Команды перехода по счетчику
JCXZ, в отличие от других команд условных переходов, не анализирует арифметические флаги. Эта команда проверяет содержание регистра СХ на равенство 0. Если равенство имеет место, тогда происходит передача управления по заданному адресу. Если равенство не выполняется, тогда управление передаётся следующей команде.
Эту команду обычно используют при входе в цикл, который при некоторых условиях может не выполняться ни одного раза, т.е. число повторений будет равно нулю. Использование JCXZ в начале цикла в случае нулевого значения счётчика СХ позволяет обойти этот цикл, не выполняя команды, содержащиеся в теле цикла.
Таким образом, команда JCXZ не изменяет содержимого регистра СХ, а только проверяет его значение.
10. Особенности синтаксиса Ассемблера, общая структура программы, основные определения.
Программа на ассемблере представляет собой совокупность блоков памяти, называемых сегментами памяти. Программа может состоять из одного или нескольких таких блоков-сегментов. Cегменты программы имеют определенное назначение, соответствующее типу сегментов: кода, данных или стека. Названия типов сегментов отражают их назначение. Деление программы на сегменты отражает сегментную организацию памяти процессоров Intel (архитектура IA-32) Каждый сегмент состоит из совокупности отдельных строк, в терминах теории компиляции называемых предложениями языка. Для языка ассемблера предложения, составляющие программу, могут представлять собой синтаксические конструкции четырех типов.
|
|
|
Предложения ассемблера бывают четырех типов:
Команды (инструкции), представляющие собой символические аналоги машинных команд.
В процессе трансляции инструкции ассемблера преобразуются в соответствующие команды системы команд микропроцессора.
Макрокоманды — это оформляемые определенным образом предложения текста программы, замещаемые во время трансляции другими предложениями.
Директивы являются указанием транслятору ассемблера на выполнение некоторых действий. У директив нет аналогов в машинном представлении.
Комментарии содержат любые символы, в том числе и буквы русского алфавита. Комментарии игнорируются транслятором.
Предложения, составляющие программу, могут представлять собой синтаксическую конструкцию, соответствующую команде, макрокоманде, директиве или комментарию. Для того чтобы транслятор ассемблера мог распознать их, они должны формироваться по определенным синтаксическим правилам. Для этого лучше всего использовать формальное описание синтаксиса языка наподобие правил грамматики. Наиболее распространенные способы подобного описания языка программирования — синтаксические диаграммы и расширенные формы Бэкуса—Наура. Для практического использования более удобны синтаксические диаграммы. К примеру, синтаксис предложений ассемблера можно описать с помощью синтаксических диаграмм, показанных на следующих рисунках.
|
|
|
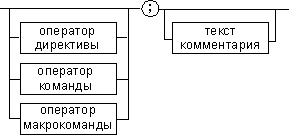
Рис. 1. Формат предложения ассемблера
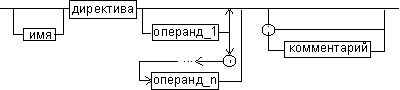
Рис. 2. Формат директив
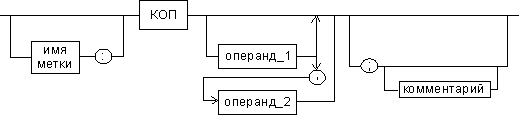
Рис. 3. Формат команд и макрокоманд
На этих рисунках:
имя метки — идентификатор, значением которого является адрес первого байта того предложения исходного текста программы, которое он обозначает;
имя — идентификатор, отличающий данную директиву от других одноименных директив. В результате обработки ассемблером определенной директивы этому имени могут быть присвоены определенные характеристики;
код операции (КОП) и директива — это мнемонические обозначения соответствующей машинной команды, макрокоманды или директивы транслятора;
операнды — части команды, макрокоманды или директивы ассемблера, обозначающие объекты, над которыми производятся действия. Операнды ассемблера описываются выражениями с числовыми и текстовыми константами, метками и идентификаторами переменных с использованием знаков операций и некоторых зарезервированных слов.
|
|
|
Как использовать синтаксические диаграммы?
Очень просто: для этого нужно всего лишь найти и затем пройти путь от входа диаграммы (слева) к ее выходу (направо). Если такой путь существует, то предложение или конструкция синтаксически правильны. Если такого пути нет, значит эту конструкцию компилятор не примет. При работе с синтаксическими диаграммами обращайте внимание на направление обхода, указываемое стрелками, так как среди путей могут быть и такие, по которым можно идти справа налево. По сути, синтаксические диаграммы отражают логику работы транслятора при разборе входных предложений программы.
