IP как протокол без установления соединения
IP является протоколом без установления соединения, поскольку eгo главная задача – обеспечивать межсетевую адресацию и маршрутизацию, а также изменять размер пакетов, если он меняется при переходе от одной сети к другой (например, от Ethernet к FDDI). Задача обеспечения надежности коммуникаций передается от протокола IP к инкапсулированному TCP-сегменту (содержащему заголовок TCP и полезную нагрузку), который следует за заголовком IP и управляет потоком, выполняет упорядочение пакетов и другие проверки, а также подтверждает получение пакетов. Когда к TCP-сегменту добавляется заголовок IP, полученный блок данных называется датаграммой (datagram) или пакетом (рис. 6.4). Именно адресная информация заголовка IP позволяет проверять маршрут (например, при переадресации IP-пакета). Заголовок пакета IP (рис.6,5) содержит поля, описанные ниже.
• Версия (Version) – поле, содержащее номер версии IP. В настоящее время в большинстве сетей применяется протокол IP version 4 (IPv4), который появился в начале 1980-х годов, а также внедряется стандарт IP version 6 (IPv6), ориентированный на Интернет и задачи мультимедиа.

Рис. Инкапсуляция пакета TCP/IP.
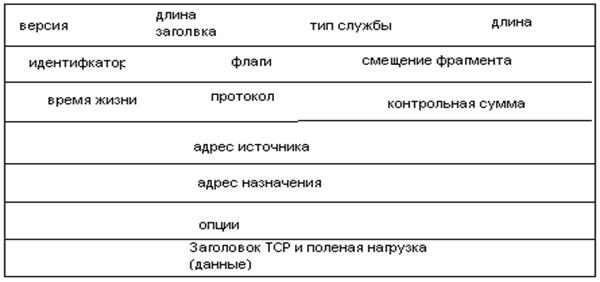
Рис.Пакет IP
Длина заголовка IP (IP Header Length, IHL) – указывает размер заголовка IP (минимум 20 байт).
Тип службы (Type of Service, TOS) – поле, указывающее старшинство или приоритет,
определенный для содержимого пакета.
Длина (Length) – полная длина пакета IP, которая может достигать 65 535 байтов.
Идентификатор (Identification). Для разнородных сетей протокол IP может преобразовывать размер пакета.
Флаги (Flags) – используются вместе с механизмом фрагментации для передачи служебной информации.
Смещение фрагмента (Fragment Offset) – содержит информацию, полагающую восстановить фрагменты, принадлежащие одной группе.
Время жизни (Time-to-Live, TTL) – информация, препятствующая зацикливанию пакета в сети (когда он непрерывно циркулирует внутри некоторой сети). Значение TTL устанавливается равным максимальному времени (в секундах), в течение которого пакет может передаваться.
Протокол (Protocol) – поле, указывающее на то, какой протокол (TCP или UDP)
инкапсулирован в IP.
Контрольная сумма (Checksum) – 16-разрядный циклический код с избыточностью (CRC), представляющий собой сумму значений всех полей заголовка IP. Эта контрольная сумма вычисляется так же, как и проверочная сумма для протокола TCP
Опции (Options) – некоторые опции, используемые протоколом IP. Например, может быть
указано время создания пакета, для ответственных (военных и правительственных) приложений может быть реализован специальный механизм защиты данных.
Заполнение (Padding) –. дополнение поля опций, когда данных недостаточно для того, чтобы общая длина заголовка IP (в битах) была кратна 32.
Билет 18.
1. Понятие ключа в базах данных, первичные и внешние ключи.
Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). Если кортежи идентифицируются только сцеплением значений нескольких атрибутов, то говорят, что отношение имеет составной ключ.
Отношение может содержать несколько ключей. Всегда один из ключей объявляется первичным, его значения не могут обновляться. Все остальные ключи отношения называются возможными ключами.
(Для каждого отношения, по крайней мере, полный набор его атрибутов является первичным ключом. Однако, при определении первичного ключа должно соблюдаться требование "минимальности", т.е. в него не должны входить те атрибуты, которые можно отбросить без ущерба для основного свойства первичного ключа - однозначно определять кортеж.)
Атрибуты, представляющие собой копии ключей других отношений, называются внешними ключами.
О первичных и внешних ключах
Напомним, что ключ или возможный ключ – это минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности. Минимальность означает, что исключение из набора любого атрибута не позволяет идентифицировать сущность по оставшимся. Каждая сущность обладает хотя бы одним возможным ключом. Один из них принимается за первичный ключ. При выборе первичного ключа следует отдавать предпочтение несоставным ключам или ключам, составленным из минимального числа атрибутов. Нецелесообразно также использовать ключи с длинными текстовыми значениями (предпочтительнее использовать целочисленные атрибуты). Не допускается, чтобы первичный ключ стержневой сущности (любой атрибут, участвующий в первичном ключе) принимал неопределенное значение. Иначе возникнет противоречивая ситуация: появится не обладающий индивидуальностью, и, следовательно не существующий экземпляр стержневой сущности. По тем же причинам необходимо обеспечить уникальность первичного ключа.
