Практическая работа № 3. Вставка, удаление и обновление данных.
ПРАКТИЧЕСКИЕ РАБОТЫ
Практическая работа № 1
Проектирование базы данных с использованием ER-технологии
Особенности диалекта SQL в СУБД MySQL рассмотрим на примере учебной базы данных book Интернет-магазина, торгующего компьютерной литературой. В базе данных должна поддерживаться следующая информация:
· тематические каталоги, по которым сгруппированы книги;
· предлагаемые книги (название, автор, год издания, цена, имеющееся на складе количество);
· зарегистрированные покупатели (имя, отчество, фамилия, телефон, адрес электронной почты, статус – авторизованный, неавторизованный, заблокированный, активный с хорошей кредитной историей);
· покупки, совершенные в магазине (время совершения покупки, число приобретенных экземпляров книги).
Логическая модель данных предметной области в стандарте IDEF1X представлена на рис. 1. Выделены сущности КАТАЛОГ, КНИГА, КЛИЕНТ, ЗАКАЗ, между которыми установлены неидентифицирующие связи мощностью oдин-ко-многим, определенные спецификой предметной области.
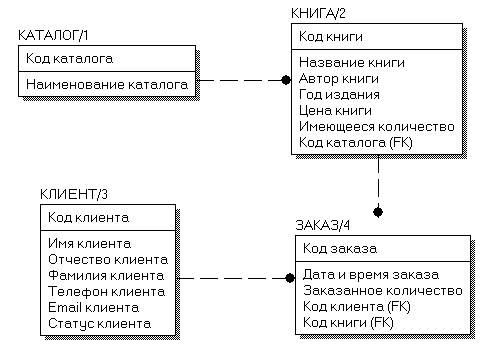
Рис. 1. Логическая модель данных предметной области
Физическая модель данных предметной области в стандарте IDEF1X для целевой СУБД MySQL представлена на рис. 2.
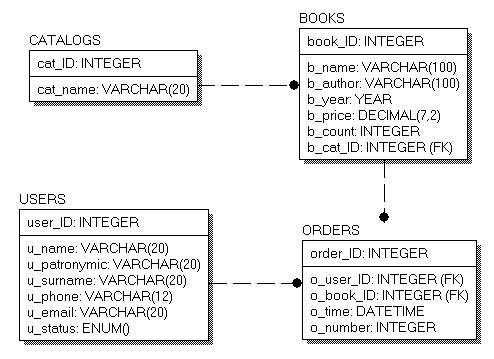
Рис. 2. Физическая модель предметной области
База данных book состоит из четырех таблиц:
· catalogs – список торговых каталогов;
· books – список предлагаемых книг;
· users – список зарегистрированных пользователей магазина;
|
|
|
· orders – список заказов (осуществленных сделок).
Таблица catalogs состоит из двух полей:
· cat_ID – уникальный код каталога;
· cat_name – имя каталога.
Оба поля должны быть снабжены атрибутом not null, поскольку неопределенное значение для них недопустимо.
Таблица books состоит из семи полей:
· book_ID – уникальный код книги;
· b_name – название книги;
· b_author – автор книги;
· b_year – год издания;
· b_price – цена книги;
· b_count – количество книг на складе;
· b_cat_ID – код каталога из таблицы catalogs.
Цена книги b_price и количество экземпляров на складе b_count могут иметь атрибут null. На момент доставки часто неизвестны количество товара и его цена, но отразить факт наличия товара в прайс-листе необходимо.
Поле b_cat_ID устанавливает связь между таблицами catalogs и books. Это поле должно быть объявлено как внешний ключ (FK)с правилом каскадного удаления и обновления. Обновление таблицы catalogs вызовет автоматическое обновление таблицы books. Удаление каталога в таблице catalogs приведет к автоматическому удалению всех записей в таблице books, соответствующих каталогу.