Допустимыми символами при написании текста программ являются:
все латинские буквы: A—Z, a—z. При этом заглавные и строчные буквы считаются эквивалентными;
цифры от 0 до 9;
знаки ?, @, $, _, &;
разделители , . [ ] ( ) < > { } + / * % ! ' " ? \ = # ^.
Предложения ассемблера формируются из лексем, представляющих собой синтаксически неразделимые последовательности допустимых символов языка, имеющие смысл для транслятора.
Лексемами являются:
идентификаторы — последовательности допустимых символов, использующиеся для обозначения таких объектов программы, как коды операций, имена переменных и названия меток. Правило записи идентификаторов заключается в следующем: идентификатор может состоять из одного или нескольких символов. В качестве символов можно использовать буквы латинского алфавита, цифры и некоторые специальные знаки — _, ?, $, @. Идентификатор не может начинаться символом цифры. Длина идентификатора может быть до 255 символов, хотя транслятор воспринимает лишь первые 32, а остальные игнорирует. Регулировать длину возможных идентификаторов можно с использованием опции командной строки mv. Кроме этого существует возможность указать транслятору на то, чтобы он различал прописные и строчные буквы либо игнорировал их различие (что и делается по умолчанию). Для этого применяются опции командной строки /mu, /ml, /mx;
|
|
|
цепочки символов — последовательности символов, заключенные в одинарные или двойные кавычки;
целые числа в одной из следующих систем счисления: двоичной, десятичной, шестнадцатеричной. Отождествление чисел при записи их в программах на ассемблере производится по определенным правилам:
Десятичные числа не требуют для своего отождествления указания каких-либо дополнительных символов, например 25 или 139.
Для отождествления в исходном тексте программы двоичных чисел необходимо после записи нулей и единиц, входящих в их состав, поставить латинское “b”, например 10010101b.
Шестнадцатеричные числа имеют больше условностей при своей записи:
Во-первых, они состоят из цифр 0...9, строчных и прописных букв латинского алфавита a, b, c, d, e, f или A, B, C, D, E, F.
Во-вторых, у транслятора могут возникнуть трудности с распознаванием шестнадцатеричных чисел из-за того, что они могут состоять как из одних цифр 0...9 (например 190845), так и начинаться с буквы латинского алфавита (например ef15). Для того чтобы "объяснить" транслятору, что данная лексема не является десятичным числом или идентификатором, программист должен специальным образом выделять шестнадцатеричное число. Для этого на конце последовательности шестнадцатеричных цифр, составляющих шестнадцатеричное число, записывают латинскую букву “h”. Это обязательное условие. Если шестнадцатеричное число начинается с буквы, то перед ним записывается ведущий ноль: 0ef15h.
Таким образом, мы разобрались с тем, как конструируются предложения программы ассемблера. Но это лишь самый поверхностный взгляд.
Практически каждое предложение содержит описание объекта, над которым или при помощи которого выполняется некоторое действие. Эти объекты называются операндами.
Их можно определить так:
операнды — это объекты (некоторые значения, регистры или ячейки памяти), на которые действуют инструкции или директивы, либо это объекты, которые определяют или уточняют действие инструкций или директив.
Операнды могут комбинироваться с арифметическими, логическими, побитовыми и атрибутивными операторами для расчета некоторого значения или определения ячейки памяти, на которую будет воздействовать данная команда или директива.
11. Сегменты - основные определения, регистры по умолчанию.
Программа на ассемблере представляет собой совокупность блоков памяти, называемых сегментами памяти. Программа может состоять из одного или нескольких таких блоков-сегментов. Каждый сегмент содержит совокупность предложений языка, каждое из которых занимает отдельную строку кода программы.
Директива .CODE описывает основной сегмент кода
.code имя_сегмента
Директива .STACK описывает сегмент стека
.stack размер
Необязательный параметр указывает размер стека. По умолчанию он равен 1 Кб.
Директива .DATAописывает обычный сегмент данных
.data
Директива .DATA? описывает сегмент неинициализированных данных
.data?
Этот сегмент обычно не включается в программу, а располагается за концом памяти, так что все описанные в нем переменные на момент загрузки программы имеют неопределенные значения.
