Support Vector Machine Model Report
Meta data
Relation: systema_pogshennya.symbolic
Contains 5 attributes:
- процентная_ставка, type = categorical
- высокая
- средняя
- низкая
- период_предоставления, type = categorical
- десять_лет
- двадцать_лет
- тридцать_лет
- прописка, type = categorical
- киевская
- не_киевская
- история_клиента, type = categorical
- позитивная
- негативная
- отсутствует
- ипотечный_кредит, type = categorical
- давать
- не_давать
Number of support vectors: 14
- высокая,десять_лет,не_киевская,негативная,не_давать
- высокая,двадцать_лет,киевская,негативная,не_давать
- высокая,тридцать_лет,киевская,позитивная,давать
- высокая,десять_лет,киевская,позитивная,давать
- высокая,двадцать_лет,киевская,позитивная,давать
- высокая,двадцать_лет,не_киевская,негативная,не_давать
- высокая,десять_лет,не_киевская,отсутствует,не_давать
- высокая,тридцать_лет,киевская,позитивная,давать
- высокая,тридцать_лет,киевская,позитивная,давать
- высокая,тридцать_лет,не_киевская,отсутствует,не_давать
- высокая,тридцать_лет,киевская,позитивная,давать
- высокая,двадцать_лет,не_киевская,негативная,не_давать
- высокая,десять_лет,не_киевская,негативная,не_давать
- высокая,десять_лет,не_киевская,негативная,не_давать
Number of coefficients: 14
- 1.0
- 1.0
- 1.0
- 0.5286220512935731
- 1.0
- -1.0
- -1.0
- -1.0
- -1.0
- -0.5286220512935731
- -1.0
- -1.0
- -1.0
- -1.0
Absolute coefficient: 0.24987490475177765
Найгіршими варіантами здійснення операції давати чи не давати є пункти з позитивним числами. А найкращими варіантами є пункти з негативними числами.
|
|
|
Найгіршим варіантом не_давати є пункт 6.7.8.9.11.12.13.14.15, а найкращим варіантом є пункти 1.2.3.4.5.
Реализация алгоритмов построения unsupervised моделей
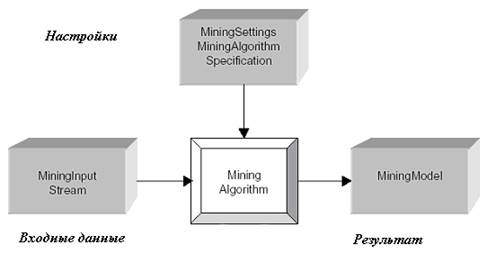
Б і бл і отека алгоритм ів.
Apriori TID на основании реализации алгоритма Apriori в Xelopes

Алгоритм KMeans
Дивизимный алгоритм кластеризации
Аггломеративный алгоритм кластеризации
Контрольные вопросы
- Что такое u nsupervised модели.
UnsupervisedMiningModel є базовою моделлю для всіх керував моделі інтелектуального аналізу даних і, отже,
не містить спеціальних реалізації моделі.
Він не забезпечує реалізацію applyModel метод. Реалізація
applyModelFunction має дуже загальний характер. Давайте подивимося, як вона працює.
UnsupervisedMiningModel містить класифікатор як внутрішня мінлива класифікатора.
класифікатора представлена через простий інтерфейс класифікатором (вже згадувалося вище), які
У свою чергу, містить метод застосовується:
public interface Classifier
{
public double apply(MiningVector miningVector) throws MiningException;
}
Таким чином, applyModelFunction метод SupervisedMiningModel просто викликає застосовувати в
класифікатор:
public double applyModelFunction(MiningVector miningVector)
throws MiningException
{
// Run inner transformations (e.g. missing values replacement,
|
|
|
outlier treatment):
if (miningTransform != null) {
MiningVector transMiningVec = miningTransform.transform(
miningVector);
transMiningVec.setMetaData( miningTransform.transform(
miningVector.getMetaData()) );
miningVector = transMiningVec;
};
// Apply classifier:
return classifier.apply( miningVector );
}
Наступні зауваження важливі для правильного застосування керував моделі інтелектуального аналізу даних для
Нові дані:
1. MiningVector передається applyModelFunction повинні мати ті ж мета-дані, як
потік гірської введення даних для навчання. Тим більше, вона повинна містити
класифікація атрибутів, навіть якщо вона не містить значущих цінностей.
