Шкала Чеддока оценки тесноты связи
Тема 6. Статистическое изучение взаимосвязи
Социально-экономических явлений
Задача 6.1. В результате исследования взаимосвязи двух показателей (X – торговая площадь продовольственного магазина, кв.м., Y – годовой товарооборот продовольственного магазина, млн. руб.) получены следующие данные:
| Торговая площадь продовольственного магазина, кв.м. | Годовой товарооборот продовольственного магазина, млн. руб. |
Методом наименьших квадратов найдите линейную функцию, которая наилучшим образом приближает эмпирические (опытные) данные. Сделайте чертеж, на котором в декартовой прямоугольной системе координат отобразите поле рассеивания и график аппроксимирующей функции.
Решение. Аппроксимирующей будет такая функция, график которой проходит как можно ближе к точкам  и при этом является достаточно простой, не «петляя» от точки к точке, и наиболее полно отображает главную тенденцию.
и при этом является достаточно простой, не «петляя» от точки к точке, и наиболее полно отображает главную тенденцию.
Простейший способ нахождения такой функции опирается на метод нахождения наименьшего отклонения между координатами точек эмпирических данных и координатами точек кривой. Этот метод называется методом наименьших квадратов и основан на решении стандартной задачи – нахождения минимума функции двух переменных (см. Приложение 4).
| Рекомендуется для наглядности использовать всю площадь рисунка. |
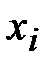 показателя Х, по оси ординат – значения
показателя Х, по оси ординат – значения 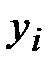 показателя Y.
показателя Y.
Как видим, в качестве аппроксимирующей подходит линейная функция 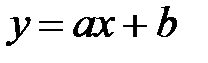 . Коэффициенты a и b можно найти, решив систему линейных уравнений (см. Приложение 4):
. Коэффициенты a и b можно найти, решив систему линейных уравнений (см. Приложение 4):

или после сокращения на п:
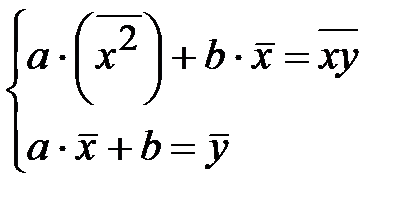 (1)
(1)
Составим вспомогательную таблицу, куда сведём все промежуточные вычисления.
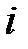
| 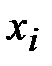
|
| 
| 
|
| 1 | ||||
| 2 | ||||
| 3 | ||||
| 4 | ||||
| 5 | ||||
| 6 | ||||
| 7 | ||||
| 8 | ||||
| 9 | ||||
| 10 | ||||
| 11 | ||||
| 12 | ||||

| ||||

| 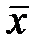 = =
| 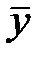 = =
|  = =
| 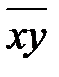 = =
|
Тогда система (1) примет вид: 
Решим её методом Крамера:



Откуда: 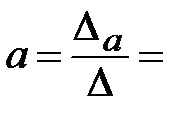

Теперь можно записать уравнение аппроксимирующей прямой:
 .
.
Построим график данной прямой на вышеприведённой диаграмме рассеивания и убедимся, что он проходит точно через скопление точек. Для построения прямой линии достаточно определить координаты её двух точек (с помощью полученного уравнения). Эти точки желательно брать далеко друг от друга, но в районе диаграммы. Поместим координаты этих двух точек в следующую табличку:

| ||
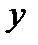
|
Видим, что построенная прямая линия проходит среди точек диаграммы рассеивания.
(В противном случае имеется ошибка в расчётах и полученные значения следует пересчитать!)
Задача 6.2. В результате проведенного исследования по 10 предприятиям фирмы получены следующие данные:
| № пред- приятия | Выработка продукции на одного рабочего, тыс. руб. | Объем произведенной продукции, тыс. руб. |
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 | ||
| 7 | ||
| 8 | ||
| 9 | ||
| 10 | ||
| Итого |
ЧАСТЬ 1
1) Построить диаграмму рассеяния (поле корреляции) данных.
2) Найти уравнение парной линейной регрессии зависимости выработки рабочего от объема производительности труда. Построить прямую регрессии на диаграмме рассеяния.
3) С помощью коэффициента корреляции Пирсона определить степень связи между размером основных фондов и выпуском продукции на один завод.
4) Проверить статистическую значимость коэффициента корреляции Пирсона при 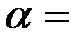 _________.
_________.
ЧАСТЬ 2
1) Вычислить ранговый коэффициент корреляции Спирмена.
2) Проверить статистическую значимость коэффициента корреляции Спирмена при _________.
ЧАСТЬ 3
1) Вычислить ранговый коэффициент корреляции Кендалла.
2) Проверить статистическую значимость коэффициента корреляции Кендалла при _________.
Решение.
ЧАСТЬ 1
1) По приведённым эмпирическим данным построим диаграмму рассеяния, представляющую собой наблюдаемое явление в пространстве двух измерений. При этом будем придерживаться следующего правила: если одну величину рассматривать как «фактор», влияющий на другую величину, то ей будет соответствовать ось Х (горизонтальная ось). Реагирующей на это влияние величине соответствует ось Y (вертикальная ось). Когда четко классифицировать переменные невозможно, распределение производится пользователем.
2) Вид диаграммы рассеяния позволяет сделать вывод о наличии линейной зависимости значений Y от значений X. Аналитически эту связь будет отображать уравнение вида
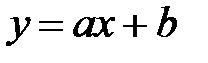 . (2)
. (2)
называемое (в данном случае) уравнением парной линейной регрессии Y на X.
