Функции нескольких переменных
Ограниченные возможности симплексного метода, заключенные в задачах со сложными видами ограничений и произвольным видом целевой функции, привели к широкому использованию итеративных методов поиска оптимального решения.
Сначала рассмотрим вопрос анализа «в статике» с использованием положений линейной алгебры и дифференциального исчисления, а также условия, которые (в достаточно общих возможных ситуациях) позволяют идентифицировать точки оптимума. Такие условия используются для проверки выбранных точек и дают возможность выяснить, являются ли эти точки точками минимума или максимума. При этом задача выбора указанных точек остается вне рамок проводимого анализа; основное внимание уделяется решению вопроса о том, соответствуют ли исследуемые точки решениям многомерной задачи безусловной оптимизации, в которой требуется минимизировать f(x) x 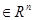 при отсутствии ограничений на x, где x — вектор управляемых переменных размерности n, f — скалярная целевая функция. Обычно предполагается, что xi (для всех значений i=1, 2, …, n) могут принимать любые значения, хотя в ряде практических приложений область значений x выбирается в виде дискретного множества. Кроме того, часто оказывается удобным предполагать, что функция f и ее производные существуют и непрерывны всюду, хотя известно, что оптимумы могут достигаться в точках разрыва f или ее градиента
при отсутствии ограничений на x, где x — вектор управляемых переменных размерности n, f — скалярная целевая функция. Обычно предполагается, что xi (для всех значений i=1, 2, …, n) могут принимать любые значения, хотя в ряде практических приложений область значений x выбирается в виде дискретного множества. Кроме того, часто оказывается удобным предполагать, что функция f и ее производные существуют и непрерывны всюду, хотя известно, что оптимумы могут достигаться в точках разрыва f или ее градиента
|
|
|
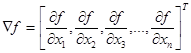
Градиентом функции f(х) называют вектор, величина которого определяет скорость изменения функции f(x), а направление совпадает с направлением наибольшего возрастания этой функции.
Следует помнить, что функция f может принимать минимальное значение в точке x, в которой f или 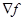 претерпевают разрыв. Кроме того, в этой точке
претерпевают разрыв. Кроме того, в этой точке 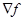 может не существовать. Для того чтобы построить систему конструктивных критериев оптимальности, необходимо (по крайней мере на первой стадии исследования) исключить из рассмотрения подобные ситуации, которые весьма усложняют анализ.
может не существовать. Для того чтобы построить систему конструктивных критериев оптимальности, необходимо (по крайней мере на первой стадии исследования) исключить из рассмотрения подобные ситуации, которые весьма усложняют анализ.
Методы прямого поиска
Ниже рассматривается вопрос анализа «в динамике» для функций нескольких переменных, т. е. исследуются методы и алгоритмы, позволяющие на итерационной основе получать оценки х*— вектора управляемых переменных, которому соответствует минимальное значение функции f(x). Указанные методы применимы также к задачам максимизации, в которых целевую функцию следует заменить на -f(х). Методы, ориентированные на решение задач безусловной оптимизации, можно разделить на три широких класса в соответствии с типом используемой при реализации того или иного метода информации.
1. Методы прямого поиска, основанные на вычислении только значений целевой функции.
|
|
|
2. Градиентные методы, в которых используются точные значения первых производных f(x).
3. Методы второго порядка, в которых наряду с первыми производными используются также вторые производные функции f(x).
Ниже рассматриваются методы, относящиеся к каждому из перечисленных классов, поскольку ни один метод или класс методов не отличается высокой эффективностью при решении оптимизационных задач различных типов. В частности, возможны случаи, когда происходит переполнение памяти ЭВМ; в других ситуациях вычисление значений целевой функции требует чрезмерных затрат времени; в некоторых задачах требуется получить решение с очень высокой степенью точности. В ряде приложений либо невозможно, либо весьма затруднительно найти аналитические выражения для производных целевой функции. Поэтому если предполагается использовать градиентные методы, следует применить процедуру разностной аппроксимации производных. В свою очередь это приводит к необходимости экспериментального определения длины шагов, позволяющего установить надлежащее соответствие между ошибкой округления и ошибкой аппроксимации. Таким образом, инженер вынужден приспосабливать применяемый метод к конкретным характеристикам решаемой задачи.
