Молекулярная генетика и генная инженерия
ВВЕДЕНИЕ.. 2
1. ОСНОВНЫЕ НАПРАВЛЕНИЯ ИССЛЕДОВАНИЙ В ОБЛАСТИ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА.. 4
1.1. МАШИННЫЙ ПЕРЕВОД.. 4
1.2. ИГРЫ И МАШИННОЕ ТВОРЧЕСТВО.. 8
1.3. Data – mining (интеллектуальный анализ данных) 10
1.4. ГЕНЕРАЦИЯ И РАСПОЗНАВАНИЕ РЕЧИ.. 21
1.5. РАСПОЗНАВАНИЕ ОБРАЗОВ И ОБРАБОТКА ВИЗУАЛЬНОЙ ИНФОРМАЦИИ.. 22
1.6. НОВЫЕ АРХИТЕКТУРЫ КОМПЬЮТЕРОВ.. 23
2. ЭКСПЕРТНЫЕ СИСТЕМЫ КАК СОСТАВНАЯ ЧАСТЬ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА.. 26
2.1. СОСТАВНЫЕ ЧАСТИ ЭС: БАЗА ЗНАНИЙ, МЕХАНИЗМЫ ВЫВОДА, ПРИОБРЕТЕНИЯ И ОБЪЯСНЕНИЯ ЗНАНИЙ. УЧАСТНИКИ ПРОЦЕССА ПРОЕКТИРОВАНИЯ.. 28
2.2. РЕЖИМЫ РАБОТЫ ЭС.. 33
2.3. КЛАССИФИКАЦИЯ ЭКСПЕРТНЫХ СИСТЕМ... 35
2.3.1. НАЗНАЧЕНИЕ ЭС.. 35
2.3.2. ПРОБЛЕМНАЯ ОБЛАСТЬ. СТАТИЧЕСКИЕ И ДИНАМИЧЕСКИЕ ЭС.. 36
2.3.3. ГЛУБИНА АНАЛИЗА ПРОБЛЕМНОЙ ОБЛАСТИ.. 40
2.3.4. ТИП ИСПОЛЬЗУЕМЫХ МЕТОДОВ ПРЕДСТАВЛЕНИЯ И ЗНАНИЙ.. 40
2.3.5. ИНСТРУМЕНТАЛЬНЫЕ СРЕДСТВА.. 41
2.3.6. КЛАСС ЭС.. 44
2.4. ТЕХНОЛОГИЯ РАЗРАБОТКИ ЭС.. 49
2.4.1. ЭТАП ИДЕНТИФИКАЦИИ.. 52
2.4.2. ЭТАП КОНЦЕПТУАЛИЗАЦИИ.. 54
2.4.3. ЭТАП ФОРМАЛИЗАЦИИ.. 55
2.4.4. ЭТАП ПРОГРАММНОЙ РЕАЛИЗАЦИИ.. 59
2.4.5. ЭТАП ТЕСТИРОВАНИЯ И ОТЛАДКИ.. 61
2.4.6. ЭТАП ОПЫТНОЙ ЭКСПЛУАТАЦИИ.. 63
2.5. ФОРМЫ ПРЕДСТАВЛЕНИЯ ЗНАНИЙ В ЭС. 66
Методы взаимодействия когнитолога с экспертом.. 79
СПИСОК ЛИТЕРАТУРЫ... 94
ВВЕДЕНИЕ
Интеллектуальные информационные системы(ИИС) — естественный результат развития обычных информационных систем, сосредоточили в себе наиболее наукоемкие технологии с высоким уровнем автоматизации не только процессов подготовки информации для принятия решений, но и самих процессов выработки вариантов решений, опирающихся на полученные информационной системой данные. ИИС способны диагностировать состояние предприятия, управлять непрерывным технологическим процессом, оказывать помощь в антикризисном управлении, обеспечивать выбор оптимальных решений по стратегии развития предприятия и его инвестиционной деятельности. Благодаря наличию средств естественно-языкового интерфейса появляется возможность непосредственного применения ИИС бизнес-пользователем, не владеющим языками программирования, в качестве средств поддержки процессов анализа, оценки и принятия решений. наибольший эффект от внедрения ИИС достигается там, где при принятии решений учитываются наряду с экономическими показателями слабо формализуемые факторы – экономические, политические, социальные. В учебном пособии значительное внимание уделено основным направлениям исследований в области искусственного интеллекта (Глава 1).
|
|
|
Методы и средства искусственного интеллекта (ИИ) материализуются и доходят до потребителя в виде интеллектуальных технологий, которые практически инвариантны к той или иной проблемной области. В «традиционном» ИИ, успешно создаются и развиваются экспертные системы (ЭС) или системы, основанные на знаниях (СОЗ) для широкого круга проблемных областей. Экспертные системы помогают не только накапливать и хранить информацию в удобном для пользователя виде, но и получать новые знания в медицине, геологии, геофизике, машиностроении, экологии, экономике и др.
|
|
|
В пособии обозначены основные проблемы, связанные с разработкой экспертных систем (Глава 2): фактуальное и операционное представление знаний, извлечение знаний, их структурирование и концептуализация, продукционный вывод.
Освещаются современные аспекты теории и практики разработки ЭС (Глава 3). В качестве инструментальной среды разработки используется экспертная оболочка CLIPS. Суть технологии CLIPS заключается в том, что язык и среда CLIPS предоставляют пользователям возможность быстро создавать эффективные, компактные и легко управляемые ЭС. При этом пользователь применяет множество уже готовых инструментов (встроенный механизм управления базой знаний, механизм логического вывода) и конструкций (упорядоченные факты, шаблоны, правила, классы, модули и др.) Пользовательский интеллектуальный интерфейс разработан в среде Borland Builder 5.0, отличается наглядностью и простотой использования.
|
|
|
1. ОСНОВНЫЕ НАПРАВЛЕНИЯ ИССЛЕДОВАНИЙ В ОБЛАСТИ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
1.1. МАШИННЫЙ ПЕРЕВОД
Машинный перевод -выполняемое на компьютере действие по преобразованию текста на одном естественном языке (ЕЯ) в эквивалентный по содержанию текст на другом естественном языке, а также результат такого действия.
Современный машинный (автоматизированный) перевод осуществляется с помощью человека: пред-редактора, который тем или иным образом предварительно обрабатывает подлежащий переводу текст, интер-редактора, который участвует в процессе перевода, или пост-редактора, который исправляетошибки и недочеты в переведенном машиной тексте.
Для осуществления машинного перевода в компьютер вводится специальная программа, реализующая алгоритм перевода, под которым понимается последовательность однозначно и строго определенных действий над текстом для нахождения переводных соответствий в данной паре языков L1 – L2 при заданном направлении перевода (с одного конкретного языка на другой). Система машинного перевода включает: двуязычные словари, снабженные необходимой грамматической информацией (морфологической, синтаксической и семантической), для обеспечения передачи эквивалентных, вариантных и трансформационных переводных соответствий; алгоритмические средства грамматического анализа, реализующие какую-либо из принятых для автоматической переработки текста формальных грамматик. Имеются также отдельные системы машинного перевода, рассчитанные на перевод в рамках трех и более языков.
|
|
|
Наиболее распространенной является следующая последовательность формальных операций, обеспечивающих анализ и синтез в системе машинного перевода:
1. На первом этапе осуществляется ввод текста и поиск входных словоформ во входном словаре с сопутствующим морфологическим анализом, в ходе которого устанавливается принадлежность данной словоформы к определенной лексеме. В процессе анализа из формы слова могут быть получены также сведения, относящиеся к другим уровням организации языковой системы.
2. Следующий этап включает в себя перевод идиоматических словосочетаний, фразеологических единств или штампов данной предметной области; определение основных грамматических характеристик элементов входного текста, производимое в рамках входного языка; разрешение омографии, после чего однозначные слова переводятся по спискам эквивалентов, а для перевода многозначных слов используются так называемые контекстологические словари, словарные статьи которых представляют собой алгоритмы запроса к контексту на наличие/отсутствие контекстных определителей значения.
3. Окончательный грамматический анализ, в ходе которого доопределяется необходимая грамматическая информация с учетом данных выходного языка.
4. Синтез выходных словоформ и предложения в целом на выходном языке.
В зависимости от особенностей морфологии, синтаксиса и семантики конкретной языковой пары, а также направления перевода, общий алгоритм перевода может включать и другие этапы, а также модификации названных этапов или порядка их следования, но вариации такого рода в современных системах, как правило, незначительны. Анализ и синтез могут производиться как пофразно, так и для всего текста, введенного в память компьютера; в последнем случае алгоритм перевода предусматривает определение так называемых анафорических связей.
Действующие системы машинного перевода ориентированы на конкретные пары языков и используют, как правило, переводные соответствия либо на поверхностном уровне, либо на некотором промежуточном уровне между входным и выходным языком. Качество машинного перевода зависит от объема словаря, объема информации, приписываемой лексическим единицам, от тщательности составления и проверки работы алгоритмов анализа и синтеза, от эффективности программного обеспечения (ПО). Современные аппаратные и программные средства допускают использование словарей большого объема, содержащих подробную грамматическую информацию. Информация может быть представлена как в декларативной (описательной), так и в процедурной (учитывающей потребности алгоритма) форме.
В практике переводческой деятельности и в информационной технологии различаются два основных подхода к машинному переводу. С одной стороны, результаты машинного перевода могут быть использованы для поверхностного ознакомления с содержанием документа на незнакомом языке. В этом случае он может использоваться как сигнальная информация и не требует тщательного редактирования. Другой подход предполагает использование машинного перевода вместо обычного «человеческого». Это предполагает тщательное редактирование и настройку системы перевода на определенную предметную область. Здесь играют роль полнота словаря, ориентированность его на содержание и набор языковых средств переводимых текстов, эффективность способов разрешения лексической многозначности, результативность работы алгоритмов извлечения грамматической информации, нахождения переводных соответствий и алгоритмов синтеза. На практике перевод такого типа становится экономически выгодным, если объем переводимых текстов достаточно велик, если тексты достаточно однородны, словари системы полны и допускают дальнейшее расширение, а программное обеспечение удобно для постредактирования.
Эффективность работы современной системы МП в решающей степени зависит от ее удачной настройки на конкретный подъязык (или микроподъязык) естественного языка, на определенную лексику и ограниченный набор грамматических средств, характерных для текстов данной предметной области, а также на определенные типы документов, хотя представления о языковых регистрах, стилях, жанрах письменного текста и т.п. были хорошо известны и в традиционной лингвистике. Подъязык, с точки зрения МП, определяется в первую очередь некоторым исходным набором текстов, в рамках которого определяется входной и выходной словари, степень распространения и характер лексической неоднозначности лексем, характер и распространенность синтаксических конструкций, способы их перевода в данной языковой паре и пр. Большую роль играют параллельные тексты и словари-конкордансы, с помощью которых можно достаточно эффективно изучить и использовать в составлении алгоритмов лексическую сочетаемость и дистрибуцию (распределение) языковых элементов в речи (дискурсе, тексте). Статистические характеристики подъязыков помогают упорядочить структуру соответствующих алгоритмов анализа и синтеза. Выходной словарь, ориентированный на потребности синтеза и передачи основных видов соответствий в конкретной языковой паре, обеспечивает приемлемый выходной текст. В любом из современных видов машинного перевода необходимо участие человека-редактора, удобство работы которого обеспечивается качеством и надежностью соответствующего программного обеспечения.
Классификация систем машинного перевода привязывается к особенностям программной реализации и использованию тех или иных специфических инструментов:
1. Машинный перевод. Это наиболее массовая и востребованная группа, представленная в основном самостоятельными приложениями, которые предназначены, как правило, для полностью автоматизированного перевода (FAMT), - пользователю нужно лишь задать направление перевода и иногда его тематику. Главным требованием к продуктам данного класса является качество перевода, отчасти скорость процесса и прочие потребительские характеристики вроде удобства интерфейса, интеграции с другими средствами обработки документов (текстовыми процессорами, браузерами, почтовыми клиентами), развитые инструменты пополнения словарной базы;
2. Контролируемый язык и машинный перевод на основе базы знаний. В таких системах реализован переход от свободного входного языка к контролируемому входному языку, что предусматривает определенные ограничения лексики, грамматики и семантики. Тем самым упрощается структура исходного текста, за счет чего повышается точность и качество перевода;
3. Инструменты для перевода в Интернете. К ним относят онлайновые службы, позволяющие работать как с фрагментами текста (собственно переводчики), так и с отдельными словами (словари). Преимущество данных инструментов состоит в том, что пользователь оперативно получает перевод непосредственно в окне браузера, без установки каких-либо дополнительных программных средств и, как правило, бесплатно. Некоторые компании, кроме того, предлагают услуги по машинному переводу с различной степенью участия человека и зависящей от этого стоимостью услуги.
