Основная цель анализа временных рядов – прогнозирование поведения объекта.
Министерство образования и науки Российской Федерации
Федеральное государственное бюджетное образовательное учреждение
Высшего профессионального образования
«Тульский государственный университет»
Политехнический институт
Кафедра «Инструментальные и метрологические системы»
Сорокин Е.В. доцент, к.т.н.
КОНСПЕКТ ЛЕКЦИЙ
по дисциплине
Программные статистические комплексы
Для студентов, обучающихся по направлению
221700 «Стандартизация и метрология»
Профиль подготовки: «Метрология и метрологическое обеспечение»
Форма обучения:очная
Тула 2012 г.
Рассмотрено на заседании кафедры
протокол №___ от "___"____________ 20___ г.
Зав. кафедрой________________ О.И. Борискин
Содержание
Лекция №1 4
Лекция №2 9
Лекция №3 17
Лекция №4 22
Лекция №5 29
Лекция №6 41
|
|
|
Лекция №7 58
Лекция №8 69
Библиографический список 75
Лекция 1
1 Современные статистические комплексы: отечественные и зарубежные.
1.1 Введение.
Для успешного функционирования в условиях жесткой конкуренции многие фирмы, предприятия, банки, страховые компании и др. нуждаются в тщательном анализе имеющейся информации и получении из нее надежных и обоснованных выводов. Это создало потребность в статистической обработке данных, а как следствие – создание программ и целых комплексов для реализации на ЭВМ.
Число програмно-статистических комплексов очень велико, все они отличаются друг от друга.
Из отечественных статистических пакетов можно назвать:
1. STADIA;
2. ЭВРИСТА;
3. МЕЗОЗАВР;
4. САНИ;
5. КЛАСС-МАСТЕР;
6. СИГАМД;
и другие.
Из зарубежных пакетов следует отметить:
1. STATISTICA;
2. STATGRAPHICS;
3. SYSTAT;
4. BMDP;
|
|
|
5. SPSS;
6. SAS;
7. CSS
и другие.
Проблема выбора подходящего пакета для конкретной аудитории (пользователя) определяется кругом их возможностей.
Компьютерные системы для анализа данных - пакеты статистических программ - считаются наукоемкими программными продуктами, но, пожалуй, наиболее широко применяются в практической и исследовательской работе в самых разнообразных областях.
При впечатляющем разнообразии статистических программных продуктов, которым характеризуется современный мировой и отечественный рынок (по официальным данным Международного статистического института, число наименований СПП приближается к тысяче), крайне важно - как для производителя, так и для потребителя этой продукции - правильно ориентироваться в этом многообразии.
Сравнительный обзор пяти статистических пакетов в испанском издании журнала BYTE.
В испанском издании журнала BYTE опубликован сравнительный обзор пяти программных продуктов для статистической обработки данных: STATISTICA, SPSS, Minitab, Statgraphics и S-PLUS. Исследование включало в себя сравнительный анализ вычислительной точности, а также большой набор количественных показателей для различных аспектов функционирования программ. Cреди этих пяти статистических пакетов высочайшую оценку получила система STATISTICA.
|
|
|
| Суммарный рейтинг | |
| STATISTICA (release 5.1) | 25 |
| SPSS (release 7.5) | 22 |
| Minitab (release 12) | 18 |
| Statgraphics Plus (release 3) | 17 |
| S-PLUS (release 4) | 16 |
Из обзорной статьи: "Система STATISTICA выделяется своим превосходным интерфейсом и мощными функциональными возможностями. (…) Этот замечательный программный продукт дает возможность пользователю эффективно анализировать данные и представлять результаты в удобной форме. Система включает все процедуры анализа, предоставляемые другими пакетами, получившими более низкие оценки, но предлагает более эффективные и надежные реализации методов. (…) Среди всех проанализированных пакетов только STATISTICA может служить в качестве критерия для оценки точности вычислений. (…) Более того, при всех своих положительных качествах система STATISTICA предлагается по более низкой цене, чем некоторые из рассмотренных в данном обзоре программ."
1.2 Виды статистических комплексов
Существующая классификация статистических пакетов предлагает делить их на четыре группы:
· интегрированные методо-ориентированные пакеты общего назначения;
|
|
|
· специализированные методо-ориентированные пакеты;
· предметно- (или проблемно-) ориентированные пакеты;
· обучающие программы.
Специальные пакеты содержат методы из одного, двух разделов статистики или конкретной предметной области.
Пакеты общего назначения ориентированы на широкий диапазон статистических методов и широкий круг пользователей, чаще всего они имеют дружеский интерфейс, что привлекает к ним широкий круг пользователей, в том числе и не специалистов.
1.3 Возможности табличных процессоров и баз данных.
Вследствие большой популярности статистических методов обработки данных, их стали включать в различные табличные процессоры и базы данных, например EXCEL, LOTUS, QUATRO PRO, ACCESS, FOX PRO и т.д.
MS Excel. Самой часто упоминаемой (и используемой) в отечественных статьях является приложение MS Excel из пакета офисных программ компании Microsoft – MS Office. Причины этого кроются в широком распространении этого программного обеспечения, наличии русскоязычной версии, тесной интеграцией с MS Word и PowerPoint. Однако, MS Excel - это электронная таблица с достаточно мощными математическими возможностями, где некоторые статистические функции являются просто дополнительными встроенными формулами. Расчеты сделанные при ее помощи не признаются авторитетными специалистами. Также в MS Excel невозможно построить качественные научные графики. Безусловно, MS Excel хорошо подходит для накопления данных, промежуточного преобразования, предварительных статистических прикидок, для построения некоторых видов диаграмм. Однако окончательный статистический анализ необходимо делать в программах, которые специально созданы для этих целей. Существует макрос-дополнение XLSTAT-Pro (http://www.xlstat.com) для MS Excel который, включает в себя более 50 статистических функций, включая анализ выживаемости, которых в основных случаях достаточно для обычного применения. Пробную версию макроса можно взять на сайте производителя.
Использование таких статистических пакетов не целесообразно, так как они работают с упрощенным представлением статистической обработки.
Следует отметить, что в настоящее время имеет место тенденция использования статистической обработки данных в универсальных инженерных пакетах типа MATHCAD, MATHLAB, MAPLE и т.д.
Данные пакеты разрабатываются ведущими математическими школами и содержат большое количество статистических функций, вычисления по изданным в этих пакетах программам, сертифицированы и поставляются заказчику.
Лекция 2
1.4 Требования к статистическим комплексам общего назначения.
Общий подход оценки статистических пакетов является развитием методологии американской «Национальной лаборатории по тестированию программных продуктов». National Software Testing Laboratory (NSTL) — независимая (от разработчиков и продавцов программ) организация, проводящая регулярные экспертные оценки, а также рейтингование различных типов программных продуктов.
Приведем общую схему определения качества (рейтинга) программного продукта:
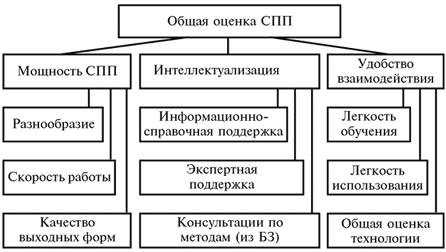
В приведенную схему, включен дополнительно (по сравнению с методологией NSTL) блок, который оценивает удобство работы пользователя- прикладника с тестируемым пакетом с позиций степени интеллектуализации данного пакета. Этот блок имеет большое значение, поскольку количество распространяемого на рынке статистического программного обеспечения явно обогнало численность специалистов-статистиков, особенно на отечественном рынке.
Работа по интеллектуализации СПП как раз и преследует цель минимизировать долю случаев подобного рода эксплуатации СПП, предоставив пользователю в автоматизированном режиме необходимую статистическую консультацию по правильной постановке задачи, выбору подходящего статистического инструментария, по умению обойти встречающиеся на пути статистического анализа типовые «ловушки», по правильной интерпретации результатов анализа и т.п.
1. разнообразия и степени продвинутости методов статистического анализа, а также средств управления данными;
2. скорости вычислений и выдачи результатов анализа;
3. качества выходных форм;
4. легкости использования;
5. легкости обучения;
6. общего уровня технологичности использования;
7. удобства и полноты общей справочной службы (касающейся используемой терминологии, методов, необходимой библиографии);
8. качества и полноты автоматизированных статистических консультаций «на входе» задачи, т.е. касающихся анализа генезиса анализируемых данных, выбора подходящих методов и моделей, подбора требуемой технологической цепочки обрабатывающих модулей СПП;
9. качества и полноты автоматизированных статистических консультаций в процессе проводящегося статистического анализа, т.е. касающихся типовых статистических «ловушек» и интерпретации промежуточных результатов;
10. качества и полноты автоматизированных статистических консультаций «на выходе» статистического анализа, т.е. касающихся интерпретации финальных статистических выводов, оценки их достоверности, возможных корректировок постановочной части.
Интегральная оценка качества и основанный на ней рейтинг получаются иерархически. А именно, детализированные характеристики, взятые с «весами», являются основой для построения оценок базовых качеств 1-10 того или иного СПП, те, в свою очередь, в виде взвешенной суммы дают оценку для каждого из трех обобщенных блочных показателей. Наконец, взвешенная сумма последних определяет общую оценку СПП.
Статистический пакет в идеале должен удовлетворять определенным требованиям:
· модульность;
· ассистирование при выборе способа обработки данных;
· использование простого проблемно-ориентированного языка для формулировки задания пользователя;
· автоматическая организация процесса обработки данных и связей с модулями пакета;
· ведение банка данных пользователя и составление отчета о результатах проделанного анализа;
· диалоговый режим работы пользователя с пакетом;
· совместимость с другим программным обеспечением.
1.5 Структура статистических комплексов общего назначения.
Следует заметить, что развитие СПП обычно идет поэтапно, на каждом из них создается вариант пакета, все в большей степени удовлетворяющий перечисленным выше требованиям. При этом если создание есть результат разработки, то на каждом этапе пакет, с одной стороны, должен представлять собой готовую к использованию программную продукцию, а с другой - входить составной частью в более поздние стадии развития пакета.
СПП в виде библиотеки модулей.
Первый уровень сложности системы - реализация пакета в виде библиотеки модулей. Под модулем СПП понимается внешняя процедура или программа на языке программирования высокого уровня, позволяющие кроме основных функций обрабатывать аварийные ситуации, имеющие стандартные интерфейсы связи по данным и передаче управления между модулями и использующие определенные операторы ввода-вывода.
Независимо от дальнейшего развития СПП организация библиотек обрабатывающих модулей в пакете остается одинаковой. Так, все библиотеки модулей (например, классификации, сокращения размерности, регрессии и т. д.) физически организованы в виде двух наборов данных - библиотеки исходных модулей и библиотеки загрузочных модулей. Первая библиотека содержит тексты модулей на языке программирования, а вторая - загрузочные модули, полученные в результате компиляции и редактирования соответствующих исходных модулей. Наличие библиотеки исходных модулей позволяет проводить модификацию и коррекцию модулей в процессе эксплуатации пакета.
При достаточной квалификации пользователя в области программирования работа с таким пакетом состоит в отборе подходящих модулей и в составлении самим пользователем головной программы на языке программирования, организующей вызов отобранных модулей в определенном порядке.
Набор тематически-ориентированных программ.
Следующий уровень сложности СПП - организация пакета в виде набора тематически-ориентированных программ (TOП), осуществляющих автоматизацию вычислительного процесса с помощью набора обрабатывающих модулей, относящихся к данной теме.
Такого типа пакеты представляют собой развитие принципов их организации, продемонстрированных в известном статистическом пакете BMDP. Существенное отличие заключается, однако, в том, что программы пакета BMDP предназначены для выполнения лишь одной какой-либо статистической процедуры (например, линейной регрессии, дискриминантного анализа). А каждый набор TOП является пакетом программ для решения некоторого подмножества задач прикладного статистического анализа.
В пакетах данного типа каждый TOП должен взаимодействовать с другими подобными программами по данным. Рассмотрим информацию, доступную TOП в рамках одного задания. Эта информация делится на три части: управляющую, обрабатываемую и терминологическую.
Управляющую информацию задает пользователь с помощью языка пакета, или ее получают в результате работы самой программы. Она содержит описание типа обрабатываемых данных, метода обработки, используемой модели, требования к настройке программы и др.
Обрабатываемая информация состоит в первую очередь из исходных и получаемых на выходе TOП данных (например, параметров регрессионных уравнений, правил классификации, моделей снижения размерности).
Терминологическая информация - это в простейшем случае словарь наименований переменных, групп, определений для качественных переменных, принятых в области исследований, для которой получена обрабатываемая информация. Использование этой информации позволяет провести настройку пакета, и в частности распечатку выходных данных в терминах области исследования. Терминологическая информация является одной из составных частей тезауруса содержательных понятий и общей для всех программ, участвующих в процессе обработки. Ее целесообразно хранить на внешних устройствах в виде отдельного набора, доступного для всех TOП.
