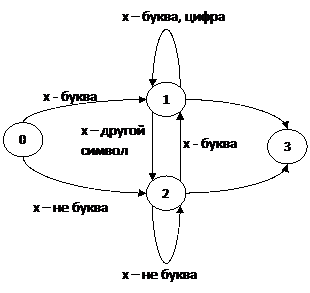
Программирование лексического анализатора
Лексический анализ включает в себя сканирование компилируемой программы и распознавание лексем, составляющих предложения исходного текста. Сканеры обычно строятся таким образом, чтобы они могли распознавать ключевые слова, операторы и идентификаторы так же, как целые числа, числа с плавающей точкой, строки символов и другие аналогичные конструкции, встречающиеся в исходной программе. Точный перечень лексем, которые необходимо распознавать, зависит, разумеется, от языка программирования, на который рассчитан компилятор, и от грамматики, используемой для описания этого языка. Такие объекты, как идентификаторы и целые числа обычно распознаются сканером как отдельные лексемы.
Данной программе будет дано 2 текстовых документа: в одном будет находиться исходный текст, в во втором – ключевые слова. Программа будет выбирать из исходного текста перечисленные во втором файле ключевые слова и записывать их в массив TAB_K. Аналогично в массив TAB_I будут записываться идентификаторы.
Текст программы:
var s,c:string;
k,kl,id,tab_i,tab_k:array [1..100] of string;
f,kluch:text;
st,i,x,n,o,j,d,d2,l,q,r,r2:integer;
begin d:=1;
d2:=1;
assign(kluch,'Kluch.txt');
reset(kluch);
i:=0;
r:=0;
r2:=0;
repeat i:=i+1;
readln (kluch,c);
kl[i]:=c;
until eof(kluch);
o:=i;
close(kluch);
assign(f,'Text.txt');
reset(f);
repeat
readln(f,c);
if (((c[1]>='A') and (c[1]<='Z')) or ((c[1]>='a') and (c[1]<='z'))) then
begin
k[1]:=c[1];
i:=1; x:=2;
st:=1;
end;
repeat
case st of
1: begin if (((c[x]>='A') and (c[x]<='Z')) or ((c[x]>='a') and (c[x]<='z')) or ((c[x]>='0') and (c[x]<='9'))) then
|
|
|
begin
k[i]:=k[i]+c[x];
inc(x);
end
else begin st:=2; x:=x+1; end;
end;
2: begin if (((c[x]>='A') and (c[x]<='Z')) or ((c[x]>='a') and (c[x]<='z'))) then
begin
i:=i+1;
k[i]:=c[x];
x:=x+1;
st:=1;
end
else x:=x+1;
end; end;
until length(c)=x;
n:=i;
for i:=1 to n do
begin l:=1;
for j:=1 to o do
if k[i]=kl[j] then l:=0;
if l=1 then begin for q:=1 to d do
if k[i]=tab_i[q] then l:=0;
if l=1 then begin r:=r+1; tab_i[r]:=k[i]; d:=d+1;end;
end;
end;
for i:=1 to n do
begin l:=0;
for j:=1 to o do
if k[i]=kl[j] then l:=1;
if l=1 then begin for q:=1 to d2 do
if k[i]=tab_k[q] then l:=0;
if l=1 then begin r2:=r2+1; tab_k[r2]:=k[i]; d2:=d2+1;end;
end;
end;
until eof(f);
close(f);
for i:=1 to r do
writeln (tab_i[i]);
writeln;
for i:=1 to r2 do
writeln (tab_k[i]);
end.
В файле Text.txt находится следующий текст:
var x,y:integer;
f:real;
begin x:=5+6;
y:=x^2;
readln (c);
f:=(y*x)/c
writeln (f);
end.
