Масштабируемые параллельные системы
Общая характеристика и типы. Масштабируемые параллельные системы, как уже говорилось, можно подразделить на мультикомпьютеры, кластеры, симметричные мультипроцессоры, архитектуры с распределенной памятью и массово-параллельные системы (табл. 1.1).
Табл. 1.1
Основные характеристики масштабируемых вычислительных систем
| Тип системы | ||||
| Характеристика | Мульти-компьютер | Кластер | SMP, DSM | MPP |
| Порядок числа N узлов | 10 – 1000 | до 100 | 10 – 100 | 100 – 1000 |
| Сложность узла | В широком диапазоне: от компьютера и выше | Компьютер, рабочая станция | Один или несколько процессоров | От процессорного элемента (ядра) до компьютера |
| Взаимодействие узлов | Разделяемые файлы, удален-ный вызов про-цедуры, обмен сообщениями, на уровне процессов | Обмен со-общениями | Общая разде-ляемая (SMP) или распределенная (DSM) память | Обмен сообще-ниями / разделяе-мые переменные распределенной памяти |
| Планирование вычислитель-ных работ | Независимые очереди процессов | Множество скоордини-рованных очередей | Одна очередь | Одна очередь на хост-узле |
| Поддержка образа единой системы | Частично | Да | Да (SMP) или иногда (NUMA) | Частично |
| Тип и наличие копий ОС | N копий распределенной ОС | N копий / N разных ОС или микроядер | 1 монолитная (SMP), от 1 до N в DSM | N микроядер монолитной ОС или N копий рас-пределенной ОС |
| Адресное пространство | Множественное | Множест-венное или единое | Единое | Множественное или единое (DSM) |
Ориентация на использование в вычислительных системах серийных микропроцессоров и памяти позволяет снизить стоимость, приходящуюся на единицу производительности. Именно соотношение стоимости и производительности стало одной из основных причин вытеснения векторно-конвейерных суперкомпьютеров массово-параллельными системами. Доминирование MPP-архитектур среди вычислительных систем высокой производительности началось в 90-х годах XX века. Тем не менее это вовсе не означает окончания эры векторных компьютеров. Серьезные достижения в этом направлении имеют японские корпорации NEC, Hitachi, а также американская компания SGI (проект Cray SV1). Однако в настоящем курсе мы ограничиваемся системами, в которых использование коммерчески доступных кристаллов процессоров и памяти является одним из необходимых условий масштабируемости.
Мультикомпьютеры. Мультикомпьютер – совокупность объединенных сетью отдельных вычислительных модулей, каждый из которых управляется своей операционной системой (ОС). Пример – серия SP фирмы IBM.
Узлы мультикомпьютера, как правило, не имеют общих структур, кроме сети, обладают высокой степенью автономности и могут состоять из отдельных компьютеров или представлять собой различные комбинации кластеров, SMP-, DSM- и MPP-систем. Для распределенной ОС мультикомпьютер выглядит как виртуальный однопроцессорный ресурс, хотя понятие образа единой системы, поддерживаемого в кластерах программным обеспечением промежуточного уровня, в полной мере к мультикомпьютерам не применимо. Взаимодействие процессов реализуется с помощью явно заданных операций связи между отдельными вычислителями, например, с помощью библиотеки MPI. Обычно в мультикомпьютере реализуется согласованный сетевой протокол и нет единой очереди выполняющихся процессов. Хотя известны и другие примеры. Например, система пакетной обработки заданий LL (Load Leveler) может применяться в суперкомпьютерах IBM SP (см. п. 1.3). В отличие от традиционных вычислительных сетей, как локальных (LAN – local area networks), так и глобальных (WAN – wide area networks), мультикомпьютер может рассматриваться пользователем как общий ресурс, выполняющий отдельные части его параллельной программы.
