Использование оператора defined
Помимо директивы #ifdef существует еще один способ выяснить, определено ли в программе некоторое макроимя. Для этого можно использовать директиву #if в сочетании с оператором времени компиляции defined . Например, чтобы узнать, определено ли макроимя MYFILE , можно использовать одну из следующих команд препроцессорной обработки.
или
При необходимости, чтобы реверсировать условие проверки, можно предварить оператор defined символом "!" . Например, следующий фрагмент кода скомпилируется только в том случае, если макроимя DEBUG не определено.
О роли препроцессора
Препроцессор C++ – прямой потомок препроцессора языка С, причем без каких‑либо усовершенствований. Однако его роль в C++ намного меньше роли, которую играет препроцессор в С. Дело в том, что многие задачи, выполняемые препроцессором в С, реализованы в C++ в виде элементов языка. Страуструп тем самым выразил свое намерение сделать функции препроцессора ненужными, чтобы в конце концов от него можно было бы совсем освободить язык.
На данном этапе препроцессор уже частично избыточен. Например, два наиболее употребительных свойства директивы #define были заменены инструкциями C++. В частности, ее способность создавать константное значение и определять макроопределение, действующее подобно функциям, сейчас совершенно избыточна. В C++ есть более эффективные средства для выполнения этих задач. Для создания константы достаточно определить const ‑переменную. А с созданием встраиваемой (подставляемой) функции вполне справляется спецификатор inline . Оба эти средства лучше работают, чем соответствующие механизмы директивы #define .
|
|
|
Приведем еще один пример замены элементов препроцессора элементами языка. Он связан с использованием однострочного комментария. Одна из причин его создания – разрешить "превращение" кода в комментарий. Как вы знаете, комментарий, использующий /*...*/ ‑стиль, не может быть вложенным. Это означает, что фрагменты кода, содержащие /*...*/ ‑комментарии, одним махом "превратить в комментарий" нельзя. Но это можно сделать с // ‑комментариями, окружив их /*...*/ ‑символами комментария. Возможность "превращения" кода в комментарий делает использование таких директив условной компиляции, как #ifdef , частично избыточным.
Директива #line
Директива #line изменяет содержимое псевдопеременных _ _LINE_ _ и _ _FILE_ _.
Директива #line используется для изменения содержимого псевдопеременных _ _LINE_ _ и _ _FILE_ _ , которые являются зарезервированными идентификаторами (макроименами). Псевдопеременная _ _LINE_ _ содержит номер скомпилированной строки, а псевдопеременная _ _FILE_ _ – имя компилируемого файла. Базовая форма записи этой команды имеет следующий вид.
|
|
|
Здесь номер – это любое положительное целое число, а имя_файла – любой допустимый идентификатор файла. Значение элемента номер становится номером текущей исходной строки, а значение элемента имя_файла – именем исходного файла. Имя_файла – элемент необязательный. Директива #line используется, главным образом, в целях отладки и в специальных приложениях.
Например, следующая программа обязывает начинать счет строк с числа 200. Инструкция cout отображает номер 202, поскольку это – третья строка в программе после директивной инструкции #line 200 .
Директива #pragma
Директива #pragma зависит от конкретной реализации компилятора.
Работа директивы #pragma зависит от конкретной реализации компилятора. Она позволяет выдавать компилятору различные инструкции, предусмотренные создателем компилятора. Общий формат его использования таков.
Здесь элемент имя представляет имя желаемой #pragma ‑инструкции. Если указанное имя не распознается компилятором, директива #pragma попросту игнорируется без сообщения об ошибке.