Таблица users состоит из семи полей:
· user_ID – уникальный код покупателя;
· u_name – имя покупателя;
· u_patronymic – отчество покупателя;
|
|
|
· u_surname – фамилия покупателя;
· u_phone – телефон покупателя (если имеется);
· u_email – e-mail покупателя (если имеется);
· u_status – статус покупателя.
Статус покупателя представлен полем типа enum, которое может принимать одно из четырех значений:
· active – авторизованный покупатель, который может осуществлять покупки через Интернет;
· passive – неавторизованный покупатель (значение по умолчанию), который осуществил процедуру регистрации, но не подтвердил ее и пока не может осуществлять покупки через Интернет, однако ему доступны каталоги для просмотра;
· lock – заблокированный покупатель, не может осуществлять покупки и просматривать каталоги магазина;
· gold – активный покупатель с хорошей кредитной историей, которому предоставляется скидка при следующих покупках в магазине.
Поля u_phone и u_email могут быть снабжены атрибутом null. Остальные поля должны получить атрибут not null.
Таблица orders включает пять полей:
· order_ID – уникальный номер сделки;
· o_user_ID – номер пользователя из таблицы users;
· o_book_ID – номер товарной позиции из таблицы books;
· o_time – время совершения сделки;
· o_number – число приобретенных товаров.
Поля таблицы orders должны быть снабжены атрибутом not null, т. к. при совершении покупки вся информация должна быть занесена в таблицу.
|
|
|
В таблице orders устанавливается связь с таблицами users (за счет поля o_user_id) и books (за счет поля o_book_id). Эти поля объявлены как внешние ключи (FK)с правилом каскадного удаления и обновления. Обновление таблиц users и books приведет к автоматическому обновлению таблицы orders. Удаление любого пользователя в таблице users приведет к автоматическому удалению всех записей в таблице orders, соответствующих этому пользователю.
Практическая работа № 2
Создание и связывание таблиц базы данных в среде MySQL
Рассмотрим следующие вопросы:
· создание и выбор базы данных;
· создание таблиц;
· столбцы и типы данных в MySQL;
· создание индексов;
· удаление таблиц, индексов и баз данных;
· изменение структуры таблиц.
Базы данных, таблицы и индексы легко создаются в рамках графического интерфейса MySQL, но мы будем использовать монитор MySQL (клиент командной строки), чтобы лучше понять структуру БД, таблиц и индексов.
Чувствительность к регистру и идентификаторы.
· Имена БД подчиняются тем же правилам зависимости от регистра символов, каким следуют каталоги операционной системы. Имена таблиц следуют тем же правилам, что и имена файлов. Все остальное не зависит от регистра.
|
|
|
· Все идентификаторы, кроме имен псевдонимов, могут содержать до 64 символов. Имена псевдонимов могут иметь до 255 символов.
· Идентификаторы могут содержать любые допустимые символы, но имена баз данных не могут содержать символы /, \ и . , а имена таблиц – символы . и /.
· Зарезервированные слова можно использовать для идентификаторов, если заключить их в кавычки.
Комментарий в SQL. Начинается с двух дефисов (--), за которыми должен следовать пробел. Кроме того, MySQL содержит ряд собственных комментариев. Shell-комментарий # действует аналогично – все, что расположено правее его, является текстом комментария. С-комментарий /* */ является многострочным – комментарий начинается с /* и заканчивается, когда встретится завершение */.
Создание и выбор базы данных. Осуществляется с помощью оператора
create database имя_базы_данных;
Убедиться в том, что оператор выполнил задачу, можно с помощью оператора
show databases;
Теперь имеется пустая БД, ожидающая создания таблиц. Прежде чем работать с БД, необходимо выбрать эту БД с помощью оператора
use имя_базы_данных;
Теперь все действия по умолчанию будут применяться именно к этой БД.
Создание таблиц.Используется оператор CREATE TABLE, который в общем виде выглядит следующим образом:
create [temporary] table [if not exists]
имя_таблицы (определение таблицы)
[type=тип_таблицы];
Ключевое слово TEMPORARY используется для создания таблиц, которые будут существовать только в текущем сеансе работы с БД и будут автоматически удалены, когда сеанс завершится.