2. З еквівалентності мета-даних в 1. Крім того, він випливає, що якщо навчання даних
була перетворена зовнішні перетворення, перш ніж buildModel був викликаний метод,
Потім miningVector (одного і того ж мета-дані в якості навчальних даних) також повинні бути
перетвориться ж зовнішньої трансформації. Найпростіше це можна зробити,
наступна конструкція:
MiningVector miningVector = miningVector0;
if ( modelMetaData.isTransformed() ) {
miningVector = modelMetaData.getMiningTransformationActivity().
transform(miningVector0);
};
Тут miningVector0 є видобуток вектора, забив який має той же мета-дані
в якості навчальних даних. Тепер miningVector є вектором, який насправді передається
applyModelFunction. ModelMetadata є мета-дані контролюється видобуток
Модель (зберігається в гірській настройки моделі). Якщо мета-даних не було
трансформуються, ми можемо працювати з вихідними даними, в іншому випадку до miningVector0 ж
зовнішні перетворення, щоб навчання дані повинні бути застосовані. Таким же чином, статична
і динамічних перетворень може бути застосована до видобутку вхідні потоки гірських векторів
щоб бути зарахований.
3. Метод застосовується в XELOPES 1,0-раніше підтримується у версії 1.1. Він закликає
applyModelFunction методом внутрішньо. Метод застосовується позначений як застарілий
і applyModelFunction повинні використовуватися замість цього.
4. Метод applyModel кидає виняток у SupervisedMiningModel (а також в
більшість її реалізації), так як потрібно функціональність вже повністю знаходиться в
applyModelFunction.
|
|
|
Деякі керував моделі інтелектуального аналізу даних, особливо дерева рішень, мають менш обмежувальним
Вимоги по мета-дані нових векторів даних (наприклад, різна кількість атрибутів,
немає цільового атрибута потрібно). Тим не менш, особливо з-за перетворення, які в основному
використовується, переконайтеся, що мета-дані з додатків і навчальних даних має таку ж структуру
(Використовується також трансформувати методи пакет Transform для цього).
|
|
|
- Что такое описательные модели.


- Какие модели относятся к типу u nsupervised.
MiningVector передається applyModelFunction повинні мати ті ж мета-дані, як
потік гірської введення даних для навчання. Тим більше, вона повинна містити
класифікація атрибутів, навіть якщо вона не містить значущих цінностей.
2. З еквівалентності мета-даних в 1. Крім того, він випливає, що якщо навчання даних
була перетворена зовнішні перетворення, перш ніж buildModel був викликаний метод,
Потім miningVector (одного і того ж мета-дані в якості навчальних даних) також повинні бути
перетвориться ж зовнішньої трансформації. Найпростіше це можна зробити,
наступна конструкція:
MiningVector miningVector = miningVector0;
if ( modelMetaData.isTransformed() ) {
miningVector = modelMetaData.getMiningTransformationActivity().
transform(miningVector0);
};
Тут miningVector0 є видобуток вектора, забив який має той же мета-дані
в якості навчальних даних. Тепер miningVector є вектором, який насправді передається
applyModelFunction. ModelMetadata є мета-дані контролюється видобуток
Модель (зберігається в гірській настройки моделі). Якщо мета-даних не було
трансформуються, ми можемо працювати з вихідними даними, в іншому випадку до miningVector0 ж
зовнішні перетворення, щоб навчання дані повинні бути застосовані. Таким же чином, статична
і динамічних перетворень може бути застосована до видобутку вхідні потоки гірських векторів
щоб бути зарахований.
