Задание на лабораторную работу №1.
Разработать структуру данных указанного назначения, довести до таблиц и привести ее в третью нормальную форму. Следует очень внимательно подойти к этому вопросу: созданная база данных будет использоваться в последующих лабораторных работах. Воплотить созданную структуру в виде таблиц на сервере.
Разработать структуру индексов, которая должна подходить к созданной структуре базы данных, ускоряя ее работу при значительной нагрузке на базу данных, создать индексы поиска по обеим ключевым столбцам таблицы связи.
Создать диаграмму, отражающую структуру созданной вами базы данных и ее связи.
Использовать имя базы данных, совпадающее с номером группы. Имена таблиц и диаграмм должны иметь вид: _x_yy_name, где x – номер подгруппы, yy – номер задания, name – присвоенный таблице студентом идентификатор. Помните, что вы все работаете на одном сервере и можете испортить друг другу работу, если случайно назовете ваши ресурсы одинаково! Имена индексов могут быть любыми, ибо относятся только к той таблице, в которой они созданы.
Сдать отчет и ответить на вопросы преподавателя.
Содержание отчета:
Дата занятия, ФИО и номер группы, подгруппы и рабочего места студента.
Полученное задание (номер и текст задания).
Разработанная структура данных с указанием логических связей и типов полей таблиц (диаграмма базы данных), перечень индексов.
Варианты заданий (назначение базы данных)
|
|
|
Следует отметить, что при правильной реализации структуры данных и приведении ее в третью нормальную форму должно получиться три или больше таблиц, одна из которых является связующей. Две другие таблицы должны содержать какие-то дополнительные сведения о хранимых объектах, помимо только названия. Количество элементов в таблицах не следует ограничивать искусственно.
1. База данных поставок различных товаров от множества поставщиков. Одна конкретная поставка содержит один или несколько товаров в каких-то количествах.
2. База данных наличия некоторого множества товаров на нескольких складах.
3. База данных, отражающая текущее состояние прайс-листа на конкретную дату в конкретной точке продажи. Цены различных позиций могут меняться в разное время. Структура должна обеспечивать возможность просмотра цен на любую дату в прошлом.
4. База данных студентов и экзаменов. Студент может сдавать один и тот же экзамен несколько раз, получая каждый раз оценку. Преподавателя учитывать не следует.
5. База данных музыкальных произведений, хранимых в фонотеке. На одном и том же экземпляре носителя (диске, ленте) может быть несколько произведений, одно и то же произведение может быть дублировано на разных носителях. Произведение всегда помещается на носитель целиком.
|
|
|
6. База данных авторов и написанных ими книг. Будем полагать, что у каждой книги автор один, но один и тот же автор мог написать несколько книг, издаваемых в разных издательствах.
7. База данных выписываемых счетов на товар. Счет имеет некоторый порядковый номер и выставляется на конкретного контрагента, указывается перечень товаров (предметы счета), их количеств и цен.
8. База данных валют и их курсов в разных пунктах обмена с выборкой информации на любую дату. Курсы могут меняться независимо.
9. База данных абонентов телефонной сети и произведенных ими междугородных переговоров с различными населенными пунктами (по кодам).
10. База данных сотрудников предприятия и произведенных им денежных выплат. Выплаты различным сотрудникам могут производиться в различное время и по различным типовым поводам.
11. База данных материальных средств и сотрудников, за которыми они закреплены.
Лабораторная работа №2. SQL-запросы и представления. Организация транзакций.
Любое взаимодействие с SQL-сервером производится посредством запросов, даже если это явно не показано. Например, программа Enterprise Manager, известная вам по прошлой работе, взаимодействует с сервером именно таким образом. По существу, она, да и все прочие приложения являются лишь локальным интерфейсом при клиент-серверном взаимодействии.
|
|
|
В данной работе вам предстоит познакомиться с непосредственным взаимодействием с сервером посредством программы SQL Query Analyzer. Кроме того, будет рассмотрено создание индексов таблиц.
Все запросы, как уже было сказано, проводятся на языке SQL. В данной работе будут рассмотрены не все аспекты взаимодействия, а только добавление данных в таблицу, изменение данных, удаление записей и выборка данных.
Загрузите программу SQL Query Analyzer. В начале работы вам будет предложено инициировать соединение с сервером.
