г├А и Г├ не выполняются. В логике высказываний доказуемость или недоказуемость можно определить за конечное число шагов, но в логике предикатов такой метод не годится. Тем не менее это не является существенным недостатком с точки зрении представления знаний и получения выводов. И основным методом получения выводов в программах, основанных на логике предикатов, является метод резолюции. Допустим, имеются формулы А1, A 2 ,…, Am. (отражающие, например, технологические операции) и формула В1, для которых рассмотрим доказательство секвенций А1,…, Am → B. Доказательство основано на достоверности, выражения 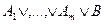 которая вытекает из теоремы о полноте. Однако выполнимость формулы Е не означает не выполнимость
которая вытекает из теоремы о полноте. Однако выполнимость формулы Е не означает не выполнимость 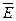 . Другими словами, она эквивалентна невыполнимости. Это следует из определения достоверности и выполнимости и из выражений
. Другими словами, она эквивалентна невыполнимости. Это следует из определения достоверности и выполнимости и из выражений
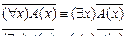 (4.47)
(4.47)
Где C ~ D означает, что С эквивалентно D. Поэтому можно считать, что ├С→ D и ├ D → C. Чтобы показать, что приведенные формулы являются достоверными, следует доказать с помощью, например, правил де Моргана невыполнимость формулы  . Для этого данную формулу приведем к сколемовской конъюнктивной форме ( клаузальной форме). Пусть
. Для этого данную формулу приведем к сколемовской конъюнктивной форме ( клаузальной форме). Пусть  обозначение литералов. Формула, в которой символом V объединены более одного литерала, как было ранее сказано, называется предложением (ctause),например
обозначение литералов. Формула, в которой символом V объединены более одного литерала, как было ранее сказано, называется предложением (ctause),например 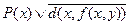 . Далее, если C 1 ,…, Ck – предложения, a x1, x2,…,xm - различные переменные, содержащиеся в
. Далее, если C 1 ,…, Ck – предложения, a x1, x2,…,xm - различные переменные, содержащиеся в  , то формула вида
, то формула вида  называется клаузалъной формой. При это
называется клаузалъной формой. При это 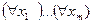 называется префиксом, а логическое выражение в скобках - матрицей. И так, все формулы A можно преобразовать в клаузальные выражения A, причем если A выполнимо, то выполнимо и A'. Следовательно, чтобы показать невыполнимость A следует показать невыполнимость A '.
называется префиксом, а логическое выражение в скобках - матрицей. И так, все формулы A можно преобразовать в клаузальные выражения A, причем если A выполнимо, то выполнимо и A'. Следовательно, чтобы показать невыполнимость A следует показать невыполнимость A '.
Запишем вначале алгоритм преобразования в клаузальную форму. 1. Преобразование A к виду
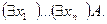
2. Переименуем переменные. Изменим связанные переменные при каждом символе или в формуле так, чтобы было соответствие различных переменных.
3. Удалим символы импликации →:
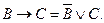
4.Переместим символ "-" внутрь 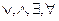 по формулам
по формулам

5. Удалим . Крайний слева член в части формулы вида 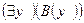 заменяется на
заменяется на 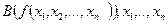 - это свободные переменные, появляющиеся в выражении
- это свободные переменные, появляющиеся в выражении 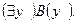 Но для всей формулы это - переменные, ограниченные
Но для всей формулы это - переменные, ограниченные 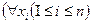 в левой части (
в левой части ( 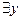 )B(y). f - вновь выбранный функциональный n-местный символ, который до сих пор не употреблялся. Кроме того, при n = 0 он заменяется на вновь выбранную константу, которая до сих пор не употреблялась.
)B(y). f - вновь выбранный функциональный n-местный символ, который до сих пор не употреблялся. Кроме того, при n = 0 он заменяется на вновь выбранную константу, которая до сих пор не употреблялась. 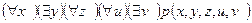 принимает вид
принимает вид 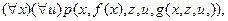 где p и g - сколемовские функции. Аналогично
где p и g - сколемовские функции. Аналогично 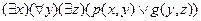 принимает вид
принимает вид 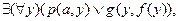 где p,g - предикаты; а - сколемовская константа, f - сколемовская функция.
