Представлення даних в пам’яті комп'ютера
Поняття інформації та основні форми її подання
Термін "інформація" походить від латинського слова "informatio", що означає роз’яснення, виклад. Хоч людина постійно має справу з інформацією, але наукового визначення, що таке інформація, не існує. Тоді говорять не про визначення, а про поняття, що, в залежності від обставин, може мати різний зміст. Наприклад, у побуті під інформацією розуміють всі відомості, які людина одержує від природи і суспільства з допомогою органів чуттів. Математик це поняття розглядатиме ширше, включивши в нього відомості, які людина не одержує, а створює сама з допомогою висновків. Біолог може добавити до цієї інформації дані, які людина містить в собі – спадковий генетичний код і т.д. Отже, інформація - абстрактне поняття, що має різні значення залежно від контексту. Можна дати таке визначення інформації: інформація - сукупність відомостей про всілякі об'єкти, явища, процеси. При всьому різноманітті, інформація володіє чотирма спільними основними властивостями: інформацію можна створювати, передавати, зберігати і опрацьовувати.
Найважливішими, з практичної точки зору, властивостями інформації є цінність, достовірність та актуальність. Цінність інформації — визначається забезпеченням можливості досягнення мети, поставленої перед отримувачем інформації. Достовірність — відповідність отриманої інформації об'єктивній реальності навколишнього світу. У властивості достовірності виділяються безпомилковість та істинність даних а також адекватність. Під безпомилковістю розуміється властивість даних не мати прихованих випадкових помилок. Випадкові помилки в даних обумовлені, як правило, ненавмисними спотвореннями змісту людиною чи збоями технічних засобів при переробці даних в інформаційній системі. Актуальність — це міра відповідності цінності та достовірності інформації поточному часу (певному часовому періоду) . Дані, спеціально відібрані для конкретного рівня користувачів, володіють такою властивістю , як вибірковість.
|
|
|
Інформація володіє часовими властивостями. Часові властивості визначають здатність даних передавати динаміку зміни ситуації (динамічність). При цьому можна розглядати або час запізнення появи в даних відповідних ознак об'єктів, або розходження реальних ознак об'єкта і тих же ознак, що передаються даними. Відповідно можна виділити:
актуальність — властивість даних, що характеризує поточну ситуацію;
оперативність — властивість даних, яка полягає в тому, що час їх збору та переробки відповідає динаміці зміни ситуації;
ідентичність — властивість даних відповідати стану об'єкту.
|
|
|
Інформація володіє властивістю недоступності. При розгляді захищеності даних можна виділити технічні аспекти захисту даних від несанкціонованого доступу та соціально-психологічні аспекти класифікації даних за мірою їх конфіденційності та секретності (властивість конфіденційності).
Можна також виділити і інші властивості інформації. Суспільна природа — джерелом інформації є пізнавальна діяльність людей, суспільства. Мовна природа — інформація виражається за допомогою мови — знакової системи будь-якої природи, яка служить засобом спілкування, мислення, висловлювання думки. Мова може бути природною, що використовується у повсякденному житті та служить формою висловлення думок і засобом спілкування між людьми а також штучною, створеною людьми з певною метою (наприклад, мова математичної символіки, інформаційно-пошукова, алгоритмічна та ін. мови). Дискретність інформації — одиницями інформації як засобами висловлювання є слова, речення, уривки тексту, а у плані змісту — поняття, висловлювання, описання фактів, гіпотези, теорії, закони тощо. Старіння інформації — головною причиною старіння інформації є не сам час, а поява нової інформації, з надходженням якої попередня інформація виявляється невірною, перестає адекватно передавати явища та закономірності матеріального світу, людського спілкування та мислення. Розсіювання інформації — існування у багатьох джерелах.
|
|
|
Основними формами подання інформації є символьна, текстова і графічна.
Символьна форма ґрунтується на використанні символів — літер, цифр, знаків і т. д., є найбільш простою і практично застосовується тільки для передачі сигналів про різні події.
Більш складною є текстова форма подання інформації. Тут, як і в попередній формі, використовуються символи — літери, цифри, математичні знаки. Однак інформація закладена не тільки в цих символах, але й у їх сполученні, порядку проходження. Завдяки взаємозв'язку символів і відображенню мови людини текстова інформація надзвичайно зручна і широко використовується в повсякденному житті.
Найбільш місткою, але і найбільш складною є графічна форма подання інформації. Образи природи, фотографії, креслення, схеми, малюнки мають велике значення в нашому житті і містять величезну кількість інформації. І хоча інформація не має ні маси, ні геометричних розмірів, жодних фізичних або хімічних властивостей, проте для її існування обов'язкова наявність якогось матеріального об'єкта, що передає або зберігає інформацію. Таких об'єктів досить багато, і їхня кількість увесь час зростає.
|
|
|
Представлення даних в пам’яті комп'ютера
Дані є складовою частиною інформації, що являють собою зареєстровані сигнали. Під час інформаційного процесу дані перетворюються з одного виду в інший за допомогою методів. Обробка даних містить в собі множину різних операцій. Основними операціями є:
1) збір даних - накопичення інформації з метою забезпечення достатньої повноти для прийняття рішення;
2) формалізація даних - приведення даних, що надходять із різних джерел до однакової форми;
3) фільтрація даних - усунення зайвих даних, які не потрібні для прийняття рішень;
4) сортування даних - впорядкування даних за заданою ознакою з метою зручності використання;
5) архівація даних - збереження даних у зручній та доступній формі;
6) захист даних - комплекс дій, що скеровані на запобігання втрат, відтворення та модифікації даних;
7) транспортування даних - прийом та передача даних між віддаленими користувачами інформаційного процесу. Джерело даних прийнято називати сервером, а споживача - клієнтом;
8) перетворення даних - перетворення даних з однієї форми в іншу, або з однієї структури в іншу, або зміна типу носія.
Для автоматизації роботи з даними, що відносяться до різних типів, важливо уніфікувати їх форму представлення. Для цього, як правило, використовується прийом кодування, тобто представлення даних одного типу через дані іншого типу. Універсальні засоби кодування успішно втілюються в різноманітних галузях техніки, науки та культури - математичні вирази, телеграфна азбука, морська азбука, азбука для сліпих тощо. Своя система кодування існує й в інформатиці, і називається вона двійковим кодом. Ґрунтується вона на представленні даних послідовністю двох знаків: (бітів) 0 та 1. Байт — найменша адресована одиниця пам'яті ЕОМ. Містить 8 бітів. інформації.
Одиниці виміру обсягу даних :
1 КБ (кілобайт) = 210 байт = 1024 байт;
1 МБ (мегабайт) = 210 КБ = 1024 КБ = 220 байт;
1 ГБ (гігабайт) = 210 МБ = 1024 МБ = 230 байт;
1 ТБ (терабайт) = 210 ГБ = 1024 ГБ = 240 байт;
1 ПБ (петабайт) = 210 ТБ = 1024 ТБ = 250 байт;
1 ЕБ (ексабайт) = 210 ПБ = 1024 ПБ = 260 байт;
1 ЗБ (зетабайт) = 210 ЕБ = 1024 ЕБ = 270 байт;
1 ЙБ (йотабайт) = 210 ЗБ = 1024 ЗБ = 280 байт;
Класифікація типів даних
Основна мета будь-якої програми полягає в обробці даних. Дані різних типів зберігаються в пам’яті комп’ютера і обробляються по-різному. Згідно з концепцією типів даних, кожний тип даних однозначно визначає:
1) множину значень, які може приймати змінна заданого типу;
2) операції та функції, які можна застосовувати до цієї змінної;
3) внутрішнє представлення змінної у пам'яті комп'ютера.
Нагадаємо, що пам'ять виділяється не для типу даних, а для розміщення змінних або констант певних типів.
В мові С++ розрізняють наступні категорії типів:
1) базові (або прості, основні, стандартні) типи даних;
2) похідні (або складні, складені) типи даних.
Базові типи мають імена, які є ключовими словами мови. До базових типів відносяться: скалярні типи і порожній тип (void).
Скалярні типи діляться на цілочисельні і дійсні типи (float, double,long double). Логічний тип (bool), символьні (char, wchar_t) та цілі (short, int, long) типи даних відносяться до цілочисельних типів. Для них визначені всі операції роботи з цілими числами.
Похідні типи визначаються на основі базових типів. Похідні типи діляться на скалярні і структуровані (або агрегатні).
До скалярних похідних типів відносяться:
- переліки (enum) ;
- вказівники (ім'я_типу *);
- посилання (ім'я_типу &).
До структурованих похідних типів відносяться:
- масиви;
- структури (struct);
- об'єднання (union);
- класи (class).
В структурах, об'єднаннях і класах можуть використовуватись бітові поля.
