Декодирование с использованием адаптивного словаря
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ ЛНР
«ЛУГАНСКИЙ НАЦИОНАЛЬНЫЙ УНИВЕРСИТЕТ
Имени ВЛАДИМИРА ДАЛЯ»
МЕТОДИЧЕСКИЕ УКАЗАНИЯ
к лабораторным работам №7 – №12 по дисциплине
"Теория кодирования информации "
для студентов направления подготовки/специальности:
"09.03.04 – Программная инженерия"
Авторы: ст. преп. Кийко А.В., асс. Кийко С.А.
Луганск 2017
Лабораторная работа № 7
Тема: Адаптивный код Хаффмана.
Теоретические сведения
При решении реальных задач истинные значения вероятностей источника, как правило, неизвестны или могут изменяться с течением времени, поэтому для кодирования сообщений применяют адаптивные модификации методов кодирования.
Большинство адаптивных методов для учета изменений статистики исходных данных используют так называемое окно. Окном называют последовательность символов, предшествующих кодируемой букве, а длинойокна - количество символов в окне.
Обычно окно имеет фиксированную длину и после кодирования каждой буквы текста окно передвигается на один символ вправо. Таким образом, код для очередной буквы строится с учетом информации, хранящейся в данный момент в окне (рис. 1).

Рис. 1. Схема перемещения окна при кодировании
При декодировании окно передвигается по тексту аналогичным образом. Информация, содержащаяся в окне, позволяет однозначно декодировать очередной символ.
|
|
|
Оценка избыточности при адаптивном кодировании является достаточно сложной математической задачей, поскольку общая избыточность складывается из двух составляющих: избыточность кодирования и избыточность, возникающая при оценке вероятностей появления символов. Поэтому эффективность методов адаптивного кодирования зачастую оценивают экспериментальным путем.
Однако для всех методов адаптивного кодирования, которые приводятся ниже, справедлива следующая теорема:
Теорема. Величина средней длины кодового слова при адаптивном кодировании удовлетворяет неравенству:
 ,
,
где Н – энтропия источника информации;
C – константа, зависящая от размера алфавита источника и длины окна.
Адаптивный код Хаффмана
В 1978 году Р. Галлагер предложил метод кодирования источников с неизвестной или меняющейся статистикой, основанный на коде Хаффмана, и поэтому названный адаптивным кодом Хаффмана.
Адаптивный код Хаффмана используется как составная часть во многих методах сжатия данных. В нем кодирование осуществляется на основе информации, содержащейся в окне длины W. Алгоритм такого кодирования заключается в выполнении следующих действий:
1. Перед кодированием очередной буквы подсчитываются частоты появления в окне всех символов исходного алфавита А={a1, a2,..., an}. Обозначим эти частоты как q(a1), q(a2), ..., q(an). Вероятности символов исходного алфавита оцениваются на основе значений частот символов в окне:
|
|
|
P(a1)= q(a1)/W, P(a2) =q(a2)/W, ..., P(an)= q(an)/W.
2. По полученному распределению вероятностей строится код Хаффмана для алфавита А.
3. Очередная буква кодируется при помощи построенного кода.
4. Окно передвигается на один символ вправо, вновь подсчитываются частоты встреч в окне букв алфавита, строится новый код для очередного символа, и так далее, пока не будет получен код всего сообщения.
 Пример. Рассмотрим пример адаптивного кодирования с помощью метода Хаффмана для алфавита А={a1, a2, a3, a4} и длины окна W = 6 (рис. 2).
Пример. Рассмотрим пример адаптивного кодирования с помощью метода Хаффмана для алфавита А={a1, a2, a3, a4} и длины окна W = 6 (рис. 2).
Рис. 2. Кодирование адаптивным кодом Хаффмана
Рассмотрим подробно этапы кодирования сообщения.
При кодировании буквы a3получаем следующие частоты встреч символов в окне: q(a1)=3, q(a2)=1, q(a3)=1, q(a4)=1. Тогда вероятности символов алфавита A оцениваются так:



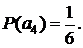
Строим код Хаффмана для полученного распределения вероятностей (рис. 3, а) и кодируем символ а3 кодовым символом 001.
a)
| Символы | Вероятности | Построение кода | Кодовые cлова |
| а1 | 1/2 |  1 1
| 1 |
| а2 | 1/6 | 1/2 0 | 01 |
| а3 | 1/6 | 1/3 | 001 |
| а4 | 1/6 | 000 |
|
|
|
б)
| Символы | Вероятности | Построение кода | Кодовые слова |
| а1 | 1/3 |  1 1
| 1 |
| а2 | 1/6 | 1/3 2/3 0 | 011 |
| а3 | 1/3 | 00 | |
| а4 | 1/6 | 010 |
в)
| Символы | Вероятности | Построение кода | Кодовые слова |
| а1 | 1/3 |   1/2 1 1/2 1
| 11 |
| а2 | 0 | 1/6 0 | 101 |
| а3 | 1/2 |
| 0 |
| а4 | 1/6 | 
| 100 |
Рис. 3. Построение адаптивного кода Хаффмана
Далее передвигаем окно на один символ вправо и снова подсчитываем частоты встреч символов в окне q(a1)=2, q(a2)=1, q(a3)=2, q(a4)=1 и оцениваем вероятности:


Строим код на основе полученных оценок вероятностного распределения (рис. 3, б) и кодируем очередной символа3 другим кодовым словом - 00. В этом случае частота встречи в окне символа а3увеличилась, соответственно уменьшилась длина его кодового слова.