Директива .CONST описывает сегмент неизменяемых данных
.const
В некоторых операционных системах этот сегмент будет загружен так, что попытка записи в него может привести к ошибке.
Директива .FARDATA описывает сегмент дальних данных
.fardata имя_сегмента
Доступ к данным, описанным в этом сегменте, потребует загрузки сегментного регистра. Если не указан операнд, в качестве имени сегмента используется FAR_DATA.
Директива .FARDATA? описывает сегмент дальних неинициализированных данных
Сегмент команд - содержит команды программы. Для доступа к этому сегменту предназначен регистр сегмента кода (CS).
Сегмент данных - содержит обрабатываемые программой данные. Регистр сегмента данных (DS).
Сегмент стека - стек - структура данных, работа с которой организована по принципу LIFO. Регистр сегмента стека (SS).
12. Загрузка сегментных регистров. Директива ASSUME.
Директива ASSUME сообщает ассемблеру о том, по каким регистрам он должен сегментировать имена из каких сегментов, и "обещает", что в этих регистрах будут находиться начальные адреса этих сегментов. Однако, загрузку этих адресов в регистры сама директива не осуществляет.
Сделать такую загрузку - обязанность самой программы, с загрузки сегментных регистров и должно начинаться выполнение программы. Делается это так.
Поскольку в ПК нет команды пересылки непосредственного операнда в сегментный регистр (а имя, т.е. начало, сегмента - это непосредственный операнд), то такую загрузку приходится делать через какой-то другой, несегментный, регистр (например, AX):
MOV AX,DT1 ;AX:=начало сегмента DT1
MOV DS,AX ;DS:=AX
Аналогично загружается и регистр ES.
Загружать регистр CS в начале программы не надо: он, как и счетчик команд IP, загружается операционной системой перед тем, как начинается выполнение программы (иначе нельзя было бы начать ее выполнение). Что же касается регистра SS, используемого для работы со стеком, то он может быть загружен так же, как и регистры DS и ES, однако в MASM предусмотрена возможность загрузки этого регистра еще до выполнения программы (см. 1.7).
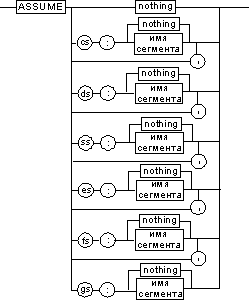
Все сегменты сами по себе равноправны, так как директивы SEGMENT и ENDS не содержат информации о функциональном назначении сегментов. Для того чтобы использовать их как сегменты кода, данных или стека, необходимо предварительно сообщить транслятору об этом, для чего используют специальную директиву ASSUME, имеющую формат, показанный на рисунке ниже. Эта директива сообщает транслятору о том, какой сегмент к какому сегментному регистру привязан. В свою очередь, это позволит транслятору корректно связывать символические имена, определенные в сегментах. Привязка сегментов к сегментным регистрам осуществляется с помощью операндов этой директивы, в которых имя_сегмента должно быть именем сегмента, определенным в исходном тексте программы директивой SEGMENT или ключевым словом nothing. Если в качестве операнда используется только ключевое словоnothing, то предшествующие назначения сегментных регистров аннулируются, причем сразу для всех шести сегментных регистров. Но ключевое слово nothing можно использовать вместо аргумента имя сегмента; в этом случае будет выборочно разрываться связь между сегментом с именем имя сегмента и соответствующим сегментным регистром.
13. Типы данных - применение, директивы определения данных, примеры.
При программировании на языке ассемблера используются данные следующих типов:
1. Непосредственные данные, представляющие собой числовые или символьные значения, являющиеся частью команды. Непосредственные данные формируются программистом в процессе написания программы для конкретной команды ассемблера.
2. Данные простого типа, описываемые с помощью ограниченного набора директив резервирования памяти, позволяющих выполнить самые элементарные операции по размещению и инициализации числовой и символьной информации. При обработке этих директив ассемблер сохраняет в своей таблице символов информацию о местоположении данных (значения сегментной составляющей адреса и смещения) и типе данных, то есть единицах памяти, выделяемых для размещения данных в соответствии с директивой резервирования и инициализации данных.
Эти два типа данных являются элементарными, или базовыми; работа с ними поддерживается на уровне системы команд микропроцессора. Используя данные этих типов, можно формализовать и запрограммировать практически любую задачу. Но насколько это будет удобно — вот вопрос.