|
|
|
Методы решения задач безусловной оптимизации отличаются относительно высоким уровнем развития по сравнению с другими методами нелинейного программирования. Ниже речь идет о методах прямого поиска, для реализации которых требуются только значения целевой функции; в следующем разделе рассматриваются градиентные методы и методы второго порядка. Здесь предполагается, что f(x) непрерывна, а 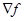 может как существовать, так и не существовать, поскольку соответствующие числовые значения не используются. Однако следует отметить, что методы прямого поиска можно применять для решения задач, в которых существует, и они часто используются в тех случаях, когда
может как существовать, так и не существовать, поскольку соответствующие числовые значения не используются. Однако следует отметить, что методы прямого поиска можно применять для решения задач, в которых существует, и они часто используются в тех случаях, когда  представляет собой сложную векторную функцию управляемых переменных. Наконец, в этом и последующих разделах предполагается, что функция f(х) унимодальна в рассматриваемой области. Если же изучаемые методы применяются для анализа мультимодальных функций, то приходится ограничиваться идентификацией локальных минимумов.
представляет собой сложную векторную функцию управляемых переменных. Наконец, в этом и последующих разделах предполагается, что функция f(х) унимодальна в рассматриваемой области. Если же изучаемые методы применяются для анализа мультимодальных функций, то приходится ограничиваться идентификацией локальных минимумов.
Многомерные методы, реализующие процедуру поиска оптимума на основе вычисления значений функции, с общих позиций можно разделить на эвристические и теоретические. Эвристические методы, как это следует из названия, реализуют процедуры поиска с помощью интуитивных геометрических представлений и обеспечивают получение частных эмпирических результатов. С другой стороны, теоретические методы основаны на фундаментальных математических теоремах и обладают такими операционными свойствами, как сходимость (по крайней мере при выполнении некоторых определенных условий). Ниже подробно рассматриваются три метода прямого поиска:
|
|
|
1) поиск по симплексу, или S2-метод;
2) метод поиска Хука—Дживса;
3) метод сопряженных направлений Пауэлла.
Первые два из перечисленных методов относятся к категории эвристических и реализуют принципиально различающиеся стратегии поиска. В процессе поиска по S2-методу последовательно оперируют регулярными симплексами в пространстве управляемых переменных, тогда как при реализации метода Хука-Дживса используется фиксированное множество (координатных) направлений, выбираемых рекурсивным способом. Метод Пауэлла основан на теоретических результатах и ориентирован на решение задач с квадратичными целевыми функциями; для таких задач метод сходится за конечное число итераций. К числу общих особенностей всех трех методов следует отнести относительную простоту соответствующих вычислительных процедур, которые легко реализуются и быстро корректируются. С другой стороны, реализация указанных методов может требовать (и часто требует) более значительных затрат времени по сравнению с методами с использованием производных.
4.1.1. Метод поиска по симплексу(S2 -метод)
Первые попытки решения оптимизационных задач без ограничений на основе прямого поиска связаны с использованием одномерных методов оптимизации. Как правило, при реализации таких методов допустимая область определения показателя качества функционирования системы (целевой функции) заменяется дискретным множеством (решеткой) точек пространства управляемых переменных, а затем используются различные стратегии уменьшения области, которая содержит решение задачи. Часто эта процедура оказывается эквивалентной равномерному поиску в узлах решетки и, следовательно, непригодной для решения задач с числом переменных, превышающим 2. Более полезная идея заключается в выборе базовой точки и оценивании значений целевой функции в точках, окружающих базовую точку. Например, при решении задачи с двумя переменными можно воспользоваться квадратным образцом, изображенным на рис.2
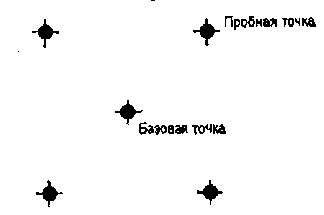 |
Рис 2. Квадратный образец (частный случай кубического образца)
Затем «наилучшая» из пяти исследуемых точек выбирается в качестве следующей базовой точки, вокруг которой строится аналогичный образец. Если ни одна из угловых точек не имеет преимущества перед базовой, размеры образца следует уменьшить, после чего продолжить поиск.
