Подсистема представления знаний
Автоматизированное формирование модели предметной области и решаемой задачи. Реализуется, как правило, на персональных компьютерах, программное обеспечение которых пишется на специальных языках программирования.
Подсистема управления данными
Организуется на компьютерах с помощью подпрограммных систем управления обработкой данных и организации вычислительного процесса.
При больших объемах накапливаемой на компьютере и циркулирующей в сети информации на предприятиях, где внедрена информационная технология, могут создаваться специальные службы такие, как администратор баз данных, администратор вычислительной сети и т.п.
Физический уровень базовой информационной технологии определяет возможность ее реализации на типовых программно-аппаратных средствах.
Включает подсистемы накопления, обмена, обработки, управления данных, а также подсистему формализации знаний.
Подсистема накопления данных реализуется на основе типовых банков, обеспечивает организацию, хранение и накопление данных.
Подсистема обмена строится на основе типовых локальных информационно-вычислительных сетей различных уровней, позволяющих осуществлять обмен вычислительным ресурсом между абонентскими и главными вычислительными машинами
Подсистема обработкиданных реализуется на базе стандартных ЭВМ различных уровней. На верхнем уровне - главные вычислительные машины; на среднем уровне - абонентские вычислительные машины; на нижнем уровне - персональные ЭВМ. Подсистема управленияданными реализуется в виде системы управления базой данных, сетью и организацией вычислительного процесса.
|
|
|
Базируется на основе баз знаний, которые формируются в рамках интеллектуальных систем.
Процесс преобразования информации в данные
Прежде, чем превратиться в данные, информация должна быть сначала собрана, соответствующим образом подготовлена, и только после этого введена в ЭВМ, представ в виде данных на машинных носителях информации.
Информационные технологии в настоящее время можно классифицировать по ряду признаков в частности по:
• способу реализации в АИС;
• степени охвата задач управления;
• классу реализуемых технологических операций;
• типу пользовательского интерфейса;
• способу построения сети ЭВМ;
• обслуживаемым предметным областям.
По способу реализации ИТ в АИСвыделяют:
- традиционно сложившиеся информационные технологии;
- новые информационные технологии.
Традиционные ИТ(до массового использования ПЭВМ) -снижение трудоемкости при формировании регулярной отчетности.
Новые информационные технологии связаны с информационным обеспечением процесса управления в режиме реального времени.
|
|
|
По степени охвата ИТ задач управлениявыделяют:
- электронная обработка данных;
- автоматизация функций управления;
- поддержка принятия решения;
- электронный офис;
- экспертная поддержка.
Электронную обработку данных, используются для автоматизации функциональных задач управления, формирования регулярной отчетности и работы в информационно-справочном режиме для подготовки управленческих решений.
Поддержка принятия решенийпредусматривает широкое использование экономико-математических методов, моделей и ППП для аналитической работы и формирования прогнозов, составления бизнес-планов, обоснованных оценок и выводов по изучаемым процессам производственно-хозяйственной практики.
ИТ электронного офиса и экспертной поддержки решений. Эти два варианта ИТ ориентированы на использование последних достижений в области новейших подходов к автоматизации работы специалистов и руководителей. Создание для них наиболее благоприятных условий выполнения профессиональных функций.
По классу реализуемых технологических операций:
- работа с текстовым редактором и табличным процессором;
- работа с СУБД;
- работа с графическими объектами;
- мультимедийные системы;
- гипертекстовые системы.
По типу пользовательского интерфейса можно рассматривать:
|
|
|
- пакетные;
- диалоговые;
- сетевые.
Пакетная ИТ исключает возможность пользователя влиять на обработку информации пока она воспроизводится в автоматическом режиме.
диалоговая ИТ предоставляет неограниченную возможность пользователю взаимодействовать с ресурсами в реальном масштабе времени.
Интерфейс сетевой ИТ предоставляет пользователю средства теледоступа к территориально распределенным информационным и вычислительным ресурсам.