3. Данные сложного типа, которые были введены в язык ассемблера с целью облегчения разработки программ. Сложные типы данных строятся на основе базовых типов, которые являются как бы кирпичиками для их построения. Введение сложных типов данных позволяет несколько сгладить различия между языками высокого уровня и ассемблером. У программиста появляется возможность сочетания преимуществ языка ассемблера и языков высокого уровня (в направлении абстракции данных), что в конечном итоге повышает эффективность конечной программы.
Обработка информации, в общем случае, процесс очень сложный. Это косвенно подтверждает популярность языков высокого уровня. Одно из несомненных достоинств языков высокого уровня — поддержка развитых структур данных. При их использовании программист освобождается от решения конкретных проблем, связанных с представлением числовых или символьных данных, и получает возможность оперировать информацией, структура которой в большей степени отражает особенности предметной области решаемой задачи. В то же самое время, чем выше уровень такой абстракции данных от конкретного их представления в компьютере, тем большая нагрузка ложится на компилятор с целью создания действительно эффективного кода. Ведь нам уже известно, что в конечном итоге все написанное на языке высокого уровня в компьютере будет представлено на уровне машинных команд, работающих только с базовыми типами данных. Таким образом, самая эффективная программа — программа, написанная в машинных кодах, но писать сегодня большую программу в машинных кодах — занятие не имеющее слишком большого смысла.
Понятие простого типа данных носит двойственный характер. С точки зрения размерности (физическая интерпретация), микропроцессор аппаратно поддерживает следующие основные типы данных :
байт — восемь последовательно расположенных битов, пронумерованных от 0 до 7, при этом бит 0 является самым младшим значащим битом;
слово — последовательность из двух байт, имеющих последовательные адреса. Размер слова — 16 бит; биты в слове нумеруются от 0 до 15. Байт, содержащий нулевой бит, называется младшим байтом, а байт, содержащий 15-й бит - старшим байтом. Микропроцессоры Intel имеют важную особенность — младший байт всегда хранится по меньшему адресу. Адресом слова считается адрес его младшего байта. Адрес старшего байта может быть использован для доступа к старшей половине слова.
двойное слово — последовательность из четырех байт (32 бита), расположенных по последовательным адресам. Нумерация этих бит производится от 0 до 31. Слово, содержащее нулевой бит, называется младшим словом, а слово, содержащее 31-й бит, - старшим словом. Младшее слово хранится по меньшему адресу. Адресом двойного слова считается адрес его младшего слова. Адрес старшего слова может быть использован для доступа к старшей половине двойного слова.
учетверенное слово — последовательность из восьми байт (64 бита), расположенных по последовательным адресам. Нумерация бит производится от 0 до 63. Двойное слово, содержащее нулевой бит, называется младшим двойным словом, а двойное слово, содержащее 63-й бит, — старшим двойным словом. Младшее двойное слово хранится по меньшему адресу. Адресом учетверенного слова считается адрес его младшего двойного слова. Адрес старшего двойного слова может быть использован для доступа к старшей половине учетверенного слова.
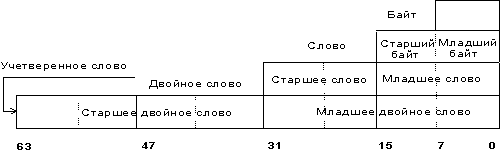
Рис. 1. Основные типы данных микропроцессора
Кроме трактовки типов данных с точки зрения их разрядности, микропроцессор на уровне команд поддерживает логическую интерпретацию этих типов:
Целый тип со знаком — двоичное значение со знаком, размером 8, 16 или 32 бита. Знак в этом двоичном числе содержится в 7, 15 или 31-м бите соответственно. Ноль в этих битах в операндах соответствует положительному числу, а единица — отрицательному. Отрицательные числа представляются в дополнительном коде. Числовые диапазоны для этого типа данных следующие:
8-разрядное целое — от –128 до +127;
16-разрядное целое — от –32 768 до +32 767;
32-разрядное целое — от –231 до +231–1.
Целый тип без знака — двоичное значение без знака, размером 8, 16 или 32 бита. Числовой диапазон для этого типа следующий:
байт — от 0 до 255;
слово — от 0 до 65 535;
двойное слово — от 0 до 232–1.
