Сведения об авторах 12 страница
Перечислим структурные элементы теории, так как это может оказаться полезным для исследователей: алгоритм, аппарат (дидактические, понятийные аппараты и т.д.); классификации; критерии; методики; методы; механизмы (классы механизмов); модели (базисные, прогностические, графовые, открытые, закрытые, динамические, комплексы моделей и т.д.); направления; обоснования; основания; основы; парадигмы; параметры; периодизации; подходы; понятия (развивающиеся понятия, системы понятий и т.д.); приемы; принципы; программы; процедуры; решения; системы (иерархические системы, генерализованные системы и т.д.); содержание; способы; средства; схемы; структуры; стратегии; фазы; сущности; таксономии; тенденции; технологии; типологии; требования; условия; фазы; факторы (системообразующие факторы и т.д.); формы (совокупности форм и т.д.); функции; характеристики (сущностные характеристики и т.д.); цели (совокупности целей, иерархии целей); этапы и т.д.
В отраслях наук сильной версии добавляются еще теоремы, леммы, утверждения. А в качестве центрального системообразующего элемента (звена) могут выступать теория, концепция, идея, единый исследовательский подход, система аксиом или система аксиоматических требований и т.д. В ряде отраслей науки, например в химии, фармации, микробиологии и т.д., в качестве центрального системообразующего звена может выступать факт получения нового химического вещества, нового лекарства, новой вакцины и т.п., что является нередко плодом многолетних трудов исследователя. А затем раскрываются условия, принципы их применения и т.д.
Но в целом вполне обоснованно можно утверждать, что общая логическая структура теорий (концепций) едина.
Опытно-экспериментальная работа. Специфика научного исследования состоит в том, что опытно-экспериментальная работа, хотя она и занимает значительную, а подчас и большую часть бюджета времени исследователя, служит лишь для подтверждения или опровержения предварительно сделанных им теоретических построений, начиная с гипотезы.
Хотя, казалось бы, опытно-экспериментальная часть исследования начинается лишь тогда, когда исследователем закончены, выявлены и выведены все теоретические построения, тем не менее, как правило, исследователь включается в опытно-экспериментальную работу намного раньше. Ведь прежде, чем будет организована и проведена именно та опытная работа, и именно те эксперименты, которые подтвердят или опровергнут гипотезу исследователя, необходимо приобрести первоначальные умения планирования и организации опытно-экспериментальной работы, анализа и обобщения ее результатов. Кроме того, этот предварительный этап позволяет подобрать нужные подходы, отработать инструментарий и т.д.
Как уже говорилось, собственно опытно-экспериментальная работа в каждом конкретном исследовании сугубо специфична, поскольку целиком определяется содержанием конкретного исследования и вряд ли может быть описана в общем виде.
Необходимо остановиться лишь на применении методов математической статистики при обработке эмпирических результатов. Важно подчеркнуть, что как массовое явление в науках «слабой версии» распространена статистическая неграмотность. Так, в медицине, педагогике, психологии, социологии и т.д. как повсеместное явление применяется вычисление «среднего балла» при использовании ранговых шкал оценок. Что повергает в ужас любого человека мало-мальски знакомого с математикой: ведь на этих шкалах операция суммы не определена, а усреднение предполагает суммирование «баллов» и затем деление «суммы» на объем выборки! Об этих и других ошибках в манипулировании результатами писалось многократно (см., в том числе, обсуждение шкал измерений выше и в [168, 169, 183]). Но ошибки эти, к сожалению, укоренились и фактически перешли в традицию. Поэтому рассмотрим кратко типовые задачи анализа данных (результатов наблюдения и/или эксперимента) и используемые при решении этих задач статистические методы.
Статистические методы. При планировании и подведении результатов эксперимента существенную роль играют статистические методы, которые дают возможность:
- компактно и информативно описывать результаты эксперимента;
- устанавливать степень достоверности сходства и различия исследуемых объектов на основании результатов измерений их показателей;
- анализировать наличие или отсутствие зависимости между различными показателями (явлениями);
- количественно описывать эти зависимости;
- выявлять информативные показатели;
- классифицировать изучаемые объекты и прогнозировать значения их показателей и характеристик, и др.
