Сортировка посредством выбора
Лекция 7: Методы сортировки массивов
см. http://www.vzmakh.ru/info/pascal/modules/page14.html#swp
От порядка расположения данных в памяти ЭВМ, во многом зависит скорость и простота выполнения алгоритмов, предназначенных для обработки этих данных. Поэтому в программировании часто возникает задача перегруппировки данных в невозрастающем или неубывающем, порядке. Такая задача называется упорядочением или сортировкой элементов данной структуры.
Под сортировкой понимают, процесс перестановки объектов множества в определенном порядке, (обычно в алфавитном или числовом).
Сортировкой или упорядочением массива называется расположение его элементов по возрастанию (или убыванию). Если не все элементы различны, то надо говорить о неубывающем (или невозрастающем) порядке.
При сортировке массивов будем предполагать, что перестановки, переводящие элементы массива в нужный порядок, должны выполняться на том же месте, т.е. без использования промежуточного массива. Методы, в которых элементы из массива A передаются в результирующий массив В, представляют значительно меньший интерес.
Все методы сортировки можно разделить на две большие группы:
- прямые методы сортировки;
- быстрые или улучшенные методы сортировки.
Прямые методы сортировки по принципу, лежащему в основе метода, в свою очередь разделяются на три подгруппы:
- сортировка вставкой (включением);
- сортировка выбором (выделением);
- сортировка обменом (так называемая "пузырьковая" сортировка).
Улучшенные методы сортировки основываются на тех же принципах, что и прямые, но используют некоторые оригинальные идеи для ускорения процесса.
|
|
|
Вообще говоря, это большая и сложная тема, в которой известно много различных алгоритмов. Критерии оценки эффективности этих алгоритмов могут включать следующие параметры:
- количество шагов алгоритма, необходимых для упорядочения;
- количество сравнений элементов;
- количество перестановок, выполняемых при сортировке.
Для прямых методов сортировки требуется порядка n^2 сравнений ключей, они более просты и удобны для объяснения характерных черт основных принципов большинства сортировок. Программы этих методов легко понимать и они короче программ быстрых алгоритмов.
Улучшенные методы сортировки требуют небольшого числа операций, но эти операции обычно сами более сложны, и поэтому для достаточно малых n прямые методы оказываются быстрее, хотя при больших значениях n их использовать не следует.
Мы рассмотрим только три простейшие схемы сортировки.
Но прежде чем перейти к рассмотрению конкретного алгоритма той или иной сортировки немного вспомним материал, который пригодится нам в дальнейшем.
|
|
|
Задача. Даны две целочисленные переменные х и y. Составить фрагмент программы, после выполнения которого значения этих переменных распределяются в порядке убывания.
Обмен значений переменных нужно производить лишь в том случае, если х<у. Для того чтобы не потерять начальное значение переменной х, введем дополнительную переменную t.
| if x<y then begin t:=x; x:=y; y:=t; end; |
Задача. Составить фрагмент программы поиска максимального числа из трех введенных с клавиатуры чисел.
Пусть а, b, c - вводимые с клавиатуры числа, Max - максимальное из их значений. На первом шаге предположим , что а - максимальное из чисел и поэтому Max:=a. Затем сравним значение предполагаемого максимума со значениями переменных b и с. Если значение m окажется меньше, чем значение очередной переменной, то переопределим значение максимума.
| . . . m:=a; if m<b then m:=b; if m<c then m:=c; . . . |
Задача. Дан массив а, состоящий из 10 элементов. Составить программу поиска максимального элемента массива.
Используем идею предыдущей задачи. Перед началом поиска выберем условно в качестве максимального первый элемент массива Max:=a[1]. Затем по очереди каждый элемент массива сравним со значением переменной m. Если он окажется больше, то изменим значение Max. После анализа всех элементов массива переменная Max содержит значение максимального элемента массива.
|
|
|
| . . . Max:=a[1]; for i := 2 to 10 do if Max<a[i] then Max := a[i]; . . . |
Метод "пузырька" (или метод обмена)
По-видимому, самым простым методом сортировки является так называемый метод "пузырька".
Принцип метода:
Слева направо поочередно сравниваются два соседних элемента, и если их взаимное расположение не соответствует заданному условию упорядоченности, то они меняются местами. Далее берутся два следующих соседних элемента и так далее до конца массива.
После одного такого прохода на последней n-ой позиции массива будет стоять максимальный (или минимальный) элемент ("всплыл" первый "пузырек"). Поскольку максимальный (или минимальный) элемент уже стоит на своей последней позиции, то второй проход обменов выполняется до (n-1)-го элемента.