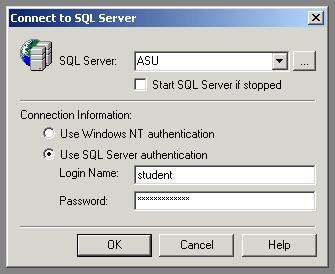
Произведя соединение, вы получаете в свое расположение окно, в котором вы можете набирать различные предложения SQL, которые будут исполнены последовательно после нажатия соответствующей кнопки на панели инструментов либо клавиши F5 на клавиатуре.
Перед операцией с базами данных ее следует сделать активной предложением USE.
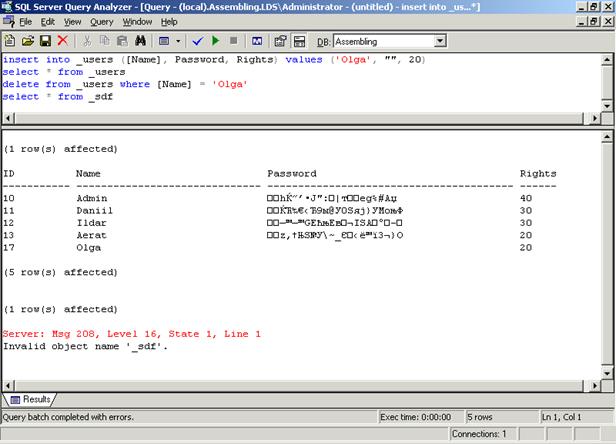
Результаты будут показаны в нижней половине окна, если какие-то предложения возвращали выборки данных, данные выборки будут показаны последовательно друг за другом. В нижеследующем примере сначала добавляется новая строка (предложение INSERT) в таблицу _users, сервер отвечает, что строка добавлена (1 row(s) affected), затем предложением SELECT формируется выборка из таблицы, которая показана ниже. Выборка содержит пять строк, о чем сказано после блока данных. После этого предложением DELETE строка удаляется (сервер снова сообщает «1 row(s) affected»).
|
|
|
Следующим предложением производится попытка выборки данных из несуществующей таблицы, на что сервер возвращает сообщение об ошибке: указан несуществующий объект. После этого выполнение сценария прекращается, т.е. следующие команды (если бы они были) не были бы обработаны.
Синтаксис предложений SQL
Всякое предложение SQL состоит из ключевого слова и параметров, определяющих функционирование сервера при его выполнении. SQL содержит значительное количество команд, позволяющих в полной мере управлять как самим сервером, так и хранимыми на нем данными и всем, что к ним относится (метаданные, пользователи и их права). Мы рассмотрим лишь основные команды, без которых невозможна работа с сервером.
Следует отметить, что SQL сервер позволяет использовать пробелы и зарезервированные слова в идентификаторах. Для этого идентификаторы должны быть заключены в квадратные скобки в конечном запросе. При описании синтаксиса квадратные скобки используются для указания необязательных конструкций. Известна проблема с идентификаторами, начинающимися на русскую букву «а».
INSERT
Предложение INSERT предназначено для добавления полей в таблицы базы данных.
INSERT INTO <таблица> [(<поле>[,...])
VALUES ( DEFAULT | NULL | <выражение>[,...] ) | DEFAULT VALUES
Указываются поля таблицы, подлежащие заполнению и значения в этих полях. Вместо указания значения можно указать предложение NULL (в поле будет вставлено пустое значение) либо DEFAULT (будет вставлено значение по умолчанию, если оно задано в структуре таблицы). Здесь приведен один из вариантов данного предложения.
SELECT
Предложение SELECT предназначено для выборки данных. Кроме того, это предложение может использоваться для иных целей – например, в теле хранимых процедур присвоение значения переменной может быть осуществлено только с использованием данной инструкции. Синтаксис предложения SELECT приводится ниже. Следует отметить, что это отнюдь не полный перечень возможностей, а только часть.
SELECT [ ALL | DISTINCT ]
[{TOP n [PERCENT]]
<список_выборки>
[INTO <новая_таблица>]
[FROM {<источник>} [,...n]]
[WHERE <условие_отбора>]
[GROUP BY <условие_группировки> [,...n]
[ORDER BY <условие_сортировки> [ASC | DESC]]
Где <список_выборки> ::= {* | { <столбец> | <выражение>} [[AS] <алиас_столбца>]}
Параметры инструкции SELECT:
ALL означает, что следует вернуть все записи, отвечающие условиям выборки. Это поведение по умолчанию.
