Стратифицированная выборка. Процедуры построения и реализации. Способы размещения выборки между стратами и возможности анализа признаков выборочной совокупности
Стратифицированный отбор и, соответственно, стратифицированная выборка, используются в тех случаях, когда из каких-то содержательных соображений важно обеспечить представительность вероятностной выборки по каким-то конкретным важным для исследовательских целей критериям. В литературе существует определенная путаница вокруг проблемы стратификации («страта»- это социальная, возрастная или иная группа, буквально «СЛОЙ»).
Применительно к стратифицированному отбору часто высказывают все те неверные и предрассудочные мнения, которые в начале ХХ века вы сказывались относительно квотной выборки (см. ниже) и ее воображаемых преимуществ перед случайным отбором. В действительности стратифицированный отбор имеет определенные практические преимущества до тех пор, пока сохраняется его вероятностный, случайный характер. Как только стратифицированная выборка превращается в более или менее специально отобранную квотную выборку, воспроизводящую некоторые известные пропорции генеральной совокупности (например, 51% женщин, 30% горожан и т. п.), любые статистические, то есть строгие, оценки параметров генеральной совокупности становятся невозможными.
Стратификацией, строго говоря, называют процедуру, при которой отбор осуществляют как бы из нескольких «параллельных» под совокупностей, заданных на одной и той же генеральной совокупности. Это абстрактное определение можно прояснить с помощью примера. Пусть у нас есть генеральная совокупность взрослых горожан, относительно которой мы располагаем какой-то существенной с точки зрения исследовательских гипотез информацией. Наличие такой предварительной информации- необходимое условие стратифицированного отбора. Предположим, мы знаем, что в генеральной совокупности 60% рабочих и 40% служащих. Это соотношение может оказаться весьма существенным с точки зрения наших исследовательских гипотез, если оно задает одну из независимых переменных, как, например, при изучении влияния рода занятий на частоту посещения футбольных матчей. Даже при отсутствии значительной систематической погрешности небольшие смещения в реализации случайной выборочной процедуры могут привести к ситуации, когда в нашей конкретной выборке соотношение рабочих и служащих будет существенно (на 5-7%) отклоняться от ожидаемой «правильной» пропорции, имеющей место в генеральной совокупности (см. обсуждение нормальной кривой и индуктивного статистического вывода в гл. 8). Соответственно, под угрозой окажется точность наших оценок взаимосвязи между главной независимой переменной (профессиональным статусом) и интересом к футболу. Такого рода неточность может быть устранена при использовании еще одной случайной выборки из генеральной совокупности, но здесь вступают в силу экономические соображения, так как исследовательский бюджет обычно ограничен. В описанной ситуации желательно заранее обеспечить представленность обеих интересующих нас групп, то есть страт, сохранив вероятностный характер отбора. Этого можно добиться, если осуществить некую независимую процедуру случайного отбора для каждой социальной группы в отдельности (в нашем примере для рабочих и служащих) и затем объединить полученные случайные подвыборки в одну (заметьте, что для нашего примера объем подвыборки рабочих, в согласии с заранее известной пропорцией, будет в 1, 5 раза больше объема подвыборки служащих). Полученная в результате выборка будет и стратифицированной (по профессиональному статусу), и вероятностной.
На практике две случайные процедуры отбора в подвыборки страты можно технически объединить в одну, если мы располагаем априорной информацией о принадлежности каждой выборочной единицы к той или иной страте. Для этого достаточно вести параллельный отбор из списка-основы в несколько подвыборок (по числу страт). Собственно выборочная процедура может быть и простой случайной, и систематической (соответственно мы получим либо простую, либо систематическую стратифицированную выборку). Рассмотрим эту процедуру на примере составления систематической выборки населения, стратифицированной по этнической принадлежности. Пусть мы осуществляем выборку взрослых жителей небольшого промышленного центра, при этом полученная выборка должна отражать существующую этнодемографическую ситуацию: 80% русских, 10% украинцев и 10% представителей других национальностей. Основываясь на информации, хранящейся в паспортных столах милиции (или на избирательных списках), мы в идеальном случае можем составить полный список-основу, включающий 100 000 известных административным органам постоянных жителей. Если предварительно мы предполагаем включить в нашу выборку около 1000 человек, нам нужно отобрать из картотек паспортных столов (или избирательных списков) каждого сотого. То есть доля генеральной совокупности f, включенная в выборку, составит 1/100: f = объем выборки (n) /объем целевой совокупности (N)
Выборка объемом в 1000 человек будет включать в себя 800 русских, 100 украинцев и 100 представителей других национальностей. Причем шаг систематического отбора (К) для всех трех подсовокупностей будет равен 100.