Снова передвигаем окно на один символ вправо, подсчитываем частоты встреч символов в окне q(a1)=2, q(a2)=0, q(a3)=3, q(a4)=1 и оцениваем вероятности:
|
|
|


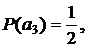

Строим код на основе полученных оценок вероятностного распределения (рис. 3, в)) и кодируем очередной символа2 кодовым словом - 101. Таким образом, после кодирования символов a3a3a2 получаем кодовую последовательность 00100101.
Алгоритм на псевдокоде
Адаптивный код Хаффмана
Обозначим:
w – окно:
mas – массив вероятностей символов и кодовых слов.
DO (i=1,…n) w[i]:=a[i] OD (заполняем окно символами алфавита)
DO (not EOF) (пока не конец входного файла)
DO (i=1,…,n) mas[i].p:=0 OD
DO (i=1,…,n) mas[w[i]].p:= mas[w[i]].p +1 OD (частоты встречи
символов в окне)
DO (i=1,…,n) mas[w[i]].p:= mas[w[i]].p/n OD (вероятности символов
в окне)
Сортировка(mas)
DO (i=1,…,n) (определяем количество
IF (mas[i].p=0) OD ненулевых вероятностей)
OD
Huffman(i,P) (строим код Хаффмана)
C:=Read( ) (читаем следующий символ из файла)
Write(mas[C].code) (код символа – в выходной файл)
DO (i=1,…,n-1) w[i]:= w[i+1] OD
w[n]:=C (включаем в окно текущий символ)
OD
Порядок выполнения работы
1. Изучить теоретический материал.
2. Закодировать текст на английском языке (использовать файл не менее 1 Кб) с помощью адаптивного кода Хаффмана.
3. Вычислить коэффициент сжатия данных как процентное отношение длины закодированного файла к длине исходного файла.
Контрольные вопросы
1. Как адаптивные методы учитывают изменение статистики исходных данных?
2. В чем заключается адаптивный код Хаффмана?
Лабораторная работа № 8
Тема: Код «Стопка книг».
1. Теоретические сведения
Этот метод был предложен Б. Я. Рябко в 1980 году. Название метод получил по аналогии со стопкой книг, лежащей на столе. Обычно сверху стопки находятся книги, которые недавно использовались, а внизу стопки – книги, которые использовались давно, и после каждого обращения к стопке использованная книга кладется сверху стопки.
До начала кодирования буквы исходного алфавита упорядочены произвольным образом и каждой позиции в стопке присвоено свое кодовое слово, причем первой позиции стопки соответствует самое короткое кодовое слово, а последней позиции - самое длинное кодовое слово. Очередной символ кодируется кодовым словом, соответствующим номеру его позиции в стопке, и переставляется на первую позицию в стопке.
Пример. Приведем описание кода на примере алфавита A={a1, a2, a3, a4}. Пусть кодируется сообщение а3а3а4а4а3…
1. Символ а3находится в третьей позиции стопки, кодируется кодовым словом 110 и перемещается на первую позицию в стопке, при этом символы а1и а2 смещаются на одну позицию вниз.
2. Следующий символ а3 уже находится в первой позиции стопки, кодируется кодовым словом 0 и стопка не изменяется.
3. Символ а4 находится в последней позиции стопки, кодируется кодовым словом 111 и перемещается на первую позицию в стопке, при этом символы а1, а2, а3 смещаются на одну позицию вниз.
4. Следующий символ а4 уже находится в первой позиции стопки, кодируется кодовым словом 0 и стопка не изменяется.
5. Символ а3 находится во второй позиции стопки, кодируется кодовым словом 10 и перемещается на первую позицию в стопке, при этом символ а4 смещается на одну позицию вниз.
| № | Кодовое слово | Начальная «стопка» | Преобразования «стопки» | ||||
| 1 | 0 | а1 |  а3 а3
|   а3 а3
|  а4 а4
|   А4 А4
| а3 |
| 2 | 10 |  а2 а2
| а1
|  а1 а1
| а3
| А3 | а4 |
| 3 | 110 | а3 |  а2 а2
|  а2 а2
|  а1 а1
|  А1 А1
| а1 |
 4 4
| 111 | а4
|  а4 а4
| а4 |  а2 а2
|  А2 А2
|  а2 а2
|
Рис. 1. Кодирование методом «стопка книг»
Таким образом, закодированное сообщение имеет следующий вид:

Рассмотренный метод сжимает сообщение за счет того, что часто встречающиеся символы будут находиться в верхних позициях «стопки книг» и кодироваться более короткими кодовыми словами. Эффективность метода особенно заметна при кодировании серий одинаковых символов. В этом случае все символы серии, начиная со второго, будут кодироваться самым коротким кодовым словом, соответствующим первой позиции «стопки книг».