3. Метод застосовується в XELOPES 1,0-раніше підтримується у версії 1.1. Він закликає
applyModelFunction методом внутрішньо. Метод застосовується позначений як застарілий
і applyModelFunction повинні використовуватися замість цього.
4. Метод applyModel кидає виняток у SupervisedMiningModel (а також в
більшість її реалізації), так як потрібно функціональність вже повністю знаходиться в
applyModelFunction.
- Какие существуют алгоритмы поиска ассоциативных
Правил
Клас SupervisedMiningAlgorithm є базовим класом для всіх керував алгоритмів інтелектуального аналізу даних.
Вона поширюється по ClassificationAlgorithm, який, у свою чергу, слугує базовим класом для всіх
алгоритмів класифікації, а також RegressionAlgorithm, базовий клас для всіх регресії
алгоритмів. Ми рекомендуємо здійснювати всі класифікації і регресії алгоритмів від одного з
цими двома класами, а не з SupervisedMiningAlgorithm безпосередньо.
З SupervisedMiningAlgorithm носить досить загальний характер, воно містить лише такі внутрішні
змінних:
Мінлива Опис ім'я
цільової MiningAttribute для цільового атрибута
confidenceAttributeName Ім'я довіри атрибут
predictedAttributeName Назва прогнозованого атрибута
costFunction Назва функція вартості
Ці змінні (охоронюваних типу), можуть бути використані алгоритми розширення
SupervisedMiningAlgorithm.
SupervisedMiningAlgorithm переписує метод setMiningSettings з MiningAlgorithm по
Реалізація цього методу для навчання з учителем. Зокрема, він перевіряє, чи є
MiningSettings відносяться до типу SupervisedMiningSettings.
Далі SupervisedMiningAlgorithm містить абстрактні методи і buildModel
runAlgorithm.
Абстрактний метод
protected abstract Classifier getClassifier();
повертає класифікатор
- Какие существуют алгоритмы сиквенциального анализа.
Целью сиквенциального анализа алгоритмов является нахождение оптимального алгоритма для решения данной задачи. В качестве критерия оптимальности алгоритма выбирается трудоемкость алгоритма, понимаемая как количество элементарных операций, которые необходимо выполнить для решения задачи с помощью данного алгоритма. Функцией трудоемкости называется отношение, связывающие входные данные алгоритма с количеством элементарных операций.
Трудоёмкость алгоритмов по-разному зависит от входных данных. Для некоторых алгоритмов трудоемкость зависит только от объема данных, для других алгоритмов — от значений данных, в некоторых случаях порядок поступления данных может влиять на трудоемкость. Трудоёмкость многих алгоритмов может в той или иной мере зависеть от всех перечисленных выше факторов.
Одним из упрощенных видов анализа, используемых на практике, является асимптотический анализ алгоритмов. Целью асимптотического анализа является сравнение затрат времени и других ресурсов различными алгоритмами, предназначенными для решения одной и той же задачи, при больших объемах входных данных. Используемая в асимптотическом анализе оценка функции трудоёмкости, называемая сложностью алгоритма, позволяет определить, как быстро растет трудоёмкость алгоритма с увеличением объема данных. В асимптотическом анализе алгоритмов используются обозначения, принятые в математическом асимптотическом анализе. Ниже перечислены основные оценки сложности.
Основной оценкой функции сложности алгоритма f(n) является оценка 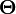 . Здесь n — величина объёма данных или длина входа. Мы говорим, что оценка сложности алгоритма
. Здесь n — величина объёма данных или длина входа. Мы говорим, что оценка сложности алгоритма
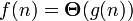
если при g > 0 при n > 0 существуют положительные с1, с2, n0, такие, что:
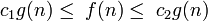
при n > n0, иначе говоря, можно найти такие с1 и c2, что при достаточно больших n f(n) будет заключена между
 и
и 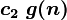 .
.