Важно! Для получения подробной информации о возможных вариантах использования директивы #pragma стоит обратиться к системной документации по используемому вами компилятору. Вы можете найти для себя очень полезную информацию. Обычно #pragma‑инструкции позволяют определить, какие предупреждающие сообщения выдает компилятор, как генерируется код и какие библиотеки компонуются с вашими программами.
|
|
|
Операторы препроцессора "#" и "##"
В C++ предусмотрена поддержка двух операторов препроцессора: "#" и "##" . Эти операторы используются совместно с директивой #define . Оператор "#" преобразует следующий за ним аргумент в строку, заключенную в кавычки. Рассмотрим, например, следующую программу.
Препроцессор C++ преобразует строку
в строку
Оператор используется для конкатенации двух лексем. Рассмотрим пример.
Препроцессор преобразует строку
в строку
Если эти операторы вам кажутся странными, помните, что они не являются операторами "повседневного спроса" и редко используются в программах. Их основное назначение – позволить препроцессору обрабатывать некоторые специальные ситуации.
|
|
|
Зарезервированные макроимена
В языке C++ определено шесть встроенных макроимен.
Рассмотрим каждое из них в отдельности.
Макросы _ _LINE_ _ и _ _FILE_ _ описаны при рассмотрении директивы #line выше в этой главе. Они содержат номер текущей строки и имя файла компилируемой программы.
Макрос _ _DATE_ _ представляет собой строку в формате месяц/день/год , которая означает дату трансляции исходного файла в объектный код.
Время трансляции исходного файла в объектный код содержится в виде строки в макросе _ _TIME_ _ . Формат этой строки следующий: часы.минуты.секунды .
Точное назначение макроса _ _STDC_ _ зависит от конкретной реализации компилятора. Как правило, если макрос _ _STDC_ _ определен, то компилятор примет только стандартный С/С++‑код, который не содержит никаких нестандартных расширений.
Компилятор, соответствующий ANSI/ISO‑стандарту C++, определяет макрос _ _cplusplus как значение, содержащее по крайней мере шесть цифр. "Нестандартные" компиляторы должны использовать значение, содержащее пять (или даже меньше) цифр.
Мысли "под занавес"
Мы преодолели немалый путь: длиной в целую книгу. Если вы внимательно изучили все приведенные здесь примеры, то можете смело назвать себя программистом на C++. Подобно многим другим наукам, программирование лучше всего осваивать на практике, поэтому теперь вам нужно писать побольше программ. Полезно также разобраться в С++‑программах, написанных другими (причем разными) профессиональными программистами. При этом важно обращать внимание на то, как программа оформлена и реализована. Постарайтесь найти в них как достоинства, так и недостатки. Это расширит диапазон ваших представлений о программировании. Подумайте также над тем, как можно улучшить существующий код, применив контейнеры и алгоритмы библиотеки STL. Эти средства, как правило, позволяют улучшить читабельность и поддержку больших программ. Наконец, просто больше экспериментируйте! Дайте волю своей фантазии и вскоре вы почувствуете себя настоящим С++‑программистом!
Для продолжения теоретического освоения C++ предлагаю обратиться к моей книге Полный справочник по C++ , М. : Издательский дом "Вильямс". Она содержит подробное описание элементов языка C++ и библиотек.
Приложение А: С‑ориентированная система ввода‑вывода
Это приложение содержит краткое описание С‑системы ввода‑вывода. Несмотря на то что вы предполагаете использовать С++‑систему ввода‑вывода, есть ряд причин, по которым вам все‑таки следует понимать основы С‑ориентированной системы ввода‑вывода. Во‑первых, если вам придется работать с С‑кодом (особенно, если возникнет необходимость его перевода в С++‑код), то вам нужно знать, как работает С‑система ввода‑вывода. Во‑вторых, часто в одной и той же программе используются как С‑, так и С++‑операции ввода‑вывода. Это особенно характерно для очень больших программ, отдельные части которых писались разными программистами в течение довольно длительного периода времени. В‑третьих, большое количество существующих С‑программ продолжают находиться в эксплуатации и нуждаются в поддержке. Наконец, многие книги и периодические издания содержат программы, написанные на С. Чтобы понимать эти С‑программы, необходимо понимать основы функционирования С‑системы ввода‑вывода.
