Язык SQL как язык работы с реляционными базами.
Министерство образования Российской федерации
Пермский государственный технический университет
И. А. Шмидт
Информационное обеспечение систем управления
Пермь 2003
УДК
Рецензенты:
д-р. техн. наук, проф. С. В. Бочкарев (Пермский государственный технический университет).
канд. техн.наук, доцент В. П. Казанцев (Пермский государственный технический университет).
Шмидт И. А.
Информационное обеспечение систем управления: конспект лекций /Перм. гос. техн. ун-т. Пермь, 2003. 43 с.
Представлен конспект лекций по курсу «Информационное обеспечение систем управления» для направления подготовки дипломированного специалиста 654500 «Электротехника, электромеханика и электротехнологии» специальности 180400 «Электропривод и автоматика промышленных установок и технологических комплексов» дневного и заочного отделений.
Конспект лекций рекомендуется для студентов изучающих курсы: «Информационное обеспечение систем управления» специальности 210200 «Автоматизация технологических процессов и производств».
Содержание
1. Архитектуры обработки данных..................................................................................................................... 4
1.1 Архитектура хост/терминал..................................................................................................................................... 4
Архитектура файл/сервер......................................................................................................................................................... 4
|
|
|
1.3 Архитектура клиент/сервер........................................................................................................................................ 5
1.4 Многозвенная архитектура...................................................................................................................................... 6
2 Способы организации данных.......................................................................................................................... 6
2.1 Сетевая модель данных.............................................................................................................................................. 6
2.2 Реляционная модель данных................................................................................................................................... 7
3 Язык SQL как язык работы с реляционными базами...................................................................... 8
4 Данные и взаимосвязи............................................................................................................................................... 9
4.1 Объекты............................................................................................................................................................................... 9
4.2 Первичные ключи. Что выбрать в качестве первичных ключей для каждой из таблиц?............ 11
4.3 Нормализация данных.............................................................................................................................................. 11
4.3.1 Первая нормальная форма................................................................................................................................... 12
|
|
|
4.3.2 Вторая нормальная форма.................................................................................................................................. 12
4.3.3 Третья нормальная форма................................................................................................................................... 12
4.4 Типы данных.................................................................................................................................................................. 13
4.4.1 Числовые целые типы данных............................................................................................................................ 13
4.4.2 Числовые типы данных с плавающей точкой................................................................................................ 13
4.4.3 Символьные типы данных.................................................................................................................................... 14
4.4.4 . Типы данных date, time и datetime.................................................................................................................... 14
4.4.5 Специальные типы данных.................................................................................................................................. 15
5 Основы методологии IDEF1X............................................................................................................................. 15
5.1 Предназначение IDEF1X............................................................................................................................................ 15
5.2 Сущности в IDEF1X и их атрибуты...................................................................................................................... 15
5.3 Связи между сущностями....................................................................................................................................... 16
|
|
|
5.4 Идентификация сущностей. Представление о ключах............................................................................. 17
5.5 Классификация сущностей в IDEF1X. Зависимые и независимые сущности............................... 19
5.6 Типы связей между сущностями. Идентифицирующие и неидентифицирующие связи.......... 19
5.7 Преимущества IDEF1X............................................................................................................................................... 20
5.8 Модель «склад» в нотации IDEF1X....................................................................................................................... 20
6 SQL (Structured System Language)................................................................................................................. 20
6.1 Структура запроса, основные ключевые слова и операторы................................................................ 20
6.1.1 Список основных операторов SQL.................................................................................................................... 21
6.1.2 Список основных ключевых слов SQL................................................................................................................ 21
6.2 Оператор SELECT.......................................................................................................................................................... 21