Рассмотрим следующую модель эксперимента [168, 169]. Пусть имеется некоторый объект, изменение состояния которого исследуется в ходе эксперимента. В качестве объекта в медицине может выступать группа лабораторных животных, в педагогике – группа обучающихся, в экономике – множество предприятий отрасли или региона и т.д. Состояние объекта измеряется[26] теми или иными показателями (характеристиками) по критериям, отражающим его существенные характеристики. Примерами критериев являются:
- в медицине: выраженность интоксикации, выживаемость в группе животных на определенный период после начала опыта и т.д. Примерами характеристик – температура, активность тех или иных ферментов в биологических жидкостях, количественные показатели структуры внутренних органов и т.д.;
- в педагогике: успешность выполнения учащимися тестов, скорость выполнения контрольных заданий и т.д. Характеристики – число правильно решенных задач, время выполнения заданий и т.д.;
- в экономике: эффективность функционирования промышленного предприятия, темпы развития региональной экономики и т.д. Характеристики – годовая прибыль, уровень капитализации, валовой доход на душу населения и т.д.
Эксперимент заключается в целенаправленном воздействии на объект, призванном изменить его определенным образом. Примерами воздействия являются: любые методы воздействия на болезнь с целью ее излечения, хирургические манипуляции – в медицине; новые методы и/или средства обучения – в педагогике; параметры госрегулирования и/или управленческая политика руководства предприятия – в экономике и т.д.
Следовательно, при проведении эксперимента необходимо обосновать, что состояние объекта изменилось, причем в требуемую сторону. Но этого оказывается недостаточно. Ведь нужно доказать, что изменения произошли именно в результате произведенного воздействия (так называемая задача изучения сходства/различий – см. ниже).
Действительно, например, на утверждение о том, что в ходе медико-биологического эксперимента температура тела у экспериментального животного снизилась в результате использования нового испытуемого вещества, можно всегда возразить, – а, может быть, она снизилась бы сама, без каких-либо нововведений, или в результате каких-либо других воздействий? Аналогично, на утверждение о том, что скорость и степень снижения температуры у животных, которым вводился новый препарат, отличаются от того, как это происходило у животных, которых лечили с применением традиционных препаратов, можно возразить, – а, может быть, сама группа имела до начала эксперимента какие-то внутренние отличия, позволившие ей продемонстрировать подобные «успешные» результаты.
Таким образом, для того, чтобы выделить в явном виде результат целенаправленного воздействия на исследуемый объект, необходимо взять аналогичный объект и посмотреть, что происходит с ним в отсутствии воздействий.
Традиционно эти два объекта называют соответственно экспериментальной группой (иногда основной) и контрольной группой (или группой сравнения).
На Рис. 11 представлена в общем виде структура эксперимента (двойными пунктирными стрелками отмечены процедуры сравнения[27] характеристик объектов).
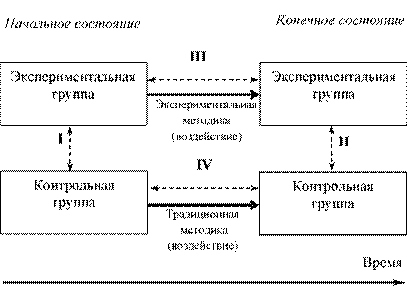
Рис. 11. Структура эксперимента
Констатации (в результате сравнения III – см. Рис. 11) различий начального и конечного состояний (динамики) экспериментальной группы недостаточно – быть может, аналогичные изменения происходят и с контрольной группой, что может быть установлено сравнением IV. Поэтому алгоритм действий исследователя заключается в следующем:
1) На основании сравнения I установить совпадение[28] начальных состояний экспериментальной и контрольной группы;
2) Реализовать воздействие на экспериментальную группу[29] по экспериментальной методике;
3) Реализвать воздействие на контрольную группу по традиционной методике;
4) На основании сравнения II установить различие конечных состояний экспериментальной и контрольной группы.
После выполнения четырех перечисленных шагов можно приступать к изучению зависимостей между различными характеристиками объектов (см. ниже).
Легко видеть, что, выполняя перечисленные шаги[30], мы, фактически, косвенным образом реализуем процедуру сравнения III, исключая влияние общих для экспериментальной и контрольной группы условий и воздействий.