Коэффициенты a и b можно найти методом наименьших квадратов, решив систему линейных уравнений (1):

Составим вспомогательную таблицу, куда сведём все промежуточные вычисления.
|
|
|
|
|
|
| 1 | ||||
| 2 | ||||
| 3 | ||||
| 4 | ||||
| 5 | ||||
| 6 | ||||
| 7 | ||||
| 8 | ||||
| 9 | ||||
| 10 | ||||
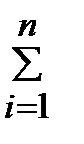
| ||||
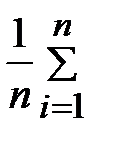
| =
| =
| =
| =
|
Тогда система (1)примет вид:
Решим её методом Крамера:
Откуда
Записываем уравнение парной линейной регрессии Y на X: .
Построим график данной прямой на вышеприведённой диаграмме рассеивания и убедимся, что он проходит точно через скопление точек. Определяем координаты двух точек (из области диаграммы):
|
| ||
|
|
Убеждаемся в том, что построенная прямая линия проходит среди точек диаграммы рассеивания (!).
В уравнении 2 коэффициент а называется выборочным коэффициентом регрессии Y на X, и, обычно, обозначается, как  . Коэффициент регрессии показывает интенсивность влияния факторов на результативный показатель (как в среднем изменится результативный признак Y, если факторный признак X увеличится на единицу).
. Коэффициент регрессии показывает интенсивность влияния факторов на результативный показатель (как в среднем изменится результативный признак Y, если факторный признак X увеличится на единицу).
В нашем случае 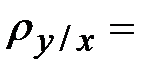 _______. Таким образом, увеличение выработки продукции на одного рабочего (X) на 1 тыс. руб. приведёт к увеличению объема произведенной продукции (Y) на _____________ тыс. руб.
_______. Таким образом, увеличение выработки продукции на одного рабочего (X) на 1 тыс. руб. приведёт к увеличению объема произведенной продукции (Y) на _____________ тыс. руб.
3) Степень (тесноту) связи между размером основных фондов и выпуском продукции на один завод определим с помощью линейного коэффициента корреляции (коэффициента корреляции Пирсона):
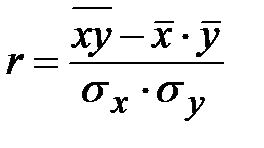 . (2)
. (2)
Как видно из формулы, для его вычисления нам понадобится найти групповые дисперсии 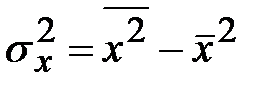 и
и 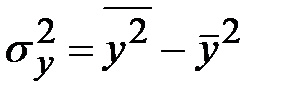 .
.
Составим очередную вспомогательную расчётную таблицу.
|
|
|
|
| 
|
|
| 1 | |||||
| 2 | |||||
| 3 | |||||
| 4 | |||||
| 5 | |||||
| 6 | |||||
| 7 | |||||
| 8 | |||||
| 9 | |||||
| 10 | |||||
| |||||
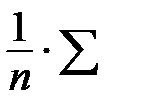
| =
| =
| =
| 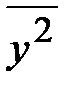 = =
| =
|
Тогда:
 _______________
_______________ 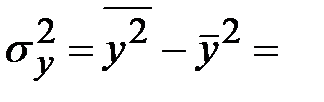 _______________
_______________
Находим средние квадратические отклонения:
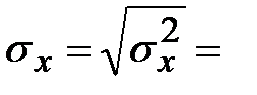 _____________,
_____________, 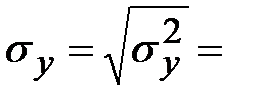 ______________
______________
Следовательно, линейный коэффициент корреляции будет равен:

(Будьте внимательны, выборочный коэффициент корреляции по модулю не может быть больше 1!)
Проверим правильность вычисления через связь между коэффициентами корреляции и регрессии:
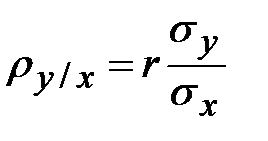 . (3)
. (3)
Как видим, при подстановке всех найденных значений равенство (3) превращается в тождество:
_______ 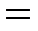 _________
_________
Выборочный коэффициент корреляции характеризует тесноту линейной связи между случайными величинами X и Y . Для оценки тесноты связи признаков X и Y пользуются шкалой Чеддока (Приложение 2).
В нашей задаче 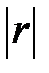 =_____, поэтому теснота связи X и Y _______________.
=_____, поэтому теснота связи X и Y _______________.
4) Проверим статистическую значимость коэффициента корреляции, то есть оценим, насколько выбранная линейная форма регрессии соответствует, то есть адекватна, выборочным данным.
Для данной проверки используем критерий Стьюдента:
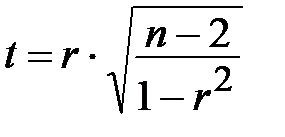 ,
,
где n – объём выборки, а случайная величина t распределена по закону Стьюдента с 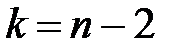 числом степеней свободы (число степеней свободы равно числу классов вариационного ряда минус число условий, при которых он был сформирован).
числом степеней свободы (число степеней свободы равно числу классов вариационного ряда минус число условий, при которых он был сформирован).