Этот тип эволюционной оптимизации был использован Боксом и другими исследователями для анализа функционирования промышленных предприятий, когда эффект варьирования значений переменных, описывающих производственные процессы, измеряется с ошибкой. В задачах большой размерности вычисление значений целевой функции проводится во всех вершинах, а также в центре тяжести гиперкуба (гиперкуб – куб в n-мерном евклидовом пространстве, т.е. множество S={x=(  )
) 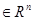 |
| 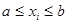 } , где а и b – заданные числа ) , т. е. в точках так называемого кубического образца. Если количество переменных (размерность пространства, в котором ведется поиск) равно n, то поиск по кубическому образцу требует
} , где а и b – заданные числа ) , т. е. в точках так называемого кубического образца. Если количество переменных (размерность пространства, в котором ведется поиск) равно n, то поиск по кубическому образцу требует 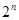 +1 вычислений значения функций для одного образца. При увеличении размерности задачи необходимое количество вычислений значения целевой функции возрастает чрезвычайно быстро. Таким образом, несмотря на логическую простоту поиска по кубическому образцу, возникает необходимость использования более эффективных методов прямого поиска для решения возникающих на практике задач оптимизации.
+1 вычислений значения функций для одного образца. При увеличении размерности задачи необходимое количество вычислений значения целевой функции возрастает чрезвычайно быстро. Таким образом, несмотря на логическую простоту поиска по кубическому образцу, возникает необходимость использования более эффективных методов прямого поиска для решения возникающих на практике задач оптимизации.
Одна из вызывающих особый интерес стратегий поиска положена в основу метода поиска по симплексу, предложенного Спендли, Хекстом и Химсвортом. Следует отметить, что указанный метод и другие подобные методы не имеют отношения к симплекс-методу линейного программирования, а сходство названий носит случайный характер. Процедура симплексного поиска Спендли, Хекста и Химсворта базируется на том, что экспериментальным образцом, содержащим наименьшее количество точек, является регулярный симплекс. Регулярный симплекс в n-мерном пространстве представляет собой многогранник, образованный n+1 равностоящими друг от друга точками-вершинами. Например, в случае двух переменных симплексом является равносторонний треугольник; в трехмерном пространстве симплекс представляет собой тетраэдр. В алгоритме симплексного поиска используется важное свойство симплексов, согласно которому новый симплекс можно построить на любой грани начального симплекса путем переноса выбранной вершины на надлежащее расстояние вдоль прямой, проведенной через центр тяжести остальных вершин начального симплекса. Полученная таким образом точка является вершиной нового симплекса, а выбранная при построении вершина начального симплекса исключается. Нетрудно видеть, что при переходе к новому симплексу требуется одно вычисление значения целевой функции. Рис 3 иллюстрирует процесс построения нового симплекса на плоскости.
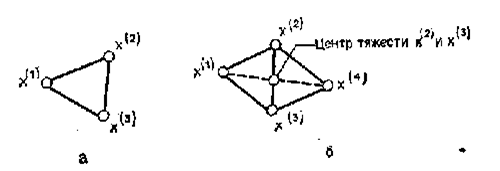 |
Рис.3.Построение нового симплекса.
а – начальный симплекс 
б – новый симплекс 
Работа алгоритма симплексного поиска начинается с построения регулярного симплекса в пространстве независимых переменных и оценивания значений целевой функции в каждой из вершин симплекса. При этом определяется вершина, которой соответствует наибольшее значение целевой функции. Затем найденная вершина проецируется через центр тяжести остальных вершин симплекса в новую точку, которая используется в качестве вершины нового симплекса. Если функция убывает достаточно плавно, итерации продолжаются до тех пор, пока либо не будет накрыта точка минимума, либо не начнется циклическое движение по двум или более симплексам. В таких ситуациях можно воспользоваться следующими тремя правилами.
Правило 1. «Накрытие» точки минимума
Если вершина, которой соответствует наибольшее значение целевой функции, построена на предыдущей итерации, то вместо нее берется вершина, которой соответствует следующее по величине значение целевой функции.
Правило 2. Циклическое движение
Если некоторая вершина симплекса не исключается на протяжении более чем М итераций, то необходимо уменьшить размеры симплекса с помощью коэффициента редукции и построить новый симплекс, выбрав в качестве базовой точку, которой соответствует минимальное значение целевой функции. Спендли, Хекст и Химс-ворт предложили вычислять М по формуле
M=1,65n+0,05 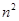
где n — размерность задачи, а М округляется до ближайшего целого числа. Для применения данного правила требуется установить величину коэффициента редукции.
Правило 3. Критерий окончания поиска
Поиск завершается, когда или размеры симплекса, или разности между значениями функции в вершинах становятся достаточно малыми. Чтобы можно было применять эти правила, необходимо задать величину параметра окончания поиска.