Узелок на память. Для С++‑программ необходимо использовать объектно‑ориентированную С++‑систему ввода‑вывода.
В этом приложении описаны наиболее употребительные С‑ориентированные функции ввода‑вывода. Однако стандартная С‑библиотека содержит такое огромное количество функций ввода‑вывода, что мы не в силах рассмотреть их здесь в полном объеме. Если же вам придется серьезно погрузиться в С‑программирование, то рекомендую обратиться к справочной литературе.
Система ввода‑вывода языка С требует включать в программы заголовочный файл stdio.h (ему соответствует заголовок <cstdio> , отвечающий новому стилю). Каждая С‑программа должна использовать заголовочный файл stdio.h , поскольку язык С не поддерживает С++‑стиль включения заголовков. С++‑программа может работать с использованием любого из этих двух вариантов. Заголовок <cstdio> помещает свое содержимое в пространство имен std , а заголовочный файл stdio.h – в глобальное пространство имен, что соответствует С‑ориентации. В этом приложении в качестве примеров приведены С‑программы, поэтому они используют С‑стиль включения заголовочного файла stdio.h и не требуют установки пространства имен.
И еще. Как отмечалось в главе 1, стандарт языка С был обновлен в 1999 году и получил название стандарта С99. В то время в С‑систему ввода‑вывода было внесено несколько усовершенствований. Но поскольку C++ опирается на стандарт С89, то он не поддерживает средств, которые были добавлены в стандарт С99. (Более того, на момент написания этой книги ни один из широко доступных компиляторов C++ не поддерживал стандарт С99. Да и ни одна из широко распространяемых программ не использовала средства стандарта С99.) Поэтому здесь не описываются средства, внесенные в С‑систему ввода‑вывода стандартом С99. Если же вас интересует язык С, включая полное описание его системы ввода‑вывода и средств, добавленных стандартом С99, я рекомендую обратиться к моей книге Полный справочник по С , М.: Издательский дом "Вильямс".
Использование потоков в С‑системе ввода‑вывода
Подобно С++‑системе ввода‑вывода, С‑ориентированная система ввода‑вывода опирается на понятие потока. В начале работы программы автоматически открываются три заранее определенных текстовых потока: stdin , stdout и stderr . Их называют стандартными потоками ввода данных (входной поток), вывода данных (выходной поток) и ошибок соответственно. (Некоторые компиляторы открывают также и другие потоки, которые зависят от конкретной реализации системы.) Эти потоки представляют собой С‑версии потоков cin , cout и cerr соответственно. По умолчанию они связаны с соответствующим системным устройством.

Помните, что большинство операционных систем, включая Windows, позволяют перенаправлять потоки ввода‑вывода, поэтому функции чтения и записи данных можно перенаправлять на другие устройства. Никогда не пытайтесь явно открывать или закрывать эти потоки.
Каждый поток, связанный с файлом, имеет структуру управления файлом типа FILE . Эта структура определена в заголовочном файле stdio.h . Вы не должны модифицировать содержимое этого блока управления файлом.
Функции printf() и scanf()
Двумя самыми популярными С‑функциями ввода‑вывода являются printf() и scanf() . Функция printf() записывает данные в стандартное устройство вывода (консоль), а функция scanf() , ее дополнение, считывает данные с клавиатуры. Поскольку язык С не поддерживает перегрузку операторов и не использует операторы "<<" и ">>" в качестве операторов ввода‑вывода, то для консольного ввода‑вывода используются именно функции printf() и scanf() . Обе они могут обрабатывать данные любых встроенных типов, включая символы, строки и числа. Но поскольку эти функции не являются объектно‑ориентированными, их нельзя использовать непосредственно для ввода‑вывода объектов классов, создаваемых программистом.