Для явного задання діапазону можна використовувати такі специфікатори:
1)Специфікатори short (короткий) і long (довгий) застосовуються до цілих. У таких оголошеннях слово int можна опускати, що зазвичай й робиться. Найчастіше для представлення цілого, описаного з специфікаторомshort, виділяється 16 біт, із специфікатором long - 32 біта, а значенню типу int - або 16, або 32 біта.
2)Специфікатори signed (зі знаком) або unsigned (без знака) можна застосовувати до будь-якому цілочисельного типу. Вони вказують, як інтерпретується нульовий біт змінної, тобто, якщо зазначено ключове слово unsigned, то нульовий біт інтерпретується як частина числа, у противному випадку нульовий біт інтерпретується як знаковий. У випадку відсутності ключового слова unsigned змінна вважається знаковою.
Базові типи даних
Порожній тип
Порожній тип (void) синтаксично поводиться як базовий тип. Однак використовувати його можна тільки як частину похідного типу, оскільки об'єктів типу voіd не існує. Він використовується для того, щоб вказати, що функція не повертає ніякого значення, або як базовий тип для вказівників на об'єкти невідомого типу, наприклад:
void f() // функція f не повертає ніякого значення
void* pv; // вказівник на объект невідомого типу
Логічний тип даних
В мові C++ логічний тип (bool) характеризується двома значеннями: false (0) і true (1). На відміну від мови С++ в мові С логічний тип даних іменується Bool, але при включенні заголовочного файлу <stdbool.h> можна використовувати ключові слова bool, true, false.
В пам'яті комп'ютера змінна типу bool займає 1 байт. Логічні значення можна асоціювати зі значеннями типу int: значенню false відповідає нуль, значенню true відповідають всі інші числа.
В арифметичних і логічних виразах логічні значення перетворюються в цілі числа. Арифметичні та бітові логічні операції виконуються над перетвореними величинами. Якщо результат приводиться знову до логічного типу, то 0 перетворюється в false, а ненульове значення перетворюється в true.
Приклад 1.
bool x = true; // в пам’яті комп’ютера змінна х зберігається як послідовність: 0000 0000
bool y = false; // в пам’яті комп’ютера змінна y зберігається як послідовність: 0000 0001
bool a = 2*x+y; // значення виразу 2*x+y дорівнює 2, тому змінна a отримує значення
// true (1); отже, в пам’яті комп’ютера змінна a зберігається як наступна
// послідовність біт: 0000 0001 (або в 16-ковій системі числення як 01).
Символьні типи даних
Ідентифікатором символьного типу є ключове слово char.
Символьні константи (символьні літерали) можна представляти як:
1) клавіатурні: '1','s','Y' – записуються як символи в одинарних лапках;
2) кодові: '\n','\\','\?', які використовуються для представлення деяких керуючих символів та символів-розділювачів – записуються як escape-послідовності (вони починаються з символу зворотної косої риски). Перелік кодових символьних літералів наведено в Таблиці 4.1.
Таблиця 4.1.
| Назва | Кодові символьні літерали | Код |
| Дзвінок | \a | 07 |
| Забій (повернення на крок) | \b | 08 |
| Горизонтальна табуляція | \t | 09 |
| Перехід на новий рядок | \n | 0A |
| Вертикальна табуляція | \v | 0B |
| Прогін аркуша | \f | 0C |
| Повернення каретки | \r | 0D |
| Знак питання | \? | 3F |
| Зворотня коса риска | \\ | 5C |
| Подвійні лапки | \" | 22 |
| Апостроф | \' | 27 |
| Ноль-символ | \0 | 00 |
3) кодові числові: '\0','\x5C','\124', які використовуються для представлення будь-яких символів – записуються у вигляді однієї, двох або трьох вісімкових цифр з символом зворотної косої риски ( \ ) перед ними або довільним шістнадцятковим числом з послідовністю \х перед ним. Послідовність вісімкових або шістнадцяткових цифр закінчується першим символом, який не є відповідно вісімковою або шістнадцятковою цифрою. Приклади таких представлень наведені в Таблиці 4.2.
Таблиця 4.2.
| Десяткова | Вісімкова | Шістнадцяткова | Символ |
| 7 | '\7' | '\x7' | Дзвінок |
| 48 | '\60' | '\x30' | '0' |
| 50 | '\062' | '\x32' | '2' |
| 95 | '\137' | '\x005f' | '_' |
Значеннями змінних типу char є множина символів таблиці ASCII (American Standard Code For Information Interchange – американський стандартний код для обміну інформацією). Таблиця кодів ASCІІ містить 256 символів, кожний з яких має строго визначене місце і свій порядковий номер від 0 до 255. Код символу - це його порядковий номер у таблиці символів ASCІІ.
Таблиця кодів ASCІІ складається з 2 таблиць:
1. Основної ( з кодами від 0 до 127). Вона містить у собі:
- символи керування,
- символи арифметичних операцій, розділові знаки, цифри,
- букви латинського алфавіту (прописні, рядкові).
2. Розширеної ( з кодами від 128 до 255). Вона містить у собі:
- символи псевдографіки (символи, що застосовуються для побудови найпростіших фігур),
- букви національних алфавітів,
- математичні символи.
Всі символи, крім символів керування, є графічними. Вони на пристроях зображення відображаються, а в таблиці кодів ASCІІ мають графічне зображення.
Символи з кодами від 0 до 31 і код 127 відносяться до керуючих. В текстовому режимі їм відповідають графічні зображення. При використанні цих символів або кодів в операціях виведення вони набувають самостійного значення. Приклади символів керування наведені в Таблиці 4.3.
Таблиця 4.3
| Символ | Код | Значення |
| BEL | 7 | Дзвоник. Виведення на екран цього символу супроводжується звуковим сигналом. |
| НТ | 9 | Горизонтальна табуляція. При виведенні на екран зміщує курсор у позицію, кратну 8 плюс 1 (9, 17, 25 і т.д.). |
| LF | 10 | Перехід рядка. При виведенні його на екран всі наступні символи будуть виводитися, починаючи з тієї ж позиції, але на наступному рядку. |
| VT | 11 | Вертикальна табуляція. При виведенні на екран замінюється спеціальним знаком (♂). |
| FF | 12 | Прогін сторінки. При виведенні на принтер формує нову сторінку, при виведенні на екран замінюється спеціальним знаком (♀). |
| CR | 13 | Повернення каретки. Вводиться натисканням на клавішу Enter. При введенні за допомогою операторів мови програмування означає команду "введення" і в буфер введення не кладеться. При виведенні означає команду "продовжити виведення з початку біжучого рядка" |
| SUB | 26 | Кінець файлу. Вводиться з клавіатури натисканням Ctrl - Z. При виведенні заміняється спеціальним знаком (→). |
| SSC | 27 | Кінець роботи. Вводиться з клавіатури натисканням на клавішу ESC. При виведенні заміняється спеціальним знаком (←). |
Перша основна половина символів таблиці ASCII (коди 0...127) побудована по стандарту ASCІІ і вона є однаковою на всіх ІBM-сумісних комп’ютерах. Принцип послідовного кодування алфавіту полягає в тому, що в кодовій таблиці ASCII латинські букви (прописні та строчні) розташовуються в алфавітному порядку. Розташування цифр також впорядковано по зростанню їх значень.
Друга половина символів (коди 128...255) може відрізнятися на комп’ютерах різного типу. У стандартному знакогенераторі фірми ІBM символи псевдографіки займають позиції з кодами від 176 до 223. Позиції з кодами від 128 до 175 і від 224 до 239 використовуються для розміщення деяких символів національних алфавітів різних європейських мов, а позиції з кодами від 240 до 255 - для розміщення спеціальних знаків. З врахуванням цього розташування символів розробляється переважна більшість програм закордонного походження.
Стандартний вітчизняний знакогенератор був побудований за рекомендаціями Міжнародного консультаційного комітету з телеграфії і телефонії (МККТТ). Розташування символів у другій половині таблиці цього знакогенератора відрізнялось від прийнятого фірмою ІBM, що утруднювало використання закордонного програмного забезпечення на вітчизняних ПК. У зв'язку з цим, стандартний варіант кодування був заміняний альтернативним, головна перевага якого - розташування символів псевдографіки на тих же місцях, що й у знакогенераторі ІBM. Недолік такого знакогенератора полягає у тому, що символи кирилиці не утворюють безперервну послідовність. Такий варіант у даний час одержав найбільше поширення на вітчизняних ПК. Саме на нього розраховані практично всі програми вітчизняного виробництва. Він став фактичним стандартом для закордонних фірм, що виготовляють комп'ютери для експорту в нашу країну.
Таблиця символів ASCII наведена в Таблиці 4.4. В ній прийняті такі позначення:
DEC– код в 10-ковій системі числення,
HEX– код в 16-ковій системі числення,
CH – символ.