Итак, мы описали задачу определения сходства/различий. На самом деле спектр задач анализа данных гораздо шире. Можно выделить следующие общие группы этих задач (см. Табл. 7):
1. Описание данных – компактное описание имеющихся данных с помощью различных агрегированных (обобщенных) показателей и графиков. К этому классу можно отнести также задачу определения необходимого объема выборки [31] (минимального числа исследуемых объектов), необходимого для того, чтобы сделать обоснованные выводы.
В практике научных исследований обычно имеется совокупность наблюдений (десятки, сотни, а иногда – тысячи результатов измерений индивидуальных характеристик), поэтому возникает задача компактного описания имеющихся данных. Для этого используют методы описательной статистики – описания результатов с помощью различных агрегированных показателей и графиков. Перечислим некоторые из них.
Табл. 7
Задачи анализа экспериментальных данных
| З А Д А Ч А | Описание данных | Изучение сходства/ различий | Исследование зависимостей | Снижение размерности | Классификация |
| М Е Т О Д Ы | - описательная статистика, - определение необходимого объема выборки. | Статистические критерии: Крамера-Уэлча, Вилкоксона-Манна-Уитни, ÷2, Фишера. | - корреляционный анализ, - дисперсионный анализ, - регрессионный анализ. | - факторный анализ, - метод главных компонент. | - дискриминантный анализ, - кластерный анализ, - группировка. |
Для результатов измерений в шкале отношений (см. описание шкал измерений выше) показатели описательной статистики можно разбить на несколько групп:
- показатели положения описывают положение экспериментальных данных на числовой оси. Примеры таких данных – максимальный и минимальный элементы выборки, среднее значение [32], медиана [33], мода [34] и др.;
- показатели разброса описывают степень разброса данных относительно своего центра (среднего значения). К ним относятся: выборочная дисперсия [35], разность между минимальным и максимальным элементами (размах, интервал выборки) и др.
- показатели асимметрии: положение медианы относительно среднего (величина разности их значений) и др.
- гистограмма [36] и др.
Данные показатели используются для наглядного представления и первичного («визуального») анализа результатов измерений характеристик экспериментальной и контрольной группы.
2. Изучение сходства/различий (сравнение двух выборок). Например, требуется установить, достоверно ли различие конечных состояний экспериментальной и контрольной группы в эксперименте (см. выше). Или, например, задача заключается в установлении совпадений или различий характеристик двух выборок (например, требуется установить, что средние значения доходов населения в двух регионах (или средние значения производительности труда в двух отраслях народного хозяйства и т.д.) совпадают или различаются). Для этого формулируются статистические гипотезы:
- гипотеза об отсутствии различий (так называемая нулевая гипотеза);
- гипотеза о значимости (достоверности) различий (так называемая альтернативная гипотеза).
Для принятия решения о том, какую из гипотез (нулевую или альтернативную) следует принять, используют решающие правила – статистические критерии [37]. То есть, на основании информации о результатах наблюдений (характеристиках членов экспериментальной и контрольной группы) по известным формулам (см., например, [183, 241]) вычисляется число, называемое эмпирическим значением критерия. Это число сравнивается с известным (например, заданным таблично в соответствующих книгах по математической статистике [183, 241]) эталонным числом, называемым критическим значением критерия.
Критические значения приводятся, как правило, для нескольких уровней значимости. Уровнем значимости называется вероятность ошибки, заключающейся в непринятии нулевой гипотезы, когда она верна, то есть вероятность того, что различия сочтены существенными, а они на самом деле случайны.
Обычно используют уровни значимости (обозначаемые á), равные вероятности 0,05, или 0,01, или 0,001. Или, переводя в проценты, выборки не различаются с вероятностями 5 %, 1 %, 0,1 %. Соответственно, вероятности того, что выборки различаются составят 0,95, 0,99, 0,999, или в процентах – 95 %, 99 % и 99,9 %. В экономических, педагогических, психологических, медико-биологических экспериментальных исследованиях обычно ограничиваются значением 0,05, то есть допускается не более чем 5 %-ая возможность ошибки (95 % уровень достоверности различий). В естественных, технических науках чаще требуются уровни достоверности различий 99 % или 99,9 %.