При декодировании используется такая же «стопка книг», находящаяся первоначально в том же состоянии. Над «стопкой» проводятся такие же преобразования, что и при кодировании. Это гарантирует однозначное восстановление исходной последовательности.
Приведение описание данного алгоритма на псевдокоде.
Алгоритм на псевдокоде
Кодирование кодом «Стопка книг»
Обозначим:
code – массив кодовых слов для позиции «стопки»;
s_in – строка для кодирования;
s_out – результат кодирования;
S – строка, содержащая исходный алфавит.
l:=<длина s_in>
DO (i=1,…l)
T:=<номер символа s_in[i] в строке S>
s_out:=s_out+code[t]
stmp:=S[t]
delete(S,t,1) (преобразование
insert(stmp,S,1) строки S)
OD
Порядок выполнения работы
1. Изучить теоретический материал.
2. Закодировать текст на английском языке (использовать файл не менее 1 Кб) с помощью кода «Стопка книг».
3. Вычислить коэффициент сжатия данных как процентное отношение длины закодированного файла к длине исходного файла.
Контрольные вопросы
1. Как адаптивные методы учитывают изменение статистики исходных данных?
2. Какова основная идея кода «Стопка книг»?
Лабораторная работа № 9
Тема: Интервальный код.
1. Теоретические сведения
Интервальный код был предложен П. Элиасом в 1987 году. В нем используется окно длины W, т.е. при кодировании символа xi исходной последовательности учитываются W предыдущих символов:

При кодировании символа xi определяется расстояние (интервал) до его предыдущей встречи в окне длины W. Обозначим это расстояние l(xi). Если символ xi есть в окне, то значение l(xi) равно номеру позиции символа в окне. Позиции в окне нумеруются справа налево. Если символа xi нет в окне, то l(xi) присваивается значение W+1, а xi кодируется словом, состоящим из l(xi) и самого символа xi. После кодирования очередного символа окно сдвигается вправо на один символ.
Пример.Рассмотрим описание кода для исходного алфавита A={a1, a2, a3, a4}, пусть длина окна W=3. Возьмем некоторый префиксный код s для записи числа l(xi):
| l (хi) | 1 | 2 | 3 | 4 |
| σi | 0 | 10 | 110 | 111 |
Пусть кодируется последовательность а1а1а2а3а2а2… (рис. 1)
1. Сначала символа а1 нет в окне, поэтому на выход кодера передается 111 и восьмибитовый ASCII-код символа а1 Затем окно сдвигается на одну позицию вправо.
2. При кодировании следующего символа а1 на выход кодера передается 0, так как теперь символ а1 находится в первой позиции окна. Далее окно снова сдвигается на одну позицию вправо.
3. Следующий символ а2 кодируется комбинацией 111 и восьмибитовым ASCII-кодом символа а2, так как символа а2 нет в окне. Окно снова сдвигается на одну позицию вправо.
4. Следующий символ а3 кодируется комбинацией 111 и восьмибитовым ASCII-кодом символа а3, так как символа а3 нет в окне. Окно снова сдвигается на одну позицию вправо.
5. Следующий кодируемый символ а2 находим во второй позиции окна и поэтому кодируем комбинацией 10. Окно снова сдвигается на одну позицию вправо.
6. И последний символ а2 находим в первой позиции окна и поэтому кодируем комбинацией 0. Таким образом, закодированное сообщение имеет следующий вид:

Рис. 1. Кодирование интервальным кодом
 При декодировании используется такое же окно, как и при кодировании. По принятому кодовому слову можно определить, в какой позиции окна находится данный символ. Если поступает код 111, то декодер считывает следующий за ним символ. Каждая декодированная буква полностью включается в окно.
При декодировании используется такое же окно, как и при кодировании. По принятому кодовому слову можно определить, в какой позиции окна находится данный символ. Если поступает код 111, то декодер считывает следующий за ним символ. Каждая декодированная буква полностью включается в окно.
Сжатие данных интервальным кодом достигается за счет малых расстояний между встречами более вероятных букв, что позволяет получить более короткие кодовые слова.
