Построение степенной регрессии.
ЗАДАНИЕ 2. ПОСТРОЕНИЕ ПАРНОЙ РЕГРЕССИОННОЙ МОДЕЛИ
Цель работы: Оценить качество парной линейной (  ) и степенной
) и степенной 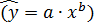 регрессий. Выбрать наилучшую модель для дальнейшего эконометрического анализа.
регрессий. Выбрать наилучшую модель для дальнейшего эконометрического анализа.
Оценка качества модели осуществляется по следующим показателям:
1. коэффициент детерминации  ;
;
2. средняя ошибка аппроксимации 
3. F- критерий Фишера.
Качество модели считается высоким, если выполняются все три условия:
1. коэффициент детерминации 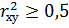 ;
;
2. средняя ошибка аппроксимации 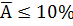 ;
;
3. Fтабл < Fфакт.
Если хоть одно из условий не выполняется, качество модели низкое.
Выбор наилучшего варианта эконометрической модели осуществляется сравнением их качественных характеристик (показателей). Соответственно лучшему варианту модели должны соответствовать лучшие характеристики.
Построение парной линейной регрессии.
Указания к выполнению лабораторной работы.
1) Создайте и сохраните на своем диске Z новый файл MS Excel.
2) Запишите тему, цель работы и вид регрессионной модели (уравнение).
3) Вставьте в него таблицу исходных данных (вместе с номером варианта), скопировав ее в файле «Задания к ЛР» (у каждого студента свой вариант заданий, который присваивает ему преподаватель на практическом занятии. Пример на стр. 2, таблица 1).
4) Выполните расчеты коэффициентов а и в уравнения регрессии, используя регрессионный анализ (методика приведена на стр. 2).
|
|
|
5) Выполните расчет 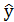 по уравнению линейной регрессии
по уравнению линейной регрессии 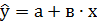 , пристроив дополнительный столбец к таблице исходных данных (см. пример таблица 1.
, пристроив дополнительный столбец к таблице исходных данных (см. пример таблица 1.
6) Рассчитайте среднюю ошибку аппроксимации (см. пример таблицы 2).
7) Сделайте вывод по показателям:
· коэффициент корреляции 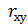 – о тесноте и характере связи;
– о тесноте и характере связи;
· коэффициент детерминации – о влиянии изменения результата «у» при изменении факторной переменной «х»;
· средняя ошибка аппроксимации 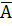 – о величине ошибки регрессии;
– о величине ошибки регрессии;
· F - критерий Фишера – о значимости и надежности оцениваемых характеристик (о принятии или отвержении гипотезы Н0).
Рассмотрим пример расчета и анализа следующих исходных данных.
Таблица 1
Продажа макаронных изделий (за год)
| Y | Х | |
| Территории потребителей | Продано в год, т. р. | Заказано в год, т.р. |
| Свердловская область | 475,5 | 502 |
| Республика Бурятия | 2100,3 | 2022,2 |
| Красноярский край | 3188,4 | 3012,2 |
| Омская область | 1038 | 1053,3 |
| Алтайский край | 2199,8 | 2100,1 |
| Кемеровская область | 20981 | 19034,5 |
| Новосибирская область | 46104,3 | 38321,1 |
| Томская область | 2503,8 | 2202,2 |
|
|
|
1) Определим, где в таблице исходных данных зависимая переменная «у», а где независимая (объясняющая) переменная «х» (т.е. что от чего зависит: объем продаж от объема заказов (изначально) или наоборот).
Обозначим: Y – продано товаров за год, т. р., Х – заказано в соответствии с договорами за год, т.р.
2) Введем обозначения переменных над шапкой таблицы исходных данных и выделите эти ячейки яркой заливкой (см. пример таблицы 2.1).
3) Находим параметры а и в. Для этого на вкладке «Данные» программы Excel щелкнуть в «Анализ данных → Регрессия» (Настройка Анализа данных: нажать Файл  Параметры
Параметры  слева в диалоговом окне щелкнуть в Надстройки справа в окне «Пакет анализа»
слева в диалоговом окне щелкнуть в Надстройки справа в окне «Пакет анализа»  далее внизу кнопку Перейти активировать(отметить галочкой) «Пакет анализа». Справа, в верхнем углу, на панели инструментов вкладки ДАННЫЕ появится функция Анализ данных).
далее внизу кнопку Перейти активировать(отметить галочкой) «Пакет анализа». Справа, в верхнем углу, на панели инструментов вкладки ДАННЫЕ появится функция Анализ данных).
