Блочное кодирование – разделение цифрового потока на блоки длиной в k бит и преобразование их в блоки большей протяженности длиной в n бит, но обладающие лучшими свойствами.
Федеральное агентство по образованию
Федеральное государственное бюджетное образовательное учреждение
Башкирский государственный университет
Физико-технический институт
Кафедра статистической радиофизики и связи
Курсовая работа
По теории электрической связи
Помехоустойчивое канальное кодирование дискретных сообщений.
Выполнил студент 3 курса
группы 3 ФТОС-2
Мусагитов Рушан Фанисович
Проверил доктор физ.-мат. наук,
проф. Гоц С.С. __________
Уфа-2013
Содержание
1.Введение
2.Теоретическая часть
3.Задание
Заключение
Список литературы
кодирование помехоустойчивое сообщение
1. ВВЕДЕНИЕ
Электросвязь - это совокупность человеческой деятельности, главным образом технической, связанной с передачей сообщений на расстояние с помощью электрических сигналов. Непрерывное развитие народного хозяйства и культуры приводит к интенсивному росту передаваемой информации, поэтому значение электросвязи в современной технике и в современной жизни огромно.
В настоящее время системы передачи дискретной - цифровой информации играют огромнейшую роль в современной жизни и являются основой современной техники связи.
Вопросам систем передачи дискретных сообщений и предназначено данное учебное пособие, оно состоит из семи глав, где рассматриваются основные определения систем передачи дискретных сообщений, первичное кодирование сообщений, помехоустойчивое кодирование, адаптивная коррекция систем передачи. Методы и устройства синхронизации в системах передачи дискретных сообщений, устройства преобразования сигналов, оконечное оборудование систем передачи дискретных сообщений.
|
|
|
Раскрываются вопросы сетей передачи дискретных сообщений: телеграфной, факсимильной и сетей передачи данных.
2. Теоретическая часть
Помехоустойчивое кодирование
Для помехоустойчивых блочных неравномерных кодов Nп>М. Это значит, что для передачи знаков сообщения используют лишь часть возможных последовательностей, составленных из m-ичных символов, (часть пространства «-последовательностей). Последовательности, используемые при кодировании, называются разрешенными кодовыми комбинациями, а все другие «-последовательности — запрещенными. На вход канала поступают только разрешенные комбинации. Если при передаче кодовой комбинации bi помехи не вызовут ошибок, то на выходе канала возникает та же разрешенная комбинация. Если же один или несколько символов принимается ошибочно, то на выходе канала может возникнуть одна из-за запрещенных комбинаций.
|
|
|
Таким образом, если комбинация на выходе канала оказывается запрещенной, то это указывает на то, что при передаче возникла ошибка. Отсюда видно, что избыточный код позволяет обнаружить, в каких принятых кодовых комбинациях имеются ошибочные символы. Безусловно, не все ошибки могут быть обнаружены. Существует вероятность того, что, несмотря на возникшие ошибки, принятая последовательность кодовых символов окажется разрешенной комбинацией (но не той, которая передавалась). Однако при разумном выборе кода вероятность необнаруженной ошибки (т. е. ошибка, которая переводит разрешенную комбинацию в другую разрешенную комбинацию) может быть сделана очень малой.
Если принята запрещенная кодовая комбинация bj, то, зная параметры канала, можно определить, какая из разрешенных комбинаций b вероятнее всего передавалась, и произвести декодирование принятой комбинации bj в комбинацию, совпадающую с b. Если действительно передавалась bj, то тем самым возникшие ошибки будут исправлены. Конечно, возможны случаи, когда в действительности передавалась не наиболее вероятная комбинация bj а какая-то другая, так что декодирование окажется неправильным. Тем не менее, при достаточной избыточности кода и хорошей его структуре вероятность неисправленной ошибки может быть достаточно малой (и во всяком случае значительно меньшей, чем при примитивном кодировании.
|
|
|
Из сказанного видно что, при избыточном кодировании возможны два основных метода декодирования — с обнаружением ошибок и с их исправлением. Сущность метода декодирования с исправлением ошибок заключается в том, что все множество В принимаемых последовательностей длины п разбивается на М неперекрывающихся подмножеств: В1, В2, ..., Вм - Если принята последовательность, принадлежащая подмножеству В,-, то считается, что передавалась кодовая комбинация Вi. Естественно, что в подмножестве В; следует включить те запрещенные комбинации bj, при приеме которых наиболее вероятной переданной комбинацией является bj.
При декодировании с обнаружением ошибок множество В разбивается на М+1 подмножеств, из которых В1, В2, ..., BМ содержат каждое по одной (разрешенной) кодовой комбинации, а подмножество Вм+1 — все остальные (запрещенные) комбинации. В некоторых системах связи принятая запрещенная комбинация просто отбрасывается и не поступает к получателю. Это обосновано в тех случаях, когда потеря переданного сообщения значительно менее вредна, чем получение ложного сообщения. Чаще при декодировании с обнаружением ошибки ошибочно принятая кодовая комбинация не теряется, а восстанавливается специальными методами. Среди них наиболее распространен метод переспроса.
|
|
|
Необходимо отметить, что правило декодирования с обнаружением ошибок однозначно определяется кодом (т. е. выбором разрешенных комбинаций) и не зависит от свойств канала. При исправлении ошибок, наоборот, возможны различные правила декодирования, поскольку каждую из запрещенных комбинаций можно включить в любое из подмножеств В. В зависимости от свойств канала то или иное правило является предпочтительным. Существуют и смешанные методы декодирования, когда некоторые ошибки исправляют, а другие только обнаруживают здесь множество В также разбито на М+1 подмножеств, но в подмножество В1 ... Вм помимо разрешенных комбинаций входят и некоторые близкие к ним запрещенные (исправляемые), а в Вм+1 — только те запрещенные комбинации, которые не могут быть достаточно надежно исправлены.