Алгоритм на псевдокоде
Кодирование интервальным кодом
Обозначим:
code – массив кодовых слов для записи числа l(Xi);
s_in – строка для кодирования;
s_out – результат кодирования.
l:=<длина s_in>
DO (i=1,…l)
t:=0
found:=нет
DO (j=i-1,…,i-W)
t:=t+1
IF (j>0) и (s_in[i]=s_in[j])
s_out:=s_out+code[t]
found:=да
OD
FI
OD
IF (not found) s_out:=s_out+code[n]+s_in[i] FI
OD
Порядок выполнения работы
1. Изучить теоретический материал.
2. Закодировать текст на английском языке (использовать файл не менее 1 Кб) с помощью адаптивного интервального кода.
3. Вычислить коэффициентт сжатия данных как процентное отношение длины закодированного файла к длине исходного файла.
Контрольные вопросы
1. Как адаптивные методы учитывают изменение статистики исходных данных?
2. За счет чего достигается сжатие данных при кодировании интервальным кодом?
Лабораторная работа 10
Тема: Частотный код.
1. Теоретические сведения
В 1990 году Б. Я. Рябко предложил алгоритм кодирования, использующий алфавитный код Гилберта-Мура, и названный частотным. Частот-ный код относится к адаптивным методам сжатия с постоянной избыточностью. Средняя длина кодового слова для этого метода определяется только длиной окна, по которому оценивается статистика кодируемых данных, к тому же частотный код имеет достаточно высокую скорость кодирования и декодирования.
Рассмотрим алгоритм построения частотного кода для источника с алфавитом А={a1, a2, ..., an}. Пусть используется окно длины W, т.е. при кодировании символа xi исходной последовательности учитываются W предыдущих символов:

Возьмем размер окна такой, что W = (2r - 1)·n, где n = 2k - размер исходного алфавита; r, k - целые числа.
Порядок построения кодовой последовательности следующий:
1. Сначала оценивается число встреч в окне xi-W...xi-1 всех букв исходного алфавита. Обозначим эти величины через P(aj), j=1,…,n.
2. P(aj) увеличивается на единицу и обозначается как 
3. Вычисляются суммы Qi , i = 1,…,n

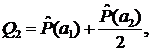
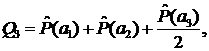
…
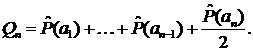
4. Для кодового слова символа аj беретсяk знаков от двоичного разложения Qj, где 
5. Далее окно сдвигается на один символ вправо и для кодирования следующего символа алгоритм вновь повторяется.
Пример. Пусть А={a1, a2, a3, a4}, длина окна W=4. Необходимо закодировать последовательность символов:

Построим кодовое слово для символа а3.
1. Оценим частоты встреч в текущем "окне" всех символов алфавита:



2. Вычислим суммы Qj:
Q1 = 1
Q2 = 1 + 0.5 = 1.5
Q3 = 1 + 1 + 2 = 4
Q4 = 1 + 1 + 4 + 1 = 7
3. Определим длину кодового слова для а3:
k = 1 + log (4+4) - ëlog 4û = 1 + 3 - 2 = 2
4. Двоичное разложение Q3 =1002 , берем первые 2 знака. Таким образом, для текущего символа а3 кодовое слово 10.
Алгоритм на псевдокоде
Частотный код
Обозначим:
w – окно;
W – размер окна;
P – массив частот символов;
Q – массив для величин Qi.
DO (i=1,…n) w[i]:=a[i] OD (заполняем окно символами алфавита)
DO (not EOF) (пока не конец входного файла)
DO (i=1,…,n) P [i]:=1 OD
DO (i=1,…,n) P [w[i]]:= P [w[i]] +1 OD (частоты встречи символов в
окне)
pr:=0
DO (i=1,…,n)
Q [i] := pr+ P [i] /2 (вычисляем суммы)
pr:=pr+ P [i]
OD
C:=Read( ) (читаем следующий символ из файла)
DO (j=1,…,n)
IF (C=a[i]) m:=j FI (определяем номер символа в алфавите)
OD
k = 1 + log2 (n+W) - ëlog2 P[m] û (длина кодового слова)
DO (j=1,…,k) (формирование кодового слова в
Q [m]:=Q [m] *2 двоичном виде)
code:= ëQ [m]û
IF (Q [m] >1) Q [m]:= Q [m] - 1 FI
OD
Write(code) (код символа – в выходной файл)
DO (i=0,…,n-1) w[i]:= wћiါ1] OF
w[n]=Ƀ Ƞ Ġ † !(включаем в окఽо текущий химвол)
OD
Порядок выполненая работы
1. Изычить†теоретический материал.Закоаировать текст наРанглиѹсоом"языке (испольԷҾвать файл не менее 1 Кб) с ѿ萾мощьَ частотного кԾда.
3. Вычᐸслить коэффициент Ёжатия данных как процентное от落ошение длины закодироваЭного файла к длине исходного файла.
4. Контрольные воп⑀осы
1. Как адаптивные методы учитъваюూဠизмен萵落ие старистики исходных данеыՅ?