В раскрывшемся диалоговом окне вводим:
® «Входной интервал Y» - щелкнуть курсор в окно напротив «входной интервал Y» и выделить весь столбец числовых значений результативного показателя (у);
® «Входной интервал Х» - щелкнуть курсор в окно напротив «входной интервал Х» и выделить весь столбец числовых значений факторного показателя (х);
|
|
|
® «Выходной интервал» - щелкнуть курсор в окно напротив «выходной интервал» и выделить одну пустую ячейку слева под таблицей исходных данных (см. пример рис. 1.)
® Нажать ОК.
Под таблицей исходных данных появится «ВЫВОД ИТОГОВ» - таблицы с показателями, рассчитанные в ходе выполнения регрессионного анализа.
«ВЫВОД ИТОГОВ» содержит 3 таблицы:
1. «Регрессионная статистика»:
· множественный R – коэффициент корреляции R;
· R–квадрат – коэффициент детерминации R2;
· нормированный R – нормированное значение коэффициента корреляции;
· стандартная ошибка – стандартное отклонение остатков;
· наблюдения – число исходных наблюдений (объем выборки).
2. Показатели таблицы «Дисперсионный анализ»:
· столбец «F» – расчетное значение F-критерия Фишера (это Fфакт);
· столбец «Значимость F» – значение уровня значимости, соответствующее вычисленному значению Fр.
3. Показатели таблицы 3:
· ячейка на пересечении столбца «Коэффициенты» и строки «Y - пересечение» – значение параметра уравнения линейной регрессии а - «отрезок».
· ячейка на пересечении столбца «Коэффициенты» и строки «Переменная Х1» – значение параметра уравнения линейной регрессии b – наклон.
|
|
|
Для нашего примера «вывод итогов» будет выглядеть следующим образом:
| Y | X | ||||||||||||||
| Территории | Продано, т.р. | Заказано, т.р. | y^=a+b*x | (y-y^)/y | |(y-y^)/y| | ||||||||||
| Свердловская область | 475,5 | 502 | 289,431216 | 0,391312 | 0,3913118 | ||||||||||
| Республика Бурятия | 2100,3 | 2022,2 | 2103,45947 | -0,0015 | 0,0015043 | ||||||||||
| Красноярский край | 3188,4 | 3012,2 | 3284,80927 | -0,03024 | 0,0302375 | ||||||||||
| Омская область | 1038 | 1053,3 | 947,28793 | 0,087391 | 0,0873912 | ||||||||||
| Алтайский край | 2199,8 | 2100,1 | 2196,41619 | 0,001538 | 0,0015382 | ||||||||||
| Кемеровская область | 20981 | 19034,5 | 22403,9416 | -0,06782 | 0,0678205 | ||||||||||
| Новосибирская область | 46104,3 | 38321,1 | 45418,3064 | 0,014879 | 0,0148792 | ||||||||||
| Томская область | 2503,8 | 2202,2 | 2318,25034 | 0,074107 | 0,0741072 | ||||||||||
| Якутия | 1780 | 1544 | 1532,83172 | 0,138859 | 0,1388586 | ||||||||||
| Читинская область | 851 | 869 | 727,365941 | 0,145281 | 0,1452809 | ||||||||||
| 0,9529295 | |||||||||||||||
| Аср.= | 9,5292947 | ||||||||||||||
| ВЫВОД ИТОГОВ | |||||||||||||||
| Регрессионная статистика | |||||||||||||||
| Множественный R (rху) | 0,999313564 | коэффициент корреляции | |||||||||||||
| R-квадрат | 0,998627599 | коэффициент детерминации | |||||||||||||
| Нормированный R-квадрат | 0,998456049 | ||||||||||||||
| Стандартная ошибка | 576,4462962 | ||||||||||||||
| Наблюдения | 10 | объем выборки | |||||||||||||
| F (табл) | 5,25 | ||||||||||||||
| Дисперсионный анализ | критерий Фишера | ||||||||||||||
| df | SS | MS | F (факт) | Значимость F | |||||||||||
| Регрессия | 1 | 1934328998 | 1934328998 | 5821,202 | 9,706E-13 | ||||||||||
| Остаток | 8 | 2658322,659 | 332290,332 |
| |||||||||||
| Итого | 9 | 1936987321 |
|
|
| ||||||||||
| Коэффициенты | Станд. ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | Нижние 95,0% | Верхние 95,0% | ||||||||
| Y-пересечение (коэф-нт a) | -309,596665 | 213,1717852 | -1,4523342 | 0,184474 | -801,1717 | 181,9784 | -801,172 | 181,9784 | |||||||
| Переменная X (коэф-нт b) | 1,193282631 | 0,015640009 | 76,2967991 | 9,71E-13 | 1,1572167 | 1,229349 | 1,157217 | 1,229349 | |||||||
 ,
,Рис. 1. Пример оформления лабораторной работы
Как показано в примере на рисунке 1, выделите и подпишите в выводах итогах регрессии все необходимые показатели: коэффициенты корреляции rху и детерминации , F-критерий Фишера, коэффициенты регрессии а и в.
