Выявление взаимных блокировок
Общей проблемой всех алгоритмов блокирования является проблема тупиковых ситуаций. Задача выявления и преодоления тупиковых ситуаций особенно сложна в распределительных системах. Благодаря простоте и эффективности алгоритма они имеют значительно большую популярность по сравнению с альтернативными:
* алгоритмы, основанные на временных метках, выполняют конфликтующие в соответствии с временными метками, которые присваиваются транзакциям и их регистрациям. Такие алгоритмы - протоколы оптимистичного управления одновременным доступом.
Данный тип алгоритма основывается на предположении, что конфликты между транзакциями редкие и они доводят транзакции до конца и лишь потом делают проверку на корректность. Если в случае такой поверки выясняется, что фиксация данной транзакции приведет к нарушению реализуемости, то транзакции откатываются и запускаются снова.
Методы выявления взаимных блокировок в распределенной среде
1. Централизованный метод. В данном типе появление одних из узлов назначается координатором взаимодействующих блокировок и, каждый менеджер блокировок с определенным интервалом направляет координатору свой локальный граф ожидания. Затем координатор строит глобальный граф и анализирует его. Находя в графе замкнутые циклы координатор разрушает их, тем самым выбирая транзакцию, которая должна быть отменена. Данный алгоритм имеет существенный недостаток, заключенный в том, узел с координатором является узким местом (в случае отказа, недоступности не работает вся система.)
|
|
|
2. Иерархический метод. Узлы в сети образуют иерархию и каждый из узлов посылает свой локальный граф ожидания узлу, который стоит выше иерархии. Координатор, который находится в выше стоящем узле, строит и анализирует глобальный граф ожидания на основе информации, полученной с нижестоящих узлов.
3. Распределительный. В данном методе к локальному графу ожидания добавляется внешний узел Т, который отражает наличие объекта на удаленном узле. Когда транзакция Т1 в узле S1 создает агента на узле S2 к локальному графу добавляется ребро, которое соединяет Т1 и Т, и помечено именем узла S2. Если в узле S2 запущена транзакция, создавшая агента в узле S3, то узел Т соединяется ребром с транзакцией с опущенной в этом узле S3. Наличие циклов в графе, не включающих Т, свидетельствует о локальной взаимной блокировке. Наличие циклов в графе ожидания, включающих Т, свидетельствует о взаимной глобальной блокировке. Если графы сливаются, то идет анализ, и если остаются подозрения, слитый граф пересылается далее, пока не будет установлена или опровергнута взаимная блокировка.
|
|
|
Интерфейсы доступа БД
Интерфейс ODBC
Интерфейс ОДВС (открытое соединение с БД) разработан фирмой Майкрософт и представляет разработчикам приложений единый API для разных БД, где API – единый интерфейс программирования приложений, СУБД (как реляционная и не рел.)
Интерфейс АПИ предназначен для предоставления прикладным разработчикам, независимо от типа данных, к которому предоставляется доступ, одинаковой возможности для любой СУБД. Эта цель достигается путем закрепления драйвера ОДВС за одним из предопределенных уровней спецификации. Чтобы считаться драйвером ОДВС, драйвер должен соответствовать спецификации ядра ОДВС. Такие требования гарантируют, что разработчик приложения всегда может рассчитывать на одни и те же функциональные возможности, не зависимо от того, к каким данным происходит обращение. Если тип данных, к которым происходит обращение непосредственно не поддерживается основными функциональными возможностями, то драйвер должен их аккумулировать (искусственно создавать). Данный тип интерфейса представляет собой библиотеку функций, которая позволяет прикладной программе обращаться к различным типам СУБД.
|
|
|
Данный ИФ предлагает независимый от поставщика доступ к СУБД. Разработчик может составлять программу для виртуальной БД и позволить драйверу ОДВС преобразовать логические данные в физические для выбранного типа СУБД.
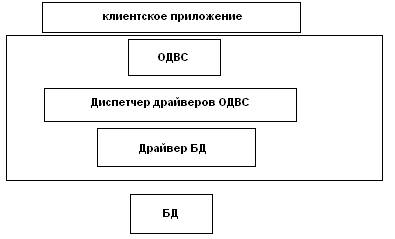
Архитектура ОДВС представляет собой 4 основных компонента:
А) прикладная программа
Б) диспетчер драйверов
В) драйвер
Г) источники данных
Клиентское приложение, которое использует ИФ ОДВС будет обеспечивать обычные средства пользователю, в том числе:
- соединение и отключение от СУБД
- выполнение запросов
- обеспечение областей хранения и формата данных для выбранных результатов.
