Агрегатные функции и группировка записей.
Предназначены для расчета итоговых значений по набору данных:
COUNT(<выражение>) – подсчитывает количество вхождений значения выражения во все строки результирующего НД;
SUM(<выражение>) – суммирует значения выражения для всех строк;
AVG(<выражение>) – находит среднее значение выражения для всех строк;
MIN(<выражение>) – находит минимальное значение выражения;
MAX(<выражение>) – находит максимальное значение выражения.
Например, число записей в таблице предметов:
SELECT COUNT(*) FROM Predmety;
Число различных предметов, имеющихся на предприятии:
SELECT COUNT(DISTINCT Predmet) FROM Nalichie
WHERE Kolvo>0;
Суммарное наличие у лица с условным номером 3:
SELECT SUM(P.Cena*N.Kolvo) AS Vsego
FROM Nalichie N, Predmety P
WHERE P.NPredm=N.Predmet AND N.Lico=3;
Средняя сумма проводки за Январь месяц:
SELECT AVG(P.Cena*V.Kolvo) AS SrSumma
FROM Provodki V, Predmety P
WHERE P.NPredm=V.Predmet AND
V.Date>=”1-JAN-2012” AND V.Date<=”31-JAN-2012”;
Самая крупная передача предметов от лица с условным номером 1 к лицу с номером 3 за Январь месяц:
SELECT P.Name, V.Date, MAX(P.Cena*V.Kolvo) AS MaxProvodka
FROM Provodki V, Predmety P
WHERE P.NPredm=V.Predmet AND V.Rashod=1 AND V.Prihod=3
AND V.Date>=”1-JAN-2012” AND V.Date<=”31-JAN-2012”;
Иногда возникает необходимость подсчета агрегированных значений (сумма, среднее, минимум …) не по всему набору данных, а по некоторым его группам, характеризуемым одинаковыми значениями определенных полей. Например, суммарное наличие по подотчетным лицам или по подразделениям.
С этой целью в операторе SELECT используется предложение:
|
|
|
GROUP BY столбец_1[, столбец_2...]
Замечание. При использовании предложения GROUP BY один из столбцов результирующего набора данных обязательно должен быть представлен агрегатной функцией.
Например, суммарное наличие по подотчетным лицам:
SELECT L.Name, SUM(N.Kolvo*P.Cena)
FROM Nalichie N, Lica L, Predmety P
WHERE L.NLic=N.Lico AND P.NPredm=N.Predmet
GROUP BY L.Name;
или количество проводок, сгруппированных по предметам и датам:
SELECT P.Name, V.Data, COUNT(V.*)
FROM Provodki V, Predmety P
WHERE P.NPredm=V.Predmet
GROUP BY P.Name, V.Data;
Замечание. В предложении SELECT могут присутствовать в чистом виде (т.е. не в качестве аргументов агрегатных функций) только те столбцы, которые присутствуют в предложении GROUP BY.
Если в результирующий набор данных необходимо включать агрегированное значение не по всем группам, а только по тем из них, которые удовлетворяют некоторому условию, то предложение GROUP BY дополняется предложением:
HAVING <условие_поиска>
где условие_поиска формируется по тем же правилам, что и предложение WHERE, за одним исключением: здесь, в отличие от WHERE, можно использовать агрегатные функции.
Например, список подотчетных лиц, имеющих наличие общей стоимостью менее 1000 руб., с указанием количества наименований, значащихся за ними предметов:
SELECT L.Name, COUNT(N.*)
|
|
|
FROM Nalichie N, Lica L, Predmety P
WHERE L.NLic=N.Lico AND P.NPredm=N.Predmet
AND N.Kolvo>0
GROUP BY L.Name HAVING SUM(N.Kolvo*P.Cena)<1000;
Замечание. В предложении HAVING, также как и в предложении SELECT могут использоваться непосредственно только столбцы, перечисленные в GROUP BY, а все остальные столбцы могут упоминаться только в качестве аргументов агрегатных функций.
Модификация наборов данных в SQL.
Операторы добавления, изменения и удаления строк в SQL, как и все другие операторы SQL, ориентированы на работу с группами строк, а не с отдельными строками. Поэтому всегда следует уделять особое внимание таким операторам в части ограничения выборки (предложение WHERE) с тем, чтобы не получить неожиданный результат.
Добавление строк в таблицу осуществляется оператором INSERT следующего формата:
INSERT INTO имя_таблицы[(столбец_1[, столбец_2 ...])]
{VALUES(<значение_1>[, <значение_2> ...]) |
<оператор SELECT>};
Список столбцов указывает столбцы, которым будут присваиваться значения. Если список опущен, то значения будут присваиваться всем столбцам таблицы, причем в том порядке, в котором они создавались.
Замечание. Во избежание недоразумений, список столбцов рекомендуется всегда указывать, поскольку их порядок может изменяться при изменении структуры таблицы.
|
|
|
Значения, присваиваемые столбцам, могут указываться двояко. Они или указываются явно, после ключевого слова VALUES, или формируются с помощью оператора SELECT.
При явном задании значений оператор INSERT имеет вид:
INSERT INTO имя_таблицы[(столбец_1[, столбец_2, ...])]
VALUES(<значение_1>[, <значение_2> ...]);
Этот оператор добавит в таблицу одну строку, в которой значение_1 будет присвоено столбцу_1, значение_2 – столбцу_2 и т.д. Значения должны соответствовать типу столбцов (с учетом возможностей автоматического преобразования).
Например, добавить в таблицу наличия строку для предмета с условным номером 12 у лица с номером 5 и количеством в 100 единиц:
INSERT INTO Nalichie(Lico, Predmet, Kolvo)
VALUES(5, 12, 100);
Если какой-либо столбец отсутствует в списке присвоения, то ему не будет присвоено никакого значения (NULL).
Во второй своей форме (с оператором SELECT) INSERT добавляет в таблицу столько строк, сколько их будет в НД, возвращенном оператором SELECT. При этом значения присваиваются столбцам в том порядке, в каком они перечислены в операторе INSERT и в SELECT. Например, для копирования всех строк из таблицы проводок в таблицу архива (с той же структурой, что и таблица проводок) можно использовать оператор вида:
|
|
|
INSERT INTO Archive SELECT * FROM Provodki;
Здесь списки столбцов опущены, так как подразумевается полная идентичность структур таблиц. В общем же случае следует указать список столбцов и в INSERT и в SELECT.
Изменение значений столбцов в строках таблицы осуществляется с помощью оператора UPDATE следующего формата:
UPDATE имя_таблицы
SET столбец_1=<значение 1>[, столбец_2=<значение 2> ...]
[WHERE <условие поиска>];
Изменению подвергаются все строки таблицы, удовлетворяющие условию поиска. Будьте внимательны, используя этот оператор! Если опустить предложение WHERE, то будут изменены все строки таблицы ! Условие поиска в UPDATE задается так же, как и в операторе SELECT.
Например, деноминация цен в таблице предметов путем деления цены на 1000:
UPDATE Predmety SET Cena=Cena/1000;
Изменить в таблице проводок все даты проводок за 1.01.2012 на 11.01.2012:
UPDATE Provodki SET Data=”11-JAN-2012”
WHERE Data=”1-JAN-2012”;
Удаление строк из таблицы выполняется оператором:
DELETE FROM имя_таблицы [WHERE <условие поиска>];
Обратите внимание, удаляются все строки, удовлетворяющие условию поиска. Если опустить условие поиска, то таблица будет полностью очищена!
- Процедурное расширение SQL.
- Хранимые процедуры.
Хранимая процедура – это программный модуль, написанный на специальном языке хранимых процедур, и хранящийся в БД как её элемент.
Хранимые процедуры могут использоваться при подготовке данных для отчетов, внесении массовых изменений в БД, для выполнении периодических действий в БД и множества других операций. Вообще, можно сформулировать такое правило: если какое-либо действие может быть выполнено без участия клиента, то его следует реализовать на сервере с помощью хранимой процедуры или триггера.
С некоторой долей условности хранимые процедуры можно разделить на две категории:
· процедуры выбора так же, как и оператор SELECT, могут возвращать многострочные наборы данных (то есть несколько наборов значений своих выходных параметров);
· процедуры действия возвращают один набор значений своих выходных параметров или вообще ничего не возвращают, а только выполняют некоторые действия в БД.
Создание хранимой процедуры
Выполняется оператором вида:
CREATE PROCEDURE имя_процедуры
[(вх.параметр1 тип_данных[,вх.параметр2 тип_данных...])]
[RETURNS(вых.параметр1 тип_данных[,вых.параметр2
тип_данных...])]
AS <тело процедуры>;
Входные параметры предназначены для передачи в процедуру некоторых значений из точки вызова. Выходные параметры предназначены для возврата результирующих значений.
Обратите внимание на четкое разграничение входных и выходных параметров. В принципе, входные параметры можно изменять в теле процедуры, но это никак не скажется на точке ее вызова.
Тип данных для параметров может быть любым, кроме массивов. И входные и выходные параметры могут отсутствовать.
Тело процедуры имеет формат:
[<объявление локальных переменных>]
BEGIN
<оператор>
[<оператор>...]
END
Операторы в теле процедуры разграничиваются точкой с запятой.
Для написания процедур используется специальный внутренний язык InterBase /FireBird, который называется PSQL. Он является процедурным языком и, соответственно, в нем есть операторы управления ходом вычислительного процесса. Этот же язык используется для написания триггеров.
Оператор приостановки SUSPEND
Используется в процедурах выбора для указания момента передачи в вызывающее приложение очередного набора значений выходных параметров.