После того как найдены коэффициенты а и в, рассчитываем функцию линейной регрессии ̂ 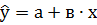 . Для этого к исходной таблице 1 добавляем столбец ̂
. Для этого к исходной таблице 1 добавляем столбец ̂ 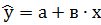 , (таблица 2).
, (таблица 2).
Таблица 2
| Y | X | ||||
| Территории потребителей | Продано, т.р. | Заказано, т.р. | y^=a+b*x | (y-y^)/y | |(y-y^)/y| |
| Свердловская область | 475,5 | 502 |
| 0,391312 | 0,3913118 |
| Республика Бурятия | 2100,3 | 2022,2 | 2103,45947 | -0,0015 | 0,0015043 |
| Красноярский край | 3188,4 | 3012,2 | 3284,80927 | -0,03024 | 0,0302375 |
| Омская область | 1038 | 1053,3 | 947,28793 | 0,087391 | 0,0873912 |
| Алтайский край | 2199,8 | 2100,1 | 2196,41619 | 0,001538 | 0,0015382 |
| Кемеровская область | 20981 | 19034,5 | 22403,9416 | -0,06782 | 0,0678205 |
| Новосибирская область | 46104,3 | 38321,1 | 45418,3064 | 0,014879 | 0,0148792 |
| Томская область | 2503,8 | 2202,2 | 2318,25034 | 0,074107 | 0,0741072 |
| Якутия | 1780 | 1544 | 1532,83172 | 0,138859 | 0,1388586 |
| Читинская область | 851 | 869 | 727,365941 | 0,145281 | 0,1452809 |
| 0,9529295 | |||||
| Аср.= | 9,5292947 |
 =а(F4)+b(F4)*гр.3
=а(F4)+b(F4)*гр.3
Для расчета величины у^ необходимо выполнить следующее:
1. поставить курсор в ячейку, выделенную желтым цветом;
2. ввести формулу:
= абсолютный адрес коэффициента (а) ( F 4) + абсолютный адрес
коэффициента (в)( F 4) * относительный адрес значения x i (Заказано, т.р.) по Свердловской области.
Для того чтобы адрес ячейки не смещался при протягивании формулы, нужно во время записи формулы ввести абсолютный адрес этой ячейки, т.е. при ссылке на адрес ячейки, где стоит коэффициент а и в вводится символ доллара (например, $ D $11). Для этого достаточно нажать клавишу F 4, после введения в строку формулы адреса соответствующей ячейки:
= адрес ячейки «коэффициент (а)» (нажать F 4 ) + адрес ячейки «коэффициент (в)» (нажать F 4 ) * адрес ячейки x i (Заказано) по Свердловской области.
3. после ввода формулы нажать клавишу E nt er и захватив мышью правый нижний угол ячейки, протянуть ее на 9 строчек вниз.
Таким образом, функция линейной регрессии рассчитана.
Далее рассчитываем среднюю ошибку аппроксимации по формуле:
 |
Расчет выполним также с помощью дополнительных вспомогательных расчетных столбцов (см. табл. 3 графа 5,6)
Таблица 3
| Y | X | |||||
| 1 | 2 | 3 | 4 | 5 | 6 | |
| Территории потребителей | Продано, т.р. | Заказано, т.р. | y^=a+b*x | (y-y^)/y | |(y-y^)/y| | |
| Свердловская область | 475,5 | 502 |
|
|
| |
| Республика Бурятия | 2100,3 | 2022,2 | 2103,45947 | -0,0015 | 0,0015043 | |
| Красноярский край | 3188,4 | 3012,2 | 3284,80927 | -0,03024 | 0,0302375 | |
| Омская область | 1038 | 1053,3 | 947,28793 | 0,087391 | 0,0873912 | |
| Алтайский край | 2199,8 | 2100,1 | 2196,41619 | 0,001538 | 0,0015382 | |
| Кемеровская область | 20981 | 19034,5 | 22403,9416 | -0,06782 | 0,0678205 | |
| Новосибирская область | 46104,3 | 38321,1 | 45418,3064 | 0,014879 | 0,0148792 | |
| Томская область | 2503,8 | 2202,2 | 2318,25034 | 0,074107 | 0,0741072 | |
| Якутия | 1780 | 1544 | 1532,83172 | 0,138859 | 0,1388586 | |
| Читинская область | 851 | 869 | 727,365941 | 0,145281 | 0,1452809 | |
|
| 0,9529295 | =S гр.6 | ||||
|
| 9,5292947 | = Аср. |
 =а(F4)+b(F4)*гр.3
=а(F4)+b(F4)*гр.3 =(гр.2-гр.4)/гр.2
=(гр.2-гр.4)/гр.2 =АВS (гр.5)
=АВS (гр.5)Для расчета графы 5 ((y-y^)/y) таблицы 3 необходимо:
1. поставить курсор в пустую ячейку, выделенную желтым цветом;
2.ввести формулу:
= (относительный адрес значения «у» по Свердловской области – относительный адрес значения «у^» по Свердловской области) / относительный адрес значения «у» по Свердловской области.
