Вопрос 23. Пирамидальная сортировка
Вопрос 20. Метод Хоара
Метод быстрой сортировки придуман в 1960 году английским математиком Чарльзом Хоаром. Есть несколько причин популярности быстрой сортировки. Во-первых действительно самый быстрый алгоритм. Во-вторых: в отличие от других алгоритмов его намного проще реализовать. Он не требует никакой дополнительной памяти за исключением небольшого стека, внутренний цикл этого алгоритма очень прост и короток.
Недостатки: неустойчивость быстрой сортировки, то есть одинаковые ключи могут идти не в том порядке, в котором они были во входном файле.
Перейдем непосредственно к алгоритму. Он построен по принципу «разделяй и властвуй», который часто используется в программировании. Эторекурсивная реализация быстрой сортировки, хотя избавиться от рекурсии не представляет труда: достаточно завести стек нужного размера. Алгоритм заключается в следующем:
* Выбрать один элемент массива (разделитель или барьерный элемент).
* Разбить массив на две группы:
1. элементы меньшие, чем разделитель
2. большие или равные разделителю
* Рекурсивно отсортировать обе группы.
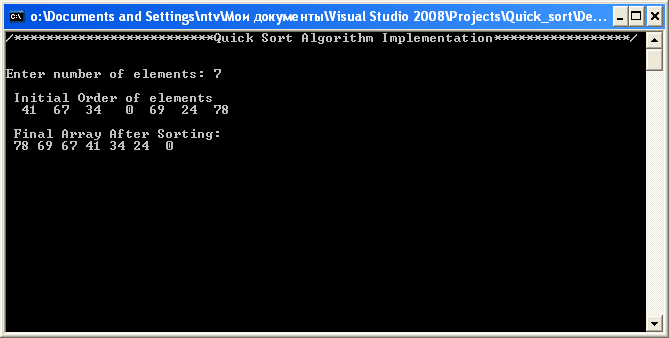
Напр: Ввести 7 элементов41 67 34 0 69 24 78Сортиовка: 78 69 67 41 34 24 0
Вопрос 21. Сортировка выбором
Имеется исходная неотсортированная последовательность x[0..n-1].
Отсортируем ее по возрастанию. Выбираем из нее наименьший элемент и ставим на первое место, то есть меняем местами найденный наименьший элемент и первый.
|
|
|
Затем в последовательности, начиная со 2-го элемента и до конца, аналогично ищем наименьший элемент и меняем его местами со 2-ым. И так далее до предпоследнего элемента. Сортировка заканчивается, когда в оставшейся неотсортированной последовательности остается 1 элемент.
Таким образом, алгоритм имеет (n-1) итераций. И на каждой i=([0..n-1])-ой итерации из элементов x[i..n-1] выбирается наименьший и меняется местами с x[i]. Когда
i=n-1 сортировка прекращается и мы получаем отсортированную последовательность.
Пример. Имеется последовательность: 7, 2, 6, 5, 10, 4. n = 6.
Получим:
0 шаг - i = 0, min = 2(i=1), меняем местами x[0]=7 и x[1]=2, в итоге: 2, 7, 6, 5, 10, 4
1 шаг - i = 1, min = 4(i=5), меняем местами x[1]=7 и x[5]=4, в итоге: 2, 4, 6, 5, 10, 7
2 шаг - i = 2, min = 5(i=3), меняемместами x[2]=6 и x[3]=5, в итоге: 2, 4, 5, 6, 10, 7
3 шаг - i = 3, min = 6(i=3), меняем местами x[3]=6 и x[3]=6, в итоге: 2, 4, 5, 6, 10, 7
4 шаг - i = 4, min = 7(i=5), меняем местами x[4]=10 и x[5]=7, в итоге: 2, 4, 5, 6, 7, 10
псевдокод: сортировка выбором
// до n-2, а не n-1, т.к.последний элемент уже стоит на своем месте for(i = 0; i<n-2; i++) {k = I; t = x[i];for(j = i+1; i<n-1; i++)if(x[j]< t){ k = j; t = x[j];x[k] = x[i];x[i] = t;}}Алгоритм делает n-1 итераций, на каждой из которых осуществляется еще
n-i проходов(сравнений) и одна перестановка.