Когда в процедуре выбора достигается оператор SUSPEND, в вызывающее приложение возвращается набор значений параметров, перечисленных в предложении RETURNS, и выполнение процедуры приостанавливается до прихода запроса на следующий набор значений.
Замечание:Оператор SUSPEND – характерный признак процедуры выбора.
Пример. Изменим процедуру, приведенную в предыдущем примере, таким образом, чтобы она выдавала количество предметов одного и того же наименования для каждой из возможных цен:
CREATE PROCEDURE KolvoPredmPoCene(Name VARCHAR(30))
RETURNS(Cena DOUBLE PRECISION, Kolvo DOUBLE PRECISION) AS
DECLARE VARIABLE N INTEGER;
BEGIN
FOR SELECT NPredm, Cena FROM Predmety
WHERE UPPER(Name)=:Name INTO :N, :Cena DO
BEGIN
SELECT SUM(Kolvo) FROM Nalichie WHERE Predmet=:N
INTO :Kolvo;
SUSPEND;
END
END
Оператор выхода EXIT
Немедленно прекращает выполнение процедуры и передает управление на последний оператор END в процедуре. EXIT может находиться в любом месте, в том числе, и внутри цикла.
Вызов других процедур
Хранимые процедуры в процессе выполнения могут вызывать другие хранимые процедуры.
Допустимы рекурсивные вызовы, при этом для каждого вызова создается отдельный экземпляр процедуры. Максимально допустимая глубина рекурсии – 1000 (ограничена во избежание бесконечной рекурсии), хотя физически ограничение может наступить раньше, ввиду превышения допустимого размера стека.
Формат вызова другой процедуры:
EXECUTE PROCEDURE имя_процедуры
[входной_параметр_1[,входной_параметр_2...]]
[RETURNING_VALUES выходной_параметр_1
[, выходной_параметр_2...]];
Список входных параметров указывает на переменные и/или содержит константы, значения которых будут использованы для передачи в вызывающую процедуру. Список выходных параметров указывает на переменные, которым будут присвоены возвращённые процедурой значения.
Удаление хранимой процедуры осуществляется оператором:
DROP PROCEDURE имя_процедуры;
Изменение процедуры возможно либо с помощью пары операторов: DROP – CREATE, либо с помощью оператора ALTER PROCEDURE, имеющего такой же формат, как и оператор CREATE PROCEDURE.
Замечание.Оператор ALTER PROCEDURE удобно использовать в тех случаях, когда процедуру нельзя удалить из-за взаимосвязи с другими процедурами или триггерами.
Вызов хранимых процедур
Выполнение хранимой процедуры действия инициируется оператором:
EXECUTE PROCEDURE имя_процедуры
[(входной_параметр_1[, входной_параметр_2...])];
Например, рассчитать с помощью приведенной в предыдущих примерах процедуры среднюю стоимость проводок по предмету с условным номером 15:
EXECUTE PROCEDURE AvgProvodka(15);
- Триггеры.
Триггер – это процедура, автоматически выполняемая сервером при добавлении, изменении или удалении строки в таблице, с которой триггер связан.
В отличие от хранимых процедур, триггеры не имеют ни входных, ни выходных параметров и их нельзя вызывать непосредственно. Вызов триггера порождается только соответствующим действием в таблице, с которой триггер связан.
Триггеры, так же как и все хранимые процедуры работают в контексте конкретной транзакции. Поэтому откат транзакции, в рамках которой сработал триггер, приведет к отмене и всех изменений, выполненных триггером.
В зависимости от события, к которому привязан триггер, различаются триггеры, вызываемые при:
1) добавлении строки;
2) удалении строки;
3) изменении строки.
В зависимости от времени срабатывания триггеры делятся на:
1) выполняемые до наступления события;
2) выполняемые после наступления события
Создание триггера
Выполняется оператором:
CREATE TRIGGER имя_триггера FOR имя_таблицы
[{ACTIVE | INACTIVE}] {BEFORE | AFTER}
{DELETE | INSERT | UPDATE} [POSITION номер]
AS <тело_триггера>;
где имя_таблицы указывает на таблицу, действия в которой триггер должен отслеживать;
ACTIVE | INACTIVE – определяет активность триггера (триггер можно включать и отключать). По умолчанию считается ACTIVE;
DELETE | INSERT | UPDATE – указывает при каком действии в таблице должен срабатывать триггер;
BEFORE | AFTER – указывает: до или после действия должен срабатывать триггер;
POSITION – определяет порядок срабатывания триггеров, если к одному и тому же событию привязано несколько триггеров (номер – целое число в интервале от 0 до 32767). Триггер с меньшим номером срабатывает раньше.
Тело триггера определяется точно также, как и тело хранимой процедуры. Единственным отличием является возможность обращения к значениям столбцов, которые имели место до изменения строки и после её изменения. С этой целью к именам столбцов добавляются префиксы OLD и NEW.
Префикс OLD указывает на предыдущее или текущее значение столбца в строке, которая изменяется или удаляется. Для добавляемых строк префикс OLD не используется.
Префикс NEW указывает на новое значение столбца в изменяемой или добавляемой строке. Для удаляемых строк он не используется.
Замечание 1. Префиксы столбцов могут использоваться в любых операторах тела триггера, в том числе и в SELECT.
Замечание 2. Новые значения, присваиваемые столбцам, могут быть изменены только до выполнения операции. То есть, например, если триггер AFTER INSERT попытается изменить значение NEW.имя_столбца, то это действие не будет иметь результата. Кроме того, фактические значения столбцов не изменяются до тех пор, пока не будет закончена операция вставки или изменения строки. Поэтому триггеры, привязанные к одному и тому же событию, не могут видеть изменения вносимые друг другом.
Замечание 3. Если триггер выполняет действие, которое приводит к тому, что он срабатывает снова, то образуется бесконечный цикл. Поэтому необходимо обеспечить, чтобы действия триггера не приводили к его срабатыванию вновь, даже неявным образом. Например, бесконечный цикл будет иметь место, если триггер, срабатывающий по INSERT в некоторой таблице, будет пытаться добавить запись в ту же таблицу.
Замечание 4. В триггерах допускается вызов хранимых процедур, генерация исключительных ситуаций и их обработка.
Изменение и удаление триггера
Для изменения триггера используется оператор ALTER TRIGGER. Этот оператор может изменять:
1) только заголовок триггера, включая событие, к которому он привязан, и его активность;
2) только тело триггера;
3) и тело и заголовок.
По своему формату оператор ALTER TRIGGER полностью совпадает с оператором CREATE TRIGGER за одним исключением: в нем отсутствует предложение FOR (то есть триггер, созданный для одной таблицы, нельзя затем перепривязать к другой таблице).
Если оператор ALTER TRIGGER используется для изменения заголовка, то в нем перечисляются только те параметры, которые должны быть изменены. Например, для временного отключения некоторого триггера Tr1 следует использовать такой оператор:
ALTER TRIGGER Tr1 INACTIVE;
Если изменяется момент срабатывания триггера (BEFORE, AFTER), то должно быть указано и действие (DELETE, INSERT, UPDATE).
Для изменения только тела триггера в операторе ALTER TRIGGER ничего не должно быть между именем триггера и словом AS.
Для удаления триггера используется оператор:
DROP TRIGGER имя_триггера;
Не может быть удален триггер, используемый в текущий момент времени.
- Генераторы. Исключительные ситуации. Примеры использования.
В InterBase/FireBird нет автоинкрементных полей. Вместо них применяются генераторы, которые возвращают уникальные значение целого типа. Для создания генератора используется оператор вида:
CREATE GENERATOR имя_генератора;
Этот оператор создает генератор и устанавливает его начальное значение в ноль. Если необходимо изменить начальное значение для созданного генератора, то используется оператор:
SET GENERATOR имя_генератора TO целое_число;
Для получения уникального значения к генератору обращаются с помощью функции:
GEN_ID (имя_генератора, шаг);
Эта функция возвращает увеличенное на шаг предыдущее значение, выданное генератором. При необходимости можно также использовать отрицательные значения для шага.
Замечание. Не рекомендуется для одного и того же генератора переустанавливать начальное значение или при разных обращениях использовать разный шаг, чтобы исключить вероятность получения неуникальных значений.
Например, для присвоения условных номеров предметам можно использовать следующий генератор:
CREATE GENERATOR PredmetN;
. . .
INSERT INTO Predmety(NPredm, Name, EdIzm, Cena)
VALUES(GEN_ID(PredmetN), ”Бензин АИ-92”, ”л”, 19.50);
Замечание 1. Не существует оператора DROP GENERATOR. Если необходимо удалить генератор из БД, то это следует сделать в системной таблице RDB$GENERATORS. Там же можно посмотреть всю информацию о созданных генераторах.
Замечание 2. Чаще всего присвоение уникальных значений полям производится в триггерах, вызываемых перед добавлением новой строки. Например, для таблицы предметов можно использовать такой триггер:
CREATE TRIGGER BI_Predmety FOR Predmety
ACTIVE BEFORE INSERT AS
BEGIN
NEW.NPredm=GEN_ID(PredmetN,1);
END
Соответственно, в операторе добавления новой записи значение полю условного номера предмета присваивать не надо, поскольку такое присвоение будет автоматически выполнено в созданном триггере.