Вычисляем эмпирическое значение критерия:
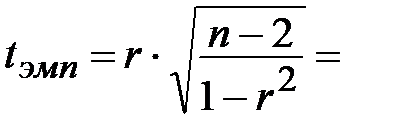
По таблице критических точек распределения Стьюдента (приложение 1) по заданному уровню значимости α = ______ и числу степеней свободы 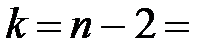 ________ находим критическую точку
________ находим критическую точку  _________.
_________.
Получили:
1) 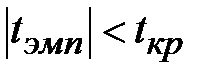 , выборочный коэффициент корреляции незначим, а X (выработка продукции на одного рабочего) и Y (объем произведенной продукции) некоррелированы, т.е. не связаны линейной зависимостью. Следовательно, прямая регрессии не адекватна выборочным данным и следует подобрать более подходящую форму регрессии.
, выборочный коэффициент корреляции незначим, а X (выработка продукции на одного рабочего) и Y (объем произведенной продукции) некоррелированы, т.е. не связаны линейной зависимостью. Следовательно, прямая регрессии не адекватна выборочным данным и следует подобрать более подходящую форму регрессии.
2) 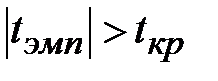 , выборочный коэффициент корреляции значим, а X (выработка продукции на одного рабочего) и Y (объем произведенной продукции) коррелированы, т.е. связаны линейной зависимостью. Следовательно, прямая регрессии адекватна выборочным данным.
, выборочный коэффициент корреляции значим, а X (выработка продукции на одного рабочего) и Y (объем произведенной продукции) коррелированы, т.е. связаны линейной зависимостью. Следовательно, прямая регрессии адекватна выборочным данным.
(ненужное зачеркнуть!)
ЧАСТЬ 2
1) На практике, для определения тесноты связи двух признаков часто применяется коэффициент ранговой корреляции Спирмена. Значениям каждого признака ставятся в соответствие значения натуральных рядов, то есть, значения признаков ранжируются по степени возрастания (от 1 до n): меньшему значению ставят в соответствие ранг равный единице, следующему значению – ранг равный двум, далее – ранг равный трём и т.д. Причём, если встречаются несколько одинаковых значений признака, то им присваивается одинаковый ранг, вычисленный, как среднее арифметическое между рангами. Рассмотрим пример ниже.
----------------------------------------------------------------------------------------------------------------------------------------------------------------------
Исходные данные
| X | Y |
| 8 | 7 |
| 4 | 8 |
| 3 | 5 |
| 4 | 3 |
| 9 | 3 |
| 4 | 6 |
Смотрим, как расставить ранги по Х. Для этого выпишем по порядку все значения Х:
| Х | 3 | 4 | 4 | 4 | 8 | 9 |
| № | 1 | 2 | 3 | 4 | 5 | 6 |
Находим среднее арифметическое для номеров, соответствующих значению Х = 4:  – это и будет ранг для «4». Аналогично получаем ранги для значений признака Y.
– это и будет ранг для «4». Аналогично получаем ранги для значений признака Y.
Возвращаемся к исходным данным и приписываем ещё по одному столбцу справа от каждого признака с номерами их значений.
Ранжированные данные
| X | Ранг Х | Y | Ранг Y |
| 8 | 5 | 7 | 5 |
| 4 | 3 | 8 | 6 |
| 3 | 1 | 5 | 3 |
| 4 | 3 | 3 | 1,5 |
| 9 | 6 | 3 | 1,5 |
| 4 | 3 | 6 | 4 |
-----------------------------------------------------------------------------------------------------------------------
После присвоения рангов значениям признаков определяется разница (разность d) между рангами, соответствующими одному наблюдению. С её помощью находят коэффициент ранговой корреляции Спирмена по формуле:
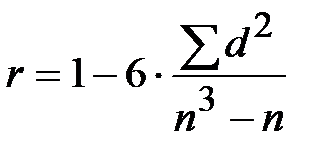 ,
,
где п – объём выборки.
Составим вспомогательную таблицу, куда сведём исходные данные и промежуточные вычисления.
|
|
| Ранг 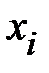 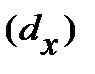
|
| Ранг 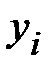 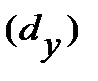
| 
| 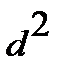
|
| 1 | ||||||
| 2 | ||||||
| 3 | ||||||
| 4 | ||||||
| 5 | ||||||
| 6 | ||||||
| 7 | ||||||
| 8 | ||||||
| 9 | ||||||
| 10 | ||||||
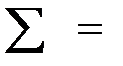
|
Отсюда получаем, что коэффициент ранговой корреляции Спирмена:
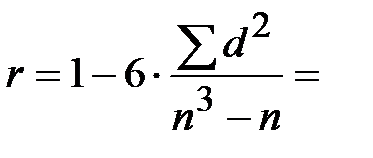
2) Оценим значимость коэффициента ранговой корреляции Спирмена с помощью критерия Стьюдента (который использовали и при оценке значимости коэффициента корреляции Пирсона):
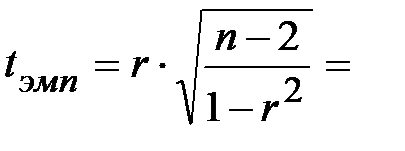
По таблице критических точек распределения Стьюдента (приложение 1) по заданному уровню значимости α = ______ и числу степеней свободы 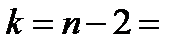 ________ находим критическую точку
________ находим критическую точку  _________.
_________.
Получили:
· , коэффициент корреляции Спирмена незначим, и X (выработка продукции на одного рабочего) и Y (объем произведенной продукции) некоррелированы, т.е., статистически значимой корреляционной связи между показателями нет.