Кластеры. Кластер – набор компьютеров, рассматриваемый ОС, системным программным обеспечением, программными приложениями и пользователями как единая система. Кластеры получили широкое распространение, благодаря высокому уровню готовности при относительно низких затратах. Высокая готовность объясняется отсутствием совместно используемой оперативной памяти и наличием в каждом узле копии ОС или своей ОС в неоднородных кластерах. Специальное программное обеспечение производит контроль работоспособности узлов. Если какой-либо из узлов кластера считается вышедшим из строя, его ресурсы, например, дисковое пространство, и программы переназначаются на другие узлы. По существу, кластер образуется из отдельных "полноценных" узлов, включающих процессоры, память, подсистему ввода/вывода, ОС и т.д. При объединении компьютеров в кластер чаще всего поддерживаются прямые межузловые коммуникации, осуществляемые посредством передачи сообщений. Коммуникационные системы могут быть как довольно простыми (например, на основе сети Ethernet), так и довольно сложными, реализуемыми такими высокоскоростными сетями, как SСI, Memory Channel, ServerNet, Myrinet. Возможно использование нескольких независимых сетей. Так, в отечественном суперкомпьютере MBC-1000M (Межведомственный суперкомпьютерный центр) сеть Myrinet используется для обмена данными в пользовательских программах, а Fast Ethernet – для выполнения сервисных функций ОС. Две типичных организации кластеров – это архитектура с разделяемыми дисками (рис. 1.1, а) и архитектура без разделения ресурсов (рис. 1. 1, б). В первой из них все узлы разделяют доступ к общим дискам, на которых может располагаться единая база данных. Во второй архитектуре, несмотря на то, что поддерживается целостный образ ресурса, каждый узел имеет собственные оперативную память и диски. В таких системах общей является лишь коммуникационная система.
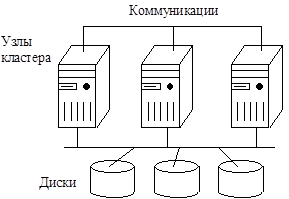

а) б)
Рис. 1.1. Кластеры с разделяемыми дисками (а) и без разделения ресурсов (б)
С точки зрения увеличения производительности, кластер – хорошо масштабируемая система. Однако отсутствие общей разделяемой памяти, а иногда и единого адресного пространства обуславливают большие накладные расходы, связанные с обменом сообщениями между узлами. Так, при использовании в кластерах коммуникационного протокола TCP/IP временные затраты на обмен несоизмеримо больше затрат на передачу данных в SMP- и DSM-системах. Существуют специальные протоколы для внутрикластерных коммуникаций, значительно снижающие время обмена, например, Virtual Interface Architecture (разработка группы компаний во главе с Intel). Наиболее эффективной областью применения кластеров являются хорошо структурируемые, как правило, научные приложения. С позиций удобства масштабирования кластерные архитектуры допускают практически неограниченное наращивание числа узлов. Однако для управления кластером необходимы специальные инструменты администрирования, поддерживающие образ единого ресурса, в частности, система пакетной обработки заданий.
Симметричные мультипроцессоры. SMP-системы состоят из нескольких десятков процессоров, разделяющих общую основную (оперативную) память и объединенных коммуникационной системой (рис. 1.2). Существуют варианты SMP-архитектур с одной и несколькими системными шинами, например, четырьмя в Cray SuperServer 6400, а также со специальным коммутатором для связи процессоров, памяти и подсистемы ввода/ вывода (Sun Ultra Enterprise 6000).