Замечание 3. Если присвоение уникальных значений полям желательно выполнять в клиентской части приложения, то для получения этих уникальных значений с сервера можно создать хранимую процедуру вида:
CREATE PROCEDURE Get_PredmetN RETURNS(N Integer) AS
BEGIN
N=GEN_ID(PredmetN,1);
END
и вызывать ее перед добавлением новой строки в таблицу предметов.
Исключительные ситуации (ИС)
Если при выполнении хранимой процедуры происходит ошибка, то генерируется исключительная ситуация.
Исключительные ситуации бывают трех видов:
1) ошибки SQL – возвращают номер ошибки SQLCODE;
2) ошибки InterBase/FireBird – возвращают номер ошибки GDSCODE;
3) исключительные ситуации, определенные пользователем.
Исключительные ситуации, определенные пользователем, являются таким же элементом БД, как и сами хранимые процедуры. Поэтому перед использованием они должны быть определены в БД с помощью оператора:
CREATE EXCEPTION имя_исключит_ситуации ’<сообщение>’;
Сообщение возвращается в приложение в случае наступления исключительной ситуации.
После того, как исключительная ситуация определена, она может быть инициирована в процедуре или триггере с помощью оператора:
EXCEPTION имя_исключит_ситуации;
Например:
. . .
CREATE EXCEPTION KolvoLessZero ’Количество меньше нуля’;
. . .
IF (Kolvo < 0) THEN EXCEPTION KolvoLessZero;
. . .
Удаление исключительной ситуации из БД выполняется оператором:
DROP EXCEPTION имя_исключит_ситуации;
изменение:
ALTER EXCEPTION имя_исключит_ситуации ’<сообщение>’;
Если исключительная ситуация не обрабатывается в процедуре (для такой обработки используется специальный оператор WHEN), то при её наступлении выполнение процедуры прекращается, все выполненные в ней действия отменяются и в вызывающее приложение передается сообщение об ошибке.
- Транзакции. Основные свойства и проблемы.
Транзакцией называется группа операций, переводящая базу данных из одного целостного состояния в другое целостное состояние. В случае успешного завершения всех операций, составляющих транзакцию, следует команда подтверждения, в результате которой все изменения, произведенные в ходе транзакции, фиксируются в БД на постоянной основе. Если при выполнении любой операции происходит ошибка или наступает нештатная ситуация, то следует команда отмены и БД откатывается к состоянию, которое имело место на момент старта транзакции.
Поскольку у СУБД отсутствует внутренняя возможность определить – какие операции должны быть объединены в рамках одной транзакции, то эта обязанность возлагается на пользователя. С этой целью в его распоряжение представляются команды вида: START TRANSACTION – определяет точку начала транзакции; COMMIT – завершает транзакцию и подтверждает сделанные в ее ходе изменения; ROLLBACK – откатывает транзакцию.
Механизм транзакций столь важен для целостности баз данных, что практически ни одно действие в серверных БД не может быть выполнено иначе, как в рамках какой-либо транзакции. Иногда у пользователя может складываться ложное впечатление, что некоторые действия он выполняет вне контекста транзакций. Оно обусловлено некоторой «самостоятельностью» используемых приложений, которые запускают (а иногда и подтверждают) транзакции без соответствующих запросов к пользователю. Часто, например, автоматическое подтверждение транзакций используется для операторов DDL. Однако на самом деле все действия в БД всегда выполняются в контексте транзакций. Редким исключением здесь является механизм генераторов в InterBase/FireBird, который работает вне контекста транзакций по понятным причинам (подумайте, к каким проблемам привел бы возврат генераторов к предыдущим значениям при откате транзакций).
Для успешной реализации своих функций транзакции должны удовлетворять четырем основным требованиям. В англоязычной литературе для них используется аббревиатура ACID, образованная начальными буквами названий соответствующих свойств.
1. Атомарность – транзакция представляет собой неделимую единицу работы, которая либо выполняется вся целиком, либо не выполняется вовсе.
2. Согласованность – транзакция должна переводить БД из одного целостного состояния в другое целостное состояние (имеется ввиду семантическая целостность информации).
3. Изолированность – транзакции должны выполняться независимо друг от друга, не влияя на результаты друг друга.
4. Постоянство – результаты успешно завершенной транзакции должны сохраняться в БД на постоянной основе с тем, чтобы никакие последующие сбои и исключительные ситуации не могли повлечь за собой их утрату.
Среди перечисленных требований наиболее сложным, в плане реализации, является обеспечение изолированности, то есть независимости, множества одновременно работающих транзакций. Здесь возникает ряд существенных проблем. Перечислим некоторые из них.
1. Проблема потерянного обновления. Пусть транзакция Т1 выполняет снятие 100 руб. со счета, на котором имеется 2000 руб. А транзакция Т2 пополняет этот же счет на 500 руб. Предположим, что обе транзакции стартовали практически одновременно и прочитали исходное состояние счета в 2000 руб. Далее транзакция Т2 рассчитала новое значение остатка 2000 + 500 = 2500 (руб.) и записала его значение на счет. Тем временем Т1 рассчитала свой результат 2000 – 100 = 1900 (руб.) и записала его поверх результата Т2. Таким образом, остаток по счету имеет значение 1900 вместо 2400.
2. Проблема зависимости от нефиксированных результатов. Возникает, когда одна транзакция получает доступ к промежуточным результатам выполнения другой транзакции до того момента, как они были зафиксированы на постоянной основе.
Пусть в тех же условиях, что и в предыдущем примере, Т1 начала выполняться раньше Т2 и к моменту старта Т2 уже записала на счет свой результат 1900, но еще не подтвердила его. Т2 считает состояние счета 1900, рассчитает остаток 1900 + 500 = 2400, а тем временем по каким-либо причинам Т1 будет отменена и вернет прежнее состояние счета в 1000 руб. Но Т2 запишет поверх уже неверный результат 2400.
3. Проблема несогласованной обработки (имеет и другие названия: неповторяемость чтения, чтение мусора, грязное чтение). Пусть транзакция Т1 выполняет суммирование остатков на счетах с №1 по №100, а Т2 переносит сумму в 1000 руб. со счета №90 на счет №10. Предположим, что Т2 стартовала после того, как Т1 просчитала сумму остатков на первых 20-ти счетах, и к тому моменту, когда Т1 дошла до счета №90 успела забрать с него 1000 руб. и прибавить их к остатку на счете №10. В результате, полученная Т1 сумма будет меньше реальной на 1000 руб. Отметим, что здесь в отличие от предыдущего примера проблема имеет место и при нормальном завершении Т2.
Для решения этих и других проблем в СУБД используются механизмы блокировок и уровней изоляции транзакций.
- Механизм блокировок
Механизм блокировок позволяет транзакции получить монопольный доступ к используемым ею элементам базы данных. При этом любая другая транзакция сможет получить доступ к тем же элементам только по завершении (успешном или неуспешном) первой транзакции.
Очевидно, что во всех приведенных примерах для решения возникших проблем достаточно было бы Т1 установить блокировку на используемые ею счета. Соответственно, Т2 получила бы к ним доступ только после завершения Т1. Однако при кажущейся простоте решения проблем возникает ряд существенных вопросов.
Например, если бы Т1 выполняла суммирование остатков по всем открытым счетам, то заблокировав их, она бы остановила работу всех остальных транзакций. Допустимо ли это? И нужно ли полностью блокировать доступ ко всем счетам, учитывая тот факт, что Т1 не изменяет их остатки? Может быть и другим транзакциям можно позволить считывать текущее состояние счетов?
Другой вопрос: когда надо блокировать используемый транзакцией элемент БД – в момент старта транзакции или в момент обращения к элементу? И т.д.
Поэтому конкретная реализация механизма блокировок может отличаться многими деталями, но основной принцип его работы всегда один: транзакция прежде, чем получить доступ к какому-либо элементу БД, должна запросить его блокировку по чтению или по записи. После того, как блокировка элемента разрешена для текущей транзакции, никакая другая транзакция не сможет изменить этот элемент и даже не сможет его прочитать (если установлена блокировка по записи) до завершения текущей транзакции.
Если транзакция установила блокировку элемента по чтению, то она имеет право только читать его, но не имеет права изменять. Если блокировку по записи – то может и читать элемент, и изменять его. Блокировка может выполняться в отношении элементов разного размера: отдельного атрибута строки, всей строки, таблицы и даже всей БД.
Поскольку при таких условиях операция чтения не может порождать конфликты, то допускается одновременная блокировка одного и того же элемента по чтению несколькими транзакциями. Поэтому блокировку по чтению называют разделяемой блокировкой. В отличие от нее блокировка по записи является эксклюзивной, то есть дает транзакции монопольное право доступа к заблокированному элементу. До тех пор, пока транзакция удерживает блокировку элемента по записи, никакая другая транзакция не сможет даже прочитать этот элемент.
Порядок работы механизма блокировок обычно бывает следующим:
¾ транзакция для получения доступа к элементу данных должна запросить его блокировку. Блокировка может запрашиваться по чтению (допускает только чтение элемента) или по записи (допускает чтение и изменение элемента);
¾ если элемент еще не заблокирован другими транзакциями, то блокировка разрешается;
¾ если элемент уже заблокирован, то тип запрашиваемого блока сравнивается с типом уже установленного. Если запрашивается доступ по чтению к элементу, который заблокирован по чтению, то доступ разрешается. Во всех остальных случаях транзакция переводится в режим ожидания снятия предыдущих блокировок;
¾ блокировка удерживается транзакцией до своего завершения или до тех пор, пока не снимет ее явным образом в ходе своего выполнения.