Следовательно, общее количество операций получаем:
|
|
|
n + (n-1 + 1) + (n-2 + 1) + ... + 2 = 1/2*(n2 + 2*n) - 1.
К достоинствам можно отнести отсутствие расхода памяти: все операции перестановки производятся на исходной последовательности.
Алгоритм - очень похож на алгоритм сортировки вставками. Можно даже сказать, что они в некотором отношении "симметричны": сортировка выбором выбирает нужный элемент из неотсортированной последовательности и вставляет его последним в отсортированную, вставками - выбирает первый элемент из неотсортированных, но вставляет его в нужное место сортированной последовательности.
Вопрос 22. Сортировка вставкой
Проходимся по всем элементам и вставляем каждый текущий элемент на свое место в уже отсортированную последовательность предыдущих просмотренных элементов. В самом начале считаем первый элемент уже отсортированной последовательностью и далее проходимся по всем остальным элементам.
В результате получим: псевдокод: сортировка вставкой
for(i = 1; i<n; i++)/* элементыx[0..i-1] - уже отсортированы */ insertx[i]inx[0..i-1]/* ставим x[i] в правильную позицию */Последовательность сортировки массива из 4-х элементов иллюстрируется ниже. Символ "|" - показывает текущее значение переменной i; элементы слева от этого символа уже отсортированы, справа - нет.
|
|
|
3 | 1 4 2 * 1 3 | 4 2 * 1 3 4 | 2 * 1 2 3 4 |
Вставка элемента в нужную позицию производится циклом, в котором элементы перебираются справа налево, а в переменной j хранится индекс очередного вставляемого элемента.
В цикле текущий элемент переставляется местами с предыдущим, если этот предыдущий элемент существует (т. e. j>0) и текущий элемент еще не установлен в нужное положение (он и предыдущий элементы находятся в неправильном порядке). Итак, получившаяся программа сортировки примет вид: псевдокод: сортировка вставкой, версия #1
For(i = 1; i<n; i++)for(j = i; (j >0) &&(x[j-1]> x[j]); j--)swap(j-1, j);В тех случаях, когда нужно написать собственную сортировку, можно начать именно с этой функции, потому что она очень проста — всего три очевидные строки.
Программу можно ускорить, раскрыв функцию явно, хотя многие оптимизирующие компиляторы способны делать это за нас. Заменим вызов функции нижеследующим кодом, в котором переменная t используется для обмена x[j] и x[j-l]:
t = x[j]; x[j] = x[j-1]; x[j-1] = t;
После этого улучшения появляется возможность сделать следующий шаг. Поскольку переменной t несколько раз присваивается одно и то же значение (исходно находящееся в x[i]), можно вынести присваивания, относящиеся к этой переменной, за рамки внутреннего цикла, а также изменить вид сравнения, что даст третью версию сортировки вставкой:Псевдокод: сортировка вставкой, версия #3
|
|
|
Эта программа сдвигает элементы вправо до тех пор, пока они превосходят значение t, а потом ставит t в правильную позицию. Эта функция из пяти строк чуть сложнее своих предшественников, но работает примерно на 15% быстрее, чем вторая версия той же сортировки.
Вопрос 23. Пирамидальная сортировка
Пирамидальная сортировка в некотором роде является модификацией такого подхода, как сортировка выбором. Естественно, без дополнительных манипуляций с неотсортированной последовательностью мы не добьемся выбора из нее максимального
(в пирамидальной сортировке выбирается максимальный, поэтому дальше будем это всегда предполагать) элемента. Точнее, для такого быстрого выбора из этой неотсортированной последовательности строится некоторая структура. И вот именно суть метода пирамидальной сортировки и состоит в построении такой структуры, называемой соответственно "пирамидой".