При использовании выражения IF NOT EXISTS таблица будет создана только в том случае, если еще нет таблицы с указанным именем.
Создать таблицу с такой же схемой, как у существующей, позволяет команда
create [temporary] table [if not exists]
имя_таблицы LIKE имя_старой_таблицы;
После имени таблицы в скобках объявляются имена столбцов, их типы и другая информация. В определение столбца можно добавить следующие описания.
· Объявить для любого столбца NOT NULL или NULL (столбцу запрещено или не запрещено содержать значения NULL). По умолчанию – NULL.
· Объявить для столбца значение по умолчанию, используя ключевое слово DEFAULT, за которым должно следовать значение по умолчанию.
· Использовать ключевое слово AUTO_INCREMENT, чтобы генерировать порядковый номер. Автоматически генерируемое значение будет на единицу большим, чем наибольшее значение в таблице. Первая введенная строка будет иметь порядковый номер 1. В таблице можно иметь не более одного столбца AUTO_INCREMENT, и он должен индексироваться.
· Объявить столбец первичным ключом таблицы с помощью выражения PRIMARY KEY.
· Объявить столбец внешним ключом, используя выражение FOREIGN KEY,с ссылкой на соответствующую таблицу с помощью выражения REFERENCES.
· Индексировать столбец с помощью слов INDEX или KEY (синонимы). Такие столбцы не обязательно должны содержать уникальные значения.
· Индексировать столбец с помощью слова UNIQUE, которое используется для указания того, что столбец должен содержать уникальные значения.
· Создать полнотекстовые индексы на основе столбцов типа TEXT, CHAR или VARCHAR с помощью слова FULLTEXT (только с таблицами MyISAM).
После закрывающей скобки можно указать тип таблицы:
· MyISAM – таблицы этого типа являются «родными» для MySQL, работают очень быстро и поддерживают полнотекстовую индексацию;
· InnoDB – ACID-совместимый механизм хранения, поддерживающий транзакции, внешние ключи, каскадное удаление и блокировки на уровне строк;
· BDB (Berkeley DB) – является механизмом хранения, который обеспечивает поддержку транзакций и блокировки на уровне страниц;
· MEMORY (HEAP) – таблицы целиком хранятся в оперативной памяти и никогда не записываются на диск, поэтому работают очень быстро, но ограничены в размерах и не допускают возможности восстановления в случае отказа системы;
· MERGE – тип позволяет объединить несколько таблиц MyISAM с одной структурой, чтобы к ним можно было направлять запросы как к одной таблице;
· NDB Cluster – тип предназначен для организации кластеровMySQL, когда таблицы распределены между несколькими компьютерами, объединенными в сеть;
· ARCHIVE – тип введен для хранения большого объема данных в сжатом формате; таблицы поддерживают только два SQL-оператора: INSERT и SELECT, причем оператор SELECT выполняется по методу полного сканирования таблицы;
· CSV – формат представляет собой обычный текстовый фал, записи в котором хранятся в строках, а поля разделены точкой с запятой (широко распространен в компьютерном мире, любая программа, поддерживающая CSV-формат, может открыть такой файл);
· FEDERATED – тип позволяет хранить данные в таблицах на другой машине сети (при создании таблицы в локальной директории создается только файл определения структуры таблицы, а все данные хранятся на удаленной машине).
MySQL поддерживает следующие типы данных, допустимые для столбцов:
· числовые;
· строковые;
· календарные;
· null – специальный тип, обозначающий отсутствие информации.
Числовые типы используются для хранения чисел и представляют два подтипа:
· точные числовые типы;
· приближенные числовые типы.
К точным числовым типам (табл. 1) относятся целый тип INTEGER и его вариации, а также вещественный тип decimal (синонимы numeric и dec). Последний используется для представления денежных данных.