Механизм блокировок, решая вышеперечисленные проблемы, создает другую, так называемую, проблему взаимной блокировки (deadlock, смертельные объятия). Пусть транзакции Т1 и Т2 для своей работы должны заблокировать по записи элементы Э1 и Э2. И пусть, вследствие сложившихся временных соотношений, Т1 успела заблокировать Э1, а Т2 – Э2. Тогда Т1 будет переведена в состояние ожидания при попытке заблокировать Э2, а Т2 – при попытке заблокировать Э1. В результате образуется бесконечный цикл взаимного ожидания.
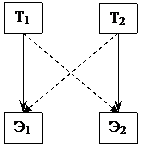
Такие ситуации обычно отслеживаются СУБД путем анализа взаимозависимости транзакций или просто по таймеру. В случае их возникновения возможны два решения. Либо какая-нибудь из транзакций выбирается случайным образом жертвой и принудительно откатывается. Либо приложению возвращается сообщение об ошибке взаимной блокировки.
- Изоляция транзакций.
Помимо механизма блокировок для обеспечения одновременной работы множества транзакций большое значение имеют уровни их изоляции. Эти уровни определяют видимость для текущей транзакции результатов других, работающих одновременно с ней транзакций. Обычно различают три уровня изоляции транзакций:
1. Dirty Read (грязное чтение). Текущей транзакции видны все изменения, внесенные другими транзакциями, в том числе и неподтвержденные ими. Этот уровень характерен для локальных БД и, по сути, означает отсутствие изоляции транзакций. В серверных БД практически не используется, поскольку может послужить причиной большого числа проблем.
2. Read Committed (чтение подтвержденного). Текущая транзакция видит только те изменения других транзакций, которые ими подтверждены. Это наиболее часто используемый уровень изоляции транзакций. Следует иметь ввиду, что при неоднократном чтении одного и того же элемента результаты могут быть разными, поскольку в промежутке времени между чтениями элемент мог быть изменен и его изменения подтверждены.
3. Repeatable Read (повторяемое чтение). Текущая транзакция видит все данные в том виде, в каком они были подтверждены на момент ее старта. То есть, транзакция как бы работает с моментальным снимком базы данных и ей не доступны никакие последующие изменения. При многократном чтении одного и того же элемента результат всегда будет одним. Такой уровень изоляции транзакций удобно использовать для фиксации состояния базы данных при составлении отчетов. Однако он может быть причиной многочисленных конфликтов блокировок.
- Механизм транзакций в InterBase.
Осуществляется с помощью трех операторов:
· SET TRANSACTION– запускает транзакцию и определяет режимы ее работы;
· COMMIT– подтверждает изменения, выполненные в рамках транзакции, и завершает транзакцию;
· ROLLBACK- отменяет изменения, выполненные в рамках транзакции, и завершает транзакцию.
Оператор SET TRANSACTION имеет следующий формат:
SET TRANSACTION
[READ WRITE | READ ONLY]
[WAIT | NO WAIT]
[[ISOLATING LEVEL] {SNAPSHOT [TABLE STABILITY] |
READ COMMITTED [[NO] RECORD_VERSION]}]
[RESERVING <список_таблиц_1> [FOR [{SHARED | PROTECTED}]
{READ | WRITE}] [, <список таблиц 2>...]];
Параметр READ WRITE | READ ONLY – определяет тип доступа (Access Mode), который транзакция имеет к используемым ею таблицам. По умолчанию предполагается READ WRITE. В случае READ ONLY допускается только чтение данных.
Замечание 1. Если предполагается, что транзакция будет только читать данные, то следует указать READ ONLY, чтобы уменьшить вероятность конфликтов блокировок.
Замечание 2.Несмотря на то, что данный параметр может быть опущен, делать это не рекомендуется. Указание режима доступа в явной форме является хорошей программной практикой. Это касается и всех последующих параметров.
Параметр WAIT | NO WAIT – определяет режим разрешения конфликтов блокировок (Lock Resolution). По умолчанию WAIT – если данная транзакция во время операции обновления или удаления встретит заблокированную строку, то она будет ждать снятия блокировки, чтобы попытаться выполнить свои действия. В случае NO WAIT – немедленно возвращается сообщение об ошибке конфликта блокировок.
Параметр SNAPSHOT | READ COMMITTED – определяет уровень изоляции транзакций (Isolation Level). По умолчанию SNAPSHOT (аналог REPEATABLE READ) – обеспечивает стабильное представление БД на момент старта транзакции (моментальный снимок БД). Другие одновременно работающие транзакции могут обновлять и вставлять строки, однако, данная транзакция не будет видеть эти изменения. Она будет видеть те версии строк, которые имели место на момент её старта. Если данная транзакция попытается обновить или удалить строки, измененные другими транзакциями, то наступит конфликт обновления.
SNAPSHOT TABLE STABILITY – обеспечивает транзакции монопольное право на внесение изменений в используемые ею таблицы. Другие, одновременно работающие транзакции, могут только читать данные из этих таблиц. Транзакции такого уровня следует использовать с осторожностью, так как они могут породить большое количество конфликтов блокировок.
READ COMMITTED – дает возможность транзакции видеть все завершенные (подтвержденные COMMIT) изменения, выполненные другими транзакциями. Такая транзакция может обновлять строки, измененные и подтвержденные другими транзакциями, работающими одновременно, без возникновения проблем потерянных обновлений.
Уровень READ COMMITTED дает также возможность указать, какие версии строк следует считывать (дело в том, что при одновременной работе нескольких транзакций в БД может иметься несколько версий одной и той же строки). Если указан параметр RECORD_VERSION, то транзакция считывает последний завершенный (подтвержденный COMMIT) вариант строки, даже если существует более поздний и еще не подтвержденный вариант. По умолчанию действует параметр NO RECORD_VERSION, при котором транзакция может считывать только последнюю версию строки. Если эта версия еще не подтверждена, возникает конфликт блокировок, разрешение которого зависит от параметра [NO] WAIT. Если указан WAIT, то транзакция будет ждать подтверждения или отмены последнего варианта, после чего выполнит повторное чтение. Если NO WAIT – то сообщит об ошибке.
Обычно используются уровни SNAPSHOT и READ COMMITTED, которые дают одновременно работающим транзакциям возможность считывать и изменять строки в совместно используемых таблицах. Эти уровни минимизируют вероятность конфликтов. Они возникают только в двух случаях:
1) когда транзакция пытается обновить строку уже обновленную или удаленную другой транзакцией. Строка, обновленная некоторой транзакцией, не может быть изменена другими транзакциями до тех пор, пока изменившая строку транзакция не будет завершена или отменена;
2) когда транзакция пытается вставить, изменить или удалить строку в таблицу, которая заблокирована другой транзакцией с уровнем SNAPSHOT TABLE STABILITY. Транзакция с уровнем SNAPSHOT TABLE STABILITY полностью блокирует таблицу по записи. Уровень SNAPSHOT TABLE STABILITY гарантирует, что только одна транзакция может изменять таблицу, но при этом растет вероятность конфликтов.
Транзакции уровня SNAPSHOT не могут изменять или удалять строки, которые были изменены и подтверждены другими одновременно работающими транзакциями. Транзакция READ COMMITTED может считывать изменения, завершенные другими транзакциями, и после этого обновлять измененные строки. Случайные конфликты обновления могут происходить, если одновременно работающие транзакции уровня SNAPSHOT или READ COMMITTED делают попытку изменить одну и ту же строку.
Замечание.Если оператор UPDATE изменяет несколько строк в таблице, то при возникновении конфликта обновления хотя бы одной строки все изменения отменяются.
Необязательное предложение RESERVING дает транзакции возможность гарантировать для себя определенные права доступа к некоторому подмножеству таблиц. Резервирование производится при запуске транзакции, а не тогда, когда операторы манипуляции данными требуют определенного режима доступа. Обычно RESERVING используется в трех случаях:
1) для предотвращения возможных взаимных блокировок;
2) с целью обеспечения блокировок для зависимых таблиц, которые изменяются триггерами или ограничениями ссылочной целостности;
3) чтобы изменить уровень доступа только для части используемых таблиц. Например, для транзакции уровня SNAPSHOT можно обеспечить исключительный доступ (уровня SNAPSHOT TABLE STABILITY) только для отдельных таблиц.
Оператор COMMIT используется для фиксации изменений, выполненных транзакцией. Этот оператор закрывает потоки записей, связанные с транзакцией, и освобождает системные ресурсы, выделенные транзакции.
Оператор ROLLBACK используется для возврата БД в то состояние, которое имело место на момент старта транзакции. Обычно применяется в случае возникновения ошибок. Он также закрывает потоки записей, связанные с транзакцией, и освобождает системные ресурсы, выделенные транзакции.
Замечание. Даже транзакции с режимом доступа READ ONLY, которые не вносят изменения, рекомендуется заканчивать оператором COMMIT, а не ROLLBACK. При этом для запуска следующей транзакции требуется меньше ресурсов.
- Компоненты Delphi для работы с InterBase.
В Delphi имеется два набора компонентов, предназначенных для создания клиентских приложений InterBase / Firebird. Во-первых, это универсальные компоненты доступа к БД через механизмы BDE (они расположены на странице BDE). Их основное достоинство заключается в универсальности, что позволяет относительно просто переориентировать приложение на использование различных СУБД. Однако универсальность имеет и оборотную сторону, заключающуюся в игнорировании множества индивидуальных возможностей разных СУБД (в универсальном механизме невозможно учесть все детали конкретных СУБД). Кроме того, BDE выступает в качестве еще одного передаточного звена между приложением и СУБД, которое может вносить свои искажения в смысл передаваемых команд и данных (ситуация эквивалентна переводу с русского языка на английский через, например, немецкий язык).