Матрицы данных. Для большинства задач статистической обработки данных достаточно между программами, работающими в составе пакета, допустить обмен информацией в виде векторов, матриц данных и матриц бинарных отношений, а также управляющей информацией.
Для программ ввода-вывода и обрабатывающих модулей матрица данных всегда представляется в виде таблицы чисел. Если в матрице данных имелись неколичественные переменные и пропущенные значения, то они заменяются некоторыми числовыми кодами. Информация о видах переменных, о соответствии определений неколичественных переменных и пропущенных значениях хранится в специальных таблицах вместе с числовыми кодами.
Матрица данных может состоять из нескольких подматриц, которые в ряде случаев используются самостоятельно для статистического анализа.
Принадлежность объектов матрицы данных к самостоятельным частям (подматрицам) можно указать одним из следующих способов:
- с помощью последовательности матриц данных, так что каждой части соответствует своя матрица, организованная в виде отдельного набора данных;
- введением группирующей переменной, так что объекты с одинаковыми значениями группирующей переменной попадают в одну подматрицу; в качестве группирующей переменной можно использовать переменную, значения которой содержатся в матрице данных, либо некоторый вектор, образующий отдельный набор данных (подобно тому, как это делается в пакетах BMDP, SPSS);
- если объекты, входящие в каждую из подматриц, расположены последовательно, то принадлежность объектов к ним можно определить, задавая соответствующий набор целых чисел, каждое из которых определяет размер интересующей пользователя подматрицы. Такую организацию матрицы данных в пакете SPSS называют субфайловой.
Для ввода данных пользователя в пакете как минимум должны быть средства уничтожения и дополнения системных файлов по объектам и переменным, объединение системных файлов, внесение исправлений в данные и описатели структурных данных. По требованию пользователя должна выдаваться информация об имеющихся у него наборах данных. Разумеется, пользователь должен иметь возможность организовать и собственные наборы данных, хотя в этом случае управление данными усложняется и возрастает вероятность ошибок при формулировании задания на обработку.
Пакет с генерацией программ. Более совершенной организацией обладают пакеты с генерацией программ. На этом уровне развития сложности пакета в качестве отдельной структурной единицы выделяется "собирающая" программа, основной функцией которой является генерация обрабатывающих программ. Собирающая программа может быть выполнена в виде нескольких программ - транслятора с входного языка, планировщика и т. д. Такая программа управляет работой пакета, осуществляя связь с операционной системой, содержит задание на обработку, в котором определена последовательность использования модулей, необходимых для выполнения задания, организует связь между модулями по информации и управлению. Результатом работы собирающей программы является план вычислений на внутреннем языке пакета.
Входной язык пакета - проблемно-ориентированный неалгоритмический язык высокого уровня, позволяющий описывать манипуляции внешнего управления пакетом и данные пользователя, а также формулировать задания. Для обеспечения удобства изучения и применения в языке пакета выделяют две части: язык администратора и язык пользователя.
Язык администратора в основном служит для модификации и расширения пакета программ (включение новых модулей, изменение правил умолчания и т. д.).
К языку пользователя предъявляется ряд особых требований, связанных с тем, что он предназначен для пользователей, большей частью не являющихся профессиональными программистами. Основное из этих требований - удобство использования языка.
Лекция 3
1.6 Краткая характеристика современных статистических комплексов.
STADIA. Программа отечественной разработки с 16-и летней историей. Включает в себя все необходимые статистические функции. Она прекрасно справляется со своей задачей - статистическим анализом. Но. Программа внешне фактически не изменяется с 1996 года. Графики и диаграммы, построенные при помощи STADIA, выглядят в современных презентациях архаично. Цветовая гамма программы (красный шрифт на зеленом) очень утомляет в работе. К положительным качествам программы можно отнести русскоязычный интерфейс и наличие книг описывающих работу. Например: Кулаичев А.П. Методы и средства анализа данных в среде Windows. - М: ИнКо, 2002. - 341 с. Со страницы http://www.protein.bio.msu.su/~akula/index.htm можно взять демо-версию STADIA.
SPSS (Statistical Package for Social Science). Самый часто используемый пакет статистической обработки данных с более чем 30-и летней историей http://www.spss.com Отличается гибкостью, мощностью применим для всех видов статистических расчетов применяемых в биомедицине. Недавно вышла 13-я англоязычная версия. Существует русскоязычное представительство компании http://www.spss.ru которое предлагает полностью русифицированную версию SPSS 12.0.2 для Windows. Появился учебник на русском языке, позволяющий шаг за шагом освоить возможности SPSS, репетитор по статистике на русском языке, помогающий в выборе нужной статистической или графической процедуры для конкретных данных и задач, а также справка по SPSS Base и SPSS Tables. Российский офис SPSS регулярно проводит учебные курсы по анализу данных при помощи программного обеспечения SPSS. На русский язык переведена книга по SPSS, которая вышла в свет в 2002 году в Киевском издательстве «Диасофт» под названием «SPSS 10: искусство обработки информации. Анализ статистических данных и восстановление скрытых закономерностей».
STATA. Профессиональный статистический программный пакет с data-management system, который может применятся для биомедицинских целей. Один из самых популярных в образовательных и научных учреждениях США наряду с SPSS. Официальный сайт http://www.stata.com Программа хорошо документирована, издается специальный журнал для пользователей системы. Однако возможности предварительного ознакомления с демо-версией нет.
STATISTICA. Производителем программы является фирма StatSoft Inc. (США) http://www.statsoft.com которая выпускает статистические приложения, начиная с 1985 года. STATISTICA включает большое количество методов статистического анализа (более 250 встроенных функций) объединенных следующими специализированными статистическими модулями: Основные статистики и таблицы, Непараметрическая статистика, Дисперсионный анализ, Множественная регрессия, Нелинейное оценивание, Анализ временных рядов и прогнозирование, Кластерный анализ, Факторный анализ, Дискриминантный функциональный анализ, Анализ длительностей жизни, Каноническая корреляция, Многомерное шкалирование, Моделирование структурными уравнениями и др. Несложный в освоении этот статистический пакет может быть рекомендован для биомедицинских исследований любой сложности.
В настоящее время выпущена версия 7. Российское представительство компании (http://www.statsoft.ru/) предлагает полностью русифицированную 6-ю версию программы. Сайт компании содержит много информации по статистической обработке медицинских данных, учебник по статистике на русском языке. Сам пакет STATISTICA описан в нескольких книгах, одна из которых, для медицинских работников: О.Ю. Реброва «Статистический анализ медицинских данных. Применение пакета прикладных программ STATISTICA.» Москва, МедиаСфера, 2002. 312 с. Ознакомиться с содержанием книги можно по адресу: http://mediasphera.aha.ru/book/rebr_sod.htm
JMR. Один из мировых лидеров в анализе данных. Развивает этот статистический пакет SAS Institute http://www.jmp.com который выкупил в конце 2002 года известную статистическую программу StatView. Однако особых преимуществ для медико-биологической статистики этот программный продукт не имеет.
SYSTAT. Статистическая система для персональных компьютеров http://systat.com Последняя 11 версия обладает неплохим интуитивно понятным интерфейсом. Компания Systat Software также разрабатывает популярные у отечественных исследователей SigmaStat и SigmaPlot, которые являются соответственно, программой статистической обработки и программой построения диаграмм. При совместной работе становятся единым пакетом для статистической обработки и визуализации данных.
NCSS. Программа развивается с 1981 года и рассчитана на непрофессионалов в области статистической обработки. Интерфейс системы многооконный и как следствие этого явления - немного непривычный в использовании. Все действия пользователя сопровождаются подсказками. Сейчас доступна версия 2004 г. С сайта http://www.ncss.com можно переписать полнофункциональную пробную версию работающую 30 дней.
MINITAB 14. Статистический пакет MINITAB в настоящее время выпускается в версии 14. С сайта производителя http://www.minitab.com можно взять полнофункциональный пробный вариант программы, которая работает 30 дней. Это достаточно удобный в работе программный пакет, имеющий хороший интерфейс пользователя, хорошие возможности по визуализации результатов работы. Имеет подробную справку.
STATGRAPHICS PLUS. Довольно мощная статистическая программа. Содержит более 250 статистических функций, генерирует понятные, настраиваемые отчеты. Последняя доступная версия - 5.1. Ее можно получить на сайте http://www.statgraphics.com Есть возможность скачать демо-версию. Следует отметить, что ранние версии этой программы были весьма популярны у отечественных исследователей.
PRISM. Эта программа создавалась специально для биомедицинских целей. Интуитивно понятный интерфейс позволяет в считанные минуты проанализировать данные и построить качественные графики. Программа содержит основные часто применяемые статистические функции, которых в большинстве исследований будет достаточно. Однако, как отмечают сами разработчики, программа не может полностью заменить серьезных статистических пакетов. На сайте http://www.graphpad.com помимо возможности ознакомления с демо-версией Prism можно получить справочник в формате PDF по биомедицинской статистике.
Дополнительная информация. В настоящее время в Интернет доступны многие ресурсы, посвященные статистической обработке данных. Один из них - это статистический портал, созданный при содействии В. П. Боровикова, автора книг по программному пакету STATISTICA http://www.statsoft.ru/home/portal Российское представительство StatSoft Inc. предлагает на своем сайте бесплатный электронный учебник по статистике, который призван помочь разобраться с основными понятиями статистики и более полно представить диапазон применения статистических методов http://www.statsoft.ru/home/download/textbook/default.htm На этом же сайте существует «Статистический медицинский советник», который поможет правильно выбрать нужный статистический метод http://www.statsoft.ru/home/portal/applications/medicine/medadvisor.htm
На какой программе остановить свой выбор? Безусловно, дороговизна программ не позволяет их менять. Поэтому имеет смысл посмотреть демо-версии, разобраться с работой и потом делать окончательный вывод. Русскоязычные версии (с документацией) имеют только SPSS и STATISTICA.
Что касается возможных рекомендаций, то они следующие:
- Если нужен мощный, общепризнанный пакет с простым и понятным даже начинающим пользователям интерфейсом, то лучше воспользоваться SPSS.
- Для начинающих и профессионалов, которым нужна подсказка и развитая документация на русском языке, можно рекомендовать STATISTICA. Это мощное приложение с профессиональными возможностями.
- Для непритязательных пользователей, которые ограничиваются в своих исследованиях стандартными статистическими методами можно рекомендовать англоязычную программу Prism.
Лекция 4
2 Классы статистических задач, решаемые комплексами, их структура и алгоритмическое (теоретическое) обеспечение.
2.1 Классификация статистических задач.
Классификация решаемых комплексами задач является очень условной, как формальное выполнение анализа не возможно без проведения экспертных оценок, включающий в себя решение следующих задач обработки данных:
- интерпритация;
- диагностика;
- мониторинг;
- конструирование;
- проектирование;
- прогнозирование;
- управление и др.
2.2. Классы аналитических задач, решаемых комплексами, их основные цели.
Пакеты общего назначения ориентированы на широкий диапазон статистических методов и широкий круг пользователей, чаще всего включают в себя библиотеки, модули и программы, решающие следующие классы задач.
Отправляясь от общего спектра задач, решаемых с помощью математико-статистического инструментария, подразделим все содержимое функционального наполнения на отдельные библиотеки модулей. Каждая из описанных ниже библиотек является, по существу, своеобразной расшифровкой соответствующей детализированной характеристики статистического пакета.
Библиотека 1: вспомогательные программы.
Эта библиотека состоит из трех разделов:
Раздел 1.1 — методы матричной алгебры, включает в себя модули, реализующие методы решения систем линейных уравнений и вычисления собственных чисел и собственных векторов в обобщенной постановке задачи. В разделе должны быть предусмотрены процедуры простого и псевдообращения матриц, процедуры диагонализации, метод Ньютона, «релаксационные» алгоритмы Гаусса-Зейделя и Якоби и т.д.
Раздел 1.2 — оптимизационные алгоритмы, должен обеспечивать статистические модули необходимыми методами и алгоритмами поиска экстремума различных версий функционалов вида определяющих критерии качества статистического метода (метод наименьших квадратов и т.п.). К числу наиболее распространенных в статистической технике оптимизационных алгоритмов следует отнести методы «покоординатного спуска», метод сопряженных градиентов, различные модификации метода Гаусса-Ньютона (например, метод Хартли, метод Марквардта, некоторые версии случайного поиска и метода стохастической аппроксимации, метод ветвей и границ). Все большее распространение получают вычислительные процедуры, основанные на нейросетях и генетических алгоритмах.
Раздел 1.3 — статистическое моделирование на ЭВМ, включает в себя модули, реализующие процесс машинного генерирования одномерных и многомерных наблюдений, «извлеченных» их генеральных совокупностей заданного типа. Наличие модулей, генерирующих случайные векторы и числа, подчиненные заданному закону распределения, является хорошим подспорьем в анализе важных свойств статистических оценок, критериев, алгоритмов, не поддающихся теоретико- аналитическому исследованию (что особенно актуально в многомерном статистическом анализе). Эти же модули являются полезными составными элементами так называемой «бутстреп- технологии», а также - машинных имитационных экспериментов, используемых при анализе сложных реальных систем.
