V. Представление результатов выполнения работы.
ЛАБОРАТОРНАЯ РАБОТА №3
Статистические методы оценки парных групповых различий в процессе интерпретации результатов медико-биологических исследований
I. Цель работы: Практическая оценка диагностической значимости различных биохимических маркеров на основе методов проверки статистических гипотез.
Одной из типичных задач анализа результатов биомедицинских исследований является задача, заключающаяся в подтверждении объективной диагностической значимости тех или иных клинико-биохимических показателей на основе анализа различий в степени их проявления в группах больных с определенным диагнозом и контрольной группе с нормальными значениями исследуемого показателя. Проблема заключается в том, что эмпирические данные представлены выборками результатов измерений исследуемого показателя среди больных с определенным диагнозом и выборкой нормальных значений показателя ограниченного объема. В этих условиях подтверждение объективного наличия (или отсутствия) различий в степени проявления тех или иных показателей возможно на основе аппарата проверки статистических гипотез.
Несмотря на огромное многообразие такого рода задач, подходы к их практическому решению во многом определяются видом статистической модели, описывающей распределение значений исследуемых показателей. Существуют две группы методов проверки статистических гипотез, применяемые в задачах анализа результатов биомедицинских исследований, условно называемые параметрическими (в тех случаях, когда эмпирическое распределение принадлежит некоторому параметрическому семейству теоретических распределений, а конкретно семейству нормальных распределений) и непараметрическими (для тех случаев, когда не удается обосновать такую принадлежность).
|
|
|
Особый интерес представляет решение сформулированной задачи в условиях, когда распределение исследуемого показателя в обоих группах, является нормальным распределением. Как показывает практика, самые разнообразные данные биомедицинских исследований с достаточной степенью точности можно считать выборками из нормального распределения. Это следует из того, что нормально распределенная случайная величина может рассматриваться как результат воздействия большого числа независимых (или почти независимых) факторов, причем влияние каждого из них вносит малый вклад в изменение значений случайной величины.
Целью данной работы является практическое освоение параметрических методов проверки статистических гипотез на примере ряда практических задач анализа данных клинико-биохимических обследований.
|
|
|
II. Структура данных: варианты эмпирических распределений клинико-биохимических показателей представлены полями var1-var12 файла l_w2.sta, располагаемому на диске Вашего компьютера:
D:\KAF704\STATISTICA6\LAB_W\l_w3.sta
III. Варианты выполнения лабораторной работы:
Вариант 1: (поля var1-var2 файла l_w3.sta). Поле var1 -эмпирическое распределение уровней a-фетопротеина (АФП) в крови обследованных женщин контрольной группы (у плода которых отсутствовал синдром Дауна); поле var2- эмпирическое распределение уровней АФП в крови женщин, у плода которых установлено наличие синдрома Дауна.
Вариант 2: (поля var3-var4 файла l_w3.sta). Поле var3- эмпирическое распределение уровней хориониеского гонадотропина человека (ХГЧ) в крови обследованных женщин контрольной группы (с отсутствием синдрома Дауна у плода); Поле var4- эмпирическое распределение уровней ХГЧ в крови женщин, у плода которых подтверждено наличие синдрома Дауна;
Вариант 3: (поля var5-var6 файла l_w3.sta)- эмпирические распределения измеренных значений уровней АФП в двух независимых группах женщин, у плода которых отсутствовал синдром Дауна.
Вариант 4: (поля var7-var8 файла l_w3.sta)- эмпирические распределения измеренных значений уровней ХГЧ в двух независимых группах женщин, у плода которых отсутствовал синдром Дауна.
|
|
|
Установлено, что АФП и ХГЧ являются определяющими биохимическими маркерами, позволяющими проводить пренатальную ( на этапе беременности) диагностику синдрома Дауна у плода. Для того, чтобы доказать их диагностическую значимость необходимо доказать:
1) что уровни указанных маркеров статистически достоверно (с достаточно высоким уровнем доверительной вероятности) различаются среди группы пациентов с синдромом Дауна у плода и контрольной группы женщин. Решение этих задач составляет содержание вариантов 1 и 2 лабораторной работы;
2) что указанные биохимические маркеры не обнаруживают статистически значимых различий в группах обследованных женщин со здоровым плодом. Решение этих двух задач составляет содержание вариантов 3 и 4 лабораторной работы.
Вариант 5: (поле var9-var10 файла l_w3.sta)- Поле var9 - эмпирическое распределение уровней лактата в крови больных с различными типами болезней дыхательной цепи митохондрий (БДЦМ), Поле var10 - эмпирическое распределение уровней лактата в контрольной группе (здоровых людей).