Реализация изучаемого алгоритма основана на вычислениях двух типов: (1) построении регулярного симплекса при заданных базовой точке и масштабном множителе и (2) расчете координат отраженной точки. Построение симплекса является достаточно простой процедурой, так как из элементарной геометрии известно, что при заданных начальной (базовой) точке 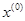 и масштабном множителе
и масштабном множителе 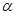 координаты остальных n вершин симплекса в n-мерном пространстве вычисляются по формуле
координаты остальных n вершин симплекса в n-мерном пространстве вычисляются по формуле
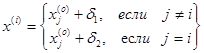 (7)
(7)
для i и j=1,2,3,…,n
Приращения 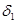 и
и 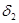 , зависящие только от n и выбранного масштабного множителя , определяются по формулам
, зависящие только от n и выбранного масштабного множителя , определяются по формулам
 (8)
(8)
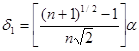 (9)
(9)
Заметим, что величина масштабного множителя 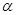 выбирается исследователем, исходя из характеристик решаемой задачи. При =1 ребра регулярного симплекса имеют единичную длину. Вычисления второго типа, связанные с отражением относительно центра тяжести, также представляют несложную процедуру. Пусть
выбирается исследователем, исходя из характеристик решаемой задачи. При =1 ребра регулярного симплекса имеют единичную длину. Вычисления второго типа, связанные с отражением относительно центра тяжести, также представляют несложную процедуру. Пусть 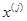 — точка, подлежащая отражению. Центр тяжести остальных n точек расположен в точке
— точка, подлежащая отражению. Центр тяжести остальных n точек расположен в точке
 (10)
(10)
Все точки прямой, проходящей через  и хс, задаются формулой
и хс, задаются формулой
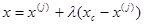 (11)
(11)
При 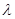 =0 получаем исходную точку
=0 получаем исходную точку 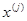 , тогда как значение
, тогда как значение 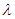 =1 соответствует центру тяжести хс. Для того чтобы построенный симплекс обладал свойством регулярности, отражение должно быть симметричным. Следовательно, новая вершина получается при
=1 соответствует центру тяжести хс. Для того чтобы построенный симплекс обладал свойством регулярности, отражение должно быть симметричным. Следовательно, новая вершина получается при 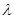 =2. Таким образом,
=2. Таким образом,
 (12)
(12)
Проиллюстрируем вычислительную схему метода следующим примером.
Пример 5. Вычисления в соответствии с методом поиска по симплексу
Минимизировать f(x)= 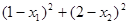
Решение.
Для построения исходного симплекса требуется задать начальную точку и масштабный множитель. Пусть x 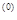 =
= 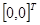 и =2. Тогда
и =2. Тогда

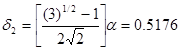
Используя эти два параметра, вычислим координаты двух остальных вершин симплекса:
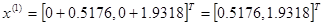
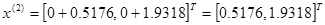
которым соответствуют значения целевой функции, равные 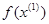 =0,2374 и
=0,2374 и 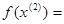 3,0658. Так как
3,0658. Так как 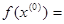 5, необходимо отразить точку
5, необходимо отразить точку  относительно центра тяжести двух остальных вершин симплекса
относительно центра тяжести двух остальных вершин симплекса
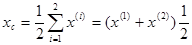
Используя формулу (12), получаем
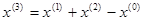
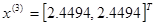
В полученной точке 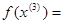 2,3027, т. е. наблюдается уменьшение целевой функции. Новый симплекс образован точками
2,3027, т. е. наблюдается уменьшение целевой функции. Новый симплекс образован точками 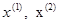 и
и  . В соответствии с алгоритмом следует отразить точку х(2), которой соответствует наибольшее значение целевой функции, относительно центра тяжести точек
. В соответствии с алгоритмом следует отразить точку х(2), которой соответствует наибольшее значение целевой функции, относительно центра тяжести точек 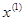 и х(3). Итерации продолжаются до тех пор, пока не потребуется применение правил 1, 2 и 3, которые были сформулированы выше.
и х(3). Итерации продолжаются до тех пор, пока не потребуется применение правил 1, 2 и 3, которые были сформулированы выше.
Изложенный выше алгоритм 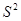 - метода имеет несколько очевидных преимуществ.
- метода имеет несколько очевидных преимуществ.
1. Расчеты и логическая структура метода отличаются сравнительной простотой, и, следовательно, соответствующая программа для ЭВМ оказывается относительно короткой.
2. Уровень требований к объему памяти ЭВМ невысокий, массив имеет размерность (n+1, n+2).