Поэтому при создании сколько-нибудь значительных клиент-серверных приложений обычно используется альтернативный набор компонентов, непосредственно взаимодействующих с SQL сервером InterBase (Firebird) без посредничества BDE. Они расположены на странице InterBase и имеют общее название InterBaseExpess (IBX). Если приложение написано только с использованием компонентов IBX, то на клиентском компьютере можно не устанавливать BDE, достаточно наличия InterBase Client (gds32.dll).
Замечание. Компоненты IBX не являются «родными» компонентами Delphi. Это сторонняя разработка, включенная в Delphi. Помимо них, существуют и другие наборы компонентов, предназначенные для создания клиентских приложений InterBase / Firebird, которые по многим параметрам превосходят IBX. Наиболее признанными и широко применяемыми среди них являются компоненты FIBPlus (к сожалению, это коммерческая разработка и предполагает соответствующую плату за использование). Мы остановимся на InterBaseExpress, только потому, что они непосредственно включены в дистрибутив Delphi.
Компонент TIBDatabase обеспечивает соединение с БД, создает ее локальный псевдоним и указывает параметры соединения. В рамках приложения обычно используется одно соединение с базой данных (один компонент TIBDatabase).
В отличие от соединения через BDE компонент TDatabase, соединение через TIBDatabase может обеспечивать одновременную работу нескольких транзакций. В IBX транзакции отделены от соединения и задаются отдельными компонентами TIBTransaction.
Компонент TIBTransaction используется для определения транзакций, которых может быть несколько для каждого из соединений с БД.
В свойстве Name указывается имя транзакции для ссылок на нее из других компонентов. Параметры транзакции задаются с помощью редактора Transaction Editor, вызываемого из контекстного меню . Наиболее часто используемый уровень изоляции транзакций – Read Committed.
Замечание. Завершение транзакции (ее подтверждение или откат) автоматически закрывает все компоненты, которые работали в ее контексте. Если работа с компонентами должна продолжаться, то они должны быть активизированы вновь в явной форме. По этой причине, в частности, не стоит привязывать большое число компонентов к одной и той же транзакции, т.к. при подтверждении или откате транзакции в целях одного из компонентов придется вновь активировать все другие компоненты, работающие в рамках данной транзакции.
Компонент TIBTable по своим свойствам и методам этот компонент во многом совпадает с компонентом TTable, но имеет особенности, обусловленные ориентацией на работу с серверными БД.
Вообще, рекомендуется весьма ограниченное использование табличных компонентов для серверных БД и только для таблиц небольшого объема. Эта рекомендация обусловлена ориентацией табличных компонентов на навигационный способ доступа к данным. Так, например, если использовать TIBTable для доступа к таблице большого объема, то переход в ней к последней записи потребует значительного времени и создаст большую нагрузку на сеть, поскольку при этом вся таблица будет последовательно, от начала до конца передана на локальное место. Аналогично, включение фильтра в табличном компоненте предполагает полное копирование таблицы с сервера на локальное место, и т.д.
Поэтому при работе с серверными БД настоятельно рекомендуется использовать компоненты типа TIBQuery, которые обеспечивают отбор необходимой информации непосредственно на сервере и по сети передают только результаты выполнения запросов, а не полное содержимое таблиц.
Для работы TIBTable необходимо в свойстве Database выбрать имя компонента TIBDatabase, а в свойстве Transaction – имя транзакции, в рамках которой будут выполняться запросы этого компонента к БД. В свойстве TableName должно быть указано имя таблицы, работа с которой предполагается через компонент TIBTable.
Свойство UniDirectional определяется возможность двунаправленного движения по таблице. Если UniDirectional установлено в False, то обеспечивается возможность перемещения по набору данных как от начала к концу, так и в обратном направлении. Однако это требует больше ресурсов для работы компонента, поскольку предполагает кэширование (буферизацию) набора данных на локальном месте (серверные БД предполагают возможность перемещения только в прямом направлении путем последовательной загрузки очередного набора строк).
Активизировать созданные компоненты можно, например, при показе главной формы приложения:
procedure TMainForm.FormShow(Sender: TObject);
begin
DM.TipyLicT.Open;
DM.PodrT.Open;
end;
Компонент TIBQuery используется для реализации запросов к БД, как возвращающих набор данных (оператор SELECT), так и не возвращающих (INSERT, UPDATE, DELETE). Возвращаемый набор данных может быть визуализирован точно так же, как и в случае TTable при посредничестве TDataSource.
Компонент TIBQuery используется для реализации запросов к БД, как возвращающих набор данных (оператор SELECT), так и не возвращающих (INSERT, UPDATE, DELETE). Возвращаемый набор данных может быть визуализирован точно так же, как и в случае TTable при посредничестве TDataSource.
Компонент TIBStoredProc предназначен для работы с хранимыми процедурами действия, которые возвращают не более одного набора значений выходных параметров. В принципе этот компонент можно использовать и для процедур выбора, но более естественным для них будет использование компонента TIBQuery с соответствующим оператором SELECT.
В свойстве StoredProcName указывается имя хранимой на сервере процедуры. В свойстве Transaction указывается имя транзакции, в рамках которой должна выполняться процедура.
Доступ к входным и выходным параметрам процедуры осуществляется через свойства Params и ParamByName аналогично динамическим запросам. Если хранимая процедура вызывается многократно с различными значениями параметров, то имеет смысл выполнить ее подготовку с помощью метода Prepare.
Выполнение хранимой процедуры действия инициируется вызовом метода ExecProc.
- Трехуровневая архитектура ANSI-SPARC.
Рассматриваемая далее методика проектирования баз данных основана на архитектуре ANSI-SPARC, которая выделяет три уровня описания данных (требований к структуре БД): внешний, концептуальный и внутренний (рис. 1).
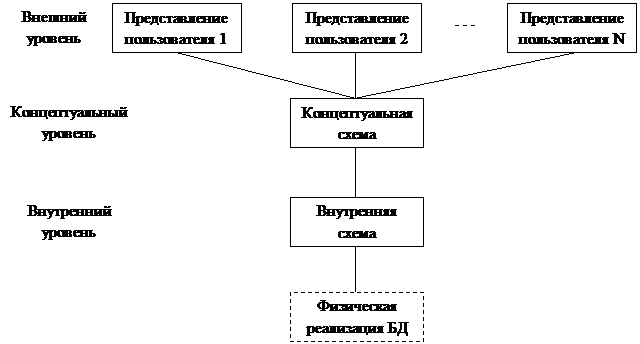
Внешний уровень состоит из представлений отдельных пользователей о том, какая информация должна храниться в базе данных; каким обработкам она будет подвергаться; какие результаты и в какой форме должны получаться. Т.е., этот уровень представляет собой постановку задачи с точки зрения будущих пользователей БД.
На концептуальном уровне представления пользователей преобразуются в единую логическую структуру, называемую концептуальной моделью данных. Эта модель должна с максимально возможной точностью отображать объекты и процессы реального мира и взаимосвязи между ними. На концептуальном уровне принимается решение о типе базы данных (реляционная, сетевая, объектная и т.д.); определяется набор отношений, связей между ними, атрибутов, множество выполняемых в базе данных операций (транзакций). Таким образом, получается постановка задачи с точки зрения разработчика базы данных.
Далее, на внутреннем уровне выбирается конкретная СУБД и концептуальная модель преобразуется во внутреннюю с учётом возможностей и ограничений выбранной СУБД. Здесь определяется набор таблиц, первичные и внешние ключи, набор индексов, требования к аппаратной части и т.п. Т.е., на внутреннем уровне разрабатывается детальный рабочий проект базы данных, на основе которого в дальнейшем выполняется физическая реализация базы данных.
Помимо структуризации процесса проектирования трехуровневая модель способствует решению важных проблем независимости от логической и физической структуры данных.
Независимость от логической структуры данных подразумевает защищённость внешних схем от изменений, вносимых в концептуальную схему. Это значит, что изменения, вносимые в концептуальную схему по требованию одного из пользователей (добавление или изменение сущностей, связей, атрибутов и т.п.), не должны сказываться на остальных пользователях. Соответственно, изменения коснутся только приложения, обслуживающего нужды конкретного пользователя, а все остальные приложения смогут продолжать свою работу без модификации.
Независимость от физической структуры данных предполагает защищённость концептуальной схемы от изменений, вносимых во внутреннюю схему. Т.е., изменения, например, файловой системы, операционного окружения, набора индексов и т.п. никоим образом не должны сказываться на концептуальной и, тем более, внешних схемах. Единственным видимым для пользователей следствием внесенных во внутреннюю схему изменений должно стать повышение производительности работы системы.
- Концептуальное проектирование баз данных.
Концептуальное проектирование – это создание концептуального представления объектов и процессов реального мира в виде совокупности некоторого множества типов сущности и связи без учета каких-либо аспектов последующей реализации базы данных.
В процессе концептуального проектирования при постоянном контакте с будущими пользователями базы данных строится концептуальная схема объектов/процессов реального мира и их взаимосвязей. Эта схема не привязывается не только к конкретной СУБД, но даже к типу БД. Основное назначение концептуальной схемы – адекватное отражение объектов и процессов, имеющих место в реальном мире. Отображение схемы в область баз данных происходит на следующем этапе логического проектирования.
