Схема метода балансировки загрузки
Nbsp; Московский ордена Ленина, ордена Октябрьской Революции и ордена Трудового Красного Знамени государственный технический университет им. Н. Э. Баумана Отчет по лабораторной работе №3 на тему: «Исследование эффективности статической балансировки загрузки МВС с помощью имитационного моделирования» Вариант Студент Сибирёв К. Е. Группа РК6-102 Преподаватель Карпенко А.П. Москва 2010
Цель работы
Целью работы является изучение метода статической балансировки загрузки многопроцессорной вычислительной системы (МВС) на основе равномерной декомпозиции узлов расчетной сетки, как приближенного способа решения задачи оптимального отображения вычислительных процессов на архитектуру многопроцессорной ЭВМ, а также исследование эффективности указанного метода с помощью имитационного моделирования.
Постановка задачи
Пусть  - n-мерный вектор параметров задачи. Положим, что
- n-мерный вектор параметров задачи. Положим, что 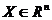 , где
, где  - n-мерное арифметическое пространство. Параллелепипедом допустимых значенийвектора параметров назовем не пустой параллелепипед
- n-мерное арифметическое пространство. Параллелепипедом допустимых значенийвектора параметров назовем не пустой параллелепипед  , где
, где  - заданные константы. На вектор X дополнительно наложено некоторое количество функциональных ограничений, формирующих множество
- заданные константы. На вектор X дополнительно наложено некоторое количество функциональных ограничений, формирующих множество  , где
, где  - непрерывные ограничивающие функции. На множестве
- непрерывные ограничивающие функции. На множестве  тем илииным способом (аналитически или алгоритмически) определена вектор-функция
тем илииным способом (аналитически или алгоритмически) определена вектор-функция  со значениями в пространстве
со значениями в пространстве  , где
, где 
 - размерность вектор-функции. Ставится задача поиска значения некоторого функционала
- размерность вектор-функции. Ставится задача поиска значения некоторого функционала  .
.
|
|
|
Положим, что приближенное решение поставленной задачи может быть найдено по следующей схеме.
Шаг 1.Покрываем параллелепипед П некоторой сеткой  (равномерной или неравномерной, детерминированной или случайной) с узлами
(равномерной или неравномерной, детерминированной или случайной) с узлами  .
.
Шаг 2. В тех узлах сетки , которые принадлежат множеству  ,вычисляем значения вектор функции
,вычисляем значения вектор функции  .
.
Шаг 3. На основе вычисленных значений вектор функции находим приближенное значение функционала .
В виде рассмотренной схемы можно представить, например, решение задачи вычисления многомерного определенного интеграла от функции в области .
Суммарное количество арифметических операций, необходимых для однократного определения принадлежности вектора X множеству (т.е. суммарную вычислительную сложность ограничений  и ограничивающих функций ), обозначим
и ограничивающих функций ), обозначим  . Вообще говоря, величина
. Вообще говоря, величина  зависит от вектора X.Мы, однако, пренебрежем этой зависимостью, и будем полагать, что имеет место равенство
зависит от вектора X.Мы, однако, пренебрежем этой зависимостью, и будем полагать, что имеет место равенство  . Заметим, что до начала вычислений величина
. Заметим, что до начала вычислений величина 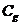 , как правило, неизвестна. Однако в процессе первого же определения принадлежности некоторого узла сетки множеству ,эту величину можно легко определить (с учетом предположения о независимости этой величины от вектора X).Поэтому будем полагать величину известной.
, как правило, неизвестна. Однако в процессе первого же определения принадлежности некоторого узла сетки множеству ,эту величину можно легко определить (с учетом предположения о независимости этой величины от вектора X).Поэтому будем полагать величину известной.
|
|
|
Неизвестную вычислительную сложность вектор-функции обозначим  . Подчеркнем зависимость величины
. Подчеркнем зависимость величины  от вектора X. Величина удовлетворяет, во-первых, очевидному ограничению
от вектора X. Величина удовлетворяет, во-первых, очевидному ограничению  . Во-вторых, положим, что известно ограничение сверху на эту величину
. Во-вторых, положим, что известно ограничение сверху на эту величину  , имеющее смысл ограничения на максимально допустимое время вычисления значения . Вычислительную сложность
, имеющее смысл ограничения на максимально допустимое время вычисления значения . Вычислительную сложность  назовем вычислительной сложностью узла
назовем вычислительной сложностью узла  ,
,  .