Говорят, что в канале произошла ошибка кратности q, если в кодовой комбинации q символов приняты ошибочно. Легко видеть, что кратность ошибки есть не что иное, как расстояние Хэмминга между переданной и принятой кодовыми комбинациями, или, иначе, вес вектора ошибки.
Рассматривая все разрешенные кодовые комбинации и определяя кодовые расстояния между каждой парой, можно найти наименьшее из них d=min d(i;j), где минимум берется по всем парам разрешенных комбинаций. Это минимальное кодовое расстояние является важным параметром кода. Очевидно, что для простого
кода d=l.
Обнаруживающая способность кода характеризуется следующей теоремой.
Если код имеет d>1 и используется декодирование по методу обнаружения ошибок, то все ошибки кратностью q<.d обнаруживаются. Что же касается ошибок кратностью q>=d, то одни из них обнаруживаются, а другие нет.
Для доказательства достаточно вспомнить, что кодовое расстояние между посланной и принятой комбинациями равно q. Следовательно, если q<d, принятая комбинация не может быть разрешенной, так как это противоречило бы определению d. Поэтому она будет принадлежать подмножеству запрещенных комбинаций, т. е. ошибка будет обнаружена. При q>d принятая комбинация может оказаться разрешенной, и ошибка останется необнаруженной, но часто и в этом случае принятая комбинация оказывается запрещенной и ошибка обнаруживается.
Процесс исправления ошибок рассмотрим сначала для симметричного канала без памяти. В таком канале по определению, вероятность правильного приема символа 1-р не зависит от того, какой символ передается, а также от того, как приняты остальные символы. Вероятность того, что вместо переданного символа bi будет принят символ bj (i=j) равна р/(т—1). Отсюда легко вывести, что вероятность получения на выходе канала комбинации bj, если на вход подана комбинация bi
P(bj|bi)=[p/(m-1)]d(i;j)(1-p)n-d(i;j)
Это следует непосредственно из теоремы умножения вероятностей независимых событий и из того, что для перехода bi в bj необходимо, чтобы на определенных d{i; /) разрядах произошли определенные ошибки, а на остальных разрядах символы были приняты верно.
Таким образом, в симметричном канале без памяти ,
P(bj;bi)
зависит только от кодового расстояния между bi и bj. В случаях, когда p<(m—l)/m, что практически всегда выполняется, выражение монотонно убывает с увеличением d(i; j). Следовательно, вероятность принять комбинацию bj тем больше, чем меньше ее кодовое расстояние от переданной комбинации bj.
Задачей декодера является принятие решения о том, какая кодовая комбинация передавалась, если принята комбинация bj, разумеется, решение, принимаемое декодером, не всегда верное. Однако можно добиваться минимума вероятности ошибочного декодирования. Пусть P(bi|bj) — условная вероятность того, что передавалась комбинация bi, если принята комбинация bj. Эту условную вероятность называют апостериорной вероятностью в отличие от безусловной априорной вероятности Р(bi) того, что передается bi, когда ничего еще не известно о принятой комбинации. Предположим, что декодер по принятой комбинации bj решил, что передавалась комбинация bft. Вероятность того, что это решение верно, очевидно, равна P(bi|bj). Чтобы эта вероятность была максимально возможной, декодер должен из всех разрешенных комбинаций bi(i=l, ..., М) выбрать ту, для которой апостериорная вероятность максимальна. Это правило декодирования. по максимуму апостериорной вероятности можно записать сокращенно так:
max P(bi|bj).
Из теории вероятности известно, что P(bi|bj)= P(bi)( P(bj|bi)/P(bj)) (5.11) Формула Байеса.
Если, как часто бывает на практике, все разрешенные кодовые комбинации равновероятны (P(bi) =const=l/M), то из (5.11) следует, что максимум апостериорной вероятности совпадает с максимум условной вероятности P(bj|bi), которую называют функцией правдоподобия1. Правило декодирования по максимуму правдоподобия можно сокращенно записать так:
max P(bj|bi)
а эта вероятность, как видно, в симметричном канале без памяти определяется только кодовым расстоянием между bi и bj. Следовательно, в таком канале запрещенную комбинацию bj следует декодировать, как ту разрешенную комбинацию bi, которая находится на наименьшем расстоянии от bj. Иначе говоря, в подмножество В^ следует включить все те комбинации bj, которые ближе (в смысле Хэмминга) к bj, чем в любой другой, разрешенной комбинации.
Такое декодирование по наименьшему расстоянию является оптимальным для симметричного канала без памяти. Однако для других каналов это правило может и не быть оптимальным, т. е. не соответствовать максимуму правдоподобия.
Исправляющая способность кода при этом правиле декодирования определяется следующей теоремой.
Если код имеет d>2 и используется декодирование с исправлением ошибок по наименьшему расстоянию, то все ошибки кратностью q<d/2 исправляются. Что же касается ошибок большей кратности, то одни из них исправляются, а другие нет.
Для доказательства покажем, что в условиях теоремы (при q<d/2) действительно переданная комбинация bi ближе (в смысле Хэмминга) к принятой комбинации bj, нежели любая другая разрешенная комбинация. Предположим противное,т.е. что существует разрешенная комбинация bk, для которой d(k; j)<.d(i; j) отсюда следует, что d{k; i)<=d(k; j) + d(i; j)<2d(i; j). Но по условию теоремы d(k; j)=q<.d/2. Отсюда d(k; i)<d, что противоречит определению d. Это противоречие и свидетельствует о справедливости теоремы.
Полученные результаты можно выразить следующими формулами:
qo<d, qи<d/2, (5.13)
где qО — кратность гарантированно обнаруживаемых ошибок в режиме, когда ошибки только обнаруживаются; qи — кратность гарантированно исправляемых ошибок.