где p,g - предикаты; а - сколемовская константа, f - сколемовская функция.
6.Переместим вперед (часть 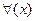 перемещается в префиксную часть формулы) .
перемещается в префиксную часть формулы) .
7. Переместим символ  относительно символа
относительно символа 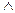 . Следующая перестановка повторяется по мере возможности:
. Следующая перестановка повторяется по мере возможности:
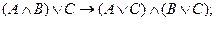 (4.48)
(4.48)
8. Минимизируем. Минимизация осуществляется с сохранением свойств выполнимости:
(1) удаляются литералы, неоднократно появляющиеся в предложе-
нии : 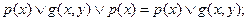
(2) удаляются предложения, литералы которых взаимно отрицают
друг друга: 
Рассмотрим пример на применение п.1 - 7:
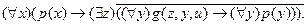
1. 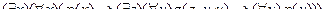
2. 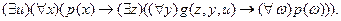
3. 
4. 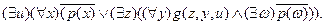
5. a - сколемовская константа ; f , q - сколемовские функции:
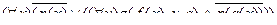

6. 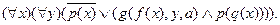
7. 
Для того чтобы показать, что в клаузальной форме сохраняется 'свойство выполнимости, следует показать, что при соответствующих преобразованиях согласно п.1 - 8 сохраняется свойство невыполнимости. Таким образом, принцип резолюции заключается в получении вывода по фразам матрицы клаузальной формы формулы с целью доказательство его невыполнимости.
Следующим разделом общего алгоритма является алгоритм унификации. Перед его применением дадим дополнительные сведения (по сравнению с ранее рассмотренными вопросами унификации) и введем некоторые обозначения. Допустим, существуют две атомарные формулы, имеющие одинаковые предикатные символы, но не имеющие общих переменных, например 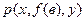 и
и 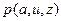 . Если вместо х подставить а, вместо
. Если вместо х подставить а, вместо 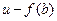 , вместо y - z, то обе формулы станут оданадавыми. A именно
, вместо y - z, то обе формулы станут оданадавыми. A именно 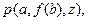 т. е. они унифицируемы. Уточним запись подстановки с указанием стрелки {
т. е. они унифицируемы. Уточним запись подстановки с указанием стрелки { 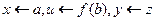 } . Далее подстановки будем обозначать строчными буквами греческого алфавита
} . Далее подстановки будем обозначать строчными буквами греческого алфавита  и т.д., а факт подстановки, например, в некоторое представление
и т.д., а факт подстановки, например, в некоторое представление 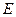 будем записывать как
будем записывать как 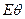 Если
Если 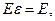 подстановка не содержит элементов. Если существует некоторый унификатор
подстановка не содержит элементов. Если существует некоторый унификатор 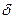 формул
формул 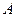 и
и  , тогда если существует
, тогда если существует 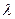 такой, что для произвольного унификатора
такой, что для произвольного унификатора 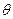 справедливо
справедливо 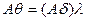 и
и 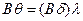 , то называется наиболее общим унификатором (НОУ). После унификации изменим последовательность литералов предложения и, собрав впереди отрицательные литералы, получим следующую фразу:
, то называется наиболее общим унификатором (НОУ). После унификации изменим последовательность литералов предложения и, собрав впереди отрицательные литералы, получим следующую фразу:  данном случае это предложение представлено как секвенция
данном случае это предложение представлено как секвенция 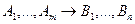 . Различие между обычной секвенцией и предложение состоит в том, что если в секвенции
. Различие между обычной секвенцией и предложение состоит в том, что если в секвенции 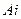 и
и  являются обычными формулами, то в предложении это - атомы (атомарные формулы). Предложение, в котором m = 0, n = 0, называется пустым. Так же как и в случае секвенции, атомарные формулы будем обозначать латинскими буквами
являются обычными формулами, то в предложении это - атомы (атомарные формулы). Предложение, в котором m = 0, n = 0, называется пустым. Так же как и в случае секвенции, атомарные формулы будем обозначать латинскими буквами 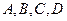 и т.д. или этими же буквами с индексами, а прописными греческими буквами - конечный или пустой ряд атомов. Допустим, что в матрице клаузального выражения существуют два предложения:;