По способу построения сети:
- ИТ локальных сетей;
- ИТ распределенных сетей;
- ИТ глобальных сетей;
- ИТ многоуровневых сетей.
По обслуживаемым предметным областям:
- ИТ бухгалтерского учета;
- ИТ банковской деятельности;
- ИТ налоговой деятельности;
- ИТ страховой деятельности и др.
Деятельность работников сферы управления (бухгалтеров, специалистов кредитно-банковской системы, менеджеров, маркетологов и т.д.) в настоящее время ориентирована на использование развитых информационных технологий.
8. Оценка эффективности ИТ. Методика оценки инвестиций в ИТ.
Для проведения оценки надо предварительно установить факторы, обеспечивающие эффективность; направления действия этих факторов; количественные показатели степени влияния данных факторов; методы расчета этих показателей.
|
|
|
Определение направления действия этих факторов сводится к выяснению, на что влияют разработка и внедрение новых ИТ(повышение эффективности труда отдельных работников, управленческой деятельности подразделений, методов управления, конкретных управленческих решений, внедряемого бизнес-процесса или всей системы управления в целом).
Для проведения оценки определяется превышение интегральных результатов от внедрения новыхИТ над интегральными затратами. Чем больше значение, тем эффективнее инвестиционный проект ИТ.
Для обоснования инвестиций в информационные технологии предлагается использовать методологию оценки их совокупной ценности для бизнеса (TVO).
TVO определяются следующие параметры:
• ценность для бизнеса, которую принесет ИТ-инициатива;
• риски;
• способность организации воплотить решение успешно.
Применение методики TVO:
· Шаг 1: Четкая формулировка целей проекта и идентификация типа инвестиций.
· Шаг 2: Оценка преимуществ для бизнеса.
· Шаг 3: определение функциональных возможностей (capabilities), реализуемых внедряемымиИТ.
· Шаг 4: Оценка финансовой составляющей проекта.
· Шаг 6: Оценка прямых выгод от реализации проекта.
· Шаг 7: Оценка косвенных выгод, связанных с влиянием проекты в будущем.
9. Реляционная модель БД. Иерархическая модель БД. Сетевая модель БД.
1)Рассмотрим реляционную модель данных, в которой данные хранятся в виде двумерных таблиц.
Таблицы обладают следующими свойствами:
- каждая ячейка таблицы является одним элементом данных;
- каждый столбец содержит данные одного типа (числа, текст и т. п.);
- каждый столбец имеет уникальное имя;
- таблицы организуются так, чтобы одинаковые строки отсутствовали;
- порядок следования строк и столбцов произвольный.
Для идентификации записей выделяют следующие виды ключей – полей, определяющих запись:
- первичный: однозначно определяет запись;
- вторичный: выполняет роль поисковых и группировочных признаков и позволяет найти несколько записей.
Первичный ключ должен обладать следующими свойствами:
- уникальность: не должно существовать двух или более записей, имеющих одинаковые значения полей, входящих в первичный ключ;
- не избыточность: первичный ключ не должен содержать поля, удаление которых из ключа не нарушит его уникальность
Пример базы данных, содержащей сведения о подразделениях предприятия и работающих в них сотрудниках, применительно к реляционной модели будет иметь вид:
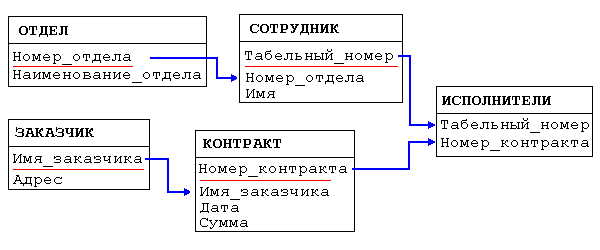
Иерархическаямодель— самая ранняя модель представления сложной структуры данных. Информация в иерархической базе организована по принципу древовидной структуры, в виде отношений «предок-потомок». Каждая запись может иметь не более одной родительской записи и несколько подчиненных. Связи записей реализуются в виде физических указателей с одной записи на другую. Основной недостаток иерархической структуры базы данных — невозможность реализовать отношения «много-ко-многим», а также ситуации, когда запись имеет несколько предков.