6.2.1 Предложение SELECT........................................................................................................................................... 23
6.2.2 Предложение FROM.............................................................................................................................................. 23
|
|
|
6.2.3 Предложение WHERE............................................................................................................................................ 24
6.2.4 Условия поиска........................................................................................................................................................ 24
6.2.5 Сортировка результатов запроса (предложение ORDER BY)................................................................. 27
6.2.6 Агрегатные функции.............................................................................................................................................. 28
6.2.7 Запросы с группировкой (предложение GROUP BY).................................................................................... 29
6.2.8 Условия поиска групп HAVING........................................................................................................................... 29
6.3 Работа с несколькими таблицами........................................................................................................................ 30
6.3.1 Объединение при помощи оператора WHERE................................................................................................ 30
6.3.2 Внутренние и внешние объединения.................................................................................................................. 31
6.4 Вложенные запросы................................................................................................................................................... 32
6.4.1 Исходная база данных........................................................................................................................................... 32
6.4.2 Вложение запросов................................................................................................................................................ 33
6.4.3 Оператор EXISTS................................................................................................................................................... 34
6.5 Объединение множества запросов в один..................................................................................................... 36
6.5.1 Когда можно выполнить объединение запросов ?....................................................................................... 36
6.5.2 Использование UNION с ORDER BY................................................................................................................... 37
6.6 Команды модификации данных.......................................................................................................................... 38
6.6.1 Ввод значений (INSERT)......................................................................................................................................... 38
6.6.2 Удаление строк из таблиц (DELETE)............................................................................................................... 39
6.6.3 Изменение значений поля (UPDATE)................................................................................................................... 39
6.6.4 Использование подзапросов для команд модификации данных................................................................ 40
6.7 Модификация структуры данных........................................................................................................................ 41
6.7.1 Команда СREATE TABLE...................................................................................................................................... 41
6.7.2 Команда ALTER TABLE......................................................................................................................................... 41
6.7.3 Команда DROP TABLE........................................................................................................................................... 42
Архитектуры обработки данных.
Проблемой многопользовательского доступа являлось обеспечение согласованной работы многих клиентов с одними данными, т. е. обеспечение целостности базы данных. При совместной работе нескольких пользователей с данными, может быть нарушена целостность данных, т.е. при обращении нескольких пользователей к одним и тем же данным содержание записи становится неопределенным. Для решения проблемы сохранения целостности существуют следующие архитектуры.
Архитектура хост/терминал.

Рис.1. Архитектура хост/терминал.
На рис.1 показана традиционная архитектура баз данных. При подобной архитектуре и СУБД, и физические данные размещаются на центральном компьютере (хост компьютере) вместе с приложением, принимающим входную информацию с пользовательского терминала (устройство ввода-вывода) и отображающим данные на экране пользователя. Для каждого терминала запускается своя копия приложения(процесс) которая обращается с базой данных. Приложение и СУБД работают на одном компьютере, и поскольку система обслуживает много различных пользователей, каждый из них ощущает снижение быстродействия по мере увеличения нагрузки на систему.
Преимущества: дешевые терминалы, невысокая загрузка сети (трафик), эффективнее решается проблема целостности.
Недостатки: мощность ограничена хостом, если в качестве терминала используются персональные компьютеры, то их ресурсы не используются.
Данная архитектура применима для больших и очень больших корпоративных сетей, построенных, как правило, на базе ОС Unix
1.2 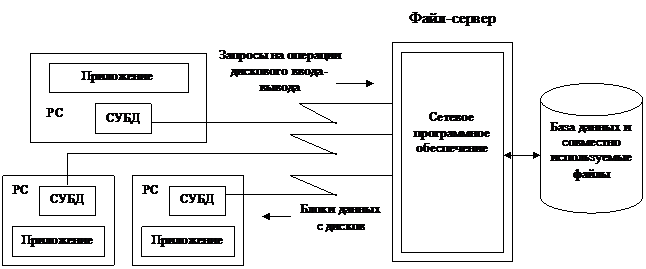 Архитектура файл/сервер.
Архитектура файл/сервер.
Рис.2.Архитектура файл/сервер.
Появление персональных компьютеров и локальных вычислительных сетей привело к разработке архитектуры файл/сервер. При такой архитектуре приложение, выполняемое на персональном компьютере, может получить “прозрачный” доступ к файл-серверу, на котором хранятся совместно используемые файлы. Когда приложению, работающему на ПК, требуется данные из совместно используемого файла, сетевое программное обеспечение автоматически считывает требуемый блок данных с сервера. В этой архитектуре мы имеем дело с файловым сервером. В данной архитектуре вопросами целостности должно заниматься каждое приложение.
Преимущества: простота. Малая стоимость.
Недостатки: низкая надежность и малое количество клиентов, вопросы целостности возлагаются на клиентские приложения.
Данная архитектура применяется в простых коробчатых вариантах программного обеспечения (Например, 1:C).