Суть методаВначале имеем исходную неотсортированную последовательность. Из нее строится структура данных - пирамида. Пирамида обладает тем свойством, что в ее вершине - находится максимальный элемент. Кроме того, вершина - это элемент в структуре пирамиды с начальным индексом. Поэтому чтобы выбрать из пирамиды максимальный элемент - не нужно делать вообще ничего - нужно просто взять этот начальный элемент структуры пирамиды. Пирамида построена, далее можно начинать основные итерации сортировки. На каждой итерации:
1. Вынимаем вершину пирамиды
2. На ее место вставляем последний в пирамиде элемент
3. "Просеиваем" этот элемент сквозь пирамиду.
И так до последней итерации, на которой из всей пирамиды останется только вершина - ее мы и вставим в конец нашей полученной отсортированной последовательности.
Просеивание. Неясным остался момент "просеивания" элемента сквозь пирамиду.
Под этим подразумевается восстановление баланса пирамиды. После того как мы ставим последний элемент на вершину – пирамида теряет свои свойства, становится "разбалансированной". Поэтому дальше нужно этот элемент поставить в соответствующее ему место, а на вершину восстановить максимальный элемент.
Так работает пирамидальная сортировка: перед сортировкой строится пирамида, на каждой итерации вынимаем из нее максимальный элемент и ставим в свою отсортированную последовательность, и далее восстанавливаем баланс пирамиды.
Структура пирамиды. Теперь рассмотрим, наконец, что же представляет собой эта пирамида. Это бинарное дерево, в котором каждый элемент меньше либо равен его родителю.Например, имеем исходную последовательность:
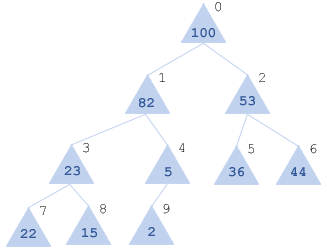 x = [22, 100, 44, 15, 2, 36, 53, 23, 82, 5]
x = [22, 100, 44, 15, 2, 36, 53, 23, 82, 5]
Пирамида для нее будет выглядетьв виде массива. Нумерацию элементов пирамиды определяем просто: проходимся сверху вниз, слева направо по каждому элементу и нумеруем его. В итоге получим то, что изображено на рисунке (цифры черным цветом - искомые индексы).Таким образом, получим x[0] - вершина пирамиды, а левый и правый потомки каждого элемента x[i] будут соответственно: x[2*i+1] и x[2*i+2] и основное свойство пирамиды тогда можно записать как:x[i] >= max( x[2*i+1], x[2*i+2] )
Построение пирамиды
Исходный массив делится пополам, вторая его половина принимается за пирамиду.
Затем последовательно берутся элементы из первой половины и добавляются в пирамиду.
Дело все в том, что для второй половины нашего исходного массива основное свойство пирамиды - выполняется автоматически. Вернее, оно не нарушается, поскольку для элементов второй половины просто уже не будет потомков!!!
Действительно, потомки для всех x[i], где i = n/2..n будут соответственно x[n+1]...x[2*n+2], т.е. такие, которых в нашем массиве уже нет. А поэтому нет смысла для элементов второй половины строить пирамиду последовательно добавляя каждый элемент, т.к. в алгоритме текущий добавляемый элемент просто будет не с чем сравнивать, сыновей-то с такими индексами - просто нет!
Так что спокойно принимаем вторую половину нашей последовательности за пирамиду и приступаем к следующему этапу построения - добавлению элементов.
Чтобы добавить в пирамиду новый элемент x[i], нужно:
- Добавить элемент x[i] слева к массиву уже имеющейся пирамиды
- Найти максимального из его сыновей: maxChild = max( x[2*i+1], x[2*i+2] )
- Если x[i] >= maxChild - завершение процедуры, элемент занимает положенное ему место, добавление завершено, иначе - шаг 4.
- maxChild> x[i] - поменять их местами (т.е. поменять местами x[i] и его большего ребенка).
При этом - просеивание, о котором велась речь - это тоже добавление, поскольку после удаления максимального элемента, т. е. вершины пирамиды, мы ставим на его место последний элемент, а это, по сути, опять же добавление элемента в пирамиду.