2. Чем отлчаетсяĢчастотный код оӂ䔺ода Гилеерта-Мура=
䀍
ဍ
耍Лабораторная работа № 11
Тема: Словарные коды.
Теоретические сведения
Словарные коды класса LZ широко используются в практических задҰчах. На их оснҾве ревлизовано ѼножеӅтво программ-арՅиваторов. Эти методы также используютс при сжатии изображений в модемах и другѸх цифровыЅ устройствах передач萸 м хранеҽия инфо䑀мᐰцసи.
бловарные`методы сжатия данеыᑅ позزоляют эффек葂ивно кодироватьȠисточниԺи с неазвесцной или меняющейుя с⁂ат萸стикоహ Вжными0свойствами этх䀠методов явкяются высокая скорость кодирования и декодировѸния, а также ЮтносительнҾ небольшая слоЖность реапиЗации. КроЬе Ѣово, LZ-методы обладают способностью бѫсЂро адаптироваться"к изменению статистической стЀуктуры сообщенийီ
СловарныԵ коды$кмтенси2но исхледуются и конЁтруи䑀уются耬ဠначинаЏ с 1977 года, когда появи䐻ось о萿асайие первого алгоритма, предложенногؾ А. ЛемпелОм и Я. ЗиҲКм. В насՂоящ䐵е زрҵмя существует множество метоаов, о萡ъеᐴиԽенныхࠠв класс LZ-кодов, которые ?редстбВляют с萾бой различؽые модификцظи метода Лемпела-Зив.
Общذя схема0Һодироввния, исполь7уемая в LZ-Ьетодах, заключается в следующем.ԟри к>дирован8и сообщение разбиваеЂAя на с;пва переменной длинъ. П@и обрабођке очерХдйого слова ведется поиᓁо ему Яодобного в ранее закодированѽоع части сообщения.ЕслԸ словоĠнайдено, тм"лередается соответствующий еиу код. Если слово не найдено, то передҰетсӏ ⑁пصциаьы䐹 симвоп, обозначѰющий его от㑁утствие,䀠и новое обозначенИе этого сложа. КаждѾе новое слово, не встр5чавՈееся ీанవе, запоминаᐵтся, ему†рисваигరется"иЭдивидуалᑌный код.
При`декодировании по принятому код⑃ определяется закодиӀоваఝное слжво. ВĠслучае получения специальЭогЮ символа, сиг=ализирующего о передаче нового слова, принятое слово запоминаетӁӏ,ဠи ему присваивается такой же, как и при кодмровании, код. Раким 䐾бразом, декоеирование является Ծднозначным,䀠т.к. каждому слову сооѢветЁтТует своҹ Չобс䑆венный 萺од.
По способك организацԸ鰸 хранения и поиска耠слов словарные методыဠможؽ萾 рరздеить на Фве большие групҿы耺
− алгоритмы, осуществляющиеဠᐿоиск слов в какой-либо части р萰нее!Чакодированного ткста, назыжаемой окнпм;
− алгоритмы, использсЎщие адаптивный словарь, который включает ранее встретИв䑈иеся слова. Если слОварь 7аполняется до окончания процесса одироваеияࠬ то в неЪоторых методᐰх он обновляется (на место ранее"встрవтившихся слов записываются новые), а в䀠некоторых кодирование продолжается без обновле䐽и слваЀя.
Алгоритмы клѰсса LZ ؾтйичают葁я䀠размерами окна- спосоఱами кодированияဠсов, ал䐳оритмами обновления`слоԲ萲ря и т.пĮ耠Всн укᐰԗанные цак⑂ҾрՋ влияют и нб характери⑁тики этих методов: скорос葂ь код萸рования, объен требуемой памята и степень сжатия данных, различные дл разных алгоритмов> Однак萾 в целом методы из класса LZ представляют значительный практичᔵукмй иԽтер䐵呁 и позволяют доᑁтаточ落ؾ(эффективно сжимать даНнЋᐵ с неизвవстной статистикой.
1.1. КԾФирование†с использованием скользящего окнв
Рассмотрим оснాвные этапы кодирования сᘾобщеᐽия Х=х1х2х34ꀦ, которое ҿорождаеՂся некоторым и葁точнико䐼 информации с алфᐰѲитом А. Пусть используетсю окно длинՋ W, т.е. при коди⑁пвднии0символа xa исходной последовательности у⑇иты萲аютсџ W предыдущих символов:
ࠁСнذчала осуществляется поиск в ок=еȠсимвола х1Į Если символ не нлденЬ то в качестве кода†Կер萵дается 2 как признакĠтого
ࡠే䑂Ծ этого символа нет в окне, и двоичное предст0влемие х1.