Иерархические базы данных. Иерархические базы данных графически могут быть представлены как перевернутое дерево, состоящее из объектов различных уровней. Верхний уровень (корень дерева) занимает один объект, второй - объекты второго уровня и так далее. Иерархической базой данных является Каталог папок Windows, с которым можно работать, запустив Проводник. Верхний уровень занимает папка Рабочий стол. На втором уровне находятся папки Мой компьютер, Мои документы, Сетевое окружение и Корзина,
Сетевая модель данных пришла на смену более простой и понятной иерархической. По своей сути сетевая модель сильно похожа на иерархическую, у нее тоже имеются корневые элементы, в которые заносится наиболее важная информация. Особенность сетевой модели - здесь есть несколько маршрутов. Сетевая модель данных предоставляет возможность построения более сложных структур данных.В сетевых моделях данных имеются указатели в обоих направлениях, которые соединяют информацию..
Сетевая модель данных - это логическая модель данных, представляющая их сетевыми структурами и связанные отношениями один-к-одному или один-ко-многим.
10. Назначение и основные возможности системы управления базами данных.
Назначение - создания баз данных, работы с данными.
С помощью средств создания БД проектировщик, переводит логическую модель в физическую структуру.
Разрабатывает программы, реализующие основные операции с данными (в реляционных БД- это реляционные операции). При проектировании привлекаются визуальные средства, т.е. объекты, и программа-отладчик, с помощью которой соединяются и тестируются отдельные блоки разработанной программы управления конкретной БД.
СУБД принципиально различаются по моделям БД, с которыми они работают.
Если модель БД реляционная, то нужно использовать реляционную СУБД, если сетевая - сетевую СУБД, и т.д.
11. Этапы проектирования базы данных. Создание новой базы данных.
Первый этап. Планирование разработки базы данных. На этом этапе выделятся наиболее эффективный способ реализации этапов жизненного цикла системы.
Второй этап. Определение требований к системе. Производится определение диапазона действий и границ приложения базы данных, а также производится сбор и анализ требований пользователей.
Третий этап. Проектирование концептуальной модели БД. Процесс создания БД начинается с определения концептуальной модели, представляющей объекты и их взаимосвязи без указания способов их физического хранения. Усилия на этом этапе должны быть направлены на структуризацию данных и выявление взаимосвязей между ними.
Четвертый этап. Построение логической модели. Построение логической модели начинается с выбора модели данных. При выборе модели важную роль играет ее простота, наглядность и сравнение естественной структуры данных с моделью, ее представляющей. Например, если иерархическая структура присуща самим данным, то выбор иерархической модели будет предпочтительнее. Но зачастую этот выбор определяется успехом (или наличием) той или иной СУБД. То есть разработчик выбирает СУБД, а не модель данных. Таким образом, на этом этапе концептуальная модель транслируется в модель данных, совместимую с выбранной СУБД.
Пятый этап. Построение физической модели. Физическая модель определяет размещение данных, методы доступа и технику индексирования. На этапе физического проектирования мы привязываемся к конкретной СУБД и расписываем схему данных более детально, с указанием типов, размеров полей и ограничений.
1. Запустите MS Access 2007.
2. Нажмите на кнопку «Новая база данных».
3. В появившемся окне введите название БД и выберите «Создать»
12. Семантическое моделирование. Основные понятия ER-диаграмм.
Семантическое моделированиепредставляет собой моделирование структуры данных, опираясь на смысл этих данных. В качестве инструмента семантического моделирования используются различные варианты диаграмм сущность-связь (ER - Entity-Relationship).
