Перспективы развития объектного подхода
Тема 17. ОСНОВНЫЕ ПОНЯТИЯ СИСТЕМ БАЗ ДАННЫХ И ИХ СИСТЕМ УПРАВЛЕНИЯ
1. Базы данных и их представление в ЭВМ.
2. Реляционные базы данных. Структурные элементы базы данных.
3. Системы управления базами данных (СУБД). Классификация СУБД.
1 База данных (БД) это данные, организованные в виде набора записей определенной структуры и хранящиеся в файлах, где, помимо самих данных, содержится описание их структуры.
Еще одно определение: базы данных - это совокупность взаимосвязанных данных на машинном носителе, организованная определённым образом. Основным назначением баз данных является быстрый поиск содержащейся в них информации.
Логическую структуру данных, хранимых в базе, называют моделью представления данных.
По моделям представления данных базы данных делят на:
- иерархические или древовидные
- сетевые
- реляционные
- объектно-реляционные
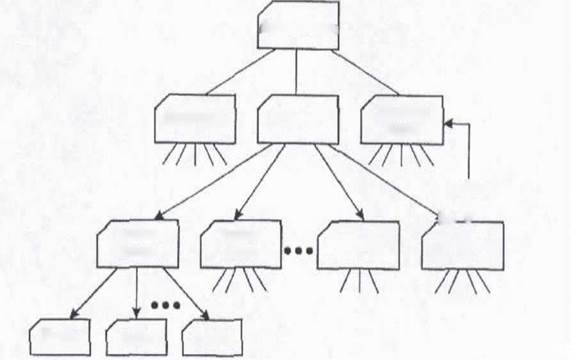
Иерархические базы данных это самая первая модель представления данных, в которой все записи базы данных представлены в виде дерева, с отношениями предок-потомок. В такой модели исходные элементы порождают другие элементы, причем эти элементы в свою очередь порождают следующие элементы и т.д. Существенно то, что каждый порожденный элемент имеет только одного «родителя». Физически данные отношения реализуются в виде указателей на предков и потомков, содержащихся в самой записи. Такая модель представления данных связана с тем, что на ранних этапах базы данных часто использовались для планирования производственного процесса: каждое выпускаемое изделие состоит из узлов, каждый узел из деталей и т.п. Для того чтобы знать сколько деталей каждого вида надо заказать, строилось дерево (см. рис. 1). Поскольку список составных частей изделия представлял из себя дерево, то для его хранения в базе данных наилучшим образом подходила иерархическая модель организации данных.
|
|
|
|
|
 |  |  | |||
Рис. 1.1. Иерархическая база данных.
Однако иерархическая модель не является оптимальной. Допустим, что один и тот же тип болтов используется в автомобиле 300 раз в различных узлах. При использовании иерархической модели, данный тип болтов будет фигурировать в базе данных не 1 раз, а 300 раз (в каждом узле - отдельно). Налицо дублирование информации. Чтобы устранить этот недостаток была введена сетевая модель представления данных.
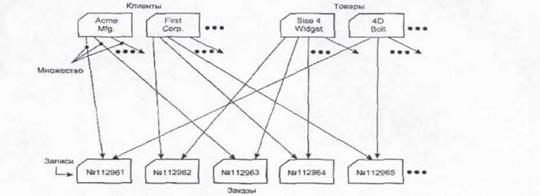
Рис 2. Сетевая база данных.
Сетевая база данных - это база данных, в которой одна запись может участвовать в нескольких отношениях предок-потомок (см. рис. 2). Т.е. фактически, база данных представляет собой не дерево, а граф. Сетевая модель данных отличается от иерархической тем, что каждый элемент сетевой структуры данных связан с любым другим элементом. Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа.
|
|
|
Физически данная модель также реализуется за счет хранящихся внутри самой записи указателей на другие записи, только, в отличие от иерархической модели, число этих указателей может быть произвольным.
Достоинством сетевой модели данных является возможность ее эффективной реализации. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей.