Библиотека 2: описательная статистика и разведочный анализ исходных данных.
Содержание библиотеки определяется основными задачами первичной статистической обработки данных. В частности, библиотека содержит модули следующего назначения:
2.1. анализ смешанной природы многомерного признака и унификация записи исходных данных.
2.2. Анализ резко выделяющихся наблюдений.
2.3. Восстановление пропущенных («стертых») наблюдений.
2.4. Проверка статистической независимости наблюдений.
2.5. Определение основных числовых характеристик и частотная обработка исходных данных (построение гистограмм, полигонов частот, вычисление выборочных средних, дисперсий и т.д.).
2.6. Критерии однородности (средних, дисперсий, законов распределения, непараметрические или нескольких выборок).
2.7. Критерии согласия ( хи-квадрат, Колмогорова и др.).
2.8. Статистическое оценивание параметров.
2.9. Вычисление наиболее распространенных модельных законов распределения вероятностей (биномиального, геометрического, Пуассона, нормального, лог-нормального, хи-квадрат, Стьюдента, Фишера, бэта-, гамма-экспоненциального, Релея, Вейбулла, Максвелла, равномерного и некоторых других).
2.10. Визуализация анализируемых многомерных статистических данных и анализ их генезиса.
Библиотека 3: статистическое исследование зависимостей.
Она тематически распадается на 6 разделов.
Раздел 3.1 — корреляционно-регрессионный анализ. Помимо модулей, реализующих более или менее традиционные методы корреляционного и регрессионного анализов, целесообразна реализация методов робастной (robust), гребневой (ridge) регрессий, итерационных методов оценивания неизвестных параметров в моделях конфлюентного анализа, а также методов, использующих кусочно-линейную аппроксимацию и «сплайновую» технику.
Раздел 3.2. — дисперсионный и ковариационный анализ.
Раздел 3.3 — системы одновременных структурных эконометрических уравнений.
Раздел 3.4 — планирование регрессионных экспериментов и выборочных обследований.
Раздел 3.5 — анализ временных рядов, содержит модули, реализующие алгоритмы решения следующих задач:
3.5.1. Предварительный (описательный) анализ временных рядов: вычисление оценок среднего, дисперсии, авто- и взаимно ковариационных функций и т.п.
3.5.2. Выявление тренда (сглаживание) временного ряда (методы скользящего суммирования, экспоненциальное сглаживание, метод переменных разностей, модифицированный метод наименьших квадратов и др.).
3.5.3. Выявление скрытых периодичностей, спектральный анализ временного ряда.
3.5.4. Анализ случайных остатков временного ряда.
3.5.5. Различные модели временных рядов и задача прогноза (экстрапо-ляции): модели авторегрессии, смешанные регрессионно-авторегрессионные модели, модели Бокса-Дженкинса, общая модель типа ARIMA, многомерный прогноз по Винеру, прогноз многомерных временных рядов по динамическим темпам и коррелированным остаткам, модели распределенных лагов, использование фильтров и переходных функций, ARCH-модели и модели коинтеграции.
3.5.6. Некоторые специальные алгоритмы обработки временных рядов: быстрое преобразование Фурье, разложение временного ряда по системе функций Уолша, вычисление свертки двух многомерных временных рядов, задача «о разладке».
3.5.7. Проверка статистических гипотез: о стационарности ряда, о независимости его членов, об адекватности «подгоняемой» модели и др.
Раздел 3.6 — анализ зависимостей марковского типа.
Библиотека 4: классификация и снижение размерности.
Это следующая (после библиотеки 3) по объему библиотека пакета. Она распадается (тематически) на 5 разделов.
Раздел 4.1 — дискриминантный анализ. Модули этого раздела реализуют алгоритмы решения следующих задач:
· задачи построения линейных дискриминантных функций Фишера при различении двух или нескольких классов;
· задачи пошагового дискрименантного анализа с последовательным отбором наиболее информативных показателей и с учетом эффектов, связанных с ограниченностью объема обучающих выборок;
· задачи построения непараметрических процедур классификации — модифицированного алгоритма k ближайших соседей Фикс–Ходжеса и алгоритма классификации, основанного на парзеновской оценке плотности;
· задачи разделения на классы в схеме нелинейного дискриминантного анализа.
Раздел 4.2 — статистический анализ смесей распределений. Помимо трудоемких итерационных алгоритмов вычисления статистических оценок неизвестных параметров смеси, эти модули реализуют процедуры статистической проверки гипотез о числе компонент смеси, о многомерной нормальности исследуемой совокупности, позволяют производить поиск унимодальных составляющих парзеновской оценки плотности.
Раздел 4.3 — кластер-анализ (таксономия). Модули этого раздела реализуют алгоритмы решения задач, связанных с оптимизацией тех или иных критериев качества классификации при четких и нечетких кластерах, а также класс так называемых иерархических процедур. Принцип работы иерархических процедур состоит в последовательном объединении (разделении) групп объектов, сначала самых близких (далеких), а затем все более отдаленных друг от друга (близких друг к другу).
Раздел 4.4 — снижение размерности в соответствии с критерием автоинформативности (без обучения). Раздел содержит программную реализацию различных вариантов метода главных компонент (линейных, нелинейных; при использовании количественных и неколичественных переменных), методов факторного анализа, методов экстремальной группировки признаков, методов многомерного шкалирования.
Раздел 4.5 — снижение размерности в соответствии с критерием внешней информативности (при наличии обучения). Раздел обслуживает проблематику отбора наиболее информативных показателей в задачах классификации (с обучением), регрессионного анализа и анализа экспертных оценок.
Библиотека 5: некоторые специальные методы статистического анализа нечисловой информации и экспертных оценок.
Целесообразность выделения отдельной библиотеки по данному разделу объясняется спецификой и весьма интенсивным развитием математических моделей экспертного оценивания, которые подчас апеллируют к исходным данным нечисловой природы, а также к методам и понятиям, не укладывающимся в рамки традиционных схем (например, к так называемым нечетким множествам).
Среди используемого здесь математико-статистического инструментария анализ таблиц сопряженности, лог-линейные модели, субъективные вероятности логит- и пробит-анализ, ранговые методы и т.п.
Библиотека 6: планирование эксперимента и выборочных обследований.
Данный класс функций рассмотрим более подробно в других лекциях.
Помимо перечисленных шести библиотек, объединяющих так называемые обрабатывающие модули, в пакет входит ряд организационно-технологических модулей и программ: организующая программа («программа-администратор»), сервисная программа, библиотека паспортов модулей, таблица семантической модели.
Лекция 5
2.3 Методы статистического анализа, их структура и алгоритмическое обеспечение.
Разведочный анализ данных (РАД; Exploratory data analysis) (впервые термин «разведочный анализ данных» был введен Дж. Тьюки в 1962 г.) употребляется, когда, с одной стороны, у исследователя имеется таблица многомерных данных, а с другой стороны, априорная информация о физическом (причинном) механизме генерации этих данных отсутствует или неполна. В этой ситуации РАД может оказать помощь в компактном и понятном исследователю описании структуры данных (например, в форме визуального представления этой структуры), отталкиваясь от которого он уже может «прицельно» поставить вопрос о более детальном исследовании данных с помощью того или иного раздела статистического анализа, обоснования полученной структуры данных с помощью аппарата проверки статистических гипотез, а также, возможно, сделать некоторые заключения и о причинной модели данных.
Этот этап называется «подтверждающим анализом данных» (confirmatory data analysis). Иногда выявление структуры данных с помощью РАД может оказаться и завершающим этапом анализа. С другой стороны, ряд методов РАД можно рассматривать и как методы подготовки данных для последующей статистической обработки без какого-либо изучения структуры данных, которое предполагается осуществить на последующих этапах. В этом случае этап РАД играет роль некоторого этапа перекодировки и преобразования данных (путем, например, сокращения размерности) в удобную для последующего анализа форму.
В любом случае, с какой бы целью ни применялись методы РАД, основная задача - переход к компактному описанию данных при возможно более полном сохранении существенных аспектов информации, содержащихся в исходных данных. Важно также, чтобы описание было понятным для пользователя.
Факторный анализ. Число параметров реально наблюдаемых объектов может быть велико, кроме того, велико и само количество объектов. Если оставить всё как есть, то можно погрязнуть в море многомерных данных и с ними невозможно будет работать.
Задача состоит в том, чтобы представить z(j) в виде комбинации небольшого числа скрытых общих факторов, т.е. в виде
Z(j) = a(j,1)*F(1) + a(j,2)*F(2) + ... + a(j,m)*F(m) + d(j)*U(j), (*)
j = 1, 2, ...,n ,
m<<n.
Отметим, что в правой части (*) стоит комбинация факторов специального вида. В математике такие комбинации называются линейными.
В представлении (*)F(k), k = 1, ..., m называются факторами или, точнее, общими факторвми (common factores), так как они являются общими для всех признаков z(j), j = 1, 2, ...,n, а не для какого – то признака или группы признаков.
d(j)*U(j) называется остатком (невязкой) или остаточным специфичным фактором.
Обычно в моделях факторного анализа предполагаются выполненными следующие предположения:
- общие факторы F(k), k = 1, ..., m являются либо некоррелированными случайными величинами с дисперсией 1, либо неизвестными неслучайными параметрами.
- остатки (остаточные факторы) U(j), j = 1, 2, ...,n имеют нормальное распределение, некоррелированны между собой и не зависят от общих факторов.
- в представлении(*)a(j,m) – неизвестные коэффициенты. Они имеют специальное название – это факторные нагрузки.
Главными целями факторного анализа являются: (1) сокращение числа переменных (редукция данных) и (2) определение структуры взаимосвязей между переменными, т.е. классификация переменных. Поэтому факторный анализ используется или как метод сокращения данных или как метод классификации.
Дискрименантный анализ.
Дискриминантный анализ используется для принятия решения о том, какие переменные различают (дискриминируют) две или более возникающие совокупности (группы). Например, некий исследователь в области образования может захотеть исследовать, какие переменные относят выпускника средней школы к одной из трех категорий: (1) поступающий в колледж, (2) поступающий в профессиональную школу или (3) отказывающийся от дальнейшего образования или профессиональной подготовки. Для этой цели исследователь может собрать данные о различных переменных, связанных с учащимися школы. После выпуска большинство учащихся естественно должно попасть в одну из названных категорий. Затем можно использовать Дискриминантный анализ для определения того, какие переменные дают наилучшее предсказание выбора учащимися дальнейшего пути.
Медик может регистрировать различные переменные, относящиеся к состоянию больного, чтобы выяснить, какие переменные лучше предсказывают, что пациент, вероятно, выздоровел полностью (группа 1), частично (группа 2) или совсем не выздоровел (группа 3). Биолог может записать различные характеристики сходных типов (групп) цветов, чтобы затем провести анализ дискриминантной функции, наилучшим образом разделяющей типы или группы.
С вычислительной точки зрения дискриминантный анализ очень похож на дисперсионный анализ. Рассмотрим следующий простой пример. Предположим, что мы измеряем рост в случайной выборке из 50 мужчин и 50 женщин. Женщины в среднем не так высоки, как мужчины, и эта разница должна найти отражение для каждой группы средних (для переменной Рост). Поэтому переменная Рост позволяет вам провести дискриминацию между мужчинами и женщинами лучше, чем, например, вероятность, выраженная следующими словами: "Если человек большой, то это, скорее всего, мужчина, а если маленький, то это вероятно женщина".
В завершение заметим, что основная идея дискриминантного анализа заключается в том, чтобы определить, отличаются ли совокупности по среднему какой-либо переменной (или линейной комбинации переменных), и затем использовать эту переменную, чтобы предсказать для новых членов их принадлежность к той или иной группе.
Дисперсионный анализ.Поставленная таким образом задача о дискриминантной функции может быть перефразирована как задача одновходового дисперсионного анализа (ANOVA). Можно спросить, в частности, являются ли две или более совокупности значимо отличающимися одна от другой по среднему значению какой-либо конкретной переменной. Однако должно быть ясно, что если среднее значение определенной переменной значимо различно для двух совокупностей, то вы можете сказать, что переменная разделяет данные совокупности.
В случае одной переменной окончательный критерий значимости того, разделяет переменная две совокупности или нет, дает F-критерий. F статистика по существу вычисляется, как отношение межгрупповой дисперсии к объединенной внутригрупповой дисперсии. Если межгрупповая дисперсия оказывается существенно больше, тогда это должно означать различие между средними.