И так далее. Всего требуется (n-1) проход.
Итак, этот алгоритм в исходном списке ищет пары цифр, которые следуют не по порядку и затем меняет их местами. Процесс повторяется до тех пор пока весь список не будет отсортированным. Элемент двигается к вершине, как пузырёк воздуха к поверхности воды. Этот эффект и дал название алгоритму пузырьковой сортировке.
|
|
|
Чтобы уяснить его идею, представьте, что массив (таблица) расположен вертикально. Элементы с большим значением всплывают вверх наподобие больших пузырьков. При первом проходе вдоль массива, начиная проход "снизу", берется первый элемент и поочередно сравнивается с последующими. При этом:
- если встречается более "легкий" (с меньшим значением) элемент, то они меняются местами;
- при встрече с более "тяжелым" элементом, последний становится "эталоном" для сравнения, и все следующие сравниваются с ним .
В результате наибольший элемент оказывается в самом верху массива.
Во время второго прохода вдоль массива находится второй по величине элемент, который помещается под элементом, найденным при первом проходе, т.е на вторую сверху позицию, и т.д.
Заметим, что при втором и последующих проходах, нет необходимости рассматривать ранее "всплывшие" элементы, т.к. они заведомо больше оставшихся. Другими словами, во время j-го прохода не проверяются элементы, стоящие на позициях выше j.
Теперь можно привести текст программы упорядочения массива M[1..N]:
| begin for j:=1 to N-1 do for i:=1 to N-j do if M[i] > M[i+1] then swap(M[i],M[i+1]) end; |
Стандартная процедура swap будет использоваться и в остальных алгоритмах сортировки для перестановки элементов (их тип мы уточнять не будем) местами:
| procedure swap (var x,y: ...); var t: ...; begin t := x; x := y; y := t end; |
Заметим, что если массив M — глобальный, то процедура могла бы содержать только аргументы (а не результаты). Кроме того, учитывая специфику ее применения в данном алгоритме, можно свести число парметров к одному (какому?), а не двум.
Применение метода "пузырька" можно проследить здесь.
http://www.vzmakh.ru/info/pascal/files/sort_bbl.html
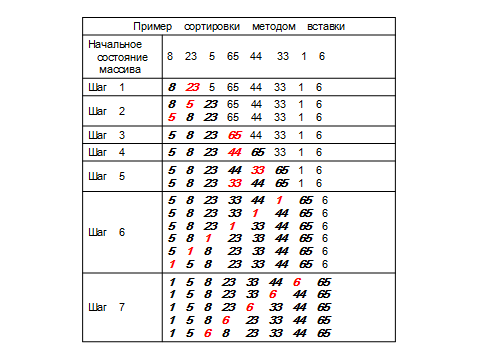
Сортировка вставками
Это тоже предельно простой для понимания алгоритм. Идея в том, чтобы создать новый массив, а затем последовательно вставлять в новый массив элементы из старого массива, чтобы созданный массив был всё время упорядоченным.
Метод называется метод вставок., т.к. на j-ом этапе мы "вставляем" j-ый элемент M[j] в нужную позицию среди элементов M[1], M[2],. . ., M[j-1], которые уже упорядочены. После этой вставки первые j элементов массива M будут упорядочены.
Принцип метода заключается в следующем:
Массив разделяется на две части: отсортированную и не отсортированную. Элементы из не отсортированной части поочередно выбираются и вставляются в отсортированную часть так, чтобы не нарушить в ней упорядоченность элементов. В начале работы алгоритма в качестве отсортированной части массива принимают только первый элемент, а в качестве не отсортированной - все остальные элементы.
Чтобы сделать процесс перемещения элемента M[j], более простым, полезно воспользоваться барьером: ввести "фиктивный" элемент M[0], чье значение будет заведомо меньше значения любого из "реальных"элементов массива (как это можно сделать?). Мы обозначим это значение через - oo.
Если барьер не использовать, то перед вставкой M[j], в позицию i-1 надо проверить, не будет ли i=1. Если нет, тогда сравнить M[j] ( который в этот момент будет находиться в позиции i) с элементом M[i-1].
Описанный алгоритм имеет следующий вид:
| begin M[0] := -oo; for j:=2 to N do begin i := j; while M[i] < M[i-1] do begin swap(M[i],M[i-1]); i := i-1 end end end; |
Процедура swap нам уже встречалась.
Демонстрация сортировки вставками.
http://www.vzmakh.ru/info/pascal/files/sort_ins.html
Сортировка посредством выбора
Суть алгоритма состоит в том, чтобы в исходном массиве найти наименьший элемент, а затем поменять местами первый элемент в списке с найденным. После того, находиться наименьший их оставшихся и меняется со вторым элементом. И так до тех пор, пока весь список не будет отсортирован.