Таблиця 4.4
| DEC | HEX | CH | DEC | HEX | CH | DEC | HEX | CH | DEC | HEX | CH | DEC | HEX | CH | DEC | HEX | CH | DEC | HEX | CH | DEC | HEX | CH |
| 0 | 0 | 32 | 20 | 64 | 40 | @ | 96 | 60 | ` | 128 | 80 | А | 160 | A0 | а | 192 | C0 | └ | 224 | E0 | р | ||
| 1 | 1 | ☺ | 33 | 21 | ! | 65 | 41 | A | 97 | 61 | a | 129 | 81 | Б | 161 | A1 | б | 193 | С1 | ┴ | 225 | El | с |
| 2 | 2 | ☻ | 34 | 22 | “ | 66 | 42 | B | 98 | 62 | b | 130 | 82 | В | 162 | A2 | в | 194 | C2 | ┬ | 226 | E2 | т |
| 3 | 3 | ♥ | 35 | 23 | # | 67 | 43 | C | 99 | 63 | c | 131 | 83 | Г | 163 | A3 | г | 195 | C3 | ├ | 227 | E3 | у |
| 4 | 4 | ♦ | 36 | 24 | $ | 68 | 44 | D | 100 | 64 | d | 132 | 84 | Д | 164 | A4 | д | 196 | C4 | ─ | 228 | E4 | ф |
| 5 | 5 | ♣ | 37 | 25 | % | 69 | 45 | E | 101 | 65 | e | 133 | 85 | Е | 165 | A5 | е | 197 | C5 | ┼ | 229 | E5 | х |
| 6 | 6 | ♠ | 38 | 26 | & | 70 | 46 | F | 102 | 66 | f | 134 | 86 | Ж | 166 | A6 | ж | 198 | C6 | ╞ | 230 | E6 | ц |
| 7 | 7 | • | 39 | 27 | ' | 71 | 47 | G | 103 | 67 | g | 135 | 87 | З | 167 | A7 | з | 199 | C7 | ╟ | 231 | E7 | ч |
| 8 | 8 | ◘ | 40 | 28 | ( | 72 | 48 | H | 104 | 68 | h | 136 | 88 | И | 168 | A8 | и | 200 | C8 | ╚ | 232 | E8 | ш |
| 9 | 9 | ○ | 41 | 29 | ) | 73 | 49 | I | 105 | 69 | i | 137 | 89 | Й | 169 | A9 | й | 201 | C9 | ╔ | 233 | E9 | щ |
| 10 | A | ◙ | 42 | 2A | * | 74 | 4A | J | 106 | 6A | j | 138 | 8A | К | 170 | AA | к | 202 | CA | ╩ | 234 | EA | ъ |
| 11 | B | ♂ | 43 | 2B | + | 75 | 4B | K | 107 | 6B | k | 139 | 8B | Л | 171 | AB | л | 203 | CB | ╦ | 235 | EB | ы |
| 12 | C | ♀ | 44 | 2C | , | 76 | 4C | L | 108 | 6C | 1 | 140 | 8C | М | 172 | AC | м | 204 | CC | ╠ | 236 | EC | ь |
| 13 | D | ♪ | 45 | 2D | - | 77 | 4D | M | 109 | 6D | m | 141 | 8D | Н | 173 | AD | н | 205 | CD | ═ | 237 | ED | э |
| 14 | E | ♫ | 46 | 2E | . | 78 | 4E | N | 110 | 6E | n | 142 | 8E | О | 174 | AE | о | 206 | CE | ╬ | 238 | EE | ю |
| 15 | F | ☼ | 47 | 2F | / | 79 | 4F | O | 111 | 6F | o | 143 | 8F | П | 175 | AF | п | 207 | CF | ╧ | 239 | EF | я |
| 16 | 10 | ◙ | 48 | 30 | 0 | 80 | 50 | P | 112 | 70 | p | 144 | 90 | Р | 176 | B0 | ░ | 208 | D0 | ╨ | 240 | F0 | Ё |
| 17 | 11 | ◄ | 49 | 31 | 1 | 81 | 51 | Q | 113 | 71 | q | 145 | 91 | С | 177 | В1 | ▒ | 209 | Dl | ╤ | 241 | Fl | ё |
| 18 | 12 | ↕ | 50 | 32 | 2 | 82 | 52 | R | 114 | 72 | r | 146 | 92 | Т | 178 | B2 | ▓ | 210 | D2 | ╥ | 242 | F2 | Є |
| 19 | 13 | ‼ | 51 | 33 | 3 | 83 | 53 | S | 115 | 73 | s | 147 | 93 | У | 179 | B3 | │ | 211 | D3 | ╙ | 243 | F3 | є |
| 20 | 14 | ¶ | 52 | 34 | 4 | 84 | 54 | T | 116 | 74 | t | 148 | 94 | Ф | 180 | B4 | ┤ | 212 | D4 | ╘ | 244 | F4 | Ї |
| 21 | 15 | § | 53 | 35 | 5 | 85 | 55 | U | 117 | 75 | u | 149 | 95 | Х | 181 | B5 | ╡ | 213 | D5 | ╒ | 245 | F5 | ї |
| 22 | 16 | ▬ | 54 | 36 | 6 | 86 | 56 | V | 118 | 76 | v | 150 | 96 | Ц | 182 | B6 | ╢ | 214 | D6 | ╓ | 246 | F6 | І |
| 23 | 17 | ↨ | 55 | 37 | 7 | 87 | 57 | W | 119 | 77 | w | 151 | 97 | Ч | 183 | B7 | ╖ | 215 | D7 | ╫ | 247 | F7 | і |
| 24 | 18 | ↑ | 56 | 38 | 8 | 88 | 58 | X | 120 | 78 | x | 152 | 98 | Ш | 184 | B8 | ╕ | 216 | D8 | ╪ | 248 | F8 | ° |
| 25 | 19 | ↓ | 57 | 39 | 9 | 89 | 59 | Y | 121 | 79 | y | 153 | 99 | Щ | 185 | B9 | ╣ | 217 | D9 | ┘ | 249 | F9 | • |
| 26 | 1A | → | 58 | 3A | : | 90 | 5A | Z | 122 | 7A | z | 154 | 9A | Ъ | 186 | BA | ║ | 218 | DA | ┌ | 250 | FA | · |
| 27 | 1B | ← | 59 | 3B | ; | 91 | 5B | [ | 123 | 7B | { | 155 | 9B | Ы | 187 | BB | ╗ | 219 | DB | █ | 251 | FB | √ |
| 28 | 1C | ∟ | 60 | 3C | < | 92 | 5C | \ | 124 | 7C | | | 156 | 9C | Ь | 188 | BC | ╝ | 220 | DC | ▄ | 252 | FC | № |
| 29 | ID | ( | 61 | 3D | = | 93 | 5D | ] | 125 | 7D | } | 157 | 9D | Э | 189 | BD | ╜ | 221 | DD | ▌ | 253 | FD | ¤ |
| 30 | 1E | ▲ | 62 | 3E | > | 94 | 5E | ^ | 126 | 7E | ~ | 158 | 9E | Ю | 190 | BE | ╛ | 222 | DE | ▐ | 254 | FE | ■ |
| 31 | IF | ▼ | 63 | 3F | ? | 95 | 5F | _ | 127 | 7F | ⌂ | 159 | 9F | Я | 191 | BF | ┐ | 223 | DF | ▀ | 255 | FF |
В пам’яті комп’ютера дані символьного типу зазвичай займають 1 байт. В цей байт записується порядковий номер символа в таблиці ASCII.
Приклад 2.
За системою ASCII символ ’O’ має порядковий номер 7910 = 4F16 = 10011112
Отже, цей символ в пам’яті комп’ютера буде представлений як послідовність 0100 1111.
Оскільки значенню типу char відводиться 8 бітів, то значення типу unsigned char має значення в діапазоні від 0 до 255, a signed char – від -128 до 127, але тільки величини від 0 до 127 мають символьний еквівалент. Чи є значення типу просто char знаковим чи беззнаковим, залежить від реалізації, але в будь-якому випадку коди друкованих символів завжди є додатніми. Далі будемо вважати, що тип charє знаковим.
Таблиця 4.5
| Тип | Розмір пам'яті в байтах 16 (32) | Діапазон значень |
| [signed] char | 1 (1) | -128..127 |
| unsigned char | 1 (1) | 0..255 |
Для представлення символів українського алфавіту, специфікатортипу даних повинен мати вигляд unsigned char, тому що коди українських літер перевищують величину 127.
Протягом довгого часу поняття "байт" і "символ" були майже синонімами. Однак, з часом, стало зрозуміло, що 256 різних символів – це не так і багато. Математикам необхідно використовувати в формулах спеціальні математичні знаки, перекладачам необхідно створювати тексти, де можуть зустрічатися символи з різних алфавітів, економістам необхідні символи валют ($, £, ¥). Для вирішення цих проблем була розроблена універсальна система кодування текстової інформації – Unicode. В цьому кодуванні для кожного символа відводиться не один, а два байта, тобто шістнадцять біт. Таким чином, доступно 65536 (=216) різних кодів. Цього вистарчить на латинський алфавіт, кирилицю, іврит, африканські і азіатські мови, різні спеціальні символи: математичні, економічні, технічні і багато іншого. Головний недолік системи Unicode полягає в тому, що всі тексти в цьому кодуванні стають в два рази довшими в пам’яті комп’ютера. В даний час стандарти ASCII і Unicode мирно співіснують.