Если полученное исследователем эмпирическое значение критерия оказывается меньше или равно критическому, то принимается нулевая гипотеза – считается, что на заданном уровне значимости (то есть при том значении á, для которого рассчитано критическое значение критерия) характеристики экспериментальной и контрольной групп совпадают. В противном случае, если эмпирическое значение критерия оказывается строго больше критического, то нулевая гипотеза отвергается и принимается альтернативная гипотеза – характеристики экспериментальной и контрольной группы считаются различными с достоверностью различий 1 – á. Например, если á = 0,05 и принята альтернативная гипотеза, то достоверность различий равна 0,95 или 95%.
Другими словами, чем меньше эмпирическое значение критерия (чем левее оно находится от критического значения), тем больше степень совпадения характеристик сравниваемых объектов. И наоборот, чем больше эмпирическое значение критерия (чем правее оно находится от критического значения), тем сильнее различаются характеристики сравниваемых объектов.
Итак, если мы ограничимся уровнем значимости á = 0,05, то, если эмпирическое значение критерия оказывается меньше или равно критическому, то можно сделать вывод, что «характеристики экспериментальной и контрольной групп совпадают на уровне значимости 0,05». Если эмпирическое значение критерия оказывается строго больше критического, то можно сделать вывод, что «достоверность различий характеристик экспериментальной и контрольной групп равна 95%».
Приведем алгоритм выбора статистического критерия (см. Табл. 8). Во-первых, необходимо определить какая шкала измерений используется – отношений, порядковая или номинальная (см. выше).
Табл. 8
Алгоритм выбора статистического критерия
| Шкала измерений | Статистический критерий |
| Отношений | Крамера-Уэлча, Вилкоксона-Манна-Уитни |
| Порядковая | Вилкоксона-Манна-Уитни, ÷2 |
| Номинальная | ÷2 |
| Дихотомическая | Фишера |
Для шкалы отношений целесообразно использовать критерий Крамера-Уэлча. Если число различающихся между собой значений[38] в сравниваемых выборках велико (более десяти)[39], то возможно использование критерия Вилкоксона-Манна-Уитни. Более подробные рекомендации по выбору критериев в том или ином конкретном случае, а также описание этих критериев можно найти в [168, 183, 241]).
Для порядковой шкалы целесообразно использовать критерий Вилкоксона-Манна-Уитни, возможно также использование критерия ÷2.
Для номинальной шкалы следует использовать критерий ÷2.
Для дихотомической шкалы (номинальной шкалы с двумя возможными значениями) следует использовать критерий Фишера.
3. Исследование зависимостей. Следующим шагом после изучения сходства/различий является установление факта наличия/отсутствия зависимости между показателями и количественное описание этих зависимостей. Для этих целей используются, соответственно, корреляционный и дисперсионный анализ, а также регрессионный анализ [168, 241].
Корреляционный анализ. Корреляция (Correlation) – связь между двумя или более переменными (в последнем случае корреляция называется множественной). Цель корреляционного анализа – установление наличия или отсутствия этой связи, то есть установление факта зависимости каких-либо явлений, процессов друг от друга или их независимости.
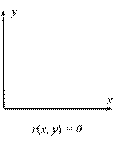
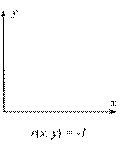
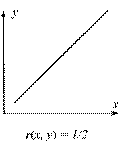
В случае, когда имеются две переменные, значения которых измерены в шкале отношений[40], используется коэффициент линейной корреляции Пирсона r, который принимает значения от -1 до +1 (нулевое его значение свидетельствует об отсутствии корреляции[41]) – см. Рис. 12, на котором каждая точка соответствует отдельному объекту, описываемому двумя переменным – x и y. Термин «линейный» свидетельствует о том, что исследуется наличие линейной связи между переменными – если r (x, y) = 1, то одна переменная линейно зависит от другой (и, естественно, наоборот), то есть существуют константы a и b, причем a > 0, такие что y = a x + b.
На Рис. 12а) и в) изображены ситуации, когда все экспериментальные точки лежат на прямой (абсолютное значение коэффициента линейной корреляции равно единице). В ситуации, изображенной на рисунке Рис. 12б), однозначно провести прямую через экспериментальные точки невозможно (коэффициент линейной корреляции равен нулю).
