Вопросы и задания для самопроверки
1. Объясните сущность многофункциональной модели? Назовите основные сферы, где целесообразны методы математического моделирования.
2. Объясните сущность макромодели и микромодели в системе социальной защиты населения.
3. Возможны ли — и какие — новые модели социальной защиты населения в ближайшие 10-15 лет XXI века?
Литература
Жуков В. И. Россия: состояние, перспективы, противоречия. — М., 1995.
Осипов Г. В., Локосов В. В. Социальная цена неолиберального реформирования. — М., 2001.
Реймерс Н. Ф. Экология человека: основные проблемы // Проблемы природоохранного просвещения. — Новосибирск, 1980.
Фирсов М. В. История социальной работы в России: Теория, история, общественная практика. — М., 1996.
Ядов В. А. Социологическое исследование: Методология, программа методы. - М., 1995.
Построение математических моделей
Социального прогнозирования
Прогноз развития социальной сферы на основе математических моделей независимо от используемого математического аппарата строится поэтапно.
Основные этапы построения прогноза:
1) определение цели прогнозирования;
2) определение структуры и степени детализации каждого блока модели;
3) сбор исходных данных;
4) определение глобальных показателей, используемых всеми блоками модели, внутренних показателей для каждого блока и показателей, стыкующих разные блоки (когда показатель на выходе одного блока является входным для другого);
|
|
|
4) построение математических описаний каждого блока;
5) синтез модели (взаимоувязка всех блоков);
6) определение возможных вариантов развития исследуемой социальной системы или социального процесса;
7) оценка достоверности (верификация) прогноза;
8) выработка рекомендаций по направлению развития исследуемого явления.
Выделение отдельных принципов прогнозирования не означает, что они существуют независимо друг от друга. Э^и принципы должны рассматриваться как единое целое. Их выборочное использование отражает разные стороны разработки прогнозов.
В соответствии с принципом системности прогнозирования социальная сфера рассматривается, с одной стороны, как единый объект, а с другой — как совокупность относительно самостоятельных блоков прогнозируемого множества объектов.
Принцип адекватности прогнозирования предполагает, что методы и модели разработки прогнозов рассчитаны в первую очередь на выявление и количественное измерение устойчивых закономерностей и взаимосвязей в развитии социальной сферы, на создание на этой основе теоретического аналога реальных процессов.
Принцип альтернативности прогнозирования связан с возможностью развития социальной сферы в целом и ее отдельных звеньев по различным траекториям, при разных взаимосвязях и структурных соотношениях. Если вероятностный характер прогнозирования отражает наличие случайных процессов и отклонений при сохранении качественной однородности, устойчивости прогнозируемых тенденций, то альтернативность исходит из предположения о возможности качественно различных вариантов развития социальной сферы. Одним из источников альтернатив развития могут быть разные предположения о конкретных целях развития. Тем самым принцип альтернативности взаимодействует с принципом целенаправленности прогнозирования.
|
|
|
В рассматриваемых далее прогнозах мы можем проследить использование математических моделей.
Прогноз состояния бюджетов
Семей, разделенных по группам и составам
Для исследования соотношения между потребительскими расходами и распределяемым доходом используются перекрестные данные о семейных бюджетах, относящиеся к некоторому фиксированному периоду времени. Прогноз строится с использованием обобщенного метода наименьших квадратов Гольдбергера[5]. Обозначим через Y величину потребительских расходов, а через X — объем распределяемого дохода. Соберем данные о бюджете 10000 семей и образуем пары соответствующих измерений для величин Хi Yi(i = 1, 2,..., 10000). Предположим, что мы уже разделили семьи на группы по их размеру и составу и рассматриваем интересующую нас связь между Y и Xвнутри конкретной группы. Мы не ожидаем, что у всех семей этой группы, имеющих один и тот же доход X ', будут одинаковые потребительские расходы Y '. Одни потратят больше других, а некоторые, наоборот, меньше, однако мы надеемся, что величины расходов сгруппируются вокруг некоторого значения, соответствующего тому объему дохода, о котором идет речь. Эта идея находит свое формальное воплощение в новой гипотезе о характере линейной зависимости:
|
|
|
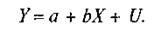 (1)
(1)
Здесь символом U обозначена переменная, принимающая то положительные, то отрицательные значения. Таким образом, если мы рассмотрим подгруппу семей, располагающих доходом X ', то центральным значением их потребительских расходов окажется величина а + b Х', в то время как реальные объемы потребления для семей данной подгруппы будут равны а + b Х' + U 1, а + b Х'+ U 2 и т.д., где U1, U2, ... измеряют отклонения потребительских расходов каждой отдельной семьи от центрального значения а + b Х'.
|
|
|
Существует три способа рационального объяснения включения в уравнение (1) стохастического члена, причем любое из этих объяснений не исключает других.