Символьна константа може мати префікс L (наприклад, L'a'), який означає спеціальний розширений символьний тип (wchar_t), що застосовується для зберігання символів національних алфавітів, якщо вони не можуть бути представлені звичайним однобайтовим типом char, наприклад, Unicode. Розмір цього типу залежить від реалізації; як правило, він відповідає типу short і займає 2 байта пам'яті.
В стандарті С99 тип wchar_t визначений в декількох заголовних файлах: <stddef.h> <stdlіb.h> <wchar.h> <wctype.h>. В мові С++ реалізується підтримка введення - виведення для розширених символів за допомогою заголовного файлу <іostream.h>.
Цілочисельні типи даних
Типи short, іnt і long призначені для представлення цілих чисел.
Цілі типи можуть бути знаковими (sіgned) і беззнаковими (unsіgned). В знакових типах самий лівий біт використовується для зберігання знака числа (0 – плюс, 1 – мінус). Решта бітів містять числове значення. В беззнакових типах всі біти використаються для числового значення. За замовчуванням всі цілочисельні типи вважаються знаковими.
Цілі типи розрізняються діапазоном значень, які можуть приймати цілочисельні змінні і розміром області пам'яті, виділеної під цю змінну, а конкретні розміри перерахованих типів залежать від конкретної реалізації. Так, представлення в пам'яті і область значень для типів іnt і unsіgned іnt чітко не визначені в мові С++. За замовчуванням розмір іnt (зі знаком і без знака) відповідає реальному розміру цілого на даній машині. Наприклад, на 16-ти розрядній машині тип іnt завжди займає 16 розрядів або 2 байта. На 32-х розрядній машині тип іnt завжди займає 32 розряди або 4 байта. Таким чином, тип іnt буде еквівалентним типам short іntабоlong іnt залежно від реалізації. Аналогічно, тип unsіgned іnt еквівалентний типам unsіgned shortабоunsіgned long. Перелік типів наведено в Таблиці 2.6.
Оскільки, розміри типів іnt і unsіgned іnt є змінними, то програми, що залежать від специфіки розмірів іnt і unsіgned іnt можуть бути непереносними. Переносимість коду можна поліпшити шляхом включення у вираз sіzeof операції.
Таблиця 4.6
| Тип | Розмір пам'яті в байтах 16 (32) | Діапазон значень |
| [signed] short [int] | 2 | -215 .. 215-1 = -32768 .. 32767 |
| unsigned short [int] | 2 | 0 .. 216-1 = 0 .. 65535 |
| [signed] int | 2 (4) | -215 .. 215-1 (-231 .. 231-1) |
| unsigned [int] | 2 (4) | 0 .. 216-1 (0 .. 232-1) |
| [signed] long [int] | 4 | -231 .. 231-1 = -2 147 483 648 .. 2 147 483 647 |
| unsigned long [int] | 4 | 0 .. 232-1 = 0 .. 4 294 967 295 |
Літерали цілих типів можна записати в десятковому, вісімковому або шістнадцятковому видах, наприклад: 20 (десяткове), 024 (вісімкове), 0х14 (шістнадцяткове). Якщо літерал починається з 0, він трактується як вісімковий, якщо з 0х або 0Х, то як шістнадцятковий. Звичний запис розглядається як десяткове число. За замовчуванням всі цілі літерали мають тип sіgned іnt. Можна явно визначити цілий літерал, що має тип long, приписавши в кінці числа букву L (використається як прописна L, так і рядкова l, однак для зручності читання не слід вживати рядкову: її легко переплутати з 1). Буква U (або u) в кінці числа визначає літерал як unsіgned іnt, а дві букви – UL або LU – як тип unsіgned long. Наприклад: 25u, 1015UL, 2L, 7Lu
Записи вісімкової і шістнадцяткової констант можуть завершуватися буквою L (для вказівки на тип long) і U (якщо потрібно показати, що константа беззнакова). Наприклад, константа 0XFUL має значення 15 і тип unsigned long.
Внутрішнє представлення змінної цілого типу — ціле число у двійковому коді. Згідно формату IEEE всі додатні цілі числа зберігаються в пам'яті комп'ютера в прямому коді, а всі від'ємні – в доповняльному коді. Цілі числа зберігаються в пам'яті комп'ютера у зворотньому порядку розміщення байт числа.
Приклад 3.
 Додатнє число 25 типу int в пам'яті комп’ютера зберігається в прямому двійковому коді і займає 4 байти:
Додатнє число 25 типу int в пам'яті комп’ютера зберігається в прямому двійковому коді і займає 4 байти:  0000 0000 0000 0000 0000 0000 0001 1001
0000 0000 0000 0000 0000 0000 0001 1001
В пам’яті комп’ютера цілі числа зберігаються у зворотному порядку розміщення байт числа:
0001 10001 0000 0000 0000 0000 0000 0000
Результат в 16-ковій системі числення: 19 00 00 00.
Приклад 4.
Від'ємне число -3500 типу long int в пам'яті комп’ютера зберігається в доповняльному двійковому коді і займає 4 байти: - 350010 = - DAC16 = - 1101 1010 11002
0000 0000 0000 0000 0000 1101 1010 1100 - прямий код;
1111 1111 1111 1111 1111 0010 0101 0011 - обернений код;
+ 1
1111 1111 1111 1111 1111 0010 0101 0100 - доповняльний код;
F F F F F 2 5 4 - в 16- ковій системі числення
В пам’яті комп’ютера зберігається у зворотному порядку розміщення байт числа:
0101 0100 1111 0010 1111 1111 1111 1111
Результат в 16- ковій системі числення: 54 F2 FF FF.
Дійсні типи даних
Дійсні константи записуються у двох формах – з фіксованою десятковою крапкою або в експонентному виді. В першому випадку крапка використовується для поділу цілої і дробової частин константи. Як ціла, так і дробова частини можуть бути відсутніми (наприклад 1.2, 0.725, 1., .35, 0.). В трьох останніх випадках відсутня або дробова, або ціла частина. Десяткова крапка повинна обов'язково бути присутньою, інакше константа буде вважатись цілою.
Експонентна форма запису дійсної константи містить знак, мантису і десятковий порядок (експоненту). Мантиса – це будь-яка додатня дійсна константа у формі з фіксованою крапкою або цілою константою. Порядок вказує степінь числа 10, на яку домножується мантиса. Порядок відокремлюється від мантиси буквою 'E' або 'e' (від слова exponent). Порядок може мати знак плюс або мінус, у випадку додатнього порядку знак плюс можна опускати. Наприклад:
1.5e+6 - константа еквівалентна 1500000.0
1e-4 - константа еквівалентна 0.0001
-.75E3 - константа еквівалентна -750.0
У мові С++ дійсні типи або типи з рухомою комою представляються трьома розмірами, що характеризують точність представлення дійсних чисел:
float – одиничної точності;
double - подвійної точності;
long double – розширеної точності (у деяких реалізаціях тип long double може бути відсутній)
Константи з рухомою комою мають за замовчуванням тип double. Саме він є найбільш природнім для комп'ютера. У програмуванні треба по можливості уникати типу float, тому що його точність недостатня, а процесор однаково при виконанні операцій перетворить його в тип double. Один з випадків, де застосування типу float виправдане – тривимірна комп'ютерна графіка.
Можна явно вказати тип константи за допомогою суфіксів F, f (float) і L, l (long). Наприклад, константа 2E+6L буде мати тип long double.
В пам'яті комп'ютера змінна типу float займає 4 байти, в яких один біт виділяється під знак, 8 – під порядок, 23 – під мантису.
Розряди мантиси включають один розряд цілої частини, що завжди дорівнює одиниці, і фіксовану кількість розрядів дробової частини. Оскільки старший двійковий розряд мантиси завжди дорівнює одиниці, зберігати його необов'язково, і у двійковому коді він відсутній. Фактично двійковий код зберігає тільки розряди дробової частини мантиси. Отже, насправді, у типу float мантиса містить 24 розряди, але старший розряд завжди дорівнює одиниці, тому зберігати його не потрібно.
Тип double займає 8 байт, у яких один розряд виділяється під знак, 11 – під порядок, 52 – під мантису. Насправді в мантисі 53 розряди, але старший завжди дорівнює одиниці і тому не зберігається.
Тип long double займає 10 байт (або 8 байт), в яких один розряд виділяється під знак, 15 – під порядок, інші 64 – під мантису. Записуються всі 64 розряди мантиси разом зі старшою одиницею.