· , коэффициент корреляции Спирмена значим, и X (выработка продукции на одного рабочего) и Y (объем произведенной продукции) коррелированы, т.е., между показателями имеется статистически значимая корреляционная связь.
(ненужное зачеркнуть!)
Интервальная оценка для коэффициента ранговой корреляции (доверительный интервал):
 .
.
Находим левую и правую границы для 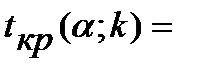 ______:
______:
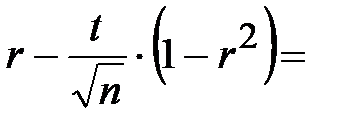
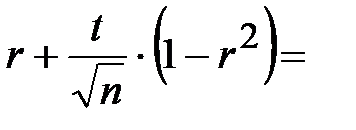
Следовательно, доверительный интервал для коэффициента ранговой корреляции Спирмена: (___________________).
ЧАСТЬ 3
1) Вычисление коэффициента ранговой корреляции Кендалла основано на подсчёте показаний «больше-меньше» при сравнении рангов значений признака (например, Y). При этом значения другого признака (обычно Х) выстраиваются в порядке возрастания (убывания) и им в соответствие ставится ряд натуральных чисел – ранги значений Х от 1 до п. Значения признака Y и соответствующие им ранги выстраиваются таким образом, чтобы каждая пара  повторяла исходные данные. Воспользуемся результатами примера, разобранного на стр. 7.
повторяла исходные данные. Воспользуемся результатами примера, разобранного на стр. 7.
----------------------------------------------------------------------------------------------------------------------------------------------------------------------
Исходные данные
| X | Y |
| 8 | 7 |
| 4 | 8 |
| 3 | 5 |
| 4 | 3 |
| 9 | 3 |
| 4 | 6 |
Расстановка рангов
по Кендаллу
|
Ранжированные данные
(столбцы со значениями признака поставлены рядом для наглядности)
| Ранг Х | X | Y | Ранг Y |
| 1 | 3 | 5 | 3 |
| 3 | 4 | 3 | 1,5 |
| 3 | 4 | 6 | 4 |
| 3 | 4 | 8 | 6 |
| 5 | 8 | 7 | 5 |
| 6 | 9 | 3 | 1,5 |
Следующий шаг: для каждого ранга Y из числа следующих за ним рангов подсчитывается количество больших него по величине рангов (заносится в столбец P) и число рангов, меньших по значению (заносится в столбец Q). Покажем построение такой таблицы для разбираемого примера. Тёмным выделен рабочий столбец, который и будем анализировать.
|
Больше «3» – 4, 6, 5  ;
меньше «3» – 1,5 и 1, 5 ;
меньше «3» – 1,5 и 1, 5  2. 2.
|
| Больше «1,5» – 4, 6, 5 ;
меньше «1,5» – нет 0.
|
Больше «4» – 6, 5 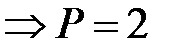 ;
меньше «4» – 1,5 1. ;
меньше «4» – 1,5 1.
|
Больше «6» – нет  ;
меньше «6» – 5 и 1,5 2. ;
меньше «6» – 5 и 1,5 2.
|
---------------------------------------------------------------------------------------------------------------
Коэффициент ранговой корреляции Кендалла находят по формуле:
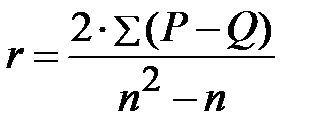
или упрощённым формулам:
 или
или 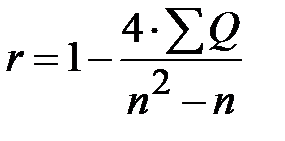 ,
,
где п – объём выборки.
Найдём коэффициент ранговой корреляции Кендалла для наших данных. Составим вспомогательные таблицы, где разместим исходные данные и промежуточные вычисления.
Исходные
данные
| № | X | Y |
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 | ||
| 7 | ||
| 8 | ||
| 9 | ||
| 10 |
Расстановка рангов
по Кендаллу
Покажем стрелками пары исходных данных |
 , чтобы избежать ошибок при совмещении ранжированных рядов
, чтобы избежать ошибок при совмещении ранжированных рядовРанжированные данные
| Ранг Х | X | Y | Ранг Y |
Находим значения P и Q
| № | Ранг Y | P | Q |
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||
| 6 | |||
| 7 | |||
| 8 | |||
| 9 | |||
| 10 | |||
|
|
Находим коэффициент ранговой корреляции Кендалла :
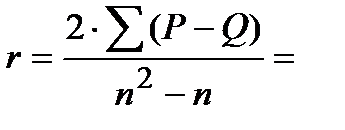
Или по упрощённым формулам:
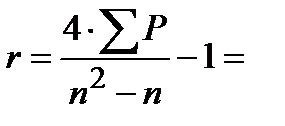
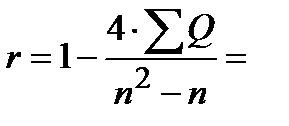
2) Оценим значимость коэффициента ранговой корреляции Спирмена с помощью критерия:
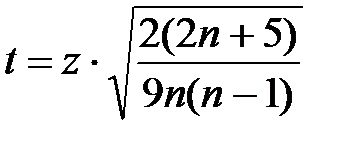 ,
,
где значение z находится по таблице значений функции Лапласса (Приложение 3) при 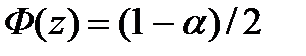 .