Результатом концептуального проектирования является обобщенная модель данных предметной области без привязки не только к конкретной СУБД, но даже и к ее типу. Для этого этапа проектирования, как и, в известной степени, для следующего этапа – логического проектирования, характерна необходимость постоянного взаимодействия с будущими пользователями БД, поскольку именно они являются основными носителями всей нужной информации. Какой бы полной не казалась исходная постановка задачи, у проектировщика неизбежно возникают вопросы, требующие выяснения или согласования с пользователями.
И еще одно замечание. Концептуальное проектирование – процесс неоднозначный и во многом субъективный. Одна и та же предметная область может быть представлена различными наборами типов сущности и связи. При этом качество модели в существенной степени определяется опытом и искусством разработчика.
- Логическое проектирование баз данных.
Логическое проектирование – это процесс преобразования концептуальной модели в логическую, отвечающую требованиям конкретной модели данных, и далее в набор отношений и связей между ними.
Логическое проектирование начинается с выбора наиболее подходящего типа (модели) базы данных, но пока без привязки к конкретной СУБД. Далее концептуальная схема преобразуется в логическую, отвечающую требованиям и ограничениям выбранного типа БД. Полученная схема проверяется на соответствие требованиям нормализации и пригодность для выполнения всего набора предполагаемых транзакций. В процессе логического проектирования схема неоднократно уточняется на основе информации, получаемой от пользователей.
В начале логического проектирования на основе информации, полученной на предыдущих этапах, делается выбор модели данных (реляционная, сетевая, объектная, …), которая позволит наиболее адекватно отразить реальные объекты и процессы предметной области средствами проектируемой БД. Поскольку каждая модель имеет известные особенности и ограничения, то исходная концептуальная модель должна быть преобразована с тем, чтобы исключить из нее все элементы, которые не могут быть реализованы в рамках выбранной модели данных.
Затем на основе скорректированной модели строится набор отношений и связей между ними и проверяется на соответствие требованиям нормализации и возможность выполнения всех предполагаемых транзакций. Здесь же определяются требования и способы поддержки целостности данных в будущей БД.
Отметим, что логическое проектирование выполняется с учетом выбранного типа базы данных, но не привязывается к какой-то конкретной СУБД.
\
- Физическое проектирование баз данных.
Физическое проектирование – это процесс создания базы данных средствами выбранной СУБД и разработки приложений.
На этапе физического проектирования выбирается конкретная СУБД, и в ее рамках определяются таблицы, первичные и внешние ключи, способы поддержания целостности хранимой информации, набор индексов, требования к аппаратной части и т.п. Схема оптимизируется под выбранную СУБД и приводится в соответствие с ее возможностями. Физическое проектирование, как правило, выполняется специалистами иного профиля, чем исполнители первых двух этапов, и не предполагает непосредственных контактов с пользователями. Все возникающие здесь вопросы решаются с исполнителями концептуального/логического проектирования и свидетельствуют о недоработках предыдущих этапов.
Вначале физического проектирования на основе всей информации, собранной в процессе концептуального и логического проектирования, с учетом предполагаемого объема хранимой информации, количества одновременно работающих приложений-клиентов, имеющегося бюджета и др. факторов делается выбор конкретной СУБД, в рамках которой будет выполняться физическая реализация базы данных.
Далее средствами выбранной СУБД создаются таблицы и реализуются ограничения, определяется набор вторичных индексов, задаются правила и права доступа к базе данных, разрабатываются серверные и клиентские части приложений. Большое внимание при этом уделяется скорости выполнения наиболее часто используемых запросов.
В целях повышения скорости выполнения запросов и общей производительности системы достаточно часто приходится использовать приемы, предполагающие отклонение от требований нормализации. При этом следует помнить, что всякий отход от требований нормальных форм до НФБК включительно создает почву для проблем обновления. Поэтому одновременно должны предприниматься адекватные меры по исключению возможности появления такого рода проблем, то есть процесс денормализации (введения избыточности) должен быть контролируемым.
- Типы сущностей. Атрибуты.
Типом сущности называется некоторое множество объектов или процессов реального мира, обладающих одинаковым набором свойств (характеристик, атрибутов). Каждый элемент этого множества называется экземпляром сущности или просто сущностью.
Замечание. Часто термин «сущность» используется для обозначения не только отдельного экземпляра сущности, но и для типа сущности. О чем идет речь, как правило, следует из контекста.
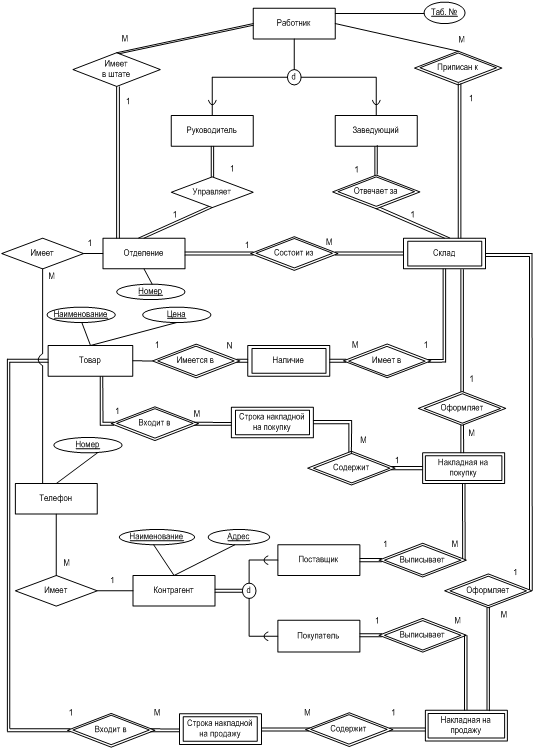
Например, в рассматриваемой учебной задаче можно выделить тип сущности «Отделение» со свойствами: номер, адрес, телефон. Экземплярами сущности здесь будут Отделение №1, Отделение №2, … Другой пример: тип сущности «Склад» с экземплярами Склад №1 Отделения №1, Склад №3 Отделения №2 и т.д.
В качестве типа сущности могут выступать не только объекты, но и процессы. Например, тип сущности «Наличие товара на складе» с атрибутами: товар, склад, количество, отражает процесс хранения товаров на складе.
Обычно различают сильные и слабые типы сущности.
Сильным называется тип сущности, существование которого не зависит от каких-либо других типов сущности. Соответственно, слабым – существование, которого зависит от других типов сущности.
Например, тип сущности «Отделение» является сильным. Когда мы говорим: Отделение №2, сразу ясно, о каком отделении идет речь, и при этом не надо выяснять его взаимосвязи с другими типами сущности. Напротив, если сказать: Склад №2, то однозначно указать на конкретный склад будет невозможно, поскольку склад №2 есть и в первом отделении и во втором и т.д. То есть, здесь для указания конкретного объекта придется дать еще ссылку на отделение. Таким образом, в рассматриваемой постановке задачи тип сущности «Склад» является слабым.
Замечание. Если ввести сквозную нумерацию складов на предприятии (а не в рамках отделения), то тип сущности «Склад» будет сильным. Поэтому приведенное выше определение сильного типа сущности не является строгим и допускает различные толкования в зависимости от конкретной постановки задачи. Более строгая формулировка понятия сильного типа сущности будет дана позднее.
На диаграммах типы сущности обозначаются прямоугольниками, причём слабые типы сущности отличаются двойным контуром .
Отдельное свойство (характеристика) сущности (типа сущности) называется её атрибутом. Например, тип сущности «Отделение» имеет атрибуты: номер, адрес, телефон; тип сущности «Товар»: наименование, единица измерения, цена.
Различают несколько разновидностей атрибутов.
Составным называется атрибут, состоящий из нескольких компонентов.
Например, атрибут «адрес» может включать в себя компоненты: город, улица, строение (вопрос о целесообразности разделения атрибута на несколько компонент будет рассмотрен позднее).
Многозначным называется атрибут, который может принимать несколько значений для одного и того же экземпляра сущности.
В нашем примере таким атрибутом является телефон отделения, поскольку по постановке задачи в каждом отделении может быть несколько телефонов.
Производным называется атрибут, значение которого рассчитывается на основе значений других атрибутов.
Примеры: общая сумма в накладной, стаж работы на предприятии, количество работников в отделении и т.п.
Множество допустимых значений атрибута называется доменом атрибута. Каждый атрибут должен быть определен на некотором домене. Причем на одном домене может быть определено несколько атрибутов, но каждый атрибут может быть определен только на одном домене.
Например, атрибут «Пол работника» может быть определен на домене, который представляет собой множество из двух символов: «м» и «ж». Для номеров отделений и складов доменом может служить множество натуральных чисел. И т.д.
Большое значение для проектирования баз данных имеют рассмотренные выше понятия потенциальных и первичных ключей. В отношении типов сущности и их атрибутов эти понятия формулируются следующим образом.
Потенциальным ключом называется атрибут или набор атрибутов, позволяющий однозначно идентифицировать каждый экземпляр типа сущности.
Первичным ключом называется потенциальный ключ, выбранный для уникальной идентификации экземпляров типа сущности.
Если ключ состоит из нескольких атрибутов, то он называется составным ключом.
На диаграммах атрибуты изображаются эллипсами, которые связаны со своими типами сущности линиями, при этом многозначные атрибуты выделяются двойным контуром; производные атрибуты – штриховым; для составных атрибутов указываются их компоненты. Наименования атрибутов входящих в первичный ключ подчёркиваются.
Для того чтобы не загромождать большие диаграммы детальной информацией, на них обычно прорисовывают только атрибуты, входящие в состав первичных ключей.