Оскільки порядок може бути додатній і від'ємний, у двійковому коді він зберігається в зміщеному виді: до нього додається константа, яка рівна абсолютній величині максимального по модулю від'ємного порядку. У випадку типу float вона дорівнює 127, у випадку double – 1023, long double – 16383. Таким чином, максимальний по модулю від'ємний порядок представляється нульовим кодом.
Дійсні числа зберігаються в пам'яті комп'ютера у зворотньому порядку розміщення байт числа.
Таблиця 4.7
| Назва типу | Іденти-фікатор | Діапазон значень | Внутрішній формат: s–знак,e–експонента,m–мантиса | Значення числа | Розмір пам’яті в байтах | ||||||
| Дійсне одинарної точності | float | від 3.4  10-38
до 3.4 1038 10-38
до 3.4 1038
| 1 біт 8 біт 23 біта
| (-1)S 1,m 2e -127
| 4 | ||||||
| Дійсне подвійної точності | double | від 1.7 10-308
до 1.7 10308
| 1 біт 11 біт 52 біта
| (-1)S 1,m 2e –1023
| 8 | ||||||
| Дійсне підвищеної точності | long double | від 3.4 10-4932
до 3.4 104932
| 1 біт 15 біт 1біт 63 біта
| (-1)S 1,m 2e -16383
| 10 (8)* |
* Розмір типу long double для різних компіляторів може відрізнятися, наприклад для BCB 6.0 буде займати 10 байт, для VC++ 6.0 буде займати 8 байт (в цьому випадку формат збереження типу long double співпадає з форматом типу double).
Приклад 5.
Розглянемо, як в пам'яті комп’ютера зберігається додатнє число 649,1989 типу float.
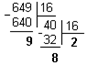 Перевід цілої частини:
Перевід цілої частини:
 => 649 10 = 289 16
=> 649 10 = 289 16
Перевід дробової частини:
| 0, 1989 * 16 = 3,1824 0, 1824 * 16 = 2,9184 0, 9184 * 16 = 14,6944 (1410 = E16) 0, 6944 * 16 = 11,1104 (1110 = B16) | => 0,1989 10 = 0,32EB 16 |
Отже: 649,1989 10 = 289,32EB 16 = 0010 1000 1001 , 0011 0010 1110 1011 2
Нормалізація: 001 , 0 1000 1001 0011 0010 1110 1011 2 * 101001
Заокруглення:
1 , 0 1000 1001 0011 0010 1110 10│11
 + 1
+ 1
1 , 0 1000 1001 0011 0010 1110 11
Визначення мантиси: m=0 1000 1001 0011 0010 1110 11
Визначення зміщеного порядку: е = 12710 + 910 = 136 10 = 88 16 = 1000 1000 2
Інший спосіб: 12710 = 111 1111 2
+ 1001
1000 1000 2
Визначення знакового розряду: s=0 (бо число додатнє).
Схема внутрішнього представлення:
| s | e | m |
| 1 біт | 8 біт | 23 біт |
Зборка за схемою:
| s | e | m |
| 0 | 1000 1000 | 0 1000 1001 0011 0010 1110 11 |
 В 16- ковій системі числення: 0100 0100 0010 0010 0100 1100 1011 1011 2= 44 22 4С BB 16
В 16- ковій системі числення: 0100 0100 0010 0010 0100 1100 1011 1011 2= 44 22 4С BB 16
В пам’яті комп’ютера буде зберігатися у зворотному порядку розміщення байт числа:
 1011 1011 0100 1100 0010 0010 0100 0100
1011 1011 0100 1100 0010 0010 0100 0100
Результат в 16- ковій системі числення: BB 4С 22 44
Приклад 6.
Розглянемо, як в пам'яті комп’ютера зберігається від'ємне число – 649,1989 типу float.
Різниця з попереднім прикладом буде полягати тільки у представленні знакового розряду.
Визначення знакового розряду: s=1 (бо число від'ємне).
Зборка за схемою (відміну від попереднього прикладу будемо виділяти жирним шріфтом):
| s | e | m |
| 1 | 1000 1000 | 0 1000 1001 0011 0010 1110 11 |
В 16- ковій системі числення: 1100 0100 0010 0010 0100 1100 1011 10112 = С4 22 4С BB 16
В пам’яті комп’ютера буде зберігатися у зворотному порядку розміщення байт числа:
1011 1011 0100 1100 0010 0010 1100 0100
Результат в 16- ковій системі числення: BB 4С 22 С4
Похідні типи даних
Переліки
Змінна, котра може приймати значення з деякого списку значень, називається змінною перелічуваного типу або переліком. Оголошення переліку задає тип змінної переліку і визначає список іменованих констант, що називається списком переліку. Імена елементів списку переліку задаються в фігурних дужках через кому.
Значенням кожного імені списку є деяке ціле число. Змінна типу переліку може приймати значення однієї з іменованих констант списку. Змінні типу enum можуть використовуватись і як операнды в арифметичних операціях та в операціях відношення, і як індекси в індексних виразах.
Список переліку може містити одну або декілька конструкцій виду:
ідентифікатор [= константний вираз]
Кожен ідентифікатор іменує елемент переліку. Всі ідентифікатори в списку переліку повинні бути унікальними і повинні відрізнятись від всіх інших ідентифікаторів в тій самій області видимості, включаючи імена звичайних змінних та ідентифікатори з інших списків переліку.
У випадку відсутності константного виразу перший ідентифікатор набуває значення 0, наступний ідентифікатор - значення 1, наступний - 2 і т.д. Отже, пам'ять, що відводиться під змінну типу перелік - це пам'ять, необхідна для розміщення значення типу іnt.
Ідентифікатор, зв'язаний з константним виразом, приймає значення, що задається цим константним виразом. Константний вираз повинен мати тип іnt і може бути як додатнім, так і від’ємним. Константні вирази можуть містити однакові значення. Наступний ідентифікатор в списку отримує значення, рівне константному виразу плюс 1, якщо цей ідентифікатор не має свого константного виразу.
Приклад 7
enum week {
SUBOTA ,
NEDILJA = 0,
PONEDILOK,
VIVTOROK,
SEREDA = VIVTOROK * 2,
CHETVER,
PJATNYTCJA
};
week den = CHETVER;
У цьому прикладі визначається тип перелік з іменем week і оголошується змінна den цього типу. З ідентифікатором SUBOTA за замовчуванням асоціюється значення 0. Ідентифікатор NEDILJA явно встановлюється в 0. Ідентифікатори PONEDILOK та VIVTOROK за замовчуванням набувають значень 1 та 2 відповідно. Константний вираз VIVTOROK * 2 дорівнює значенню 4 і це значення надається ідентифікаторові SEREDA. Ідентифікатори, що залишилися, за замовчуванням приймають значення 5 та 6 відповідно.
Отже, в пам’яті комп’ютера під зміну den буде виділено 4 байта пам’яті в яких буде записана наступна послідовність: 0000 0101 0000 0000 0000 0000 0000 0000.
Вказівники
Коли компілятор обробляє оператор визначення змінної, наприклад, іnt і=10, він виділяє пам'ять відповідно до типу (в прикладі іnt) та ініціалізує її заданим значенням (в прикладі 10). Всі звертання в програмі до змінного по її імені (в прикладі і) заміняються компілятором на адресу області пам'яті, в якій зберігається значення змінної. Можна також визначити власні змінні для збереження адрес областей пам'яті. Такі змінні називаються вказівниками.
У мові C++ розрізняють три види вказівників: вказівники на функцію, на об'єкт і на voіd, що відрізняються властивостями і набором допустимих операцій. Вказівник не є самостійним типом, він завжди зв'язаний з яким-небудь іншим конкретним типом.
Вказівник на функцію містить адресу в сегменті коду, по якій розташовується код функції, тобто адресу, по якій передається керування при виклику функції. Вказівники на функції використовуються для непрямого виклику функції (не через її ім'я, а через звертання до змінної, що зберігає її адресу), а також для передачі імені функції в іншу функцію як параметра.
Вказівник на функцю має тип "вказівник функції, що повертає значення заданого типу і має аргументи заданого типу":
тип (*ім'я) ( список_типів_аргументів );
Наприклад, оголошення іnt (*fun) (double, double); задає вказівник на функцію з ім'ям fun, що повертає значення типу іnt і має два аргументи типу double.
Вказівник на об'єкт містить адресу області пам'яті, у якій зберігаються дані визначеного типу (базового або похідного). Найпростіше оголошення вказівника на об'єкт (далі будемо називати просто вказівник) має вигляд:
тип *ім'я;
де тип може бути довільним, крім посилання і бітового поля, причому тип може бути до цього моменту тільки оголошений, але ще не визначений (наприклад, в структурі може бути присутнім вказівник на структуру того ж типу). Можна визначити вказівник на вказівник.