Недостатком сетевой модели данных является высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность ее понимания обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей из-за допустимости установления произвольных связей между записями.
Базы данных на основе сетевой модели не получили широкого распространения на практике.
И иерархическая и сетевая модель достаточно просты, однако они имеют общий недостаток: для того, чтобы получить ответ даже на простой вопрос, программист был должен написать программу, которая просматривала базу данных, двигаясь по указателям от одной записи к другой. Написание программы занимало некоторое время, и часто к тому моменту, когда такая программа была написана, необходимость в получении данных уже отпадала. Поэтому в середине 80-х годов 20 века произошел практически повсеместный переход к реляционным базам данных.
|
|
|
Реляционная модель данных была предложена сотрудником фирмы IBM Эдгаром Коддом и основывается на понятии отношения.
Отношение представляет собой множество элементов, называемых кортежами. Наглядной формой представления отношения является двумерная таблица.
То есть, в реляционных базах данных информация хранится в одной или нескольких таблицах. Связь между таблицами осуществляется по средствам значений одного или нескольких совпадающих полей.
Основными недостатками реляционной модели являются следующие: -отсутствие стандартных средств идентификации отдельных записей, - сложность описания иерархических и сетевых связей.
Объектно-реляционные базы данных появились в последнее время у значительного числа производителей СУБД (Oracle, Informix, PostgrcSQL) и сочетают в себе реляционную модель данных с концепциями объектно-ориентированного программирования (полиморфизм, инкапсуляция, наследование).
|
|
|
По технологии обработки данных базы данных подразделяются на централизованные и распределённые.
Централизованные базы данных хранятся в памяти одной вычислительной системы. Если эти данные являются компонентом сети ЭВМ, возможен распределённый доступ к такой базе. Такой способ использования баз данных часто применяют в локальных сетях ПК.
Распределённая база данных состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети.
По способу доступа к данным базы данных распределяются на базы данных с локальным доступом и базы данных с удалённым (сетевым) доступом.
2. Большинство баз данных, независимо от того, реализованы ли они на компьютере или нет, для хранения данных используют таблицы. Каждая таблица состоит из строк и столбцов, которые в компьютерных базах данных называются записями и полями, соответственно. Например, в таблице "Расчет заработной платы" содержатся следующие сведения: Ф.И.О., оклад, налог, сумма к выдаче.
Расчет заработной платы
| N п/п | Ф.И.О. | Оклад | Налог | Сумма к выдаче |
| Иванов И.И. | 11 200 | |||
| Петров П.П. | 11 100 |
Каждую строку можно рассматривать как единичную запись. Информация внутри записи состоит из полей и в нашем примере это поля "Ф.И.О.", "Оклад", "Налог", "Сумма к выдаче".
Каждая таблица состоит из фиксированного числа столбцов и некоторого (переменного) числа строк. Описание столбцов принято называть макетом таблицы.
Все записи состоят из одинаковых полей. Данные для одного поля во всех записях имеют одинаковый тип, но разные поля могут иметь разный тип данных.
Основные понятия, используемые при работе с базами данных:
Поле или элемент данных - это элементарная единица логической организации данных, которая соответствует неделимой единице информации - реквизиту.
Для описания поля используются следующие характеристики:
Имя - например, Фамилия, Имя, Отчество, дата рождения;
Тип - например, символьный, числовой, календарный;
Длина - например, 12 байт, причём будет определяться максимально возможным количеством символов;
Точность - для числовых данных, например, два десятичных знака для отображения дробной части числа.
Запись - это совокупность полей, соответствующих логически связанным реквизитам. Структура записи определяется составом и последовательностью входящих в неё полей, каждое из которых содержит элементарные данные. Например, если списочный состав сотрудников предприятия представить в виде таблицы, где в шапке таблицы будут стоять: Ф.И.О., дата рождения, должность, оклад, то строка данных в таблице о конкретном сотруднике будет являться записью. Экземпляр записи - отдельная реализация записи, содержащая конкретные значения её полей.