DISTINCT означает, что следует вернуть только различные строки запроса. Если в выборке есть одинаковые строки, лишние дубликаты будут удалены.
TOP n [PERCENT] указывает, что следует вернуть только первые n записей выборки. Если указано слово PERCENT, то будут возвращены только n процентов всей выборки.
* (звездочка) означает, что следует вернуть все столбцы в том порядке, в каком они содержатся в источнике.
Источник – имя таблицы активной базы данных либо имя представления. Может быть указан алиас (псевдоним) таблицы. Источников может быть несколько.
Столбец в списке выборки может содержать и имя таблицы, чтобы избежать путаницы при обращении к одинаково названным столбцам разных таблиц. Например, _users.ID означает столбец ID таблицы _users. Алиас столбца предназначен для переименования столбца в рамках данной выборки, с той же целью. Далее мы будем полагать, что везде, где требуется указать стобец, может быть использован его псевдоним.
Новая_таблица указывает имя новой таблицы, которая будет создана для помещения в нее результатов обработки запроса.
Условие_отбора представляет собой собственно инструмент формирования выборки из всего множества данных в данном источнике. Как правило, это оператор сравнения. Подробнее данный оператор рассмотрен в лекционном курсе. См. также список операторов в лабораторной работе №4 в этом же пособии.
Задание условия_группировки позволяет сгруппировать одинаковые строки выборки. Как правило, это имя столбца в выборке. Поля, имеющие типы text, ntext, image, bit не могут быть использованы.
Условие_сортировки, будучи задано, упорядочивает выборку по указанному выражению. Как правило, указывается столбец выборки. Можно указать несколько столбцов. Столбцы, имеющие тип ntext, text, image не могут быть указаны. Параметр ASC требует сортировать выборку в возрастающем (неубывающем) порядке, DESC в обратном. Пустые значения воспринимаются как имеющие минимальный вес.
Примеры:
SELECT * FROM _users
Выборка всей таблицы _users. Столбцы будут возвращены в том порядке, в каком они присутствуют в таблице.
SELECT [ID], [Name] FROM _users WHERE [Name] = ‘Oleg’
Выборка полей ID, Name из таблицы _users в той ее части, где поле Name имеет значение ‘Oleg’.
SELECT * FROM goods WHERE [Date] > 13.10.1999 ORDER BY [Name]
Выборка всех полей из таблицы goods. Выбираются записи, где значение поля Date содержит значения, большие 13 декабря 1999 года. Выборка упорядочивается по полю Name.
SELECT * FROM [студенты] WHERE [номер группы] = 4512 GROUP BY [рейтинг]
Из таблицы студенты выбираются все студенты, имеющие номер группы 4512 и выборка группируется по рейтингу.
Наряду с выборкой, с базой данных приходится производить и такие операции как добавление, удаление и изменение данных.
DELETE
DELETE FROM <источник> WHERE <условие_отбора>
Производится удаление записей из указанного источника (таблицы), условие отбора аналогично предложению SELECT.
Примеры:
DELETE FROM _users WHERE [ID] = 2387
Из таблицы _users удаляются строки, имеющие значение 2387 в поле ID.
DELETE FROM [студенты] WHERE [студенты].[имя] = (SELECT [имя], [оценка] FROM [экзамены].[оценка] = 2)
Из таблицы студенты удаляются записи о тех студентах, для которых оценка в таблице экзамены равна двойке.
Внимание! В случае исполнения конструкции типа «DELETE FROM _table» из указанной таблицы будут удалены все записи!
UPDATE
UPDATE <источник> SET <список_присвоений> WHERE <условие_отбора>
Производится изменение значений полей источника в соответствии со списком присвоений. Условие отбора то же.
Примеры:
UPDATE _users SET [Name] = ‘David’ WHERE [Name] = ‘Oleg’
Пользователь имя Oleg в таблице _users заменяется на David.
UPDATE [студенты] SET [имя] = ‘Иванова А.Б.’ WHERE [имя] = ‘Петрова А.Б.’
Студентка Иванова А.Б. в таблице студенты переименовывается в Петрову.
UPDATE [студенты] SET [на отчисление] = TRUE WHERE [имя] = (SELECT [имя], [оценка] FROM [экзамены] WHERE [оценка] = 2)
Для студентов, сдавших экзамен на двойку, проставляется флаг на отчисление (значение булевского поля на отчисление меняется на значение Истина).