- выполнение транзакций в режиме реального времени.
- обеспечение средств, которое является внешними по отношению к ОДВС
Диспетчер драйверов является динамической библиотекой, который загружает необходимые драйверы и обеспечивает единственную точку входа функции ОДВС для различных типов драйверов. Все функции ОДВС подразделяются на 7 групп. Эти группы содержат все функции, которые были выделены и определены проектом спецификации фирм X/OPEN и интерфейс на уровне вызовов. Британская фирма является независимой всемирной организацией, которая поддерживается значительным числом поставщиков ИС.
|
|
|
Американская фирма SQL. Занимается аналогичной деятельностью. Эти две фирмы совместно занимаются разработкой спецификации SQL. Согласно оной вес ИФ функции группируют сл. образом:
- назначение и отмена назначения
- соединение
- выполнение SQL оператора
- получение результатов обработки
- управление транзакциями
- идентификация ошибок
- смешанная функция
Интерфейс OLE DB
Он представляет собой набор ИФ ОЛЕ, представляют унифицированный доступ приложений к данным из различных источников. Эти ИФ поддерживают необходимый объем функциональности для каждого типа СУБД, с целью сделать доступной информацию, которая в них хранится. Данный тип ИФ позволяет разрабатывать приложения, которые работают с различными источниками данных.. ИФ ОЛЕ ДБ облегчает приложениям доступ к данным, хранящимся в разных СУБД. В качестве источника для СУБД могла выступать БД серверного и деск-топного вида. В качестве источников не СУБД типа относят файловые системы, электронную почту.
Концептуально, архитектура ОЛЕ ДБ является много компонентной СУБД. Преимущества таких СУБД можно рассматривать с 2 точек зрения:
1. с точки зрения потребителя
2. с точки зрения компонентов доступа к данным
Потребности в том, что касается управлении БД у разных потребителей могут сильно отличаться. Если некий потребитель решает использовать некую модель СУБД, это подразумевает выбор конкретного диспетчера, выбор метода доступа к файлам, конкретной модели защиты языка запросов процессора и диспетчера транзакций.
Зачастую, пользователи используют не все функциональные возможности коммерческой монолитной СУБД. Отсюда им приходится расплачиваться дополнительными расходами за ненужную им функциональность.
Большие объемы данных, которые хранятся в системах не попадают под определение СУБД. Существующие популярные АПИ доступа к данным устанавливаемых для компонентов доступа высокую изначальную планку.
ОЛЕ ДБ уменьшает эту начальную планку для тех типов данных, которые являются наиболее простыми и характерными для хранилищ данных. В минимальном варианте компонентам доступа необходим ИФ, который обеспечивает доступ к данным как к простым таблицам. Такая возможность позволяет создавать компоненты процессора запросов, который позволяет использовать табличную информацию. Каждая компонента тем самым обеспечивая доступ к данным с помощью ОЛЕ ДБ. Архитектура ОЛЕ ДБ включает следующие определения:
Потребитель – каждый фрагмент системного или прикладного кода, который использует ИФ ОЛЕ ДБ.
Компонент доступа – каждый программный компонент, который представляет ИФ ОЛЕ ДБ. Все компоненты доступа разделяют на 2 класса:
- компонент доступа к данным – каждый компонент доступа ОЛЕ ДБ, который владеет данными и представляет их в табличной форме в виде рядов
- компонент доступа к сервису – компонент ОЛЕ ДБ, у которых нет собственных данных, но который реализует некий сервис, производя или потребляя данные через ИФ ОЛЕ ДБ.
ОЛЕ ДБ определяет следующие компоненты, каждый из которых представляет собой компонент ОЛЕ-КОМ.
Перечислители – осуществляют поиск доступных источников данных и др. перечислителей.
Объекты источников данных – реализуют механизм подключения к источникам данных и служат фабриками для сессий.
Сессия – представляет содержимое транзакций, которые могут быть явными или не явными. Сессии служат фабриками для транзакций, команд и наборов рядов.