Функция printf()
Функция printf() имеет такой прототип:
Первый аргумент, fmt_string , определяет способ отображения всех последующих аргументов. Этот аргумент часто называют строкой форматирования . Она состоит из элементов двух типов: текста и спецификаторов формата. К элементам первого типа относятся символы (текст), которые выводятся на экран. Элементы второго типа (спецификаторы формата) содержат команды форматирования, которые определяют способ отображения аргументов. Команда форматирования начинается с символа процента, за которым следует код формата. Спецификаторы формата перечислены в табл. А.1. Количество аргументов должно в точности совпадать с количеством команд форматирования, причем совпадение обязательно и в порядке их следования. Например, при вызове следующей функции printf() .
На экране будет отображено: "Привет с 10 всем! " .
Функция printf() возвращает число реально выведенных символов. Отрицательное значение возврата свидетельствует об ошибке.
Команды формата могут иметь модификаторы, которые задают ширину поля, точность (количество десятичных разрядов) и признак выравнивания по левому краю. Целое значение, расположенное между знаком % и командой форматирования , выполняет роль спецификатора минимальной ширины поля . Наличие этого спецификатора приведет к тому, что результат будет заполнен пробелами или нулями, чтобы гарантированно обеспечить для выводимого значения заданную минимальную длину. Если выводимое значение (строка или число) больше этого минимума, оно будет выведено полностью, несмотря на превышение минимума. По умолчанию в качестве заполнителя используется пробел. Для заполнения нулями нужно поместить 0 перед спецификатором ширины поля. Например, строка форматирования %05d дополнит выводимое число нулями (их будет меньше пяти), чтобы общая длина была равной пяти символам.


Точное значение модификатора точности зависит от кода формата, к которому он применяется. Чтобы добавить модификатор точности, поставьте за спецификатором ширины поля десятичную точку, а после нее – значение спецификации точности. Для форматов а , А , е , Е , f и F модификатор точности определяет число выводимых десятичных знаков. Например, строка форматирования %10.4f обеспечит вывод числа, ширина которого составит не меньше десяти символов, с четырьмя десятичными знаками. Применительно к целым или строкам, число, следующее за точкой, задает максимальную длину поля. Например, строка форматирования %5.7s отобразит строку длиной не менее пяти, но не более семи символов. Если выводимая строка окажется длиннее максимальной длины поля, конечные символы будут отсечены.
По умолчанию все выводимые значения выравниваются по правому краю: если ширина поля больше выводимого значения, оно будет выровнено по правому краю поля. Чтобы установить выравнивание по левому краю, поставьте знак "минус" сразу после знака % . Например, строка форматирования %‑10.2f обеспечит выравнивание вещественного числа (с двумя десятичными знаками в 10‑символьном поле) по левому краю. Рассмотрим программу, в которой демонстрируется использование спецификаторов ширины поля и выравнивания по левому краю.
При выполнении эта программа отображает такие результаты.
Существуют два модификатора команд форматирования, которые позволяют функции printf() отображать короткие (short ) и длинные (long ) целые. Эти модификаторы могут применяться к спецификаторам типа d , i , о , и , х и X . Модификатор l уведомляет функцию printf() о длинном формате значения. Например, строка %ld означает, что должно быть выведено длинное целое. Модификатор h указывает на применение короткого формата. Следовательно, строка %hu означает, что выводимое целочисленное значение имеет тип short unsigned .
Чтобы обозначить, что соответствующий аргумент указывает на длинное целое, к спецификатору n можно применить модификатор l . Для указания на короткое целое примените к спецификатору n модификатор h .
Если вы используете современный компилятор, который поддерживает добавленные в 1995 году средства работы с символами широкого формата (двухбайтовыми символами), то можете задействовать модификатор l применительно к спецификатору с , чтобы уведомить об использовании двухбайтовых символов. Кроме того, модификатор l можно использовать с командой формата s для вывода строки двухбайтовых символов.