В таком случае говорят еще, что функция g(n) является асимптотически точной оценкой функции f(n), так как по определению функция f(n) не отличается от функции g(n) с точностью до постоянного множителя (см. асимптотическое равенство). Например, для метода сортировки heapsort оценка трудоёмкости составляет
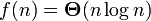 то есть g(n) = nlog n
то есть g(n) = nlog n
Из следует, что 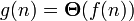 .
.
Важно понимать, что  представляет собой не функцию, а множество функций, описывающих рост
представляет собой не функцию, а множество функций, описывающих рост 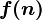 с точностью до постоянного множителя.
с точностью до постоянного множителя.
дает одновременно верхнюю и нижнюю оценки роста функции. Часто бывает необходимо рассматривать эти оценки по отдельности. Оценка 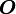 представляет собой верхнюю асимптотическую оценку трудоемкости алгоритма. Мы говорим, что
представляет собой верхнюю асимптотическую оценку трудоемкости алгоритма. Мы говорим, что 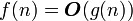 если
если
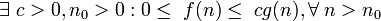
Иначе говоря, запись означает, что f(n) принадлежит классу функций, которые растут не быстрее, чем функция g(n) с точностью до постоянного множителя.
Оценка 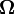 задает нижнюю асимптотическую оценку роста функции f(n) и определяет класс функций, которые растут не медленнее, чем g(n) с точностью до постоянного множителя.
задает нижнюю асимптотическую оценку роста функции f(n) и определяет класс функций, которые растут не медленнее, чем g(n) с точностью до постоянного множителя.  если
если

Например, запись 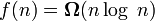 обозначает класс функций, которые растут не медленнее, чем
обозначает класс функций, которые растут не медленнее, чем 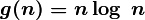 , в этот класс попадают все полиномы со степенью большей единицы, равно как и все степенные функции с основанием большим единицы. Равенство выполняется тогда и только тогда, когда и .
, в этот класс попадают все полиномы со степенью большей единицы, равно как и все степенные функции с основанием большим единицы. Равенство выполняется тогда и только тогда, когда и .
Асимптотический анализ алгоритмов имеет не только практическое, но и теоретическое значение. Так, например, доказано, что все алгоритмы сортировки, основанные на попарном сравнении элементов, отсортируют n элементов за время, не меньшее 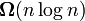 .
.
Важную роль в развитии асимптотического анализа алгоритмов сыграли A. Ахо, Дж. Ульман, Дж. Хопкрофт.
- В чем идея алгоритма KMeans.
K-means
Материал из Википедии — свободной энциклопедии
k-means (иногда называемый k-средних) - наиболее популярный метод кластеризации. Был изобретён в 1950-х математиком Г. Штейнгаузом[1] и почти одновременно С. Ллойдом[2]. Особую популярность приобрёл после работы МакКвина[3].
Действие алгоритма таково, что он стремится минимизировать суммарное квадратичное уклонение точек кластеров от центров этих кластеров:

где k - число кластеров, Si - полученные кластеры, 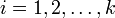 и μi - центры масс векторов
и μi - центры масс векторов 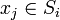 .
.
По аналогии с методом главных компонент центры кластеров называются также главными точками, а сам метод называется методом главных точек[4] и включается в общую теорию главных объектов, обеспечивающих наилучшую аппроксимацию данных
Алгоритм
Алгоритм представляет собой версию EM-алгоритма, применяемого также для разделения смеси гауссиан. Он разбивает множество элементов векторного пространства на заранее известное число кластеров k.
Основная идея заключается в том, что на каждой итерации перевычисляется центр масс для каждого кластера, полученного на предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с тем, какой из новых центров оказался ближе по выбраной метрике.
Алгоритм завершается, когда на какой-то итерации не происходит изменения кластеров. Это происходит за конечное число итераций, так как количество возможных разбиений конечного множество конечно, а на каждом шаге суммарное квадратичное уклонение V уменьшается, поэтому зацикливание невозможно.