Две доказанные теоремы позволяют оценить вероятность ошибочного декодирования (при декодировании с исправлением ошибок) и вероятность необнаруженной ошибки (при декодировании с обнаружением ошибок) в симметричном канале без памяти. Для этого напомним, что вероятность возникновения каких-либо ошибок кратности q определяется известным биномиальным законом
p(q) = Сnqpq(1 - p)n-q . (5.14)
Эта формула следует из того, что ошибки в таком канале являются независимыми событиями с вероятностью р.
Используя доказанные теоремы и равенство (5.14), получаем следующие оценки для вероятности ошибочного декодирования Ро.я1 при коррекции ошибок и для вероятности необнаруженной ошибки рНА1 при обнаружении ошибок:
Pо.д ≥  Сnqpq(1 - p)n-q (5.15)
Сnqpq(1 - p)n-q (5.15)
Рн.о ≥  Сnqpq(1 - p)n-q (5.16)
Сnqpq(1 - p)n-q (5.16)
Здесь [d/2] обозначает наибольшую целую часть d/2. Знак неравенства в (5.8) и (5.9) ставится потому, что код, вообще говоря, может исправлять некоторые ошибки кратности d/2 и выше и обнаруживать ошибки кратности d и выше.
Помехоустойчивые коды можно применять и в дискретных каналах со стиранием. Если в принятом блоке ошибок нет, но имеется qc стертых (не опознанных модемом) символов, то при qc<id эти стирания могут быть исправлены при декодировании по минимуму расстояния Это вытекает из определения d, так как для того, чтобы две комбинации оказались неразличимыми, необходимо стереть не менее d символов, Можно показать также, что при декодировании по минимуму расстояния в канале с ошибками и стираниями гарантированно исправляются q0 ошибок и qQ стираний, если qс+qo<d.
Неравенства (5.15) и (5.16) иллюстрируют важную роль d как основного показателя исправляющих и обнаруживающих свойств кода в симметричном канале без памяти (чем больше d, тем меньше ро.д и рн.о). Поэтому задача кодирования состоит в выборе кода, обладающего максимально достижимым d. Впрочем, такая формулировка задачи неполна. Увеличивая длину кода п V и сохраняя число кодовых комбинаций М, можно получить сколь угодно большое значение d. Проще всего это достигается повторением символов кодовых комбинаций. Но совершенно очевидно, что такое «решение» задачи не представляет интереса, так как с. увеличением п уменьшается возможная скорость передачи информации от источника. Если длина кода п задана, то можно получить любое значение d, не превышающее п, уменьшая число комбинаций М. Поэтому задачу поиска наилучшего кода (в смысле максимального d) следует формулировать так: при заданных М и п найти код длины п, содержащий М комбинаций и имеющий наибольшее возможное d. В общем виде эта задача в теории кодирования не решена, хотя для многих значений п и М ее решения получены.
Эффективность помехоустойчивого кода возрастает при увеличении его длины, так как вероятность ошибочного декодирования уменьшается при увеличении длины кодируемого сообщения.
На первый взгляд помехоустойчивое кодирование реализуется весьма просто. В память кодирующего устройства (кодера) записываются разрешенные кодовые комбинации выбранного кода и правило, по которому с каждым из М сообщений источника сопоставляется одна из таких комбинаций. Данное правило известно и на декодере.
Получив от источника определенное сообщение, кодер отыскивает соответствующую ему комбинацию и посылает в канал. В свою очередь, декодер, приняв комбинацию, искаженную помехами, сравнивает ее со всеми М комбинациями списка и отыскивает ту из них, которая ближе остальных к принятой. Однако даже при умеренных значениях п такой способ весьма сложный. Покажем это на примере.
Пусть для двоичного кода выбрало значение n = 100, а скорость кода (logM)/n примем равной 0,5. Тогда logM = 50 и М = 250»1015. Таким образом, кодовая таблица должна содержать 1015 кодовых комбинаций, или 100 * 1015=1017 кодовых символов. В аппаратуре кодера и декодера эти таблицы «записываются» на двоичных запоминающих ячейках: например, магнитных дисках, магнитной ленте, триггерах, криотронах и т. п. Предположим, что в результате успехов микроэлектроники через несколько лет удастся производить подобную запись, затрачивая на каждый двоичный символ объем в 10-5 мм3 или 10-8 см3. Такие запоминающие устройства в настоящее время можно найти только на страницах фантастических романов. Вся таблица в данном случае займет объем 1017- 10-8=l09 см3. Это объем куба, каждая сторона которого равна 10 м. Очевидно, что изготовление такого* устройства совершенно нереально. Но им не исчерпываются кодер и декодер. В частности, в декодере необходимо проделать 1017 операций, сравнивая символы принятой комбинации с символами, хранящимися в таблице. Так как на это можно отвести только время порядка длительности кодовой комбинации (например, 1 с), а число операций, выполняемых в одну секунду электронными логическими схемами не так велико.
Таким образом, применение достаточно эффективных ( а значит, и достаточно длинных) кодов при табличном методе кодирования и декодирования невозможно. Поэтому основное направление теории помехоустойчивого кодирования заключается в поисках таких классов кодов, для которых кодирование и декодирование осуществляется не перебором таблицы, а с помощью некоторых правил, определенных алгебраической структурой кодовых комбинаций. Один из таких классов представляют линейные коды.
АЧХ канал
В магнитной записи наиболее широко используется двухуровневое кодирование без возвращения к нулю (БВН), которое можно связать с двумя противоположными состояниями намагниченности рабочего слоя носителя. Он мало пригоден для непосредственной записи на ленте и воспроизведения индукционной магнитной головкой и напрямую не годится, например, для записи видеосигналов на цифровой видеомагнитофон. АЧХ кода БВН и тракта цифрового видеомагнитофона (канала связи) заметно различаются, что ведет к нежелательным последствиям.
АЧХ канала записи-воспроизведения без подмагничивания.