- Типы связей.
Типом связи называется осмысленная взаимосвязь между типами сущностей. Взаимосвязи между отдельными экземплярами сущностей называются экземплярами связей или просто связями.
Например: работник состоит в штате отделения – тип связи, а работник Иванов состоит в штате отделения №1 – экземпляр связи.
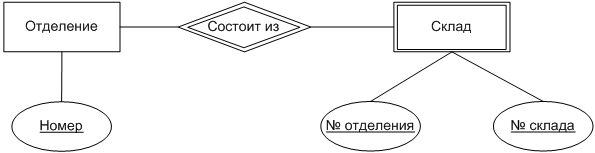
На диаграммах типы связи обозначаются ромбами. Если в связи участвует слабая сущность, то контур ромба должен быть двойным. Например, связи «отделение состоит из складов» соответствует такая диаграмма.
Для детального изучения свойств связей часто используют семантические диаграммы, на которых прорисовывают отдельные экземпляры связей (рис. 7). На них экземпляры сущностей обозначаются точками, а экземпляры связей – ромбиками.
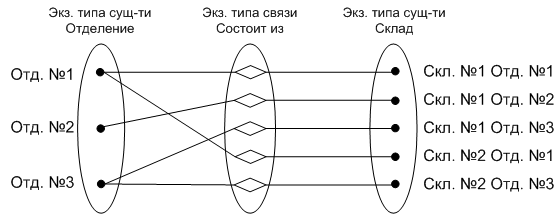
Естественно, что семантические диаграммы прорисовывают только для отдельных частей полной диаграммы для выяснения характера конкретных типов связи.
Степенью связиназывается количество охватываемых ею типов сущности.
Наиболее распространены бинарные (степени 2) связи, которые соединяют два типа сущности. Например, рассмотренная выше связь «состоит из» имеет степень 2. Реже встречаются связи больших степеней. Например, кватернарная (степени 4) связь «покупатель покупает товар»
Иногда встречаются рекурсивные (унарные) связи, в которых один и тот же тип сущности выступает в разных ролях. Например, руководитель отделения, являясь работником отделения, руководит всеми остальными работниками этого отделения (рис. 9).
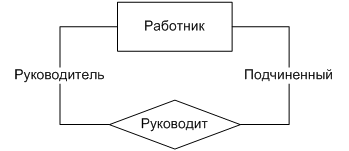
Рис. 9. Унарная связь
Важной характеристикой связи является ее показатель кардинальности. Различают следующие показатели кардинальности: один-к-одному (1:1), один-ко-многим (1:M), многие-ко-многим (M:N). Для определения кардинальности связи обычно используют семантические диаграммы.
Рассмотрим, например, связь «работник заведует складом» (рис. 12).
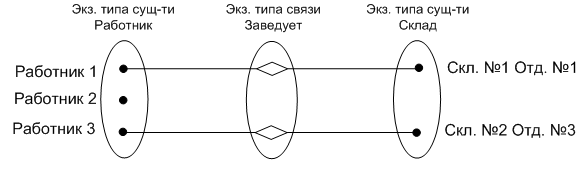
Еще одной важной характеристикой связи является степень участия в ней связываемых сущностей. Если все экземпляры некоторой сущности должны участвовать в рассматриваемой связи, то степень участия этой сущности будет полной. Если некоторые экземпляры сущности могут не участвовать в связи, то – частичной. Например, в связи «работник заведует складом» сущность «Работник» имеет частичное участие, т.к. не все работники являются заведующими складами. А сущность «Склад» в этой связи имеет полное участие, т.к. каждый склад должен иметь заведующего.
- Ловушки соединений. Специализация / генерализация.
Неправильная интерпретация связей на этапе создания ER-модели может послужить причиной появления ряда проблем при физической реализации базы данных. Эти проблемы получили название ловушек соединения. Различают ловушки разветвления и ловушки разрыва. Рассмотрим их на примерах.
Возьмем следующий фрагмент модели (рис. 18). На первый взгляд такая схема обеспечивает взаимосвязь сущностей «Работник» и «Склад» через сущность «Отделение». Проверим это заключение с помощью семантической диаграммы (рис. 19).

Рис. 18. Фрагмент ER-модели (вариант 1)
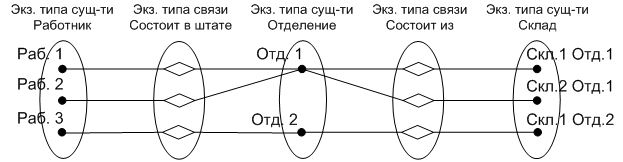
Рис. 19. Семантическая диаграмма (вариант 1)
Из семантической диаграммы видно, что такой вариант модели не позволит ответить на запрос: какие работники работают на первом складе первого отделения, поскольку Работник1 и Работник2 могут в этой модели быть приписаны как к первому, так и ко второму складам. Это и есть ловушка разветвления.
Ловушка разветвления имеет место в тех случаях, когда на схеме есть цепь связей между двумя типами сущности, но связи между отдельными экземплярами этих сущностей определяются неоднозначно.
Для устранения обнаруженной проблемы перестроим модель следующим образом (рис. 20). Соответствующая семантическая диаграмма будет иметь вид (рис. 21).

Рис. 20. Фрагмент ER-модели (вариант 2)
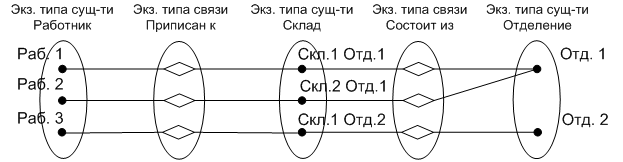
Рис. 21. Семантическая диаграмма (вариант 2)
В некоторых случаях для повышения информативности модели, уточнения функций отдельных подтипов имеет смысл выделить их на ER-модели. При этом категорию, соответствующую общему понятию (в данном случае «Работник»), называют суперклассом, а категории, соответствующие частным понятиям (руководитель отделения, заведующий складом) – подклассами. Сам процесс выделения подклассов из суперкласса называют специализацией.
Возможен и обратный процесс объединения нескольких подклассов в единый суперкласс, называемый генерализацией. В рассматриваемой постановке задачи может оказаться целесообразным объединение типов сущности «Поставщик» и «Покупатель» в суперкласс «Контрагент».
На схемах специализацию/генерализацию изображают следующим образом (рис. 25).

Буква “d” в кружке означает, что подклассы являются непересекающимися, то есть участник одного подкласса не может одновременно быть участником и другого подкласса. В противном случае, для пересекающихся подклассов, в кружке ставится буква “o”. Кроме того, на схемах отражают степень участия суперкласса в специализации. Если все члены суперкласса должны входить в какой-либо подкласс, то это полное участие (отмечается двойной линией связи для суперкласса), если такое требование отсутствует (например, не все работники являются руководителями отделений или заведующими складами) – то участие частичное. На рис. 26 изображена генерализация типов сущности «Поставщик» и «Покупатель» для случая, когда один и тот же контрагент может быть как поставщиком, так и покупателем.

- ER-модели.
Одним из важных инструментов, используемых на этапах концептуального и логического проектирования, являются модели «сущность - связь» («Entity – Relationship», ER-модели). В основе ER-моделирования лежат три понятия: тип сущности, атрибут, тип связи.
Пример:
- Нормализация и проблемы обновления.
1. Избыточность хранимой информации. Например, информация о некотором товаре (наименование, единица измерения, цена) будет повторяться для каждого склада, где этот товар хранится.
2. Проблема вставки кортежей. При добавлении на некоторый склад товара, который уже имеется на других складах, необходимо повторить ввод всех атрибутов товара точно в таком виде, в котором они уже записывались ранее для других складов. Здесь появляется потенциальная возможность ввода разных значений атрибутов одного и того же товара в строках, относящихся к различным складам. Кроме того, для рассматриваемого отношения первичный ключ определяется по атрибутам: номер отделения, номер склада, наименование и цена товара. Поэтому, если возникнет необходимость добавить информацию о новом складе, на котором еще нет товаров, то сделать это будет невозможно, так как нельзя добавить строку с незаполненными полями наименования и цены товара (нарушение требования целостности сущностей).
3. Проблема удаления кортежей. Если на каком-либо складе не останется товаров, то при удалении строки с последним товаром будет удалена и информация о самом складе.
4. Проблема изменения кортежей. При необходимости, например, изменить наименование какого-либо товара, соответствующие изменения должны быть сделаны в нескольких строках, относящихся к различным складам, на которых этот товар имеется в наличии. Соответственно, появляется возможность рассогласования информации в записях об одном и том же товаре на различных складах.
Замечание. Последние три из перечисленных выше проблем получили наименование проблем обновления.
Для исключения перечисленных проблем при проектировании баз данных используется набор приемов, получивший общее название: нормализация отношений.
Нормализацией называется метод проектирования отношений в реляционных базах данных, который позволяет минимизировать избыточность хранимой информации и исключить возможность появления проблем обновления.
Замечание. Существуют методики проектирования баз данных, полностью основанные на процессе нормализации. Рассматриваемая далее методика проектирования использует нормализацию в качестве вспомогательного средства проверки отношений, полученных иными способами.
Процесс нормализации заключается в последовательном приведении отношений в соответствие с требованиями первой нормальной формы (1НФ), второй нормальной формы (2НФ), третьей нормальной формы (3НФ), нормальной формы Бойса-Кодда (НФБК) и, в некоторых случаях, 4НФ и 5НФ.