.
Для нашего случая  ________, тогда критическое значение z кр = ____ и
________, тогда критическое значение z кр = ____ и
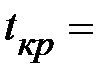
Сравним теперь найденный ранее коэффициент ранговой корреляции Кендалла с критическим значением 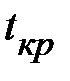 .
.
Получили:
·  , коэффициент корреляции Кедалла незначим, и X (выработка продукции на одного рабочего) и Y (объем произведенной продукции) некоррелированы, т.е., статистически значимой корреляционной связи между показателями нет.
, коэффициент корреляции Кедалла незначим, и X (выработка продукции на одного рабочего) и Y (объем произведенной продукции) некоррелированы, т.е., статистически значимой корреляционной связи между показателями нет.
·  , коэффициент корреляции Кендалла значим, и X (выработка продукции на одного рабочего) и Y (объем произведенной продукции) коррелированы, т.е., между показателями имеется статистически значимая корреляционная связь.
, коэффициент корреляции Кендалла значим, и X (выработка продукции на одного рабочего) и Y (объем произведенной продукции) коррелированы, т.е., между показателями имеется статистически значимая корреляционная связь.
(ненужное зачеркнуть!)
Вывод. _________________________________________________________________________
________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
Приложение 1
Критические точки распределения Стьюдента.
В таблице приведены значения 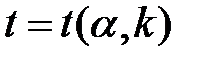 в зависимости от числа степеней свободы и доверительной вероятности P (уровня значимости a = 1 – P).
в зависимости от числа степеней свободы и доверительной вероятности P (уровня значимости a = 1 – P).
| k | Доверительная вероятность (надёжность) P | |||||||
| 0.80 | 0.90 | 0.95 | 0.98 | 0.99 | 0.995 | 0.998 | 0.999 | |
| 1 | 3.0770 | 6.3130 | 12.7060 | 31.820 | 63.656 | 127.656 | 318.306 | 636.619 |
| 2 | 1.8850 | 2.9200 | 4.3020 | 6.964 | 9.924 | 14.089 | 22.327 | 31.599 |
| 3 | 1.6377 | 2.35340 | 3.182 | 4.540 | 5.840 | 7.458 | 10.214 | 12.924 |
| 4 | 1.5332 | 2.13180 | 2.776 | 3.746 | 4.604 | 5.597 | 7.173 | 8.610 |
| 5 | 1.4759 | 2.01500 | 2.570 | 3.649 | 4.0321 | 4.773 | 5.893 | 6.863 |
| 6 | 1.4390 | 1.943 | 2.4460 | 3.1420 | 3.7070 | 4.316 | 5.2070 | 5.958 |
| 7 | 1.4149 | 1.8946 | 2.3646 | 2.998 | 3.4995 | 4.2293 | 4.785 | 5.4079 |
| 8 | 1.3968 | 1.8596 | 2.3060 | 2.8965 | 3.3554 | 3.832 | 4.5008 | 5.0413 |
| 9 | 1.3830 | 1.8331 | 2.2622 | 2.8214 | 3.2498 | 3.6897 | 4.2968 | 4.780 |
| 10 | 1.3720 | 1.8125 | 2.2281 | 2.7638 | 3.1693 | 3.5814 | 4.1437 | 4.5869 |
| 11 | 1.363 | 1.795 | 2.201 | 2.718 | 3.105 | 3.496 | 4.024 | 4.437 |
| 12 | 1.3562 | 1.7823 | 2.1788 | 2.6810 | 3.0845 | 3.4284 | 3.929 | 4.178 |
| 13 | 1.3502 | 1.7709 | 2.1604 | 2.6503 | 3.1123 | 3.3725 | 3.852 | 4.220 |
| 14 | 1.3450 | 1.7613 | 2.1448 | 2.6245 | 2.976 | 3.3257 | 3.787 | 4.140 |
| 15 | 1.3406 | 1.7530 | 2.1314 | 2.6025 | 2.9467 | 3.2860 | 3.732 | 4.072 |
| 16 | 1.3360 | 1.7450 | 2.1190 | 2.5830 | 2.9200 | 3.2520 | 3.6860 | 4.0150 |
| 17 | 1.3334 | 1.7396 | 2.1098 | 2.5668 | 2.8982 | 3.2224 | 3.6458 | 3.965 |
| 18 | 1.3304 | 1.7341 | 2.1009 | 2.5514 | 2.8784 | 3.1966 | 3.6105 | 3.9216 |
| 19 | 1.3277 | 1.7291 | 2.0930 | 2.5395 | 2.8609 | 3.1737 | 3.5794 | 3.8834 |
| 20 | 1.3253 | 1.7247 | 2.08600 | 2.5280 | 2.8453 | 3.1534 | 3.5518 | 3.8495 |
| 21 | 1.3230 | 1.7200 | 2.0790 | 2.5170 | 2.8310 | 3.1350 | 3.5270 | 3.8190 |