Модификатор l можно также поставить перед командами форматирования вещественных чисел е , Е , f , F , g и G . В этом случае он уведомит о выводе значения типа long double .
Функция scanf()
Функция scanf() – это С‑функция общего назначения ввода данных с консольного устройства. Она может считывать данные всех встроенных типов и автоматически преобразует числа в соответствующий внутренний формат. Ее поведение во многом обратно поведению функции printf() . Общий формат функции scanf() таков.
Управляющая строка, задаваемая параметром fmt_string , состоит из символов трех категорий:
■ спецификаторов формата;
■"пробельных" символов (пробелы, символы табуляции и пустой строки);
■ символов, отличных от "пробельных".
Функция scanf() возвращает количество введенных полей, а при возникновении ошибки – значение EOF (оно определено в заголовке stdio.h ).
Спецификаторы формата – им предшествует знак процента (% ) – сообщают, какого типа данное будет считано следующим. Например, спецификатор %s прочитает строку, а %d – целое значение. Эти коды приведены в табл. А.2.
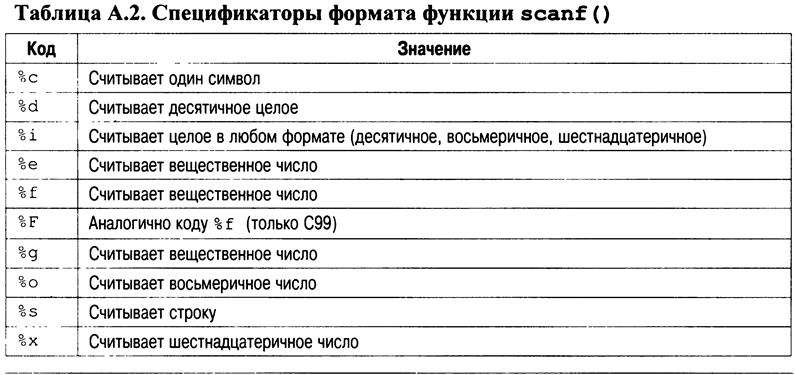

Пробельные символы в строке форматирования заставляют функцию scanf() пропустить один или несколько пробельных символов во входном потоке. Под пробельным символом подразумевается пробел, символ табуляции или символ новой строки. По сути, один пробельный символ в управляющей строке заставит функцию scanf() считывать, но не сохранять любое количество (пусть даже нулевое) пробельных символов до первого непробельного.
"Непробельный" символ в строке форматирования заставляет функцию scanf() прочитать и отбросить соответствующий символ. Например, при использовании строки форматирования %d , %d функция scanf() сначала прочитает целое значение, затем прочитает и отбросит запятую и наконец прочитает еще одно целое. Если заданный символ не обнаружится, работа функции scanf() будет завершена.
Все переменные, используемые для приема значений с помощью функции scanf() , должны передаваться посредством их адресов. Это значит, что все аргументы должны быть указателями на переменные. (С не поддерживает ссылки или ссылочные параметры.) Передача указателей позволяет функции scanf() изменять содержимое любого аргумента. Например, если нужно считать целочисленное значение в переменную count , используйте следующий вызов функции scanf() .
Строки обычно считываются в символьные массивы, а имя массива (без индекса) является адресом первого элемента в этом массиве. Поэтому, чтобы считать строку в символьный массив address , используйте такой код.
В этом случае параметр address уже является указателем, и поэтому его не нужно предварять оператором "&" .
Элементы входного потока, считываемые функцией scanf() , должны быть разделены пробелами, символами табуляции или новой строки. Такие символы, как запятая, точка с запятой и тому подобное, не распознаются в качестве разделителей. Это означает, что инструкция:
Примет значения, введенные как 10 20 , но наотрез откажется от "блюда", поданного в виде 10,20 .
Подобно printf() , в функции scanf() спецификаторы формата по порядку сопоставляются с переменными, перечисленными в списке аргументов.