Транзакция – объекты транзакций используются для подтверждения или отмены вложенных транзакций на каждом уровне, кроме самого низкого.
Команды – исполняет текст команды, как правило, на языке SQL.
Наборы рядов – представляют данные в табличной форме.
Ошибки – могут создаваться любые ИФ любого объекта ОЛЕ ДБ и содержат дополнительную информацию об ошибке, включающий необязательный объект – ошибку.
Интерфейс ADO
Интерфейс АДО – это объектно-ориентированный интерфейс фирмы Майкрософт для работы с БД и другими аналогичными объектами ActiveX. Интерфейс содержит описание объектов, которые можно использовать для работы со многими типами БД. Данный интерфейс опирается на модель СОМ и содержит объекты, которые доступны для многих языков программирования, в том числе виртуальных. Интерфейс может быть использован в серверных приложениях, особенно ориентирован на работу с ASP. Интерфейс АДО содержит описание различных используемых объектов, но не обеспечивает их специальной реализацией. Компания Майкрософт обеспечивает доступ к любым имеющимся данным, типа ОЛЕ ДБ, включая новую разработку Active Directory. Данный механизм реализует интерфейс ОЛЕ ДБ для работы с файлами данных. Такая реализация АДО для интерфейса ОЛЕ ДБ получила название АДО ДБ. Этот интерфейс может также использоваться для доступа к провайдеру ОЛЕ ДБ, который обеспечивает в свою очередь доступ к любым имеющимся данным интерфейса ОДВС.
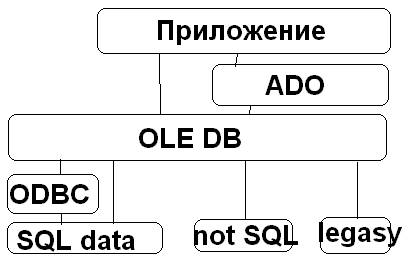
В основу интерфейса АДО положен набор объектов гораздо более простых в использовании, чем ОЛЕ ДБ. Хотя структура АДО аналогична структуре Оле ДБ, объекты АДО не являются столь же зависимыми от иерархии. В большинстве случаев можно создавать и использовать только те объекты, которые необходимы для работы, поэтому отпадает необходимость заботиться о создании родительских классов. Сам интерфейс АДО состоит из следующих классов объектов:
1. Соединение – используется для представления связи с источником данных, а также для обработки некоторых команд и транзакций
2. Операнд или команда – используется для работы с командами, которые отправляются источнику данных.
3. Набор записей – используется для работы с табличными данными, в том числе для изменения и извлечения данных
4. Поле – используется для представления информации о столбце в наборе записей, включая информацию о значении этого столбца.
5. Параметры – используются для обмена с командами, которые отправляются источнику данных.
6. Свойства – используются для регулирования определенной свойственности других объектов.
7. Ошибка – используется для получения более конкретной информации о возможных ошибках.
Сопоставительный анализ ИФ
| Сравнительная характеристика | ODBC | OLE DB | ADO |
| 1. Поддержка интерфейса многими СУБД | + | + | + |
| 2. Единый API для различных источников данных | + | + | + |
| 3. Источник данных может не поддерживать SQL | - | + | + |
| 4. Поддержка не реляционных источников данных | - | + | + |
| 5. Удобство использования интерфейса | + | - | + |
| 6. Возможность применения интерфейса для связи БД с интернетом | - | - | + |
Большинство новых программных продуктов фирмы Майкрософт имеет поддержку интерфейса ОЛЕ ДБ, т.к. этот интерфейс является интерфейсом низкого уровня, построенный на технологии СОМ и позволяет использовать в каждом конкретном случае не все элементы интерфейса, а только необходимые. В свою очередь это позволяет добиться более компетентных программ и наилучшей скорости взаимодействия с СУБД и, хотя интерфейс ОДВС поддерживается почти всеми СУБД, интерфейс ОЛЕ ДБ предоставляет компонент доступа данных ОДВС, который преобразует запросы ОЛЕ ДБ в запросы ОДВС, поэтому автоматически, через интерфейс ОЛЕ ДБ, можно получить доступ практически ко всем СУБД, которые поддерживают интерфейс ОДВС. Однако интерфейс ОЛЕ ДБ довольно сложно использовать в прикладном программировании, поэтому, как видно из результатов сравнения интерфейсов можно определить, что интерфейс АДО, собравший в себе достоинства ОЛЕ ДБ, имеет удобство программирования, является наиболее удобным при программировании прикладных приложений.