Другими словами:
находим (выбираем) в массиве элемент с минимальным значением на интервале от 1-го элемента до n-го (последнего) элемента и меняем его местами с первым элементом. На втором шаге находим элемент с минимальным значением на интервале от 2-го до n-го элемента и меняем его местами со вторым элементом. И так далее для всех элементов до n-1-го.
Т.о., идея сортировки с помощью выбора не сложнее двух предыдущих.
На j-ом этапе выбирается элемент наименьший среди M[j], M[j+1],. . ., M[N](см. процедуру FindMin) и меняется местами с элементом M[j]. В результате после j-го этапа все элементы M[j], M[j+1],. . ., M[N]будут упорядочены.
Сказанное можно описать следующим образом:
нц для j от 1 до N-1
выбрать среди M[j],. . ., M[N] наименьший элемент и
поменять его местами с M[j]
кц
Более точно:
| begin for j:=1 to N-1 do begin FindMin(j, i); swap(M[j],M[i]) end end; |
В программе, как уже было сказано, используется процедура FindMin, вычисляющая индекс lowindex элемента, наименьшего среди элементов массива с индексами не меньше, чем startindex:
| procedure FindMin (startindex: integer; var lowindex: integer); var lowelem: ...; u: integer; begin lowindex := startindex; lowelem := M[startindex]; for u:=startindex+1 to N do if M[u] < lowelem then begin lowelem := M[u]; lowindex := u end end; |
Оценивая эффективность применения , учтите что в демонстрации сортировки выбором отсутствует пошаговое выполнение этой процедуры.
http://www.vzmakh.ru/info/pascal/files/sort_chc.html
Итак:
Методы внутренней сортировки можно разбить в соответствии с определяющими их принципами на три класса:
- Сортировка вставками: элементы просматриваются по одному, и каждый новый элемент вставляется на подходящую позицию среди ране упорядоченных элементов.
- Сортировка с помощью выбора: сначала выделяется наименьший (или наибольший) элемент и каким-либо образом отделяется от остальных, затем выбирается наименьший (наибольший) из оставшихся элементов и т.д.
- Сортировка с помощью обмена: последовательно просматриваются пары соседних элементов; если элементы в паре образуют инверсию (т.е. неупорядочены), то они меняются местами.
Все прямые методы сортировки фактически передвигают каждый элемент массива на каждом элементарном шаге на одну позицию. Поэтому требуют O(n2) таких шагов. В основу любых улучшенных методов положен принцип перемещения элементов на каждом шаге сортировки на большие расстояния. Такой подход позволяет существенно уменьшить время сортировки, но усложнить алгоритмы выполнения.
Улучшенный метод обмена – Шейкерная сортировка, метод Хоара (самый быстрый из известных на сегодняшний день методов внутренней сортировки), усовершенствование сортировки прямого включения – метод Шелла, прямого выбора – сортировка с помощью бинарного дерева.
Бинарный поиск
Использование упорядоченности позволяет создавать эффективные алгоритмы для решения многих интересных задач.
Если у нас есть массив, содержащий упорядоченную последовательность данных, то очень эффективен двоичный поиск.
Переменные Up и Down содержат, соответственно, левую и правую границы отрезка массива, где находится нужный нам элемент. Мы начинаем всегда с исследования среднего элемента отрезка: Mid = (Up + Down)/2;Если искомое значение меньше среднего элемента, мы переходим к поиску в левой половине отрезка, где все элементы меньше только что проверенного. Другими словами, значением Up становится (Mid – 1) и на следующей итерации мы работаем с половиной массива. Таким образом, в результате каждой проверки мы вдвое сужаем область поиска. Таким образом, если длина массива равна 6, нам достаточно трех итераций, чтобы найти нужное число.
Подробнее:
− В начале переменная Up указывает на самый маленький - первый (левый) элемент массива (Up := 0), Down - на самый большой - последний (правый) (Down := n, где n - верхний индекс массива), а Mid - на средний.
Дальше,
− если искомое число равно Mid, то задача решена;
− если число меньше Mid, то нужный нам элемент лежит ниже среднего, и за новое значение Up принимается Mid + 1;
− и если нужное нам число меньше среднего элемента, значит, оно расположено выше среднего элемента, и Down := Mid - 1.
− затем следует новая итерация цикла, и так повторяется до тех пор, пока не найдётся нужное число, или Up не станет больше Doun.
Дата добавления: 2021-01-21; просмотров: 81; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!