1.2. ИГРЫ И МАШИННОЕ ТВОРЧЕСТВО
Известны три метода синтезирования музыкальных сочинений с помощью ЭВМ. Нотный текст моделируется в виде стационарной последовательности нот, в которой вероятность появления ноты зависит лишь от нескольких непосредственно предшествующих ей нот. Нота на самом деле означает всего лишь высоту звука. Простота и кажущаяся универсальность метода привлекают тех, кто не знаком со спецификой музыки. Этот метод не дает и не может дать хороших результатов, что и подтвердила практика, потому что в мелодии все ноты взаимосвязаны. Этот метод предполагает лишь локальную взаимосвязь нескольких (трех-четырех) соседних нот. При этом синтезируемая последовательность высот не зависит от ритма.
В отличие от этого метода структурный метод синтезирования сочинений основан на программировании правил композиции, которые удалось либо выявить, анализируя творчество композиторов (при имитации традиционных музыкальных структур), либо сконструировать умозрительно (при создании музыки нетрадиционных структур - алеаторики, схоластической музыки и т. п.). Этим методом синтезирована музыка одноголосная, многоголосная и другое. Выбор текущей ноты зависит от многих параметров - от предшествующей мелодической или ритмической фигуры, от метра - положения ноты на сильной или слабой доле текста, от ладогармонической функции текущего такта и др.
Третий метод - это метод заготовок. В композиторской практике ЭВМ стала удобным помощником для создания вариантов фрагментов (заготовок) музыкальных сочинений (звуковысотных сочетаний, аккордов, тембров, ритмических фигур и т. п.). Сочинение таких заготовок "вручную" требует много времени и кропотливого, а имея машинные заготовки, композитор отбирает те, которые отвечают его замыслу, и включает их в свое сочинение уже без помощи машины. Машинные заготовки используют и при сочинении композиций классического стиля.
Алгоритм «машинного творчества», направленного на создание компьютером «литературных произведений», то есть текста, имеющего по результатам субъективной экспертной оценки хотя бы минимальную литературную ценность, можно условно разделить на две основные части: методику составления «сценария» произведения, и непосредственно схему генерации самого текста.
Первый этап выглядит следующим образом: сценарий дробится на составляющие его элементы, числом пять: реалии, персонажи, встречи, поступки и ситуации. Все указанные элементы логически связаны между собой, то есть имеют четко прослеживающуюся взаимосвязь: на фоне избранных реалий существуют персонажи, которые попадают в различные ситуации. Ситуации провоцируют героев на поступки или встречи, в результате которых складываются новые ситуации. Сам сценарий делится на три составляющих части, которые условно можно назвать «завязка», «развитие сюжета» и «развязка» в пропорции согласно «правилу золотого сечения». Каждый из составляющих сценарий элементов в свою очередь состоит из более мелких частей: например, реалии включают в себя географическую точку, в которой развивается действие произведения, время года, время суток, погоду; персонажи — на «положительных» и «отрицательных», «мужчин» и «женщин», и так далее. Очевидно, что и эти понятия дробятся на целый ряд дополнительных компонент: время суток — на «день», «ночь» «утро» и «вечер», погода — на «дождь», «грозу», «солнечно», «пасмурно». Все данные элементы тоже логически связаны между собой. Машине остается только выбирать готовые элементы из уже существующих и проверять их на логическую совместимость, выстраивая согласно заданным алгоритмам единую смысловую линию.
Процесс генерации итогового текста еще более прост. Все правила орфографии, синтаксиса и пунктуации литературного языка тысячи раз описаны в огромном количестве книг, существуют четкие и исчерпывающие правила и законы, согласно которым строится предложение. Достаточно лишь превратить эти законы в алгоритм.
1.3. Data – mining (интеллектуальный анализ данных)
Развитие методов записи и хранения данных привело к бурному росту объемов собираемой и анализируемой информации. Объемы данных настолько внушительны, что человеку просто не по силам проанализировать их самостоятельно. Для того чтобы провести автоматический анализ данных, используется Data Mining.
Информация, найденная в процессе применения методов Data Mining, должна быть нетривиальной и ранее неизвестной. Знания должны описывать новые связи между свойствами, предсказывать значения одних признаков на основе других и т.д. Найденные знания должны быть применимы и на новых данных с некоторой степенью достоверности. Полезность заключается в том, что эти знания могут приносить определенную выгоду при их применении. Знания должны быть в понятном для пользователя не математика виде. Например, проще всего воспринимаются человеком логические конструкции 'если … то …'. Более того, такие правила могут быть использованы в различных СУБД в качестве SQL-запросов. В случае, когда извлеченные знания непрозрачны для пользователя, должны существовать методы постобработки, позволяющие привести их к интерпретируемому виду.
Задачи, решаемые методами Data Mining:
1. Классификация – это отнесение объектов (наблюдений, событий) к одному из заранее известных классов.
2. Кластеризация – это группировка объектов (наблюдений, событий) на основе данных (свойств), описывающих сущность этих объектов. Объекты внутри кластера должны быть "похожими" друг на друга и отличаться от объектов, вошедших в другие кластеры. Чем больше похожи объекты внутри кластера и чем больше отличий между кластерами, тем точнее кластеризация.
3. Регрессия, в том числе задачи прогнозирования. Установление зависимости непрерывных выходных от входных переменных.
4. Ассоциация – выявление закономерностей между связанными событиями. Примером такой закономерности служит правило, указывающее, что из события X следует событие Y. Такие правила называются ассоциативными. Впервые эта задача была предложена для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее еще называют анализом рыночной корзины (market basket analysis).
5. Последовательные шаблоны – установление закономерностей между связанными во времени событиями, т.е. обнаружение зависимости, что если произойдет событие X, то спустя заданное время произойдет событие Y.
6. Анализ отклонений – выявление наиболее нехарактерных шаблонов.
Для решения вышеописанных задач используются различные методы и алгоритмы Data Mining. Ввиду того, что Data Mining развивалась и развивается на стыке таких дисциплин, как статистика, теория информации, машинное обучение, теория баз данных, вполне закономерно, что большинство алгоритмов и методов Data Mining были разработаны на основе различных методов из этих дисциплин.
Специфика современных требований к переработке «сырых» данных следующие:
· Данные имеют неограниченный объем;
· Данные являются разнородными (количественными, качественными, текстовыми);
· Результаты должны быть конкретны и понятны;
· Инструменты для обработки сырых данных должны быть просты в использовании.
В основу современной технологии Data Mining (discovery-driven data mining) положена концепция шаблонов (паттернов), отражающих фрагменты многоаспектных взаимоотношений в данных. Эти шаблоны представляют собой закономерности, свойственные подвыборкам данных, которые могут быть компактно выражены в понятной человеку форме. Поиск шаблонов производится методами, не ограниченными рамками априорных предположений о структуре выборке и виде распределений значений анализируемых показателей.
Важное положение Data Mining - нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные (unexpected) регулярности в данных, составляющие так называемые скрытые знания (hidden knowledge).
В первую очередь методы Data Mining сегодня, необходимы коммерческим предприятиям, которые развертывают проекты на основе информационных хранилищ данных (Data Warehousing). Опыт многих таких предприятий показывает, что отдача от использования Data Mining может достигать 1000%.
Data Mining представляют большую ценность для руководителей и аналитиков в их повседневной деятельности. Деловые люди осознали, что с помощью методов Data Mining они могут получить ощутимые преимущества в конкурентной борьбе.
Некоторые бизнес-приложения Data Mining
1)Розничная торговля
Вот типичные задачи, которые можно решать с помощью Data Mining в сфере розничной торговли:
· анализ покупательской корзины (анализ сходства) предназначен для выявления товаров, которые покупатели стремятся приобретать вместе.
· исследование временных шаблонов помогает торговым предприятиям принимать решения о создании товарных запасов.
· создание прогнозирующих моделей дает возможность торговым предприятиям узнавать характер потребностей различных категорий клиентов с определенным поведением.
Банковское дело
Достижения технологии Data Mining используются в банковском деле для решения следующих распространенных задач:
· выявление мошенничества с кредитными карточками. Путем анализа прошлых транзакций, которые впоследствии оказались мошенническими, банк выявляет некоторые стереотипы такого мошенничества.
· сегментация клиентов. Разбивая клиентов на различные категории, банки делают свою маркетинговую политику более целенаправленной и результативной, предлагая различные виды услуг разным группам клиентов.
· прогнозирование изменений клиентуры. Data Mining помогает банкам строить прогнозные модели ценности своих клиентов, и соответствующим образом обслуживать каждую категорию.
Телекоммуникации
В области телекоммуникаций методы Data Mining помогают компаниям более энергично продвигать свои программы маркетинга и ценообразования, чтобы удерживать существующих клиентов и привлекать новых. Среди типичных мероприятий отметим следующие:
· анализ записей о подробных характеристиках вызовов. Назначение такого анализа - выявление категорий клиентов с похожими стереотипами пользования их услугами и разработка привлекательных наборов цен и услуг;
· выявление лояльности клиентов. Data Mining можно использовать для определения характеристик клиентов, которые, один раз воспользовавшись услугами данной компании, с большой долей вероятности останутся ей верными.
Страхование
Страховые компании в течение ряда лет накапливают большие объемы данных. Здесь обширное поле деятельности для методов Data Mining:
· выявление мошенничества. Страховые компании могут снизить уровень мошенничества, отыскивая определенные стереотипы в заявлениях о выплате страхового возмещения, характеризующих взаимоотношения между юристами, врачами и заявителями.
· анализ риска. Путем выявления сочетаний факторов, связанных с оплаченными заявлениями, страховщики могут уменьшить свои потери по обязательствам.
Медицина
Известно много экспертных систем для постановки медицинских диагнозов. Они построены главным образом на основе правил, описывающих сочетания различных симптомов различных заболеваний. С помощью таких правил узнают не только, чем болен пациент, но и как нужно его лечить.
Молекулярная генетика и генная инженерия
Наиболее остро и вместе с тем четко задача обнаружения закономерностей в экспериментальных данных стоит в молекулярной генетике и генной инженерии. Здесь она формулируется как определение так называемых маркеров, под которыми понимают генетические коды, контролирующие те или иные фенотипические признаки живого организма. Такие коды могут содержать сотни, тысячи и более связанных элементов.
Прикладная химия
Методы Data Mining находят широкое применение в прикладной химии (органической и неорганической). Здесь нередко возникает вопрос о выяснении особенностей химического строения тех или иных соединений, определяющих их свойства.
Можно привести еще много примеров различных областей знания, где методы Data Mining играют ведущую роль. Особенность этих областей заключается в их сложной системной организации. Они относятся главным образом к надкибернетическому уровню организации систем, закономерности которого не могут быть достаточно точно описаны на языке статистических или иных аналитических математических моделей.
Другие приложения в бизнесе
Data Mining может применяться во множестве других областей:
· развитие автомобильной промышленности. При сборке автомобилей производители должны учитывать требования каждого отдельного клиента, поэтому им нужны возможность прогнозирования популярности определенных характеристик и знание того, какие характеристики обычно заказываются вместе;
· политика гарантий. Производителям нужно предсказывать число клиентов, которые подадут гарантийные заявки, и среднюю стоимость заявок;
· поощрение часто летающих клиентов. Авиакомпании могут обнаружить группу клиентов, которых данными поощрительными мерами можно побудить летать больше.
Выделяют пять стандартных типов закономерностей, которые позволяют выявлять методы Data Mining:
· Ассоциация имеет место в том случае, если несколько событий связаны друг с другом.
· Если существует цепочка связанных во времени событий, то говорят о последовательности.
· С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил.
· Кластеризация отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства Data Mining самостоятельно выделяют различные однородные группы данных.
· Основой для всевозможных систем прогнозирования служит историческая информация, хранящаяся в БД в виде временных рядов. Если удается построить найти шаблоны, адекватно отражающие динамику поведения целевых показателей, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем.
Data Mining является мультидисциплинарной областью, возникшей и развивающейся на базе достижений прикладной статистики, распознавания образов, методов искусственного интеллекта, теории баз данных и др. Отсюда обилие методов и алгоритмов, реализованных в различных действующих системах Data Mining. Многие из таких систем интегрируют в себе сразу несколько подходов. Ниже приводится классификация указанных ключевых компонент на основе работы.
1) Предметно-ориентированные аналитические системы
Предметно-ориентированные аналитические системы очень разнообразны. Наиболее широкий подкласс таких систем, получивший распространение в области исследования финансовых рынков, носит название "технический анализ". Он представляет собой совокупность нескольких десятков методов прогноза динамики цен и выбора оптимальной структуры инвестиционного портфеля, основанных на различных эмпирических моделях динамики рынка. Эти методы часто используют несложный статистический аппарат, но максимально учитывают сложившуюся своей области специфику.
2)Статистические пакеты
Последние версии почти всех известных статистических пакетов включают наряду с традиционными статистическими методами также элементы Data Mining. Но основное внимание в них уделяется все же классическим методикам - корреляционному, регрессионному, факторному анализу и другим. Недостатком систем этого класса считают требование к специальной подготовке пользователя. Также отмечают, что мощные современные статистические пакеты являются слишком "тяжеловесными" для массового применения в финансах и бизнесе.