Определение шага отбора (К)
80 000 человек в «русской» страте : 800 русских в выборке = 100;
10 000 человек в «украинской» страте : 100 украинцев в выборке = 1 00;
10 000 человек в страте «другие национальности» : 100 представителей других национальностей в выборке = 100.
Таким образом, мы будем выписывать из реальных картотек (списков) каждого сотого русского, каждого сотого украинца и т. п. (естественно, украинцы и представители других национальностей будут встречаться в списках в среднем в 10 раз реже русских)''·
Выборка в описанном нами примере является пропорциональной, так как она представляет все страты в той пропорции, в которой они содержатся в генеральной совокупности. Пропорциональный стратифицированный отбор особенно важен для целей дескриптивной, описательной статистики, то есть когда перед исследователем стоит задача, основываясь на выборке, описать, как распределены те или иные параметры в разных группах генеральной совокупности. Именно так обычно можно сформулировать цель предвыборного опроса, маркетингового исследования покупательских предпочтений и т. п. Еще одним преимуществом стратифицированного вероятностного отбора является уменьшение такого источника общей ошибки измерения, как дисперсия выборки. Не вдаваясь здесь в статистические тонкости, заметим, что стратификация уменьшает так называемую стандартную ошибку (лишь в том случае, если интересующая исследователя переменная значительно варьирует между стратами, то есть когда заранее выделенные страты (например, возрастные группы) сильно отличаются по уровню измеряемой переменной (например, по частоте посещения дискотек). При этом различия внутри страт должны быть относительно невелики, то есть межгрупповой разброс значений переменной должен значительно превосходить внутригрупповой.
Иногда, однако, основной задачей исследования является сравнение различных, обычно важных с точки зрения некоторой теории, групп внутри выборки с целью описания некоторого соотношения, имеющего место в генеральной совокупности. Некоторые из таких «теоретически релевантных» групп могут быть весьма малочисленными. Для того чтобы сделать такие малочисленные группы-субпопуляции статистически сопоставимыми с другими группами и, следовательно, получить статистически значимые выводы о существующих (несуществующих) межгрупповых различиях, можно использовать два метода.
Первый метод заключается в увеличении объема выборки. В этом случае пропорционально возрастает объем «редкой» страты, но столь же быстро (а иногда и быстрее) растут расходы на проведение исследования. Если, например, пожилые люди старше 85 лет составляют лишь 1/20 часть целевой совокупности горожан пенсионеров, то в исследовании эффективности социальной работы с пожилыми людьми нам понадобится выборка объемом 4000 пенсионеров, чтобы получить 200 наблюдений, относящихся к редкой подсовокупности тех, кто старше 85.
Другой, более дешевый метод заключается в непропорциональной стратификации, то есть в непропорциональном отборе из различных подсовокупностей. Нередко возникает необходимость сделать «распространенные» и «редкие» страты равно представленными в выборке. Если вернуться к обсуждавшемуся выше примеру исследования городского населения, можно, в частности, представить ситуацию, когда необходимо сравнить кулинарные предпочтения русских и украинцев. Очевидно, не вполне корректно сравнивать 800 русских и 100 украинцев. В этом случае можно прибегнуть к непропорциональному систематическому отбору из названных страт: если отбирать каждого 200-го русского и каждого 25-го украинца, мы получим две вполне сопоставимые, равные по объему - 400 и 400 человек - подвыборки (однако эти равные подвыборки будут непропорционально репрезентировать доли соответствующих под совокупностей, в чем можно убедиться, самостоятельно произведя подсчеты по описанным выше формулам).