1. Индукционная головка не воспроизводит постоянную составляющую – плавание базовой линии.
2. Тракт видеомагнитофона имеет спад в области нижних и верхних частот, а код БВН такого спада не имеет – межсимвольная интерференция (ВЧ) и уменьшение отношения сигнал-шум.
3. Длинные последовательности 0 и 1 уменьшают возможности самосинхронизации – нет регулярной информации о тактовой частоте.
4. Код должен иметь высокую эффективность.
В случае записи с высокой плотностью проявляется взаимовлияние фронтов (межсимвольные искажения) записанных сигналов из-за ограниченной полосы пропускания канала записи–воспроизведения и из-за нелинейного процесса стирания ранее записанного участка сигналограммы полем записи.
Огибающая спектра записываемого цифрового сигнала должна быть по возможности близкой к выбранной амплитудно-частотной характеристике канала прямой записи-воспроизведения. Спектр не должен содержать постоянную составляющую во избежание «плавания базовой линии» воспроизводимого сигнала. Наиболее важные составляющие спектра не должны располагаться в ВЧ области, которая в большей степени подвержена паразитным амплитудной и фазовой модуляциям, вызванным переменным неконтактом. Записываемый сигнал должен обладать свойством самосинхронизации для обеспечения правильного определения тактового интервала воспроизводимого сигнала в условиях зашумленности и паразитных частотной, амплитудной и фазовой его модуляций.
Возможности детектирования сигнала можно оценить по глаз-диаграмме.