Многомерные переменные.При применении дискриминантного анализа обычно имеются несколько переменных, и задача состоит в том, чтобы установить, какие из переменных вносят свой вклад в дискриминацию между совокупностями. В этом случае вы имеете матрицу общих дисперсий и ковариаций, а также матрицы внутригрупповых дисперсий и ковариаций. Вы можете сравнить эти две матрицы с помощью многомерного F-критерия для того, чтобы определить, имеются ли значимые различия между группами (с точки зрения всех переменных). Эта процедура идентична процедуре многомерного дисперсионного анализа(MANOVA). Так же как в MANOVA, вначале можно выполнить многомерный критерий, и затем, в случае статистической значимости, посмотреть, какие из переменных имеют значимо различные средние для каждой из совокупностей. Поэтому, несмотря на то, что вычисления для нескольких переменных более сложны, применимо основное правило, заключающееся в том, что если вы производите дискриминацию между совокупностями, то должно быть заметно различие между средними.
В практике математических исследований очень часто имеющиеся данные нельзя считать выборкой из многомерной нормальной совокупности, например, когда одна из рассматриваемых переменных не является случайной или когда линия регрессии явно не прямая и т.п. В этих случаях пытаются определить кривую (поверхность), которая дает наилучшее (в смысле метода наименьших квадратов) приближение к исходным данным. Соответствующие методы приближения получили название регрессионного анализа.
Регрессионный анализ. Задачами регрессионного анализа являются установление формы зависимости между переменными, оценка функции регрессии, оценка неизвестных значений (прогноз значений) зависимой переменной.
Функция f(x2, x3, …, xт), описывающая зависимость показателя от параметров, называется уравнением (функцией) регрессии. Термин "регрессия" (regression (лат.) – отступление, возврат к чему-либо) связан со спецификой одной из конкретных задач, решенных на стадии становления метода. Его ввел английский статистик Ф. Гальтон. Он исследовал влияние роста родителей и более отдаленных предков на рост детей. По его модели рост ребенка определяется наполовину родителями, на четверть – дедом с бабкой, на одну восьмую прадедом и прабабкой и т.д. Другими словами, такая модель характеризует движение назад по генеалогическому дереву. Ф. Гальтон назвал это явление регрессией как противоположное движению вперед – прогрессу. В настоящее время термин "регрессия" применяется в более широком плане – для описания любой статистической связи между случайными величинами.
Решение задачи регрессионного анализа целесообразно разбить на несколько этапов:
· предварительная обработка данных;
· выбор вида уравнений регрессии;
· вычисление коэффициентов уравнения регрессии;
· проверка адекватности построенной функции результатам наблюдений.
Предварительная обработка включает стандартизацию данных, расчет коэффициентов корреляции, проверку их значимости и исключение из рассмотрения незначимых параметров.
Проверка значимости уравнения регрессии производится на основе дисперсионного анализа. Здесь же он применяется как вспомогательное средство для изучения качества регрессионной модели. Согласно основной идее дисперсионного анализа.
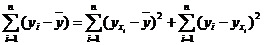 (1)
(1)
или Q=QR+Qe, (2)
где Q - общая сумма квадратов отклонений зависимой переменной от средней, a QR и Qe - соответственно сумма квадратов, обусловленная регрессией, и остаточная сумма квадратов, характеризующая влияние неучтенных факторов.
Убедимся в том, что пропущенное в (2) третье слагаемое 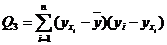 равно нулю. Учитывая (2) и первое уравнение системы, имеем:
равно нулю. Учитывая (2) и первое уравнение системы, имеем:
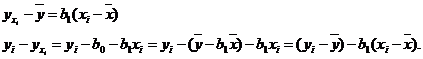
Теперь
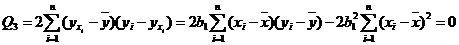
Схема дисперсионного анализа имеет вид, представленный в таблице.
| Компоненты дисперсии | Сумма квадратов | Число степеней свободы | Средние квадраты |
| Регрессия | 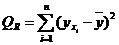
| 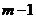
| 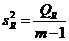
|
| Остаточная | 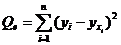
| 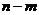
| 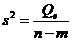
|
| Общая | 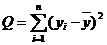
| 
|
Средние квадраты 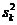 и
и 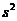 (табл. 1) представляют собой несмещенные оценки дисперсий зависимой переменной, обусловленной соответственно регрессией или объясняющей (ими) переменной(ыми) X и воздействием неучтенных случайных факторов и ошибок; т - число оцениваемых параметров уравнения регрессии; п - число наблюдений.
(табл. 1) представляют собой несмещенные оценки дисперсий зависимой переменной, обусловленной соответственно регрессией или объясняющей (ими) переменной(ыми) X и воздействием неучтенных случайных факторов и ошибок; т - число оцениваемых параметров уравнения регрессии; п - число наблюдений.
При отсутствии линейной зависимости между зависимой и объясняющей(ими) переменной(ыми) случайные величины
и имеют 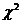 -распределение соответственно c и степенями свободы, а их отношение - F-распределение с теми же степенями свободы. Поэтому уравнение регрессии значимо на уровне α, если фактически наблюдаемое значение статистики
-распределение соответственно c и степенями свободы, а их отношение - F-распределение с теми же степенями свободы. Поэтому уравнение регрессии значимо на уровне α, если фактически наблюдаемое значение статистики
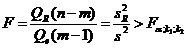 (3)
(3)
где 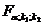 - табличное значение F -критерия Фишера–Снедекора, определенное на уровне значимости α при k1 = m–1 и k2= n–m степенях свободы.
- табличное значение F -критерия Фишера–Снедекора, определенное на уровне значимости α при k1 = m–1 и k2= n–m степенях свободы.
Кластерный анализ – это метод анализа, позволяющий разделить множество объектов на взаимно непересекающиеся подмножества относительно однородных объектов.
Термин кластерный анализ (впервые ввел Tryon, 1939) в действительности включает в себя набор различных алгоритмов классификации. Общий вопрос, задаваемый исследователями во многих областях, состоит в том, как организовать наблюдаемые данные в наглядные структуры, т.е. развернуть таксономии. Например, биологи ставят цель разбить животных на различные виды, чтобы содержательно описать различия между ними. В соответствии с современной системой, принятой в биологии, человек принадлежит к приматам, млекопитающим, амниотам, позвоночным и животным. Заметьте, что в этой классификации, чем выше уровень агрегации, тем меньше сходства между членами в соответствующем классе.
Объединение или метод древовидной кластеризации используется при формировании кластеров несходства или расстояния между объектами. Эти расстояния могут определяться в одномерном или многомерном пространстве. Наиболее прямой путь вычисления расстояний между объектами в многомерном пространстве состоит в вычислении евклидовых расстояний. Если вы имеете двух- или трёхмерное пространство, то эта мера является реальным геометрическим расстоянием между объектами в пространстве (как будто расстояния между объектами измерены рулеткой). Однако алгоритм объединения не "заботится" о том, являются ли "предоставленные" для этого расстояния настоящими или некоторыми другими производными мерами расстояния, что более значимо для исследователя; и задачей исследователей является подобрать правильный метод для специфических применений.
1. Евклидово расстояние.Это наиболее общий тип расстояния. Оно попросту является геометрическим расстоянием в многомерном пространстве и вычисляется следующим образом:
расстояние 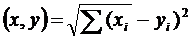
2. Расстояние городских кварталов (манхэттенское расстояние).Это расстояние является просто средним разностей по координатам. В большинстве случаев эта мера расстояния приводит к таким же результатам, как и для обычного расстояния Евклида. Однако отметим, что для этой меры влияние отдельных больших разностей (выбросов) уменьшается (так как они не возводятся в квадрат). Манхэттенское расстояние вычисляется по формуле:
расстояние (х,у) = Σi |хi - уi|
3. Расстояние Чебышева.Это расстояние может оказаться полезным, когда желают определить два объекта как "различные", если они различаются по какой-либо одной координате (каким-либо одним измерением). Расстояние Чебышева вычисляется по формуле:
расстояние (х,у) = максимум |хi - уi|
4. Степенное расстояние.Иногда желают прогрессивно увеличить или уменьшить вес, относящийся к размерности, для которой соответствующие объекты сильно отличаются. Это может быть достигнуто с использованием степенного расстояния. Степенное расстояние вычисляется по формуле:
расстояние (х,у) = (Σi |хi - уi|р)1/r
где r и p - параметры, определяемые исследователем.
Несколько примеров вычислений могут показать, как «работает» эта мера. Параметр p ответственен за постепенное взвешивание разностей по отдельным координатам, параметр r ответственен за прогрессивное взвешивание больших расстояний между объектами. Если оба параметра - r и p, равны двум, то это расстояние совпадает с расстоянием Евклида.
5. Процент несогласия (% различий в векторах).Эта мера используется в тех случаях, когда данные являются категориальными. Это расстояние вычисляется по формуле:
расстояние(x,y) = (Количество xi 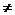 yi)/ n
yi)/ n
Анализ временных рядов. В самом широком смысле временными рядами называют ряды измерений, зависящие от дискретного или непрерывного аргумента (времени), подвергающиеся нерегулярным случайным воздействиям или флуктуациям и допускающие только статистическое описание.
Наблюдаемые явления, с одной стороны, имеют элемент случайности, а с другой, - изменяются во времени. Можно наблюдать кардиограмму или энцефалограмму больного и исследовать их методами теории случайных процессов. Экономические показатели на различном уровне также можно рассматривать как временные ряды, пытаясь найти в них не видимые на первый взгляд закономерности, скрытые периодичности, прогнозировать моменты появления пиков и т д.
Самый широкий круг явлений, в которых объединены случайность и время описывается моделями временных рядов.
Анализ временных рядов представляет собой самостоятельную, весьма обширную и одну из наиболее интенсивно развивающихся областей математической статистики.
Под временным рядом (динамическим рядом, или рядом динамики) в экономике подразумевается последовательность наблюдений некоторого признака (случайной величины) X в последовательные равноотстоящие моменты времени. Отдельные наблюдения называются уровнями ряда, которые будем обозначать xt (t = 1,2,...,n), где n - число уровней.
Основная цель анализа временных рядов – прогнозирование поведения объекта.
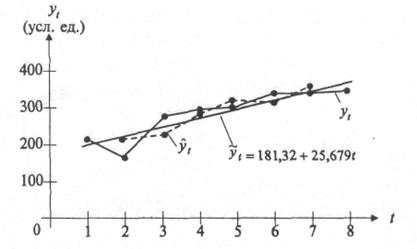
В табл. 1 приведены данные, отражающие цену и спрос на некоторый товар за восьмилетний период (усл. ед.), т.е. два временных ряда - цены товара xt и спроса yt на него.
Таблица 1
| Год, t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Цена, xt | 492 | 462 | 350 | 317 | 340 | 351 | 368 | 381 |
| Спрос, yt | 213 | 171 | 291 | 309 | 317 | 362 | 351 | 361 |
В качестве примера на рис. 1 временной ряд yt, изображен графически.
В общем виде при исследовании экономического временного ряда xt выделяются несколько составляющих:
xt = ut + vt + сt + εt (t = 1,2,…,n),
где ut - тренд, плавно меняющаяся компонента, описывающая чистое влияние долговременных факторов, т.е. длительную («вековую») тенденцию изменения признака (например, рост населения, экономическое развитие, изменение структуры потребления и т.п.);
vt - сезонная компонента, отражающая повторяемость экономических процессов в течение не очень длительного периода (года, иногда месяца, недели и т.д., например, объем продаж товаров или перевозок пассажиров в различные времена года);
сt - циклическая компонента, отражающая повторяемость экономических процессов в течение длительных периодов (например, влияние волн экономической активности Кондратьева, демографических «ям», циклов солнечной активности и т.п.);
εt - случайная компонента, отражающая влияние не поддающихся учету и регистрации случайных факторов.
Следует обратить внимание на то, что в отличие от εt первые три составляющие (компоненты) ut, vt, ct являются закономерными, неслучайными.
Важнейшей классической задачей при исследовании экономических временных рядов является выявление и статистическая оценка основной тенденции развития изучаемого процесса и отклонений от нее.
Отметим основные этапы анализа временных рядов:
• графическое представление и описание поведения временного ряда;
• выделение и удаление закономерных (неслучайных) составляющих временного ряда (тренда, сезонных и циклических составляющих);
• сглаживание и фильтрация (удаление низко- или высокочастотных составляющих временного ряда);
• исследование случайной составляющей временного ряда, построение и проверка адекватности математической модели для ее описания;
• прогнозирование развития изучаемого процесса на основе имеющегося временного ряда;
• исследование взаимосвязи между различными временными рядами.
Лекция 6
3 Применение статистических комплексов для оценки постоянных величин и параметров математических моделей переменных величин, зависящих от одного или нескольких аргументов, и для оценки качества изделий, характеризующихся совокупностью разнородных величин.
Вообще говоря, конечная цель всякого исследования или научного анализа состоит в нахождение связей (зависимостей) между переменными. Философия науки учит, что не существует иного способа представления знания, кроме как в терминах зависимостей между количествами или качествами, выраженными какими-либо переменными. Таким образом, развитие науки всегда заключается в нахождении новых связей между переменными. Исследование корреляций по существу состоит в измерении таких зависимостей непосредственным образом. Тем не менее, экспериментальное исследование не является в этом смысле чем-то отличным. Назначение статистики состоит в том, чтобы помочь объективно оценить зависимости между переменными.