Указатель на память двух типов:
ближнего типа — 32-разрядный логический адрес, представляющий собой относительное смещение в байтах от начала сегмента. Эти указатели могут также использоваться в сплошной (плоской) модели памяти, где сегментные составляющие одинаковы;
дальнего типа — 48-разрядный логический адрес, состоящий из двух частей: 16-разрядной сегментной части — селектора, и 32-разрядного смещения.
Цепочка — представляющая собой некоторый непрерывный набор байтов, слов или двойных слов максимальной длины до 4 Гбайт.
Битовое поле представляет собой непрерывную последовательность бит, в которой каждый бит является независимым и может рассматриваться как отдельная переменная. Битовое поле может начинаться с любого бита любого байта и содержать до 32 бит.
Неупакованный двоично-десятичный тип — байтовое представление десятичной цифры от 0 до 9. Неупакованные десятичные числа хранятся как байтовые значения без знака по одной цифре в каждом байте. Значение цифры определяется младшим полубайтом.
Упакованный двоично-десятичный тип представляет собой упакованное представление двух десятичных цифр от 0 до 9 в одном байте. Каждая цифра хранится в своем полубайте. Цифра в старшем полубайте (биты 4–7) является старшей.
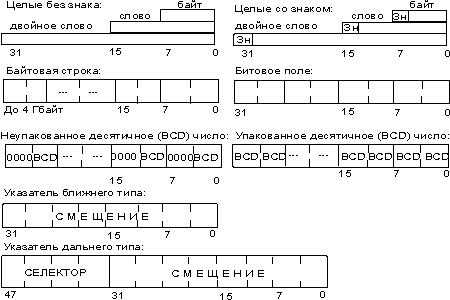
Рис. 2. Основные логические типы данных микропроцессора
Отметим, что “Зн” на рис. 2 означает знаковый бит.
TASM предоставляет очень широкий набор средств описания и обработки данных, который вполне сравним с аналогичными средствами некоторых языков высокого уровня.
Для описания простых типов данных в программе используются специальные директивы резервирования и инициализации данных, которые, по сути, являются указаниями транслятору на выделение определенного объема памяти. Если проводить аналогию с языками высокого уровня, то директивы резервирования и инициализации данных являются определениями переменных.
Машинного эквивалента этим директивам нет; просто транслятор, обрабатывая каждую такую директиву, выделяет необходимое количество байт памяти и при необходимости инициализирует эту область некоторым значением.
Директивы резервирования и инициализации данных простых типов имеют формат, показанный на рис. 3.

Рис. 3. Директивы описания данных простых типов
На рис. 3 использованы следующие обозначения:
? показывает, что содержимое поля не определено, то есть при задании директивы с таким значением выражения содержимое выделенного участка физической памяти изменяться не будет. Фактически, создается неинициализированная переменная;
значение инициализации — значение элемента данных, которое будет занесено в память после загрузки программы. Фактически, создается инициализированная переменная, в качестве которой могут выступать константы, строки символов, константные и адресные выражения в зависимости от типа данных. Подробная информация приведена в приложении 1;
выражение — итеративная конструкция с синтаксисом, описанным на рис. 5.17. Эта конструкция позволяет повторить последовательное занесение в физическую память выражения в скобках n раз.
имя — некоторое символическое имя метки или ячейки памяти в сегменте данных, используемое в программе.
На рис. 3 представлены следующие поддерживаемые TASM директивы резервирования и инициализации данных:
db — резервирование памяти для данных размером 1 байт.
Директивой db можно задавать следующие значения:
выражение или константу, принимающую значение из диапазона:
для чисел со знаком –128...+127;
для чисел без знака 0...255;
8-битовое относительное выражение, использующее операции HIGH и LOW;
символьную строку из одного или более символов. Строка заключается в кавычки. В этом случае определяется столько байт, сколько символов в строке.
dw — резервирование памяти для данных размером 2 байта.
Директивой dw можно задавать следующие значения:
выражение или константу, принимающую значение из диапазона:
для чисел со знаком –32 768...32 767;
для чисел без знака 0...65 535;
выражение, занимающее 16 или менее бит, в качестве которого может выступать смещение в 16-битовом сегменте или адрес сегмента;
1- или 2-байтовую строку, заключенная в кавычки.
dd — резервирование памяти для данных размером 4 байта.