Ее получают на экране осциллографа, синхронизированного тактовой частотой, при подаче воспроизводимого сигнала на вертикальный вход осциллографа. Благодаря наложению различных комбинаций сигнала и шума изображение представляется в виде утолщенных линий – век «глаза», который закрывается при увеличении шумов, фазовых дрожаний и смещениях базовой линии. При полностью раскрытом «глазе» условия детектирования наилучшие; если «глаз» закрыт, то пороговое детектирование невозможно. Уменьшение плавания базовой линии и самосинхронизация часто достигаются введением избыточности (дополнительных битов) в цифровой сигнал.
Канальные коды
Модифицированный код БВН: 1 – изменение полярности сигнала на тактовом интервале, 0 – отсутствие такого изменения. Не обладает свойствами самосинхронизации и также мало пригоден для магнитной записи. О пригодности кодов для передачи через канал магнитной записи – воспроизведения – можно судить по их нескольким параметрам:
1. Отношение минимального интервала Тмин между изменением полярности сигнала к тактовому интервалу Ттхарактеризует так называемую эффективность кода, влияющую на требуемую полосу пропускания канала передачи сигнала и определяющую условия взаимовлияния соседних символов, что особенно важно при записи. Чем больше отношение Tмин/Тт, тем меньше взаимовлияние символов.
2. Возможность самосинхронизации кодов, т.е. способность нести в себе регулярную информацию о продолжительности тактовых интервалов, определяется отношением максимального интервала Тмакс между изменением полярности сигнала к тактовому интервалу. Чем меньше отношение ТМАКС/ТТ, тем лучше самосинхронизация кода, тем проще осуществлять посимвольную синхронизацию сигнала при воспроизведении.
3. Отношение минимальной разницы между интервалами изменения полярности сигнала  в кодовой последовательности к тактовому интервалу («окно детектирования») характеризует способность кода к детектированию (различению символов при воспроизведении) и оказывает влияние на требуемые полосу пропускания канала и допустимые временные искажения сигналов записи – воспроизведения. Чем больше отношение /ТТ, тем проще детектировать сигнал и тем менее жесткие требования предъявляются к полосе пропускания канала записи – воспроизведения и к допустимым временным искажениям воспроизводимого сигнала.
в кодовой последовательности к тактовому интервалу («окно детектирования») характеризует способность кода к детектированию (различению символов при воспроизведении) и оказывает влияние на требуемые полосу пропускания канала и допустимые временные искажения сигналов записи – воспроизведения. Чем больше отношение /ТТ, тем проще детектировать сигнал и тем менее жесткие требования предъявляются к полосе пропускания канала записи – воспроизведения и к допустимым временным искажениям воспроизводимого сигнала.
Неравномерные интервалы между изменениями полярности кодированного сигнала могут привести к изменению постоянной составляющей в текущем или мгновенном (на протяженном участке кодовой последовательности) спектре сигнала, к «плаванию базовой линии» воспроизводимого сигнала, затрудняющему пороговое детектирование. Для сбалансированных кодов отношение постоянной составляющей кодовой последовательности (С) к полному размаху сигнала (А) стремится к нулю. Для несбалансированных кодов отношение С/А может достигать 0,5. В последнем случае пороговое детектирование сигнала невозможно. Выделяют следующие канальные коды:
1) Бифазный код (БФ): 1 –изменение фазы сигнала на 180° в начале тактового интервала и противоположное изменение фазы в середине тактового интервала, 0 – изменение фазы сигнала на 180° в середине тактового интервала.
2) Бичастотный код (БЧ) 1 – два полупериода прямоугольного колебания с частотой 1/Tт в течение тактового интервала, 0 – один полупериод прямоугольного колебания с частотой 1/2TT.
Бичастотная и бифазная кодовые последовательности близки по своей структуре и по спектральному составу. Они полностью сбалансированы (постоянная составляющая равна 0), обладают наилучшей самосинхронизирующей способностью, но требуют вдвое большей полосы пропускания канала передачи, чем БВН.
3) Модифицированный код Миллера (или М2) – полностью сбалансирован. 1 – изменение полярности в середине тактового интервала, за исключением последней 1 в серии «единиц»; 0 – изменение полярности в начале тактового интервала, за исключением случая, когда 0 непосредственно следует за 1.
4) Кодированный сигнал состоит из полупериодов прямоугольных колебаний продолжительностью Tт, 1,5TТ, 2,5Тт и ЗТТ. Этот код часто применяют при цифровой записи.
Блочное кодирование – разделение цифрового потока на блоки длиной в k бит и преобразование их в блоки большей протяженности длиной в n бит, но обладающие лучшими свойствами.
6) ТВ блочный код 8/10. Блоки 8 бит преобразуются в 10 бит и отбираются 252 кодовых слова, содержащие по 5 нулей и 5 единиц (для исключения постоянной составляющей). Общее число сбалансированных кодовых слов определяется выражением