3. Используется сравнительно небольшое число заранее установленных параметров: масштабный множитель , коэффициент уменьшения множителя (если применяется правило 2) и параметры окончания поиска.
4. Алгоритм оказывается эффективным даже в тех случаях, когда ошибка вычисления значений целевой функции велика, поскольку при его реализации оперируют наибольшими значениями функции в вершинах, а не наименьшими.
Перечисленные факторы характеризуют метод поиска по симплексу как весьма полезный при проведении вычислений в реальном времени.
Алгоритм обладает также рядом существенных недостатков.
1. Не исключено возникновение трудностей, связанных с масштабированием, поскольку все координаты вершин симплекса зависят от одного и того же масштабного множителя 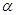 . Чтобы обойти трудности такого рода, в практических задачах следует промасштабировать все переменные с тем, чтобы их значения были сравнимыми по величине.
. Чтобы обойти трудности такого рода, в практических задачах следует промасштабировать все переменные с тем, чтобы их значения были сравнимыми по величине.
2. Алгоритм работает слишком медленно, так как полученная на предыдущих итерациях информация не используется для ускорения поиска.
3. Не существует простого способа расширения симплекса, не требующего пересчета значений целевой функции во всех точках образца. Таким образом, если  по какой-либо причине уменьшается (например, если встречается область с узким «оврагом» или «хребтом»), то поиск должен продолжаться с уменьшенной величиной шага.
по какой-либо причине уменьшается (например, если встречается область с узким «оврагом» или «хребтом»), то поиск должен продолжаться с уменьшенной величиной шага.
Метод поиска Хука-Дживса.
Метод, разработанный Хуком и Дживсом, является одним из первых алгоритмов, в которых при определении нового направления поиска учитывается информация, полученная на предыдущих итерациях. По существу процедура Хука—Дживса представляет собой комбинацию «исследующего» поиска с циклическим изменением переменных и ускоряющегося поиска по образцу с использованием определенных эвристических правил. Исследующий поиск ориентирован на выявление характера локального поведения целевой функции и определение направлений вдоль «оврагов». Полученная в результате исследующего поиска информация затем используется в процессе поиска по образцу при движении по «оврагам».
Исследующий поиск.
Для проведения исследующего поиска необходимо задать величину шага, которая может быть различной для разных координатных направлений и изменяться в процессе поиска. Исследующий поиск начинается в некоторой исходной точке. Если значение целевой функции в пробной точке не превышает значения функции в исходной точке, то шаг поиска рассматривается как успешный. В противном случае необходимо вернуться в предыдущую точку и сделать шаг в противоположном направлении с последующей проверкой значения целевой функции. После перебора всех N координат исследующий поиск завершается. Полученную в результате точку называют базовой точкой.
Поиск по образцу.
Поиск по образцу заключается в реализации единственного шага из полученной базовой точки вдоль-прямой, соединяющей эту точку с предыдущей базовой точкой. Новая точка образца определяется в соответствии с формулой
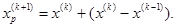
Как только движение по образцу не приводит к уменьшению целевой функция, точка  фиксируется в качестве временной базовой точки и вновь проводится исследующий поиск. Если в результате получается точка с меньшим значением целевой функции, чем в точке
фиксируется в качестве временной базовой точки и вновь проводится исследующий поиск. Если в результате получается точка с меньшим значением целевой функции, чем в точке  , то она рассматривается как новая базовая точка
, то она рассматривается как новая базовая точка 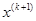 . С другой стороны, если исследующий поиск неудачен, необходимо вернуться в точку и провести исследующий поиск с целью выявления нового направления минимизации. В конечном счете, возникает ситуация, когда такой поиск не приводит к успеху. В этом случае требуется уменьшить величину шага путем введения некоторого множителя и возобновить исследующий поиск. Поиск завершается, когда величина шага становится достаточно малой. Последовательность точек, получаемую в процессе реализации метода, можно записать в следующем виде:
. С другой стороны, если исследующий поиск неудачен, необходимо вернуться в точку и провести исследующий поиск с целью выявления нового направления минимизации. В конечном счете, возникает ситуация, когда такой поиск не приводит к успеху. В этом случае требуется уменьшить величину шага путем введения некоторого множителя и возобновить исследующий поиск. Поиск завершается, когда величина шага становится достаточно малой. Последовательность точек, получаемую в процессе реализации метода, можно записать в следующем виде:
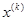 - текущая базовая точка,
- текущая базовая точка,
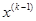 - предыдущая базовая точка,
- предыдущая базовая точка,
- точка, построенная при движении по образцу,
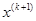 - следующая (новая) базовая точка.