| 22 | 1.3212 | 1.7117 | 2.0739 | 2.5083 | 2.8188 | 3.1188 | 3.5050 | 3.7921 |
| 23 | 1.3195 | 1.7139 | 2.0687 | 2.4999 | 2.8073 | 3.1040 | 3.4850 | 3.7676 |
| 24 | 1.3178 | 1.7109 | 2.0639 | 2.4922 | 2.7969 | 3.0905 | 3.4668 | 3.7454 |
| 25 | 1.3163 | 1.7081 | 2.0595 | 2.4851 | 2.7874 | 3.0782 | 3.4502 | 3.7251 |
| 26 | 1.315 | 1.705 | 2.059 | 2.478 | 2.778 | 3.0660 | 3.4360 | 3.7060 |
| 27 | 1.3137 | 1.7033 | 2.0518 | 2.4727 | 2.7707 | 3.0565 | 3.4210 | 3.6896 |
| 28 | 1.3125 | 1.7011 | 2.0484 | 2.4671 | 2.7633 | 3.0469 | 3.4082 | 3.6739 |
| 29 | 1.3114 | 1.6991 | 2.0452 | 2.4620 | 2.7564 | 3.0360 | 3.3962 | 3.8494 |
| 30 | 1.3104 | 1.6973 | 2.0423 | 2.4573 | 2.7500 | 3.0298 | 3.3852 | 3.6460 |
Приложение 2
Шкала Чеддока оценки тесноты связи
| Диапазон
| до 0,3 | 0,3  0,5 0,5
| 0,5 0,7
| 0,7 0,9
| выше 0,9 |
| Теснота связи X и Y | слабая | умеренная | заметная | высокая | весьма высокая |
Приложение 3
Значения функции Лапласа 
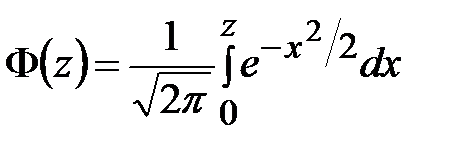
| 
|
|
|
|
|
|
|
| 0,00 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,09 0,10 0,11 0,12 0,13 0,14 0,15 0,16 0,17 0,18 0,19 0,20 0,21 0,22 0,23 0,24 0,25 0,26 0,27 0,28 0,29 0,30 0,31 0,32 0,33 0,34 0,35 0,36 0,37 0,38 0,39 | 0,0000 0,0040 0,0080 0,0120 0,0160 0,0199 0,0239 0,0279 0,0319 0,0359 0,0398 0,0438 0,0478 0,0517 0,0557 0,0596 0,0636 0,0675 0,0714 0,0753 0,0793 0,0832 0,0871 0,0910 0,0948 0,0987 0,1026 0,1064 0,1103 0,1141 0,1179 0,1217 0,1255 0,1293 0,1331 0,1368 0,1406 0,1443 0,1480 0,1517 | 0,40 0,41 0,42 0,43 0,44 0,45 0,46 0,47 0,48 0,49 0,50 0,51 0,52 0,53 0,54 0,55 0,56 0,57 0,58 0,59 0,60 0,61 0,62 0,63 0,64 0,65 0,66 0,67 0,68 0,69 0,70 0,71 0,72 0,73 0,74 0,75 0,76 0,77 0,78 0,79 | 0,1554 0,1591 0,1628 0,1664 0,1700 0,1736 0,1772 0,1808 0,1844 0,1879 0,1915 0,1950 0,1985 0,2019 0,2054 0,2088 0,2123 0,2157 0,2190 0,2224 0,2257 0,2291 0,2324 0,2357 0,2389 0,2422 0,2454 0,2486 0,2517 0,2549 0,2580 0,2611 0,2642 0,2673 0,2703 0,2734 0,2764 0,2794 0,2823 0,2852 | 0,80 0,81 0,82 0,83 0,84 0,85 0,86 0,87 0,88 0,89 0,90 0,91 0,92 0,93 0,94 0,95 0,96 0,97 0,98 0,99 1,00 1,01 1,02 1,03 1,04 1,05 1,06 1,07 1,08 1,09 1,10 1,11 1,12 1,13 1,14 1,15 1,16 1,17 1,18 1,19 | 0,2881 0,2910 0,2939 0,2967 0,2995 0,3023 0,3051 0,3078 0,3106 0,3133 0,3159 0,3186 0,3212 0,3238 0,3264 0,3289 0,3315 0,3340 0,3365 0,3389 0,3413 0,3438 0,3461 0,3485 0,3508 0,3531 0,3554 0,3577 0,3599 0,3621 0,3643 0,3665 0,3686 0,3708 0,3729 0,3749 0,3770 0,3790 0,3810 0,3830 | 1,20 1,21 1,22 1,23 1,24 1,25 1,26 1,27 1,28 1,29 1,30 1,31 1,32 1,33 1,34 1,35 1,36 1,37 1,38 1,39 1,40 1,41 1,42 1,43 1,44 1,45 1,46 1,47 1,48 1,49 1,50 1,51 1,52 1,53 1,54 1,55 1,56 1,57 1,58 1,59 | 0,3849 0,3869 0,3883 0,3907 0,3925 0,3944 0,3962 0,3980 0,3997 0,4015 0,4032 0,4049 0,4066 0,4082 0,4099 0,4115 0,4131 0,4147 0,4162 0,4177 0,4192 0,4207 0,4222 0,4236 0,4251 0,4265 0,4279 0,4292 0,4306 0,4319 0,4332 0,4345 0,4357 0,4370 0,4382 0,4394 0,4406 0,4418 0,4429 0,4441 |
|
|
|
|
|
|
|
|
|
| 1,60 1,61 1,62 1,63 1,64 1,65 1,66 1,67 1,68 1,69 1,70 1,71 1,72 1,73 1,74 1,75 1,76 1,77 1,78 1,79 1,80 1,81 1,82 1,83 1,84 | 0,4452 0,4463 0,4474 0,4484 0,4495 0,4505 0,4515 0,4525 0,4535 0,4545 0,4554 0,4564 0,4573 0,4582 0,4591 0,4599 0,4608 0,4616 0,4625 0,4633 0,4641 0,4649 0,4656 0,4664 0,4671 | 1,85 1,86 1,87 1,88 1,89 1,90 1,91 1,92 1,93 1,94 1,95 1,96 1,97 1,98 1,99 2,00 2,02 2,04 2,06 2,08 2,10 2,12 2,14 2,16 2,19 | 0,4678 0,4686 0,4693 0,4699 0,4706 0,4713 0,4719 0,4726 0,4732 0,4738 0,4744 0,4750 0,4756 0,4761 0,4767 0,4772 0,4783 0,4793 0,4803 0,4812 0,4821 0,4830 0,4838 0,4846 0,4854 | 2,20 2,22 2,24 2,26 2,28 2,30 2,32 2,34 2,36 2,38 2,40 2,42 2,44 2,46 2,48 2,50 2,52 2,54 2,56 2,58 2,60 2,62 2,64 2,66 2,68 | 0,4861 0,4868 0,4875 0,4881 0,4887 0,4893 0,4898 0,4904 0,4909 0,4913 0,4918 0,4922 0,4927 0,4931 0,4934 0,4938 0,4941 0,4945 0,4948 0,4951 0,4953 0,4956 0,4959 0,4961 0,4963 | 2,70