Теперь о внешних ключах:
· Если сущность С связывает сущности А и В, то она должна включать внешние ключи, соответствующие первичным ключам сущностей А и В.
· Если сущность В обозначает сущность А, то она должна включать внешний ключ, соответствующий первичному ключу сущности А.
2. Основные функциональные характеристики блоков КЭШ-памяти.
1. Объём. Достаточно мал, должен быть таким; достаточным для того что бы большинство обращений процессора приходилось на данные, которые уже имеются в КЭШ. В целом объём КЭШ связан со спецификацией приложений.
2. Метод отображений. Поскольку количество строк КЭШ много меньше строк ОП необходимо устранить соответствие между строками КЭШ и блоками строк ОП – такой способ называется: функцией отображения:
1. Прямой. За каждым блоком ОП закрепляется фиксированная строка КЭШ.

+ простота реализации в схеме управления блоком КЭШ памяти
- слишком частое обновление одних строк КЭШ по сравнению с другими
2. Ассоциативный. В этом случае тэгом являются все старшие разряды кода адреса. В результате присутствует жёсткая связь между блоком ОП и строкой КЭШ.

+ обеспечение гибкости при распределении данных между строками КЭШ
- применение более сложных алгоритмов
В КЭШ должен имеется резерв.
3. Секционно-ассоциативный. Комбинация двух первых.
+ простота реализации. Гибкость ассоциативного метода в этом случае вся КЭШ делится на секции, которые состоят из строк.
3. Алгоритм замены строк.
1. Заменяется строка к которой дольше всего не обращался процессор. LRU – least recently used
2. Заменяется строка записанная раньше остальных FIFO
3. Заменяется реже всего используемая строка. LFU – least frequently used
4. Случайный
4. Целостность информации
1. Сквозная запись – вся информация дублируется и в КЭШ и в ОП
2. Обратная запись – минимизируется количество к ОП и вся информация хранится в КЭШ
5. Размер блока
Используются блоки длинной от 2 до 8 слов, при этом ставятся в соответствие размер блока и эффективность КЭШ
6. Структурная организация блоков КЭШ
В настоящие время используются два и более уровней КЭШ памяти. На структурном уровне решаются задачи: 1. Количество уровней иерархии: L1 – внутр., L2 – внешн.
2. Разделение на КЭШ команд и КЭШ данных

Если имеется единый массив КЭШ, то достоинство упрощение схем контролеров КЭШ-памяти и высокая эффективность работы. В противоположном случае имеется суперскалярная архитектура, которая обеспечивает параллельное выполнение команд.
3. IP-адреса. Использование масок в IP-адресах.
Классы IP адресов:
A, B, C, D, E.
Если первый бит ip адреса подсети начинается с 0, то это класс А. если два первых бита равны 10, то это класс В и под адрес сети выделяется 15 бит и под адрес узла 16. если три первые бита 1 1 0, то это класс С. Здесь под адрес сети 21 бит, под адрес узла 8 бит. Если байт начинается 1 1 1 0, класс D. Остальные 28 битов образуют групповой адрес. Если в пакете стоит такой адрес, то этот пакет должен быть доставлен сразу нескольким узлам.
Основное назначение групповой адресации:
Распространение информации по модели: 1 источник – множество приемников. Для осуществления такой передачи используется протокол IGMP. Класс Е: начинается с комбинации 11110. адреса такого класса зарезервированы.
Содержимое первого байта IP адреса:
Класс А: 0 – 127, Класс В: 128 – 191, класс С: 192 – 223, класс D: 224 – 239, класс Е: 240 – 247.
Классы А, В и С предназначены для однонаправленной адресации, однако каждому классу соответствует свой размер сети. Класс А используется для самых крупных сетей, насчитывающих до 16 777 216 узлов. Класс В – это формат однонаправленной адресации для сетей среднего размера, содержащих до 65 536 узлов. Адреса класса С применяются в небольших сетях с однонаправленными коммуникациями и количеством хостов, не превышающем 254. Адреса класса D не связаны с размером сети, они предназначены лишь для групповых рассылок. Четыре байта адреса используются для указания группы адресов, которым предназначены широковещательные пакеты. Эта группа содержит узлы, являющиеся подписчиками таких пакетов. Адреса класса D выбираются из диапазона значений от 224.0.0.0 до 239.255.255.255. Пятый класс адресов, класс Е, используется для исследовательских задач и в первом байте содержит значения от 240 до 255.