Как показали Д.Артур и С.Вассилвицкий, на некоторых классах множеств сложность алгоритма по времени, нужному для сходимости, равна 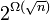 .[6]
.[6]
Проблемы k-means
- Не гарантируется достижение глобального минимума суммарного квадратичного уклонения V, а только одного из локальных минимумов.
- Результат зависит от выбора исходных центров кластеров, их оптимальный выбор неизвестен.
- Число кластеров надо знать заранее.
Расширения и вариации
Широко известна и используется нейросетевая реализация K-means - сети векторного квантования сигналов (одна из версий нейронных сетей Кохонена).
- Какие существуют дивизимные алгоритмы и чем они отличаются друг от друга.
Среди алгоритмов иерархической кластеризации различаются два основных ти-
па. Дивизимные или нисходящие алгоритмы разбивают выборку на всё более и более
мелкие кластеры. Более распространены агломеративные или восходящие алгорит-
мы, в которых объекты объединяются во всё более и более крупные кластеры. Реа-
лизация этой идеи представлена в Алгоритме 1.5.
Сначала каждый объект считается отдельным кластером. Для одноэлементных
кластеров естественным образом определяется функция расстояния
R({x}, {x′}) = ρ(x, x′).
Затем запускается процесс слияний. На каждой итерации вместо пары самых
близких кластеров U и V образуется новый кластер W = U ∪V . Расстояние от нового
кластера W до любого другого кластера S вычисляется по расстояниям R(U, V ),
R(U, S) и R(V, S), которые к этому моменту уже должны быть известны:
R(U ∪ V, S) = αUR(U, S) + αV R(V, S) + βR(U, V ) + γ|R(U, S) − R(V, S)|,
где αU, αU, β, γ _ числовые параметры. Эта универсальная формула обобщает прак-
тически все разумные способы определить расстояние между кластерами. Она была
предложена Лансом и Уильямсом в 1967 году [8, 6].
На практике используются следующие способы вычисления расстояний R(W, S)
между кластерами W и S. Для каждого из них доказано соответствие.
- Какие существуют аггломеративные алгоритмы и чем они отличаются друг от друга.
Более распространены агломеративные или восходящие алгорит-
мы, в которых объекты объединяются во всё более и более крупные кластеры.
Сначала каждый объект считается отдельным кластером. Для одноэлементных
кластеров естественным образом определяется функция расстояния
R({x}, {x′}) = ρ(x, x′).
Затем запускается процесс слияний. На каждой итерации вместо пары самых
близких кластеров U и V образуется новый кластер W = U ∪V . Расстояние от нового
кластера W до любого другого кластера S вычисляется по расстояниям R(U, V ),
R(U, S) и R(V, S), которые к этому моменту уже должны быть известны:
R(U ∪ V, S) = αUR(U, S) + αV R(V, S) + βR(U, V ) + γ|R(U, S) − R(V, S)|,
где αU, αU, β, γ _ числовые параметры. Эта универсальная формула обобщает прак-
тически все разумные способы определить расстояние между кластерами. Она была
предложена Лансом и Уильямсом в 1967 году [8, 6].На практике используются следующие способы вычисления расстояний R(W, S)
между кластерами W и S.
Висновок:
При виконанні цієї практичної роботи було отримані навички роботи з бібліотекою data mining алгоритмів Xelopes та прийшов до висновку що при роботі з цією бібліотекою дуже зручно працювати при інтелектуальному аналізі данних.
В цій практичній роботі я вивчив основни побудови
| Apriori TID на основании реализации алгоритма Apriori в Xelopes |
| Алгоритм KMeans |
| Дивизимный алгоритм кластеризации |
Також при виконанні цієї роботи було вивчено та практично застосовано різні види алгоритмів, виконано застосування різних параметрів налаштування для різних моделей.
Тому при роботі з цією бібліотекою, на мою думку, дуже просто і зручно працювати.
Дата добавления: 2022-12-03; просмотров: 22; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!