Программные статистические комплексы позволяют автоматизировать сотни различных процедур анализа в терминах оценки различных типов взаимосвязей между переменными.
3.1 Виды математических моделей и их параметрическое описание.
Математическая модель – представление реального объекта, процесса или явления с использованием формальных понятий математики.
Все математические модели по виду представления можно разделить на:
- структурные;
- параметрические.
По способу описания:
- детерминированные (определенные);
- стохастические (вероятностные).
3.2 Постоянные и переменные величины.
Постоянные – это параметры, величина которых не изменяется в рамках данной модели.
Переменные - это то, что можно измерять, контролировать или что можно изменять в исследованиях. Переменные отличаются многими аспектами, особенно той ролью, которую они играют в исследованиях, шкалой измерения и т.д.
3.3 Зависимые и независимые переменные.
Независимыми переменными называются переменные, которые варьируются исследователем, тогда как зависимые переменные - это переменные, которые измеряются или регистрируются.
Может показаться, что проведение этого различия создает путаницу в терминологии, поскольку как говорят некоторые студенты "все переменные зависят от чего-нибудь". Тем не менее, однажды отчетливо проведя это различие, вы поймете его необходимость. Термины зависимая и независимая переменная применяются в основном в экспериментальном исследовании, где экспериментатор манипулирует некоторыми переменными, и в этом смысле они "независимы" от реакций, свойств, намерений и т.д. присущих объектам исследования. Некоторые другие переменные, как предполагается, должны "зависеть" от действий экспериментатора или от экспериментальных условий. Иными словами, зависимость проявляется в ответной реакции исследуемого объекта на посланное на него воздействие. Отчасти в противоречии с данным разграничением понятий находится использование их в исследованиях, где вы не варьируете независимые переменные, а только приписываете объекты к "экспериментальным группам", основываясь на некоторых их априорных свойствах.
Шкалы измерений. Переменные различаются также тем "насколько хорошо" они могут быть измерены или, другими словами, как много измеряемой информации обеспечивает шкала их измерений. Очевидно, в каждом измерении присутствует некоторая ошибка, определяющая границы "количества информации", которое можно получить в данном измерении. Другим фактором, определяющим количество информации, содержащейся в переменной, является тип шкалы, в которой проведено измерение. Различают следующие типы шкал:
- (a) номинальная,
- (b) порядковая (ординальная),
- (c) интервальная
- (d) относительная (шкала отношения).
Соответственно, имеем четыре типа переменных: (a) номинальная, (b) порядковая (ординальная), (c) интервальная и (d) относительная.
Номинальные переменные используются только для качественной классификации. Это означает, что данные переменные могут быть измерены только в терминах принадлежности к некоторым, существенно различным классам; при этом вы не сможете определить количество или упорядочить эти классы. Типичные примеры номинальных переменных - пол, национальность, цвет, город и т.д. Часто номинальные переменные называют категориальными.
Порядковые переменные позволяют ранжировать (упорядочить) объекты, указав какие из них в большей или меньшей степени обладают качеством, выраженным данной переменной. Однако они не позволяют сказать "на сколько больше" или "на сколько меньше". Порядковые переменные иногда также называют ординальными.
Интервальные переменные позволяют не только упорядочивать объекты измерения, но и численно выразить и сравнить различия между ними. Например, температура, измеренная в градусах Фаренгейта или Цельсия, образует интервальную шкалу. Вы можете не только сказать, что температура 40 градусов выше, чем температура 30 градусов, но и что увеличение температуры с 20 до 40 градусов вдвое больше увеличения температуры от 30 до 40 градусов.
Относительные переменные очень похожи на интервальные переменные. В дополнение ко всем свойствам переменных, измеренных в интервальной шкале, их характерной чертой является наличие определенной точки абсолютного нуля, таким образом, для этих переменных являются обоснованными предложения типа: x в два раза больше, чем y. Типичными примерами шкал отношений являются измерения времени или пространства. Например, температура по Кельвину образует шкалу отношения, и вы можете не только утверждать, что температура 200 градусов выше, чем 100 градусов, но и что она вдвое выше.
Связи между переменными. Независимо от типа, две или более переменных связаны (зависимы) между собой, если наблюдаемые значения этих переменных распределены согласованным образом. Другими словами, мы говорим, что переменные зависимы, если их значения систематическим образом согласованы друг с другом в имеющихся у нас наблюдениях. Можно отметить два самых простых свойства зависимости между переменными:
- величина зависимости;
- надежность зависимости.
Величина зависимости. Величину зависимости легче понять и измерить, чем надежность. Например, можно предсказать значения одной переменной по значениям другой.
Надежность ("истинность") взаимозависимости - менее наглядное понятие, чем величина зависимости, однако чрезвычайно важное. Надежность зависимости непосредственно связана с репрезентативностью определенной выборки, на основе которой строятся выводы. Другими словами, надежность говорит нам о том, насколько вероятно, что зависимость, подобная найденной вами, будет вновь обнаружена (иными словами, подтвердится) на данных другой выборки, извлеченной из той же самой популяции.
Статистическая значимость результата представляет собой оцененную меру уверенности в его "истинности" (в смысле "репрезентативности выборки"). Выражаясь более технически, p-уровень (этот термин был впервые использован в работе Brownlee, 1960) это показатель, находящийся в убывающей зависимости от надежности результата. Более высокий p- уровень соответствует более низкому уровню доверия к найденной в выборке зависимости между переменными. Именно, p-уровень представляет собой вероятность ошибки, связанной с распространением наблюдаемого результата на всю совокупность. Например, p-уровень = .05 (т.е. 1/20) показывает, что имеется 5% вероятность, что найденная в выборке связь между переменными является лишь случайной особенностью данной выборки.
Не существует никакого способа избежать произвола при принятии решения о том, какой уровень значимости следует действительно считать "значимым". Выбор определенного уровня значимости, выше которого результаты отвергаются как ложные, является достаточно произвольным. На практике окончательное решение обычно зависит от того, был ли результат предсказан априори (т.е. до проведения опыта) или обнаружен апостериорно в результате многих анализов и сравнений, выполненных с множеством данных, а также на традиции, имеющейся в данной области исследований. Обычно во многих областях результат p 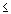 .05 является приемлемой границей статистической значимости, однако следует помнить, что этот уровень все еще включает довольно большую вероятность ошибки (5%). Результаты, значимые на уровне p .01 обычно рассматриваются как статистически значимые, а результаты с уровнем p .005 или p . 001 как высоко значимые. Однако следует понимать, что данная классификация уровней значимости достаточно произвольна и является всего лишь неформальным соглашением, принятым на основе практического опыта в той или иной области исследования.
.05 является приемлемой границей статистической значимости, однако следует помнить, что этот уровень все еще включает довольно большую вероятность ошибки (5%). Результаты, значимые на уровне p .01 обычно рассматриваются как статистически значимые, а результаты с уровнем p .005 или p . 001 как высоко значимые. Однако следует понимать, что данная классификация уровней значимости достаточно произвольна и является всего лишь неформальным соглашением, принятым на основе практического опыта в той или иной области исследования.
Статистическая значимость и количество выполненных анализов. Понятно, что чем больше число анализов вы проведете с совокупностью собранных данных, тем большее число значимых (на выбранном уровне) результатов будет обнаружено чисто случайно. Например, если вы вычисляете корреляции между 10 переменными (имеете 45 различных коэффициентов корреляции), то можно ожидать, что примерно два коэффициента корреляции (один на каждые 20) чисто случайно окажутся значимыми на уровне p .05, даже если переменные совершенно случайны и некоррелированы в популяции. Некоторые статистические методы, включающие много сравнений, и, таким образом, имеющие хороший шанс повторить такого рода ошибки, производят специальную корректировку или поправку на общее число сравнений. Тем не менее, многие статистические методы (особенно простые методы разведочного анализа данных) не предлагают какого-либо способа решения данной проблемы. Поэтому исследователь должен с осторожностью оценивать надежность неожиданных результатов.
Как измерить величину зависимости между переменными. Статистиками разработано много различных мер взаимосвязи между переменными. Выбор определенной меры в конкретном исследовании зависит от числа переменных, используемых шкал измерения, природы зависимостей и т.д. Большинство этих мер, тем не менее, подчиняются общему принципу: они пытаются оценить наблюдаемую зависимость, сравнивая ее с "максимальной мыслимой зависимостью" между рассматриваемыми переменными. Говоря технически, обычный способ выполнить такие оценки заключается в том, чтобы посмотреть как варьируются значения переменных и затем подсчитать, какую часть всей имеющейся вариации можно объяснить наличием "общей" ("совместной") вариации двух (или более) переменных. Говоря менее техническим языком, вы сравниваете то "что есть общего в этих переменных", с тем "что потенциально было бы у них общего, если бы переменные были абсолютно зависимы".
Общая конструкция большинства статистических критериев. Так как конечная цель большинства статистических критериев (тестов) состоит в оценивании зависимости между переменными, большинство статистических тестов следуют общему принципу, объясненному в предыдущем разделе. Говоря техническим языком, эти тесты представляют собой отношение изменчивости, общей для рассматриваемых переменных, к полной изменчивости. Например, такой тест может представлять собой отношение той части изменчивости WCC, которая определяется полом, к полной изменчивости WCC (вычисленной для объединенной выборки мужчин и женщин). Это отношение обычно называется отношением объясненной вариации к полной вариации. В статистике термин объясненная вариация не обязательно означает, что вы даете ей "теоретическое объяснение". Он используется только для обозначения общей вариации рассматриваемых переменных, иными словами, для указания на то, что часть вариации одной переменной "объясняется" определенными значениями другой переменной и наоборот.
Нормальное распределение случайной величины.
В пакете STATISTICA можно вычислить точные значения вероятностей, связанных с различными значениями нормального распределения, используя Вероятностный калькулятор; например, если задать z-значение (т.е. значение случайной величины, имеющей стандартное нормальное распределение) равным 4, соответствующий вероятностный уровень, вычисленный STATISTICA будет меньше .0001, поскольку при нормальном распределении практически все наблюдения (т.е. более 99.99%) попадут в диапазон ±4 стандартных отклонения.
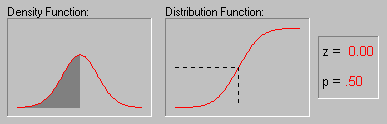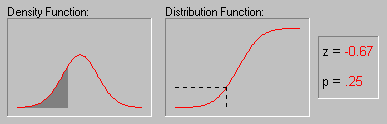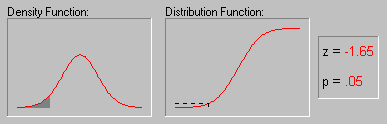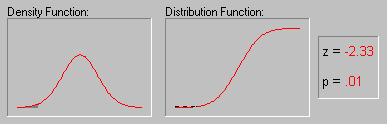
Иллюстрация того, как нормальное распределение используется в статистических рассуждениях (индукция).
Все ли статистики критериев нормально распределены? Не все, но большинство из них либо имеют нормальное распределение, либо имеют распределение, связанное с нормальным и вычисляемое на основе нормального, такое как t, F или хи-квадрат. Обычно эти критериальные статистики требуют, чтобы анализируемые переменные сами были нормально распределены в совокупности. Многие наблюдаемые переменные действительно нормально распределены, что является еще одним аргументом в пользу того, что нормальное распределение представляет "фундаментальный закон". Проблема может возникнуть, когда пытаются применить тесты, основанные на предположении нормальности, к данным, не являющимся нормальными.
Как узнать последствия нарушений предположений нормальности? Хотя многие утверждения других разделов Элементарных понятий статистики можно доказать математически, некоторые из них не имеют теоретического обоснования и могут быть продемонстрированы только эмпирически, с помощью так называемых экспериментов Moнте-Кaрло. В этих экспериментах большое число выборок генерируется на компьютере, а результаты полученные из этих выборок, анализируются с помощью различных тестов. Этим способом можно эмпирически оценить тип и величину ошибок или смещений, которые вы получаете, когда нарушаются определенные теоретические предположения тестов, используемых вами. Исследования с помощью методов Монте- Карло интенсивно использовались для того, чтобы оценить, насколько тесты, основанные на предположении нормальности, чувствительны к различным нарушениям предположений нормальности. Общий вывод этих исследований состоит в том, что последствия нарушения предположения нормальности менее фатальны, чем первоначально предполагалось. Хотя эти выводы не означают, что предположения нормальности можно игнорировать, они увеличили общую популярность тестов, основанных на нормальном распределении.
3.4 Оценка качества изделий с использованием различных оценок.
Для проведения исследований целесообразно использовать следующие статистические методы контроля качества продукции.
1. Гистограмма
Метод гистограмм является эффективным инструментов обработки данных и предназначен для текущего контроля качества в процессе производства, изучения возможностей технологических процессов, анализа работы отдельных исполнителей и агрегатов.