Выбор между пропорциональной и непропорциональной стратификацией исследователь осуществляет, исходя из содержательных и экономических соображений. Нужно, однако, иметь в виду некоторые «послевыборочные» последствия непропорционального отбора, с которыми социологи сталкиваются на стадии анализа. В частности, для получения более точных оценок распределения исследуемых переменных иногда приходится применять так называемое взвешивание (иногда употребляют термин «перевзвешивание»). Взвешивание используют также для того, чтобы исключить влияние некоторых типов систематического смещения в основе выборки и других типов систео1tатической ошибки измерения. Например, взвешивание полезно для исключения смещений, возникающих из-за дублирования в списке-основе или, наоборот, из-за наличия систематических «пропусков» для какой-то одной группы (скажем, если в списке пропущено много пожилых людей, постоянно проживающих с детьми, но прописанных по другому адресу). Так как необходимость взвешивания чаще всего вызвана нарушением исходных соотношений, пропорций между входящими в целевую совокупность группами, мы опишем общую идею этой процедуры на примере непропорционального стратифицированного отбора.
Напомним, что к непропорциональной стратифицированной выборке прибегают в тех случаях, когда точность оценок для выборки в целом или для отдельных подгрупп (субпопуляций) внутривыборки оказывается недостаточной. В этом случае доли генеральной совокупности (f) будут различны для разных страт. Последнее утверждение равносильно признанию разной вероятности попадания в выборку для единиц, принадлежащих к разным стратам. Как совместить неравные вероятности отбора с данным нами выше определением вероятностной (случайной) выборки, в котором подчеркивалось равенство шансов попадания в выборку для всех входящих в генеральную совокупность единиц-«случаев»? Некоторые статистики считают предложенное нами выше определение не вполне точным и предпочитают говорить о вероятностной выборке как о выборке, где каждая единица отбора имеет «известную, ненулевую вероятность быть включенной в выборку», хотя шансы для различных единиц не обязательно равны. Существующее многообразие определений вероятностной выборки восходит к давней дискуссии о правомерности выводов, основанных на априорных («до») и апостериорных («после испытания») вероятностях. Мы, однако, сохраним наше определение случайной выборки, внеся в него некоторое уточнение: когда шансы попадания в выборку неравны, как при непропорциональном отборе из страт, они могут быть выравнены при помощи взвешивания на стадии анализа, то есть на собственно послевыборочной стадии исследования (конечно, если отбор внутри страт сохраняет свой случайный и равновероятный характер). Для этого нужно внести определенные поправки в полученные данные, а именно - приписать некоторым наблюдениям (классам наблюдений) больший «вес», компенсирующий меньшие шансы попадания в выборку (и наоборот).
Результатом приписывания веса каждому наблюдению является увеличение точности оценок для исследуемых параметров. Вес каждой единицы (респондента) в k-й страте равен отношению числа таких элементов в генеральной совокупности к объему выборки для k-й страты, то есть:
w = Nk/nk
При расчете среднего или других параметров каждое наблюдавшееся значение просто умножается на весовой коэффициент «своей» страты.
В частности, среднее значение какого-то параметра совокупности (например, средний доход или среднее количество хронических заболеваний) будет равняться просто взвешенной сумме средних значений для отдельных страт:
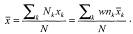
Формула расчета стандартной ошибки для стратифицированной выборки также включает в себя весовые коэффициенты,

Стандартные компьютерные программы, используемые при статистическом анализе данных, всегда содержат элементарные процедуры взвешивания.
Вернемся к нашему примеру с непропорциональным стратифицированным отбором русского и украинского населения. Предположим, мы выяснили, что в среднем каждая украинская семья заготавливает на зиму 50 кг варенья, тогда как среднее значение для русской страты составило 40 кг (для простоты расчетов примем мало правда подобное допущение, что остальные 10 000 опрошенных представителей других национальностей вообще не варят варенье, а используют другие технологии хранения ягод, то есть для этой страты среднее равно нулю). Для украинской страты весовой коэффициент составит:

Соответственно для русского населения:

С учетом этих весовых коэффициентов уточненная оценка сред
него запаса варенья в выборке составит:
х =50*0*200 + 25*50*400 + 200*40*400 / 100 000 = 37 кг.
Если бы мы не учли в своих расчетах сверх представленность украинцев в нашей непропорциональной стратифицированной выборке, то оценка среднего запаса варенья для всей совокупности оказалась бы завышенной (45 кг).
Дата добавления: 2018-02-28; просмотров: 2491; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!