Запись является основной структурной единицей обработки данных и единицей обмена между оперативной и внешней памятью.
Записи (строки) в таблице не упорядочены - не существует первой или десятой строки. Однако поскольку на строки надо как-то ссылаться, то вводится понятие "первичный ключ". Первичный ключ - это столбец, значения которого во всех строках разные. Используя первичный ключ можно однозначно сослаться на какую-либо строку (поле) таблицы.
В общем виде ключи записи бывают двух видов: первичный (уникальный) и вторичный ключ.
Первичный ключ - это одно или несколько полей, однозначно идентифицирующих запись. Если первичный ключ состоит из одного поля, он называется простым, если из нескольких полей - составным ключом.
Вторичный ключ, в отличие от первичного - это такое поле, значение которого может повторяться в нескольких записях файла, т.е. он не является уникальным. Если по значению первичного ключа может быть найден один единственный экземпляр записи, то по вторичному - несколько.
Модель данных - это описание данных в виде логической схемы или таблицы, которая содержит информацию о всех файлах, типах записей, типах элементов, а так же о всех связях между файлами, записями или элементами.
При описании логической организации данных каждому файлу присваивается уникальное имя и даётся описание структуры его записей. Описание структуры записей включает перечень входящих в неё полей и их порядок внутри записи.
Для каждого поля задаётся сокращённое обозначение - имя поля (идентификатор поля внутри записи), формат поля - тип хранимого данного, длина поля и точность числовых данных. Для полей, выполняющих роль уникального (первичного) ключа записи, признак ключа.
Например. Представим логическую структуру записи файла (таблицы) «STUDENT», содержимое которого составляют: номер занятой клетки, фамилию, имя, отчество и дату рождения. Структура записи файла student линейная, она содержит записи фиксированной длины.
Реляционная модель данных (РМД) некоторой предметной области представляет собой набор отношений, изменяющихся во времени. При создании информационной системы совокупность отношений позволяет хранить данные об объектах предметной области и моделировать связи между ними. Термины РМД:
| Термин реляционной модели | Эквивалентный термин |
| Отношение | Таблица |
| Схема отношения | Строка заголовков столбцов таблицы (заголовок таблицы) |
| Кортеж | Строка таблицы, запись |
| Сущность | Описание свойств объекта |
| Атрибут | Столбец, поле |
| Домен | Множество допустимых значений атрибута |
| Кардинальность | Количество строк |
| Первичный ключ | Уникальный идентификатор |
| Степень | Количество столбцов |
Реляционная база данных представляет собой хранилище данных, содержащее набор двумерных таблиц. Данные в таблицах должны удовлетворять следующим принципам:
1. Значения атрибутов должны быть атомарными (иными словами каждое значение, содержащееся на пересечении строки и колонки должно быть не расчленяемым на несколько значений).
2. Значение атрибута должны принадлежать к одному и тому же типу.
3. Каждая запись в таблице уникальна.
4. Каждое поле имеет уникальное имя.
5. Последовательность полей и записей в таблице не существенна.
Отношение является важнейшим понятием и представляет собой двумерную таблицу, содержащую некоторые данные.
Сущность есть объект любой природы, данные о котором хранятся в базе данных. Данные о сущности хранятся в отношении.
Атрибуты представляют собой свойства, характеризующие сущность. В структуре таблицы каждый атрибут именуется и ему соответствует заголовок некоторого столбца таблицы.
Математически отношение можно описать следующим образом.
Пусть даны n множеств D1 D2, D3 Dn, тогда отношение R есть множество упорядоченных кортежей <d1, d.2, d3 dn>, где dk e Dk, dk — атрибут, a Dk — домен отношения R.
На рис. 3 приведен пример отношения «СОТРУДНИК».