2,72
2,74
2,76
2,78
2,80
2,82
2,84
2,86
2,88
2,90
2,92
2,94
2,96
2,98
3,00
3,20
3,40
3,60
3,80
4,00
4,50
5,00
| 0,4965 0,4967 0,4969 0,4971 0,4973 0,4974 0,4976 0,4977 0,4979 0,4980 0,4981 0,4982 0,4984 0,4985 0,4986 0,49865 0,49931 0,49966 0,499841 0,499928 0,499968 0,499997 0,49999997 0,5 |
Примечание. Функция Лапласа обладает свойством нечётности: 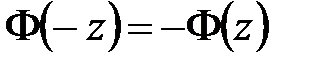 .
.
Приложение 4
Метод наименьших квадратов
Пусть в некоторой предметной области исследуются показатели X и Y , которые имеют количественное выражение. При этом есть все основания полагать, что показатель Y зависит от показателя X.
Предположим, что после проведения п наблюдений получены следующие числовые данные:
| X | 
| 
| … | 
|
| Y | 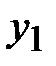
| 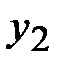
| … | 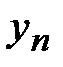
|
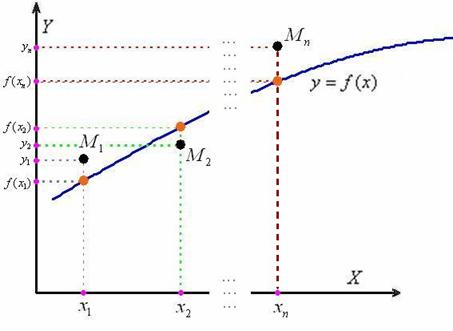
Эти табличные данные также можно представить в виде точек  ,
, 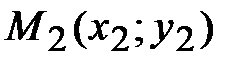 , …,
, …, 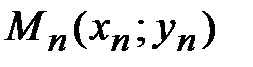 и изобразить в декартовой системе координат XО Y . Требуется подобрать функцию
и изобразить в декартовой системе координат XО Y . Требуется подобрать функцию  , график которой проходит как можно ближе к точкам .
, график которой проходит как можно ближе к точкам . 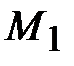 ,
,  , …,
, …, 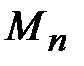 . Такую функцию называют аппроксимирующей (аппроксимация – приближение) или теоретической функцией. При этом разыскиваемая функция должна быть достаточно проста, т.е. легка в обработке, и в то же время должна отражать зависимость адекватно.
. Такую функцию называют аппроксимирующей (аппроксимация – приближение) или теоретической функцией. При этом разыскиваемая функция должна быть достаточно проста, т.е. легка в обработке, и в то же время должна отражать зависимость адекватно.
Один из методов нахождения таких функций называется методом наименьших квадратов. Его суть заключается в следующем. Пусть некоторая функция приближает экспериментальные данные , , …, :
Как оценить точность данного приближения? Вычислим значения функции 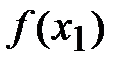 ,
,  , …,
, …, 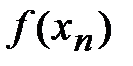 и разности (отклонения)
и разности (отклонения) 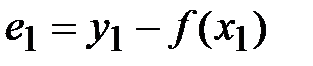 ,
, 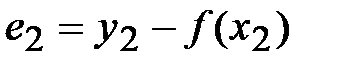 , …,
, …,  между экспериментальными и функциональными значениями и оценим сумму этих отклонений. При этом, во избежание обнуления сумы из-за наличия отрицательных отклонений, будем возводить их в квадрат:
между экспериментальными и функциональными значениями и оценим сумму этих отклонений. При этом, во избежание обнуления сумы из-за наличия отрицательных отклонений, будем возводить их в квадрат: 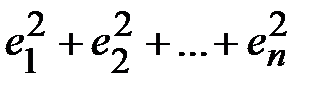 , после чего будем искать такую функцию , чтобы сумма квадратов отклонений
, после чего будем искать такую функцию , чтобы сумма квадратов отклонений 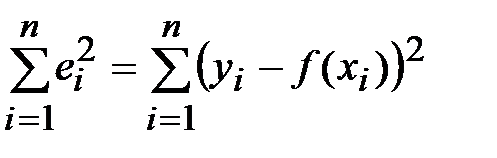 была как можно меньше.