3. после ввода формулы нажать клавишу E nt er и захватив мышью правый нижний угол ячейки, протянуть ее на 9 строчек вниз.
Для расчета графы 6 (|(y-y^)/y|) таблицы 3необходимо:
1. поставить курсор в ячейку, выделенную оранжевым цветом;
2. На панели инструментов щелкнуть в кнопку f ( x ). В появившемся диалоговом окне выбрать Категорию «Математические» ® функция «ABS» ®ОК® в ыделить значение графы 5 ((y-y^)/y) по Свердловской области ® ОК.
3. После ввода формулы захватив мышью правый нижний угол ячейки и протянуть ее на 9 строчек вниз.
4. Находим сумму графы |(y-y^)/y|(т.е. автосумму графы 6) в ячейке сиреневого цвета (см.табл.3) под этим столбцом.
5. Рассчитываем Аср. по формуле стр.7. Ставим курсор в ячейку ниже автосуммы (гр.6) и записываем формулу:
= щелкаем в ячейку с автосуммой/ 10*100
6. Делаем выводы о качестве модели по показателям:
1. коэффициент корреляции;
2. коэффициент детерминации;
3. средняя ошибка аппроксимации;
4. F-критерий Фишера.
7. Сделаем общий вывод о качестве построенной линейной модели (см. стр.1)
Построение степенной регрессии.
Цель данной работы аналогичная, что для парной линейной регрессии: оценить качество модели (см. стр.1).
1) Запишите тему, цель работы и вид степенной регрессии  .
.
2) Для построения степенной регрессии используются те же исходные данные, что и при построении линейной регрессии. Скопируйте их и вставьте на новый рабочий лист.
Так как цель аналогична предыдущей работе, значит и последовательность выполнения расчетов будет аналогична.
Отличительной особенностью будет расчет регрессионного анализа, в который берутся не исходные данные У и Х, а прологарифмированные значения этих переменных (см.таблицу4). Так как регрессионный анализ строится только для линейных функций, мы степенную регрессию должны привести к линейному виду (через функцию LN), а затем рассчитать параметры уравнения регрессии а и в.
Для этого к таблице исходных данных (таблица 1), которую скопировали на новый рабочий лист, необходимо добавить два столбца (таблица 4 графа 4,5).
Таблица 4
| Y | X |
|
| ||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Территории потребителей | Продано, т.р. | Заказано, т.р. | LN Y | LN X | y^=a*x^b | (y-y^)/y | |(y-y^)/y| |
| Свердловская обл. | 475,5 | 502 | =LN(y)
| =LN(x)
| 496,5352 | -0,04424 | 0,04423 |
| Республика Бурятия | 2100,3 | 2022,2 | 7,6498 | 7,61194 | 2124,595 | -0,01157 | 0,01156 |
| Красноярский край | 3188,4 | 3012,2 | 8,06727 | 8,01042 | 3219,812 | -0,00985 | 0,00985 |
| Омская область | 1038 | 1053,3 | 6,94505 | 6,95968 | 1075,812 | -0,03643 | 0,03642 |
| Алтайский край | 2199,8 | 2100,1 | 7,69612 | 7,64974 | 2210,055 | -0,00466 | 0,00466 |
| Кемеровская обл. | 20981 | 19034,5 | 9,95137 | 9,85400 | 22037,49 | -0,05035 | 0,05035 |
| Новосибирская обл. | 46104,3 | 38321,1 | 10,7386 | 10,5537 | 45731,91 | 0,00807 | 0,00807 |
| Томская область | 2503,8 | 2202,2 | 7,82556 | 7,69721 | 2322,269 | 0,07250 | 0,07250 |
| Якутия | 1780 | 1544 | 7,48436 | 7,34213 | 1603,337 | 0,09924 | 0,09924 |
| Читинская область | 851 | 869 | 6,74641 | 6,76734 | 880,2109 | -0,03433 | 0,03432 |
| 0,37125 | |||||||
| Аср.= | 3,71255 |
Для заполнения колонок LN Y и LN X необходимо поставить курсор в первую ячейку столбца LN Y (синяя заливка)и на вкладке «Формулы» вызвать “Вставить функцию ® Категория: Математические ® функция: LN” и выделить значение Y (продано) по Свердловской области и нажать «ОК». После ввода формулы захватив мышью правый нижний угол ячейки, протянуть ее на 9 строчек вниз, а затем на одну колонку вправо.