Легко выделить тактовую частоту при помощи петли ФАПЧ. Может содержать постоянную составляющую, большая избыточность (25%).Кодеры 8/10 могут быть выполнены с использованием устройства памяти.

1 – универсальный регистр сдвига; 2 – ПЗУ; 3– универсальный регистр сдвига; 4 – устройство ввода ограничений; 5 – устройство управления.
Параметры канальных кодов
| Тип кодов | Tмин /Tт | Tмакс /Tт | ДТ/ТТ |
| БВН, БВН-1 | 1 | - | 1 |
| БФ | 1 2 | 1 | 1/2 |
| М2 | 1 | 3 | 1/2 |
| ЗРМ | 1,5 | 5 | 1/2 |
| 8/10 | 1 | 3 | 1 |
Помехоустойчивые коды
Вероятность ошибки в одном разряде может составлять 10-4..10-5. При скоростях цифрового потока 150-200 Мбит/с, каждую секунду будут происходить тысячи ошибок. Качество такого изображения будет неудовлетворительным. Все способы кодирования, позволяющие обнаруживать и исправлять ошибки, предполагают введение избыточности:
1) Обнаруживающие коды. Проверка на четность.

Если число единиц не является четным, то в канале произошла ошибка. Выход – использовать маскирование отсчета путем интерполяции. Находит применение при очень малой вероятности ошибок.
2) Исправляющий матричный код. Для исправления ошибки надо найти строку и столбец матрицы, в которых произошли нарушения четности числа единиц, и заменить символ на пересечении на противоположный. Избыточность кода очень велика, она сокращается с ростом длины информационной части слова.
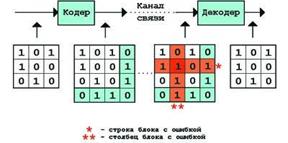
3) Коды Рида-Соломона – требует добавления двух проверочных символов в расчете на одну исправляемую ошибку. Относятся к классу циклических кодов.
Если кодируемая информация i описывается набором (блоком) из k символов, то этому набору, или слову можно поставить в соответствие информационный многочлен
i(x)=ik-1xk-1+ik-2xk-2+...+i1x+i0.
Каждому информационному слову должно соответствовать кодовое слово c=(cn-1, cn-2, ..., c1, c0) большей длины с добавленной избыточностью в виде дополнительных символов. Это кодовое слово также можно записать в виде многочлена
c(x)=cn-1xn-1+cn-2xn-2+...+c1x+c0.
В соответствии с теорией циклических кодов образование кодовых слов производится с помощью порождающего многочлена, степень которого равна числу дополнительных (проверочных) символов:
g(x)=gn-kxn-k+gn-k-1xn-k-1+...+g1x+g0.
Процедура нахождения кодового слова заключается в умножении информационного многочлена на порождающий многочлен кода. Следовательно, они все делятся на порождающий многочлен без остатка.