Числовые типы могут характеризоваться максимальной длиной М. Для типа decimal параметр м задает число символов для отображения всего числа, a d – для его дробной части. Например: b_price DECIMAL (5, 2). Цифра 5 определяет общее число символов под число, а цифра 2 – количество знаков после запятой (интервал величин от –99.99 до 99.99). Можно не использовать параметры вообще, указать только общую длину или указать длину и число десятичных разрядов.
Объявления точных числовых типов можно завершать ключевыми словами UNSIGNED и (или) ZEROFILL. Ключевое слово UNSIGNED указывает, что столбец содержит только положительные числа или нули. Ключевое слово ZEROFILL означает, что число будет отображаться с ведущими нулями.
Таблица 1
| Тип | Объем памяти | Диапазон |
| TINYINT (M) TINYINT unsigned | 1 байт | от -128 до 127 (от -27 до 27-1) от 0 до 255 (от 0 до 28-1) |
| SMALLINT (M) SMALLINT unsigned | 2 байта | от -32 768 до 32 767 (от -215 до 215-1) от 0 до 65 535 (от 0 до 216-1) |
| MEDIUMINT (M) MEDIUMINT unsigned | 3 байта | от -8 388 608 до 8 388 607 (от -223 до 223-1) от 0 до 16 777 215 (от 0 до 224-1) |
| INT (INTEGER) (M) INT unsigned | 4 байта | от -2 147 683 648 до 2 147 683 647 (от -231 до 231-1) от 0 до 4 294 967 295 (от 0 до 232-1) |
| BIGINT (M) BIGINT unsigned | 8 байт | (от-263 до263-1) (от 0 до 264 -1) |
| BIT (M) | (М+7)/8 байт | От 1 до 64 битов, в зависимости от значения М |
| BOOL, BOOLEAN | 1 байт | 0 (false) либо 1 (true) |
| DECIMAL (M, D), NUMERUC (M, D) | М + 2 байта | Повышенная точность, зависит от параметров М и D |
К приближенным числовым типам (табл. 2) относятся:
· FLOAT – представление чисел с плавающей запятой с обычной точностью;
· DOUBLE – представление чисел с плавающей запятой с двойной точностью.
Таблица 2
| Тип | Объем памяти | Диапазон |
| FLOAT (М, D) | 4 байта | Минимальное по модулю значение 1.175494351*10-39 Максимальное по модулю значение 3.402823466*1038 |
| DOUBLE (M, D), REAL (M,D), DOUBLE PRECISION (M,D) | 8 байт | Минимальное по модулю значение 2.2250738585072014*10-308 Максимальное по модулю значение 1.797693134862315*10308 |
Числовые типы с плавающей точкой также могут иметь параметр unsigned. Атрибут предотвращает хранение в столбце отрицательных величин, но максимальный интервал величин столбца остается прежним.
Приближенные числовые данные могут задаваться в обычной форме (например, 45.67) и в форме с плавающей точкой (например, 5.456Е-02 или 4.674Е+04).
Текстовые типы и строки (табл. 3):
· CHAR – хранение строк фиксированной длины;
· VARCHAR – хранение строк переменной длины;
· TEXT, BLOB и их вариации – хранение больших фрагментов текста;
· ENUM и SET – хранение значений из заданного списка.
Таблица 3
| Тип | Объем памяти | Максимальный размер |
| CHAR(M) | М символов | М символов |
| VARCHAR(M) | L+1 символов | М символов |
| TINYBLOB, TINYTEXT | L+1 символов | 28-1 символов |
| BLOB, TEXT | L+2 символов | 216-1 символов |
| MEDIUMBLOB, MEDIUMTEXT | L+3 символов | 224-1 символов |
| LONGBLOB, LONGTEXT | L+4 символов | 232-1 символов |
| ENUM('value 1', 'value2 ', ...) | 1 или 2 байта | 65 535 элементов |
| SET('value 1', 'value2', ...) | 1, 2, 3, 4 или 8 байт | 64 элемента |
Здесь l – длина хранимой в ячейке строки, а приплюсованные к l байты – накладные расходы для хранения длины строки.