.
Вычислительную сложность генерации сетки положим равной  , а вычислительную сложность конечномерной аппроксимации функционала - равной
, а вычислительную сложность конечномерной аппроксимации функционала - равной  , где
, где  (дзета) - общее количество узлов сетки , принадлежащих множеству .Положим, что при данных
(дзета) - общее количество узлов сетки , принадлежащих множеству .Положим, что при данных  величины
величины  - известные константы.
- известные константы.
В качестве вычислительной системы рассмотрим однородную МВС с распределенной памятью, состоящую из процессоров  и host-процессора, имеющих следующие параметры:
и host-процессора, имеющих следующие параметры:
-  – время выполнения одной арифметической операции с плавающей запятой;
– время выполнения одной арифметической операции с плавающей запятой;
|
|
|
- 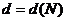 - диаметр коммуникационной сети;
- диаметр коммуникационной сети;
- l – длина вещественного числа в байтах;
-  – латентность коммуникационной сети;
– латентность коммуникационной сети;
-  – время передачи байта данных между двумя соседними процессорами системы без учета времени .
– время передачи байта данных между двумя соседними процессорами системы без учета времени .
В качестве меры эффективности параллельных вычислений используем ускорение
 ,
,
где  - время последовательного решения задачи на одном процессоре системы,
- время последовательного решения задачи на одном процессоре системы,
 - время параллельного решения той же задачи на N процессорах,
- время параллельного решения той же задачи на N процессорах,
Схема метода балансировки загрузки
Рассматривается статическая балансировка загрузки МВС на основе равномерной декомпозиции узлов расчетной сетки. Положим, что из числа  узлов расчетной сетки множеству принадлежит
узлов расчетной сетки множеству принадлежит  узлов
узлов  . Для простоты записи положим, что величина кратна количеству процессоров
. Для простоты записи положим, что величина кратна количеству процессоров  , так что
, так что  - целое число.
- целое число.
Идею рассматриваемого метода балансировки загрузки можно представить в следующем виде (рисунок 3.1):
- среди всех узлов сетки выделяем узлы ;
- разбиваем эти узлы на подмножеств  ,
,  , где подмножество
, где подмножество  содержит узлы
содержит узлы  , подмножество
, подмножество  - узлы
- узлы  и т.д.;
и т.д.;
- назначаем для обработки процессору  множество узлов , .
множество узлов , .

Схему параллельных вычислений при решении рассматриваемой задачи с использованием статического метода балансировки загрузки можно представить в следующем виде.
|
|
|
Шаг 1. Host-процессор выполняет следующие действия:
- строит сетку ;
- среди всех узлов сетки выделяет узлы ;
- разбивает эти узлы на множеств узлов , ;
- посылает каждому из процессоров  координаты соответствующего множества узлов .
координаты соответствующего множества узлов .
Шаг 2. Процессор выполняет следующие действия:
- принимает от host-процессора координаты  узлов множества ;
узлов множества ;
- вычисляет в каждом из этих узлов значение вектор-функции ;
- передает host-процессору вычисленных векторов и заканчивает вычисления.
Шаг 3. Host-процессор на основе полученных значений вектор-функции вычисляет приближенное значение функционала .
Экспериментальная часть
Рассмотрим двумерную задачу (  ). Параллелепипед
). Параллелепипед  в этом случае представляет собой прямоугольник
в этом случае представляет собой прямоугольник  . Положим, что
. Положим, что  ,
,  , так что область является единичным квадратом (рисунок 2.3).
, так что область является единичным квадратом (рисунок 2.3).
Множество  формируется с помощью одной ограничивающей функции
формируется с помощью одной ограничивающей функции  , т.е.