 а)
а)
|  б)
б)
|  в)
в)
| |
 г)
г)
| 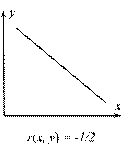 д)
д)
| ||
Рис. 12. Величины коэффициента линейной корреляции
в различных ситуациях
Если экспериментальные точки сгруппированы около некоторой прямой – см. Рис. 12г) и д), то коэффициент линейной корреляции принимает значения, отличные от нуля, причем чем «ближе» точки к прямой, тем выше абсолютное значение коэффициента линейной корреляции. То есть, чем выше абсолютное значение коэффициента Пирсона, тем сильнее исследуемые переменные линейно связаны между собой.
Для данных, измеренных в порядковой шкале, следует использовать коэффициент ранговой корреляции Спирмена (он может применяться и для данных, измеренных в интервальной шкале, так как является непараметрическим и улавливает тенденцию – изменения переменных в одном направлении), который обозначается s и определяется сравнением рангов – номеров значений сравниваемых переменных в их упорядочении.
 Рис. 13. Пример: коэффициент линейной корреляции (Пирсона) равен нулю для функционально (нелинейно и немонотонно) связанных переменных
Рис. 13. Пример: коэффициент линейной корреляции (Пирсона) равен нулю для функционально (нелинейно и немонотонно) связанных переменных
| Коэффициент корреляции Спирмена является менее чувствительным, чем коэффициент корреляции Пирсона (так как первый в случае измерений в шкале отношений учитывает лишь упорядочение элементов выборки). В то же время, он позволяет выявлять корреляцию между монотонно нелинейно связанными переменными (для которых коэффициент Пирсона может показывать незначительную корреляцию – см. Рис. 13). |
Отметим, что большое (близкое к плюс единице или к минус единице) значение коэффициента корреляции говорит о связи переменных, но ничего не говорит о причинно-следственных отношениях между ними. Так, например, из высокой корреляции температуры воздуха за окном и времени суток нельзя делать вывод о том, что движение солнца обусловлено изменениями температуры воздуха. Поэтому для установления причин связей между какими-либо явлениями, процессами необходимы дополнительные исследования по содержательной интерпретации этих связей.
Дисперсионный анализ. Изучение наличия или отсутствия зависимости между переменными можно также проводить и с помощью дисперсионного анализа. Его суть заключается в следующем. Дисперсия характеризует «разброс» значений переменной. Переменные связаны, если для объектов, отличающихся значениями одной переменной, отличаются и значения другой переменной. Значит, нужно для всех объектов, имеющих одно и то же значение одной переменной (называемой независимой переменной), посмотреть, насколько различаются (насколько велика дисперсия) значения другой (или других) переменной, называемой зависимой переменной. Дисперсионный анализ как раз и дает возможность сравнить отношение дисперсии зависимой переменной (межгрупповой дисперсии) с дисперсией внутри групп объектов, характеризуемых одними и теми же значениями независимой переменной (внутригрупповой дисперсией).
Другими словами, дисперсионный анализ «работает» следующим образом. Выдвигается гипотеза о наличии зависимости между переменными: например, между возрастом и уровнем образования сотрудников некоторой организации. Выделяются группы элементов выборки (сотрудников) с одинаковыми значениями независимой переменной – возраста, то есть сотрудников одного возраста (или принадлежащих выделенному возрастному диапазону). Если гипотеза о зависимости уровня образования от возраста верна, то значения зависимой переменной (уровня образования) внутри каждой такой группы должны различаться не очень сильно (внутригрупповая дисперсия уровня образования должна быть мала). Напротив, значения зависимой переменной для различающихся по возрасту групп сотрудников должны различаться сильно (межгрупповая дисперсия уровня образования должна быть велика). То есть, переменные зависимы, если отношение межгрупповой дисперсии к внутригрупповой велико. Если же гипотеза о наличии зависимости между переменными не верна, то это отношение должно быть мало.
Регрессионный анализ. Если корреляционный и дисперсионный анализ дают ответ на вопрос, существует ли взаимосвязь между переменными, то регрессионный анализ предназначен для того, чтобы найти «явный вид» функциональной зависимости между переменными. Для этого предполагается, что зависимая переменная (иногда называемая откликом) определяется известной функцией (иногда говорят – моделью), зависящей от зависимой переменной или переменных (иногда называемых факторами) и некоторого параметра. Требуется найти такие значения этого параметра, чтобы полученная зависимость (модель) наилучшим образом описывала имеющиеся экспериментальные данные. Например, в простой [42] линейной регрессии предполагается, что зависимая переменная y является линейной функцией y = a x + b от независимой переменной x. Требуется найти значения параметров a и b, при которых прямая a x + b будет наилучшим образом описывать (аппроксимировать) экспериментальные точки (x1, y1), (x2, y2), …, (xn, yn).