Для строк varchar требуется количество символов, равное длине строки плюс 1 байт, тогда как тип char(m), независимо от длины строки, использует для ее хранения все м символов. Тип char обрабатывается эффективнее переменных типов. Нельзя смешивать в таблице столбцы charи varchar. Если есть столбец переменной длины, все столбцы типа char будут приведены к типу varchar.
Типы blob и text аналогичны и отличаются в деталях. При выполнении операций над столбцами типа text учитывается кодировка, а типа blob – нет. Тип text используется для хранения больших объемов текста, тип blob – для больших двоичных объектов (электронные документы, изображения, звук). Основное отличие text от char и varchar – поддержка полнотекстового поиска.
Строки типов данных enum и set принимают значения из заданного списка. Значение типа enum должно содержать точно одно значение из указанного множества, тогда как столбцы set могут содержать любой или все элементы заданного множества одновременно. Для типа set (как и для enum) при объявлении задается список возможных значений, но ячейка может принимать любое значение из списка, а пустая строка означает, что ни один из элементов списка не выбран.
Типы enum и set задаются списком строк, но во внутреннем представлении элементы множеств сохраняются в виде чисел. Элементы типа enumнумеруются последовательно, начиная с 1. Под столбец может отводиться 1 байт (до 256 элементов в списке) или 2 байта (от 257 до 65536 элементов в списке). Элементы типа set обрабатываются как биты, размер типа определяется числом элементов в списке: 1 байт (от 1 до 8 элементов), 2 байта (от 9 до 16 элементов), 3 байта (от 17 до 24 элементов), 4 байта (от 25 до 32 элементов) и 8 байт (от 33 до 64 элементов).
Календарные типы данных (табл. 4):
· Date – для хранения даты (формат YYYY-MM-DD для дат вида 2009-10-15 и формат YY-MM-DD для дат вида 09-10-15);
· Time – для хранения времени суток (формат hh:mm:ss, где hh – часы, mm – минуты, ss – секунды, например, 10:48:56);
· Datetime– для представления и даты, и времени суток;
· Timestamp – если в соответствующем столбце строки не указать конкретное значение или NULL, там будет записано время, когда соответствующая строка была создана или в последний раз изменена (в формате DATETIME);
· Year – позволяет хранить только год.
Таблица 4
| Тип | Объем памяти | Диапазон |
| DATE | 3 байта | от '1000-01-01' до '9999-12-31' |
| TIME | 3 байта | от '-828:59:59' до '828:59:59' |
| DATATIME | 8 байт | от '1000-01-01 00:00:00' до '9999-12-31 00:00:00' |
| TIMESTAMP (M) | 4 байта | от '1970-01-01 00:00:00' до '2038-12-31 59:59:59' |
| YEAR(2) YEAR(4) | 1 байт | формат YY, диапазон – от 1970 до 2069 формат YYYY, диапазон – от 1901 до 2155 |
Дни, месяцы, часы, минуты и секунды можно записывать как с ведущим нулем, так и без него. Например, все следующие записи идентичны:
'2009-04-06 02:04:08' '2009-4-06 02:04:08' '2009-4-6 02:04:08'
'2009-4-6 2:04:08' '2009-4-6 2:4:08' '2009-4-6 2:4:8'
В качестве разделителя между годами, месяцами, днями, часами, минутами, секундами может выступать любой символ, отличный от цифры. Так, следующие значения идентичны:
'09-12-31 11:30:45' '09.12.31 11+30+45' '09/12/31 11*30*45'
При указании времени после секунд через точку можно указать микросекунды, т. е. использовать расширенный формат вида hh:mm:ss.ffffff, например '10:25:14.000001'. Кроме того, можно использовать краткие форматы НН:ММ и НН (вместо пропущенных величин будут подставлены нулевые значения).