3) Нейронные сети
Это большой класс систем, архитектура которых имеет аналогию (как теперь известно, довольно слабую) с построением нервной ткани из нейронов. Для того чтобы сеть можно было применять в дальнейшем, ее прежде надо "натренировать" на полученных ранее данных, для которых известны и значения входных параметров, и правильные ответы на них.
Основным недостатком нейросетевой парадигмы является необходимость иметь очень большой объем обучающей выборки. Другой существенный недостаток заключается в том, что даже натренированная нейронная сеть представляет собой черный ящик. Знания, зафиксированные как веса нескольких сотен межнейронных связей, совершенно не поддаются анализу и интерпретации человеком.
4) Системы рассуждений на основе аналогичных случаев
Идея систем case based reasoning - CBR - на первый взгляд крайне проста. Для того чтобы сделать прогноз на будущее или выбрать правильное решение, эти системы находят в прошлом близкие аналоги наличной ситуации и выбирают тот же ответ, который был для них правильным. Поэтому этот метод еще называют методом "ближайшего соседа" (nearest neighbour). В последнее время распространение получил также термин memory based reasoning, который акцентирует внимание, что решение принимается на основании всей информации, накопленной в памяти.
Системы CBR показывают неплохие результаты в самых разнообразных задачах. Главным их минусом считают то, что они вообще не создают каких-либо моделей или правил, обобщающих предыдущий опыт, - в выборе решения они основываются на всем массиве доступных исторических данных, поэтому невозможно сказать, на основе каких конкретно факторов CBR системы строят свои ответы.
Другой минус заключается в произволе, который допускают системы CBR при выборе меры "близости". От этой меры самым решительным образом зависит объем множества прецедентов, которые нужно хранить в памяти для достижения удовлетворительной классификации или прогноза.
5) Деревья решений (decision trees)
Деревья решения являются одним из наиболее популярных подходов к решению задач Data Mining. Они создают иерархическую структуру классифицирующих правил типа "ЕСЛИ... ТО..." (if-then), имеющую вид дерева. Для принятия решения, к какому классу отнести некоторый объект или ситуацию, требуется ответить на вопросы, стоящие в узлах этого дерева, начиная с его корня. Вопросы имеют вид "значение параметра A больше x?". Если ответ положительный, осуществляется переход к правому узлу следующего уровня, если отрицательный - то к левому узлу; затем снова следует вопрос, связанный с соответствующим узлом.
Популярность подхода связана как бы с наглядностью и понятностью. Но деревья решений принципиально не способны находить "лучшие" (наиболее полные и точные) правила в данных. Они реализуют наивный принцип последовательного просмотра признаков и "цепляют" фактически осколки настоящих закономерностей, создавая лишь иллюзию логического вывода.
6) Эволюционное программирование
В данной системе гипотезы о виде зависимости целевой переменной от других переменных формулируются в виде программ на некотором внутреннем языке программирования. Процесс построения программ строится как эволюция в мире программ (этим подход немного похож на генетические алгоритмы). Когда система находит программу, более или менее удовлетворительно выражающую искомую зависимость, она начинает вносить в нее небольшие модификации и отбирает среди построенных дочерних программ те, которые повышают точность. Таким образом система "выращивает" несколько генетических линий программ, которые конкурируют между собой в точности выражения искомой зависимости.
Другое направление эволюционного программирования связано с поиском зависимости целевых переменных от остальных в форме функций какого-то определенного вида.
7) Генетические алгоритмы
Data Mining не основная область применения генетических алгоритмов. Их нужно рассматривать скорее как мощное средство решения разнообразных комбинаторных задач и задач оптимизации. Тем не менее генетические алгоритмы вошли сейчас в стандартный инструментарий методов Data Mining, поэтому они и включены в данный обзор.
Первый шаг при построении генетических алгоритмов - это кодировка исходных логических закономерностей в базе данных, которые именуют хромосомами, а весь набор таких закономерностей называют популяцией хромосом. Далее для реализации концепции отбора вводится способ сопоставления различных хромосом. Популяция обрабатывается с помощью процедур репродукции, изменчивости (мутаций), генетической композиции. Эти процедуры имитируют биологические процессы. Наиболее важные среди них: случайные мутации данных в индивидуальных хромосомах, переходы (кроссинговер) и рекомбинация генетического материала, содержащегося в индивидуальных родительских хромосомах (аналогично гетеросексуальной репродукции), и миграции генов. В ходе работы процедур на каждой стадии эволюции получаются популяции с все более совершенными индивидуумами.
Генетические алгоритмы удобны тем, что их легко распараллеливать. Но так же имеют ряд недостатков. Критерий отбора хромосом и используемые процедуры являются эвристическими и далеко не гарантируют нахождения "лучшего" решения. Это особенно становится заметно при решении высокоразмерных задач со сложными внутренними связями.
8 ) Алгоритмы ограниченного перебора
Эти алгоритмы вычисляют частоты комбинаций простых логических событий в подгруппах данных. Примеры простых логических событий: X = a; X < a; X a; a < X < b и др., где X - какой либо параметр, "a" и "b" - константы. Ограничением служит длина комбинации простых логических событий. На основании анализа вычисленных частот делается заключение о полезности той или иной комбинации для установления ассоциации в данных, для классификации, прогнозирования и пр.
9) Системы для визуализации многомерных данных
В той или иной мере средства для графического отображения данных поддерживаются всеми системами Data Mining. Вместе с тем, весьма внушительную долю рынка занимают системы, специализирующиеся исключительно на этой функции.
В подобных системах основное внимание сконцентрировано на дружелюбности пользовательского интерфейса, позволяющего ассоциировать с анализируемыми показателями различные параметры диаграммы рассеивания объектов (записей) базы данных. К таким параметрам относятся цвет, форма, ориентация относительно собственной оси, размеры и другие свойства графических элементов изображения. Кроме того, системы визуализации данных снабжены удобными средствами для масштабирования и вращения изображений.
1.4. ГЕНЕРАЦИЯ И РАСПОЗНАВАНИЕ РЕЧИ
Проблемы сегментации речевого сообщения при построении систем автоматического распознавания речи.Чтобы научить компьютер распознавать речь, необходимо оцифровать звук. Затем с помощью математического манипулирования удалить лишний шум и прочие побочные звуки. Далее "очищенный" поток речи делится на фрагменты (сегменты), каждый из которых должен соответствовать целому слову или части слова. Это делается с помощью статистических алгоритмов, которые основаны на знании того, как говорят на данном языке. Один из методов автоматического распознавания речи осуществляется посредством анализа амплитудно-временного представления (АВП) звуковых волн, являющихся носителем речевой информации. Под сегментацией подразумевается “объективное разделение речевого сообщения на единицы, соотносимые с элементами принятого алфавита”. В качестве основной цели сегментации преследуется адекватность расчленения амплитудно-временного представления звуковой волны на денотатно-завершенные отрезки. Следовательно, всякий объект исследования, локализованный в результате такой сегментации, должен соответствовать концепту, то есть звуковому образу одного из элементов принятого алфавита. Однако очевидна проблематичность решения задачи сегментации, т.к. “речевой сигнал не допускает простого и однозначного членения на элементы (фонемы, аллофоны, слова), поскольку эти элементы не имеют явных физических границ”.
С другой стороны, “одной из наиболее сложных в автоматическом распознавании речи является проблема поиска признаков, описывающих речевой сигнал. Мы почти ничего не знаем о том, как распределена речевая информация в акустическом сигнале и по каким основным законам она кодирована”.
Основу процедур распознавания при этом составляет критериальное сравнение образа некоторого отрезка указанного представления звуковой волны с эталонами в выбранном пространстве признаков. В качестве эталонов выбирают, как правило, одну или несколько фонологических (языковых) единиц, множество которых составляют аллофоны, фонемы, диафоны, слоги, слова. В дальнейшем на основе распознавания указанных фонологических единиц осуществляется их интерпретация буквами языка, на котором происходит передача речевых сообщений, согласующаяся со словарно-грамматическими правилами, введенными в систему. Результатом распознавания являются графические эквиваленты фонологически определенных фрагментов звуковых волн как единиц языка. Алгоритмизация расчетов указанных групп признаков на протяжении звуковой волны должна привести к выявлению таких отрезков, которые представляют образы фонологических единиц, а следовательно, и к решению задачи автоматической сегментации речевых сообщений. Но распознавание слов - это еще не все. Для практического применения технологии необходимо добиться того, чтобы компьютер буквально понимал слова, причем именно в подлинном контексте запроса. Так что ему предстоит кропотливая работа по изучению смысла тысяч предложений. Компьютер дробит типовые предложения (до грамматических составляющих). Ему задают смысл каждой из компонент, так что он в дальнейшем сможет понять смысл отдельных слов или даже их частей.
1.5. РАСПОЗНАВАНИЕ ОБРАЗОВ И ОБРАБОТКА ВИЗУАЛЬНОЙ ИНФОРМАЦИИ
В последние годы распознавание образов находит все большее применение в повседневной жизни. Распознавание речи и рукописного текста значительно упрощает взаимодействие человека с компьютером, распознавание печатного текста используется для перевода документов в электронную форму. Алгоритмы, лежащие в основе распознавания, довольно очевидны.
В классической постановке задачи распознавания, универсальное множество, включающее все возможные для решения задачи элементы, разбивается на части-образы. Образ какого-либо объекта задается набором его частных проявлений. В случае с распознаванием текста в универсальное множество войдут все возможные знаки, в образ "Ы" - все возможные начертания этой буквы, а программа распознавания занимается тем, что на основе небольшого набора примеров начертаний каждой буквы (обучающей выборки) определяет, какую из них символизирует введенная закорючка.
Методика отнесения элемента к какому-либо образу называется решающим правилом. Еще одно важное понятие - метрика, способ определения расстояния между элементами универсального множества. Чем меньше это расстояние, тем более похожими являются символы, звуки - то, что мы распознаем. Обычно элементы задаются в виде набора чисел (а как еще?), а метрика - в виде функции. От выбора представления образов и реализации метрики зависит эффективность программы, один алгоритм распознавания с разными метриками будет ошибаться с разной частотой (право на ошибку для программ распознавания так же характерно, как и для людей).
1.6. НОВЫЕ АРХИТЕКТУРЫ КОМПЬЮТЕРОВ
В основу построения подавляющего большинства компьютеров положены следующие общие принципы.
1. Принцип программного управления. Из него следует, что программа состоит из набора команд, которые выполняются процессором автоматически друг за другом в определенной последовательности.
Выборка программы из памяти осуществляется с помощью счетчика команд. Этот регистр процессора последовательно увеличивает хранимый в нем адрес очередной команды на длину команды. А так как команды программы расположены в памяти друг за другом, то тем самым организуется выборка цепочки команд из последовательно расположенных ячеек памяти.
2. Принцип однородности памяти. Программы и данные хранятся в одной и той же памяти. Поэтому компьютер не различает, что хранится в данной ячейке памяти - число, текст или команда. Над командами можно выполнять такие же действия, как и над данными.
3. Принцип адресности. Структурно основная память состоит из перенумерованных ячеек; процессору в произвольный момент времени доступна любая ячейка.
Но существуют компьютеры, принципиально отличающиеся от фон-неймановских. Для них, например, может не выполняться принцип программного управления, т.е. они могут работать без "счетчика команд", указывающего текущую выполняемую команду программы. Для обращения к какой-либо переменной, хранящейся в памяти, этим компьютерам не обязательно давать ей имя. Такие компьютеры называются не-фон-нейман овскими.
Проблемы архитектуры фон Неймана. Узкое горло классической фон-неймановской архитектуры связано с тремя генетически присущими ей свойствами:
· необходимостью выборки команды из памяти для выполнения;
· выполнением одной команды в один момент времени;
· необходимостью выборки данных в процессор даже в том случае, когда они не требуют обработки.
Искусственные нейронные сети прочно вошли в нашу жизнь и в настоящее время широко используются при решении самых разных задач и активно применяются там, где обычные алгоритмические решения оказываются неэффективными или вовсе невозможными. В числе задач, решение которых доверяют искусственным нейронным сетям, можно назвать следующие: распознавание текстов, игра на бирже, контекстная реклама в Интернете, фильтрация спама, проверка проведения подозрительных операций по банковским картам, системы безопасности и видеонаблюдения.
Следует сформулировать следующие различия между двумя архитектурами. На принципе последовательных вычислений на ограниченных по длине символах основаны компьютеры, реализованные по традиционной архитектуре фон Неймана с алгоритмическими программами, а параллельные вычисления и распознавание образов лежат в основе нейрокомпьютеров, организованных по принципам, схожим с устройством и работой мозга.
Как уже было сказано, основная задача нейрокомпьютеров — обработка образов. При этом у них, как и в мозгу, отсутствуют общие шины, нет разделения на активный процессор и пассивную память, а вычисления и обучение распределены по всем элементарным процессорам — нейронам, которые функционируют параллельно. За счет этого нейрокомпьютеры позволяют добиться фантастической производительности, которая может в миллионы раз превышать производительность традиционных компьютеров с последовательной архитектурой.
Преимущества нейросетевого подхода заключаются в следующем:
· параллелизм обработки информации;
· единый и эффективный принцип обучения;
· надежность функционирования;
· способность решать неформализованные задачи.