Символ стоящий "*" после знака "%" и перед кодом формата, прочитает данные заданного типа, но запретит их присваивание переменной. Следовательно, инструкция
при вводе данных в виде 10/20 поместит значение 10 в переменную х , отбросит знак деления и присвоит значение 20 переменной у .
Команды форматирования могут содержать модификатор максимальной длины поля. Он представляет собой целое число, располагаемое между знаком "%" и кодом формата, которое ограничивает количество символов, считываемых для любого поля. Например, если вы хотите прочитать в переменную str не более 20 символов, используйте следующую инструкцию.
Если входной поток содержит более 20 символов, то при последующем выполнении операции ввода считывание начнется с того места, в котором "остановился" предыдущий вызов функции scanf() . Например, если (при использовании данного примера) вводится такая строка символов
то в переменную str будут приняты только первые 20 символов (до буквы 'Т' ), поскольку команда форматирования здесь содержит модификатор максимальной длины поля.
Это означает, что остальные символы, "UVWXYZ" , не будут использованы вообще. В случае другого вызова функции scanf() .
символы "UVWXYZ" поместились бы в переменной str . При обнаружении "пробельного" символа ввод данных для поля может завершиться до достижения максимальной длины поля. В этом случае функция scanf() переходит к считыванию следующего поля.
Несмотря на то что пробелы, символы табуляции и новой строки используются в качестве разделителей полей, при считывании одиночного символа они читаются подобно любому другому символу. Например, если входной поток состоит из символов х у , то инструкция
поместит символ х в переменную а , пробел – в переменную b и символ у – в переменную с .
Функцию scanf() можно также использовать в качестве набора сканируемых символов (scanset ). В этом случае определяется набор символов, которые могут быть считаны функцией scanf() и присвоены соответствующему массиву символов. Функция scanf() продолжает считывать символы и помещать их в соответствующий символьный массив до тех пор, пока не встретится символ, отсутствующий в заданном наборе. После этого она переходит к следующему полю (если такое имеется).
Для определения такого набора необходимо заключить символы, подлежащие сканированию, в квадратные скобки. Открывающая квадратная скобка должна следовать сразу за знаком процента. Например, следующий набор сканируемых символов говорит о том, что необходимо прочитать только символы X , Y и Z .
Соответствующая набору переменная должна быть указателем на массив символов. При возврате из функции scanf() этот массив будет содержать строку с завершающим нулем, состоящую из считанных символов. Например, следующая программа использует набор сканируемых символов для считывания цифр в массив s1 . Если будет введен символ, отличный от цифры, массив s1 завершится нулевым символом, а остальные символы будут считываться в массив s2 до тех пор, пока не будет введен следующий "пробельный" символ.
Многие компиляторы позволяют с помощью дефиса задать в наборе сканируемых символов диапазон. Например, при выполнении следующей инструкции функция scanf() будет принимать символы от А до Z .
При этом в наборе сканируемых символов можно задать даже несколько диапазонов. Например, эта программа считывает сначала цифры, а затем буквы.
Если первый символ в наборе сканируемых символов является знаком вставки (^ ), то получаем обратный эффект: вводимые данные будут считываться до первого символа из заданного набора символов, т.е. знак вставки заставляет функцию scanf() принимать любые символы, которые не определены в наборе. В следующей модификации предыдущей программы знак вставки используется для запрещения считывания символов, тип которых указан в наборе сканируемых символов:
Важно помнить, что набор сканируемых символов различает прописные и строчные буквы. Следовательно, если вы хотите сканировать как прописные, так и строчные буквы, задайте их отдельно.
Некоторые спецификаторы формата могут использовать такие модификаторы, которые точно указывают тип переменной, принимающей данные. Чтобы прочитать длинное целое, поставьте перед спецификатором формата модификатор l , а чтобы прочитать короткое целое – модификатор h . Эти модификаторы можно использовать с кодами формата d , i , o , u , x и n .