и т.д. или этими же буквами с индексами, а прописными греческими буквами - конечный или пустой ряд атомов. Допустим, что в матрице клаузального выражения существуют два предложения:;
∆  (4.49)
(4.49)
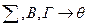 (4.49а)
(4.49а)
где А и В - атомарные формулы, имеющие одинаковые предикатные символы. Если при этом оба предложения имеют общие переменные, то, выполнив подстановку в одну из них, изменим ее так, чтобы они не имели общих переменных. Такая подстановка называется переименованием. Причина переименования заключается в следующем: пусть имеются два предложения С и D,Переименование в данном случае соответствует преобразованию одной клаузальной формы, например  , другую клаузальную форму, например
, другую клаузальную форму, например 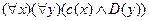 .Введем теперь переименовываемую подстановку и измени переменную в предложении
.Введем теперь переименовываемую подстановку и измени переменную в предложении  . Положим, что А и В унифицируеми их НОУ есть . Правило вывода, с помощью которого из (4.49) и (4.49а) выводиться следующие предложение (4.50)называется резолюцией (разрешением):∆
. Положим, что А и В унифицируеми их НОУ есть . Правило вывода, с помощью которого из (4.49) и (4.49а) выводиться следующие предложение (4.50)называется резолюцией (разрешением):∆ 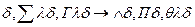
При этом само предложение (4.50), как уже было сказано, называется резольвентой. Если вместо переименования переменной в (4.49) выполнить переименование в (4.49а), резольвента будет иметь следующий вид:
∆ 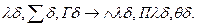 (4.51)
(4.51)
где - НОУ атомов 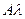 и .
и .
Например, из предложения  и
и 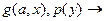
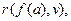 с помощью резолюции получаем следующую резольвенту:
с помощью резолюции получаем следующую резольвенту:
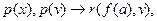
где переименовывающей подстановкой было { 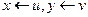 } , а НОУ {
} , а НОУ {  }Если (4.49) и (4.49а) достоверны, то достоверна и (4.51). Важным в резолюции является отсутствие общих переменных в предпосылках. Поскольку резолюция предполагает исключение по одному соответствующему из двух предложений, являющихся предпосылками, то назовем ее бинарной резолюцией. Однако одной лишь бинарной резолюции, как правила вывода недостаточно, необходимо еще одно правило, называемое факторизацией. Допустим, что в предложениях
}Если (4.49) и (4.49а) достоверны, то достоверна и (4.51). Важным в резолюции является отсутствие общих переменных в предпосылках. Поскольку резолюция предполагает исключение по одному соответствующему из двух предложений, являющихся предпосылками, то назовем ее бинарной резолюцией. Однако одной лишь бинарной резолюции, как правила вывода недостаточно, необходимо еще одно правило, называемое факторизацией. Допустим, что в предложениях
∆ 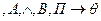
Г  ∆ A , B , П (4.52)
∆ A , B , П (4.52)
атомы A и В унифицируемы и их НОУ есть . Тогда
∆ 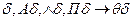
и (4.53)
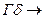 ∆
∆ 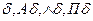
называются факторами предложений. Правило, с помощью которого из фразы С выводится фактор С, называется факторизацией. Например, фактор резольвенты 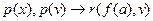 есть
есть  Допустим теперь, что задано множество предложений М, это множество является опровержимым, если существует ряд предложений
Допустим теперь, что задано множество предложений М, это множество является опровержимым, если существует ряд предложений 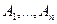 такой, что
такой, что 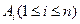 является элементом М или фактором Ai (j < i) или резольвентой
является элементом М или фактором Ai (j < i) или резольвентой  и
и 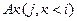 , а А является пустым предложением→.При этом данный ряд называется опровержением множества М. Рассмотрим пример. Множество М состоит из следующих предложений:
, а А является пустым предложением→.При этом данный ряд называется опровержением множества М. Рассмотрим пример. Множество М состоит из следующих предложений:
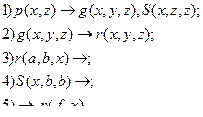
Опровержение М:
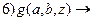 (резольвента 2 и З);
(резольвента 2 и З);
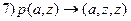 (резольвента 1и 6);
(резольвента 1и 6);
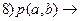 (резольвента 4и7);
(резольвента 4и7);
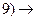 (резольвента 5и8).