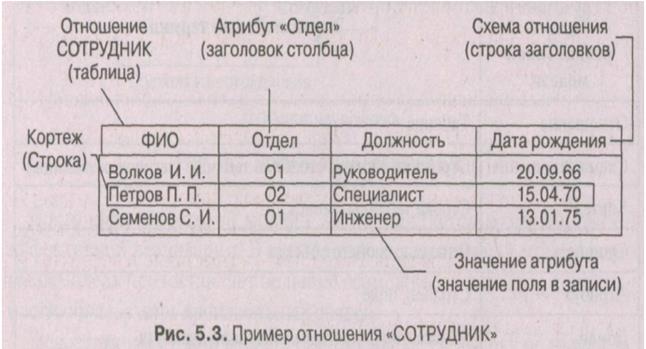 Рис. 3. Пример отношения «СОТРУДНИК»
Рис. 3. Пример отношения «СОТРУДНИК»
Домен представляет собой множество всех возможных значений опре деленного атрибута отношения. Отношение «СОТРУДНИК» включа ет 4 домена:
множество всех возможных фамилий сотрудников;
множество всех возможных номеров отделов;
множество всех возможных названий должностей;
множество возможных дат рождения сотрудников.
Значения домена принадлежат к одному типу (числовому, символьному и т. д.).
Отношение «СОТРУДНИК» содержит 3 кортежа (кортежу соответствует строка таблицы). Информация о предметной области вносится по 4-м атрибутам.
Схема отношения — перечень имен атрибутов. Например: СОТРУДНИК (ФИО, Отдел, Должность, Дата рождения). Множество кортежей отношения называют телом отношения.
Ключом отношения называется совокупность его атрибутов, однозначно идентифицирующих каждый из кортежей отношения. Иными словами, множество атрибутов К, являющееся ключом отношения, обладает свойством уникальности. Следующее свойство ключа — не избыточность. То есть никакое из собственных подмножеств множества К не обладает свойством уникальности.
Каждое отношение всегда имеет комбинацию атрибутов, которая может служить ключом. Ее существование гарантируется принципом № 3 РМД. По крайней мере, вся совокупность атрибутов обладает свойством уникальности.
Возможны случаи, когда отношение имеет несколько комбинаций атрибутов, каждая из которых однозначно определяет все кортежи от ношения. Все эти комбинации атрибутов являются возможными ключами отношения. Любой из возможных ключей может быть выбран как первичный.
Ключи обычно используют для достижения следующих целей:
• исключения дублирования значений в ключевых атрибутах (остальные атрибуты в расчет не принимаются);
• упорядочения кортежей. Возможно упорядочение по возрастанию или убыванию значений всех ключевых атрибутов, а также смешанное упорядочение (по одним — возрастание, а по другим — убывание);
• организации связывания таблиц.
Важным является понятие внешнего ключа. Внешний ключ можно определить как множество атрибутов одного отношения R2, значения которых должны совпадать со значениями возможного ключа другого отношения R\ [18].
Атрибуты отношения R2, составляющие внешний ключ, не являются ключевыми для данного отношения.
С помощью внешних ключей устанавливаются связи между отношениями.
3. При большом объеме информации проблема эффективности средств организации обрабатываемых данных и доступа к ним приобретает особое значение. Если вам необходимо использовать данные, хранящиеся в разных таблицах, без систем управления базами данных вам не обойтись.
Система управления базами данных (СУБД) - это совокупность программных средств, обеспечивающая возможность создания базы данных, доступа к данным и управление базой данных.
В состав СУБД, как правило, входят:
- средства задания (описания) структуры базы данных;
- средства конструирования заданных форм, предназначенных для ввода данных, просмотра и их обработки в диалоговом режиме;
- средства создания запросов для выборки данных при заданных условиях, а так же выполнения операций по их обработке;
- средства создания отчётов из базы данных, для вывода на печать результатов обработки в удобном для пользователя виде;
- языковые средства - макросы, встроенный алгоритмический язык, язык запросов и т.д., которые используются для реализации нестандартных алгоритмов обработки данных, а так же процедур обработки событий в задачах пользователя;
- средства создания приложений пользователя (генераторы приложений, средства создания меню и пакетов управления приложениями).