Вариант 6: (поле var11-var12 файла l_w3.sta)- Поле var11- эмпирическое распределение уровней 3-гидроксибутирата в крови больных с различными типами болезней дыхательной цепи митохондрий (БДЦМ), Поле var12 - эмпирическое распределение уровней 3-гидроксибутирата в контрольной группе (здоровых людей).
|
|
|
БДЦМ- представляют собой группу тяжелых наследственных заболеваний, в диагностике которых ведущая роль принадлежит биохимическим методам. Одними из определяющих биохимических маркеров является лактат (молочная кислота) и 3-гидроксибутират, изменение уровня которых с большой степенью уверенности позволяет предположить наличие у пациента данного диагноза. Подтверждение их диагностической значимости определяет содержание вариантов 5-6 лабораторной работы.
IV. Краткие сведения о методах проверки статистических гипотез, связанных с параметрами нормального распределения.
Предположим, что в 2-х независимых группах пациентов проведены измерения некоторого случайного показателя (в рассматриваемом нами случае- уровни биохимических маркеров). Результаты измерений представлены выборками X1,...X n и Y1,...,Y m реализаций его значений. Предполагается также, что случайные величины X и Y имеют нормальное распределение с параметрами: X Î N(mx, s 2 x ), Y Î N(my, s 2 y),где mx,my - математические ожидания, а s 2 x , s 2 y - дисперсии измеряемого параметра в исследуемых группах. Заметим, что выдвинутое предположение должно быть предварительно обосновано на основе критериев согласия.
С учетом выдвинутого предположения, в математической постановке рассматриваемая задача анализа различий в значениях измеряемых параметров X,Y, имеющих нормальное распределение, формулируется как задача сравнения их средних значений. Рассмотрим нулевую гипотезу
Н0: mx=my,
заключающуюся в том, что средние значения измеряемого параметра в исследуемых группах не различаются, против альтернативной гипотезы mx ¹ my.
Для проверки гипотезы Н0: mx=my используется критерий Стьюдента (или t-тест), основу которого составляет статистика следующего вида:
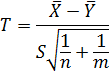
где 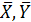 - выборочные средние измеряемого параметра в сравниваемых группах;
- выборочные средние измеряемого параметра в сравниваемых группах;
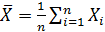 ,
, 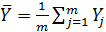
n, m- объемы выборок; S2- оценка дисперсии исследуемого показателя в объединенной выборке
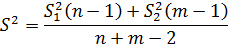
S 2 1 , S 2 2 - выборочные дисперсии исследуемого показателя в сравниваемых группах.
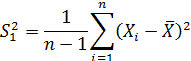
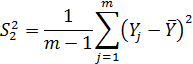
Приведенная выше статистика Т в том случае, когда гипотеза Н0: mx=my верна, имеет распределение Стьюдента с n+m-2 степенями свободы. Опираясь на известный закон распределения Стьюдента можно сформулировать правило оценки различий между группами. Это правило опирается на анализе следующих величин:
1) 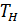 –наблюдаемое значение статистики Стьюдента, рассчитанное на основе экспериментальных данных с использованием вышеприведенных выражений
–наблюдаемое значение статистики Стьюдента, рассчитанное на основе экспериментальных данных с использованием вышеприведенных выражений
2) уровень значимости p – вероятность получить такое как наблюдаемое значение статистики Стьюдента, если верно предположение об отсутствии различий между группами. Это предположение отвергается, если рассчитанный уровень значимости мал ( 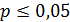 ). Иными словами, делается вывод о том, что сравниваемые группы демонстрируют статистически значимые различия по значениям показателя, на основе которого проводится их сравнение. В противном случае (
). Иными словами, делается вывод о том, что сравниваемые группы демонстрируют статистически значимые различия по значениям показателя, на основе которого проводится их сравнение. В противном случае ( 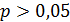 ) делается вывод о том, что представленные для анализа данные не подтверждают статистически достоверных различий между группами.
) делается вывод о том, что представленные для анализа данные не подтверждают статистически достоверных различий между группами.
Решение о статистической значимости различий между исследуемыми группами по уровню измеряемого параметра на основе критерия Стьюдента, зависит от того, равны или не равны дисперсии распределения измеряемого параметра в исследуемых группах. Иными словами из равенства математических ожиданий следует надежный вывод об отсутствии различий между группами только в том, случае если дисперсии исследуемого покаателя в сравниваемых группах равны
Для проверки гипотезы о равенстве дисперсий 2 используется статистика следующего вида:
F= S21/ S22,
называемая статистикой Фишера.