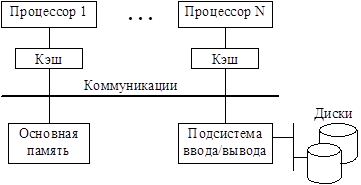
Рис. 1.2. Структура SMP-системы
Каждый процессор имеет доступ ко всей основной памяти, может прерывать другие процессоры и выполнять операции ввода/вывода. Пропускная способность коммуникационной системы достаточна для поддержания быстрого доступа к памяти. У отдельных процессоров имеется один или несколько уровней собственной кэш-памяти. Достаточный объем кэша и сравнительно небольшое количество процессоров в SMP-системах позволяют удовлетворить обращения к основной памяти, поступающие от нескольких процессоров так, что время доступа к общей памяти примерно одинаково для всех процессоров. Это объясняет еще одно название таких архитектур – UMA (Uniform Memory Access), т.е. однородный доступ к памяти. В них имеется одна ОС, а программное обеспечение работает с единым адресным пространством общей памяти, несмотря на реально существующую иерархию "кэш – основная память". При этом возникает сложная проблема сохранения когерентности данных, т.е. согласованных изменений содержимого кэшей и общей памяти, когда предотвращается использование копий данных в кэше какого-либо процессора, если они подверглись модификации в другом процессоре. Следовательно, если модифицируется одна из копий данных, остальные копии должны либо так же модифицироваться, либо объявляться недостоверными. По сути, это определяет два альтернативных подхода к поддержанию когерентности разделяемых данных: запись с обновлением и запись с аннулированием копий данных. В SMP-системах, как правило, реализуется шинный протокол наблюдения (snoopy), когда происходит "прослушивание" шины всеми процессорами с целью обнаружения операций записи в те ячейки памяти, копии содержимого которых размещены в кэшах. Производительность систем с общей памятью, в том числе и SMP, зависит от принятой модели согласованности (consistency) памяти, определяющей, в каком порядке процессоры наблюдают последовательность операций записи и чтения (см. п. 1.2). Разумеется, передача данных между кэшами разных процессоров в SMP-системах выполняется значительно быстрее, чем обмен данными между узлами кластера или мультикомпьютера. Поэтому SMP-архитектуры лучше масштабируются с целью увеличения производительности при обработке большого числа коротких транзакций, свойственных банковским приложениям. Что же касается удобства масштабирования и уровня готовности, SMP-системы уступают кластерам. Ограничения в наращивании числа процессоров обусловлены, прежде всего, наличием общей основной, нераспределенной по процессорам памяти и поддержанием моделей строгой, последовательной или процессорной согласованности. Сохранение когерентности требует специальных аппаратных средств быстрой модификации копий данных. Однако, если при этом следовать модели строгой согласованности, когда каждая операция чтения возвращает последнее записанное значение, снижение производительности системы неизбежно. Причина заключается в том, что необходимо введение "единого времени" и упорядочение действий всех процессоров. Невысокая степень готовности SMP-систем объясняется сильной связанностью процессоров и наличием одной ОС, разделяемой всеми процессорами. Потеря работоспособности каким-либо из них может привести к деградации системы, если модифицированная вышедшим из строя процессором копия данных не передается другим процессорам и в основную память.
Системы с распределенной разделяемой памятью. DSM-системы могут быть реализованы различными способами. Общим является наличие, помимо кэша, локальной памяти в каждом процессорном узле. Узел может состоять из нескольких процессоров и иметь архитектуру SMP. Поддерживается общее адресное пространство памяти. Однако при этом память является распределенной по узлам и время доступа зависит от места расположения данных. Поэтому некоторые DSM-системы получили название NUMA (Non-Uniform Memory Access), что означает неоднородный доступ к памяти.
Один из способов реализации NUMA-архитектур – отказ от аппаратных средств поддержки когерентности кэшей. Наиболее известные примеры таких систем – это суперкомпьютеры Cray T3D и Т3Е. Процессорные узлы в таких системах объединяются сетью, в узлах которой размещаются специальные контроллеры, анализирующие адрес обращения к памяти. Если данные размещаются в памяти удаленного узла, то его контроллеру посылается сообщение для обращения к этим данным. Разделяемые данные не заносятся в кэши, что снимает проблему когерентности. Однако по сравнению с SMP-системами программирование таких NUMA-архитектур усложняется. Механизмы программной поддержки когерентности данных компилятором ограничены и существующие методы применимы к программам с хорошо структурированным параллелизмом на уровне циклов.
Альтернативный способ – обеспечение согласованности данных в кэш-памяти всех процессорных узлов. В архитектуре сcNUMA (cache coherent NUMA) механизм работы кэша каждого узла увязан с доступом к локальной памяти удаленного узла. Одна из первых реализаций этого принципа – система NUMA-Q компании Sequent. Другой пример – компьютер HP Superdome. Состояния кэшей отслеживаются с помощью протокола на основе справочника (directory). Этот протокол может рассматриваться как альтернатива протоколу наблюдения. Общая структура сcNUMA-системы показана на рис. 1.3.