Современные СУБД включают:
- набор средств для поддержки таблиц и отношений между ними;
- развитый пользовательский интерфейс, который позволяет вводить и модифицировать информацию, выполнять поиск и представлять информацию в текстовом или графическом виде;
- средства программирования высокого уровня, с помощью которого вы можете создать собственные приложения для работы с базами данных;
- средства для выбора нужных данных;
- средства для вывода информации на печать;
- средства для выполнения расчетов.
На этапе разработки баз данных СУБД служит для описания структуры базы данных, определения таблиц, определения количества полей, типа данных, отображающихся в них, размеров полей, определения связей между таблицами.
Во время эксплуатации баз данных СУБД обеспечивает редактирование структуры базы данных, заполнение ее данными, поиск сортировку, отбор данных по заданным критериям, формирование отчетов.
В мире насчитывается более 50 видов СУБД для IBM PC и совместимых с ним компьютеров: dBASE, Fox Pro, Paradox, Clarion, Access.
Существующие архитектуры СУБД.
По способу организации взаимодействия с базой данных через сеть, СУБД делят на:
СУБД с централизованной архитектурой.
СУБД с архитектурой файл-сервер.
СУБД с архитектурой клиент-сервер.
СУБД с трехуровневой архитектурой: "тонкий клиент" - сервер приложений - сервер базы данных.
В СУБД с централизованной архитектурой, СУБД и сама база данных размещается и функционирует на центральном миникомпьютере (мэйнфрейме), а пользователи получают доступ к базе данных при помощи обычных терминалов - компьютер рассматривается просто как устройство ввода и отображения информации: на мэйнфрейм передаются нажатия клавиш, в обратном направлении передаются данные, отображаемые непосредственно на мониторе пользователя. Примерами СУБД с централизованной архитектурой являются ранние версии СУБД DB2, ранние версии СУБД Oracle и Ingres.
В СУБД с архитектурой файл-сервер база данных хранится на сервере, а копии СУБД устанавливаются на компьютерах пользователей. Файл базы данных, находящийся на сервере, совместно используется всеми пользователями одновременно, при помощи сетевого программного обеспечения и самой операционной системы. Ярким примером такой архитектуры является СУБД MS Access: копии СУБД установлены на компьютере каждого пользователя, а сам файл базы данных находится на сервере в сетевой папке. Архитектура файл-сервер позволяет добиться приемлемой производительности, т.к. в распоряжении каждой копии СУБД находятся все ресурсы компьютера пользователя. С другой стороны, производительность такой схемы для каждого пользователя, напрямую зависит от характеристик компьютера пользователя. Кроме того, такая схема работы значительно загружает сеть. Допустим, что пользователю необходимо отобрать строки таблицы с товарами, по которым объем продаж не превышает 100 тыс. руб. Поскольку строки в таблице не упорядочены, то скорее всего по сети будут переданы все строки таблицы, из которых СУБД уже "на месте" (на компьютере пользователя) отберет нужные. Очевидно, что такая схема нерациональна при больших объемах обрабатываемой информации или большом числе пользователей базы данных. Поэтому, для таких БД целесообразнее применять архитектуру клиент-сервер.
При архитектуре клиент-сервер база данных хранится на сервере, а СУБД подразделяется на две части: клиентскую и серверную. Клиентская часть СУБД выполняется на стороне клиента и обеспечивает интерактивное взаимодействие с пользователем и формирование запросов к базе данных (на языке SQL). Серверная часть работает на сервере и взаимодействует с базой данных, обеспечивая выполнение запросов клиентской части. Т.е. , если провести аналогию с рассмотренным выше примером, то клиентская часть сформирует и отправит серверной части запрос "Отбери для меня строки таблицы с товарами, по которым объем продаж не превышает 100 тыс. руб", серверная часть выполнит данный запрос и отошлет клиентской части только те строки, которые необходимо, не передавая по сети все строки таблицы. Большинство современных СУБД реализованы по архитектуре клиент- сервер: Oracle, MS SQL Server, PostgreSQL, MySQL, Informix, DB2 и др.