Первый вариант модели сущность-связь был предложен в 1976 г. Питером Пин-ШэнЧеном. В дальнейшем многими авторами были разработаны свои варианты подобных моделей (нотация Мартина, нотация IDEF1X, нотация Баркера и др.). Кроме того, различные программные средства, реализующие одну и ту же нотацию, могут отличаться своими возможностями.
По сути, все варианты диаграмм сущность-связь исходят из одной идеи - рисунок всегда нагляднее текстового описания. Все такие диаграммы используют графическое изображение сущностей предметной области, их свойств (атрибутов), и взаимосвязей между сущностями.
Основные понятия ER-диаграмм (близко к нотации Баркера)
Определение 1. Сущность - это класс однотипных объектов, информация о которых должна быть учтена в модели.
Каждая сущность должна иметь наименование, выраженное существительным в единственном числе.
Примерами сущностей могут быть такие классы объектов как "Поставщик", "Сотрудник", "Накладная".
Каждая сущность в модели изображается в виде прямоугольника с наименованием:

Определение 2. Экземпляр сущности - это конкретный представитель данной сущности.
Например, представителем сущности "Сотрудник" может быть "Сотрудник Иванов".
Экземпляры сущностей должны быть различимы, т.е. сущности должны иметь некоторые свойства, уникальные для каждого экземпляра этой сущности.
Определение 3. Атрибут сущности - это именованная характеристика, являющаяся некоторым свойством сущности.
Наименование атрибута должно быть выражено существительным в единственном числе (возможно, с характеризующими прилагательными).
Примерами атрибутов сущности "Сотрудник" могут быть такие атрибуты как "Табельный номер", "Фамилия", "Имя", "Отчество", "Должность", "Зарплата" и т.п.
Атрибуты изображаются в пределах прямоугольника, определяющего сущность:

Определение 4. Ключ сущности - это неизбыточный набор атрибутов, значения которых в совокупности являются уникальными для каждого экземпляра сущности. Неизбыточность заключается в том, что удаление любого атрибута из ключа нарушается его уникальность.
Сущность может иметь несколько различных ключей.
Ключевые атрибуты изображаются на диаграмме подчеркиванием:

Определение 5. Связь - это некоторая ассоциация между двумя сущностями. Одна сущность может быть связана с другой сущностью или сама с собою.
Связи позволяют по одной сущности находить другие сущности, связанные с нею.
Например, связи между сущностями могут выражаться следующими фразами - "СОТРУДНИК может иметь несколько ДЕТЕЙ", "каждый СОТРУДНИК обязан числиться ровно в одном ОТДЕЛЕ".
Графически связь изображается линией, соединяющей две сущности:

Каждая связь имеет два конца и одно или два наименования. Наименование обычно выражается в неопределенной глагольной форме: "иметь", "принадлежать" и т.п. Каждое из наименований относится к своему концу связи. Иногда наименования не пишутся ввиду их очевидности.
Каждая связь может иметь один из следующих типов связи:
Связь типа один-к-одному означает, что один экземпляр первой сущности (левой) связан с одним экземпляром второй сущности (правой). Связь один-к-одному чаще всего свидетельствует о том, что на самом деле мы имеем всего одну сущность, неправильно разделенную на две.
Связь типа один-ко-многим означает, что один экземпляр первой сущности (левой) связан с несколькими экземплярами второй сущности (правой). Это наиболее часто используемый тип связи. Левая сущность (со стороны "один") называется родительской, правая (со стороны "много") - дочерней.
Связь типа много-ко-многим означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Тип связи много-ко-многим является временным типом связи, допустимым на ранних этапах разработки модели. В дальнейшем этот тип связи должен быть заменен двумя связями типа один-ко-многим путем создания промежуточной сущности.
Каждая связь может иметь одну из двух модальностей связи:

Модальность "может" означает, что экземпляр одной сущности может быть связан с одним или несколькими экземплярами другой сущности, а может быть и не связан ни с одним экземпляром.