В файле Kluch.txt записан текст:
var
integer
begin
writeln
end
real
readln
В результате компиляции программы получится следующий результат:
 x
x
y
f идентификаторы
c
 var
var
integer
real
begin ключи
readln
writeln
end
Лабораторная работа №6
Лексический анализатор. Процедура, которая не смещает указатель входного потока
 |
Текст программы:
var s,c:string;
k,kl,id,tab_i,tab_k:array [1..100] of string;
|
|
|
f,kluch:text;
st,i,x,n,o,j,d,d2,l,q,r,r2:integer;
procedure scan (c:string; var k:array [1..100] of string; i:integer);
begin if (((c[1]>='A') and (c[1]<='Z')) or ((c[1]>='a') and (c[1]<='z'))) then
begin
k[1]:=c[1];
i:=1;
x:=2;
st:=1;
end;
repeat
case st of
1: begin if (((c[x]>='A') and (c[x]<='Z')) or ((c[x]>='a') and (c[x]<='z')) or ((c[x]>='0') and (c[x]<='9'))) then
begin
k[i]:=k[i]+c[x];
inc(x);
end
else begin st:=2; x:=x+1; end;
end;
2: begin if (((c[x]>='A') and (c[x]<='Z')) or ((c[x]>='a') and (c[x]<='z'))) then
begin
i:=i+1;
k[i]:=c[x];
x:=x;
st:=1;
end
else x:=x+1;
end; end;
until length(c)=x;
end;
begin d:=1;
d2:=1;
assign(kluch,'Kluch.txt');
reset(kluch);
i:=0;
r:=0;
r2:=0;
repeat i:=i+1;
readln (kluch,c);
kl[i]:=c;
until eof(kluch);
o:=i;
close(kluch);
assign(f,'Text.txt');
reset(f);
repeat
readln(f,c);
scan (c,k,i);
n:=i;
for i:=1 to n do
begin l:=1;
for j:=1 to o do
if k[i]=kl[j] then l:=0;
if l=1 then begin for q:=1 to d do
if k[i]=tab_i[q] then l:=0;
if l=1 then begin r:=r+1; tab_i[r]:=k[i]; d:=d+1;end;
end;
end;
for i:=1 to n do
begin l:=0;
for j:=1 to o do
if k[i]=kl[j] then l:=1;
if l=1 then begin for q:=1 to d2 do
if k[i]=tab_k[q] then l:=0;
if l=1 then begin r2:=r2+1; tab_k[r2]:=k[i]; d2:=d2+1;end;
end;
end;
until eof(f);
close(f);
for i:=1 to r do
writeln (tab_i[i]);
writeln;
for i:=1 to r2 do
writeln (tab_k[i]);
end.
В результате компиляции программы получится следующий результат:
 xx
xx
yy
|
|
|
iinteger
f идентификаторы
rreal
y
cc
ff
 var
var
begin
readln ключи
writeln
end
Лабораторная работа №7
Рекурсивный спуск
1) Цель работы: создать программу, которая осуществляет выполнение алгоритма рекурсивного спуска для следующей грамматики:
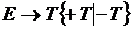
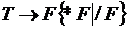
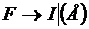
Алгоритм построения процедур.
Для построения процедур просматривается правая часть правила для каждого нетерминала.
1. Если встречается нетерминальный символ, то вызывается процедура для этого символа. Если она завершается без ошибки, то в исходном тексте фраза для этого терма закрыта, и все семантические действия тоже выполнены.
2. Если встречается терминальный символ, он сравнивается с очередным символом входной строки. Если они совпадают, этот символ просто закрывается. Указатель смещается на один шаг вправо. Если не совпадают, то это синтаксическая ошибка и трансляция прекращается.
3. Если встречается метасимвол:
3.1. Если встречается итерация {, то организуется цикл while, в который помещается все, что заключено в {}. Условием входа в цикл является то, что очередной символ не принадлежит множеству Follow для этого нетерминала.
3.2. Если встречается альтернатива ( | ), то организуется оператор if или несколько вложенных операторов if. Число ветвей должно быть на единицу больше, чем альтернатив. Условие для входа в ветвь – принадлежность текущего символа множеству First для этой альтернативы, а последняя ветвь Else соответствует синтаксической ошибке.
|
|
|
Содержимое файла: I+(I*I-I)#
2) Исходный текст программы:
program rs1;
var x:string; i:integer;
flag:boolean; file2:text;
procedure Err(a:integer);
begin
if a=1 then writeln('Ожидается конец файла');
if a=2 then writeln('Неверный символ');
if a=3 then writeln('Ожидается закрывающая скобка');
x[i]:='#';
end;
procedure T; forward;
procedure E;
begin
T;
while not((x[i]='#') or (x[i]=')')) do
if x[i]='+' then begin
i:=i+1;
T;
end
else if x[i]='-' then begin
i:=i+1;
T;
end
else begin Err(1); flag:=false; end;
end;
procedure F; forward;
procedure T;
begin
F;
while not((x[i]='#') or (x[i]=')') or (x[i]='+') or (x[i]='-')) do
begin
if x[i]='*' then begin
i:=i+1;
F;
end
else if x[i]='/' then begin
i:=i+1;
F;
end
else begin Err(1); flag:=false; end;
end;
end;
procedure F;
begin
if x[i]='I' then i:=i+1
else if x[i]='(' then begin
i:=i+1;
E;
if x[i]=')' then i:=i+1
else begin Err(3); flag:=false; end;
end
else begin Err(2); flag:=false; end;
end;
begin
flag:=true;
assign (file2,'7.txt');
reset (file2);
read (file2,x);
i:=1;
E;
if flag=true then
writeln ('Строка правильная');
close (file2);
end.
3) Результаты:
Исходный файл: I+(I*I-I)#
Результат: Строка правильная
Исходный файл: (I+(I*I-I)#
Результат: Ожидается закрывающая скобка
Исходный файл I+(I*I-R)#
Результат: Неверный символ
Исходный файл: I+(I*I-I)
Результат: Ожидается конец файла
Лабораторная работа №8
Дата добавления: 2018-04-05; просмотров: 367; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!