Рис. 1.3. Структура сcNUMA-системы
Справочник распределен по узлам ccNUMA-системы и хранит состояние каждого блока данных, который может заноситься в кэш. В справочнике содержится информация о том, в каких кэшах имеются копии этого блока данных, а также сведения о модификации данных. Пусть Узел 1 (см. рис. 1.3) обращается к ячейке с адресом А в основной памяти, не являющейся локальной памятью Узла 1. Справочник Узла 1 анализирует адрес А и распознает, что он относится к локальной памяти Узла N. После этого он посылает сообщение с запросом А в справочник Узла N, который выбирает значение ячейки А из своей локальной памяти и передает его справочнику Узла 1. В отличие от шинного протокола наблюдения, при записи нового значения в кэш узла сообщение о модификации передается не всем узлам, а лишь тем, в которых имеются копии соответствующих данных. Достоинством протокола на основе единого справочника является его простота. Однако размеры справочника пропорциональны емкости не кэш-памяти, а основной памяти системы.
Иерархичность доступа к памяти в NUMA-архитектурах сдерживает увеличение числа процессорных узлов. Как правило, в современных NUMA-системах их число не больше 64, а число процессоров – 128. Для сглаживания неоднородности по времени доступа к памяти некоторые поставщики ccNUMA-систем определенным образом модифицируют ОС: при запросе программой данных ОС выделяет соответствующую область локальной памяти именно в том узле, в котором эта программа выполняется. И все же из-за дополнительных накладных расходов на пересылку данных из удаленных узлов вряд ли NUMA-архитектуры могут заменить симметричные мультипроцессоры на задачах, требующих интенсивного трафика обмена данными и частой синхронизации работы процессоров. Из-за проблем с масштабируемостью и SMP-, и NUMA-системы больше ориентированы на емкий рынок коммерческих приложений, например, в качестве UNIX-серверов, нежели на роль наиболее производительных систем в классе суперкомпьютеров. Невысокая степень готовности ссNUMA-архитектур объясняется теми же причинами, что и для симметричных мультипроцессоров: наличием единой ОС и необходимостью поддержки когерентности кэш-памяти.
Как развитие архитектуры ссNUMA, преодолевающее ограничение на масштабируемость, можно рассматривать архитектуру S2MP (Scalable Shared Memory MultiProcessing), реализованную в компьютерах Onyx2 и Origin 2000 фирмы SGI (рис. 1.4).
Одним из узких мест, сдерживающих увеличение числа процессорных узлов, является пропускная способность шин оперативной памяти. В частности, по этому показателю векторно-конвейерные суперкомпьютеры, например, Cray C90, сильно опережают системы на базе RISC-микропроцессоров. В архитектуре S2MP процессорные узлы (рис. 1.5) объединены сетью, образуемой средой межсоединений (CrayLink Interconnect) и маршрутизаторами, что сближает S2MP c архитектурой ServerNet.
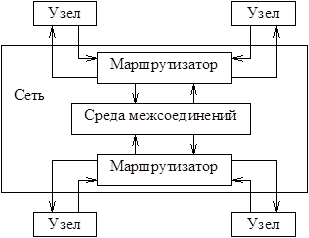
Рис. 1.4. Структура S2MP
Структура сети позволяет многим процессорным узлам одновременно связываться друг с другом. Важная часть каждого узла (см. рис. 1.5) – концентратор. По сути, он представляет собой коммутатор (crossbar switch) с четырьмя двунаправленными портами, которые связывают его с процессорами, оперативной памятью, подсистемой ввода/вывода и маршрутизаторами.

Рис. 1.5. Структура процессорного узла архитектуры S2MP
Для поддержания когерентности кэшей используется протокол справочника. Применение программируемых маршрутизаторов позволяет реализовать системы с различной топологией. В частности, в компьютерах Origin 2000 стандартной является топология гиперкуба, а число процессорных узлов достигает 512.
Архитектура NUMAflex, положенная в основу систем Origin 3x00, во многом наследует черты S2MP. Более высокая степень готовности обеспечивается технологией так называемого разделения, которая роднит NUMAflex с кластерами. Каждый раздел, представляющий собой независимый сервер, для связи с другими узлами использует инфраструктуру межсоединений (см. рис. 1.4). В каждом разделе может работать своя версия ОС Irix. Специальные аппаратные средства позволяют изолировать ошибку, возникающую в одном из разделов, не давая ей распространиться далее.
Существуют также и другие разновидности систем с распределенной разделяемой памятью: COMA (Cache Only Memory Architecture) и системы с рефлексивной памятью (RM – reflective memory).