Модальность "должен" означает, что экземпляр одной сущности обязан быть связан не менее чем с одним экземпляром другой сущности.
Связь может иметь разную модальность с разных концов.
Описанный графический синтаксис позволяет однозначно читать диаграммы, пользуясь следующей схемой построения фраз:
Каждый экземпляр СУЩНОСТИ 1 МОДАЛЬНОСТЬ СВЯЗИ НАИМЕНОВАНИЕ СВЯЗИ ТИП СВЯЗИ экземпляр СУЩНОСТИ 2 .
Каждая связь может быть прочитана как слева направо, так и справа налево. Например,
Слева направо: "каждый сотрудник может иметь несколько детей".
Справа налево: "Каждый ребенок обязан принадлежать ровно одному сотруднику".
27. Концептуальный уровень базовой информационной технологии( не сокращ)
27. Концептуальный уровень базовой информационной технологии.
Так как средства и методы обработки данных могут иметь разное значение, то различают глобальную, базовую и специальную (конкретную) информационные технологии.
Глобальная ИТ включает в себя модели, методы и средства формирования и использования информационных ресурсов в обществе.
Базовая ИТ ориентируется на определенную область применения (производство, научные исследования, проектирование, обучение и т.д.). Она должна задавать модели, методы и средства решения информационных задач в своей предметной области.
Базовая ИТ может быть представлена совокупностью информационных процессов, процедур и операций (см. рис. 2.1) и направлена на получение качественного информационного продукта из исходного информационного ресурса в соответствии с поставленной задачей. Эта технология может быть рассмотрена на трех уровнях: концептуальном (определяется содержательный аспект, использующий язык соответствующей предметной области), логическом (отображается формальное - модельное - описание на языке информационных или математических моделей) и физическом (описывается реализация на языке программно-аппаратных средств).Применительно к информационной технологии это означает содержательное описание используемых в ней информационных процессов и процедур на концептуальном уровне в виде набора моделей (информационных, математических и т.д.) процессов и их составляющих на логическом уровне и структурную реализацию информационных процессов как совокупности аппаратных средств, системного и прикладного программного обеспечения на физическом уровне.
Специальные (конкретные) ИТ задают обработку данных в определенных типах задач пользователей.
Концептуальная модель базовой информационной технологии содержит информационное описание предметной области (рис. 2.10).
На этой схеме выделены страты (слои) информационных технологий, процессов, процедур и операций. Вертикальной пунктирной линией слева отделены процессы и процедуры, работающие с информационными потоками, в которых преобладает смысловое содержание (происходит преобразование информации в данные и наоборот), в центре - работающие с данными, в которых преобладает синтаксический аспект информации, а справа - работающие со знаниями, в которых преобладает семантический аспект информации.
Если построить цепочку, состоящую из процессов и процедур, перечисленных на рис. 2.10 последовательно слева на право, получится описание во времени процессов преобразования информационного ресурса в информационный продукт (рис. 2.11). Формирование информационного ресурса осуществляется в процессе "Получение" и начинается с процедуры "Сбор", отображающей предметную область (параметры, характеристики, состояние объекта управления). Собранная информация должна быть соответствующим образом подготовлена (осмыслена, структурирована, проверена на полноту, достоверность, непротиворечивость и т.д.). После подготовки и проверки информация может быть передана для преобразования традиционными способами (телефон, курьер, почта, телеграф), а может быть подвергнута алгоритму преобразования в данные, т.е. процессу ввода.
Процедуры сбора, подготовки, проверки и ввода информации в ИТ организационно-экономических систем процесса "Получение" по своей реализации являются в основном ручными (кроме процедур проверки и ввода, которые могут быть частично автоматизированными). В процессе ввода информация преобразуется в данные, имеющие форму цифровых кодов, реализуемых на физическом уровне с помощью различных физических явлений (электрических, магнитных, оптических, механических и т.д.).