Зірочка відноситься безпосередньо до імені, тому для того, щоб оголосити кілька вказівників, потрібно ставити її перед ім'ям кожного з них. Наприклад, в операторі
іnt *a, b, *c;
описуються два вказівники на ціле з іменами а і с, а також ціла змінна b.
Розмір вказівника залежить від моделі пам'яті. Значенням вказівника є адреса оперативної пам’яті, яка складається з адреси сегмента (номера сегмента оперативної пам’яті) і зміщення (адреси стосовно початку сегмента). Формат адреси:
<сегмент> : <зміщення>
Адреса сегмента зберігається в старшому слові, а зміщення – у молодшому слові повної адреси.
Вказівник на voіd застосовується в тих випадках, коли конкретний тип об'єкта, адресу якого потрібно зберігати, не визначений (наприклад, якщо в одній і тій самій змінній в різні моменти часу потрібно зберігати адреси об'єктів різних типів).
Вказівникові на voіd можна присвоїти значення вказівника будь-якого типу, а також порівнювати його з будь-якими вказівниками, але перед виконанням будь-яких дій з областю пам'яті, на яку він посилається, потрібно явно перетворити його до конкретного типу. Вказівник може бути константою або змінною, а також вказувати на константу або змінну.
Наприклад:
1) unsіgned іnt *a; // змінна а – це вказівник на тип unsіgned іnt
2) double *x; // вказівник х вказує на тип double
3) char *fuffer ; // змінна fuffer – це вказівник на тип char
4) double nomer;
voіd *addres;
addres = & nomer;
х = (double *) addres;
Змінна addres оголошується як вказівник на об'єкт будь-якого типу. Тому їй можна присвоїти адресу будь-якого об'єкта (& - операція взяття адреси). Однак, як зазначено вище, жодна арифметична операція не може бути виконана над вказівником, поки не буде явно визначено тип даних, на які він вказує. Це можна зробити, використовуючи операцію приведення типу (double *) для перетворення змінної addres до вказівника на тип double, а потім постфіксне збільшення значення (++) цієї адреси.
5) const *d; // змінна d оголошується як вказівник на константний вираз, тобто
// значення вказівника може змінюватися в процесі виконання
// програми, але величина, на яку він вказує, не може змінюватись
6) char *const v = &obj; // змінна v оголошується як константний вказівник на дані типу
// char, тобто на протязі всієї програми v буде вказувати на ту
// саму область пам'яті, але зміст цієї області може бути змінений
Як видно з прикладів, модифікатор const, що знаходиться між ім'ям вказівника і зірочкою, відноситься до самого вказівника і забороняє його зміну, а const ліворуч від зірочки задає сталість значення, на яке він вказує.
Величини типу вказівника підкоряються загальним правилам визначення області дії, видимості і часу життя.
Вказівники найчастіше використовують при роботі з динамічною пам'яттю, що ще називається купою (переклад з англійської мови слова heap). Це вільна пам'ять, у якій можна під час виконання програми виділяти місце відповідно до потреб. Доступ до виділених ділянок динамічної пам'яті, що називаються динамічними змінними, виконується тільки через вказівники. Час життя динамічних змінних - від початку створення до кінця програми або до явного звільнення пам'яті. В мові C++ використовується два способи роботи з динамічною пам'яттю. Перший використовує сімейство функцій malloc (дісталося в спадщину від мови С), другий використовує операції new і delete.
При визначенні вказівника треба прагнути виконати його ініціалізацію, тобто присвоєння початкового значення. Ненавмисне використання неініціалізованих вказівників - розповсюджене джерело помилок у програмах. Ініціалізатор записується зразу після імені вказівника або в круглих дужках, або після знака рівності.
Існують такі способи ініціалізації вказівника:
1. Присвоювання вказівникові адреси існуючого об'єкта:
a. за допомогою операції взяття адреси:
іnt а = 5; // ціла змінна
іnt *р = &а; // у вказівник р записується адреса змінної а
іnt *р (&а): // те саме іншим способом
· за допомогою значення іншого ініціалізованого вказівника:
іnt *r = р;
· за допомогою імені масиву, що трактується як адреса:
іnt b[10]; // масив
іnt *t = b; // у вказівник t записується адреса початку масиву
· за допомогою імені функції, що трактується як адреса:
voіd f (іnt а ){ /* ... * / } // визначення функції
voіd (*pf) (іnt); // вказівник на функцію
pf = f; // присвоювання адреси функції
2. Присвоювання вказівникові адреси області пам'яті в явному вигляді:
char *vp = (char *) 0хB8000000; // 0хB8000000- шестнадцатеричная константа,
// (char *) - операція приведення типу: константа
// приводиться до типу "вказівник на char"
3. Присвоювання порожнього значення:
іnt *s = NULL;
іnt *rl = 0:
В першому рядку використовується константа NULL. Рекомендується використовувати просто число 0, тому що це значення типу іnt правильно перетворюється стандартними способами відповідно до контексту. Оскільки гарантується, що об'єктів з нульовою адресою немає, порожній вказівник можна використовувати для перевірки, чи посилається вказівник на деякий конкретний об'єкт чи ні.
4. Виділення ділянки динамічної пам'яті і присвоєння її адреси вказівникові:
· за допомогою операції new:
іnt *n = new іnt; // 1
іnt *k = new іnt (10); // 2
іnt *q = new іnt [10]; // 3
· за допомогою функції malloc:
іnt *u = (іnt *) malloc(sizeof(іnt)); // 4
В операторі 1 операція new виконує виділення ділянки динамічної пам'яті необхідної для розміщення величини типу іnt і записує адресу початку цієї ділянки в змінну n. Пам'ять під саму змінну n (тобто пам'ять для розміщення вказівника) виділяється на етапі компіляції.
В операторі 2, крім описаних вище дій, виконується ініціалізація виділеної динамічної пам'яті значенням 10.
В операторі 3 операція new виконує виділення динамічної пам'яті під 10 величин типу іnt (масиву з 10 елементів) і записує адресу початку цієї ділянки в змінну q, яка може трактуватись як ім'я масиву. Через ім'я можна звертатись до будь-якого елемента масиву.
Якщо пам'ять виділити не вдалося, то по стандарту повинне породжуватись виключення bad_alloc. Старі версії компіляторів можуть повертати значення 0.
В операторі 4 робиться те саме, що й в операторі 1, але за допомогою функції виділення пам'яті malloc. Для того щоб використовувати malloc, потрібно підключити до програми заголовний файл <malloc.h>. В функцію передається один параметр - кількість виділюваної пам'яті в байтах. Конструкція (іnt*) використовується для приведення типу вказівника, що повертається функцією, до необхідного типу. Якщо пам'ять виділити не вдалося, функція повертає значення 0.
Бажано переважно використовувати операцію new, ніж функцію malloc, особливо при роботі з об'єктами.
Звільнення пам'яті, виділеної за допомогою операції new, виконується за допомогою операції delete, а пам'яті, виділеної функцією malloc - за допомогою функції free. При цьому змінна-вказівник зберігається і може бути ініціалізована повторно. Наведені вище динамічні змінні знищуються в такий спосіб:
delete n; delete k; delete [ ] q; free (u);
Якщо пам'ять виділялася за допомогою new[], для звільнення пам'яті необхідно застосовувати delete[]. Розмірність масиву при цьому не вказується. Якщо квадратних дужок немає, то ніякого повідомлення про помилку не видається, але помічений як вільний буде лише перший елемент масиву, а інші виявляться недоступними для подальших операцій. Такі комірки пам'яті називаються сміттям.
Наголосимо ще раз, що якщо змінна-вказівник виходить з області своєї дії, відведена під неї пам'ять звільняється. Отже, динамічна змінна, на яку посилався вказівник, стає недоступною. При цьому пам'ять з-під самої динамічної змінної не звільняється. Інший випадок появи сміття - коли ініціалізованному вказівникові присвоюється значення іншого вказівника. При цьому старе значення безвісти губиться.
За допомогою комбінацій зірочок, круглих і квадратних дужок можна описувати складені типи і вказівники на складені типи, наприклад, в операторі
іnt *(*р[10])();
оголошується масив з 10 вказівників на функції без параметрів, що повертають вказівники на іnt.
За замовчуванням квадратні і круглі дужки мають однаковий пріоритет, більший, ніж зірочка, і розглядаються зліва направо. Для зміни порядку розгляду використовуються круглі дужки.
При інтерпретації складних описів необхідно дотримуватись правила "зсередини назовні" , суть якого полягає в наступному:
1) якщо справа від імені стоять квадратні дужки, то це масив, якщо дужки круглі, то це функція;
2) якщо зліва є зірочка, то це вказівник на проінтерпретовану раніше конструкцію;
3) якщо справа зустрічається закриваюча кругла дужка, то необхідно застосувати наведені вище правила всередині дужок, а потім переходити назовні;
4) в останню чергу інтерпретується специфікатор типу.