Представления («Views»)
Предложение SELECT с указанием нескольких таблиц позволяет производить любую выборку данных. Вместе с тем, существует еще один механизм, позволяющий выбирать связанную информацию из нескольких таблиц одновременно. Предложение SQL SELECT позволяет задействовать несколько таблиц, увязав их в достаточно сложную конструкцию и получить необходимые данные в требуемой форме. Вместе с тем, сложная инструкция SELECT выполняется достаточно долго, ибо интерпретируется сервером «на ходу», причем интерпретируется заранее. Повысить скорость выполнения такого рода операций, одновременно улучшив их читабельность и упростив отладку, позволяет организация представлений.
Представление – это своего рода источник данных, могущий быть употребленным в инструкции SQL SELECT. Само представление выбирает данные из таблиц либо иных представлений. Поскольку представление хранится на сервере, последний имеет возможность предкомпиляции представления, что повышает скорость его обработки.
Впоследствии, создав представление, пользователь может использовать его в конструкции SELECT в качестве источника данных.
Для создания представления следует выбрать пункт «Views» конкретной базы данных в левом окне Enterpise Manager и вызвать правой кнопкой мыши конекстное меню.
Выбрав пункт «New view», пользователь попадает в окно конструирования представления:
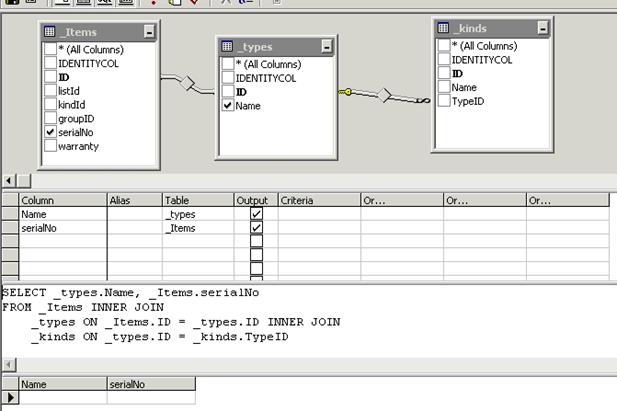
Окно состоит из четырех основных частей: в верхней части показаны используемые в представлении таблицы, далее перечислены все поля представления (область полей), затем идет сам текст представления (область текста) в виде SQL-предложения и, наконец, результат исполнения представления (область данных).
Вызывая контекстное меню в области таблиц, пользователь выбирает пункт «Add table» (добавить таблицу) и в появившемся окне выбирает необходимые таблицы и представления, которые будут использованы в качестве источника данных для конструируемого представления. При добавлении сервер старает «угадать» связь таблиц между собой, что ему не всегда удается. Перетаскивая левой кнопкой мыши поля из одной таблицы в другую, пользователь устанавливает связь таблиц по определенному полю. Сама связь может редактироваться. Значок ключа означает связь «к одному», значок бесконечности – связь «ко многим». Сам вид ромбика на связи показывает тип связи и то, все ли поля таблицы добавлены в результат. Проставляя «галочки» на полях таблиц, пользователь требует включить данное поле в возвращаемую выборку.
В области полей перечислены все добавляемые поля и их имена (алиасы) в формируемой выборке. Если поля с одинаковыми именами из разных таблиц помещены в выборку, сервер попытается переименовать одно из них. В любом случае, пользователь может задать имена полей в возвращаемой выборке. «Галочка» в столбце «Add to output» (добавить в результат) требует включить поле в возвращаемый результат выборки (поле может использоваться только для отбора значений без возвращения его значений пользователю). Поля «Criteria» задают условие отбора записей по значению в данном поле. Можно указать конструкции типа «>10», «=15», «=имя_поля» и т.д.
В области текста сервер показывает текст представления в виде SQL предложения. Конструирование текста происходит автоматически, но пользователь может сделать это вручную. Содержимое остальных областей будет изменено автоматически.
В области данных пользователь может просмотреть результат исполнения написанного представления с «живыми» данными из таблиц.
Организация транзакций
При работе с базой данных возможны сбои, особенно при подсоединении удаленного клиента. Поскольку семантическая структура базы данных совершенно не отслеживается сервером, при сбоях могут иметь место такие моменты, когда база данных, будучи формально корректна с точки зрения СУБД, теряет логические связи с точки зрения клиента (например, ссылка на несуществующий товар в складской бухгалтерии). Чтобы этого избежать, существует механизм организации транзакций.