В настоящее время на рынке наиболее популярными СУБД, которые применяют данную архитектуру, являются такие продукты, как Fox Pro, D Base, Paradox, Access.
Архитектура клиент/сервер.
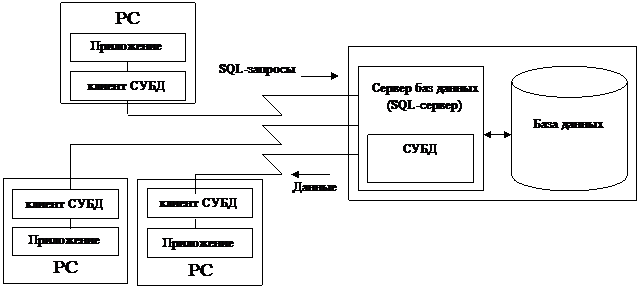
Рис.3. Архитектура клиент/сервер.
При такой архитектуре персональные компьютеры объединены в локальную сеть, в которой имеется сервер содержащий общие базы данных. В этой архитектуре мы имеем дело с сервером баз данных. Функции СУБД разделены на две части. Пользователь формирует запрос к БД. При помощи клиентской части СУБД запрос передается к серверу БД (ядро СУБД). Сервер БД выполняет запрос и при необходимости возвращает результат запроса клиенту. Пользовательские запросы объединяются в транзакции. Транзакция -логически связанная последовательность трансляции данных (запросов). Средством написания запросов является язык SQL, который является стандартным языком, обеспечивающим взаимодействие между клиентскими приложениями. Синтаксис и правила выполнения запросов SQL стандартизированы. В настоящее время этим занимается американский национальный институт стандартизации ANSI. Помимо стандартных возможностей каждый производитель СУБД может расширять свою версию SQL дополнительными возможностями, которые впоследствии могут стать частью стандарта.
Преимущества: использование ресурса, как клиента, так и сервера.
Недостатки: при очень большой загрузке (при высоком трафике) падает производительность.
Данная архитектура применяется в масштабе предприятия.
В настоящее время на рынке имеются огромное количество СУБД, применяющих данную архитектуру. Перечислим наиболее популярные: ORACLE, Sy Base, MS SQL, InterBase.
Многозвенная архитектура.

Рис.4.Многозвенная архитектура.
При такой архитектуре персональные компьютеры взаимодействуют с сервером приложений через тонкий клиент. Когда тонкому клиенту, работающему на ПК, требуется получить данные из совместно используемого файла, сервер приложений автоматически считывает требуемый блок данных с SQL-сервера и, преобразуя их в формат HTML, выдает тонкому клиенту.
Данная архитектура является гибридной. Тонкий клиент позволяет в стандартном формате работать с любыми данными. Сервер приложений является инструментом для отображения данных в формате HTML. Эта архитектура применяется в таких сетях, как Internet (всемирная сеть), Intranet (внутренняя сеть). В сервере приложений запускается столько копий приложений, сколько пользователей требует информацию. Широко применяется программное обеспечение для серверов приложений, называемое Apache.
Преимущества: удобство и гибкость (при замене модификации приложения достаточно заменить его только на сервере приложений), невысокие требования для клиентского компьютера.
Недостатки: ограничение возможностей, тонкий клиент имеет ограниченные возможности.
Способы организации данных.
Сетевая модель данных
Сетевая модель организована на принципе соответствия логической и физической структурах данных. Связи между сущностями базы данных указаны непосредственно. Прикладная программа может:
· найти конкретную запись предка по ключу (например, номер клиента);
· перейти к первому потомку в конкретном множестве (первый заказ, размещенный клиентом);
· -перейти в сторону от одного потомка к другому в конкретном множестве (следующий заказ, сделанный этим же клиентом);
· -перейти вверх от потомка к его предку в другом множестве (служащий, принявший заказ).
Сетевые базы данных обладают рядом преимуществ:
· Гибкость. Множественные отношения предок/потомок позволяют сетевой базе данных хранить данные, структура которой сложнее простой иерархии.
· Стандартизация. Появление стандарта CODASYL увеличило популярность сетевой модели, а такие поставщики мини-компьютеров, как Digital Equipment Corporation и Data General, реализовали сетевые СУБД.
· Быстродействие. Вопреки своей большой сложности, сетевые базы данных достигли быстродействия, сравнимого с быстродействием иерархических баз данных. Множества представляются указателями на физические записи данных, и в некоторых системах администратор может задать кластеризацию данных на основе множества отношений.