Директивой dd можно задавать следующие значения:
выражение или константу, принимающую значение из диапазона:
для i8086:
для чисел со знаком –32 768...+32 767;
для чисел без знака 0...65 535;
для i386 и выше:
для чисел со знаком –2 147 483 648...+2 147 483 647;
для чисел без знака 0...4 294 967 295;
относительное или адресное выражение, состоящее из 16-битового адреса сегмента и 16-битового смещения;
строку длиной до 4 символов, заключенную в кавычки.
df — резервирование памяти для данных размером 6 байт;
dp — резервирование памяти для данных размером 6 байт.
Директивами df и dp можно задавать следующие значения:
выражение или константу, принимающую значение из диапазона:
для i8086:
для чисел со знаком –32 768...+32 767;
для чисел без знака 0...65 535;
для i386 и выше:
для чисел со знаком –2 147 483 648...+2 147 483 647;
для чисел без знака 0...4 294 967 295;
относительное или адресное выражение, состоящее из 32 или менее бит (для i80386) или 16 или менее бит (для младших моделей микропроцессоров Intel);
адресное выражение, состоящее из 16-битового сегмента и 32-битового смещения;
константу со знаком из диапазона –247...247–1;
константу без знака из диапазона 0...248-1;
строку длиной до 6 байт, заключенную в кавычки.
dq — резервирование памяти для данных размером 8 байт.
Директивой dq можно задавать следующие значения:
выражение или константу, принимающую значение из диапазона:
для МП i8086:
для чисел со знаком –32 768...+32 767;
для чисел без знака 0...65 535;
для МП i386 и выше:
для чисел со знаком –2 147 483 648...+2 147 483 647;
для чисел без знака 0...4 294 967 295;
относительное или адресное выражение, состоящее из 32 или менее бит (для i80386) или 16 или менее бит (для младших моделей микропроцессоров Intel);
константу со знаком из диапазона –263...263–1;
константу без знака из диапазона 0...264–1;
строку длиной до 8 байт, заключенную в кавычки.
dt — резервирование памяти для данных размером 10 байт.
Директивой dt можно задавать следующие значения:
выражение или константу, принимающую значение из диапазона:
для МП i8086:
для чисел со знаком –32 768...+32 767;
для чисел без знака 0...65 535;
для МП i386 и выше:
для чисел со знаком –2 147 483 648...+2 147 483 647;
для чисел без знака 0...4 294 967 295;
относительное или адресное выражение, состоящее из 32 или менее бит (для i80386) или 16 или менее бит (для младших моделей);
адресное выражение, состоящее из 16-битового сегмента и 32-битового смещения;
константу со знаком из диапазона –279...279-1;
константу без знака из диапазона 0...280-1;
строку длиной до 10 байт, заключенную в кавычки;
14. Различия между программами COM и EXE файлов.
Размер программы. EXE-программа может иметь любой размер, в то время как COM-файл ограничен размером одного сегмента и не превышает 64К. COM-файл всегда меньше, чем соответствующий EXE-файл; одна из причин этого - отсутствие в COM-файле 512-байтового начального блока EXE-файла.
Сегмент стека. В EXE-программе определяется сегмент стека, в то время как COM-программа генерирует стек автоматически. Таким образом при создании ассемблерной программы, которая будет преобразована в COM-файл, стек должен быть опущен.
Сегмент данных. В EXE программе обычно определяется сегмент данных, а регистр DS инициализируется адресом этого сегмента. В COM-программе все данные должны быть определены в сегменте кода. Ниже будет показан простой способ решения этого вопроса.
Инициализация. EXE-программа записывает нулевое слово в стек и инициализирует регистр DS. Так как COM-программа не имеет ни стека, ни сегмента данных, то эти шаги отсутствуют. Когда COM-программа начинает работать, все сегментные регистры содержат адрес префикса программного сегмента (PSP), - 256-байтового (шест. 100) блока, который резервируется операционной системой DOS непосредственно перед COM или EXE программой в памяти. Так как адресация начинается с шест. смещения 100 от начала PSP, то в программе после оператора SEGMENT кодируется директива ORG 100H.