Следующие за процессом "Получение" информационные процессы уже производят преобразование данных. Эти процессы протекают в ЭВМ под управлением различных программ. Процесс обработки данных включает в себя процедуры преобразования значений и структур данных путем моделирования, логического вывода и др., а также процедур организации вычислений.
Процесс "Отображение" содержит процедуры преобразования данных в форму, удобную для восприятия: звук, изображение - текстовое, цифровое, графическое, видео, твердая копия на бумаге.
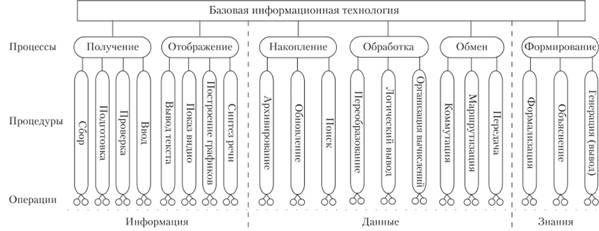
Рис. 2.10. Концептуальная модель базовой информационной технологии
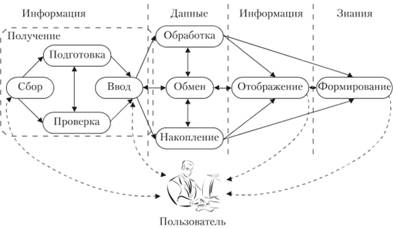
Рис. 2.11. Процессы преобразования ИР
Процесс формирования знаний является составной частью базовой информационной технологии, поскольку ее высшим продуктом является знание. Формирование знания как высшего информационного продукта до сих нор являлось прерогативой человека. Автоматизированный процесс предоставления знаний может оказать помощь при решении трудно формализуемых задач. В этом процессе объединяются такие процедуры, как формализация знаний, их накопление и генерация (вывод) новых знаний на основе накопленных в соответствии с поставленной задачей, объяснение полученных автоматизированным путем знаний.
Процесс "Обмен" предполагает передачу данных между всеми процессами ИТ и связан со всеми процедурами на уровне данных. При обмене данными можно выделить три основных типа процедур: коммутация, маршрутизация (передача данных по каналам связи и организации сети) и передача. Процедуры передачи данных реализуются с помощью операции кодирования-декодирования, модуляции-демодуляции, согласования и усиления сигналов. Операции по организации сети включаются в качестве основных в процедуры коммутации и маршрутизации потоков данных (трафика) в вычислительной сети. Процесс обмена позволяет передавать данные между абонентами и используется в процессах получения и отображения информации, а также он способствует процессу накопления информации, поступающей из многих источников.
Процесс накопления позволяет преобразовывать информацию, длительное время хранить, постоянно обновляя, и при необходимости оперативно извлекать в заданном объеме и по определенным признакам. Процедуры этого процесса - архивирование, обновление и поиск - состоят в организации хранения (быстрое и неизбыточное накопление данных по заданным признакам и не менее быстрое осуществление их поиска) и актуализации данных (поддержание хранимых данных на уровне, соответствующем информационным потребностям решаемых задач). Актуализация данных осуществляется с помощью операций добавления новых данных, корректировки (изменения значений или элементов структур) данных и их уничтожения.
В информатике часто используют слова "информация" и "данные", причем часто как взаимозаменяемые. Хотя в необходимых случаях специалисты отмечают и их смысловое различие. Например, "информация кодируется с помощью данных и извлекается путем их декодирования и интерпретации". Кодирование информации происходит в процессе ввода ее в память ЭВМ, и можно считать, что данные - это информация, представленная в специальной фиксированной форме, пригодной для последующей компьютерной обработки, хранения и передачи.
В этом смысле представленные на схеме информационные процессы накопления, обработки и обмена манипулируют именно с данными, а процесс получения обеспечивает поступление информации и ее превращение в данные, так же как процесс отображения выполняет обратную функцию превращения данных в информацию.
Дата добавления: 2018-06-01; просмотров: 282; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!