- следующая (новая) базовая точка.
Приведенная последовательность характеризует логическую структуру поиска по методу Хука — Дживса.
Структура метода поиска Хука — Дживса
Шаг 1 . Определить:
начальную точку  ,
,
приращения 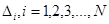
коэффициент уменьшения шага 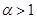 ,
,
параметр окончания поиска 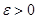 .
.
Ш а г 2. ровести исследующий поиск.
Ш а г 3. Был ли исследующий поиск удачным (найдена ли точка с меньшим значением
целевой функции)?
Да: перейти к шагу 5.
Нет: продолжать.
Ш а г 4. Проверка на окончание поиска.
Выполняется ли неравенство 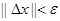 ?
?
Да: прекратить поиск; текущая точка аппроксимирует точку оптимума 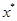 .
.
Нет: уменьшить приращения по формуле
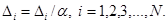
Перейти к шагу 2.
Ш а г 5. Провести поиск по образцу:
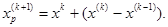
Шаг 6. Провести исследующий поиск, используя 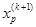 в качестве базовой точки;
в качестве базовой точки;
пусть 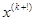 полученная в результате точка.
полученная в результате точка.
Ш а г 7. Выполняется ли неравенство 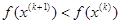 ?
?
Да: положить 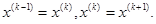 Перейти к шагу 5.
Перейти к шагу 5.
Нет: перейти к шагу 4.
Пример 6 Поиск по методу Хука — Дживса
Найти точку минимума функции 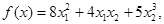 используя начальную точку
используя начальную точку  .
.
Решение.
Для того чтобы применить метод прямого поиска .Хука — Дживса, необходимо задать следующие величины:
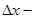 векторная величина приращения =
векторная величина приращения = 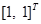 ,
,
 коэффициент уменьшения шага = 2,
коэффициент уменьшения шага = 2,
 параметр окончания поиска = 10-4.
параметр окончания поиска = 10-4.
Итерации начинаются с исследующего поиска вокруг точки 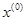 , которой соответствует значение функции
, которой соответствует значение функции 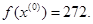 Фиксируя
Фиксируя  , дадим приращение переменной
, дадим приращение переменной 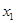 :
:
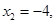
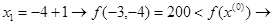 Успех.
Успех.
Следовательно, необходимо зафиксировать 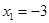 и дать приращение переменной
и дать приращение переменной 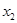 :
:
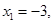
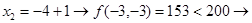 Успех.
Успех.
Таким образом, в результате исследующего поиска найдена точка
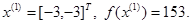
Поскольку исследующий поиск был удачным, переходим к поиску по образцу:

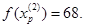
Далее проводится исследующий поиск вокруг точки 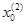 , который оказывается удачным при использовании положительных приращений переменных х1 и х2. В результате получаем точку
, который оказывается удачным при использовании положительных приращений переменных х1 и х2. В результате получаем точку
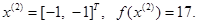
Поскольку  , поиск по образцу следует считать успешным, и
, поиск по образцу следует считать успешным, и 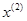 становится новой базовой точкой при следующем проведении поиска по образцу. Итерации продолжаются, пока уменьшение величины шага не укажет на окончание поиска в окрестности точки минимума. Последовательные шаги реализации метода показаны на рисунке.
становится новой базовой точкой при следующем проведении поиска по образцу. Итерации продолжаются, пока уменьшение величины шага не укажет на окончание поиска в окрестности точки минимума. Последовательные шаги реализации метода показаны на рисунке.
Из примера следует, что метод Хука — Дживса характеризуется несложной стратегией поиска, относительной простотой вычислений и невысоким уровнем требований к объему памяти ЭВМ, который оказывается даже ниже, чем в случае использования метода поиска по симплексу.
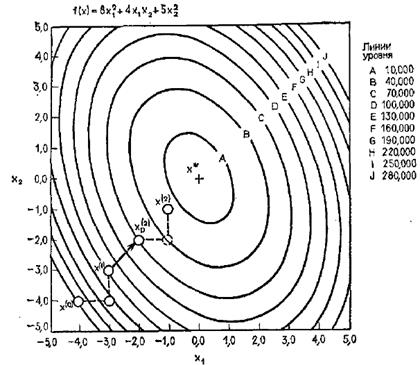 |
Итерации поиска по методу Хука-Дживса на примере
Дата добавления: 2018-09-22; просмотров: 476; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!