2. ЭКСПЕРТНЫЕ СИСТЕМЫ КАК СОСТАВНАЯ ЧАСТЬ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Разработка интеллектуальных информационных cucmeм или систем, основанных на знаниях - это одно из главных направлений ИИС. Основной целью построения таких систем являются выявление, исследование и применение знаний высококвалифицированных экспертов для решения сложных задач, возникающих на практике. При построении систем, основанных на знаниях (СОЗ), используются знания, накопленные экспертами в виде конкретных правил решения тех или иных задач. Это направление преследует цель имитации человеческого искусства анализа неструктурированных и слабоструктурированных проблем. В данной области исследований осуществляется разработка моделей представления, извлечения и структурирования знаний, а также изучаются проблемы создания баз знаний (БЗ), образующих ядро СОЗ.
В течение последних десятилетий в рамках исследований по искусственному интеллекту (ИИ) сформировалось самостоятельное направление - экспертные системы (ЭС) или инженерия знании. В задачу этого направления входят исследование и разработка программ (устройств), использующих знания и процедуры вывода для решения задач, являющихся трудными для людей-экспертов. В отличие от специализированных систем ИИ экспертные системы могут быть отнесены к системам ИИ общего назначения - системам, которые не только исполняют заданные процедуры, но на основе мета процедур поиска генерируют и используют процедуры решения новых конкретных задач [1,3].
Экспертные системы – это наиболее распространенный класс ИИС, ориентированный на тиражирование опыта высококвалифицированных специалистов в областях, где качество принятия решений традиционно зависит от уровня экспертизы, например таких, как медицина, юриспруденция, геология, экономика, военное дело и др.
Огромный интерес к ЭС со стороны пользователей вызван, по крайней мере, тремя причинами:
· Во-первых, они ориентированы на решение широкого круга задач в неформализованных областях, на приложениях, которые до недавнего времени считались малодоступными для вычислительной техники.
· Во-вторых, с помощью ЭС специалисты, не знающие программирования, могут самостоятельно разрабатывать интересующие их приложения, что позволяет резко расширить сферу использования вычислительной техники.
· В-третьих, ЭС при решении практических задач достигают результатов, не уступающих, а иногда и превосходящих возможности людей-экспертов, не оснащенных ЭВМ.
Особенно широкое распространение ЭС получили в проектировании интегральных микросхем, в поиске неисправностей, в военных приложениях и автоматизации программирования. Применение ЭС позволяет: 1) при проектировании интегральных микросхем повысить (по данным фирмы NEC) производительность труда в 3-6 раз, при этом выполнение некоторых операций ускоряется в 10-15 раз; 2) ускорить поиск неисправностей в сложных устройствах в 5-10 раз; 3) повысить производительность труда программистов (по данным фирмы ТОSHIВА) в 5 раз; 4) при профессиональной подготовке сократить (без потери качества) в 8-12 раз затраты на индивидуальную работу с обучаемыми.
В последнее время ведутся разработки ЭС для следующих приложений: раннее предупреждение национальных и международных конфликтов и поиск компромиссных решений; принятие решений в кризисных ситуациях; охрана правопорядка; образование; медицина) планирование и распределение ресурсов; система организационного управления (кабинет министров, муниципалитет, учреждение) и т.д.
2.1. СОСТАВНЫЕ ЧАСТИ ЭС: БАЗА ЗНАНИЙ, МЕХАНИЗМЫ ВЫВОДА, ПРИОБРЕТЕНИЯ И ОБЪЯСНЕНИЯ ЗНАНИЙ. УЧАСТНИКИ ПРОЦЕССА ПРОЕКТИРОВАНИЯ
Знания, которыми обладает специалист в какой-либо области (дисциплине), можно разделить на формализованные (точные) и неформализованные (неточные). Формализованные знания формируются в книгах и руководствах в виде общих и строгих суждений (законов, формул, моделей, алгоритмов и т.п.), отражающих универсальные знания. Неформализованные знания, как правило, не попадают в книги и руководства в связи с их конкретностью, субъективностью и приблизительностью. Знания этого рода являются результатом обобщения многолетнего опыта работы и интуиции специалистов. Они обычно представляют многообразие эмпирических (эвристических) приемов и правил.
В зависимости от того, какие знания преобладают в той или иной области (дисциплине), ее относят к формализованным (если преобладают точные знания) или к неформализованным (если преобладают неточные знания) описательным областям. Задачи, решаемые на основе точных знаний, называют формализованными, а задачи, решаемые с помощью неточных знаний - неформализованными. (Речь идет не о неформализуемых, а о неформализованных задачах, т.е. о задачах, которые, возможно, и формализуемы, но эта формализация пока неизвестна).
Традиционное программирование в качестве основы для разработки программы использует алгоритм, т.е. формализованное значение. Поэтому до недавнего времени считалось, что ЭВМ не приспособлены для решения неформализованных задач. Расширение сферы использования ЭВМ показало, что неформализованные задачи составляют очень важный класс задач, вероятно, значительно больший, чем класс формализованных задач. Неумение решать неформализованные задачи сдерживает внедрение ЭВМ в описательные науки. По мнению авторитетов, основной задачей информатики является внедрение ее методов в описательные науки и дисциплины. На основании этого можно утверждать, что исследования в области ЭС занимают значительное место в информатике.
К неформализованным задачам относятся те, которые обладают одной или несколькими из следующих особенностей:
а) алгоритмическое решение задачи неизвестно (хотя, возможно, и существует) или не может быть использовано из-за ограниченности ресурсов ЭВМ (времени, памяти);
б) задача не может быть определена в числовой форме (требуется символьное представление);
в) цели задачи не могут быть выражены в терминах точно определенной целевой функции.
Как правило, неформализованные задачи обладают неполнотой, ошибочностью, неоднозначностью и/или противоречивостью знаний (как данных, так и используемых правил преобразования).
Экспертные системы не отвергают и не заменяют традиционного подхода к программированию, они отличаются от традиционных программ тем, что ориентированы на решение неформализованных задач и обладают следующими особенностями:
· алгоритм решения не известен заранее, а строится самой ЭС с помощью символических рассуждений, базирующихся на эвристических приемах;
· ясность полученных решений, т.е. система "осознает" в терминах пользователя, как она получила решение;
· способность анализа и объяснения своих действий и знаний;
· способность приобретения новых знаний от пользователя-эксперта, не знающего программирования, и изменения в соответствии с ними своего поведения (открытая система);
· обеспечение "дружественного", как правило, естественно-языкового (ЕЯ) интерфейса с пользователем.
Обычно к ЭС относят системы, основанные на знании, т.е. системы, вычислительная возможность которых является в первую очередь следствием их наращиваемой базы знаний (БЗ) и только во вторую очередь определяется используемыми методами. Методы инженерии знаний (методы ЭС) в значительной степени инвариантны тому, в каких областях они могут применяться. Области применения ЭС весьма разнообразны: военные приложения, медицина, электроника, вычислительная техника, геология, математика, космос, сельское хозяйство, управление, финансы, юриспруденция, и т.д. В настоящее время ЭС используются при решении задач следующих типов: принятие решений в условиях неопределенности (неполноты информации), интерпретации символов и сигналов, предсказание, диагностика, конструирование, планирование, управление, контроль и др.
Типичная ЭС состоит из следующих основных компонентов (рис.2.1): решателя (интерпретатора), рабочей памяти (РП), называемой также базой данных (БД), базы знаний (БЗ), компонентов приобретения знаний, объяснительного и диалогового.
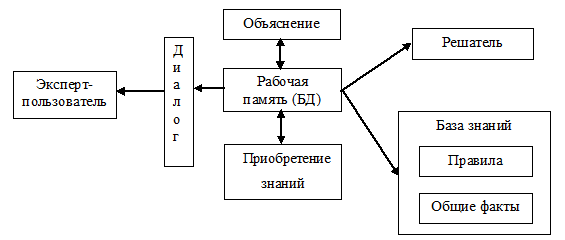
Рис. 2.1. Схема обобщенной экспертной системы
Рабочая память (база данных) предназначена для хранения исходных и промежуточных данных решаемой в текущей момент задачи. Термин база данных совпадает по названию, но не по смыслу с термином, используемым в информационно-поисковых системах (ИПС) и системах управления базами данных (СУБД) для обозначения всех данных (и в первую очередь не текущих, а долгосрочных), хранимых в системе.
База знаний в ЭС предназначена для хранения долгосрочных данных, описывающих рассматриваемую область (а не текущих данных), и правил, описывающие целесообразные преобразования данных этой области.
Решатель(интерпретатор) используя исходные данные из БД и знания из БЗ, формирует такую последовательность правил, которые, будучи примененными к исходным данным, приводят к решению задачи.
Компонента приобретения знаний автоматизирует процесс наполнения ЭС знаниями, осуществляемый пользователем-экспертом.
Объяснительная компонента объясняет, как система получила решение задачи (или почему она не получила решения) и какие знания при этом она использовала, что облегчает эксперту тестирование системы и повышает доверие пользователя к полученному результату.
Диалоговая компонента необходима длядружелюбного общения со всеми категориями пользователей, как в ходе решения задач, так и приобретения знаний, объяснения результатов работы.
В разработке ЭС участвуют представители следующих специальностей:
· эксперт в той проблемной области, задачи которой будет решать ЭС;
· инженер по знаниям (когнитолог) - специалист по разработке ЭС;
· программист - специалист по разработке инструментальных средств.
Необходимо отметить, что отсутствие среди участников разработки инженера по знаниям (т.е. его замена программистом) либо приводит к неудаче в процессе создания ЭС, либо значительно удлиняет его.
Эксперт определяет знания (данные и правила), характеризующие проблемную область, обеспечивает полноту и правильность введения в ЭС знаний.
Инженер по знаниям (когнитолог)помогает эксперту выявить и структурировать знания, необходимые для работы ЭС. Он выбирает тот инструментарий, который наиболее подходит для данной проблемной области, и определяет способ представления знаний в нем, выделяет и программирует (традиционными средствами) стандартные функции (типичные для данной проблемной области), которые будут использоваться в правилах, вводимых экспертом.
Уже при разработке первых ЭС стало очевидно, что наиболее ответственным этапом является построение БЗ, для чего в общем случае и необходим посредник – так называемый инженер по знаниям, который должен обеспечить проведение домашинных этапов разработки СОЗ, заключающихся, как правило, в анализе предметной области, извлечении знаний из эксперта и их структурировании.
Эти процедуры оказались самыми тяжелыми [1,6] поскольку, с одной стороны, чрезвычайно высок уровень требований, предъявляемых к личности инженера по знаниям (высококвалифицированный специалист в вычислительной науке, обладающий способностями к контакту с экспертами, умеющий побудить эксперта поставлять нужную информацию, умеющий отделять главное от второстепенного и т.д.), а с другой – стали наблюдаться трудности с поисками собственно экспертов (например, эксперт испытывает затруднения с четкой формулировкой своих знаний, не всегда расположен полностью делиться знаниями и др).
Поэтому почти одновременно с появлением индустрии знаний стали разрабатываться автономные системы, автоматизирующие процессы получения необходимой информации от экспертов. Позднее подобные программные средства получили название “оболочек приобретения”, а затем – инструментальных средств.
Программистразрабатывает инструментальное средство, содержащее в пределе все основные компоненты ЭС, осуществляет сопряжение с той средой, в которой оно может быть использовано.
2.2. РЕЖИМЫ РАБОТЫ ЭС
Экспертная система работает в двух режимах:
· приобретения знаний;
· решения задач (называемом также режимом консультации или режимом использования ЭС).
В режимеприобретения знаний общение с ЭС осуществляет эксперт через посредничество инженера по знаниям. Эксперт описывает проблемную область в виде совокупности данных и правил. Данные определяют объекты, их характеристики и значения, существующие в области экспертизы. Правила определяют способы манипулирования данными, характерные для рассматриваемой проблемной области. Эксперт, используя компонент приобретения знаний, наполняет систему знаниями, которые позволяют ЭС в режиме решения самостоятельно (без эксперта) решать задачи из проблемной области.
Важную роль в режиме приобретения знаний играет объяснительный компонент. Именно благодаря ему эксперт на этапе тестирования локализует причины неудачной работы ЭС, что позволяет эксперту целенаправленно моделировать старые или вводить новые знания. Обычно, объяснительный компонент сообщает следующее: как правильно использовать информацию пользователя; почему использовались или не использовались данные или правила; какие были сделаны выводы и т.п. Все объяснения делаются, как правило, на ограниченном естественном языке или языке графики. Отметим, что режиму приобретения знаний при традиционном подходе к разработке программ соответствуют этапы алгоритмизации, программирования и отладки, выполняемые программистом. Таким образом, в отличие от традиционного подхода разработку программ осуществляет эксперт (с помощью ЭС), не владеющий программированием, а не программист.