Опираясь на известный закон распределения Фишера можно сформулировать правило оценки различий между дисперсиями исследуемого показателя в сравниваемых группах. Это правило опирается на анализе следующих величин:
1) 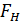 –наблюдаемое значение статистики Фишера, рассчитанное на основе экспериментальных данных с использованием вышеприведенных выражений
–наблюдаемое значение статистики Фишера, рассчитанное на основе экспериментальных данных с использованием вышеприведенных выражений
2) уровень значимости 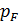 – вероятность получить такое как наблюдаемое значение статистики Фишера, если верно предположение об отсутствии различий между дисперсиями. Это предположение отвергается, если рассчитанный уровень значимости мал (
– вероятность получить такое как наблюдаемое значение статистики Фишера, если верно предположение об отсутствии различий между дисперсиями. Это предположение отвергается, если рассчитанный уровень значимости мал ( 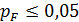 ). В этом случае вывод о наличии различий между группами недостаточно надежен и требуется его дополнительное подтверждение с использованием других методов, например, методов непараметрической статистики. В противном случае ( ) можно утверждать, что дисперсии значений исследуемого показателя в сравниваемых группах не демонстрируют существенных различий, а значит, вывод сделанный ранее на основе статистики Стьюдента абсолютно надежен.
). В этом случае вывод о наличии различий между группами недостаточно надежен и требуется его дополнительное подтверждение с использованием других методов, например, методов непараметрической статистики. В противном случае ( ) можно утверждать, что дисперсии значений исследуемого показателя в сравниваемых группах не демонстрируют существенных различий, а значит, вывод сделанный ранее на основе статистики Стьюдента абсолютно надежен.
IV. Порядок выполнения работы.
1. Произвести загрузку пакета ”STATISTICA”.
2. В горизонтальном меню пакета активизировать опцию “Статистики” (S tatistics ), а затем опцию “Основные статистики и таблицы” (Basic Statistics/Tables).
3. Произвести загрузку файла исходных данных l_w3.sta нажатием функциональной клавиши (ФК) “Open Data”. Поиск файла в соответствии с приведенным в п. II путем доступа производится традиционными для системы Windows средствами.
4. Переходим непосредственно к анализу различий между сравниваемыми выборками. Возможны различные по строгости и степени обоснованности выводов подходы к анализу различий между группами по уровню значений измеряемого параметра:
-качественный (предварительный этап), на основе визуального анализа кривых плотности распределения вероятностей значений измеряемого параметра в каждой из групп. В некоторых случаях, когда различия очевидны, можно ограничиться лишь качественным анализом, но в большинстве случаев он может рассматриваться как предварительный этап, требующий дальнейшего подтверждения на основе количественного критерия;
-количественный, на основе подтверждения статистической значимости различий в значениях измеряемого параметра с использованием критерия Стьюдента.
Качественный (визуальный) анализ распределения значений измеряемого параметра в исследуемых группах. Для практической реализации этого вида анализа необходимо выбрать опцию “Графики” (Graphs) горизонтального меню и далее “Двумерные графики” (2D Graphs). Во всплывающем меню необходимо выбрать опцию “Гистограммы” (Histograms) двойным нажатием левой клавиши мыши. В появившемся экране “Гистограммы” (2D Histograms) необходимо указать варианты эмпирических распределений измеряемого показателя в сравниваемых группах. Для чего используется ФК “Переменные” (Variables) с последующей маркировкой интересующей Вас пары переменных (задаваемой вариантом задания). Маркировка необходимой пары сравниваемых переменных осуществляется их последовательным выбором при нажатой клавиши Shift на клавиатуре.
В блоке настроек («Advanced») указывается “Тип графика” (Graph Type)- “Многомерный” (Multiple). Выбор указанной опции обеспечивает совмещенное отображение гистограмм распределения значений исследуемого параметра для каждой их двух исследуемых групп. Аналогичные возможности реализует опция “Две ординаты” (Double-Y), отличающаяся тем, что в этом случае отображение значений функции плотности по каждой из исследуемых переменных осуществляется с привязкой к собственной шкале. Этот вид графика удобнее использовать для сравнения распределений переменных, для которых характерно значительное различие в распределении значений частот по интервалам группировки гистограммы. В блоке настроек “Вид теоретического распределения” (Fit Type) необходимо указать “Нормальное распределение” (Normal). В блоке настроек “Группировка” (Categories) необходимо указать число интервалов группировки, в соответствии с которым будет сформирована гистограмма распределения.
Замечание: выбор опции “Целочисленный” (Integer mode) приводит к тому, что автоматически все значения измеряемого параметра в выборках будут округлены до целых значений с последующим отображением гистограммы в целочисленной шкале.