Исходным материалом для нормализации обычно служат отношения, получаемые из существующих печатных форм и документов путем представления их в табличном виде.
- Функциональные зависимости атрибутов.
Атрибут  называется функционально зависимым от атрибута
называется функционально зависимым от атрибута  (
(  ), если каждому конкретному значению атрибута всегда соответствует одно и то же значение атрибута . При этом конкретному значению атрибута может соответствовать несколько значений атрибута .
), если каждому конкретному значению атрибута всегда соответствует одно и то же значение атрибута . При этом конкретному значению атрибута может соответствовать несколько значений атрибута .
Замечание. Под атрибутами и могут пониматься как отдельные атрибуты, так и группы атрибутов.
Атрибут в функциональной зависимости 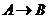 называется детерминантом.
называется детерминантом.
Приведем примеры функциональных зависимостей:
№ отд.  Адрес, телефон;
Адрес, телефон;
№ отд., № скл. ФИО зав. скл., Таб. № зав. скл.;
Таб. № зав. скл. № отд., № скл.;
№ отд., № скл., Наименование товара, Цена все остальные атрибуты.
Легко заметить, что понятие функциональной зависимости атрибутов практически совпадает с аналогичным понятием однозначной функции в функциональном анализе. При этом атрибут выступает, как аргумент функции 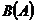 (см. рис. 1)
(см. рис. 1)
Для случая, когда представляет собой группу атрибутов, можно сформулировать понятие полной функциональной зависимости.
Атрибут называется полностью функционально зависимым от набора атрибутов , если он функционально зависит только от полного набора атрибутов и не зависит от любого его подмножества.
Или то же самое другими словами: функциональная зависимость называется полной, если она утрачивается при исключении любого атрибута из набора .
Примеры:
№ отд., № скл., Наименование товара, Цена Количество – полная;
№ отд., № скл., Наименование товара, Цена Адрес, Телефон – частичная (№ скл., Наименование товара и Цена могут быть исключены из набора );
№ отд., № скл. ФИО зав. скл., Таб. № зав. скл. – полная.
Атрибут 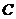 называется транзитивно зависимым от атрибута через атрибут , если имеют место зависимости и
называется транзитивно зависимым от атрибута через атрибут , если имеют место зависимости и  , но атрибут не зависит ни от , ни от .
, но атрибут не зависит ни от , ни от .
- 1НФ и 2НФ.
Отношение находится в первой нормальной форме, если в нем на пересечении каждого столбца с каждой строкой (т.е. в каждой ячейке) имеется значение и притом единственное.
Переход к 1НФ осуществляется простым дублированием значений в пустых ячейках (табл. 2). Очевидно, что при этом быстро растет избыточность представленной в таблице информации.
Отношение находится во второй нормальной форме, если оно отвечает требованиям 1НФ и все его атрибуты (не входящие в первичный ключ) полностью функционально зависят от атрибутов первичного ключа.
Переход от 1НФ к 2НФ осуществляется путем декомпозиции исходного отношения на несколько более мелких отношений. При этом в отдельные отношения выносятся атрибуты, частично зависимые от первичного ключа, с копией той части ПК, от которой они зависят полностью.
Выполним переход к 2НФ в нашем примере. Для этого выпишем полные функциональные зависимости для всех атрибутов, не входящих в ПК:
№ отд. Адрес, Телефон;
№ отд., № скл. ФИО зав. скл., Таб. № зав. скл.;
Наименование товара, Цена Ед.изм.;
№ отд., № скл., Наименование товара, Цена Количество.
Из анализа этих зависимостей видно, что из исходного отношения следует выделить следующие три отношения с копиями частей первичного ключа:
Отделение(№ отд., Адрес, Телефон);
Склад(№ отд., № скл., ФИО зав. скл., Таб. № зав. скл.);
Товар(Наименование товара, Цена, Ед.изм.)
после чего исходное отношение примет вид:
Наличие(№ отд., № скл., Наименование товара, Цена, Количество).
- 3НФ и НФБК.
Отношение находится в третьей нормальной форме, если оно отвечает требованиям 2НФ и в нем нет атрибутов (не входящих в первичный ключ), транзитивно зависимых от первичного ключа.
Для перехода к 3НФ также используется декомпозиция. При этом в отдельные отношения выносятся транзитивно зависимые атрибуты с копиями своих детерминантов
НФБК является более строгой разновидностью 3НФ. В ней учитываются зависимости не только от первичного ключа, но и от всех потенциальных ключей.
Отношение находится в нормальной форме Бойса-Кодда, если оно соответствует 3НФ и все его детерминанты являются потенциальными ключами.
Если отношение имеет единственный потенциальный ключ, то для него НФБК совпадает с 3НФ.
Замечание. На практике нарушение требований НФБК в 3НФ встречается редко, так как требует наличия нескольких составных потенциальных ключей, пересекающихся по набору атрибутов.
- Соотношение нормализации и производительности.
Соответствие отношений НФБК гарантирует отсутствие проблем обновления. Однако некоторая избыточность может все еще иметь место. Для ее уменьшения возможен переход к 4НФ и 5НФ, но обычно его не делают. Дело в том, что, уменьшая избыточность, мы создаем другую проблему.
Переход к старшим нормальным формам производится путем декомпозиции (разделения) исходного отношения на несколько отношений. А при выполнении запросов приходится решать обратную задачу – соединения отношений. Если при этом соединяемые отношения имеют большой объем, то операция построения соединений может потребовать существенных затрат времени, что негативно сказывается на скорости выполнения запросов.
Поэтому в процессе нормализации всегда приходится искать компромисс между избыточностью хранимой информации и скоростью ее обработки. Причем в некоторых случаях, в целях повышения производительности системы могут нарушаться требования 3НФ или даже 2НФ. Естественно, что одновременно должны предприниматься меры по недопущению возникновения проблем обновления, обусловленных отходом от требований нормализации.
- Определение типов сущностей, связей и их атрибутов.
На первом этапе концептуального проектирования необходимо в рассматриваемой предметной области выделить объекты и процессы, подпадающие под определение типа сущности. С этой целью из постановки задачи выписывают существительные, сочетания существительное + существительное, прилагательное + существительное и иногда причастные обороты. Из множества полученных сочетаний выбирают те сочетания, которые обозначают наиболее крупные, независимо существующие объекты, и отбрасывают сочетания, которые представляют собой характеристики (атрибуты) выбранных объектов.
Например, в нашей постановке задачи встречаются следующие существительные и сочетания: отделение, район города, номер отделения, адрес отделения, телефон отделения, руководитель отделения, склад, номер склада, заведующий складом, работник, …
Как наиболее крупные и независимые, среди них могут быть выделены: отделение, руководитель отделения, склад, заведующий складом, работник, … Соответственно, будут отброшены их характеристики: район города, номер отделения, адрес отделения, телефон отделения, номер склада, …
Как и все концептуальное проектирование, процесс определения набора типов сущности, достаточного для представления рассматриваемой предметной области, неоднозначен и может потребовать уточнений на последующих этапах. Кроме того, выбор осложняется тем обстоятельством, что пользователи зачастую используют разные наименования для обозначения одних и тех же объектов (отделение – офис, адрес – район города, склад – хранилище), а иногда – одно и то же наименование для разных объектов (руководитель отделения, заведующий складом – начальник). Поэтому и необходим постоянный контакт с пользователями для уточнения постановки задачи.
Предположим, что в нашем примере были выделены следующие типы сущности: отделение, руководитель отделения, склад, заведующий складом, работник, товар, поставщик, покупатель, накладная на покупку, накладная на продажу.
Вся полученная на данном этапе информация сводится в таблицу.
Определение типов связи осуществляется в два этапа. На первом этапе из постановки задачи извлекаются выражения, указывающие на взаимосвязи определенных ранее типов сущности.
Например: работой отделения управляет руководитель, в отделении имеется несколько складов, за работу склада отвечает заведующий складом, в отделении есть работники, часть работников прикреплена к определённым складам, …
На втором этапе следует проверить: не пропущены ли какие-либо связи. Для этого каждая произвольная пара типов сущности проверяется на предмет наличия связи.
Например, следует проверить – нет ли связи между поставщиками и отделениями, то есть, не работают ли определенные поставщики только с определенными отделениями, или же такой связи нет. И т.д.
После определения набора связей необходимо для каждой из них указать кардинальность и степень участия соответствующих типов сущности. Вся информация сводится в таблицу
Определение атрибутов и связывание их с типами сущности и связи выполняется также в два этапа. На первом этапе из постановки задачи выделяются все характеристики (атрибуты) выбранных ранее типов сущности. На втором этапе набор атрибутов уточняется. Для этого в отношении каждого типа сущности задается вопрос: какую информацию надо хранить о …
Замечание 1. На данном этапе рассматриваются только собственные атрибуты типов сущности, которые присущи им самим, а не унаследованы по связям с родительскими типами сущности. Например, для типа сущности Склад собственным является атрибут № склада, а № отделения наследуется от родительского типа сущности Отделение.
Замечание 2. Типы связи, как и типы сущности, могут иметь атрибуты. Так, например, тип связи «товар включается в накладную» имеет своим атрибутом количество товара, указываемое в накладной.
- Приведение модели в соответствие с требованиями реляционной МД.
Построенная на этапе концептуального проектирования модель может содержать структуры, плохо приспособленные для реализации в реляционной базе данных. Поэтому задача первого этапа логического проектирования состоит в исключении или преобразовании указанных структур. Решается эта задача в несколько приемов.
Дата добавления: 2018-05-31; просмотров: 413; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!