, т.е.  . Примем, что эта функция линейна и проходит через заданную преподавателем точку плоскости
. Примем, что эта функция линейна и проходит через заданную преподавателем точку плоскости  с координатами
с координатами  (рисунок 2.3). Таким образом, уравнение этой функции имеет вид
(рисунок 2.3). Таким образом, уравнение этой функции имеет вид  ,
,  (при этом, очевидно,
(при этом, очевидно,  ).
).

В качестве сетки используем равномерную детерминированную сетку с количеством узлов по осям  ,
,  равным 256, т.е. сетку с количеством узлов
равным 256, т.е. сетку с количеством узлов  .
.
Будем исходить из следующих значений параметров задачи и МВС:
-  ;
;
- l=8;
-  ;
;
-  ;
;
-  ;
;
-  .
.
GPSS-модель
* * * * * * * * * * * * * * * * * * * *
* Единица модельного времени mkc *
* Вычислительная сложность 1e7 *
* Время обработки 0 - 1e5 mks *
* * * * * * * * * * * * * * * * * * * *
* "Параллельная" модель *
* * * * * * * * * * * * * * * * * * * *
compute function rn1,c2 ;время вычисления F(X) для одного узла
0,0/1,100001
sp fvariable p5/p4 ;расчет коэффициента ускорения
tablesp table v$sp,42,0.5,30
initial x$disp,0
nodes variable 65536 ;узлы
z variable (v$nodes\v$proc)
proc variable 2
proc_par storage 2 ;число процессоров в "параллельной" модели
proc_posl storage 1 ;число процессоров в "посл" модели
generate ,,,1 ;транзакт-задача
assign 6,50
strt mark 2
split (v$proc-1) ; количество групп
assign 1,v$z ; количество узлов в группе
queue qhost1_par ;очередь на host-процессоре
seize host
depart qhost1_par
advance 5,3 ;обработка на host-процессоре
release host
queue qproc_par
enter proc_par ;обработка процессором
depart qproc_par
proc2 advance fn$compute ;цикл для обработки группы
loop 1,proc2 ;число итераций определено в 1-ом параметре транзакта
leave proc_par
queue qhost2_par ;заключительная обработка на host
seize host
depart qhost2_par
advance 5,3
release host
assemble v$proc ;объединение транзактов
assign 4,mp2 ;фиксация времени прохождения транзакта
* * * * * * * * * * * * * * * * * * * *
* "Последовательная" модель *
* * * * * * * * * * * * * * * * * * * *
mark 3
split (v$nodes-1) ;
queue qhost1_posl
seize host
depart qhost1_posl
advance 5,3
release host
queue qproc_posl
enter proc_posl ;обработка процессором
depart qproc_posl
advance fn$compute
leave proc_posl
queue qhost2
seize host
depart qhost2
advance 5,3
release host
assemble v$nodes
assign 5,mp3 ;фиксация времени прохождения транзакта tabulate tablesp ;расчет коэффициента ускорения
loop 6,strt ;цикл r
savevalue disp,(td$tablesp#td$tablesp)
terminate 1
start 1
Результаты эксперимента
a=
b=
 =
=
Количество «прогонов» модели  =1. Для заданных преподавателем величин ,
=1. Для заданных преподавателем величин ,  ,
,  вычислить с помощью разработанной GPSS-модели значения ускорения
вычислить с помощью разработанной GPSS-модели значения ускорения  для
для  .
.
| Cfmax\N | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | |
Таблица значений ускорения S

График зависимости S(N) для заданных 
Количество «прогонов» модели = 300. Для заданных преподавателем величин , , вычислить с помощью разработанной GPSS-модели оценки математического ожидания ускорения  и его дисперсии
и его дисперсии  для .
для .
| Cfmax\N | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | |
Таблица значений математического ожидания ускорения M[S]
| Cfmax\N | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | |
Таблица значений среднеквадратичного отклонения ускорения σ[S]


Графики зависимостей M[S(N)] и σ[S(N)] для заданных
Дата добавления: 2018-05-12; просмотров: 235; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!