Если цель кодирования – исправить t ошибок в кодовом слове, то степень порождающего многочлена
(n-k)=2t.
Записываемый на магнитный носитель кодовый блок может претерпеть искажения, например, из-за шумов. Это можно в общем виде описать добавлением к кодовому блоку набора ошибок e, которому соответствует многочлен
e(x)=en-1xn-1+en-2xn-2+...+e1x+e0.
Принятому или воспроизведенному набору символов соответствует таким образом многочлен
v(x)=c(x)+e(x).
Найдя остаток от деления принятого многочлена v(x) на порождающий g(x), можно понять, были ли на самом деле ошибки. Если остаток равен нулю, значит принятое слово является кодовым и ошибок не было. Если остаток не равен нулю, то при передаче были ошибки. Остаток от деления дает многочлен, зависящий только от многочлена ошибки. Его называют синдромным многочленом.
Синдромный многочлен s(x) зависит только от конфигурации ошибок, т.е. является синдромом, или описанием ошибок. Если число ошибок не превышает заданный предел t, то между e(x) и s(x) существует однозначное соответствие и с помощью определенных вычислений можно найти коэффициенты многочлена ошибок по синдромному многочлену. Таким образом можно восстановить переданный кодовый многочлен:
c(x)=v(x)-e(x).
Разделив c(x) на g(x), можно найти и информационный многочлен.
Кроме кодирования по правилу
c(x)=i(x)g(x)
существует т.н. систематическое правило кодирования, при котором k старших коэффициентов кодового слова устанавливаются равными коэффициентам информационного многочлена:
c(x)=ik-1xn-1+ik-2xn-2+...+i0xn-k+ pn-k-1xn-k-1+...+p1x+p0.
(n-k) младших коэффициентов кодового слова p, часто называемых проверочными, подбираются такими, чтобы c(x) делился бы на g(x) без остатка.
Это будет так, если соответствующий проверочный многочлен
p(x)=pn-k-1xn-k-1+...+p1x+p0
рассчитывается как
p(x)=-R[(xn-ki(x)):g(x)].
Систематическое правило кодирования дает кодовые слова, более удобные на практике, т.к. информационные слова в явном виде размещаются в k старших разрядах кодовых слов.
Декодирование принятого или воспроизведенного набора предполагает следующие действия:
- нахождение синдромного многочлена;
- вычисление многочлена ошибок е(x) по найденному синдромному многочлену (ошибки нет, если s(x)=0);
- восстановление переданного кодового многочлена;
- определение переданного блока информации по старшим коэффициентам восстановленного кодового многочлена.
4) Каскадное кодирование – используется для исправления пакетных ошибок (выпадений сигнала). Длина выпадений – до десятков тысяч символов. Для исправления таких больших пакетных ошибок надо использовать кодовые слова очень большой длины, что на практике бывает не совсем удобным, например, из-за ограничений, налагаемых необходимостью монтажа. Проблема решается за счет использования кодов-произведений.
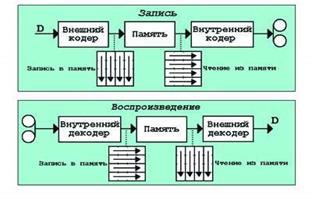
Это раздельное кодирование столбцов и строк прямоугольной матрицы – массива цифровых данных. К столбцам матрицы добавляются проверочные символы одного кода, называемого внешним (n1,k1), а к строкам – проверочные символы другого кода, называемого внутренним (n2, k2). Такое двумерное кодирование существенно увеличивает мощность кода.
Способность кодов-произведений исправлять пакетные ошибки достигается благодаря использованию буферной памяти между внешним и внутренними кодерами и чередованию направлений записи в память и чтения из нее.
При записи память заполняется по столбцам, к которым добавляются проверочные символы внешнего кода. Затем содержимое памяти построчно записывается на магнитную ленту вместе с добавляемыми проверочными символами внутреннего кода. При воспроизведении чередование направлений записи и чтения из буферной памяти является обратным.
В результате такого чередования направлений записи и чтения из буферной памяти (перемежения) пакетная ошибка, длина которой равна нескольким строкам буферной памяти, распределяется маленькими порциями в разных кодовых словах внешнего (вертикального) кода и может быть исправлена при сравнительно небольшой его мощности. Внешний код, способный исправлять всего одну ошибку в одном кодовом слове, может исправить пакетную ошибку длиной до целой строки буферной памяти.
Размер буферной памяти кодера-декодера является важнейшим параметром, позволяющим сравнивать потенциальные возможности различных форматов видеозаписи. Чем больше размер памяти, тем больше возможности исправления пакетных ошибок, обусловленных выпадениями сигнала.
Для работы с нестандартными скоростями воспроизведения размер слов и памяти должен быть сравнительно небольшим (кодовое слово внутреннего кода определяет минимальную порцию информации, которая должна считываться при любой нестандартной скорости воспроизведения). Эти два противоречивых требования удается выполнить, разбивая матрицу памяти кодера-декодера на подматрицы.
Кодовое слово внутреннего кода определяется горизонтальным размером подматрицы, проверочные символы внутреннего кода добавляются к строкам матрицы частями. Одновременно достигается оптимальная стратегия борьбы со случайными и пакетными ошибками. Внутреннее кодирование позволяет обнаруживать и исправлять ошибки случайного характера, имеющие сравнительно небольшую длину. Внешнее кодирование оптимизируется для устранения пакетных ошибок, вызванных выпадениями.
Задание
Необходимо закодировать и передать 7 различных сообщений по двоичному симметричному каналу без памяти. Вероятность ошибки при передаче символа по каналу р=0.2. Кодирование производится избыточным кодом qи=1...4
Рассчитать в зависимости от изменения qи:
d; n; r; qо кода.
Вероятности ошибочного декодирования и необнаруженной ошибки.
Время передачи по каналу одного сообщения, если vк=1000 сим/с.
Построить графики указанных зависимостей.
Сначала рассчитаем параметры кода:
А) по известной кратности исправляемых ошибок  найдем минимальное кодовое расстояние d. Известно, что
найдем минимальное кодовое расстояние d. Известно, что  для нечетных d,
для нечетных d, 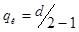 для четных d. Отсюда находим:
для четных d. Отсюда находим:
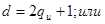
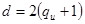
 канала
канала 