Рассмотрим сетевую модель на примере.
Рассмотрим систему получения, отпуска товара на склад. Отпуск товара по расходным или приходным документам . Каждый документ имеет реквизиты (ДАТА,НОМЕР), НАЗВАНИЕ и НОМЕР СКЛАДА , НАЗВАНИЕ ПОСТАВЩИКА или ПОЛУЧАТЕЛЯ . Кроме этого документ имеет список получаемых или отпускаемых материальных ценностей . На основании данного документа осуществляется перемещение материальных ценностей . Итоговые данные о всех перемещениях фиксируются в сущности ОСТАТОК. Один документ связан с одним клиентом .
 |
Рис.5.Структура сущность-связь.
Если один документ связан со многими перемещениями (например, один товар и несколько цен) то связь называется один ко многим.
Если материальная ценность связана со многими перемещениями, то связь называется многие к одному.
Кроме того, существуют следующие связи: один к одному и многие ко многим.
Достоинства: наглядность, быстрая работа с данными.
Недостатки: сложность описания, нет стандартных средств описания сетевой модели.
Реляционная модель данных.
Реляционная модель данных была создана Коддом в 1970 году и вызвала всеобщий интерес. Реляционная модель была попыткой упростить структуру базы данных. В ней отсутствовали явные указатели на предков и потомков, а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы.
К сожалению, практическое определение понятия “реляционная база данных” оказалась гораздо более расплывчатым, чем точное математическое определение, данное этому термину Коддом в 1970 году. В первых реляционных СУБД не были реализованы некоторые из ключевых частей модели Кодда, и этот пробел был восполнен только в последствии. По мере роста популярности реляционной концепции реляционными стали называться многие базы данных, которые на деле таковыми не являлись.
Реляционной называется база данных, в которой все данные, доступные пользователю, организованы в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами.
· У каждой таблицы есть уникальное имя.
· В каждой таблице есть один или несколько столбцов, которые упорядочены в направлении слева направо.
· В каждой таблице есть ноль или более строк, каждая из которых содержит одно значение данных в каждом столбце; строки в таблице не упорядочены.
· Все значения данных в одном столбце имеют одинаковый тип данных и входят в набор допустимых значений, который называется доменом столбца.
Отношение между таблицами реализуется с помощью содержащихся в них данных. В реляционной модели данных для представления этих отношений используются первичные и внешние ключи.
· Первичным ключом называется столбец или группа столбцов таблицы, значения которых уникальным образом идентифицируют каждую строку таблицы. У таблицы есть только один первичный ключ.
· Внешним ключом называется столбец или группа столбцов таблицы, значения которых совпадают со значениями первичного ключа другой таблицы. Таблица может содержать несколько внешних ключей, связывающих ее с одной или несколькими другими таблицами.
· Пара “первичный ключ- внешний ключ” создает отношение предок/потомок между таблицами, содержащими их.
Каждая таблица содержит строки и столбцы.
Каждая строка (называемая также записью) соответствует определенному индивидууму, каждый столбец содержит значения соответствующего типа данных, представленных в каждой строке. Строки таблицы предполагаются расположенными в произвольном порядке.
В отличие от строк столбцы таблицы (также называются полями) упорядочены и пронумерованы.
Атрибут- пересечение строки и столбца, атрибут можно рассматривать как значение поля..
Язык SQL как язык работы с реляционными базами.
SQL является инструментом , предназначенным для обработки и чтения данных , содержащихся в компьютерной базе данных. SQL-это сокращенное название структурированного языка запросов (Structured Query Language).Как следует из названия , SQL является языком программирования , который применяется для организации взаимодействия пользователя с базой данных . На самом деле SQL работает только с базами данных одного определенного типа, называемых реляционными.
Сегодня SQL представляет собой нечто гораздо большее, чем простой инструмент создания запросов, хотя именно для этого он и был первоначально предназначен. Несмотря на то, что чтение данных по-прежнему остается одной из наиболее важных функций SQL, сейчас, этот язык используется для реализации всех функциональных возможностей, которые СУБД представляют пользователю, а именно:
· Организация данных. SQL дает пользователю возможность изменять структуру представления данных, а также устанавливать отношения между элементами базы данных.