Если время задается в недопустимом формате, то в поле записывается нулевое значение. Нулевое значение присваивается полям временного типа по умолчанию, когда им не присваивается инициирующее значение (табл. 5).
Таблица 5
| Тип | Нулевое значение |
| DATE | '0000-00-00' |
| TIME | '00:00:00' |
| DATATIME | '0000-00-00 00:00:00' |
| TIMESTAMP | |
| YEAR |
Формат timestamp совпадает с datetime, но во внутреннем представлении дата хранится как число секунд, прошедших с полуночи 1 января 1970 г. (такое исчисление принято в операционной системе UNIX, а дата 01.01.1970 считается началом эпохи UNIX и днем рождения операционной системы).
Если в таблице несколько столбцов timestamp, при модификации записи текущее время будет записываться только в один из них (первый). Можно явно указать столбец, которому необходимо назначать текущую дату при создании или изменении записи. Чтобы поля принимали текущую дату при создании записи, следует после определения столбца добавить default current_timestamp. Если текущее время должно выставляться при модификации записи, при использовании оператора update следует добавить on update current_timestamp.
Тип данных NULL используется, когда информации недостаточно и для части данных нельзя определить, какое значение они примут. Для указания того, что поле может принимать неопределенное значение, в определении столбца после типа данных следует указать ключевое слово null. Если поле не должно принимать значение null, следует указать ключевое слово not null.
Рекомендации по выбору типа данных.
· Обработка числовых данных происходит быстрее строковых. Так как типы enum и set имеют внутреннее числовое представление, им следует отдавать предпочтение перед другими видами строковых данных, если это возможно.
· Производительность можно увеличить за счет представления строк в виде чисел. Пример – преобразование IP-адреса из строки в bigint. Это позволит уменьшить размер таблицы и значительно увеличить скорость при сортировке и выборке данных, но потребует дополнительных преобразований.
· Базы данных хранятся на жестком диске, и чем меньше места они занимают, тем быстрее происходит поиск и извлечение. Если есть возможность, следует выбирать типы данных, занимающие меньше места.
· Типы фиксированной длины обрабатываются быстрее типов переменной длины, т. к. в последнем случае при частых удалениях и модификациях таблицы происходит ее фрагментация.
· Если применение столбцов с данными переменной длины неизбежно, для дефрагментации таблицы следует применять команду optimize table.
Обеспечение ссылочной целостности. Задается конструкцией:
foreign key [name_key] (col1, ... ) REFERENCES tbl (tbl_col, ... )
[ON DELETE {CASCADE | SET NULL | NO ACTION | RESTRICT | SET DEFAULT}] [ON UPDATE {CASCADE | SET NULL | NO ACTION | RESTRICT | SET DEFAULT}]
Конструкция позволяет задать внешний ключ с необязательным именем name_key на столбцах, которые задаются в круглых скобках (один или несколько). Ключевое слово references указывает таблицу tbl, на которую ссылается внешний ключ, в круглых скобках указываются имена столбцов. Необязательные конструкции ON DELETE и ON UPDATE позволяют задать поведение СУБД при удалении и обновлении строк из таблицы-предка. Параметры, следующие за этими ключевыми словами, имеют следующие значения:
· CASCADE – при удалении или обновлении записи в таблице-предке, содержащей первичный ключ, записи со ссылками на это значение в таблице-потомке удаляются или обновляются автоматически;
· SET NULL – при удалении или обновлении записи в таблице-предке, содержащей первичный ключ, в таблице-потомке значения внешнего ключа, ссылающегося на таблицу-предка, устанавливаются в null;
· NO ACTION – при удалении или обновлении записей, содержащих первичный ключ, с таблицей-потомком никаких действий не производится;
· RESTRICT – если в таблице-потомке имеются записи, ссылающиеся на первичный ключ таблицы-предка, при удалении или обновлении записей с таким первичным ключом возвращается ошибка;
· SET DEFAULT – согласно стандарту SQL, при удалении или обновлении первичного ключа в таблице-потомке для ссылающихся на него записей в поле внешнего ключа должно устанавливаться значение по умолчанию (в MySQL это ключевое слово зарезервировано, но не обрабатывается).
