Обобщенная структура экспертных систем
Экспертные системы — это сложные программные комплексы, аккумулирующие знания специалистов в конкретных предметных областях и тиражирующие эти знания для консультаций менее квалифицированных пользователей.
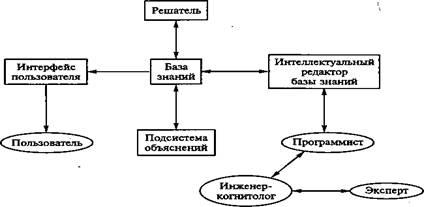
база знаний — ядро экспертной системы, совокупность знаний предметной области, записанная на машинном носителе в форме, понятной эксперту и пользователю; интеллектуальный реДактор базы знаний — программа, представляющая инженеру-когнитологу и программисту возможность создавать базу знаний в диалоговом режиме. Она включает в себя системы вложенных меню, шаблонов языка представления знаний, подсказок (help-режим) и других сервисных средств, облегчающих работу с базой знаний; интерфейс пользователя — комплекс программ, реализующих диалог пользователя с экспертной системой на стадии как ввода информации, так и получения результатов;
решатель (синонимы: Дедуктивная машина, блок логического вывода) — программа, моделирующая ход рассуждений эксперта на основании знаний, имеющихся в базе знаний;
подсистема объяснений — программа, позволяющая пользователю получать ответы на вопросы: «Как была получена та или иная рекомендация?» и «Почему система приняла такое решение?». Ответ на вопрос «Как?» — это трассировка всего процесса получения решения с указанием исполняющих фрагментов базы знаний, т. е. всех шагов цепи умозаключений. Ответ на вопрос «Почему?» — ссылка на умозаключение, непосредственно предшествовавшее полученному решению, т. е. отход на один шаг назад.
|
|
|
Хвостовая рекурсия
Есть один вариант рекурсии, который использует практически столько же оперативной памяти, сколько итерация в императивных языках программирования. Это так называемая хвостовая или правая рекурсия. Для ее осуществления рекурсивный вызов определяемого предиката должен быть последней подцелью в теле рекурсивного правила и к моменту рекурсивного вызова не должно остаться точек возврата (непроверенных альтернатив). То есть у подцелей, расположенных левее рекурсивного вызова определяемого предиката, не должно оставаться каких-то непроверенных вариантов и у процедуры не должно быть предложений, расположенных ниже рекурсивного правила. Турбо Пролог, на который мы ориентируемся в нашем курсе, распознает хвостовую рекурсию и устраняет связанные с ней дополнительные расходы. Этот процесс называется оптимизацией хвостовойрекурсии или оптимизацией последнего вызова.
Пример. Попробуем реализовать вычисление факториала с использованием хвостовой рекурсии. Для этого понадобится добавить два дополнительных параметра, которые будут использоваться нами для хранения промежуточных результатов. Третий параметр нужен для хранения текущего натурального числа, для которого вычисляется факториал, четвертый параметр - для факториала числа, хранящегося в третьем параметре.
|
|
|
Вся процедура будет выглядеть следующим образом:
fact2(N,F,N,F):-!. /* останавливаем рекурсию, когда третий
аргумент равен первому*/
fact2(N,F,N1,F1):-
N2=N1+1, /* N2 - следующее натуральное число
после числа N1 */
F2=F1*N2, /* F2 - факториал N2 */
fact2(N,F,N2,F2).
/* рекурсивный вызов с новым натуральным
числом N2 и соответствующим ему
посчитанным факториалом F2 */
Создать предикат, позволяющий проверить принадлежность элемента списку
Предикат будет иметь два аргумента: первый — искомое значение, второй — список, в котором производится поиск. Построим данный предикат, опираясь на тот факт, что объект принадлежит списку, если он либо является первым элементом списка, либо элементом хвоста. Это может быть записано в виде двух предложений: member(X,[X|_]). /* X — первый элемент списка */ member(X,[_|T]) :– member(X,T). /* X принадлежит хвосту T*/ Заметим, что в первом случае (когда первый элемент списка совпадает с исходным элементом), нам неважно, какой у списка хвост, и можно в качестве хвоста указать анонимную переменную. Аналогично, во втором случае, если X принадлежит хвосту, нам не важно, какой элемент первый. Отметим, что описанный предикат можно использовать двояко: во-первых, конечно, для того, для чего мы его и создавали, т.е. для проверки, имеется ли в списке конкретное значение. Мы можем, например, поинтересоваться, принадлежит ли двойка списку [1, 2, 3]: member(2, [1, 2, 3]). Получим, естественно, ответ: "Yes".
|
|
|
member(X,[X|_]).
member(X,[_|T]) :- (X,T).
Билет № 12
Многослойный персептрон
частный случай перцептронаРозенблатта, в котором один алгоритмобратногораспространенияошибки обучает все слои. Название по историческим причинам не отражает особенности данного вида перцептрона, то есть не связано с тем, что в нём имеется несколько слоёв (так как несколько слоёв было и у перцептрона Розенблатта). Особенностью является наличие более чем одного обучаемого слоя (как правило — два или три). Необходимость в большом количестве обучаемых слоёв отпадает, так как теоретически единственного скрытого слоя достаточно, чтобы перекодировать входное представление таким образом, чтобы получить линейнуюразделимость для выходного представления. Существует предположение, что, используя большее число слоёв, можно уменьшить число элементов в них, то есть суммарное число элементов в слоях будет меньше, чем если использовать один скрытый слой. Это предположение успешно используется в технологиях глубокогообучения и имеет обоснование.
|
|
|

Среди отличий многослойного перцептрона Румельхарта от перцептрона Розенблатта можно выделить следующие:
· Использование нелинейной функции активации, как правило сигмоидальной.
· Число обучаемых слоев больше одного. Чаще всего в приложениях используется не более трёх.
· Сигналы, поступающие на вход и получаемые с выхода, не бинарные, а могут кодироваться десятичными числами, которые нужно нормализовать так, чтобы значения были на отрезке от 0 до 1 (нормализация необходима как минимум для выходных данных, в соответствии с функцией активации — сигмоидой).
· Допускается произвольная архитектура связей (в том числе, и полносвязные сети).
· Ошибка сети вычисляется не как число неправильных образов после итерации обучения, а как некоторая статистическая мера невязки между нужным и получаемым значением.
· Обучение проводится не до отсутствия ошибок после обучения, а до стабилизации весовых коэффициентов при обучении или прерывается ранее, чтобы избежать переобучения.
Многослойный перцептрон будет обладать функциональными преимуществами по сравнению с перцептроном Розенблатта только в том случае, если в ответ на стимулы не просто будет выполнена какая-то реакция (поскольку уже в перцептроне может быть получена реакция любого типа), а выразится в повышении эффективности выработки таких реакций. Например, улучшится способность к обобщению, то есть к правильным реакциям на стимулы которым перцептрон не обучался. Но на данный момент таких обобщающих теорем нет, существует лишь масса исследований различных стандартизированных тестов, на которых сравниваются различные архитектуры.
Дата добавления: 2018-02-28; просмотров: 543; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!