Б) найдем количество избыточных символов кода 
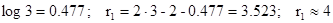



В)определим количество информационных символов k как наибольшее ближайшее целое к log7, то k=3.
Г) найдем общую длину кодовой комбинации n=k+r:



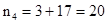
Д) обнаруживающая способность кода 
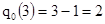



Затем определяем вероятность ошибочного декодирования

И вероятность необнаруженной ошибки 
Здесь  обозначает наибольшую целую часть
обозначает наибольшую целую часть 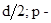 вероятность ошибочной передачи одного кодового символа;
вероятность ошибочной передачи одного кодового символа; 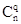 - количество сочетаний из n элементов по q:
- количество сочетаний из n элементов по q:




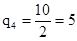







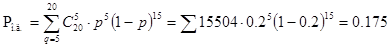





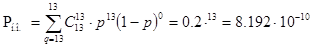


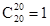






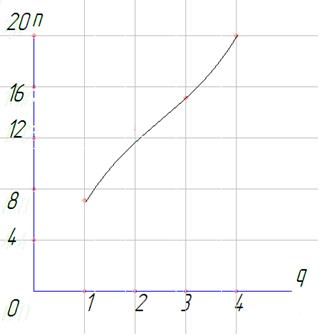
Рис.1 зависимость 

Рис.2 зависимость 

Рис.3 зависимость 

Рис.4 зависимость 
Заключение
Таким образом мы определили ряд вероятностей ошибочного декодирования  вероятность необнаруженной ошибки
вероятность необнаруженной ошибки  , а так же рассчитали время передачи одного сообщения по каналу:
, а так же рассчитали время передачи одного сообщения по каналу:

| 
| 
| 
|
| 1 | 0,275 | 
| 0,007 |
| 2 | 0,246 | 
| 0,013 |
| 3 | 0,188 | 
| 0,015 |
| 4 | 0,175 | 
| 0,02 |
Список использованной литературы
Зюко А.Г. «Теория передачи сигналов». – М.: Радио и связь, 1986г.
2. Козлов С.В., Седов С.С. «Теория электрической связи». Пособие по курсовой работе. Казань. 2001г.
1. Размещено на www.allbest.ru
Дата добавления: 2018-09-22; просмотров: 197; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!