В пакете «STATISTICA» предусмотрена возможность отображения, как гистограммы распределения исследуемых значений, так и выборочной функции распределения. Представление того или иного закона распределения регулируется настройкой признака «Тип отображаемой зависимости» (« Showing Type »). Для отображения гистограммы распределения необходимо выбрать стандартный режим графического представления (« Standard »). Для отображения выборочной функции распределения устанавливается признак представления накопленных частот «Cumulative».
Конкретизация настроечного признака «Ось Y » (« Y axis ») позволит строить распределения либо в виде абсолютного числа значений (« N »), попадающих в различные интервалы группировки, либо в виде процентной доли («%»).
Дополнительно можно провести проверку согласия распределения значений в группах с нормальным законом распределения, используя настроечные признаки группы «Статистики» («Stastistics»).
Осуществив необходимые настройки и их подтверждение нажатием ФК “ОК” получим совместное графическое отображение функций плотности (либо функций распределения в зависимости от настроек), анализ которых позволит выдвинуть предварительное предположение относительно наличия(или отсутствия) различий в значениях измеряемого параметра в исследуемых группах пациентов.
Оценка статистической значимости различий с использованием критерия Стьюдента . Для получения подобной оценки необходимо в меню “Основные статистики” (Basic Statistics) выбрать опцию “t-тест для независимых выборок” (t-test for idependent samples). Пакет обеспечивает два варианта доступа к реализации критерия Стьюдента, в зависимости от способа представления данных в исходном файле. Опция “ t -тест для независимых выборок с учетом признака группировки” (t-test, idependent, by group ) предполагает, что исходный файл сформирован в виде двух полей. Первое поле - код переменной (или код сравниваемой группы), указывает принадлежность каждого значения измеряемого параметра к конкретной группе. Второе поле - измеренное значение показателя. Опция “ t -тест для независимых выборок, содержащихся в различных переменных” (t-test, idependent, by group ) предполагает, что все значения измеряемого параметра предварительно сгруппированы для каждой из исследуемых групп пациентов в отдельную переменную. Структура файла l_w3.sta ориентирована на использование именно этой опции!!
Подтвердив способ реализации критерия Стьюдента нажатием ФК «ОК», провести дальнейшие настройки процедуры реализации теста:
- указать пару исследуемых переменных, используя ФК “Переменные” (Variables);
- произвести настройки для проверки условий применимости критерия Стьюдента для конкретного характера эмпирического распределения и объема отображаемых результатов: 1) использование критерия Стьюдента в случае, когда равенство дисперсий не предполагается (t-test with separate variance estimate); 2) в тех случаях, когда объемы исследуемых выборок малы (<30) необходима дополнительная проверка о равенстве дисперсий исследуемых выборках с использованием либо критерия Левена (Leven’s test), либо критерия Брауна-Форсайта (Brown - Forsythe test)/ Заметим однако, что критерий Стьюдента позволяет формулировать вполне достоверные выводы относительно различий выборочных средних исследуемых нормальных распределений во всех случаях, когда объемы выборок >30, в этом случае нет необходимости в дополнительном использовании теста Левена.
Выполнив необходимые настройки для получения результатов анализа необходимо нажать ФК “ Summary ”. Результаты анализа с использованием критерия Стьюдента будут представлены в следующем составе:
-выборочное среднее в группе 1 (Mean Group 1);
-выборочное среднее в группе 2 (Mean Group 2);
-статистика Стьюдента (t-value), рассчитанная в предположении о том, что дисперсии измеряемого параметра в каждой из исследуемых групп неизвестны, но равны;
-число степеней свободы (df);
- уровень значимости p. Если рассчитанный уровень значимости р< 0.05 можно утверждать, что различия существуют, причем выявленные различия отражают объективную тенденцию, в противном случае выявленные различия не являются статистически значимыми и, следовательно, их не следует рассматривать как объективную тенденцию, отражающую соотношение значений исследуемого показателя в сравниваемых группах.
- среднеквадратичекое отклонение значений исследуемого показателя в первой группе (Std. Dev. Group1);
- среднеквадратичекое отклонение значений исследуемого показателя во второй группе (Std. Dev. Group2);
- рассчитанное значение статистики Фишера (F-ratio variances);
- уровень значимости
V. Представление результатов выполнения работы.
Отчет о проделанной работе должен включать следующие результаты:
1. Графическое представление распределения значений исследуемого показателя и их аппроксимация нормальным распределением. Графическое представление распределений должно включать совмещенное отображение как функции плотности распределения вероятностей, так и функции распределения вероятностей.
3. Таблица результатов анализа различий исследуемых групп пациентов по рассматриваемому показателю на основании критерия Стьюдента.
4. Интерпретация полученных результатов и вывод по работе
Дата добавления: 2020-12-22; просмотров: 35; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!