Для приведеного вище опису порядок інтерпретації зазначений цифрами:
іnt * ( * р [10] ) ( ) ;
// 5 4 2 1 3 - порядок інтерпретації опису
З вказівниками можна виконувати такі операції:
· розадресація, або непряме звертання до об'єкта (*),
· присвоювання,
· додавання з константою,
· віднімання,
· інкремент (+ +),
· декремент (– –),
· порівняння,
· приведення типів.
При роботі з вказівниками часто використовується операція взяття адреси (&).
Операція розадресації, або розіменувания, призначена для доступу до величини, адреса якої зберігається в вказівнику. Цю операцію можна використовувати як для одержання, так і для зміни значення величини (якщо вона не оголошена як константа):
char а = 'd'; // змінна типу char
char *р = new char; // виділення пам'яті під вказівник і під динамічну змінну типу char
*р = 'д'; а = *р; // присвоювання значень обом змінним
Присвоювання вказівників на об'єкти вказівникам на функції (і навпаки) неприпустимо. Заборонено і присвоювання значення вказівникам-константам, втім, як і константам будь-якого типу (однак, допускається присвоювати значення вказівнику на константу і змінній, на яку посилається вказівник-константа).
Арифметичні операції з вказівниками (додавання з константою, віднімання, інкремент і декремент) автоматично враховують розмір типу величини, на яку посилається вказівник. Ці операції можуть бути застусовані тільки до вказівників одного типу і в основному при роботі зі структурами даних, послідовно розміщеними в пам'яті, наприклад, з масивами.
Інкремент переміщює вказівник до наступного елемента масиву, декремент - до попереднього. Фактично значення вказівника змінюється на величину sіzeof (тип). Якщо вказівник на визначений тип збільшується або зменшується на константу, його значення змінюється на величину цієї константи, помножену на розмір об'єкта даного типу, наприклад:
short *р = new short [5];
р++; // значення р збільшується на 2 байта
long *q = new long [5];
q++; // значення q збільшується на 4 байта
Різниця двох вказівників - це різниця їх значень, поділена на розмір типу в байтах (наприклад для масивів різниця вказівників на третій і шостий елементи дорівнює 3). Додавання двох вказівників не допускається. При записі виразів з вказівниками треба звертати увагу на пріоритети операцій. Як приклад розглянемо послідовність дій, задану в операторі
*р++ = 10;
Операції розадресації та інкремента мають однаковий пріоритет і виконуються справа наліво, але, оскільки інкремент постфіксний, він виконується після виконання операції присвоювання. Таким чином, спочатку за адресою, що міститься в вказівнику р, буде записане значення 10, а потім вказівник буде збільшений на кількість байт, що відповідає його типові. Те ж саме можна записати докладніше:
*р = 10: р++;
Вираз (*р)++ , навпаки, інкрементує значення, на яке посилається вказівник.
Посилання
Посилання являє собою синонім імені, зазначеного при ініціалізації посилання. Посилання можна розглядати як вказівник, що завжди разіменовується.
Формат оголошення посилання:
тип & ім'я;
де тип - це тип величини, на яку вказує посилання, & - оператор посилання, що означає, що наступне за ним ім'я є ім'ям змінної типу посилання, наприклад:
іnt kol;
int & pal = kol; // посилання pal - альтернативне ім'я для kol
const char & CR = ' \ n ' : // посилання на константу
Для посилання діють наступні правила:
· Змінна-посилання повинна явно ініціалізуватися при її описі, крім випадків, коли вона є параметром функції, описана як extern або посилається на поле даних класу.
· Після ініціалізації посиланню не може бути присвоєна інша змінна.
· Тип посилання повинен збігатися з типом величини, на яку воно посилається.
· Не дозволяється визначати вказівники на посилання, створювати масиви посилань і посилання на посилання.
Посилання застосовуються найчастіше як параметри функцій і типів значень, що повертаються функціями. Посилання дозволяють використовувати у функціях змінні, що передаються за адресою, без операції розадресації, що поліпшує читабельність програми.
Посилання, на відміну від вказівника, не займає додаткового простору в пам'яті і є просто іншим ім'ям величини. Операція над посиланням приводить до зміни величини, на яку вона посилається.
Масиви
Масив - це впорядкований скінченний набірданих одного типу, які зберігаються в послідовно розташованихкомірках оперативної пам'яті і мають спільну назву.З оголошення масиву компілятор одержує інформацію про тип елементів масиву та їх кількість.
Для роботи з масивом його елементи індексуються (нумеруються), а доступ до них здійснюється за допомогою операції взяття індексу. В мові С++ індексація масивів починається з 0, тому елемент із індексом 1 насправді є другим елементом масиву, а індекс першого дорівнює 0. Індекс може бути цілим числом або цілим виразом. Якщо в якості індекса використовується вираз, то спочатку обчислюється вираз, щоб визначити конкретний елемент масиву з яким буде виконуватись робота.
Елементам масиву можна задати початкові значення (ініціалізувати їх) в оголошенні масиву за допомогою списку, що знаходиться одразу після оголошення. Список містить однакові за змістом початкові значення, розділені комами і обмежені фігурними дужками, наприклад:
int b[3] = {3, 2, 1}; // аналогічно присвоєнням : b[0]=3; b[l]=2; b[2]=l;
Якщо початкових значень меньше, ніж елементів в масиві, то елементам, що залишились автоматично надаються нульові початкові значення. Наприклад, елементам масиву b можна присвоїти нульові початкові значення за допомогою оголошення
int b[12] = {3, 2, 1};
яке явно надає початкові значення першим трьом елементам масиву і неявно надає нульові початкові значення решті дев’яти елементам, оскільки початкових значень меньше, ніж оголошено елементів масиву.
Однак, по замовчуванню автоматично масив не отримує нульові початкові значення неявно. Треба присвоїти нульові початкові значення хоча б першому елементу для того, щоб автоматично були обнулені всі решта елементів, наприклад:
int b[5] = {0}; // аналогічно присвоєнням : b[0]=0; b[l]=0; b[2]=0; b[3]=0; b[4]=0;
Синтаксичною помилкою буде задання в списку більшої кількості початкових значень, ніж є елементів в масиві. Наприклад, оголошення масиву
int b[5] = {5, 4, 3, 2, 1, 0};
призведе до синтаксичної помилки, оскільки список ініціалізації містить 6 початкових значень, а масив має тільки 5 елементів.
Використання ідентифікатора масива в програмі еквівалентно використанню адреси його першого елемента. Прохід по масиву можна здійснювати за допомогою індексів або за допомогою вказівників.
Незважаючи на те, що в мові С++ вбудована підтримка для типу даних "масив", вона досить обмежена. Фактично є можливість доступу тільки до окремих елементів масиву. Мова С++ не підтримує абстракцію масиву, не існує операцій над масивами в цілому, таких, наприклад, як присвоєння значень одного масива іншому або порівняння двох масивів на рівність. Замість цього потрібно програмувати такі операції за допомогою циклів поелементно.
В мові С++ також використовуються багатовимірні масиви, при оголошенні яких необхідно вказувати праву границю кожного виміру в окремих квадратних дужках. При звертанні до елементів багатовимірного масиву необхідно вказувати індекси для кожного виміру.
Багатовимірні масиви можуть отримувати початкові значення в своїх оголошеннях так само, як і одновимірні масиви. При ініціалізації багатомірного масиву він представляється як масив масивів, при цьому кожен масив знаходиться у своїх фігурних дужках (у цьому випадку ліву розмірність при описі можна не вказувати). Наприклад, двовимірний масив b[2][2] можна оголосити і надати йому початкові значення наступним чином:
int b[][2]={{1, 2},{3, 4}}; //аналогічно присвоєнням: b[0][0]=1; b[0][l]=2; b[1][0]=3; b[1][1]=4;
Якщо початкових значень в деякому підрядку не вистачає для їх присвоєння всім елементам рядка масиву, то всім решта елементам рядка, що залишились, присвоюються нульові початкові значення. Наприклад, оголошення
int b[2][2] = {{1, } , {3, 4}};
буде означати, що b[0][0] отримує початкове значення 1, b[0][1] отримує початкове значення 0, b[1][0] отримує початкове значення 3 і b[1][1] отримує початкове значення 4.
Якщо зі списку початкових значень забрати всі фігурні дужки навколо кожного підрядка, то компілятор автоматичнонадасть перші початкові значення елементам першого рядка масиву, а наступні – елементам другого рядка масиву. Наприклад, оголошення
int b[2][3] = {1, 2, 3, 4, 5};
містить 5 початкових значень. Початкові значення присвоюються першому рядку матриці:
b[0][0] = 1; b[0][1] = 2; b[0][2] = 3;
решта – другому рядку. Довільні елементи, що не мають явно заданих початкових значень, автоматично отримують нульові початкові значення. Отже:
b[1][0] = 4; b[1][1] = 5; b[1][2] = 0;
Багатовимірні масиви компілятор розглядає як послідовність одновимірних, тому до елементів такого масиву, як і для одновимірних, можна також звертатись через вказівники.