В режиме консультацииобщение с ЭС осуществляет конечный пользователь, которого интересует результат и/или способ получения решения. Пользователь в зависимости от назначения ЭС может не быть специалистом в данной проблемной области, в этом случае он обращается к ЭС за советом, не умея получить ответ сам, или быть специалистом, в этом случае он обращается к ЭС, чтобы либо ускорить процесс получения результата, либо возложить на ЭС рутинную работу. Термин "пользователь" является многозначным, так как кроме конечного пользователя применять ЭС может и эксперт, и инженер по знаниям, и программист. Поэтому, когда хотят подчеркнуть, что речь идет о том, для кого делалась ЭС, используют термин "конечный пользователь".
В режиме консультации данные о задаче пользователя обрабатываются диалоговой компонентой, которая выполняет следующие действия: распределяет роли участников (пользователя и ЭС) и организует их взаимодействие в процессе кооперативного решения задачи; преобразует данные пользователя о задаче, представленные на первичном для пользователя языке, во внутренний язык системы; преобразует сообщения системы, представленные на внутреннем языке в сообщения на языке, привычном для пользователя (обычно это ограниченный естественный язык или язык графики). В общем случае процесс решения задачи с помощью ЭС в режиме консультации может быть представлен в виде схемы (рис.2.2).

Рис. 2.2. Процесс решения задачи с помощью ЭС в режиме
консультации
После обработки данные поступают в РП. На основе входных данных из РП, общих данных о проблемной области и правил из БЗ решатель (интерпретатор) формирует решение задачи.
В отличие от традиционных программ ЭС в режиме задачи не только исполняет предписанную последовательность операций, но и предварительно формирует ее. Если ответ ЭС не понятен пользователю, то он может потребовать объяснения, как ответ получен.
2.3. КЛАССИФИКАЦИЯ ЭКСПЕРТНЫХ СИСТЕМ
Экспертные системы как любой сложный объект можно определить только совокупностью характеристик. Выделим следующие характеристики ЭС:
· Назначение;
· Проблемная область;
· Глубина анализа проблемной области;
· Тип используемых методов и знаний;
· Инструментальные средства;
· Стадия существования (см. раздел 2.5. Технология разработки ЭС);
· Класс системы.
Перечисленный набор характеристик не претендует на полноту (в связи с отсутствием общепринятой классификации), а определяет ЭС как целое, не выделяя отдельных компонентов (способ представления знаний, решения задач и т.п.).
2.3.1. НАЗНАЧЕНИЕ ЭС
Назначение определяется следующей совокупностью параметров: цель создания ЭС - для обучения специалистов, для решения задач, для автоматизации рутинных работ, для тиражирования знаний экспертов и т.п.; основной пользователь - не специалист в области экспертизы, специалист, учащийся.
2.3.2. ПРОБЛЕМНАЯ ОБЛАСТЬ. СТАТИЧЕСКИЕ И ДИНАМИЧЕСКИЕ ЭС
Проблемная область может быть определена совокупностью параметров: предметной областью и задачами, решаемыми в предметной области, каждый из которых может рассматриваться с точки зрения как конечного пользователя, так и разработчика ЭС.
С точки зрения пользователя, предметную область можно характеризовать описанием области в терминах пользователя, включающим наименование области, перечень и взаимоотношение подобластей и т.п., а задачи, решаемые существующими ЭС, - их типом. Обычно выделяют следующие типы задач:
· интерпретация символов или сигналов - составление смыслового описания по входным данным;
· предсказание - определение последствий наблюдаемых ситуаций;
· диагностика - определение состояния неисправностей, заболеваний по признакам (симптомам);
· конструирование - разработка объекта с заданными свойствами при соблюдении установленных ограничений;
· планирование - определение последовательности действий, приводящих к желаемому состоянию объекта;
· слежение - наблюдение за изменяющимся состоянием объекта и сравнение его показателей с установленными или желаемыми;
· управление - воздействие на объект для достижения желаемого поведения.
С точки зрения разработчика целесообразно выделять статические и динамические предметные области. Предметная область называется статической, если описывающие ее исходные данные не изменяются во времени (точнее рассматриваются как не изменяющиеся за время решения задачи). Статичность области означает неизменность описывающих ее исходных данных. Если исходные данные, описывающие предметную область, изменяются за время решения задачи, то предметную область называют динамической. Кроме того, предметные области можно характеризовать следующими аспектами: числом и сложностью сущностей; их атрибутов и значений атрибутов; связностью сущностей и их атрибутов; полнотой знаний; точностью знаний (знания точны или правдоподобны; правдоподобность знаний представляется некоторым числом или высказыванием).
Решаемые задачи, с точки зрения разработчика ЭС, также можно разделить на статические и динамические. Будем говорить, что ЭС решает динамическую или статическую задачу, если процесс решения задачи изменяет или не изменяет исходные данные о текущем состоянии предметной области.
В подавляющем большинстве существующих ЭС исходит из предположения статичности предметной области и решают статические задачи, будем называть такие ЭС статическими. ЭС, которые имеют дело с динамическими предметными областями и решают статистические или динамические задачи, будем называть динамическими. В последние годы стали появляться первые динамические ЭС. Видимо решение многих важнейших практических неформализованных задач возможно только с помощью динамических, а не статических ЭС. Следует подчеркнуть, что на традиционных (числовых) последовательных ЭВМ с помощью существующих методов инженерии знаний можно решать только статические задачи, а для решения динамических задач, составляющих большинство реальных приложений, необходимо использовать специализированные символьные ЭВМ.

Рис. 2.3. Архитектура статической и динамической ЭС
На рис.2.3 представлена архитектура статической и динамической ЭС [6,1,4].
Решаемые задачи, кроме того, можно характеризовать следующими аспектами: числом и сложностью правил, используемых в задаче; связностью правил; пространством поиска; количеством активных агентов, изменяющих предметную область; классом решаемых задач.
По степени сложности выделяют простые и сложные правила,
К сложным относят правила, текст знаний которых на естественном языке занимает 1/3 страницы и больше. Правила, текст которых занимает менее 1/3 страницы относят к простым.
По степени связности правил, задачи делятся на связные и мало связные. К связным относят задачи (подзадачи), которые не удается разбить на независимые задачи. Мало связные задачи удается разбить на некоторое количество независимых подзадач.
Можно сказать, что степень сложности определяется не просто общим количеством правил данной задачи, а количеством правил в ее наиболее связной независимой подзадаче.
Пространство поиска может быть определено по крайней мере тремя под аспектами: размером, глубиной и шириной. Размер пространства поиска дает обобщенную характеристику сложности задачи. Выделяют малые (до 10! состояний) и большие (свыше 10! состояний) пространства поиска. Глубина пространства поиска характеризуется средним числом последовательно применяемых правил, преобразующих исходные данные в конечный результат, ширина пространства - средним числом правил, пригодных к выполнению в текущем состоянии.
Класс решаемых задач характеризует методы, используемые ЭС для решения задачи. Данный аспект в существующих ЭС применяет следующие значения: задачи расширения, доопределения, преобразования. Задачи расширения и доопределения являются статическими, а задачи преобразования - динамическими.
К задачам расширения относятся задачи, в процессе решения которых осуществляется только увеличение информации о предметной области, не приводящие ни к изменению ранее выведенных данных, ни к выбору другого состояния области. Типичной задачей этого класса являются задачи классификации.
К задачам доопределения относятся задачи с неполной или неточной информацией о реальной предметной области, цель решения которых - выбор из множества альтернативных текущих состояний предметной области того, которое адекватно исходным данным. В случае неточных данных альтернативные текущие состояния возникают как результат ненадежности данных и правил, что приводит к многообразию различных доступных выводов из одних и тех же исходных данных. В случае неполных данных альтернативные состояния являются результатом до определения области, т.е. результатом предположений о возможных значениях недостающих данных.
К задачам преобразования относятся задачи, которые осуществляют изменения исходной или выведенной ранее информации о предметной области, являющиеся следствием изменений либо реального мира, либо его модели.
Большинство существующих ЭС решают задачи расширения, в которых нет ни изменений предметной области, ни активных агентов, преобразующих предметную область. Подобное ограничение неприемлемо при работе в динамических областях.
2.3.3. ГЛУБИНА АНАЛИЗА ПРОБЛЕМНОЙ ОБЛАСТИ
По степени сложности структуры ЭС делят на поверхностные и глубинные. Поверхностные ЭС представляют знания об области экспертизы в виде правил (условие ® действие). Условие полного правила определяет образец некоторой ситуации, при соблюдении которой правило может быть выполнено. Поиск решения состоит в выполнении тех правил, образцы которых сопоставляются с текущими данными (текущей ситуации в РП). Глубинные ЭС, кроме возможностей поверхностных систем, обладают способностью при возникновении неизвестной ситуации определять с помощью некоторых общих принципов, справедливых для области экспертизы, какие действия следует выполнять.
2.3.4. ТИП ИСПОЛЬЗУЕМЫХ МЕТОДОВ ПРЕДСТАВЛЕНИЯ И ЗНАНИЙ
По типу используемых методов и знаний ЭС делят на традиционные и гибридные. Традиционные ЭС используют в основном неформализованные методы инженерных знаний и неформализованные знания, полученные от экспертов. Гибридные ЭС используют и методы инженерии знаний и формализованные методы, а также данные традиционного программирования и математики.
Сейчас говорят о трех поколениях ЭС. К первому поколению следует относить статические поверхностные ЭС, ко второму - статические глубинные ЭС (иногда ко второму поколению относят гибридные ЭС), а к третьему - динамические ЭС (вероятно, они, как правило, будут глубинными и гибридными).
2.3.5. ИНСТРУМЕНТАЛЬНЫЕ СРЕДСТВА
Большинство инструментальных средств (ИТС) предназначено для создания прототипов ЭС, решающих статические задачи (обычно задачи расширения) в статических проблемных областях. По степени применимости ИТС выделяют следующие стадии существования: исследовательская, промышленная, коммерческая. Разделяют следующие типы ИТС:
1) языки программирования;
2) языки инженерии знаний;
3) средства автоматизации разработки (проектирования) ЭС;
4) оболочки ЭС.
С точки зрения потребителя, на выбор ИТС влияют моменты:
· затраты труда на построение ЭС или ее прототипа с помощью ИТС;
· эффективность функционирования ЭС, построенной на основе выбранного ИТС;
· квалификация разработчика, необходимая для применения ИТС.
Оболочки ЭС ориентированы на работу с пользователем–непрофессионалом в области программирования. Основным свойством оболочек является то, что они содержат все компоненты ЭС в готовом виде и их использование не предполагает программирования, а сводится лишь к вводу в оболочку знаний о проблемной области. Каждая оболочка характеризуется фиксированным способом представления знаний и организации вывода и фиксирования компонентов, которые будут использоваться во всех положениях, где будет применяться оболочка. Наиболее популярные оболочки обладают следующими свойствами:
1. решают задачи класса расширения в статических предметных областях в условиях ненадежности знаний;
2. представляют процедурные знания в виде правил;
3. описывают предметную область в виде значений неструктурированных переменных и утверждений, снабженных мерой их истинности (определенности).
Желание представить разработчику ЭС разнообразные средства для учета особенностей приложения, привело к объединению в рамках одной системы различных методов решения задач, представления и интерпретации знаний. В их состав могут входить средства модификации функционирования оболочки, набор компонентов, позволяющих конструировать собственные оболочки, средства комплексирования компонентов в виде языка высокого уровня, развитые интерактивные графические средства общения с пользователем. Подобные средства называют средствами автоматизации проектирования (разработки) ЭС.
Характеристика "Универсальность" определяет возможности ЭС в использовании различных способах представления знаний в рабочей памяти и базе знаний и различных парадигм функционирования системы. Наличие универсальности позволяет адекватно отображать в системе различные типы знаний о проблемной области. К настоящему времени в большинстве ЭС при представлении знаний используют фреймы и сети, а в качестве механизма функционирования, как правило, программирование, ориентированное на правила.
Характеристика "Основные свойства" определяет особенности, которые присущи инструментарию ЭС в реализации основных программных компонентов системы. Для решателя наиболее важны способы сопоставления и основной способ планирования вычисления (построение цепочек вывода от данных или от целей). Задача сопоставления состоит в том, чтобы определить, какое из правил, хранящихся в БЗ, может быть применено к текущему состоянию предметной области, хранимой в РП. Способы сопоставления в значительной мере зависят от: типа ссылки на объекты РП, используемого в правиле; вида данных РП, сопоставляемых со ссылками; вида проверок, выполняемых в ходе сопоставления.
Выделяют следующие типы ссылок:
· конкретная, когда ссылка (идентификатор) в условии правила является адресом конкретного элемента РП;
· абстрактная, когда ссылка (идентификатор и его описание) в условии правила именует не конкретный, а любой элемент в РП, свойства которого сопоставляются с описанием ссылки, указанным в правиле (т.е. описание определяет класс элементов РП).
Существующие инструментальные средства ЭС допускают следующие виды данных РП: константы; переменные, имеющие значения; сложные структуры (типы фрейм), логически объединяющее множество переменных. В них используются либо тривиальные виды проверок, сводящиеся к проверке наличия (отсутствия) указанных элементов в РП, либо сложные, требующие вычисления некоторых соотношений между значениями ссылок, указанных в условиях правил. В первом приближении способ сопоставления определяется используемым типом ссылок, видом данных РП к видам проверок.
