Двухфакторная дисперсионная модель.
Двухфакторная дисперсионная модель имеет вид:
xijk =μ+Fi +Gj +Iij +εijk , (15)
где xijk - значение наблюдения в ячейке ij с номером k;
μ - общая средняя;
Fi - эффект, обусловленный влиянием i-го уровня фактора А;
Gj - эффект, обусловленный влиянием j-го уровня фактора В;
Iij - эффект, обусловленный взаимодействием двух факторов, т.е. отклонение от средней по наблюдениям в ячейке ij от суммы первых трех слагаемых в модели (15);
εijk - возмущение, обусловленное вариацией переменной внутри отдельной ячейки.
Предполагается, что εijk имеет нормальный закон распределения N(0; с2 ), а все математические ожидания F* , G* , Ii * , I* j равны нулю.
Групповые средние находятся по формулам:
- в ячейке:
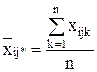 ,
,
- по строке:
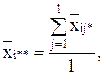
- по столбцу:
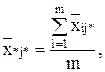
- общая средняя:
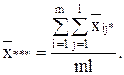
В таблице 1 представлен общий вид вычисления значений, с помощью дисперсионного анализа.
Таблица 1.2 – Базовая таблица дисперсионного анализа
| Компоненты дисперсии | Сумма квадратов | Число степеней свободы | Средние квадраты |
| Межгрупповая (фактор А) | 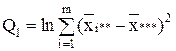
| m-1 | 
|
| Межгрупповая (фактор B) | 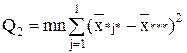
| l-1 | 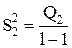
|
| Взаимодействие | 
| (m-1)(l-1) | 
|
| Остаточная | 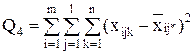
| mln - ml | 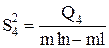
|
| Общая | 
| mln - 1 |
Проверка нулевых гипотез HA , HB , HAB об отсутствии влияния на рассматриваемую переменную факторов А, B и их взаимодействия AB осуществляется сравнением отношений 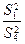 ,
,  ,
, 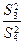 (для модели I с фиксированными уровнями факторов) или отношений
(для модели I с фиксированными уровнями факторов) или отношений  ,
, 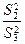 , (для случайной модели II) с соответствующими табличными значениями F – критерия Фишера – Снедекора. Для смешанной модели III проверка гипотез относительно факторов с фиксированными уровнями производится также как и в модели II, а факторов со случайными уровнями – как в модели I.
, (для случайной модели II) с соответствующими табличными значениями F – критерия Фишера – Снедекора. Для смешанной модели III проверка гипотез относительно факторов с фиксированными уровнями производится также как и в модели II, а факторов со случайными уровнями – как в модели I.
|
|
|
Если n=1, т.е. при одном наблюдении в ячейке, то не все нулевые гипотезы могут быть проверены так как выпадает компонента Q3 из общей суммы квадратов отклонений, а с ней и средний квадрат  , так как в этом случае не может быть речи о взаимодействии факторов.
, так как в этом случае не может быть речи о взаимодействии факторов.
С точки зрения техники вычислений для нахождения сумм квадратов Q1 , Q2 , Q3 , Q4 , Q целесообразнее использовать формулы:
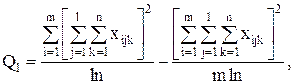
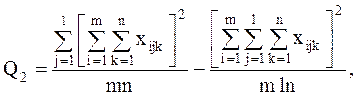


Q3 = Q – Q1 – Q2 – Q4 .
Отклонение от основных предпосылок дисперсионного анализа — нормальности распределения исследуемой переменной и равенства дисперсий в ячейках (если оно не чрезмерное) — не сказывается существенно на результатах дисперсионного анализа при равном числе наблюдений в ячейках, но может быть очень чувствительно при неравном их числе. Кроме того, при неравном числе наблюдений в ячейках резко возрастает сложность аппарата дисперсионного анализа. Поэтому рекомендуется планировать схему с равным числом наблюдений в ячейках, а если встречаются недостающие данные, то возмещать их средними значениями других наблюдений в ячейках. При этом, однако, искусственно введенные недостающие данные не следует учитывать при подсчете числа степеней свободы.
|
|
|
Прикладные программы.
Благодаря автоматизации дисперсионного анализа исследователь может проводить различные статистические исследования, затрачивая при этом меньше времени и усилий на расчеты данных. В настоящее время существует множество пакетов прикладных программ, в которых реализован аппарат дисперсионного анализа. Наиболее распространенными являются такие программные продукты как:
- MSExcel;
- Statistica;
- Stadia;
- SPSS.
В современных статистических программных продуктах реализованы большинство статистических методов. С развитием алгоритмических языков программирования стало возможным создавать дополнительные блоки по обработке статистических данных.
Дата добавления: 2022-06-11; просмотров: 18; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!