В СОМА-архитектурах (рис. 1.6) локальная память узла строится по принципу кэш-памяти и называется притягивающей. Поступающий в узел блок данных размещается в кэше процессора и притягивающей памяти. Каждый блок данных снабжается тегом, определяющим адрес блока и его состояние. Если требуемого блока данных не содержится в кэше, то контроллер памяти узла просматривает теги притягивающей памяти с целью извлечения необходимых данных из локальной памяти узла. При их отсутствии делается запрос к другим процессорным узлам системы.
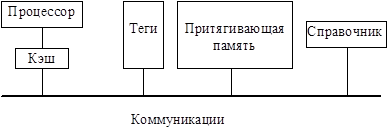
Рис. 1.6. Структура процессорного узла СОМА-архитектуры
Примеры систем с архитектурой COMA – KSR, SUN S3.mp, DDM. Способы реализации СОМА-архитектуры различаются организацией межузловых связей. В многоуровневых СОМА-системах имеет место древовидная структура шин. Каждый уровень дерева содержит справочник со сведениями о блоках данных, размещаемых в нижележащих уровнях. Поэтому при поиске данных необходимо просматривать справочники вышележащих уровней иерархии до тех пор, пока не будет обнаружен требуемый блок данных. В одноуровневых (плоских) СОМА-системах справочник каждого узла содержит сведения о местоположении резидентных данных этого узла. В таких системах, в отличие от иерархических СОМА-архитектур, для организации межузловых взаимодействий не требуется сетей со специальной организацией. Если необходимый блок данных не содержится в притягивающей памяти узла, то определяется резидентный узел, в справочнике которого имеется информация о местоположении требуемых данных. В резидентный узел направляется запрос на передачу данных. В случае их отсутствия в притягивающей памяти резидентного узла запрос направляется к местоположению данных в соответствии со справочником. Притягивающая память функционирует подобно кэшу. Однако данные, удаляемые из нее, должны быть размещены в притягивающей памяти другого процессорного узла. Если существует несколько копий блока данных, то одна из них объявляется основной. В отличие от других копий, основная обязательно перемещается в притягивающую память другого узла, если нет места для вновь поступающих в узел данных. Таким образом, для СОМА-архитектуры характерно перемещение данных между отдельными узлами, что создает дополнительную нагрузку на коммуникационную сеть.
Главной особенностью RM-архитектур является то, что каждая копия разделяемых данных во всех процессорных узлах имеет одно и то же значение. Общая структура узла RM-системы показана на рис. 1.7.

Рис. 1.7. Структура процессорного узла RM-архитектуры
Страницы памяти узла делятся на локальные неразделяемые и глобальные разделяемые. Рефлексивная память содержит глобально разделяемые страницы, отображаемые в единое адресное пространство. В отличие от NUMA- и СОМА-архитектур, в RM-архитектуре для пользователя имеется возможность управлять степенью разделения данных путем заполнения таблиц трансляции адресов, отображающих область локальной памяти узла в единое адресное пространство. Таким образом, фиксированная адресация всей памяти отсутствует, вместо нее применяется отображение в единое адресное пространство выделенных страниц. Взаимные преобразования локальных адресов узла и глобальных адресов осуществляются с помощью адаптера коммуникационной системы (см. рис. 1.7). Необходимость модификации множественных копий разделяемых страниц может создавать большую нагрузку на коммуникации. Примеры кластерных реализаций RM-архитектуры – AlphaServer8xxx, HP SPP1600, DEC TruCluster.
В рассмотренных системах с общей памятью применяются различные механизмы поддержки когерентности. Так, в SMP-архитектурах возможны как модификация разделяемых данных, так и объявление их недостоверными. В архитектурах NUMA и СОМА реализуется объявление разделяемых данных недостоверными, в RM-архитектуре – модификация разделяемых страниц.