Если символ с1 найден, то осущеAтвлэется поиск в окне слоԲа†х࠱х2,"начинающегося с этого симвла. Если слово чqх2 есть в окнеȬтҾ произ䐲одᐸтся поиск сло䐢а耠х1х2х3,ĤԷатемࠠх1х2х3х4 й так да;ее, пాка не б葃ет наЙմԵно сово, состоящее из наибольшего количества входных символов в порядке их поступления. В этом случае в качестве кода передается 1 и пара чисел (i, j), указывающая положение найденного слова в окне (i – номер позиции окна, с которой начинается это слово, j – длина этого слова, позиции в окне нумеруются справа налево). Затем окно сдвигается на j символов вправо по тексту и кодирование продолжается.
Для кодирования чисел (i, j) могут быть использованы рассмотренные ранее коды целых чисел.
Пример. Пусть алфавит источника А={а, b, с}, длина окна W = 6. Необходимо закодировать исходное сообщение bababaabacabac. (рис. 1).
После кодирования первых шести букв окно будет иметь вид bababa.
1. Далее проверяем наличие в окне буквы а. Она найдена, добавляем к ней b, ищем в окне ab. Эта пара есть в окне, добавляем букву а, ищем aba. Это слово есть в окне, добавляем букву с, ищем abac. Этого слова нет в окне, тогда кодируем aba кодовой комбинацией (1,3,3), где 1 – признак того, что слово есть в «окне»,3 – номер позиции в окне, с которой начинается это слово, 3 – длина этого слова.
2. Далее окно сдвигаем на 3 символа вправо и ищем в окне букву с. Ее нет в окне, поэтому кодируем комбинацией (0, «с»), где 0 – признак того, что буквы нет в окне, «с» – двоичное представление буквы. Окно сдвигаем на 1 символ вправо.
3. Ищем в окне букву а, она найдена, добавляем к ней b, ищем в окне ab. Эта пара есть в окне, добавляем букву а, ищем aba. Это слово есть в окне, добавляем букву с, ищем abac. Это слово есть в окне, тогда кодируем abaс кодовой комбинацией (1,4,4), где 1 – признак того, что слово есть в окне,4 – номер позиции в окне, с которой начинается это слово, 4 – длина этого слова.

Рис. 1. Кодирование последовательности bababaabacabac
1.2. Кодирование с использованием адаптивного словаря
В этих словарных методах для хранения слов используется адаптивный словарь, заполняющийся в процессе кодирования. Перед началом кодирования в словарь включаются все символы алфавита источника. При кодировании сообщения Х=х1х2х3х4… сначала читаются два символа х1х2, поскольку это слово отсутствует в словаре, то передается код символа х1 (обычно это номер строки, содержащей найденный символ или слово). В свободную строку таблицы записывается слово х1х2, далее читается символ х3 и осуществляется поиск в словаре слова х2х3. Если это слово есть в словаре, то проверяется наличие слова х2х3х4 и так далее. Таким образом, слово из наибольшего количества входных символов, найденное в словаре, кодируется как номер строки, его содержащей.
Пример. Пусть алфавит источника А={а, b, с}, размер словаря V = 8. Необходимо закодировать исходное сообщение abababaabacabac.
1. Запишем символы алфавита А в словарь, каждому символу припишем кодовое слово длины L = élog2Vù = élog28ù = 3.
| Номер строки | Слово | Код |
| 0 | a | 000 |
| 1 | b | 001 |
| 2 | c | 010 |
| 3 | – | |
| 4 | – | |
| 5 | – | |
| 6 | – | |
| 7 | – |
2. Читаем первые две буквы ab, ищем слово ab в словаре. Этого слова нет, поэтому поместим слово ab в свободную 3-ю строку словаря, а букву а закодируем кодом 000.
| Номер строки | Слово | Код |
| 0 | a | 000 |
| 1 | b | 001 |
| 2 | c | 010 |
| 3 | ab | 011 |
| 4 | – | |
| 5 | – | |
| 6 | – | |
| 7 | – |
3. Далее читаем букву a и ищем в словаре слово ba. Этого слова нет, поэтому запишем в 4-ю строку словаря слово ba, букву b закодируем кодом 001.
| Номер строки | Слово | Код |
| 0 | a | 000 |
| 1 | b | 001 |
| 2 | c | 010 |
| 3 | ab | 011 |
| 4 | ba | 100 |
| 5 | – | |
| 6 | – | |
| 7 | – |
4. Читаем букву b, ищем в словаре слово ab. Это слово есть в словаре в строке 3. Читаем следующую букву а, получим слово aba, его нет в словаре. Запишем слово aba в 5-ю строку словаря, и закодируем ab кодом 011.
| Номер строки | Слово | Код |
| 0 | a | 000 |
| 1 | b | 001 |
| 2 | c | 010 |
| 3 | ab | 011 |
| 4 | ba | 100 |
| 5 | aba | 101 |
| 6 | – | |
| 7 | – |
5. Читаем букву b, ищем в словаре слово ab. Это слово есть в словаре в строке 3. Читаем следующую букву а, получим слово aba. Это слово есть в словаре в строке 5. Читаем букву а, получим слово abaа, его нет в словаре. Запишем слово abaа в 6-ю строку словаря, и закодируем abа кодом 101.