Поэтому для просеивания нам не нужно писать еще одну функцию, мы просто вызываем добавление по отношению к этому новому элементу.
В итоге имеем лишь единственную процедуру, которую можно назвать общим понятием для этих двух действий - назовем ее "восстановлением баланса пирамиды".
На каждом шаге этого цикла мы продвигаемся на 2*ij позиций вперед
по направлению к концу пирамиды(массивы), где j - номер итерации цикла.
Пр. Построим пирамиду для последовательности. x = [22, 100, 44, 15, 2, 36, 53, 23, 82, 5].Делим пополам: 22, 100, 44, 15, 2 | 36, 53, 23, 82, 5. Алгоритм:
- Устанавливаем границы пирамиды c 0 по n-1, т.е. на данном этапе вся пирамида x[0..n-1]. А вершина(heap) = 0 и конец(tail) = n-1
- Меняем x[heap] и x[tail]
- Корректируем tail = tail - 1
- Просеиваем новую вершину x[0] через пирамиду x[1..tail].
- Если tail = 1, то конец сортировки, иначе - п.2.
Для нашей построенной в предыдущем примере пирамиды, получим:
- Обмен x[0]=100, x[9]=2; просеивание x[0]=2 через [82 53 23 5 36 44 22 15]
Получим: [82 23 53 22 5 36 44 2 15 100]*. - Обмен x[0]=82 и x[8]=15, просеивание x[0]=15 через [23 53 22 5 36 44 2]
Получим: [53 23 44 22 5 36 15 2 82 100]* - Обмен x[0]=53 и x[7]=2, просеивание x[0]=53 через [23 44 22 5 36 15]
Получим: [44 23 36 22 5 2 15 53 82 100]* - Обмен x[0]=44 и x[6]=15, просеивание x[0]=44 через [23 36 22 5 2]
Получим: [36 23 15 22 5 2 44 53 82 100]* - Обмен x[0]=36 и x[5]=2, просеивание x[0]=2 через [23 15 22 5]
Получим: [23 22 15 2 5 36 44 53 82 100]* - Обмен x[0]=23 и x[4]=5, просеивание x[0]=5 через [23 15 2]
Получим: [22 5 15 2 23 36 44 53 82 100]* - Обмен x[0]=22 и x[3]=2, просеивание x[0]=2 через [5 15]
Получим: [15 5 2 22 23 36 44 53 82 100]* - Обмен x[0]=15 и x[2]=2, просеивание x[0]=2 через [5]. В данном случае все просеивание сведется к обмену x[0]=2 и x[1]=5.
Получим: [5 2 15 22 23 36 44 53 82 100]* - Обмен x[0]=2 и x[1]=5. Просеивание делать уже не имеет смысла. Однако если в конкретной реализации данного алгоритма оно запускается для такого случая - то процедура просеивания должна отличать такую ситуации и не делать никаких перестановок.
В результате получили искомую сортировку: x=[2 5 15 22 23 36 44 53 82 100], что и требовалось.
Следует отметить, что если сравнивать с быстрой сортировкой - то вторая выигрывает по производительности, но при этом как известно расходует намного больше памяти.
Вопрос 24. Унифицированный язык моделирования - UnifiedModelingLanguage (UML)обсудить >>
Пирамидальная сортировка, балансировка пирамиды, просеивание элементов через пирамиду, C++, code #29ссылка+
рейтинг:7/3,4.76(931), управление:
Как видно, алгоритм разбит на 2 важные задачи: функция балансировки пирамиды и собственно сама сортировка.
Производительность: ~O(n*log n)
Расход памяти: - (только счетчики цикла, доп. переменные, вызов функции балансировки)
Тестировалось на: MSVisualStudio 2005, .NETFramework 2.0

обсудить >>
В настоящее время унифицированный язык моделирования – UML - является, пожалуй, самой модной технологией в области программной инженерии. UML позволяет системным архитекторам представлять свое видение системы в виде набора стандартных диаграмм, которые, к тому же, служат отличным средством коммуникации в команде разработчиков и прекрасным помощником в общении с заказчиком. И при всем этом, UML - достаточно логичная и простая для изучения нотация, навыками использования которой, без сомнения, должен овладеть любой специалист, собирающийся работать в области программной инженерии.