· Чтение данных. SQL дает пользователю или приложению возможность читать из базы данных содержащиеся в ней данные и пользоваться ими.
· Обработка данных. SQL дает пользователю или приложению возможность изменять базу данных, т. е. добавлять в нее новые данные, а также удалять или обновлять уже имеющиеся в ней данные.
· Управление доступом. С помощью SQL можно ограничить возможности пользователя по чтению и изменению данных и защитить их от несанкционированного доступа.
· Совместное использование данных. SQL координирует совместное использование данных пользователями, работающими параллельно, чтобы они не мешали друг другу.
· Целостность данных. SQL позволяет обеспечить целостность базы данных, защищая ее от разрушения из-за несогласованных изменений или отказа системы.
Таким образом, SQL является достаточно мощным языком для взаимодействия с СУБД. SQL на сегодняшний день является единственным стандартным языком для работы с реляционными базами данных. SQL- это достаточно мощный и в то же время относительно легкий для изучения язык.
Успех языку SQL принесли следующие его особенности:
· независимость от конкретных СУБД;
· переносимость с одной вычислительной системы на другую;
· наличие стандартов;
· одобрение компанией IBM;
· поддержка со стороны компании Microsoft;
· реляционная основа;
· высокоуровневая структура напоминающая английский язык;
· возможность выполнения специальных интерактивных запросов;
· обеспечение программного доступа к базам данных;
· полноценность как языка, предназначенного для работы с базами данных;
· возможность динамического определения данных;
· поддержка архитектуры клиент/сервер.
Данные и взаимосвязи.
Мы начинаем рассмотрение структуры базы данных с построения простой модели взаимосвязи объектов. В самых общих чертах такое моделирование (иногда называемое объектным моделированием) подразумевает определение:
· Объектов, информация о которых будет содержаться в базе данных
· Свойств этих объектов
· Взаимосвязей между ними
Объекты.
Сначала рассмотрим объекты, на основе которых будет построена наша база данных. Без учета финансовой информации список объектов будет выглядеть так:
· Клиенты, с которыми мы имеем дело
· Документы, в которых числятся данные о клиентах и их товарах
· Склады, в которых располагаются товары
Каждый пункт в этом списке описывает объект, существующий независимо от других объектов в мире нашей базы. Каждый такой объект представляется отдельной таблицей. (Ряд других объектов также представлен в этой базе данных отдельными таблицами, но пока не будем забегать вперед).
Каждый из этих объектов обладает собственными свойствами, которые также записаны в базе данных. Среди них:
· Название (имя) клиента
· Реквизиты клиента
· Реквизиты банка
· Тип документа
· Город, в котором расположен клиент
· Название материальной ценности (товара)
· Цена товара
· Группа, в которую входит материальная ценность.
Каждый пункт этого списка описывает отдельное свойство или атрибут рассматриваемого объекта («клиент», «документ», «город» или «склад») и является потенциальным столбцом в базе данных. Названия столбцов должны быть предельно ясными (назначение столбца должно быть понятно из названия) и кратким (чтобы упростить ввод названий и уменьшить их ширину).
Создание списка объектов и их свойств должно помочь вам решить, какие таблицы и столбцы нужно включить в базу данных.
В результате вы можете получить, например, следующий макет базы:




 Таблица Документ
Таблица Документ
Код дата номер Idn_клиента Idn_склада
Таблица Клиент

 Idn Idn_города название(имя) реквизиты Idn_банка
Idn Idn_города название(имя) реквизиты Idn_банка

Таблица Склад



 Idn Idn_мат.отв реквизиты название
Idn Idn_мат.отв реквизиты название
Таблица Перемещение
 Idn порядков№ код_док дата_док номер_док Idn_группы Idn_мат.цен кол-во цена
Idn порядков№ код_док дата_док номер_док Idn_группы Idn_мат.цен кол-во цена
Таблица Остатки
 Idn Idn_группы Idn_мат.ценкол-во цена Idn_склада Idn_перемещения
Idn Idn_группы Idn_мат.ценкол-во цена Idn_склада Idn_перемещения
 Таблица Города Таблица Группы Таблица Банки
Таблица Города Таблица Группы Таблица Банки



 Idn название Idn название Idn реквизиты
Idn название Idn название Idn реквизиты
Дата добавления: 2018-05-30; просмотров: 59; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!