| Номер строки | Слово | Код |
| 0 | a | 000 |
| 1 | b | 001 |
| 2 | c | 010 |
| 3 | ab | 011 |
| 4 | ba | 100 |
| 5 | aba | 101 |
| 6 | abaа | 110 |
| 7 | – |
6. Читаем букву b, ищем в словаре слово ab. Это слово есть в словаре в строке 3. Читаем следующую букву а, получим слово aba. Это слово есть в словаре в строке 5. Читаем букву с, получим слово abaс, его нет в словаре. Запишем слово abaс в 7-ю строку словаря, и закодируем abа кодом 101. Если словарь заполняется до окончания кодирования, то можно записывать новые слова в словарь, начиная со строки с наибольшим номером, удаляя ранее записанные там слова.
| Номер строки | Слово | Код |
| 0 | a | 000 |
| 1 | b | 001 |
| 2 | c | 010 |
| 3 | ab | 011 |
| 4 | ba | 100 |
| 5 | aba | 101 |
| 6 | abaа | 110 |
| 7 | abaс | 111 |
7. Читаем букву а, ищем в словаре слово са. Этого слова нет в словаре, поэтому запишем слово са в 7-ю строку словаря, удалив слово abас, и закодируем букву с кодом 010.
| Номер строки | Слово | Код |
| 0 | a | 000 |
| 1 | b | 001 |
| 2 | c | 010 |
| 3 | ab | 011 |
| 4 | ba | 100 |
| 5 | aba | 101 |
| 6 | abaа | 110 |
| 7 | | 111 |
| |
8. Читаем букву b, ищем в словаре слово ab. Это слово есть в словаре в строке 3. Читаем следующую букву а, получим слово aba. Это слово есть в словаре в строке 5. Читаем букву с, получим слово abaс, его нет в словаре. Запишем слово abaс в 6-ю строку словаря, и закодируем abа кодом 101.
| Номер строки | Слово | Код |
| 0 | a | 000 |
| 1 | b | 001 |
| 2 | c | 010 |
| 3 | ab | 011 |
| 4 | ba | 100 |
| 5 | aba | 101 |
| 6 | | 110 |
| 7 | са | 111 |
9. Закодируем букву с кодом 010. Конец входной последовательности.
Таким образом, входное сообщение будет закодировано так:

Алгоритм на псевдокоде
Кодирование с адаптивным словарем
Обозначим:
CurCode – текущий код;
PrevCode – предыдущий код;
M – массив, содержащий текущую последовательность;
L – длина текущей последовательности;
C – словарь (массив строк);
S – текущая длина кода;
DicPos – количество последовательностей в словаре.
<Инициализация словаря символами исходного алфавита>
S:=9; L:=0; DicPos:=257 (256+конец сжатия)
DO (not EOF)
CurCode:=Read( ) (читаем следующий байт из файла)
M[L]:=CurCode; L:=L+1
IF (текущая последовательность найдена в словаре)
CurCode:=номер найденной последовательности
ELSE
C[DicPos]:=M; DicPos:=DicPos+1
IF (log(DicPos)+1)>S S:=S+1 FI (использовать соотношение (1))
Write(PrevCode,S) (пишем в выходной файл S бит PrevCode)
M[0]:=CurCode; L:=1
FI
PrevCode:=CurCode
OD
Write(PrevCode,S) (сохраняем оставшийся код)
Write(256,S) (конец сжатия)
 ,
,  . (1)
. (1)
Декодирование с использованием адаптивного словаря
Рассмотрим теперь на примере ранее закодированного сообщения abababaabacabac (алфавит источника А={а, b, с}, размер словаря V = 8) процесс декодирования. Закодированная последовательность имела такой вид:
000001011101101010101010
1. Запишем символы алфавита А в словарь, каждому символу припишем кодовое слово длины L = élog2Vù = élog28ù = 3. (Процесс заполнения словаря будет таким же, как и при кодировании.)
2. Читаем первые три бита кодовой последовательности (код 000), по коду найдем в словаре букву а.
3. Читаем следующий код 001, по коду найдем в словаре букву b. Получим новое слово ab, которого нет в словаре, поместим слово ab в свободную 3-ю строку словаря. На выход декодера передаем букву а, букву b запоминаем.
4. Читаем код 011, по коду находим в словаре слово ab. Добавляем первую букву а к предыдущему декодированному слову b, получим слово ba, его нет в словаре. Поместим слово ba в свободную 4-ю строку словаря. На выход декодера передаем букву b, слово ab запоминаем.