была как можно меньше.
Как отмечалось выше, подбираемая функция должна быть достаточно проста. Но таких функций существует немало: линейная, гиперболическая, экспоненциальная, логарифмическая, квадратичная и т.д. Какой класс функций выбрать для исследования? Проще всего изобразить точки , , …, на чертеже и проанализировать их расположение. Если они имеют тенденцию располагаться по прямой, то следует искать уравнение прямой 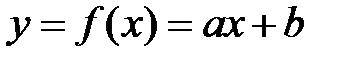 с оптимальными значениями a и b. Иными словами, задача состоит в нахождении таких коэффициентов a и b, чтобы сумма квадратов отклонений
с оптимальными значениями a и b. Иными словами, задача состоит в нахождении таких коэффициентов a и b, чтобы сумма квадратов отклонений
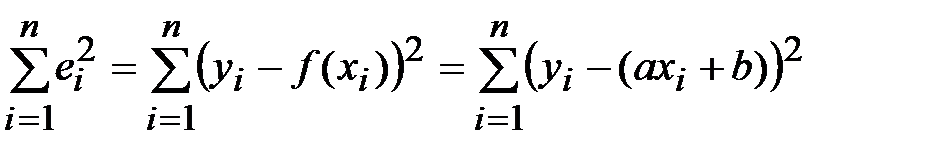
была наименьшей.
Если же точки расположены, например, по гиперболе, то заведомо понятно, что линейная функция будет давать плохое приближение. В этом случае ищем наиболее «выгодные» коэффициенты a и b для уравнения гиперболы 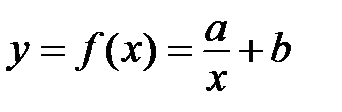 . То есть те, которые дают минимальную сумму квадратов
. То есть те, которые дают минимальную сумму квадратов
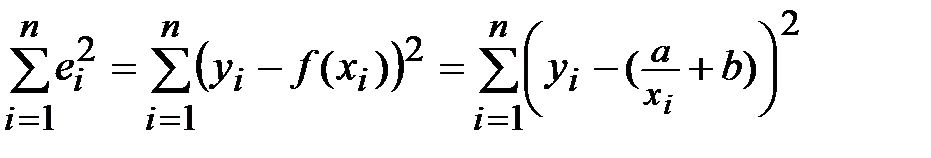 .
.
Обратите внимание, что в обоих случаях речь идёт о функции двух переменных, аргументами которой являются параметры разыскиваемых зависимостей:

И по существу нам требуется решить стандартную задачу – найти минимум функции двух переменных. Для этого сначала вычисляют частные производные 1-го порядка. Согласно правилу линейности дифференцировать можно прямо под значком суммы:


Составим стандартную систему:

Сокращаем каждое уравнение на «2» и разделяем суммы:

Перепишем систему в более удобном виде:

Теперь приступаем к решению задачи. Координаты точек , , …, нам известны. Суммы 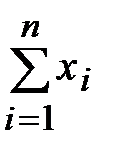 ,
, 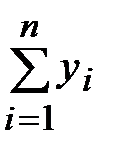 ,
, 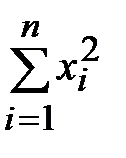 ,
,  находим из решения системы двух линейных уравнений с двумя неизвестными (a и b). Систему решаем, например, методом Крамера, в результате чего получаем стационарную точку
находим из решения системы двух линейных уравнений с двумя неизвестными (a и b). Систему решаем, например, методом Крамера, в результате чего получаем стационарную точку 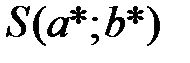 . Проверяя достаточное условие экстремума, можно убедиться, что в данной точке функция
. Проверяя достаточное условие экстремума, можно убедиться, что в данной точке функция 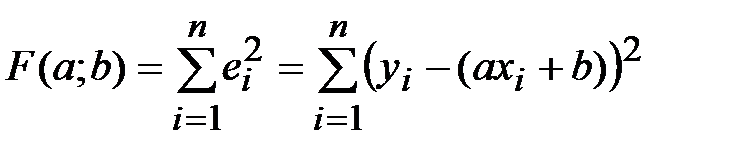 достигает именно минимума.
достигает именно минимума.
Делаем окончательный вывод: функция 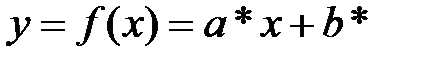 наилучшим образом приближает экспериментальные точки , , …, , а её график проходит максимально близко к этим точкам.
наилучшим образом приближает экспериментальные точки , , …, , а её график проходит максимально близко к этим точкам.
В традициях эконометрики полученную аппроксимирующую функцию также называют уравнением парной линейной регрессии.
Источник: http://www.mathprofi.ru/metod_naimenshih_kvadratov.html
Дата добавления: 2021-06-02; просмотров: 192; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!