Во-первых, мы можем предположить, что потребительские расходы для всех и каждой из рассматриваемых семей были бы полностью объяснены, если бы мы знали все факторы, влияющие на эти расходы, и располагали необходимыми данными. Одинаковые по размеру и составу семьи могут отличаться возрастом родителей и детей, сложившейся динамикой дохода (возрастает он или убывает), бережливостью членов семьи и т.д. Многие из этих факторов не измеряются количественно, не квантуются и даже если такое измерение достижимо, то получение всех необходимых данных на практике оказывается невозможным.
Поскольку среди многочисленных факторов, влияющих на потребительский спрос конкретной семьи, многие действуют в противоположных направлениях, можно рассчитывать, что малые значения U , будут встречаться чаще, чем большие. Мы подошли, таким образом, к пониманию U как случайной переменной, обладающей вероятностным распределением с нулевым средним и с конечной дисперсией. Это позволяет нам обращаться с переменной U как со стохастическим возмущением (ошибкой). Ввиду того, что U включает много факторов, которые, по-видимому, можно считать независимыми, обращение к центральной предельной теореме показывает нам выбор для U нормального распределения.
Вторым оправданием присутствия в экономических соотношениях возмущающего члена служит то обстоятельство, что только с его помощью можно отразить вечный и непредсказуемый элемент случайности человеческих реакций, сплошь и рядом оказывающий воздействие на суммарный эффект существенных факторов и поэтому непосредственно влияющий на наблюдаемые значения переменной Y .
Третьим источником ошибок являются ошибки наблюдения или измерения.
Итак, пусть существует линейное соотношение между переменной Y , k-1,объясняющими переменными Х2, Х3 ..... Xk ивозмущением U. Если мы имеем выборку из п наблюдений над переменными Y и Xj, j = 2, 3, ..., k , то можно записать
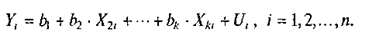
Коэффициенты bи параметры распределения Uнеизвестны. Уравнения, соответствующие всем п наблюдениям, могут быть записаны компактно в матричной форме
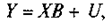 (2)
(2)
где
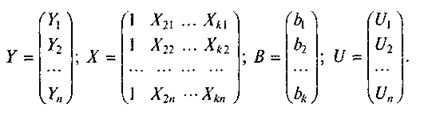
Соглашение, в силу которого через Xki обозначается i-е наблюдение переменной Xk , означает, что индексы в матрице X расположены в порядке, обратном общепринятому, когда первый индекс — номер строки, второй — номер столбца.
Примем простую гипотезу о нулевом значении математического ожидания стохастического возмущения U: E[U]= 0 и введем матрицу V:

где UT — вектор-строка, полученная транспонированием вектора-столбца U .
По диагонали матрицы V расположены дисперсии элементов вектора U , остальные элементы — ковариации элементов вектора U :
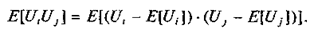
Задача прогноза состоит в предсказании изолированного значения зависимой переменной для заданного вектора-строки Х0. Мы можем записать:
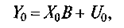
где U0 — истинное, но неизвестное значение возмущения в прогнозируемый момент. Пусть
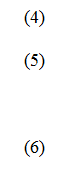
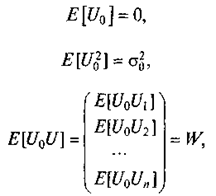
где W— вектор размерности (n´1) прогнозируемого возмущения вектором выборочных возмущений. Сформулируем линейный прогноз:
Р = CTY , (7)
где С — вектор размерности (n´1), состоящий из п констант.
Чтобы значение Р было наилучшим прогнозом, необходимо выбрать вектор С, минимизирующий дисперсию прогноза:
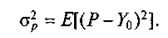
Для определения ошибки прогноза вычтем из уравнения (7) уравнение (3); подставим в результат значение Y из (2) и, выполнив соответствующие преобразования, получим:
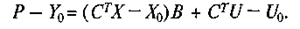
Из условия несмещенности прогноза следует, что вектор С должен удовлетворять равенству:
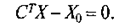 (9)
(9)
Тогда для ошибки прогноза имеем P – Y 0 = CTU - U 0 , и, поскольку (Р – Y 0 ) — скаляр, дисперсия прогноза равна
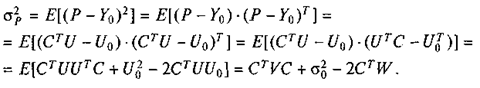 (10)
(10)
Чтобы минимизировать (10) при условии (9), образуем функцию
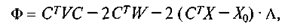
где L — вектор размерности (k´l), образованный множителями Лаг-ранжа. Затем продифференцируем Ф по векторам С и L и приравняем вектор частных производных к нулевому вектору.