Помимо классов, существуют некоторые IP-адреса специального назначения (например, адрес 255.255.255.255, который представляет собой широковещательный пакет, посылаемый всем узлам сети). Пакеты, имеющие в первом байте значение 127, используются для тестирования сети. Чтобы указать всю сеть, задается только идентификатор сети, а другие байты содержат нули.
Маска – это четырехбайтовое число, которое используется совместно с IP адресом и позволяет гибко устанавливать границы между адресом сети и адресом узла. В тех разрядах, которые соответствуют адресу сети содержится 1.
Роль маски подсети
Адреса TCP/IP требуют указания маски подсети, которая используется для Решения двух задач: для обозначения используемого класса адресов и для деления сети на подсети при управлении сетевым трафиком. Маска подсети позволяет прикладной программе определить, какая часть адреса является идентификатором сети, а какая соответствует идентификатору хоста. Например, Маска для сети класса А имеет единицы во всех разрядах первого байта и нули – в остальных байтах, т. е. 11111111.00000000.00000000.00000000 (255.0.0.0 в Десятичном представлении). В этом случае единицы указывают на разряды Идентификатора сети (подсети), а нули – на разряды идентификатора хоста.
Создание подсетей
При делении сети на подсети маска содержит идентификатор подсети, определенный администратором и расположенный в диапазоне значений идентификаторов сети и хоста. К примеру, третий байт в адресе класса может быть использован для определения идентификатора подсети, например, 11111111. 11111111. 11111111.00000000 (255.255.255.0). В другом случае для идентификации подсети могут быть задействованы только первые несколько разрядов третьего байта, а остальные три разряда (и последний байт целиком) могут определять идентификатор хоста, т. е. получится значение 11111111. 11111111. 11111000.00000000 (255.255.248.0). (Просмотр и настройка IP-адресов и масок подсетей рассматриваются в практических заданий с 6-1 по 6-4.) Нужно заметить, что применение маски подсети для деления сети на несколько мелких подсетей позволяет устройствам Класса 3 фактически игнорировать типовые характеристики классов адресов,
что создает дополни тельные возможности для сегментирования сетей с использованием
множества подсетей и дополнительных сетевых адресов. В этом случае можно преодолеть
ограничения 4-байтовой адресации. Игнорировать классы адресов можно также при помощи бесклассовой междоменной маршрутизации (Classless Interdomain Routing, CIDR), когда после десятичного представления адреса с разделительными точками указывается символ косой черты ("/"). CIDR-адресация обеспечивает, в сетях среднего размера дополнительные возможности IP-адресации 12 36 55., поскольку имеется нехватка адресов классов В и С. Эта нехватка объясняется увеличением количества сетей и конечным числом адресов, возможных при использовании базового механизма 4-байтовых адресов. CIDR-адресация позволяет обойти фиксированный размер идентификаторов сети (равный 8, 16 и 24 разрядам для сетей класса А, В и С соответственно) и задействовать неиспользуемые адреса. Рассмотрим для примера сеть класса С, в которой имеется только 100 узлов (идентификаторов хостов), но адресов в ней достаточно для идентификации 254 узлов. В этом случае теряется 154 возможных идентификатора хостов. При использовании CIDR-адресации число после косой черты представляет собой количество разрядов в адресе, выделяемых для обозначения идентификатора сети. Например, сеть должна иметь идентификаторы для 16 384 (214) хостов Чтобы определить количество разрядов, необходимых для идентификации сети, нужно вычесть 14 (количество разрядов для идентификаторов хостов) из 32 (общее количество разрядов в IP-адресе): 32 - 14 = 18. Таким образом 18 разрядов требуются для идентификатора сети и 14 – для идентификатора хоста (теперь маска подсети равна 11111111. 11111111. 11000000.00000000, т.е. 255.255.192.0). IP-адрес для нашего примера может иметь вид 165.100.18.44/18. Если вы хотите с помощью масок подсети разбить сетевой трафик по нескольким небольшим подсетям, заранее спланируйте размещение узлов по сегментам и выберите маски подсетей для этих сегментов. При этом следует
учесть перспективы развития сети на ближайшие несколько лет, чтобы при каждом изменении сети не нужно было заново переделывать ее сегменты. При плохом планировании и изменении конфигурации сегментов клиенты должны будут менять IP-адреса своих компьютеров, что создает дополнительные трудности в администрировании сети.
Билет 19.
1. Проектирование реляционных баз данных, основные понятия, оценки текущего проекта БД.
Проектированию подвергается структура таблицы и взаимосвязей между таблицами.
В настоящее время применяются 2 основных подхода:
Дата добавления: 2018-05-12; просмотров: 444; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!