Создание индексов. Индексы играют большую роль в БД, т. к. это основной способ ускорения их работы. Записи в таблице располагаются хаотически. Чтобы найти нужную запись, необходимо сканировать всю таблицу, на что уходит много времени. Идея индексов состоит в том, чтобы создать для столбца копию, которая постоянно будет поддерживаться в отсортированном состоянии. Это позволяет быстро осуществлять поиск по такому столбцу.
Все необходимые индексы формируются при создании таблицы. Индексированы будут все столбцы, объявленные как PRIMARY KEY, KEY, UNIQUE или INDEX. Индекс также можно добавить с помощью оператора CREATE INDEX. Перед выполнением оператор преобразуется в оператор ALTER TABLE. Например, создание индекса с именем name на основе поля u_name из таблицы users:
create index name on users (u_name);
Перед ключевым словом index может присутствовать UNIQUE, требующее уникальности ограничения.
Корректность таблиц в БД можно проверить с помощью оператора
SHOW TABLES;
Более подробную информацию о структуре таблицы дает команда
DESCRIBE имя_таблицы;
Переименование БД. Специального оператора переименования БД нет, но можно переименовать каталог БД в системном каталоге (…\DATA).
Удаление БД. Удалить всю БД вместе с ее содержимым можно командой:
drop database [IF EXISTS] имя_базы_данных;
Удаление таблиц и индексов. Удалить таблицу можно с помощью оператора:
drop table [IF EXISTS] имя_таблицы;
Удалить индекс можно с помощью оператора:
drop index имя_индекса on имя_таблицы;
Изменение структуры таблиц.Изменить структуру существующей таблицы можно с помощью оператора ALTER TABLE. Например, можно создать индекс name для таблицы users следующим образом:
alter table users add index name (u_name);
Оператор ALTER TABLE является исключительно гибким, поэтому он имеет огромное множество дополнительных ключевых слов.
Практическая работа № 3. Вставка, удаление и обновление данных.
При выполнении лабораторной работы необходимо для заданной предметной области средствами MySQL:
· создать базу данных;
· создать таблицы, определить поля таблиц, индексы;
· определить связи между таблицами и ограничения целостности;
· составить отчет по лабораторной работе.
Рассмотрим следующие вопросы:
· вставка данных с помощью оператора INSERT;
· удаление данных операторами DELETE и TRUNCATE;
· обновление данных с помощью оператора UPDATE.
После создания БД и таблиц перед разработчиком встает задача заполнения таблиц данными. В реляционных БД традиционно применяют три подхода:
· однострочный оператор insert – добавляет в таблицу новую запись;
· многострочный оператор insert – добавляет в таблицу несколько записей;
· пакетная загрузка LOAD DATA INFILE – добавление данных из файла.
Вставка данных с помощью оператора INSERT. Однострочный оператор insert может использоваться в нескольких формах. Упрощенный синтаксис первой формы:
insert [IGNORE] [INTO] имя_таблицы [(имя_столбца, ... )]
VALUES (выражение, ... );
Оператор вставляет новую запись в таблицу имя_таблицы. Значения полей записи перечисляются в списке (выражение, ... ). Порядок следования столбцов задается списком (имя_столбца, ... ). Список столбцов (имя_столбца, ... ) позволяет менять порядок следования столбцов при добавлении.
Первичный ключ таблицы является уникальным, и попытка добавить уже существующее значение приведет к ошибке. Чтобы новые записи с дублирующим ключом отбрасывались без генерации ошибки, следует добавить после оператора insert ключевое слово IGNORE.