Средства приобретения знаний в существующих ЭС можно оценивать с точки зрения допустимых способов формирования БЗ. Выделяют следующие способы формирования БЗ:
· редакторы;
· средства отладки;
· средства индуктивного вывода новых знаний.
Редакторы позволяют отображать и модифицировать БЗ, возможно, в графическом виде, поддерживая ее целостность. Средства отладки обеспечивают анализ содержимого БЗ. переформирование и отображение его результатов пользователю. Средства индуктивного вывода осуществляют формирование новых знаний (правил) на основе вводимых пользователем примеров ситуаций с их решениями.
2.3.6. КЛАСС ЭС
В последнее время выделяются два больших класса ЭС (существенно отличающихся по технологии их проектирования), которые условно можно назвать простыми и сложными ЭС. Простая ЭС может быть охарактеризована следующими значениями основных параметров: поверхностная ЭС; традиционная ЭС (реже гибридная); выполненная на персональной ЭВМ. Сложная ЭС может быть охарактеризована следующими значениями параметров: глубинная ЭС; гибридная ЭС; выполненная либо на символьной ЭВМ, либо на мощной универсальной ЭВМ, либо на интеллектуальной рабочей станции.
Следует отметить, что единую классификацию всех существующих на сегодня ЭС провести достаточно сложно, так как, с одной стороны, можно выделить большое количество специфических характеристик ЭС, а с другой стороны – у разных авторов существуют значительные различия в терминологии обозначения одних и тех же вещей.
Предложим классификацию ЭС на основе следующих базовых параметров:
· уровень используемого языка;
· машина вывода (решатель);
· методы описания ПО;
· способ представления знаний;
· парадигма программирования и др.
На рис.2.4-2.8 показаны классификации ЭС по указанным параметрам.
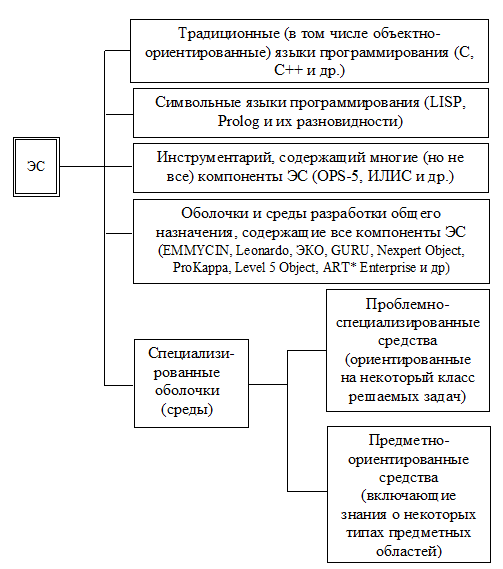
Рис. 2.4. Классификация ЭС по уровню используемого языка
На рис.2.4 весь инструментарий перечислен в порядке убывания трудозатрат, необходимых при создании ЭС с их помощью.
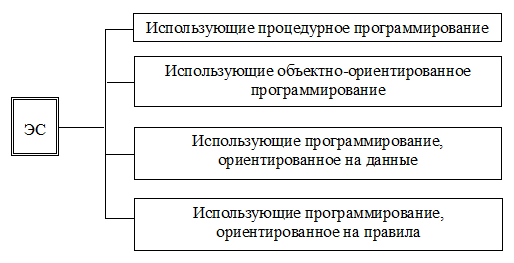
Рис. 2.5. Классификация ЭС по парадигмам программирования (механизм реализации исполняемых утверждений)
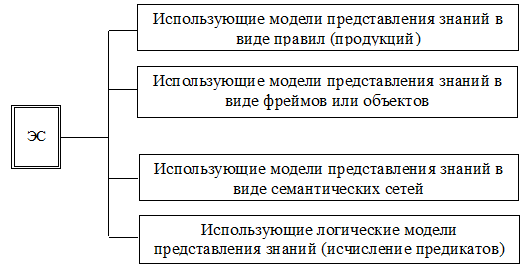
Рис. 2.6. Классификация ЭС по способу представления знаний (характеризующемуся моделью представления знаний)
На рис.2.7 дана классификация ЭС по параметру, связанному не с машиной вывода, а с общими способами рассуждений, принятыми в конкретных предметных областях.
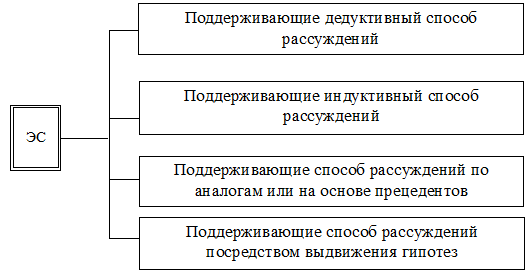
Рис. 2.7. Классификация ЭС по реализации различных способов
рассуждений

Рис. 2.8. Классификация ЭС по методам описания
проблемных областей
Признаки системной классификации методов исследования (рис.2.9.б) зададим через обобщение структуры ИИС (рис.2.9.а).

Рис. 2.9.Научные методы исследования
Подавляющее большинство совместимых статических ЭС ориентированны на реализацию дедуктивного способа рассуждений, причем акценты делаются на такие параметры логического вывода, как:
· структура процесса получения решения;
· методы поиска решения;
· стратегии разрешения конфликтов;
· управление достоверностью и др.
Конкретные значения этих параметров могут выступать как некоторые критерии оценки машины вывода.
Следует отметить, что из всего многообразия моделей в современных ЭС используются только правила и объекты (фреймы). Напомним также, что ЭС, имеющие в своем составе более двух моделей представления знаний, называются гибридными.
Комментируя классификацию, приведенную на рис.2.8, следует отметить, что подход на базе поверхностных знаний заключается в извлечении из эксперта фрагментов эвристических знаний о данной ПО, которые релевантны решаемой задаче, причем не предпринимается никаких попыток глубинного изучения области, что предопределяет использование поиска в пространстве состояний в качестве универсального механизма вывода. Как правило, этот подход применяется к задачам, которые не могут быть точно описаны, и в качестве способа представления знаний выбираются правила. Если же задача может быть заранее структурирована или при ее решении можно воспользоваться некоторой моделью, то такой подход неэффективен.
Структурированный подход используется в качестве развития поверхностного подхода в том случае, если применение поверхностного не обеспечивает решения задачи. Используя декомпозицию задачи на подзадачи (дерево подзадач), можно затем решать каждую задачу на основе поверхностного или глубинного подхода, а возможно, и их комбинации.
При использовании глубинного подхода к решению задачи качество и компетентность ЭС будут зависеть от модели ПО, причем эта модель может быть определена различными способами (декларативно, процедурно). При глубинном подходе используются ЭС с мощными моделирующими возможностями, а именно: объекты (фреймы) с присоединенными процедурами, иерархическое наследование свойств, активные объекты, механизмы передачи сообщений объектам и др. Если сравнить, описанные выше подходы, с типами ПО то можно более детально классифицировать и оценить конкретные ЭС по данному параметру.
2.4. ТЕХНОЛОГИЯ РАЗРАБОТКИ ЭС
Разработка (проектирование) ЭС существенно отличается от разработки обычного программного продукта. Опыт разработки ранних ЭС показал, что использование при разработке методологии, принятой в традиционном программировании, либо чрезмерно затягивает процесс создания ЭС, либо вообще приводит к отрицательному результату. Дело в том, что неформализованность задач, решаемых ЭС, отсутствие завершенной теории ЭС и методологии их разработки приводит к необходимости модифицировать их принципы и способы построения ЭС в ходе процесса разработки по мере того, как увеличивается знание разработчиков о проблемной области.
Перед тем, как приступить к разработке ЭС, инженер по знаниям должен рассматривать вопрос, следует ли разрабатывать ЭС для данного приложения. В обобщенном виде ответ может быть таким: использовать ЭС следует тогда, когда разработка ЭС: 1) возможна, 2) оправдана и 3) методы инженерии знаний соответствуют решаемой задаче.
1. Чтобы разработка ЭС была возможна (для данного приложения), необходимо одновременно выполнение по крайней мере следующих требований:
· существуют эксперты в данной области, которые решают задачу значительно лучше, чем начинающие специалисты;
· эксперты должны сходиться в оценке предлагаемого решения, иначе нельзя будет оценить качество разработанной ЭС;
· эксперты должны уметь выразить на естественном языке (вербализовать) и объяснить используемые ими методы, в противном случае трудно рассчитывать на то, что знания экспертов будут "извлечены" и вложены в ЭС;
· задача, возложенная на ЭС, требует только рассуждений, а не действий (если требуется действие, то необходимо объединять ЭС с роботами);
· задача не должна быть слишком трудной, ее решение должно занимать у эксперта несколько часов, а не дней или недель;
· задача, хотя и не должна быть выражена в формальном виде, но все же должна относиться к достаточно "понятной" и структурированной области, т.е. должны быть выделены основные понятия, отношения и известные (хотя бы эксперту) способы получения решения задач;
· решение задачи не должно в значительной степени использовать "здравый смысл'" (т.е. широкий спектр общих сведений о мире и о способе его функционирования, которые знает и умеет использовать любой нормальный человек), т.к. подобные знания пока не удается (в достаточном количестве) вложить в системы искусственного интеллекта.
Использование ЭС в данном приложении может быть возможно, но не оправдано.
2. Применение ЭС может быть оправдано одним из следующих факторов:
· решение задачи принесет значительных эффект, например, использование ЭС для поиска полезных ископаемых;
· использование человека-эксперта невозможно либо из-за недостаточного количества экспертов, либо из-за необходимости выполнять экспертизу одновременно в различных местах;
· при передаче информации эксперту происходит недопустимая потеря времени или информации;
· при необходимости решать задачу в окружении враждебном для человека.
3. Приложение соответствует методам ЭС, если решаемая задача обладает совокупностью следующих характеристик:
· может быть естественным образом решена посредством манипуляции символами (т.е. с помощью символьных рассуждений), а не с числами (как принято в математических методах и традиционных программах);
· должна иметь эвристическую (не алгоритмическую) природу, т.е. ее решение должно сводиться к применению эвристических правил; задачи, которые могут быть гарантировано решены (с соблюдением заданных ограничений) с помощью некоторых формальных процедур, не подходит для применения ЭС;
· должна быть достаточно сложной чтобы оправдать затраты на разработку ЭС, однако, не должна быть чрезмерно сложной (решение занимает у эксперта часы, а не недели), чтобы ЭС могла ее решить;
· должна быть достаточно узкой, чтобы решаться методами инженерии знаний, и практически значимой.
При разработке ЭС используется концепция "быстрого прототипа". Суть ее состоит в том, что разработчики не пытаются сразу создать конечный продукт. На начальном этапе они создают прототип (прототипные) ЭС, которые должны удовлетворять двум противоречивым требованиям: с одной стороны, решать типовые задачи конкретного приложения, а с другой - время и трудоемкость его разработки должны быть весьма незначительны, чтобы можно было максимально запараллелить процесс накопления и отладки знаний (осуществляемый экспертом) с процессом выбора (разработки) программных средств (осуществляемым инженером по знаниям и программистом). Прототип должен продемонстрировать пригодность методов инженерии знаний для данного приложения. В случае успеха эксперт с помощью инженера по знаниям расширяет знания прототипа о проблемной области. При неудаче может потребоваться разработка нового прототипа или разработчики могут прийти к выводу о непригодности методов инженерии знаний для данного приложения.
В ходе работ по созданию ЭС сложилась определенная технология их разработки, включающая шесть следующих этапов: идентификация, концептуализация, формализация, выполнение, тестирование, опытная эксплуатация (рис.2.10).
Рассмотрим этапы разработки ЭС:
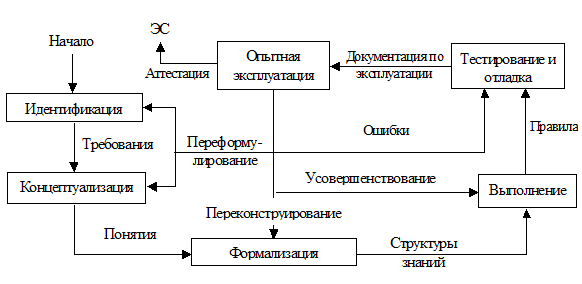
Рис. 2.10. Технология разработки ЭС
2.4.1. ЭТАП ИДЕНТИФИКАЦИИ
На данном этапе идентифицируются (определяются) задачи, которые подлежат решению, выявляются цели разработки, определяются участники процесса проектирования и их роли (эксперты и категории пользователей), ресурсы.
Идентификация задачи заключается в составлении неформального (вербального) описания решаемой задачи. В этом описании указываются: общие характеристики задачи; подзадачи, выделяемые внутри данной задачи; ключевые понятия (объекты), характеристики и отношения; входные (выходные) данные; предположительный вид решения; знания, релевантные решаемой задаче; примеры (тесты) решения задачи. Цель идентификации задачи - характеризовать задачу и структуру поддерживающих ее знаний и таким образом обеспечить начальный импульс для развития БЗ. Если исходная задача оказывается слишком сложной с точки зрения имеющихся ресурсов, то этап идентификации может потребовать нескольких итераций.