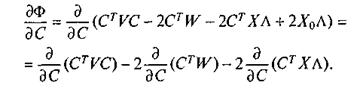
Рассмотрим
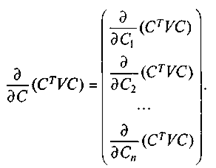
Учитывая, что V— симметричная матрица, то есть для I ¹ j:
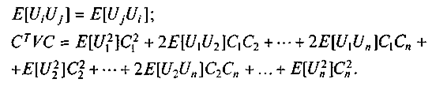
Возьмем частные производные по элементам вектора С:
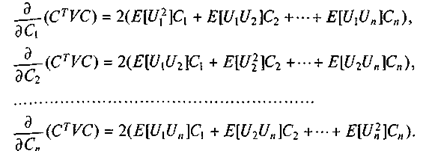
За исключением множителя 2, правые части этих уравнений содержат элементы матричного произведения VС, которые образуют n-мерный вектор-столбец. Следовательно,
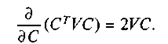
Аналогично получаем:
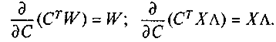
В результате дифференцирования имеем:
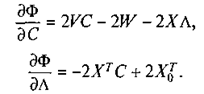 (11) (12)
(11) (12)
Примем вектор частных производных равным нулевому вектору и получим систему:
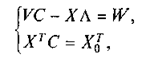
которая может быть записана в виде
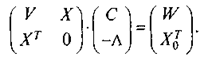 (13)
(13)
Из (13)получаем:
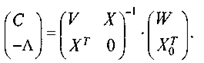
Применив правило отыскания матрицы, обратной к матрице, подвергшейся разбиению, имеем:
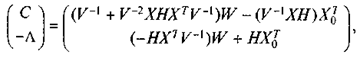 (14)
(14)
где Н = (-ХТ V -1 Х)-1
Из (14)получаем:
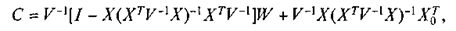 (15)
(15)
где I - единичная матрица.
Следовательно, наилучшим нелинейным несмещенным прогнозом будет:
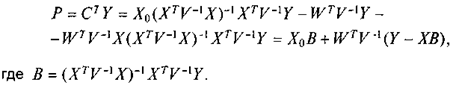
Учитывая, что e =( Y - XB ) — вектор остатков, соответствующий методу наименьших квадратов,
Р = Х0В+ WTV -1 e . (16)
Это и есть основной результат, полученный Гольдбергером для предсказания с помощью обобщенной модели наименьших квадратов.
Задача. Исследовать уровень ежемесячного среднедушевого потребления товаров первой необходимости и сделать прогноз этого уровня на будущее для семей со средним уровнем достатка.
Имеются данные среднемесячных затрат на питание по основным группам продуктов (распределяемый доход) и общих затрат на товары первой необходимости в выбранной группе семей в сопоставимых денежных единицах за 5 лет. Общая сумма затрат на товары первой необходимости включает, кроме затрат на указанные группы продуктов, затраты на фрукты, кондитерские изделия, а также непродовольственные товары повседневного спроса (мыло, газеты и т.п.).
Оценить необходимые затраты на эти товары при сохранении установившегося рациона питания, если цены на преобладающие продукты питания (колонки 2, 3, 4, 5) увеличатся в 1,5 раза по сравнению с последним годом.
| Период времени (годы) | Затраты на мясные продукты (в мес.) | Затраты на молочные продукты (в мес.) | Затраты на оно щи (в мес.) | Затраты на мучные и крупяные изделия (в мес.) | Общие затраты на товары первой необходимости (в мес.) |
| 1 2 3 4 5 | 9 9,5 10 12 15 | 3 3,7 4,5 5 6 | 6 6,5 9 10 11 | 2 3 5,5 6 8 | 40 50 54 70 85 |
Решение. В качестве математической модели зависимости общих затрат на товары первой необходимости от цен на основные продукты питания возьмем линейное соотношение (2). На основе данных задачи сформируем матрицы X , Y , Х0:
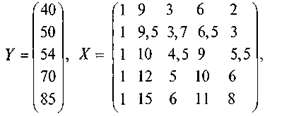 (17)
(17)
Х0 =(1 22,5 9 16,5 12).