Обработка. Для программ в EXE и COM форматах выполняется ассемблирование для получения OBJ-файла, и компановка для получения EXE-файла. Если программа создается для выполнения как EXE-файл, то ее уже можно выполнить. Если же программа создается для выполнения как
COM-файл, то компановщиком будет выдано сообщение:
Warning: No STACK Segment
(Предупреждение: сегмент стека не определен)
Главное различие между файлами типа .COM и типа .EXE связано с форматом записи соответствующего объектного файла на дискете. Оба типа файлов являются программами, записанными на машинном языке. Программа, записанная в файле типа .COM может сразу выполняться. DOS может непосредственно загрузить его в память машины с дискеты. После этого DOS передает управление в сегмент памяти, отведенный для команд, в точку со смещением 100H. Файл типа .EXE непосредственно выполнен быть не может. У соответствующего объектного файла, хранящегося на дискете, имеется заголовок. В нем содержится информация, сгенерированная редактором связей. Наиболее важная ее часть относится к информации, связанной с перемещением. В то время, как у файла типа .COM перемещаем один сегмент команд, у файла типа .EXE могут быть перемещены многие различные сегменты. Это ограничивает максимальный размер файла .COM 64 кбайтами, если только программа не подгружает еще и другие сегменты. Файл типа .EXE может содержать ряд сегментов, которые динамически перемещаются в пределах программной области.
15. Компиляция и компоновка программы. Описание процесса.
На вход ассемблера подаётся исходный файл, а на выходе получается объектный файл, содержащий машинный код. Содержимое объектного файла анализируется компоновщиком. Он определяет, есть ли в программе внешние ссылки, т.е. содержит ли программа команды вызова процедур, находящихся в одной из библиотек объектных модулей (link library). Компоновщик находит эти ссылки в объектном файле программы, копирует необходимые процедуры из библиотек, объединяет их вместе с объектным файлом (этот процесс называется разрешением внешних ссылок) и создаёт исполняемый файл (executable file).
Компоновщик (linker) предназначен для обработки объектного файла, создавая на его основе исполняемый файл, предназначенного для выполнения программы.
16. Организация условий в Ассемблере. Примеры.
До сих пор мы рассматривали команды перехода с «безусловным» принципом действия, но в системе команд процессора есть большая группа команд, призванных самостоятельно принимать решение о том, какая команда должна выполняться следующей. Решение принимается в зависимости от определенных условий, определяемых конкретной командой перехода. Процессор поддерживает 18 команд условного перехода, позволяющих проверить:
· отношение между операндами со знаком (больше или меньше);
· отношение между операндами без знака (выше или ® состояниями арифметических флагов ZF, SF, CF, OF, PF (но не AF).
Команды условного перехода имеют одинаковый синтаксис: jcc метка_перехода
Как видно, мнемокод всех команд начинается с символа «j» — от слова jump (прыжок). Вместо символов «сс» указывается конкретное условие, анализируемое командой. Что касается операндаметка_перехода, то он определяет метку перехода, которая может находиться только в пределах текущего сегмента кода; межсегментной передачи управления в условных переходах не допускается. В связи с этим отпадает вопрос о модификаторе, который присутствовал в синтаксисе команд безусловного перехода. В ранних моделях процессора (8086, 80186 и 80286) команды условного перехода могли осуществлять только короткие переходы — на расстояние от -128 до +127 байт от команды, следующей за командой условного перехода. Начиная с процессора 80386 это ограничение снято, но, как видите, только в пределах текущего сегмента кода.
Для того чтобы принять решение отом, куда будет передано управление командой условного перехода, предварительно должно быть сформировано условие, на основании которого должно приниматься решение. Источниками такого условия могут быть:
· любая команда, изменяющая состояние арифметических флагов;
· команда CMP, сравнивающая значения двух операндов;
· состояние регистра ЕСХ/СХ.
Обсудим эти варианты, чтобы разобраться с тем, как работают команды условного перехода.
Команда сравнения
Команда сравнения СМР (СоМРаге)имеет интересный принцип работы. Он абсолютно такой же, как у команды вычитания SUB (см. главу 8). Команда СМР так же, как и команда SUB, выполняет вычитание операндов и по результатам сравнения устанавливает флаги. Единственное, чего она не делает, — не записывает результат вычитания на место первого операнда.
Синтаксис команды сшр операнд_1,операнд_2
Флаги, устанавливаемые командой СМР, можно анализировать специальными командами условного перехода. Прежде чем мы их рассмотрим, уделим немного внимания мнемонике этих команд (табл.10.1). Понимание обозначений (элементов в названии команды JCC, обозначенных нами символами «сс») при формировании названия команд условного перехода облегчит их запоминание и дальнейшее практическое использование.