В ходе идентификации задачи (задач) необходимо ответить на следующие вопросы:
· какие задачи предлагается решать ЭС и как они могут быть охарактеризованы и определены;
· на какие задачи разбивается каждая задача и какие данные они используют;
· каковы основные понятия и взаимоотношения, используемые при формулировании и решении задачи;
· какие знания релевантны решаемой задаче;
· какие ситуации препятствуют решаемой задачи;
· как эти препятствия будут влиять на ЭС.
Идентификация целей заключается в формулировании, в явном виде, целей построения ЭС. При этом важно отличать цели, ради которых создается ЭС, от задач, которые она должна решать. Примерами возможных целей являются:
· формализация неформальных знаний экспертов;
· улучшение качества решений, принимаемых экспертом;
· автоматизация рутинных аспектов работы эксперта (пользователя);
· тиражирование знаний эксперта.
Определение участников и их ролей сводится к определению количества экспертов и инженеров по знаниям, а также форм их взаимоотношения. Обычно, в основном цикле разработки ЭС участвует не менее трех, четырех человек - один эксперт, один или два инженера по знаниям и один программист, привлекаемый для модификации и согласования инструментальных средств. К процессу разработки могут привлекаться и другие участники, группа экспертов с руководителем и др. Что касается формы взаимоотношения экспертов и инженеров, то применяются следующие формы: эксперт выполняет роль информирующего или учителя, а инженер роль ученика. Форма учитель - ученик больше соответствует реальности. В процессе идентификации задачи инженер и эксперт работают в тесном контакте.
При проектировании ЭС типичными ресурсами являются: источники знаний, время разработки, вычислительные средства и объем финансирования. Для достижения успеха эксперт и инженер должны использовать все доступные им источники знаний.
2.4.2. ЭТАП КОНЦЕПТУАЛИЗАЦИИ
Эксперт и инженер по знаниям объясняют и выделяют ключевые понятия, отношения (упомянутые на этапе идентификации) и характеристики, необходимые для описания решения задачи. На этом этапе определяются следующие особенности задачи:
· типы доступных данных;
· исходные и выводимые данные:
· подзадачи общей задачи;
· используемые стратегии и гипотезы; виды взаимосвязей между объектами проблемной области;
· типы используемых отношений (иерархия, причина-следствие, часть-целое и т.п.);
· процессы, используемые в ходе решения задачи; типы ограничений, накладываемых на процессы, используемые в ходе решения;
· состав знаний, используемых для решения задачи;
· состав знаний, используемых для оправдания (объяснения) решения.
На данном этапе (как и на этапе идентификации) может потребоваться несколько повторных взаимодействий между экспертом и инженером по знаниям, что приводит к значительным затратам времени. Опыт разработок ЭС убеждает в том, что на данном этапе невозможно, да и не нужно добиваться корректности и полноты разрабатываемой ЭС. Необходимо как можно раньше переходить к следующим этапам (формализации и выполнению).
2.4.3. ЭТАП ФОРМАЛИЗАЦИИ
На данном этапе все ключевые понятия и отношения, введенные на этапе концептуализации, выражаются на некотором формальном языке, предложенном (выбранном) инженером по знаниям. Он определяет, подходят ли имеющиеся ЭС для решения рассматриваемой проблемы или необходимы оригинальные разработки. Выходом этапа формализации является описание того, как рассматриваемая задача может быть представлена в выбранном или разработанном формализме.
При проектировании ЭС перед разработчиками неизменно встает вопрос о выборе подходящего формализма для представления знаний. Решение этого вопроса является не только важнейшей стратегической задачей при разработке ЭС, но и достаточно сложной экспертной задачей.
Рассмотрим некоторые предложения (или критерии) по выбору адекватного формализма для представления знаний. Поскольку процесс выбора является творческой задачей и на сегодня не существует исчерпывающих рекомендаций по ее решению, то зафиксируем некоторые экспертные знания по этому вопросу.
Ниже представлены 8 критериев (рекомендаций) по выбору модели представления знаний на основе учета базовых характеристик предметной области – понятийной структуры предметной области. Для удобства все критерии сформулированы как правила вида: “Если (условие), то (действие)”.
1. ЕСЛИ понятия простые И отношения между ними выражаются в языке исчисления предикатов И способ рассуждений дедуктивный, ТО целесообразно использовать логические модели.
2. ЕСЛИ понятия являются в основном простыми И есть небольшое число отношений на понятиях И способ рассуждений индуктивный, ТО целесообразно использовать индуктивные модели.
3. ЕСЛИ понятия устроены сложным образом И есть большое число отношений на понятиях И способ рассуждений – выдвижение гипотез, ТО целесообразно использовать сетевые модели.
4. ЕСЛИ понятия устроены сложным образом И есть небольшое число отношений на понятиях И способ рассуждений дедуктивный, ТО целесообразно использовать наследственно-конечные модели (типа тезаурусов).
5. ЕСЛИ понятия устроены сложным образом И большое число отношений на понятиях И способ рассуждений по аналогии или дедуктивный, ТО целесообразно использовать фреймовые модели.
6. ЕСЛИ понятия устроены простым образом И большое число отношений на понятиях И способ рассуждений дедуктивный, ТО целесообразно использовать продукционные модели.
7. ЕСЛИ понятия устроены сложным образом И структура многих понятий не ясна И способ рассуждений – выдвижение гипотез, ТО целесообразно использовать сетевые модели.
8. ЕСЛИ понятия устроены сложным образом И есть большое число отношений на понятиях И способ рассуждений индуктивный, ТО подходящий формализм отсутствует.
С точки зрения классификации знаний по “глубине” и “жесткости” можно также предложить некоторые критерии выбора модели представления знаний, сформулированные в виде следующих правил.
1. ЕСЛИ представляемые знания являются поверхностными И жесткими, ТО целесообразно использовать логические модели.
2. ЕСЛИ представляемые знания являются поверхностными И мягкими ИЛИ жесткими, ТО целесообразно использовать продукционные модели.
3. ЕСЛИ представляемые знания являются глубинными И мягкими ИЛИ жесткими, ТО целесообразно использовать модели в виде семантических сетей или фреймов (объектно-ориентированные модели).
Процесс формализации зависит от трех основных факторов:
· структуры пространства поиска, характеризующей особенности решаемой задачи;
· модели, лежащей в основе процесса решения задачи;
· свойств данных решаемой задачи.
Чтобы понять структуру пространства поиска, необходимо формализовать понятия (объекты, их характеристики и значения) и определить, как они могут связываться друг с другом при образовании гипотез, используемых для направления поиска. При этом необходимо ответить на следующие вопросы:
· являются ли понятия примитивными или имеют внутреннюю структуру;
· необходимо ли представлять причинные или пространственно-временные отношения между понятиями и должны ли они быть представлены явно;
· необходима ли иерархия гипотез;
· относится коэффициент определенности (или другие средства для выражения мнения) только к окончательным гипотезам, или он необходим для промежуточных гипотез;
· необходимо ли рассматривать понятия и процессы на различных уровнях абстракции?
Важный шаг в процессе формализации знаний - построение модели исследуемой задачи, так как наличие модели позволяет генерировать решение. Могут быть использованы как поведенческие, так и математические модели. Если эксперт использует при рассуждении или обосновании решения хотя бы простейшую поведенческую модель, то это позволяет выработать важные понятия и отношения. Если же эксперт использует математическую модель (аналитическую или статистическую), то она может быть непосредственно включена в ЭС как для формирования решения, так и для объяснения (оправдания) причинных отношений, обнаруживаемых в БЗ.
Для формализации знаний весьма важно понимать природу данных проблемной области. Необходимо определить свойства данных, которые существенно влияют на решение исходной проблемы. Это могут быть следующие свойства:
· данные объясняются или нет в терминах гипотез;
· тип отношений между данными (причинные, определительные, корреляционные);
· знание типа отношений помогает объяснить, как взаимосвязаны данные, гипотезы и цели в процессе решения;
· данные редки (обильны) или недостаточны (избыточны);
· данные определены или нет, т.е. требуется ли коэффициент определенности;
· интерпретация данных зависит или не зависит от порядка их появления во времени;
· стоимость приобретения данных; как данные приобретаются (какие вопросы необходимо задать для получения данных);
· как необходимые характеристики объектов могут быть извлечены из входного сообщения (сигнал, изображение, текст на естественном языке, устная речь и т.п.);
· данные надежны (ненадежны), точны (неточны);
· данные согласованы (не согласованы), полные (неполные).
Часто на этапе формализации выясняется, что для различных частей общей задачи нужны различные ЭС.
2.4.4. ЭТАП ПРОГРАММНОЙ РЕАЛИЗАЦИИ
Цель этапа - создание одного или нескольких прототипов ЭС, решающих требуемые задачи. Затем на данном этапе, по результатам этапов тестирования и опытной эксплуатации, создается конечный продукт, пригодный для промышленного использования. Разработка прототипа состоит в программировании его компонентов или выборке их из имеющихся ЭС и пополнении БЗ.
Приобретение знаний необходимо начинать как только составлены или выбраны программы, позволяющие работать с простейшими управляющими структурами, а следовательно максимально рано следует начать выполнение отдельных подзадач и обнаружить необходимость дополнительных знаний для их решения. Иными словами, первый прототип экспертной системы - демонстрационный (ЭС - 1) должен появиться через несколько месяцев (обычно два - три), а не через годы после начала работы.
Разработка прототипа - важный шаг в создании ЭС. Некоторые программы прототипа могут войти в окончательную версию ЭС. Однако, главное, чтобы прототип обеспечил проверку адекватности идей, методов и способов представления, выбранных при создании данной ЭС, решаемым задачам. Создание первого прототипа должно подтвердить, что выбранные методы решений и способы представления пригодны для успешного решения, по крайней мере, ряда задач из области экспертизы, а также показать, что с увеличением объема знаний и улучшением стратегий поиска ЭС сможет дать высококачественные и эффективные решения всех задач данной проблемной области. Очевидно, что в первом прототипе реализуется (используется) простейшая процедура вывода.
После разработки первого прототипа необходимо расширить круг задач, решаемых системой, для того, чтобы собрать пожелания и замечания, которые будут учтены в очередной версии системы (ЭС-2). Для этого осуществляется развитие ЭС-1 путем добавления:
· "дружественного" интерфейса;
· средств для исследования как БЗ, так и цепочек выводов, генерируемых системой (что обеспечивает прозрачность и понимаемость системы разработчиком);
· средств для сбора замечаний пользователей;
· средств библиотеки задач, решенных системой.
Расширенная версия ЭС-1 может рассматриваться как исследовательский прототип ЭС.
Для достижения эффективного функционирования ЭС необходимо осуществить структурирование знаний. Наиболее важным средством для этого являются абстрактные понятия промежуточного уровня. При представлении правил в виде, понятном ЭС особое внимание следует уделять двум ситуациям: некоторое правило слишком громоздко; имеется много похожих правил. Громоздкость правила может объясняться тем, что в нем отражено несколько фактов из данной проблемной области. Если это так, то правило надо разбить на несколько более мелких. Вторая ситуация возникает тогда, когда в проблемной области существует понятие, явно не указанное экспертом, а возможно, и не имеющее имени. В этом случае новое понятие необходимо ввести в явном виде, присвоить ему специальное имя и, используя это понятие, сформулировать одно правило взамен группы подобных.
Выполнение экспериментов с расширенной версией ЭС-1, анализ пожеланий и замечаний служит отправной точкой для создания второго прототипа (ЭС-2). Процесс разработки ЭС-2 итеративный. Анализ результатов прогонов тестовых примеров позволяет выявить недостатки ЭС и разработать пути для их устранения. Этот итеративный процесс может продолжаться от нескольких месяцев до нескольких лет в зависимости от сложности проблемной области, гибкости выбранного представления и степени соответствия управляющего механизма решаемым задачам (возможно, потребуется разработка ЭС-3 и т.д.). При разработке ЭС-2, кроме перечисленных задач, решаются следующие:
· анализ функционирования системы при значительном расширении БЗ;
· исследование возможностей системы в решении более широкого круга задач и принятие мер для обеспечения таких возможностей;
· анализ мнения пользователя о недостатках системы, о том, какую дополнительную помощь он хочет получить от ЭС и т.п.;
· разработка системы ввода-вывода, осуществляющая анализ или синтез предложений ограниченного естественного языка, что позволяет пользователю взаимодействовать с ЭС-2 в форме, близкой к форме стандартных учебников для данной области.
2.4.5. ЭТАП ТЕСТИРОВАНИЯ И ОТЛАДКИ
Здесь осуществляется оценка выбранного способа представления знаний и ЭС в целом. Как только ЭС оказывается в состоянии обработать от начала до конца два или три примера, необходимо начинать проверку на более широком круге примеров, чтобы определить недостатки БЗ и управляющего механизма (процедур вывода). Инженер по знаниям должен подобрать примеры, обеспечивающие всестороннюю проверку ЭС.