Структура определения языка. Довольно часто компиляторы и IDE языков программирования написаны с использованием этих же языков. Подобный метод применяется и при описании UML. Авторы использовали так называемое четырехуровневое мета-моделирование.
Первый уровень- это сами данные.
Второй - это их модель, т. е., например, описание их в программе.
Третий - метамодель, т. е. описание языка построения модели.
Четвертый - мета-метамодель, т. е. описание языка, на котором описана метамодель. Для примера - следующий рисунок, позаимствованный из стандарта UML, показывает применение этого подхода к простым записям о котировках акций 
Рисунок 4 – Пример четырехуровнего моделирования
Метамодель - описание самого языка, мета-метамодель - описание формализма, с помощью которого производится описание языка.
Все это сопровождается комментариями на естественном языке и примерами моделей.
Выводы
• UML - еще один формальный язык, который необходимо освоить каждому, кто собирается заниматься программной инженерией.
• Само собой разумеется, что знание UML не гарантирует построения разумных и понятных моделей, хотя и является для этого необходимым.
• UML предоставляет огромную свободу при рисовании диаграмм и выборе инструмента рисования. Производители инструментов также воспользовались этой свободой, чтобы по своему разумению "украсить" имеющуюся нотацию.
Вопрос 25. UML.Терминология и нотация
Терминология.
Система - совокупность взаимосвязанных управляемых подсистем, объединенных общей целью функционирования.
Подсистема - это система, функционирование которой не зависит от сервисов других подсистем. Программная система структурируется в виде совокупности относительно независимых подсистем. Также определяются взаимодействия между подсистемами.
Таким образом, система представляется в виде набора более простых сущностей, которые относительно самодостаточны. Это можно сравнить с тем, как в процессе разработки программы мы строим графический интерфейс из стандартных "кубиков" - визуальных компонентов, или как текст программы разбивается на модули, которые содержат подпрограммы, объединенные по функциональному признаку, и их можно использовать повторно, в следующих программах.
Модель - это некий объект, отображающий лишь наиболее значимые для данной задачи характеристики системы. Модели бывают разные - материальные и нематериальные, искусственные и естественные, декоративные и математические...
Примеры. Пластмассовые игрушечные автомобильчики - это не что иное, как материальная искусственная модель реального автомобиля.
В ходе медицинских исследований опыты на животных часто предшествуют клиническим испытаниям медицинских препаратов на людях. В таком случае животное выступает в роли материальной естественной модели человека.
Уравнение - математическая модель, и она что-то описывает.
Диаграмма - это графическое представление множества элементов. Обычно изображается в виде графа с вершинами (сущностями) и ребрами (отношениями).
Нотация - это то, что в других языках называют "синтаксисом". Само слово "нотация" подчеркивает, что UML - язык графический, а модели (точнее диаграммы) не "записывают", а рисуют. Одна из задач UML - служить средством коммуникации внутри команды и при общении с заказчиком.
"В рабочем порядке" диаграммы часто рисуют на бумаге от руки, причем обычно - не слишком аккуратно. Поэтому при выборе элементов нотации основным принципом был отбор значков, которые хорошо смотрелись бы и были бы правильно интерпретированы в любом случае их представления. Вообще же, в UML используется четыре вида элементов нотации:фигуры, линии, значки, надписи.
Фигуры используются "плоские" - прямоугольники, эллипсы, ромбы и т. д. Внутри любой фигуры могут помещаться другие элементы нотации.
О линиях стоит сказать лишь то, что своими концами они должны соединяться с фигурами. На UML диаграммах вы не встретите линий, нарисованных "сами по себе" и не соединяющих фигуры. Применяется два типа линий - сплошная и пунктирная. Линии могут пересекаться, и хотя таких случаев следует по возможности избегать.