Вычислим определитель квадратной матрицы X
detX = |X|= 2,9.
Так как detX ¹ 0, матрица X является невырожденной и, следовательно, для нее существует единственная обратная матрица Х-1и уравнение (15) может быть упрощено раскрытием скобок:
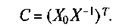
А это означает, что прогнозируемое значение среднемесячных затрат на основные продукты питания в следующем году может быть вычислено по формуле:
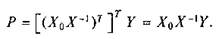 (18)
(18)
Для вычисления матрицы, обратной к X , воспользуемся известной теоремой. Совместное преобразование матриц Х и Е (единичной) будем осуществлять таким образом, чтобы врезультате каждого шага один из векторов матрицы X становился единичным.
Для преобразования k -говектора матрицы Х кединичному пересчет элементов матрицы X осуществляется по следующим формулам:
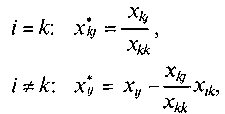
где i— номер строки;. J — номер столбца; верхним индексом * отмечены пересчитанные изданном шаге значения.
Элементы xkk каждого последующего шага выделены жирным шрифтом.
| 1 | 9 | 3 | 6 | 2 | 1 | 0 | 0 | 0 | 0 |
| 1 | 9,5 | 3,7 | 6,5 | 3 | 0 | 1 | 0 | 0 | 0 |
| 1 | 10 | 4,5 | 9 | 5,5 | 0 | 0 | 1 | 0 | 0 |
| 1 | 12 | 5 | 10 | 6 | 0 | 0 | 0 | 1 | 0 |
| 1 | 15 | 6 | 11 | 8 | 0 | 0 | 0 | 0 | 1 |
| 1 | 9 | 3 | 6 | 2 | 1 | 0 | 0 | 0 | 0 |
| 0 | 0,5 | 0,7 | 0,5 | 1 | -1 | 1 | 0 | 0 | 0 |
| 0 | 1 | 1,5 | 3 | 3,5 | -1 | 0 | 1 | 0 | 0 |
| 0 | 3 | 2 | 4 | 4 | - 1 | 0 | 0 | 1 | 0 |
| 0 | 6 | 3 | 5 | 6 | - 1 | 0 | 0 | 0 | 1 |
| 1 | 0 | -9,6 | -3 | -16 | 19 | -18 | 0 | 0 | 0 |
| 0 | 1 | 1,4 | 1 | 2 | -2 | 2 | 0 | 0 | 0 |
| 1 | 0 | 0,1 | 2 | 1,5 | 1 | -2 | 1 | 0 | 0 |
| 0 | 0 | -2,2 | 1 | -2 | 5 | -6 | 0 | 1 | 0 |
| 0 | 0 | -5,4 | -1 | -6 | 11 | -12 | 0 | 0 | 1 |
| 1 | 0 | -16,2 | 0 | -22 | 34 | -36 | 0 | 3 | 0 |
| 0 | 1 | 3,6 | 0 | 4 | -7 | 8 | 0 | -1 | 0 |
| 0 | 0 | 4,5 | 0 | 5,5 | -9 | 10 | 1 | -2 | 0 |
| 0 | 0 | -2,2 | 1 | -2 | 5 | -6 | 0 | 1 | 0 |
| 0 | 0 | -7,6 | 0 | -8 | 16 | -18 | 0 | 1 | 1 |
| 1 | 0 | 4,7 | 0 | 0 | -10 | 13,5 | 0 | 0,25 | -2,75 |
| 0 | 1 | -0,2 | 0 | 0 | 1 | -1 | 0 | -0,5 | 0,5 |
| 0 | 0 | - 0,725 | 0 | 0 | 2 | -2,375 | 1 | -1,3125 | 0,6875 |
| 0 | 0 | -0,3 | 1 | 0 | 1 | -1,5 | 0 | 0,75 | -0,25 |
| 0 | 0 | 0,95 | 0 | 1 | -2 | 2,25 | 0 | -0,125 | -0,125 |
Во избежание накопления ошибок округления последний шаг выполним в простых дробях. Тогда левая матрица станет единичной, правая после вынесения за знак матрицы общего для всех элементов множителя элемента примет вид:
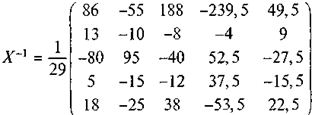 (19)
(19)
В соответствии со значениями переменных (17) и (19),
Р = X 0 X-1Y = 157,0775862 = 157.
Ответ: Прогнозируемые затраты на продукты первой необходимости составят 157 денежных единиц.
Дата добавления: 2021-04-05; просмотров: 97; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!