Теперь можно искать параметры а и b. Для этого выполняем следующее: Данные ®анализ данных →Регрессия.
В раскрывшемся диалоговом окне ввести толькод анные:
a) «В ходной интервал Y» - выделить весь диапазон числовых значений содержащихся в колонке LN Y;
b) «В ходной интервал Х» - выделить весь диапазон числовых значений содержащихся в колонке LN X;
c) «В ыходной интервал» - выделить одну пустую ячейку слева под таблицей исходных данных см. рис. 1стр.4
После нажатия кнопки «ОК» в диалоговом окне Регрессии под таблицей исходных данных появятся результаты регрессионного анализа, которые называются «Вывод итогов».
В появившихся таблицах также как и при построении линейной функции необходимо выделить заливкой и подписать: коэффициенты корреляции и детерминации, критерий Фишера, коэффициенты А и в.
Обратите внимание, что с помощью Регрессии вы нашли коэффициент
«А», а не «а». Следовательно, для того чтобы определить «а» необходимо поставить курсор в пустую ячейку рядом с «Выводом итогов» и на вкладке
«Формулы» вызвать “В ставить функцию ® Категория: Математические ®
функция: EXP” и выделить значение «А».
После того как найдены коэффициенты а и в, мы можем рассчитать функцию степенной регрессии у̂ = ахв. Для этого к таблице 4 необходимо добавить столбец (графа 6).
Для расчета графы 6необходимо выполнить следующие команды (как и в линейной регрессии):
1. поставить курсор в ячейку, выделенную желтым цветом;
2. ввести формулу: = абсолютный адрес коэффициента (а) * относительный адрес значения (х) заказано по Свердловской области ^ абсолютный адрес коэффициента (в)
Для того чтобы возвести число в степень, необходимо переключить клавиатуру на английский язык и нажать сочетание клавиш Shift – 6 и тогда у вас появится значок (^), означающий возведение в степень.
3. после ввода формулы нажать клавишу E nt er и захватив мышью правый нижний угол ячейки, протянуть ее на 9 строчек вниз.
Далее также как и при построении линейной модели, необходимо рассчитать среднюю ошибку аппроксимации (пристраиваем графы 7 и 8 таблица 4) и оценить качество построенной степенной модели, придерживаясь указаний изложенных выше и в лекционной материале. Работа должна завершиться написанием вывода по степенной модели, а также необходимо сравнить линейную и степенную модель и сделать вывод о том какая модель подходит для ваших данных больше.
Для того чтобы рассчитать колонку у = а*х^в необходимо:
1. поставить курсор в ячейку, выделенную желтым цветом;
2. ввести формулу: = абсолютный адрес коэффициента (а) * относительный адрес значения (х) заказано по Свердловской области ^ абсолютный адрес коэффициента (в)
Для того чтобы возвести число в степень, необходимо переключить клавиатуру на английский язык и нажать сочетание клавиш Shift – 6 и тогда у вас появится значок (^), означающий возведение в степень.
3. после ввода формулы нажать клавишу Enter и захватив мышью правый нижний угол ячейки, протянуть ее на 9 строчек вниз.
Далее также как и при построении линейной модели, необходимо рассчитать среднюю ошибку аппроксимации и оценить качество построенной степенной модели, придерживаясь указаний изложенных выше. Работа должна завершиться написанием вывода по степенной модели, а также необходимо сравнить линейную и степенную модель и сделать вывод о том какая модель подходит для ваших данных больше.
Дата добавления: 2021-01-20; просмотров: 63; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!