Гистограмма - это графический метод представления данных, сгруппированных на частоте попадания в определенный интервал.
2. Расслаивание
Этот метод, основанный только на достоверных данных, применяется для получения корректной информации, выявления причинно - следственных связей.
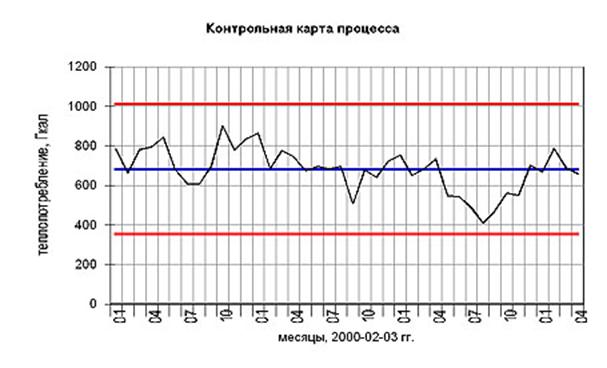
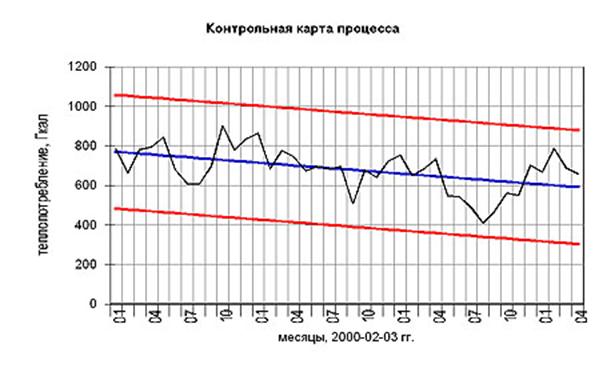
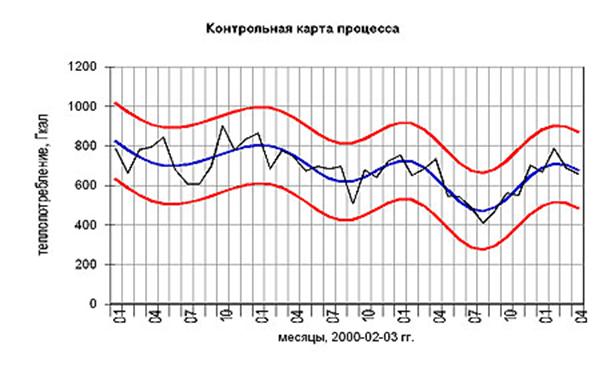
3. Контрольные карты
Контрольные карты графически отражают динамику процесса, т.е. изменение показателей во времени. На карте отмечен диапазон неизбежного рассеивания, который лежит в пределах верхней и нижней границ с помощью этого метода можно оперативно проследить начало дрейфа параметров по какому либо показателю качества в ходе технологического процесса для того чтобы проводить предупредительные меры и не допускать брака готовой продукции.
4. АВС-анализ
АВС - анализ - способ оптимального управления. Этот метод универсален и может применяться при решении проблем распределения усилий в любой отрасли промышленности и сферы деятельности. В АВС - анализе используется двойное накопление до 100 % как на оси абсцисс, так и на оси ординат, получается кривая (ломаная) линия.
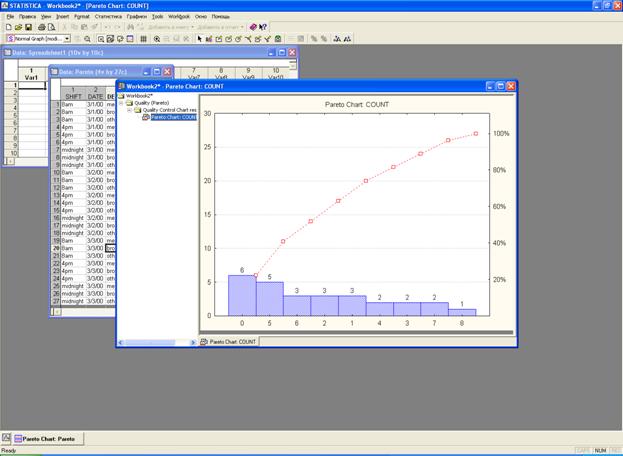
5. Диаграмма Парето
Диаграмма Парето — это схема, построенная на основе группирования по дискретным признакам, ранжированная в порядке убывания и показывающая кумулятивную частоту. Построив её, можно отметить, как говорилось выше, что большая часть бракованной продукции или сумма убытков обусловливается небольшой частью факторов. И если разработать мероприятия, обратив главное внимание на эти факторы, то можно ожидать большого эффекта. То есть простого коллегиального обсуждения основных причин решаемой проблемы обычно недостаточно, так как мнения разных лиц и инстанций субъективны и некорректны. А в основе любого мероприятия, как правило, лежит достоверная информация, которую и позволяет получить диаграмма Парето, т.е. в этом заключается её основной смысл.
Различают два вида диаграмм Парето.
А) Диаграмма Парето по результатам деятельности. Эта диаграмма предназначена для выявления главной проблемы и отражает следующие нежелательные результаты деятельности:
• качество: дефекты, поломки, ошибки, отказы, рекламации, ремонты, возвраты продукции;
• себестоимость: объем потерь, затраты;
• сроки поставок: нехватка запасов, ошибки в составлении счетов, срыв сроков поставок;
• безопасность: несчастные случаи, трагические ошибки, аварии.
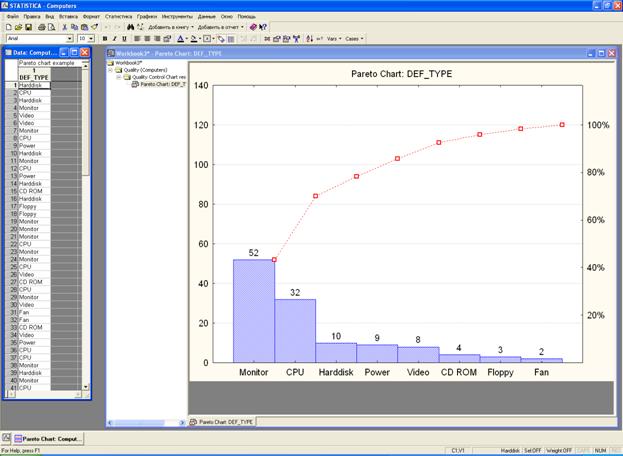
Б) Диаграмма Парето по причинам.
Эта диаграмма отражает причины проблем, возникающих в ходе производства, и используется для выявления главной из них:
• исполнитель работы: смена, бригада, возраст, опыт работы, квалификация, индивидуальные характеристики;
• оборудование: станки, агрегаты, инструменты, оснастка, организация использования, модели, штампы;
• сырье: изготовитель, вид сырья, завод-поставщик, партия;
• метод работы: условия производства, заказы-наряды, приемы работы, последовательность операций;
• измерения: точность (указаний, чтения, приборная), верность и повторяемость (умение дать одинаковое указание в последующих измерениях одного и того же значения), стабильность (повторяемость в течение длительного периода), совместная точность, т.е. вместе с приборной точностью и тарированием прибора, тип измерительного прибора (аналоговый или цифровой).
|
6. Корреляционно-регрессионный анализ
Для оценки связей между входными и выходными параметрами часто используют корреляционно-регрессионный анализ, который призванн решать следующие задачи:
- выявление зависимости признаков;
- выбор формы связи и нахождение ее аналитического выражения;
- измерение степени тесноты связи;
- расчет теоретических уровней;
- анализ полученных результатов
Выявление зависимости признаков предполагает логическую обработку первичного материала, отбор факторов, влияющих на результативный признак, выявление зависимостей с помощью метода группировок.
Выбор формы связи осуществляется с помощью графического метода с последующим построением уравнения связи – регрессионной модели.
Степень тесноты связи измеряется с помощью коэффициента корреляции с целью суждения об адекватности (соответствии) полученной модели данному процессу или явлению.
Расчет теоретических уровней состоит в том, чтобы по полученному уравнению регрессии или модели находить теоретические уровни, т.е. планируемые прогнозируемые показатели на предстоящий период.
Следовательно, можно сказать, что данный метод анализа применяется в целях научно обоснованного нормирования, краткосрочного планирования и прогнозирования.
Корреляционно-регресионный метод исследования состоит из двух этапов. К первому относится корреляционный анализ, а ко второму – регрессионный анализ.
Корреляционный метод исследования призван решать следующие задачи:
- выявлять зависимость между признаками;
- устанавливать форму связи и находить ее аналитическое выражение;
- измерять степень тесноты связи
К задачам регрессионного анализа относятся:
- выражение аналитической формы связи в виде построения уравнения связи (регрессии)
- на основе этого уравнения рассчитываются теоретические уровни, т.е. ожидаемые, планируемые или прогнозируемые показатели на предстоящий период.
Лекция 7
4 Использование программных пакетов при планировании эксперимента.
4.1 Эксперименты в науке и технике. Основные задачи, решаемые при планировании эксперимента.
Экспериментальные методы широко используются как в науке, так и в промышленности, однако нередко с весьма различными целями. Обычно основная цель научного исследования состоит в том, чтобы показать статистическую значимость эффекта воздействия определенного фактора на изучаемую зависимую переменную.
В условиях промышленного эксперимента основная цель обычно заключается в извлечении максимального количества объективной информации о влиянии изучаемых факторов на производственный процесс с помощью наименьшего числа дорогостоящих наблюдений. Если в научных приложениях методы дисперсионного анализа используются для выяснения реальной природы взаимодействий, проявляющейся во взаимодействии факторов высших порядков, то в промышленности учет эффектов взаимодействия факторов часто считается излишним в ходе выявления существенно влияющих факторов.
Различия в методике. Указанное отличие приводит к существенному различию методов, применяемых в науке и промышленности. Если просмотреть классические учебники по дисперсионному анализу, например, монографии Винера (1962) или Кеппеля (1982), то обнаружится, что в них, в основном, обсуждаются планы с количеством факторов не более пяти (планы же с более чем шестью факторами обычно оказываются бесполезными: подробнее см. в разделе Вводный обзор главы Дисперсионный анализ). Основное внимание в данных рассуждениях сосредоточено на выборе общезначимых и устойчивых критериев значимости. Однако если обратиться к стандартным учебникам по экспериментам в промышленности (например, Бокс, Хантер и Хантер (1978); Бокс и Дрейпер (1987); Мейсон, Ганс и Гесс (1989); Тагучи (1987)), то окажется, что в них обсуждаются, в основном, многофакторные планы (например, с 16-ю или 32-мя факторами), в которых нельзя оценить эффекты взаимодействия, и основное внимание сосредоточивается на том получении несмещенных оценок главных эффектов (или, реже, взаимодействий второго порядка) с использованием наименьшего числа наблюдений.
Это сравнение можно продолжить, но после того как вы получите более подробную информацию о планировании промышленных экспериментов, различия станут еще более очевидны. Отметим, что глава Дисперсионный анализ содержит подробное обсуждение типичных вопросов, касающихся планирования эксперимента в научных исследованиях, а модуль Дисперсионный анализ системы STATISTICA представляет исчерпывающую реализацию общей линейной модели в дисперсионном и ковариационном анализе (как одномерном, так и многомерном). Разумеется, существует немало промышленных приложений, в которых с успехом используются обычные планы дисперсионного анализа, зарекомендовавшие себя в научных исследованиях. Для того, чтобы составить более общее впечатление о совокупности методов, объединенных понятием Планирование эксперимента, будет полезно обратиться к разделу Вводный обзор главы Дисперсионный анализ.
4.2 Дробные 2**(k-p) факторные планы, их построение, чтение плана, рандомизация опытов, анализ результатов экспериментов, графическое представление результатов
Во многих случаях достаточно рассмотреть всего два уровня факторов, влияющих на производственный процесс. Например, температура проведения химического процесса может быть установлена немного ниже или немного выше заданного уровня, количество растворителя при производстве красителя можно немного увеличить или уменьшить и так далее. Экспериментатор хотел бы установить, влияют ли какие-либо из этих изменений на результат производственного процесса. Наиболее очевидный подход в данном случае состоит в полном переборе комбинаций уровней интересующих факторов. Это отлично сработает, если бы число необходимых опытов в таком эксперименте не росло экспоненциально. Например, если вы хотите провести эксперимент с 7 факторами, то необходимое число опытов равно 2**7 = 128. Чтобы изучить 10 факторов вам потребуется 2**10 = 1,024 опытов. Поскольку для проведения каждого опыта нужна длительная и дорогостоящая перенастройка, то на практике часто нереально ставить столь большое число опытов. В этом случае при планировании эксперимента обычно используют дробные планы, отбрасывающие взаимодействия высокого порядка и уделяющие наибольшее внимание главным эффектам.