Транзакция есть совокупность действий над базой данных, которая выполняется только целиком, либо же происходит откат на начальное состояние в случае невозможности полного выполнения транзакции. Транзакция переводит одно согласованное состояние базы данных в другое. Пользователь может искусственно оборвать транзакцию, если сочтет это нужным. Сервер ведет специальный журнал транзакций, который используется при восстановлении после сбоев сервера.
Транзакция имеет следующие свойства:
1. Неделимость (атомарность). Как уже было сказано, транзакция выполняется только полностью, частичное выполнение транзакции невозможно.
2. Долговечность. После выполнения транзакции результат ее работы фиксируется в базе данных на сколь угодно длительное время.
3. Согласованность. Формальная целостность базы данных на уровне СУБД соблюдается. За сохранением же семантической целостности должен следить сам пользователь, осуществляющий изменение базы данных.
4. Изоляция. Различные транзакции, будучи запущены одновременно, не влияэт друг на друга. Выполнение одной транзакции полностью скрыто от всех других.
5. Восстановимость. До тех пор пока транзакция не завершена, возможен полный откат на ее начало – на согласованное состояние базы данных, имевшее место перед запуском транзакции.
Возможно определение контрольных точек внутри транзакции, после которых можно частично зафиксировать результаты выполнения транзакии и к которым возможен возврат в пределах транзакции. Несмотря на наличие контрольных точек, транзакция все равно должна быть явным образом завершена предложением COMMIT для сохранения сделанных в ней изменений.
Выполнение транзакций в SQL
Для запуска транзакции служит инструкция SQL BEGIN TRANSACTION, для завершения транзакции следует исполнить предложение COMMIT, для отката транзакции вызывают предложение ROLLBACK. Транзакции могут вкладываться друг в друга, однако нельзя из транзакции текущего уровня завершить транзакцию предыдущего уровня. Т.е., невозможна такая последовательность SQL-команд:
BEGIN TRANSACTION fistTrans
DELETE FROM dbUsers WHERE sName = ‘Daniil’
BEGIN TRANSACTION secondTrans
DELETE FROM dbItems WHERE nLocation = 82794
COMMIT TRANSACTION firstTrans ‘ Здесь ошибка!
COMMIT TRANSACTION secondTrans ‘ Это должно быть раньше!
Формат предложений:
BEGIN TRAN[SACTION] [имя | @переменная]
СУБД начинает транзакцию, фиксируя состояние базы данных на момент выполнения данного предложения. Имя – имя, присвоенное данной транзакции. Имя должно быть корректным идентификатором в языке SQL. Следует использовать только внутри пары предложений BEGIN..COMMIT или BEGIN..ROLLBACK. @переменная – определенная пользователем переменная, содержащая действительное имя транзакции. Тип переменной может быть char, varchar, nchar, nvarchar.
COMMIT [TRAN[SACTION] [имя | @переменная]]
Аргументы те же, что и в предложении BEGIN TRANSACTION. Предложение завершает транзакцию, фиксируя в базе данных все сделанные транзакцией изменения.
COMMIT [WORK]
То же самое, но предложение COMMIT TRANSACTION принимает имя транзакции в качестве параметра. Данное предложение в форме COMMIT либо COMMIT WORK отвечает стандарту SQL’92.
SAVE TRAN[SACTION] {имя | @переменная}
Данное предложение определяет контрольную точку в пределах транзакции. Параметры аналогичны параметрам предложения BEGIN TRANSACTION, но служат для именования данной контрольной точки. Впоследствии возможен откат состояния как на начало транзакции, так и на любую из пройденных контрольных точек.
ROLLBACK [TRAN[SACTION] [имя | @переменная]]
Предложение завершает транзакцию с откатом состояния базы данных на начало транзакции либо к заданной контрольной точке, в зависимости от того, что указано в качестве параметра. Данное предложение не передает никуда управления (при исполнении в рамках хранимой процедуры), а только производит восстановление состояния базы данных.
ROLLBACK [WORK]
Предложение завершает транзакцию с откатом проделанных изменений. Данное предложение в форме ROLLBACK либо ROLLBACK WORK отвечает стандарту SQL’92.
Транзакции обычно используются в том случае, когда приложению необходимо выполнить некоторый набор действий над базой данных, причем семантическое согласование базы данных может быть нарушено в том случае, если указанный набор действий не будет выполнен полностью.
Дата добавления: 2019-11-16; просмотров: 175; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!