UML предоставляет исключительную свободу - можно рисовать что угодно и как вздумается, лишь бы можно было понять смысл созданных диаграмм. В изображении фигур и значков тоже нет каких-то жестких требований, и разработчики CASE-средств для UML-проектирования вовсю используют эту свободу, применяя различные стили рисования, заливку фигур цветом, тени и т. д. Иногда это смотрится весьма симпатично, а иногда даже раздражает.
Об инструментах рисования
Ктакимпакетамможноотнести:IBM Rational Rose; Borland Together; Gentleware Poseidon; Microsoft Visio; Telelogic TAU G2.
Наиболее известными из этой пятерки являются RationalRose и Together.
TAU G2 от Telelogic - легендарное средство моделирования, которое сочетает в себе мощь и простоту использования, предоставляя уникальную возможность начальной верификации моделей.
Проектирование
UML позволяет строить модели любых программных систем. По этим моделям потом может производиться генерация каркасного кода проектируемых приложений.
Документирование
По большому счету, UML-модели сами по себе уже являются документами. Причем любой элемент на любой диаграмме может быть снабжен ноутсом - текстовым комментарием. Т. е. построение набора диаграмм уже является процессом документирования будущей системы. Он может служить средством обмена информацией.
Кроме этого, UML является отличным средством спецификации систем, причем спецификации в процессе разработки. Разработанные архитектурные решения, задокументированные с помощью UML, могут использоваться повторно.
Теперь о том, для чего UML использовать нельзя:1) UML не является языком программирования; 2)UML - средство моделирования, т. е. создания не программ; 3)UML не является и спецификацией какого бы то ни было инструмента моделирования.
Разработка модели любой системы всегда предшествует ее созданию или обновлению. Это необходимо хотя бы для того, чтобы яснее представить себе решаемую задачу.
Метод объектно-ориентированного анализа позволяет описывать реальные сложные системы наиболее адекватным образом.
Вопрос 26. Диаграммы UML
Диаграмма - это графическое представление множества элементов. Обычно изображается в виде графа с вершинами (сущностями) и ребрами (отношениями).
Примеры диаграмм. Это и схема программы, и схемы монтажа различного оборудования, и дерево файлов и каталогов на диске. В этой отрасли с помощью диаграмм можно визуализировать систему с различных точек зрения.
Одна из диаграмм, например, может описывать взаимодействие пользователя с системой.
Другая - изменение состояний системы в процессе ее работы, третья - взаимодействие между собой элементов системы и т. д.
Сложную систему можно представить в виде набора небольших и почти независимых моделей-диаграмм, каждая модель соответствует некоторой определенной, частной точке зрения на проектируемую систему.
Ни одна отдельная диаграмма не является моделью. Диаграммы - лишь средство визуализации модели, и эти два понятия следует различать. Лишь набор диаграмм составляет модель системы и наиболее полно ее описывает, но не одна диаграмма, вырванная из контекста.
Виды диаграмм.В UML 1.5 - двенадцать типов диаграмм, разделенных на три группы:
- четыре типа диаграмм представляют статическую структуру приложения;
- пять представляют поведенческие аспекты системы;
- три представляют физические аспекты функционирования системы (диаграммы реализации).
Текущая версия UML 2.1 внесла не слишком много изменений. Диаграммы слегка изменились внешне, немного усовершенствовалась нотация, некоторые диаграммы получили новые наименования. Для простых приложений нет необходимости строить все без исключения диаграммы. Напр., для локального приложения не обязательно строить диаграмму развертывания. Важно понимать, что перечень диаграмм зависит от специфики разрабатываемого проекта и определяется самим разработчиком.
Цель - не описать абсолютно все возможности UML, а лишь познакомить с этим языком, дать первоначальное представление об этой технологии.
Существуют Диаграммы: прецедентов;классов;объектов;последовательностей;взаимодействия;состояний;активности;развертывания.
Дата добавления: 2018-02-15; просмотров: 1278; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!