Спецификация для создания ПО
Технология СОМ
Компонентная объектная модель СОМ разработана фирмой Майкрософт в 1993 году. Данная модель первоначально использовалась как интеграционная схема для поддержки ОЛЕ и позволяла реализовывать компоненты, которые взаимодействуют в рамках одного адресного пространства или между процессами на одном компьютере. Она представляет собой средства динамической интеграции компонентов.
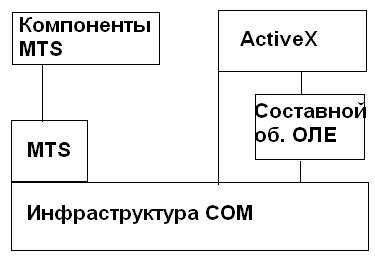
MTS – Microsoft transaction Server – обеспечивает управление хранением данных со стороны сервера.
ActiveX – элементы управления, которые выполняются в контексте вызвавшего их процесса.
Модель СОМ предназначена позволить программисту достаточно эффективно решить проблему повторного использования программного кода и избежать при этом проблем совместимости. Вместо стандартной подпрограммы модель СОМ предлагает высокоуровневую конструкцию, которая гораздо лучше согласуется с общепринятыми принципами объектного программирования. Основное достоинство модели СОМ заключается в независимости от языка программирования. Для достижения этого в СОМ имеется собственный механизм передачи параметров и собственной системы типов, которая является нейтральными по отношению к языкам программирования. Чтобы добиться этой независимости, в модель СОМ было введено два понятия: интерфейс и тип данных variant. В модели СОМ под интерфейсом понимается свод правил и соглашений для взаимодействия между несколькими объектами. Под это определение попадают даже объявления функций и процедур. Т.о. по сути модель СОМ представляет собой перечень методов, которые компонент СОМ представляет пользователю, а интерфейс включает в себя только методы.
В дальнейшем развитие модели СОМ позволило разработать специфические направления моделей:
1. ActiveX – соответствующие элементы управления, которые выполняются в контексте вызвавшего их процесса. Эти элементы имеют графический интерфейс, и иногда попадаются элементы без граф. Интерфейса, реализованные по технологии АДО.
2. OLE Automation – в данной технологии клиент управляет самостоятельным приложением, которое выполняется в контексте собственного процесса и в изолированной области памяти. Приложение должно быть написано спец. Образом в виде сервера Automation.
3. DCOM – распределенная разновидность СОМ – модели, способная работать в локальной сети. Т.е. по данной технологии можно строить распределенные приложения, в которых специально выделенные серверы приложений решают необходимые задачи и выдают клиентам результаты работы. Данная технология появилась в 1996 году в системе Windows NT4.
Технология CORBA
Под термином CORBA понимают технологию, архитектуру, набор спецификаций, набор стандартов промежуточного ПО для создания распределенных программных приложений. Базовыми принципами данной технологии являются:
1. Независимость от физического размещения объекта, т.е. компоненты ПО не обязаны находиться в одном исполняемом файле или выполняться в рамках одного процесса.
2. Независимость от платформы, т.е. компоненты могут выполняться на различных операционных и аппаратных платформах, взаимодействуя друг с другом в рамках единой системы.
3. Независимость от языка программирования, т.е. связываемые программные приложения могут быть написаны на разных языках и необязательно объектно-ориентированных.
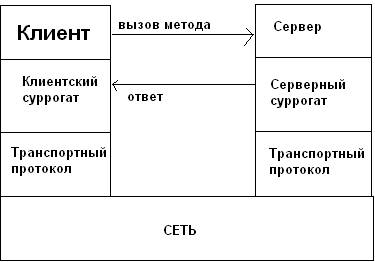
Прообразом взаимодействия между клиентским процессом и сервером объекта является объектный вариант механизма вызова удаленной процедуры. Данный механизм реализует схему передачи сообщений, в соответствии с которыми в распределенном приложении процедура-клиент передает специальное сообщение с параметрами вызова по сети – удаленную серверную процедуру. Для реализации данной схемы на стороне клиента и сервера поддерживается специальные компоненты, которые называются серверный и клиентский суррогат. Для того чтобы вызвать ту или иную функцию, клиент обращается к клиентскому суррогату, который упаковывает аргументы в сообщение-запрос и передает на транспортный уровень соединения. После получения сообщения серверный суррогат распаковывает сообщение и, в соответствие с полученными параметрами, вызывают необходимую процедуру или объектный метод.