Однако и архитектура клиент-сервер не лишена недостатков. Если деловая логика взаимодействия с базой данных (логика, определяющаяся порядком работы предприятия: какие таблицы и в каком порядке заполнять, что делать при добавлении нового сотрудника и т.д.) изменяется, то приходится заново переписывать клиентские программы (вводить новые формы, менять порядок их заполнения и т.д.). Если изменения происходят слишком часто, а количество рабочих мест велико, то постоянная переустановка программного обеспечения (которая, кстати, должна осуществляться достаточно быстро) становится серьезной проблемой. В таких случаях следует переходить к трехуровневой архитектуре: "тонкий клиент" - сервер приложений - сервер базы данных. При трехуровневой архитектуре в функции клиентской части ("тонкий клиент") входит только интерактивное взаимодействие с пользователем, а вся деловая логика вынесена на сервер приложений, который собственно и обеспечивает формирование запросов к базе данных, передаваемых на выполнение сервер) базы данных. "Тонкий клиент" находится на компьютере пользователя и чаще всего представляет из себя Web-браузер (например, Internet Explorer) с применением в соответствующей HTML-странице апплетов Java или компонентов ActiveX. Сервер приложений находится на сервере и может являться специализированной программой (например, Oracle Forms Server) или обычным Web-сервером, вызывающим для обработки HTTP-запроса 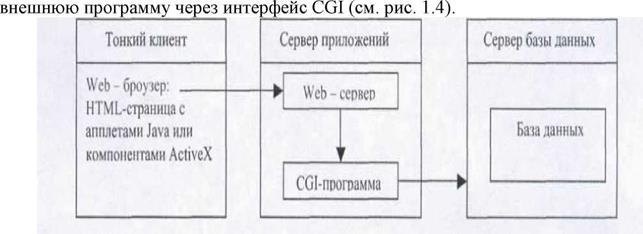
Рис 1.4. Трехуровневая архитектура.
Преимущества трехуровневой архитектуры очевидны: при необходимости изменений в деловой логике, изменения вносятся только один раз - на сервере приложений. Изменять или переустанавливать клиентские программы нет никакой необходимости.
Классификация современных СУБД.
К важным признакам классификации современных СУБД относятся:
*тип поддерживаемой в СУБД модели данных - сетевая, иерархическая, реляционная;
* используемая концепция работы с нетрадиционными данными - объектно-реляционные, объектные;
*уровень использования - локальная (для настольных систем), архитектура клиент-сервер, с параллельной обработкой данных (многопроцессорная).
Перспективы развития архитектур СУБД связаны с развитием концепции обработки нетрадиционных данных и их интеграции, обмена данными из разных СУБД, многопользовательской технологии в локальных сетях.
Перспективы развития объектного подхода
Одной из важнейших тенденций развития СУБД является разработка "универсальных" СУБД, способных интегрировать в базе традиционные и нетрадиционные данные - тексты, рисунки, звук и видео, страницы HTML и др. Это особенно актуально для Web. Имеются два подхода к построению таких СУБД: объектно-реляционный - совершенствование существующих реляционных СУБД и объектный.
Следует отметить, что современные реляционные СУБД уже способны интегрировать данные, однако нетрадиционные данные не доступны для внутренней обработки. "Универсальные" СУБД должны выполнять такую обработку. В таких системах не нужны разнородные программы, которыми сложно управлять. По пути создания объектно-реляционных СУБД пошли такие фирмы, как IBM, Informix. В IBM разработана объектно-реляционная СУБД DB2 для ОС AIX и OS/2.
Корпорация Microsoft сделала ставку на объектно-ориентированный интерфейс OLE DB, который обеспечивает доступ к данным Microsoft SQL Server (реляционная СУБД).
Дата добавления: 2021-12-10; просмотров: 62; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!