По умолчанию спецификаторы f , е и g заставляют функцию scanf() присваивать данные переменным типа float . Если поставить перед одним из этих спецификаторов формата модификатор l , функция scanf() присвоит прочитанное данное переменной типа double . Использование же модификатора L означает, что переменная, принимающая значение, имеет тип long double .
Модификатор l можно применить и к спецификатору с , чтобы обозначить указатель на двухбайтовый символ с типом данных wchar_t (если ваш компилятор соответствует стандарту C++). Модификатор l можно также использовать с кодом формата s , чтобы обозначить указатель на строку двухбайтовых символов. Кроме того, модификатор l можно использовать для модификации набора сканируемых двухбайтовых символов.
С‑система обработки файлов
Несмотря на то что файловая система в С отличается от той, что используется в C++, между ними есть много общего. С‑система обработки файлов состоит из нескольких взаимосвязанных функций. Наиболее популярные из них перечислены в табл. А.З.
Общий поток, который "цементирует" С‑систему ввода‑вывода, представляет собой файловый указатель (file pointer). Файловый указатель – это указатель на информацию о файле, которая включает его имя, статус и текущую позицию. По сути, файловый указатель идентифицирует конкретный дисковый файл и используется потоком, чтобы сообщить всем С‑функциям ввода‑вывода, где они должны выполнять операции. Файловый указатель – это переменная‑указатель типа FILE , который определен в заголовке stdio.h .


Функция fopen()
Функция fopen() выполняет три задачи.
1. Открывает поток.
2. Связывает файл с потоком.
3. Возвращает указатель типа FILE на этот поток.
Чаще всего под файлом подразумевается дисковый файл. Функция fopen() имеет такой прототип.
Здесь параметр filename указывает на имя открываемого файла, а параметр mode – на строку, содержащую нужный статус (режим) открытия файла. Возможные значения параметра mode показаны в приведенной табл. А.4. Параметр filename должен представлять строку символов, составляющих имя файла, которое допустимо в данной операционной системе. Эта строка может включать спецификацию пути, если действующая среда поддерживает такую возможность.
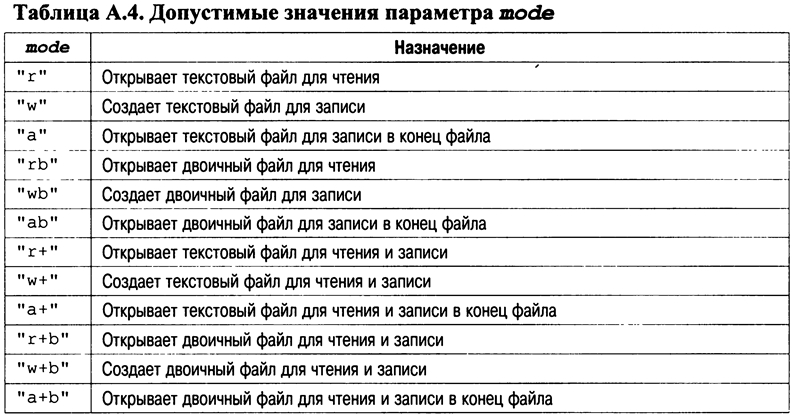
Если функция fopen() успешно открыла заданный файл, она возвращает указатель FILE . Этот указатель идентифицирует файл и используется большинством других файловых системных функций. Он не должен подвергаться модификации кодом программы. Если файл не удается открыть, возвращается нулевой указатель.
Как видно из табл. А.4, файл можно открывать либо в текстовом, либо в двоичном режиме. При открытии в текстовом режиме выполняются преобразования некоторых последовательностей символов. Например, символы новой строки преобразуются в последовательности символов "возврат каретки" /"перевод строки" . В двоичном режиме подобные преобразования не выполняются.
Если вам нужно открыть файл test для записи, используйте следующую инструкцию.
Здесь переменная fp имеет тип FILE* . Однако зачастую для открытия файла используется такой код.
