Общий вид концептуальной модели программы
Общий вид концептуальной модели программы представлен на следующем рисунке:

 | |




 | |||
 | |||
Рисунок 1 – Общая концепция программы
Из концепции следует, что проектируемая программа поблочно захватывает звук со звуковой карты, посредством звуковой библиотеки PyAudio. Далее блок данных записанного звука передается на обработку, для получения спектра. Спектр сигнала вычисляется посредством специализированной библиотеки scipy . signal. Стоит отметить, что следующий блок записывается одновременно с процессом обработки текущего блока данных. После завершения преобразования содержимого блока данных в спектр он передается на последнюю ступень, для его визуального отображения.
Детализированная концептуальная модель программы
Подробная концептуальная модель представлена на рисунке 2:


| |
 |

 |


 |


 | |||||
 | |||||
 | |||||

 |


| |
Проектирование программы
Разработка интерфейса
Интерфейс программы содержит два графика: верхний график спектрограммы частоты от времени (рисунок 3) и график звуковой волны амплитуды от времени (рисунок 4).
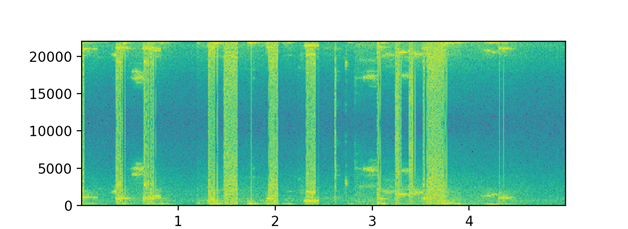
Рисунок 3 – Спектрограмма частоты от времени

Рисунок 4 – Спектрограмма амплитуды от времени
Кодирование программы
import pyaudioimport numpy as np
import scipy.signal as signal
import matplotlib.pyplot as plt
import time
import keyboard
'''
timer_begin = time.time()
timer_end = time.time()
timer_secs = timer_end - timer_begin
times_msecs = timer_secs * 1000
print('Затраченное время: %f ms', times_msecs)
'''
CHANNELS = 1
RATE = 44100
WAVE_OUTPUT_FILENAME = "output.wav"
FORMAT = pyaudio.paInt16
CHUNK = 1024
p = pyaudio.PyAudio()
RECORD_SECONDS = 10
SOUND_BUFFER_SIZE = int(RATE * RECORD_SECONDS)
soundBuffer = np.zeros(SOUND_BUFFER_SIZE)
timer_begin = time.time()
PAUSE = False
def callback(in_data, frame_count, time_info, status):
global soundBuffer
data = np.frombuffer(in_data, dtype='b')
#data = np.frombuffer(in_data)
shift = data.size
if PAUSE == False:
soundBuffer = np.roll(soundBuffer, -shift, axis=0)
np.put(soundBuffer, range(len(soundBuffer) - shift, len(soundBuffer)), data)
return in_data, pyaudio.paContinue
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
output=False,
input=True,
frames_per_buffer=CHUNK,
stream_callback=callback)
stream.start_stream()
SIZE = int(SOUND_BUFFER_SIZE/2)
#SIZE = 1000
#[(SOUND_BUFFER_SIZE-SIZE):SOUND_BUFFER_SIZE]
fig, (ax1, ax2) = plt.subplots(2)
STEP = int(SIZE/100)
#STEP = 500
def plus():
global SIZE
SIZE += STEP
if SIZE > SOUND_BUFFER_SIZE:
SIZE = SOUND_BUFFER_SIZE
def minus():
global SIZE
SIZE -= STEP
if SIZE < 64:
SIZE = 64
def stop():
global LOOP
LOOP = False
def pause():
global PAUSE
PAUSE = not PAUSE
LOOP = True
keyboard.add_hotkey('Ctrl + -', plus)
keyboard.add_hotkey('Ctrl + =', minus)
keyboard.add_hotkey('Ctrl + 1', stop)
keyboard.add_hotkey('Ctrl + 2', pause)
while LOOP:
_nperseg = int(SIZE/500)
if _nperseg < 10:
_nperseg = 10
# timer_begin = time.time()
f, t, Sxx = signal.spectrogram(soundBuffer[(SOUND_BUFFER_SIZE-SIZE):SOUND_BUFFER_SIZE], fs=RATE, nperseg = _nperseg)
dBS = 10 * np.log10(Sxx)
# timer_end = time.time()
# timer_secs = timer_end - timer_begin
# times_msecs = timer_secs * 1000
ax1.cla()
ax2.cla()
ax2.set_ylim(-100, 100)
# ax2.set_xlim(0, 20)
ax1.pcolormesh(t, f, dBS)
ax2.plot(soundBuffer[(SOUND_BUFFER_SIZE-SIZE):SOUND_BUFFER_SIZE])
plt.pause(0.01)
#print('Затраченное время: %f ms', times_msecs)
Дата добавления: 2023-01-08; просмотров: 41; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!