Массово-параллельные системы. Прежде всего они характеризуются большим числом процессорных узлов (см. табл. 1.1). Узлы обычно состоят из одного или нескольких процессоров, локальной памяти и нескольких устройств ввода/вывода. Чаще всего в MPP-системах реализуется архитектура без разделения ресурсов. В каждом узле работает своя копия ОС, а узлы объединяются специализированной коммуникационной средой. Если узел управляется своей собственной ОС и имеет уникальное адресное пространство памяти, то не требуется аппаратного обеспечения когерентности. Когерентность в этом случае обеспечивается программными средствами на основе техники обмена сообщениями. Такие MPP-системы можно отнести к мультикомпьютерам (например, IBM SP1 и SP2). В MPP-системах c распределенной разделяемой памятью возможна как программная, так и аппаратная поддержка когерентности кэш-памяти. Как уже отмечалось, эти разновидности массово-параллельных систем можно определить соответственно как NUMA (например, Cray T3D/3E) и ccNUMA (в частности, Origin 2000/3x000, а также системы HP Exemplar). Вообще же нужно признать, что классификацию MPP-архитектур и используемую при этом терминологию вряд ли можно считать устоявшимися в настоящее время.
Cистемы с быстрой памятью. Cистемы с быстрой памятью (High Bandwidth Memory, HBM) имеют существенно большую пропускную способность по сравнению с DDR памятью, устанавливаемой вместе с большинством современных центральных процессоров. (DDR - Double Data Rate означает двойную скорость передачи данных, и в основном за счет этого вы можете выполнять две задачи записи и две операции чтения для каждого тактового цикла.) На сегодняшний день память стандарта HBM устанавливается преимущественно в векторные архитектуры (например, NEC SX–Aurora TSUBASA) либо в многоядерные центральные процессоры с векторными расширениями (например, Fujitsu A64FX), поскольку векторная обработка данных позволяет эффективно задействовать широкую шину памяти за счет обращений к подсистеме памяти от векторных устройств. Другим важным классом архитектур, использующих память стандарта HBM, являются графические ускорители NVIDIA (CUDA – Compute Unified Device Architecture), которые, однако, так же используют векторную обработку данных: GPU–нити группируются в так называемые варпы, в каждый момент времени выполняющие одну и ту же инструкцию над различными данными, что является основным принципом векторных вычислений.
Модель выполнения программы на GPU схожа для всех современных поколений графических процессоров. При запуске вычислений на GPU создается большое количество нитей, причём обычно рекомендуется создавать десятки и сотни тысяч нитей для более эффективной работы с подсистемой памяти. Например, в процессоре NVIDIA Pascal нити объединяются в вычислительные блоки (обычно до 1024 нитей), после чего различные блоки размещаются планировщиком Giga Thread Engine на различных потоковых мультипроцессорах, которые выполняют потоки команд каждой из нитей блока. При этом нити одного блока группируются в варпы по 32 нити круговом порядке, при чём каждый варп в любой момент времени выполняет одну и ту же инструкцию над различными данными. Именно данное свойство и обуславливает наличие принципов векторной обработки данных в архитектуре NVIDIA GPU – нити одного и того же варпа производят вычисления с использованием SIMD инструкций длины 32.
CUDA-ядра в архитектуре Pascal сгруппированы в потоковые мультипроцессоры (Streaming Multiprocessor – SM), каждый из которых состоит из 64 ядер CUDA. CUDA-ядра потоковых мультипроцессоров имеют различные типы, необходимые для выполнения операций с одинарной или двойной точностью, работы с памятью или же специальных математических вычислений. Потоковые мультипроцессоры GPU так же оборудованы планировщиками варпов (warp schedulers), необходимыми для организации работы CUDA-ядер согласно SIMD модели, а также регистрами и быстрой памятью.
В то же время нити различных варпов могут выполнять различные инструкции над различными данными, работая в соответствии с принципами модели MIMD (Multiple Instruction Multiple Data). Данное сочетание принципов SIMD (внутри одного варпа) и MIMD (для различных варпов) моделей выполнения получило название SIMT (Single Instruction Multiple Thread) модели.
Выводы. Итак, общей особенностью рассмотренных масштабируемых систем является распределенность процессов обработки и распределенность данных. С одной стороны, в распределении вычислений и данных заложена возможность повышения производительности таких систем. С другой, интенсивный обмен данными, часто и не вызванный информационными зависимостями между процессами обработки, как в СОМА-архитектуре, сильно загружает коммуникационную среду. Естественно, это ограничивает возможности масштабирования систем. Следовательно, эффективность выполнения программ в масштабируемых архитектурах в значительной мере зависит от организации взаимодействия распределенных процессов.
Дата добавления: 2021-03-18; просмотров: 172; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!