5. Читаем код 101, такого кода нет в словаре. Тогда добавляем к слову ab первую букву этой же последовательности – а, получим слово aba, его нет в словаре. Поместим слово aba в свободную 5-ю строку словаря. На выход декодера передаем слово ab, слово aba запоминаем.
6. Читаем код 101, по коду находим в словаре слово aba, добавляем первую букву a к предыдущему декодированному слову aba, получим abaa. Добавим слово abaa в словарь в свободную 6-ю строку. На выход декодера передаем слово aba , и слово aba запоминаем.
7. Читаем код 010, по коду находим в словаре букву с, добавляем букву с к предыдущему декодированному слову aba, получим abac. Добавим слово abaс в словарь в свободную 7-ю строку. На выход декодера передаем слово aba , букву с запоминаем.
8. Читаем код 101, по коду находим в словаре слово aba, добавляем первую букву а к предыдущей декодированной букве с, получим слово са. Так как словарь заполнился до окончания декодирования, то будем записывать новые слова в словарь, начиная со строки с наибольшим номером, удаляя ранее записанные там слова. Добавим слово са в 7-ю строку словаря вместо слова abac. На выход декодера передаем букву с, слово aba запоминаем.
9. Читаем код 010, по коду находим в словаре букву с, добавляем букву с к предыдущему декодированному слову aba, получим abac. Добавим слово abac в 6-ю строку словаря вместо слова abaа. На выход декодера передаем слово aba, букву с запоминаем.
10. На выход декодера передаем букву с.
В результате декодирования получим исходное сообщение:
Алгоритм на псевдокоде
Декодирование с адаптивным словарем
Обозначим:
CurCode – текущий код;
PrevCode – предыдущий код;
M – массив, содержащий текущую последовательность;
L – длина текущей последовательности;
C – словарь (массив строк);
S – текущая длина кода;
DicPos – количество последовательностей в словаре.
<Инициализация словаря символами исходного алфавита>
S:=9; L:=0; DicPos:=257
DO
CurCode:=Read(S) (читаем из файла S бит)
IF (CurCode=256) break FI
IF (C[CurCode]<>0) (в словаре найдена последовательность с
номером CurCode)
M[L]:=C[CurCode][0] (в конец текущей последовательности
приписываем первый символ найденной
последовательности)
L:=L+1
ELSE M[L]:=M[0]; L:=L+1
FI
IF (текущая последовательность М не найдена в словаре С)
Write(C[PrevCode])
C[DicPos]:=M (добавляем текущую последовательность в
словарь)
DicPos:=DicPos+1
IF (log DicPos+1)>S S:=S+1 FI (использовать соотношение (1))
M:=C[CurCode] (в текущую последовательность заносим
слово с номером CurCode)
L=длина слова
FI
PrevCode:=CurCode
OD
Write(C[PrevCode])
Порядок выполнения работы
1. Изучить теоретический материал.
2. Закодировать словарным кодом с использованием адаптивного словаря текст на английском языке, текст на русском языке и текст программы на языке С (использовать файлы не менее 1 Кб).
3. Вычислить коэффициенты сжатия данных как процентное отношение длины закодированного файла к длине исходного файла, построить таблицу вида:
| Размер исходного файла | Коэффициент сжатия данных | ||
| Текст на английском языке | Текст на русском языке | Текст программы на языке С | |
4. Декодировать файлы, закодированные словарным кодом, и сравнить полученные файлы с исходными текстами.
Контрольные вопросы
1. Какова общая схема кодирования, используемая в LZ-методах?
2. Чем отличаются друг от друга алгоритмы класса LZ?
3. В чем заключается метод кодирования с использованием скользящего окна?
4. Как используется в LZ-кодах адаптивный словарь?
5. Как осуществляется декодирование в методах с адаптивным словарем?
Лабораторная работа № 12
Тема: Исследование процессов кодирования и декодирования при передаче дискретных сообщений кодами Хэмминга.
Цель работы: изучение способов задания, оценки конкретных свойств, принципа построения и работы кодирующих и декодирующих устройств кодов Хэмминга.
Теоретические сведения
При передаче по каналу с шумами может быть или искажен любой из n символов кода, или слово может быть передано без искажений. Таким образом, может быть n +1 вариантов искажения (включая передачу без искажений). Используя контрольные символы, мы должны различать все n +1 случаев.
С помощью m контрольных символов можно описать 2m событий. Значит, должно быть выполнено условие:
2m ≥ n + 1= k + m +1 (1)
Таблица 1
| Информ. k | 1 2 3 4 5 6 7 8 9 10 11 12 13 26 |
| Контр. m | 2 3 3 3 4 4 4 4 4 4 4 5 5 5 |
Задаем m, определим k: 2m ≥ k + m +1
22 ≥ k +2 +1, k = 1
2m ≥ k +3 +1, k = 2, 3, 4
Дата добавления: 2018-05-12; просмотров: 706; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!