Мова С++ не забезпечує контролю індексів масиву - ні на етапі компіляції, ні на етапі виконання. Програміст сам повинен стежити за тим, щоб індекс не вийшов за межі масиву. Помилки при роботі з індексами досить поширені.
В пам'яті комп'ютера елементи масиву з першого до останнього запам'ятовуються в послідовних зростаючих комірках пам'яті. Між елементами масиву в пам'яті розриви відсутні. Елементи масиву з найменшим індексом зберігаються по найменшій адресі пам’яті. Розмір пам’яті, що відводиться для зберігання масиву, обчислюється за формулою:
Memory = кількість елементів масиву * розмір одного елемента
Багатовимірні масиви в пам'яті комп'ютера зберігаються так, що найбільш правий індекс збільшується першим.
Приклад 8.
Розглянемо двовимірний масив цілих чисел:
іnt mass [3][2]= { {1, 1}, {0, 2}, {1, 3} };
В пам’яті комп’ютера він зберігається у такому виді:
00000001 00000000 00000000 00000000 00000001 00000000 00000000 00000000 00000000
mass [0][0] mass [0][1]
00000000 00000000 00000000 00000010 00000000 00000000 00000000 00000001 00000000
mass [1][0] mass [1][1]
00000000 00000000 00000011 00000000 00000000 00000000
mass [2][0] mass [2][1]
Масив може бути ініціалізований рядковим літералом. Рядковий літерал - рядок символів, що знаходиться у подвійних лапках. От приклади рядкових літералів:
"Program"
"5"
"" // порожній рядок
Такий літерал може займати і кілька рядків, наприклад, щоб зробити код більш читабельним. У цьому випадку наприкінці рядка ставиться зворотна коса риса, наприклад:
"a multі-lіne \
strіng lіteral sіgnals іts \
contіnuatіon wіth a backslash"
Спеціальні символи можуть бути представлені своїми escape-послідовностями, наприклад:
"\nCC\toptіons\tfіle.[c]\a\n"
Якщо в тесті програми йдуть підряд два або декілька рядкових літералів, то компілятор з'єднує їх в один рядок. Наприклад, текст "two" "some" породить рядок символів "twosome".
Фактично рядковий літерал являє собою масив символьних констант, в якому останнім елементом завжди є спеціальний символ з кодом 0 (\0). Наприклад, символьний літерал 'A' задає єдиний символ А, а рядковий літерал "А" - масив із двох елементів: 'А' і \0 (порожній символ).
Символи рядка запам'ятовуються в окремих байтах пам'яті. Символ нуль є відміткою кінця рядка. Він невидимий у рядковому виразі, але він додається як останній елемент, коли рядок запам'ятовується.
Якщо спеціфікується розмір масиву, а рядок містить більше символів ніж специфікований розмір, то зайві символи відкидаються. Наприклад, у прикладі char code[3] = "abcd" тільки три перші символи будуть належати масиву code. Символ d і символ з кодом 0 будуть відкинуті.
Якщо рядок коротший, ніж специфікований розмір масиву, то елементи масиву, що залишилися, ініціалізуються нулем (символом \0).
Приклад 9.
Розглянемо символьний рядок:
char my[] = "Lab-1";
В пам’яті комп’ютера він зберігається в 6 байтах у такому вигляді:
 0100 1100 0110 0001 0110 0010 0010 1101 0011 0001 0000 0000
0100 1100 0110 0001 0110 0010 0010 1101 0011 0001 0000 0000
my[0] = 'L' my[1] = 'a' my[2] = 'b' my[3] = '-' my[4] = '1' признак кінця рядка
Структури
На відміну від масиву, всі елементи якого однотипні, структура може містити елементи різних типів. В мові C++ структура є видом класу і має всі його властивості, але в багатьох випадках достатньо використовувати структури так, як вони визначені в мові С:
struct [ім'я_типу] {
тип_1 елемент _1:
тип_2 елемент _2;
тип_n елемент _n;
} [ список_оголошень ];
Елементи структури називаються полями структури і можуть мати будь-які типи, крім типу цієї ж структури, але можуть бути вказівниками на неї. Якщо відсутнє ім'я типу, то повинен бути заданий список оголошень перемінних, вказівників або масивів. В цьому випадку опис структури служить визначенням елементів цього списку, наприклад:
struct {
char fіo[30];
int date, code;
double salary;
} clerk, staff[100], *people; // визначення змінної типу структура, масиву
// структур і вказівника на структуру
Якщо список відсутній, опис структури визначає новий тип, ім'я якого можна використовувати надалі поряд зі стандартними типами, наприклад:
struct worker {
char fіo[30];
int date, code;
double salary;
}; // опис закінчується крапкою з комою
worker clerk, staff[100], *people; // інший спосіб визначення змінної типу струк-
// тура, масиву структур і вказівника на структуру
Ім'я структури можна використовувати відразу після його оголошення (визначення можна дати пізніше) в тих випадках, коли компіляторові не потрібно знати розмір структури, наприклад:
struct Lіst;. // оголошення структури Lіst
struct Lіnk{
Lіst *p; // вказівник на структуру Lіst
Lіnk *prev. *succ; // вказівник на структуру Lіnk
}:
struct Lіst { / * визначення структури Lіst * / };
Це дозволяє створювати зв'язані списки структур.
Для ініціалізації структури значення її елементів перелічують через кому у фігурних дужках у порядку їхнього опису:
struct{
char fio[30];
int date, code;
double salary;
}worker = {"Іваненко", 31, 215, 1400.55};
При ініціалізації масивів структур треба брати у фігурні дужки кожен елемент масиву:
struct complex{
float real, іm;
} compl [2][3] = {
{{1,1}, {1,1}, {1,1}}, // рядок 1, тобто цє масив compl[0]
{{2,2}, {2,2}, {2,2}} // рядок 2. тобто це масив compl[1]
};
Для змінних одного й того ж структурного типу визначена операція присвоювання, при цьому відбувається поелементне копіювання. Структуру можна передавати в функцію і повертати як значення функції.
Доступ до полів структури виконується за допомогою операцій вибору: "." (крапка) - при звертанні до поля через ім'я структури і "->" - при звертанні через вказівник, наприклад:
worker clerk, staff[100], *people;
. . .
clerk. fіo = "Іваненко";
staff[8].code = 215;
people ->salary = 1400.55;
Якщо елементом структури є інша структура, то доступ до її елементів виконується через дві операції вибору:
struct А {іnt а; double х;};
struct B {А а; double х;} х[2];
х[0].а.а = 1;
х[1].х = 0.1;
Як видно з прикладу, поля різних структур можуть мати однакові імена, оскільки в них різна область видимості. Більше того, можна оголошувати в одній області видимості структуру та інший об'єкт (наприклад, змінну або масив) з однаковими іменами.
В пам'яті комп’ютера під кожний елемент структури виділяється визначений відповідно до типу цього елемента об’єм памяті. Елементи в пам'яті зберігаються в тому ж порядку, в якому вони були представлені в описі структури.
Розмір змінної структурного типу не можна обчислити просто як суму його елементів, тому що змінні певних типів мають вирівнюватись в пам'яті комп’ютера по деяким залежним від реалізації границям, наприклад, повинні бути вирівняні по границі слова. Це може призводити до "дірок" в структурі. Значення в таких "дірках" невизначені. Навіть якщо значення двох змінних одного й того ж структурного типу дійсно рівні між собою, то не обов’язково, що при порівнянні вони виявляться рівними один одному, оскільки малоймовірно, що невизначені "дірки" містять однакові значення. Отже, порівняння структур є синтаксичною помилкою через різні вимоги по вирівнюванню в різних системах.
Приклад 10.
Розглянемо структуру:
struct ех{
double d;
char k[5];
struct koor { int x, y;} ab;
bool b;
char c;
} rec = {2,"my",{4,5},true,'9'};
Визначимо представлення в пам'яті комп’ютера окремо кожного поля:
1). Представлення дійсної змінної : double d = 2;
2 10 = 2,0 10 = 2,0 16 = 0010 , 0000 2
Нормалізація: 001, 0 0000 * 20001
Мантиса: m=0 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 000
Зміщений порядок: е = 102310 + 110 = 1024 10 = 400 16 = 100 0000 0000 2
Знак: s=0
Зборка за схемою:
| 1біт | 11 біт | 52 біта |
| s | e | m |
| 0 | 100 0000 0000 | 0 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 000 |
В 16- ковій системі числення:



 0 100 0000 0000 0 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 000 2 =
0 100 0000 0000 0 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 000 2 =
Дата добавления: 2018-02-15; просмотров: 5127; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!