Можно использовать полиномиальную регрессию, в которой предполагается, что зависимая переменная является полиномом (многочленом) некоторой степени от независимой переменной (напомним, что линейная зависимость является полиномом первой степени). Например, полиномом второй степени (знакомая всем из школьного курса алгебры парабола) будет зависимость вида y = a x2 + b x + c и задачей регрессии будет нахождение коэффициентов a, b и c.
Выше мы рассмотрели простую регрессию (по одной независимой переменной) – линейную и нелинейную. Возможно также использование множественной регрессии – определения зависимости одной переменной от нескольких факторов (независимых переменных).
Регрессионный анализ, помимо того, что он позволяет количественно описывать зависимость между переменными, дает возможность прогнозировать значения зависимых переменных – подставляя в найденную формулу значения независимых переменных, можно получать прогноз значений зависимых. При этом следует помнить, что построенная модель «локальна», то есть, получена для некоторых вполне конкретных значений переменных. Экстраполяция результатов модели на более широкие области значений переменных может привести к ошибочным выводам.
4. Снижение размерности. Часто в результате экспериментальных исследований возникают большие массивы информации. Например, если каждый из исследуемых объектов описывается по нескольким критериям (измеряются значения нескольких переменных – признаков), то результатом измерений будет таблица с числом ячеек, равным произведению числа объектов на число признаков (показателей, характеристик). Возникает вопрос, а все ли переменные являются информативными. Конечно, исследователю желательно было бы выявить существенные переменные (это важно с содержательной точки зрения) и сконцентрировать внимание на них. Кроме того, всегда желательно сокращать объемы обрабатываемой информации (не теряя при этом сути). Чем тут могут помочь статистические методы?
Существует целый класс задач снижения размерности, цель которых как раз и заключается в уменьшении числа анализируемых переменных либо посредством выделения существенных переменных, либо/и построения новых показателей (на основании полученных в результате эксперимента).
Для снижения размерности используется факторный анализ, а основными методами являются кратко рассматриваемый ниже метод главных компонент и многомерное шкалирование [183].
Метод главных компонент заключается в получении нескольких новых показателей – главных компонент, являющихся линейными комбинациями исходных показателей (напомним, что линейной комбинацией называется взвешенная сумма), полученных в результате эксперимента. Главные компоненты упорядочиваются в порядке убывания той дисперсии, которую они «объясняют». Первая главная компонента объясняет бóльшую часть дисперсии, чем вторая, вторая – бóльшую, чем третья и т.д. Понятно, что чем больше главных компонент будет учитываться, тем большую часть изменений можно будет объяснить.
Преимущество метода главных компонент заключается в том, что зачастую первые несколько главных компонент (одна-две-три) объясняют бóльшую часть (например, 80-90 %) изменений большого числа (десятков, а иногда и сотен) показателей. Кроме того, может оказаться, что в первые несколько главных компонент входят не все исходные параметры. Тогда можно сделать вывод о том, какие параметры являются существенными, и на них следует обратить внимание в первую очередь.
Решив задачи описания данных, установления сходства/отличий, проанализировав качественно и количественно зависимости между переменными и выявив существенные переменные, можно анализировать соотношение групп переменных и пытаться прогнозировать значения одних переменных в зависимости от значений других переменных или времени развития того или иного процесса.
5. Классификация. Обширную группу задач анализа данных, основывающихся на применении статистических методов, составляют так называемые задачи классификации. В близких смыслах (в зависимости от предметной области) используются также термины: «группировка», «систематизация», «таксономия», «диагностика», «прогноз», «принятие решений», «распознавание образов». Обсудим некоторые различия между этими терминами. В [183] предложено выделить три подобласти теории классификации: дискриминация (дискриминантный анализ), кластеризация (кластерный анализ) и группировка. Здесь мы кратко остановимся на сути этих методов. Тех же читателей, которые заинтересуются, как ими пользоваться, мы адресуем к соответствующей литературе [183, 241].
Дата добавления: 2016-01-04; просмотров: 15; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!