Обычно выделяют следующие источники неудач в работе системы:
· тестовые примеры;
· ввод-вывод; правила вывода;
· управляющие стратегии.
Наиболее очевидной причиной неудачной работы ЭС являются недостаточно показательные тестовые примеры. В худшем случае тестовые примеры могут оказаться вообще вне проблемной области, на которую рассчитана ЭС, однако чаще множество тестовых примеров находится в рассматриваемой проблемной области, но является однородным и не позволяет охватить всю проблемную область.
Ввод-вывод можно характеризовать данными, приобретенными в ходе диалога с экспертом, и заключениями, предъявленными ЭС в ходе объяснений. Методы приобретения данных могут не давать нужных результатов, так как задавались неправильные вопросы или собрана не вся необходимая информация. Ошибки при вводе могут возникнуть из-за неудобного для пользователя входного языка. В ряде приложений для пользователей удобен ввод не только в печатной, но и в звуковой форме, может понадобиться ввод и в графическом виде.
Выходные сообщения (заключения) системы могут оказаться непонятны пользователю (эксперту) по содержанию, либо потому, что их слишком мало. Типичным источником ошибок в рассуждениях являются правила вывода. Важная причина здесь - неучтены зависимости между правилами (точнее, между их означиваниями). Дело в том, что правила редко независимы друг от друга, хотя на первом этапе отладки удобно считать их таковыми. Среди других причин ошибок можно отметить ошибочность, противоречивость и неполноту правил. Необходимо принять меры против порождения гипотез (промежуточных заключений), которые правдоподобны каждая в отдельности, но комбинируются в бессмысленные последовательности (комбинации). Требуется разработать специальные правила, препятствующие образованию ошибочных комбинаций.
Весьма часто к ошибкам в работе ЭС приводят управляющие стратегии. Возможно, изменение стратегии необходимо, если ЭС рассматривает сущности в порядке, отличном от "естественного" для эксперта. Последовательность, в которой данные рассматриваются ЭС, не только влияет на эффективность работы системы, но и может приводить к изменению конечного результата. Например, рассмотрение правила X до правила Y может иногда привести к тому, что правило Y всегда будет игнорироваться системой. Изменение стратегии необходимо и в случае неэффективной работы ЭС. Кроме того, недостатки в управляющих стратегиях могут привести к чрезмерно сложным заключениям и объяснениям ЭС.
2.4.6. ЭТАП ОПЫТНОЙ ЭКСПЛУАТАЦИИ
На данном этапе проверяется пригодность ЭС для конечного пользователя. Здесь ЭС занимается решением всех задач возможных при работе с различными пользователями. Пригодность ЭС для пользователя определяется в основном удобством работы с ней и ее полезностью. Под полезностью ЭС понимается способность ее в ходе диалога определять потребности пользователя, выявлять и устранять причины неудач в работе, а также удовлетворять потребности пользователя (т.е. решать поставленные задачи). Другими словами пользователю важно донести "до сознания" ЭС свою информационную потребность, несмотря на возможные ошибки, допускаемые им из-за недостаточного знания ЭС.
Под удобством работы ЭС понимается естественность взаимодействия с ней (общение в привычном, не утомляющем пользователя виде), гибкость ее (способность системы настраиваться на различных пользователей, а также учитывать изменения в квалификации одного и того же пользователя) и устойчивость системы к ошибкам (способность не выходить из строя при ошибочных действиях неопытного пользователя).
По результатам эксплуатации может потребоваться не только модификация программ и данных (совершенствование или изменение языка общения, диалоговых систем, средства обнаружения и исправления ошибок, настройка на пользователя и т.д.), но и изменения устройств ввода-вывода из-за их неприемлемости для пользователя. По результатам этого же этапа принимается решение о переносе системы на другие ЭВМ (например, для расширения сферы использования ЭС и (или) снижения ее стоимости).
С точки зрения назначения большинство ЭС создается для тиражирования знаний экспертов и ориентированы либо на специалистов, стремящихся повысить свои знания, либо на неспециалистов, чтобы оказать им помощь в решении сложных задач.
По характеристике "Проблемная область" ЭС обобщенно можно определить так: предметная область является статической (как правило, с неточными знаниями); решаемые задачи являются статическими (как правило, задачи расширения и реже задачи до определения). Приложения, реализуемые с помощью ЭС, различаются по количеству возможных решений, по сложности (структурированности) проблемной области, по методам решения задач, по типу используемых знаний.
С точки зрения глубины анализа проблемной области большинство существующих ЭС являются поверхностными, что обеспечивает их высокую эффективность. Однако для многих приложений необходимо создание глубинных ЭС, реализация которых требует существенных вычислительных ресурсов, что препятствует их широкому распространению. По типу используемых методов и знаний ЭС делятся на традиционные и гибридные. Большинство существующих ЭС традиционные. Тенденцией является создание гибридных ЭС путем выделения в неформализованной задаче формализуемых подзадач и реализации их методами традиционного программирования (т.е. в виде БД и ППП). Гибридизация ЭС значительно усложняет процесс управления системой, увеличивает количество неявно представленных знаний, что ухудшает ее объяснительные возможности и сужает номенклатуру используемых методов инженерии знаний. С точки зрения класса ЭС большинство существующих ЭС являются простыми (в США из общего числа продаваемых ЭС 90% простые).
На рис.2.11 представлена более удобная для восприятия (по сравнению с рис.2.9 ) схема стандартной технологии разработки ЭС.
Характерной особенностью подобной технологии являются многочисленные возвраты к любому этапу и пересмотр принятых там проектных решений, что достаточно удобно для быстрого создания небольших автономно функционирующих ЭС (концепция "быстрого прототипирования"), однако модель жизненного цикла (ЖЦ), соответствующая такой технологии, затруднена для промышленного использования из-за низкой эффективности разработки конкретной системы, она важнее для исследовательских целей и как ЭС-1.

Рис. 2.11. Стандартная технология разработки ЭС
Технология создания ЭС, может также включать три фазы: проектирование, реализацию и внедрение, а ЖЦ разработки состоит из шести этапов:
1. исследование выполнимости проекта;
2. разработка общей концепции ЭС;
3. разработка и тестирование серии прототипов;
4. разработка и испытание головного образца;
5. разработка и проверка расширенных версий системы;
6. привязка системы к реальной рабочей среде.
Сравнивая данные технологии между собой, можно заметить, что первые два этапа промышленной технологии соответствуют этапу идентификации, а следующие три этапа – этапам концептуализации, формализации и тестирования. Единственное отличие – наличие этапа привязки ЭС к реальной рабочей среде.
2.5. ФОРМЫ ПРЕДСТАВЛЕНИЯ ЗНАНИЙ В ЭС.
Экспертные системы представляют собой одно из направлений в области искусственного интеллекта. Эти системы используют большое количество знаний, передаваемых им специалистами, а с другой - способны вступать в диалог и объяснять свои собственные выводы. Это предполагает наличие эффективного управления большой по объему и хорошо структурированной базой знаний, строгое разграничение между различными уровнями знаний, наличие множества удобных представлений для правил, схем предикатов или прототипов и четко определенный процесс обмена информацией между различными источниками.
База знаний содержит знания в символьной форме. Точнее говоря, в нее могут входить также таблицы чисел, диапазоны значений величин и, где это требуется, некоторые вычислительные процедуры. Однако основное содержание БЗ - факты и эвристики.
В состав фактов БЗ входят описания объектов, их признаки и соответствующие числовые данные для области, в которой предполагается применять ЭС. Например, для систем управления технологическими процессами в состав фактических знаний могут быть включены описания конкретного предприятия или его части, характеристики отдельных компонентов, значения, получаемые от датчиков, состав запасов и т.д.
Эвристики, или правила, представляют собой пути вынесения суждений на основании фактов для решения конкретной проблемы. Эти знания базируются на прошлом опыте; эксперты постоянно пользуются ими, но часто держат их в тайне. Инженерию знаний можно охарактеризовать как некий процесс, в ходе которого информация "добывается и обогащается" создателями экспертных систем. Для систем управления технологическим процессом эти знания могут содержать такой набор правил: когда требуется профилактический ремонт завода или подсистемы; каким должен быть объем запасов, исходя из текущих цен; правила диагностики неисправностей и рекомендации по их устранению и др.
Ценность ЭС для коллективов специалистов, начиная от лабораторий и кончая целыми фирмами, проявляется в нескольких аспектах:
а) сбор, уточнение, кодирование и распространение экспертных знаний ("Эксперт под рукой");
б) решение проблем, сложность которых превышает человеческие возможности;
в) решение проблем, требующих объема знаний, которого один человек не в состоянии охватить;
г) решение проблем, для которых требуется экспертные знания из нескольких областей ("сплав" знаний);
д) сохранение наиболее уязвимой ценности коллектива - коллективной памяти;
е) обеспечение высокой конкурентоспособности за счет применения новой технологии.
Создание комплексных баз знаний открывает широкие возможности, которые обусловлены безошибочностью и тщательностью, присущими машине, и синтезом знаний нескольких экспертов. Если же БЗ объединяет информацию по нескольким дисциплинам, такой "сплав" знаний приобретает дополнительную ценность.
Типы знаний в ЭС.Выделим восемь основных типов знаний по следующим признакам:
1) Базовые элементы, объекты реального мира. Они связаны с непосредственным восприятием, не требуют обсуждения и добавляются к нашей базе фактов в том виде, в котором они получены.
2) Утверждения и определения. Они основаны на базовых элементах и заранее рассматриваются как достоверные.
3) Концепции. Они определяют собой перегруппировки или обобщения базовых объектов. Для построения каждой концепции используются свои приемы.
4) Отношения. Они выражают как элементарные свойства базовых элементов, так и отношения между концепциями. Кроме того, к свойствам отношений относятся их большее или меньшее правдоподобие, большая или меньшая связь с данной ситуацией. Еще раз отметим, что представление знаний в ЭС близко к моделям, используемым в БД. Таким путем построена реляционная (обобщенная) модель БД в некоторых ЭС. Пара понятий "свойство-значение" хорошо известна в семантических сетях; фреймы и скрипты являются не чем иным, как наиболее простыми бинарными отношениями. Некоторые ЭС в качестве базы фактов используют уже базы существующих данных.
5) Теоремы и правила перезаписи. Они являются частными случаем продукционных правил с вполне определенными свойствами. Теоремы не представляют никакой пользы без экспертных правил их использования. Явное присутствие теорем ЭС представляет главное отличие от систем управления классическими базами данных (СУБД), в которых они либо отсутствуют, либо программируются. Модификация или добавление новых теорем является весьма трудоемкой, хотя и необходимой процедурой, так как нужно обеспечить хорошее структурированное управление БД и оптимизировать получение ответов.
6) Алгоритмы решений. Они необходимы для выполнения определенных задач. Во всех случаях они связаны со знанием особого типа, поскольку определяемая ими последовательность действий оказывается оформленной в блок, в строго необходимом порядке в отличие от других типов знания, где элементы информации могут появляться и располагаться без связи друг с другом.
Очевидно, что очень трудно работать с длинными процедурами, состоящими из большого числа различных действий. Использование чистых алгоритмов ограничено очень частными случаями, большая часть которых имеет дело с обработкой числовой информации. ЭВМ должна рассматривать и неалгоритмические ситуации.
7) Стратегии и эвристика. Этот тип представляет врожденные или приобретенные правила поведения, которые позволяют в данной конкретной ситуации принять решение о необходимых действиях. Он использует информацию в порядке, обратном тому, в котором она была получена. Например, рассуждения типа: "Я знал, что это действие приводит к такому-то результату (информация типа в п.4), поэтому, если я хочу получить именно этот результат, я могу рассмотреть это действие''. Человек постоянно пользуется этим типом знаний при восприятии, формировании концепций, решении задач и формальных рассуждениях. Появление ЭС связано с необходимостью принятия в расчет именно этого фундаментального типа человеческих знаний.
8) Метазнание. Без сомнения оно присутствует на многих уровнях и представляет собой знание того, что известно и определяет значение коэффициента к этому знанию, важность элементарной информации по отношению ко всему множеству знаний. Кроме того, сюда же относятся вопросы организации каждого типа знаний и указаний, когда и как они могут быть использованы. Метазнание представляет собой любое знание о знании. Оно является фундаментальным понятием для систем, которые не только используют свою БЗ такой, как она есть, но и умеют на ее основе делать выводы, структурировать ее, абстрагировать, обобщать, а также решать, в каких случаях она может быть полезна.
Приведем краткий список наиболее распространенных методов представления знаний. Фундаментальное различие между ними состоит в простоте модификации знания. В таблице 2.1 они приведены в порядке от наиболее процедурного (наиболее застывшего, структурированного) до наиболее декларативного (наиболее открытого, свободного, неупорядоченного). Такая классификация является несколько грубой, но правильно отражает идею.
Таблица 2.1
Методы представления знаний
|
Процедурные “закрытые”
Декларативные “открытые”, “неупорядоченные”
 Мы поможем в написании ваших работ! |