(резольвента 5и8).
Итак, если на основании следующей теоремы секвенция является невыполнимой, это обстоятельство можно доказать в системе резолюций.
Теорема. Допустим, М - это множество предложений матрицы в секвенции S клаузальной (или логической) формы, тогда невыполнимость S эквивалентна опровержимости М. Другими словами, чтобы показать доказуемость некоторой секвенции в системе резолюций, отрицание этой секвенции преобразуется в клаузальную форму, и по его предложениям выполняются выводы.
Наиболее важной проблемой при программировании процесса опровержения является выбор двух предложений - посылок, пригодных для применения резолюции, или их факторов. Изложим основные принципы двух методов решения этой проблемы. Cтратегия приоритета простейшего предложения и множество поддержки. Стратегия приоритета простейшего предложения - это способ приоритетного выбора предложения, состоящего из одного литерала (простейшего предложения), в качестве посылки для резолюции. Он основан на получении пустого предложения с помощью бинарной резолюции двух простейших предложений вида 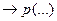 и
и 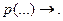 Концепция множества поддержки основана на идее максимального исключения лишних выводов, поскольку среди элементов опровержимого множества предложений М не исключена возможность существования предложений, не имеющих отношения к опровержению, и вывод следует выполнять только на основе предложений, имеющих прямое отношение к опровержению. Для пояснения этого момента разделим множество предложений M на два подмножества Т и М-Т ж рассмотрим их выполнимость. Под выполнимостью множества предложений будем понимать выполнимость формулы, в которой все предложения, принадлежащие множеству, соединены связкой , а все свободные переменные ограничению квантором . Допустим, что выполнимость М-Т очевидна, даже если неизвестна невыполнимость М. Тогда, выполняя вывод так, чтобы хотя бы одна из посылок, необходимых для применения резолюции, была предложением, принадлежащим подмножеству T, либо его фактором, либо резольвентой, можно сделать опровержение М, если оно является невыполнимым. Такое опровержение называется опровержением М, имеющим множество поддержки Т. В системе резолюций, так же как и в естественной дедуктивной системе, можно при наличии ряда формул Г обрабатывать вопросы ряда формул B. Другими словами, если Г→В доказуемо, то ответом на вопрос является "да", а если доказуемо
Концепция множества поддержки основана на идее максимального исключения лишних выводов, поскольку среди элементов опровержимого множества предложений М не исключена возможность существования предложений, не имеющих отношения к опровержению, и вывод следует выполнять только на основе предложений, имеющих прямое отношение к опровержению. Для пояснения этого момента разделим множество предложений M на два подмножества Т и М-Т ж рассмотрим их выполнимость. Под выполнимостью множества предложений будем понимать выполнимость формулы, в которой все предложения, принадлежащие множеству, соединены связкой , а все свободные переменные ограничению квантором . Допустим, что выполнимость М-Т очевидна, даже если неизвестна невыполнимость М. Тогда, выполняя вывод так, чтобы хотя бы одна из посылок, необходимых для применения резолюции, была предложением, принадлежащим подмножеству T, либо его фактором, либо резольвентой, можно сделать опровержение М, если оно является невыполнимым. Такое опровержение называется опровержением М, имеющим множество поддержки Т. В системе резолюций, так же как и в естественной дедуктивной системе, можно при наличии ряда формул Г обрабатывать вопросы ряда формул B. Другими словами, если Г→В доказуемо, то ответом на вопрос является "да", а если доказуемо 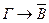 , то ответом служит "нет". Стратегия приоритета простейшего предложения является самой эффективной среди стратегий общего назначения, но если простейшее предложение нельзя выбрать в качестве предпосылки, то необходимо, чтобы предпосылкой было предложение с двумя и более литералами. Однако возникает вопрос, существует ли класс множеств предложений, опровержимых просто путем выбора простейшего предложения хотя бы в качестве одной предпосылки? Ответ на этот вопрос утвердительный. Такие множества называются хорновскими, а их элементы - хорновскими предложениями. Как было показано ранее, хорновское предложение содержит всего один правильный литерал. Другими словами, в таком предложении справа от стрелки либо может быть одна атомарная формула, либо ее нет. Резолюция, в которой хотя бы одна из предпосылок является простейшим предложением, называется простейшей резолюцией. Невыполнимость хорновского множества не только означает, что его опровержимость можно доказать с помощью простейшей резолюции, но и показывает, что в процессе опровержения не требуется осуществлять факторизацию. Если типы предложений ограничить хорновскими, опровержение невыполнимого множества можно сделать очень эффективным. Однако даже хорновские множества нельзя назвать полными в смысле теоремы Геделя о полноте, т.е. существует такое множество хорновских предложений, которое нельзя опровергнуть, как нельзя опровергнуть и его отрицание. Однако благодаря простым механизмам вывода хорновское множество было предложено в качестве языка программирования. В результате был создан язык ПРОЛОГ.