При таком методе выявляется любая ошибка, связанная с открытием файла (например, при использовании защищенного от записи или заполненного диска), и только после этого можно предпринимать попытку записи в заданный файл. NULL – это макроимя, определенное в заголовке stdio.h .
Если вы используете функцию fopen() , чтобы открыть файл исключительно для выполнения операций вывода (записи), любой уже существующий файл с заданным именем будет стерт, и вместо него будет создан новый. Если файл с таким именем не существует, он будет создан. Если вам нужно добавлять данные в конец файла, используйте режим "a" . Если окажется, что указанный файл не существует, он будет создан. Чтобы открыть файл для выполнения операций чтения, необходимо наличие этого файла. В противном случае функция возвратит значение ошибки. Наконец, если файл открывается для выполнения операций чтения‑записи, то в случае его существования он не будет удален; но если его нет, он будет создан.
Функция fputc()
Функция fputc() используется для вывода символов в поток, предварительно открытый для записи с помощью функции fopen() . Ее прототип имеет следующий вид.
Здесь параметр fp – файловый указатель, возвращаемый функцией fopen() , а параметр ch – выводимый символ. Файловый указатель сообщает функции fputc() , в какой дисковый файл необходимо записать символ. Несмотря на то что параметр ch имеет тип int , в нем используется только младший байт.
При успешном выполнении операции вывода функция fputc() возвращает записанный в файл символ, в противном случае – значение EOF .
Функция fgetc()
Функция fgetc() используется для считывания символов из потока, открытого в режиме чтения с помощью функции fopen() . Ее прототип имеет следующий вид.
Здесь параметр fp – файловый указатель, возвращаемый функцией fopen() . Несмотря на то что функция fgetс() возвращает значение типа int , его старший байт равен нулю.
При возникновении ошибки или достижении конца файла функция fgetc() возвращает значение EOF . Следовательно, для того, чтобы считать все содержимое текстового файла (до самого конца), можно использовать следующий код.
Функция feof()
Файловая система в С может также обрабатывать двоичные данные. Если файл открыт в режиме ввода двоичных данных, то не исключено, что может быть считано целое число, равное значению EOF . В этом случае при использовании такого кода проверки достижения конца файла, как ch != EOF , будет создана ситуация, эквивалентная получению сигнала о достижении конца файла, хотя в действительности физический конец файла может быть еще не достигнут. Чтобы решить эту проблему, в языке С предусмотрена функция feof() , которая используется для определения факта достижения конца файла при считывании двоичных данных. Ее прототип имеет такой вид.
Здесь параметр fp идентифицирует файл. Функция feof() возвращает ненулевое значение, если конец файла был‑таки достигнут; в противном случае – нуль. Таким образом, при выполнении следующей инструкции будет считано все содержимое двоичного файла.
Безусловно, этот метод применим и к текстовым файлам.
Функция fclose()
Функция fclose() закрывает поток, который был открыт в результате обращения к функции fopen() . Она записывает в файл все данные, еще оставшиеся в дисковом буфере, и закрывает файл на уровне операционной системы. При вызове функции fclose() освобождается блок управления файлом, связанный с потоком, что делает его доступным для повторного использования. Вероятно, вам известно о существовании ограничения операционной системы на количество файлов, которые можно держать открытыми в любой момент времени, поэтому, прежде чем открывать следующий файл, рекомендуется закрыть все файлы, уже ненужные для работы.
Функция fclose() имеет следующий прототип,
Здесь параметр fp – файловый указатель, возвращаемый функцией fopen() . При успешном выполнении функция fclose() возвращает нуль; в противном случае возвращается значение EOF . Попытка закрыть уже закрытый файл расценивается как ошибка. При удалении носителя данных до закрытия файла будет сгенерирована ошибка, как и в случае недостатка свободного пространства на диске.
Дата добавления: 2018-09-22; просмотров: 899; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!