Таблица 10.1. Значение аббревиатур в названии команды jcc
| Мнемоническое обозначение | Оригинальный термин | Перевод | Типоперандов |
| е | Equal | Равно | Любые |
| п | Not | Нет | Любые |
| g | Greater | Больше | Числа со знаком |
| 1 | Less | Меньше | Числа со знаком |
| а | Above | Выше (в смысле больше) | Числа без знака |
| Ь | Below | Ниже (в смысле меньше) | Числа без знака |
В табл. 10.2 представлен перечень команд условного перехода для команды СМР. Не удивляйтесь тому обстоятельству, что одинаковым значениям флагов соответствуют несколько разных мнемокодов команд условного перехода (они отделены друг от друга косой чертой). Разница в названии обусловлена желанием разработчиков процессора упростить использование команд условного перехода с разными группами команд. Поэтому разные названия отражают скорее разную функциональную направленность. Тем не менее, то, что эти команды реагируют на одни и те же флаги, делает их абсолютно эквивалентными и равноправными в программе. Именно поэтому они сгруппированы не по названиям, а по значениям флагов (условиям), на которые они реагируют.
Таблица 10. 2. Перечень команд условного перехода для командысmp
| Типы операндов | Мнемокод команды условного перехода | Критерий условного перехода | Значения флагов для перехода |
| Любые | JE | операнд_1 -* операнд_2 | ZF = 1 |
| Любые | JNE | операнд_1 <> операнд_2 | ZF- 0 |
| Со знаком | JL/JNGE | < | SF <> OF |
| Сознаком | JLE/JNG | операнд_1 <= операнд_2 | SF <> OF или ZF = 1 |
| Со знаком | JG/JNLE | операнд_1 > операнд_2 | SF = OF и ZF = 0 |
| Со знаком | JGE/JNL | операнд_1 => | SF OF |
| Без знака | JB/JNAE | операнд_1 < | CF-1 |
| Без знака | JBE/JNA | операнд_1 <= | CF = 1 или ZF=1 |
| Без знака | JA/JNBE | операнд_1 > | CF-0иZF-0 |
| Без знака | JAE/JNB | опсранд_1 => | CF = 0 |
Команды условного перехода и флаги
Мнемоническое обозначение некоторых команд условного перехода отражает название флага, с которым они работают, и имеет следующую структуру: первым идет символ «j» (jump — переход), вторым — либо обозначение флага, либо символ отрицания «п», после которого стоит название флага. Такая структура команды отражает ее назначение. Если символа «п» нет, то проверяется состояние флага и, если он равен 1, производится переход на метку перехода. Если символ «п» присутствует, то проверяется состояние флага на равенство 0 и в случае успеха производится переход на метку перехода. Мнемокоды названия флагов и условия переходов приведены в табл. 10.3. Эти команды можно использовать после любых команд, изменяющих указанные флаги.
Таблица 10.3. Команды условного перехода и флаги
| Название флага | Номер бита в регистре eflags/flags | Команда условного перехода | Значение флага для осуществления перехода |
| Переноса CF | 1 | JC | CF = 1 |
| Четности PF | 2 | JP | PF-1 |
| Нуля ZF | 6 | JZ | ZF = 1 |
| Знака SF | 7 | JS | SF = 1 |
| Переполнения OF | 11 | JO | OF - 1 |
| Переноса CF | 1 | JNC | CF = 0 |
| Четности PF | 2 | JNP | PF- 0 |
| Нуля ZF | 6 | JNZ | ZF- 0 |
| Знака SF | 7 | jns | sf = 0 |
| Переполнения OF | 11 | JNO | OF- 0 |
Если внимательно посмотреть на табл. 10.2 и 10.3, видно, что многие команды условного перехода в них эквивалентны, так как в них анализируются одинаковые флаги.
В листинге10.1 приведен пример программы, производящей в строке символов длиной п байт замену строчных букв английского алфавита прописными. Для осмысленного рассмотрения этого примера вспомним ASCII-коды, соответствующие этим буквам (см. главу 6). Строчные и прописные буквы в таблице ASCII упорядочены по алфавиту. Строчным буквам соответствует диапазон кодов 61h-7ah, прописным — Для того чтобы понять идею, лежащую в основе алгоритма
преобразования, достаточно сравнить представления соответствующих прописных и строчных букв в двоичном виде:
A - 0110 0001...z-0111 1010
А - 0100 0001...Z - 0101 1010
Как видно из приведенного двоичного представления, для выполнения преобразования между строчными и прописными буквами достаточно всего лишь инвертировать 5-й бит.
Дата добавления: 2018-04-04; просмотров: 753; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!