Построение плана. В качестве примера рассмотрим следующий план, включающий 11 факторов, но требующий проведения только 16 опытов (наблюдений).
| Design: 2**(11-7), Resolution III | |||||||||||
| Run | A | B | C | D | E | F | G | H | I | J | K |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | 1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 | 1 1 1 1 -1 -1 -1 -1 1 1 1 1 -1 -1 -1 -1 | 1 1 -1 -1 1 1 -1 -1 1 1 -1 -1 1 1 -1 -1 | 1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 | 1 1 -1 -1 -1 -1 1 1 -1 -1 1 1 1 1 -1 -1 | 1 -1 -1 1 -1 1 1 -1 1 -1 -1 1 -1 1 1 -1 | 1 -1 -1 1 1 -1 -1 1 -1 1 1 -1 -1 1 1 -1 | 1 -1 1 -1 -1 1 -1 1 -1 1 -1 1 1 -1 1 -1 | 1 -1 -1 1 -1 1 1 -1 -1 1 1 -1 1 -1 -1 1 | 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 1 1 1 1 | 1 1 -1 -1 1 1 -1 -1 -1 -1 1 1 -1 -1 1 1 |
Чтение плана. План, представленный в таблице, интерпретируется следующим образом. Каждый столбец таблицы содержит +1 или -1 для обозначения уровня соответствующего фактора (верхнего или нижнего, соответственно). Так, например, в первом опыте эксперимента все факторы от A до K установлены на верхнем уровне (+1); во втором опыте факторы A, B, и C - на верхнем уровне, а фактор D - на нижнем и так далее. Отметим также, что имеется множество опций для отображения плана на экране и сохранения в файле с использованием обозначений, отличных от ± 1 для уровней факторов. Например, можно использовать реальные значения факторов (например, 90° C и 100° C) или текстовые метки (Низкая температура, Высокая температура).
Рандомизация опытов. Поскольку многие условия проведения эксперимента могут измениться от опыта к опыту то, чтобы не возникали систематические смещения, следует рандомизировать порядок проведения опытов (модуль Планирование эксперимента позволяет случайно выбрать порядок их проведения).
Разрешение плана. План в приведенной выше таблице описывается как 2**(11-7) план разрешения III (три). Это означает, что изучается k = 11 факторов (первая цифра в скобках), однако p = 7 из этих факторов (вторая цифра в скобках) порождены взаимодействиями полного факторного плана 2**[(11-7) = 4]. В результате план не обеспечивает полного разрешения, т.е. имеются эффекты взаимодействий, которые смешиваются с другими эффектами (идентичны им). Вообще, план называется планом разрешения R, если в нем ни одно взаимодействие порядка l = 1,…,[(r+1)/2] не смешивается с каким-либо взаимодействием порядка меньше R-l. В данном примере, R равно 3. Ни одно из взаимодействий порядка l = 1 (то есть ни один главный эффект) не смешивается здесь с каким-либо другим взаимодействием порядка меньше R-l = 3-1 = 2. Главные эффекты в этом плане смешиваются со взаимодействиями 2-го порядка и, следовательно, все взаимодействия более высоких порядков также смешаны. Если провести 64 опыта по плану 2**(11-5), полученное разрешение равнялось бы четырем (R = IV). Для того чтобы сделать такой вывод достаточно убедиться, что взаимодействия порядка (l=1) (главные эффекты) не смешиваются со взаимодействиями порядка меньше R-l = 4-1 = 3, а взаимодействия второго порядка (l=2) не смешиваются со взаимодействиями порядка меньшего, чем R-l = 4-2 = 2. Это приводит к тому, что некоторые взаимодействия второго порядка в данном плане смешаны друг с другом.
4.3 Методы Тагучи: робастное планирование эксперимента. Основные понятия: функция потери качества, отношение сигнал/шум (С/Ш), ортогональные массивы.
Приложения. Методы Тагучи находят все большее применение в последние годы. Примеры значительного улучшения качества, связанного с внедрением этих методов (смотрите, например, Phadke, 1989; Noori, 1989), вызвали интерес к ним американских промышленников. Так, некоторые из ведущих производителей начали использовать их с очень большим успехом. Например, AT&T использует эти методы в производстве очень больших интегральных контуров (ОБИК), компания Форд добилась значительного улучшения качества, используя эти методы (Американский институт снабжения, 1984 по 1988).
Обзор. Методы Тагучи находятся во многих отношениях в стороне от традиционных процедур контроля качества (смотрите Контроль качестваиАнализ производственных процессов) и промышленного эксперимента. Особенно важными являются следующие понятия:
1. функция потери качества,
2. отношение сигнал/шум (С/Ш),
3. ортогональные массивы
Эти основные аспекты методов робастного планирования будут обсуждаться в следующих разделах. По этим методам недавно было опубликовано несколько монографий, например, Peace (1993), Phadke (1989), Ross (1988) и Roy (1990), и рекомендуется обращаться к ним для более детального изучения темы. Вводные обзоры идей Тагучи о качестве и его улучшении можно найти в работах Barker (1986), Garvin (1987), Kackar (1986) и Noori (1989).
Функции качества и потерь качества. Что такое качество. Тагучи начинает с вопроса, что такое качество? Нелегко дать простое определение качества; однако, если ваш новый автомобиль теряет скорость в центре напряженного перекрестка, подвергая вас и других участников движения риску, то вы говорите, что ваш автомобиль не обладает высоким качеством. Понятие противоположное качеству более простое: это общие потери для вас и для общества, обусловленные функциональной изменчивостью (изменчивостью) и неблагоприятными побочными эффектами, связанными с соответствующим продуктом. Таким образом, в качестве рабочего определения вы можете измерять качество в терминах этих потерь, и чем больше потери качества, тем ниже оно само.
Разрывная функция потерь. Вы можете сформулировать гипотезу об общем классе и форме функции потерь. Предположим, что имеется особая идеальная точка высшего качества; например, превосходный автомобиль без каких-либо проблем с качеством. Обычно в статистическом контроле процессов (СКП, см. также Анализ производственных процессов) принято определять уровень допуска вокруг номинальной идеальной точки производственного процесса. Согласно традиционной точке зрения, используемой в методах СКП,если вы находитесь внутри допуска, у вас не возникает проблем с качеством. Другими словами, внутри зоны допуска потери качества равны нулю. Если вы вышли за его пределы, потери качества объявляются неприемлемыми. Так, согласно традиционной точке зрения, функция потерь качества является разрывной порогообразной функцией: если вы находитесь внутри зоны допуска, потери качества пренебрежимы, а когда вы выходите за его пределы, потери становятся неприемлемыми.
Квадратичная функция потерь. Зададимся вопросом: является ли кусочно-постоянная функция хорошей моделью для потери качества? Вернемся к примеру “превосходного автомобиля”. Имеется ли разница между автомобилем, с которым ничего не случилось в течение года после покупки, и автомобилем, у которого начало что-то немножко барахлить, например, отвалились некоторые крепления и разбились часы на панели (все это входит в гарантийный ремонт, не так ли...)? Если вы когда-либо покупали новый автомобиль, вы очень хорошо знаете, как могут раздражать такие небольшие по общему признанию проблемы с качеством. Точка зрения здесь такова: не является реалистичным предположение о том, что если вы удаляетесь от номинального определения вашего производственного процесса, потери качества равны нулю, если вы находитесь в зоне допуска. Наоборот, если вы не попали точно “в цель”, то потери все же существуют, например, в терминах удовлетворения покупателя. Более того, эти потери, вероятно, не являются линейной функцией отклонения от номинальной спецификации процесса, а являются квадратичной функцией арочного типа (вроде перевернутой буквы U). Шум в одном месте вашего автомобиля раздражает, но вы, вероятно, не будете слишком опечалены этим; но добавьте еще пару шумов и, возможно, вы объявите ваш автомобиль “хламом”. Если постепенные отклонения от номинала дают непропорциональное увеличение потерь, то скорее всего это квадратичные увеличения.
Вывод: контроль изменчивости. Если фактически потери качества являются квадратичной функцией отклонения от номинального значения, то цель ваших усилий состоит в том, чтобы минимизировать квадрат отклонения или дисперсию продукта относительно его номинальной (идеальной) спецификации, а не число единиц внутри границы допуска (как это делается в традиционных процедурах анализа процессов).
Отношения (С/Ш) сигнал/шум. Измерение потери качества. Даже если вы заключили, что функция потерь квадратична, вы до сих пор точно не знаете, как измерять сами потери. Однако, на какой бы мере вы ни остановились, она должна отражать квадратичную природу функции.
Сигнал, шум и управляющие факторы. Продукт идеального качества всегда должен откликаться одинаковым образом на управляющие сигналы. Когда вы поворачиваете ключ зажигания автомобиля, то ожидаете, что стартер провернет двигатель, и он заведется. В автомобиле идеального качества процесс зажигания всегда происходит одним и тем же образом, например, после трех поворотов ключа зажигания двигатель заводится. Если в ответ на один и тот же сигнал - поворот ключа зажигания - наблюдается случайная изменчивость процесса, вы имеете дело с качеством, худшим, чем идеальное. Например, из-за таких неконтролируемых факторов, как низкая температура, влажность, изношенность двигателя и так далее последний может иногда завестись только после 20 попыток и даже не завестись совсем. Этот пример иллюстрирует ключевой принцип измерения качества по Тагучи: вам хотелось бы минимизировать изменчивость реакции продукта в ответ на факторы шума, максимизируя при этом изменчивость в ответ на управляющие факторы.
Факторы Шума - это те факторы, которые находятся вне контроля оператора. В примере с автомобилем эти факторы включают колебания температуры, различия в качестве бензина, изношенность двигателя и так далее. Управляющие факторы – это те факторы, которые устанавливаются или управляются оператором машины для ее использования по назначению (поворот ключа зажигания запускает двигатель и автомобиль может начать движение).
Итак, целью ваших усилий по улучшению качества является установка наилучших значений управляющих факторов, которые включены в производственный процесс для того, чтобы максимизировать отношение С/Ш (сигнал-шум); так что здесь факторы в эксперименте выступают как управляющие.
С/Ш отношения. Вывод из предыдущего состоит в том, что качество может быть рассмотрено с точки зрения отклика продукта на шумы и управляющие факторы. Идеальный продукт будет реагировать только на сигналы оператора, и не будет реагировать на случайный шум (погоду, температуру, влажность и так далее). Следовательно, цель ваших усилий по совершенствованию качества может рассматриваться как попытка максимизировать отношение сигнал/шум (С/Ш)соответствующего продукта. Отношения С/Ш, описанные в последующих параграфах, были предложены Тагучи (1987).
Меньше - лучше. Если вы хотите минимизировать число появлений некоторых дефектов продукта, вычислите следующее отношение С/Ш:
Eta = -10 * log10 [(1/n) * S (yi2)] for i = 1 to no. vars see outer arrays
Здесь Eta является результирующим отношением С/Ш, n - число наблюдений, а y - соответствующая характеристика. Например, число повреждений окраски автомобиля могло бы выступать как переменная y и анализироваться посредством отношения С/Ш. Эффект управляющих факторов равен нуло, поскольку нуль повреждений окраски является желаемым состоянием. Заметим, что отношение С/Ш является выражением предполагаемой квадратичной функции потерь. Множитель -10 указывает на то, что это отношение измеряет величину, противоположную “плохому качеству”: чем больше повреждений окраски, тем больше сумма квадратов чисел повреждений и тем меньше (то есть более отрицательным) становится отношение С/Ш. Максимизация этого отношения приводит к возрастанию качества.
Номинальное – наилучшее значение. Здесь вы имеете фиксированную величину сигнала (номинальное значение), и дисперсия вокруг этого значения рассматривается как результат действия шумов:
Eta = 10 * log10 (Mean2/Variance)
Такое отношение сигнал/шум может использоваться, когда идеальное качество совпадает с конкретным номинальным значением. Например, диаметр поршневых колец в двигателе автомобиля должен быть как можно ближе к стандартному, чтобы обеспечить высокое качество двигателя.
Больше - лучше. Примерами такого типа инженерных задач является экономия топлива автомобиля (литров бензина на километр), прочность цементного раствора, сопротивление защитных материалов и так далее. Здесь используется следующее отношение С/Ш:
Eta = -10 * log10 [(1/n) *  (1/yi2)] for i = 1 to no. vars see outer arrays
(1/yi2)] for i = 1 to no. vars see outer arrays
Цель со знаком. Этот тип отношения С/Ш применяется, когда характеристика качества имеет идеальное значение 0 (ноль) и могут встречаться как положительные, так и отрицательные значения качества (отклонения от 0). Например, причиняющее ущерб напряжение в дифференциальных усилителях постоянного тока может быть как положительным, так и отрицательным (смотрите Phadke, 1989). Можно воспользоваться следующим отношением С/Ш для проблем такого типа:
Eta = -10 * log10(s2) for i = 1 to no. vars see outer arrays
где s2 обозначает дисперсию характеристики качества по измерениям (переменным).