В технологии CORBA серверный суррогат имеет спец. название – скелетон.
В отличие от технологии СОМ, архитектура CORBA с самого начала создавалась для распределительных систем. Её автором является консорциум OMG, в состав которого входят более 800 компаний. Задачами данной архитектуры ставились: разработать стандартную архитектуру для взаимодействия объектов в неоднородной сетевой среде.
Общепринято выделять в данной архитектуре 4 основных части:
1. Брокер объектных запросов (Object Requested Broker)
2. Объектные сервисы (Object Services)
3. Общие средства (Common Facilities)
4. Прикладные и отраслевые интерфейсы (Application (domain) Interfaces)
Ядром архитектуры CORBA является брокер объектных запросов, который представляет собой объектную шину, по которой в стиле классического механизма вызова удаленной процедуры происходит взаимодействие удаленных и локальных объектов. Помимо этих задач, брокером реализуется поиск реализации объекта, его подготовка, получение и доставка результатов выполнения клиенту.
Архитектура CORBA включает в себя несколько групп реализаций:
1. Прикладные объекты – представляют собой реализации объектов для конкретных пользовательских приложений.
2. Объектные службы – реализации объектов, которые представляют общие для любой объектно-ориентированной среды возможности, такие как службы имен, служба событий, служба транзакций и т.д.
3. Общие средства – реализации объектов, которые необходимы для большого числа приложений, например поддержка составных документов или потоков заданий.
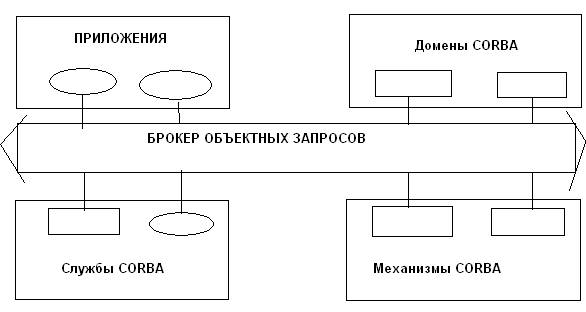
В CORBA существует понятие замена, а так же реализация объекта для необходимого домена. Данные объекты предназначены для приложений вертикальных рынков. Например здравоохранение, страхование любых производственных отраслей.
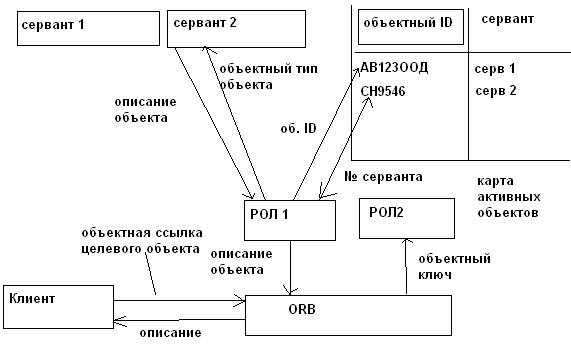
Процесс вызова клиентом объектно-серверного приложения. Этот вызов обращается к объекту по объектной ссылке, которая уникально идентифицирует корба объект в соответствующем пространстве имен. Через брокер объектных запросов запрос передается на сервер. Часть объектной ссылки, которая называется объектным ключом уникально идентифицирует объект в его серверном приложении. Этот объектный ключ позволяет брокеру выбрать именно тот адаптер, который отвечает за вызываемый объект. Адаптер выделяет из объектного ключа объектный идентификатор и по нему узнает какой сервер связан с вызвавшим объектом. Адаптер может узнать это событие по специальной активной карте активных объектов или вызвать приложение, которое должно обеспечить необходимый сервант (серверная программа, реализованная на любом языке программирования и выполняющая CORBA объект). После выполненных операций с запросом начинает работать сервант. Он отвечает за выполнение запроса и возвращение результатов работы назад к объектному адаптеру, который передает их брокеру объектных запросов, а тот в свою очередь клиенту.
Дата добавления: 2018-04-15; просмотров: 253; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!