, то ответом служит "нет". Стратегия приоритета простейшего предложения является самой эффективной среди стратегий общего назначения, но если простейшее предложение нельзя выбрать в качестве предпосылки, то необходимо, чтобы предпосылкой было предложение с двумя и более литералами. Однако возникает вопрос, существует ли класс множеств предложений, опровержимых просто путем выбора простейшего предложения хотя бы в качестве одной предпосылки? Ответ на этот вопрос утвердительный. Такие множества называются хорновскими, а их элементы - хорновскими предложениями. Как было показано ранее, хорновское предложение содержит всего один правильный литерал. Другими словами, в таком предложении справа от стрелки либо может быть одна атомарная формула, либо ее нет. Резолюция, в которой хотя бы одна из предпосылок является простейшим предложением, называется простейшей резолюцией. Невыполнимость хорновского множества не только означает, что его опровержимость можно доказать с помощью простейшей резолюции, но и показывает, что в процессе опровержения не требуется осуществлять факторизацию. Если типы предложений ограничить хорновскими, опровержение невыполнимого множества можно сделать очень эффективным. Однако даже хорновские множества нельзя назвать полными в смысле теоремы Геделя о полноте, т.е. существует такое множество хорновских предложений, которое нельзя опровергнуть, как нельзя опровергнуть и его отрицание. Однако благодаря простым механизмам вывода хорновское множество было предложено в качестве языка программирования. В результате был создан язык ПРОЛОГ.
КОМБИНАТОРНЫЙ АНАЛИЗ
При построении экспертных систем, систем автоматического вывода имеется различное число вариантов научных решений конкретной проблемы, ближе или дальше отстоящих от оптимальною решения. Кроме того, целый ряд решений носит комбинаторно - логический характер. В общем случае при анализе модели предметной области производятся oпeрации над дискретными множествами, которые изменяют либо структуру множеств, либо их состав. Простейшими операциями первого типа являются обычные перестановки элементов, второго - выделение подмножеств элементов или, как принято говорить, их выборки. Операции применяют в задачах чаще всего неоднократно и в самых разнообразных комбинациях, при наложении различных условий. Это создает практически неисчерпаемые возможности дискретных построений, которые нередко называют конфигурациями (иногда комбинаторными конфигурациями) [22, 23].
В зависимости от характера предмета исследования и вводимых операций определяется совокупность задач, решаемых средствами комбинаторного анализа. Самыми первыми были задачи о числе дискретных построений, удовлетворяющих поставленным условиям. Метода их решения получили название перечислительных. Кроме задач перечислительного типа в комбинаторном анализа рассматриваются вопросы существования или несуществования конфигурации, удовлетворяющей заданным условиям, отыскиваются алгоритмы построения конфигураций, а также выделения из заданной совокупности конфигураций, или алгоритмов таких, которые обладали бы избранными свойствами в наибольшей или наименьшей степени (задачи и методы оптимизации) [24].
Дата добавления: 2018-11-24; просмотров: 450; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!