Доля дефектов. Это отношение С/Ш используется для минимизации отходов, минимизации доли пациентов, у которых развиваются побочные реакции на препарат, и так далее. Тагучи также ссылается на значения Эта как на значения Омеги. Заметим, что это отношение С/Ш эквивалентно известному преобразованию логит (смотрите главу Нелинейное оценивание):
Eta = -10 * log10[p/(1-p)]
где p доля дефектных изделий
Упорядоченные категории (аккумуляционный анализ). В некоторых случаях измерения характеристики качества могут быть получены только в терминах категорий. Например, покупатели могут категоризировать товар как превосходный, хороший, средний или ниже среднего. В этом случае вы пытаетесь максимизировать количество продуктов, оцениваемых как превосходные и хорошие. Обычно результат аккумуляционного анализа представляется в виде гистограммы.
Ортогональные массивы. Третий аспект робастных планов Тагучи весьма схож с трациционными методами. Тагучи разработал систему табулированных планов, которые позволяют оценить несмещенным (ортогональным) образом максимальное число главных эффектов при помощи минимального числа опытов в эксперименте. Планы на латинских квадратах, 2**(k-p) планы (Планы Плакетта-Бермана, в частности), и Планы Бокса-Бенкена также предназначены для достижения этой цели. Многие стандартные ортогональные массивы, табулированные Тагучи, идентичны дробным факторным двухуровневым планам, планам Плакетта-Бермана, планам Бокса-Бенкена, латинским квадратам, греко-латинским квадратам и так далее.
Лекция 8
4.4 Построение оптимальных планов. Основные методы и стратегии поиска.
Средства построения оптимальных планов в модуле Планирование эксперимента будут “осуществлять поиск” оптимальные планы при заданном списке “точек-кандидатов”. Иными словами, при заданном списке точек, определяющих допустимую область, и определенном пользователем числе опытов окончательного эксперимента, программа будет отбирать точки для оптимизации соответствующего критерия. Этот “поиск” наилучшего плана не точный метод, а алгоритмическая процедура, использующая некоторые стратегии поиска для нахождения наилучшего плана (согласно некоторому критерию оптимальности).
Предложенные процедуры и алгоритмы поиска описаны ниже (для обзора и подробного сравнения, смотрите работу Cook и Nachtsheim, 1980). Они расположены в порядке скорости реализации: Последовательный метод или метод Дейкстры является наиболее быстрым, но часто приводит к неправильному результату, то есть к плану, не являющемуся оптимальным (например, строится только локально оптимальный плану, вопрос о котором будет коротко обсужден далее).
Последовательный метод или метод Дейкстры. Этот алгоритм принадлежит Дейкстре (Dykstra, 1971). Начиная с пустого плана, программа ведет поиск по списку точек-кандидатов и на каждом шаге отбирает одну, которая максимизирует выбранный критерий. Не проводятся итерации, программа просто последовательно отбирает заданное число точек. Таким образом, этот метод самый быстрый из обсуждаемых. Кроме того, по умолчанию, этот метод используется остальными для построения начального плана.
Метод простого обмена (Винна-Митчелла). Этот алгоритм обычно приписывают работам Mitchell и Miller (1970) и Wynn (1972). Метод стартует с начального плана требуемого объема (по умолчанию строящийся с помощью алгоритма последовательного поиска, описанного выше). В каждой итерации одна точка (опыт) выбрасывается из плана, а одна – добавляется из списка кандидатов. Выбор точек для выбрасывания и добавления последовательный, то есть на каждом шаге точка, добавляющая меньше всего относительно выбранного критерия оптимальности выбрасывается из плана, затем алгоритм отбирает точку из списка кандидатов для максимального увеличения соответствующего критерия. Алгоритм останавливается, когда нет дальнейшего улучшения с помощью дополнительных изменений.
Алгоритм DETMAX (обмен с отклонениями). Этот алгоритм принадлежащий Митчеллу (Mitchell, 1974b), вероятно наилучший из известных и наиболее широко используемый для поиска оптимального плана. Подобно алгоритму простого обмена (Винна-Митчелла) вначале строится исходный план (по умолчанию с помощью алгоритма последовательного поиска, описанного выше). Поиск начинается с применения алгоритма простого обмена (Винна-Митчелла), как описано выше. Однако, если соответствующий критерий (D или A) не улучшается, алгоритм предпринимает отклонения. А именно, алгоритм добавляет или выбрасывает более одной точки за один раз, так что во время поиска число точек в плане может изменяться между ND+ Nотклонение и ND+ Nотклонение, где ND – требуемый объем плана, а Nотклонение обозначает максимально допустимое отклонение, определяемое пользователем. Итерации останавливаются, когда выбранный критерий (D или A) больше не улучшается с помощью максимального отклонения.
Модифицированный алгоритм Федорова (одновременного переключения). Этот алгоритм представляет модификацию (Cook и Nachtsheim, 1980) основного алгоритма Федорова, описанного ниже. Он также начинается с исходного плана требуемого объема (по умолчанию строящегося с помощью алгоритма последовательного поиска). На каждой итерации алгоритм обменивается каждой точкой плана с отобранной из списка точек-кандидатов, чтобы оптимизировать план согласно выбранному критерию (D или A). В отличие от алгоритма простого обмена (Винна-Митчелла) алгоритм, описанного выше, в данном алгоритме обмен не последовательный, а одновременный. Так, на каждой итерации каждая точка плана сравнивается с каждой точкой из списка кандидатов, и обмен происходит парой, оптимизирующей план. Алгоритм останавливается, когда нет дальнейшего улучшения соответствующего критерия оптимальности.
Алгоритм Федорова (одновременного переключения). Этот оригинальный метод одновременного переключения предложен В.В.Федоровым (см. Cook и Nachtsheim, 1980). Отличие данной процедуры от процедуры, описанной выше (модифицированный алгоритм Федорова), заключается в том, что на каждой итерации осуществляется только единственный обмен, то есть на каждой итерации оцениваются все возможные пары точек плана и списка кандидатов. Алгоритм обменивается парой, оптимизирующей план относительно выбранного критерия. Таким образом, этот алгоритм потенциально может быть весьма медленным, поскольку на каждой итерации осуществляется ND*NC сравнений для обмена единственной точкой.
Общие рекомендации. Если подумать над основными стратегиями поиска, представленных различными алгоритмами, описанными выше, станет ясно, что не существует точного решения проблемы оптимального плана. Именно, детерминант матрицы X’X (и след ее обратной) являются сложными функциями списка точек-кандидатов. В частности, имеется несколько “локальных минимумов” относительно выбранного критерия оптимальности, например, в любой момент поиска план может казаться оптимальным, до тех пор, пока вы одновременно не выбросите половину точек плана и не выберете некоторые другие точки из списка кандидатов, но если вы обмениваетесь отдельными точками или только несколькими точками (как в алгоритме DETMAX), тогда улучшения не случится.
Следовательно, важно попробовать ряд начальных планов и несколько алгоритмов. Если после повторения оптимизации несколько раз со случайного старта получится тот же самый или близкий оптимальный план, тогда вы можете быть в достаточной мере уверены, что вы не “попали” в локальный минимум или максимум.
Кроме того, методы, описанные выше, сильно различаются способностью “попадания” в локальные минимумы или максимумы. Общее правило состоит в том, что чем медленнее алгоритм (то есть чем он ниже в списке, описанном выше), тем более вероятно, что он приведет к истинно оптимальному плану. Однако, заметим, что модифицированный алгоритм Федорова практически работает так же хорошо, как и не модифицированный алгоритм (смотрите Cook и Nachtsheim, 1980); следовательно, если не рассматривать фактор времени, мы рекомендуем модифицированный алгоритм Федорова как наилучший для практического использования.
D-оптимальность и A-оптимальность. По вычислительным соображениям (смотрите Galil и Kiefer, 1980), обновление следа матрицы (для критерия A-оптимальности) много медленнее, чем обновление детерминанта (для D-оптимальности). Так что, если вы выбираете критерий A-оптимальности, вычисления могут занимать значительно больше времени по сравнению с критерием D-оптимальности. Поскольку на практике имеется много других факторов, влияющих на качество эксперимента, (например, надежность измерения зависимой переменной), мы, вообще говоря, рекомендуем использование критерия D-оптимальности. Однако, в трудных ситуациях построения плана, например, когда выясняется, что имеется много локальных максимумов критерия D, и повторные попытки приводят к сильно различающимся результатам, вы можете попробовать несколько прогонов оптимизации критерия A , чтобы лучше изучить различные типы возможных планов.
Устранение вырожденности матрицы.
Может оказаться, что в процессе поиска, программа не сможет вычислить обратную матрицу к X’X матрица (для A-оптимальности) или, что детерминант матрицы становится близок к 0 (нулю). В этом случае поиск обычно не может продолжаться. Чтобы избежать подобной ситуации, программа осуществляет оптимизацию, основываясь на подправленной матрице X’X :
X'Xaugmented = X'X +  *(X0'X0/N0)
*(X0'X0/N0)
где X0 обозначает матрицу плана, построенную из списка N0 всех точек-кандидатов, а where X0 stands for the design matrix constructed from the list of all N0 candidate points, and (альфа) – определяемая пользователем малая константа. Так, вы можете использовать это свойство, положив (alpha) is a user-defined small constant. Thus, you can turn off this feature by setting = 0 (нулю).
“Подправление” планов. Свойства оптимальных планов могут быть использованы для “подправления” планов. Например, предположим, что вы используете ортогональный план, но некоторые данные потеряны (например, из-за неисправности оборудования), и вследствие этого некоторые интересующие вас эффекты не могут быть оценены. Вы, конечно, можете переделать потерянные опыты, но, предположим, что у вас нет ресурсов для того, чтобы переделать их все. В этом случае вы можете построить список точек-кандидатов из всех подходящих для этого точек экспериментальной области, добавить к этому списку все точки, для которых вы уже проделали опыты, и проинструктировать программу всегда включать эти точки в окончательный план (и никогда их не исключать, то есть вы можете пометить их в списке кандидатов с помощью опции непременного (насильственного) включения). Теперь можно исключать из плана лишь те точки, в которых вы пока не ставили опытов. Подобным образом вы можете, например, найти единственный опыт, добавив который к эксперименту, вы оптимизируете соответствующий критерий.
Ограниченные экспериментальные области и оптимальный план. Типичным применением оптимального плана являются ситуации, когда интересующая нас экспериментальная область ограничена. Как описано ранее в этом разделе, существуют средства и возможности для нахождения вершин и центроидов в случае областей с линейными ограничениями и для смесей. Такие точки могут затем быть представлены в списке точек-кандидатов для построения оптимального плана заданного объема для конкретной модели. Таким образом, эти два свойства, будучи объединены, предоставляют очень мощное средство справиться с трудными ситуациями построения плана, когда интересующая нас область подвергнута сложным ограничениям, а мы желаем подогнать конкретную модель при наименьшем числе опытов.
4.5. Заключение
Изложенный материал является малой частью методического обеспечения в рамках выбора и использования программно-статистических комплексов.
В вопросе выбора того или иного продукта на рынке СПП предлагается связывать общую оценку качества данного продукта, получаемую на основе предложенной методологии, с его ценой. Это позволяет обоснованно выбирать тот или иной пакет на основе диаграммы «Цена — Качество».
На основе описанного выше подхода пользователь может сопоставлять, с позиций интересующей его прикладной задачи, нужные ему модули универсального пакета с конкурирующими специализированными пакетами.
Библиографический список
1. Боровиков, В. STATISTICA. Искусство анализа данных на компьютере / В. Боровиков .— / 2-е изд. — М.и др. : Питер, 2003 .— 688с.
2. Боровиков, В.П. Прогнозирование в системе STATISTICA в среде Windows: Основы теории и интенсивная практика на компьютере : учеб. пособие для вузов / В.П. Боровиков, Г.И. Ивченко .— 2-е изд., перераб. и доп. — М. : Финансы и статистика, 2006 .— 368с.
3. Вуколов, Э.А. Основы статистического анализа. Практикум по статистическим методам и исследованию операций с использованием пакетов Statistica и Excel : учеб. пособие / Э.А. Вуколов.— М. : Форум: ИНФРА-М, 2004 .— 464с. — (Проф. образование).
4. Каплан, А.В. Математика, статистика, экономика на компьютере : [учеб. пособие] / Каплан А.В. [и др.].— М. : ДМК Пресс, 2006 .— 600с.
5. Халафян, А.А. STATISTICA 6. Статистический анализ данных : учеб. пособие для вузов / А.А. Халафян .— 2-е изд., перераб. и доп. — М. : БИНОМ, 2010 .— 522 с.
6. Половко, А.М. Mathcad для студента / А.М. Половко, И.В. Ганичев .— СПб. : БХВ-Петербург, 2006 .— 336с.
7. Яковлев, В.Б. Статистика. Расчеты в Microsoft Excel : учеб. пособие для вузов / В.Б. Яковлев.— М. : КолосС, 2005 .— 352с.
Дата добавления: 2018-05-12; просмотров: 373; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!