Другая форма оператора insert предполагает использование слова set:
insert [IGNORE] [INTO] имя_таблицы
SET имя_столбца1 = выражение1, имя_столбца2 = выражение2, ... ;
Оператор заносит в таблицу имя_таблицы новую запись, столбец имя_столбца в которой получает значение выражение.
Многострочный оператор INSERT совпадает по форме с однострочным оператором, но после ключевого слова values добавляется через запятую несколько списков (выражение, ... ).
Практические примеры использования оператора insert для заполнения учебной БД book см. ниже, в пункте «Пример выполнения работы».
Удаление данных.Для удаления записей из таблиц предусмотрены:
· оператор DELETE;
· оператор TRUNCATE TABLE.
Оператор DELETE имеет следующий синтаксис:
DELETE FROM имя_таблицы
[Where условие]
[ORDER BY имя_поля]
[LIMIT число_строк];
Оператор удаляет из таблицы имя_таблицы записи, удовлетворяющие условию. В следующем примере из таблицы catalogs удаляются записи, имеющие значение первичного ключа catalog_id больше двух.
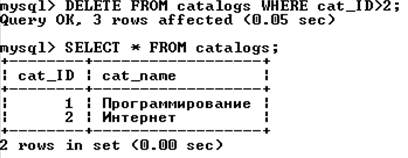
Если в операторе отсутствует условие where, удаляются все записи таблицы.

Ограничение limit позволяет задать максимальное число записей, которые могут быть удалены. Следующий запрос удаляет все записи таблицы orders, но не более 3 записей.
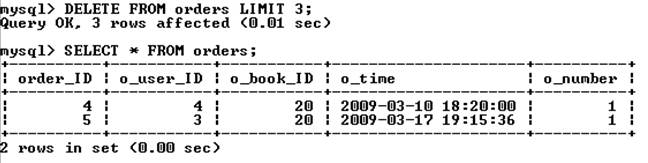
Конструкция order by обычно применяется вместе с ключевым словом limit. Например, если необходимо удалить 20 первых записей таблицы, то производится сортировка по полю типа datetime – тогда в первую очередь будут удалены самые старые записи.
Оператор truncate table полностью очищает таблицу и не допускает условного удаления. Он аналогичен оператору delete без условия where и ограничения limit. Удаление происходит гораздо быстрее, т. к. осуществляется не перебор записей, а полное очищение таблицы.

Обновление данных.Обновление данных (изменение значений полей в существующих записях) обеспечивают:
· оператор Update;
· оператор Replace.
Оператор UPDATE позволяет обновлять отдельные поля в существующих записях. Имеет следующий синтаксис
Update [IGNORE] имя_таблицы
SET имя_столбца1= выражение1 [, имя_столбца2 = выражение2 … ]
[WHERE условие]
[ORDER BY имя_поля ]
[LIMIT число_строк] ;
После ключевого слова update указывается таблица, которая изменяется. В предложении set указывается, какие столбцы обновляются и устанавливаются их новые значения. Необязательное условие WHERE позволяет задать критерий отбора строк (обновляться будут только строки, удовлетворяющие условию).
Если указывается необязательное ключевое слово ignore, то команда обновления не будет прервана, даже если при обновлении возникнет ошибка дублирования ключей. Строки, породившие конфликтные ситуации, обновлены не будут.
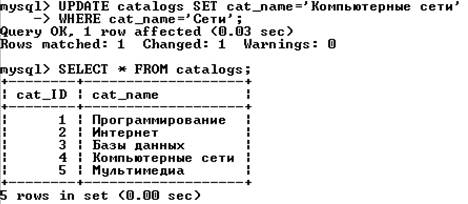
Запрос, изменяющий в таблице catalogs «Сети» на «Компьютерные сети».
Обновлять можно всю таблицу. Пусть требуется уменьшить на 5 % цену на все книги. Для этого следует старую цену в рублях умножить на 0,95.

Инструкции limit и order by позволяют ограничить число изменяемых записей. При этом за один запрос можно обновить несколько столбцов таблицы. Например, необходимо в таблице books для десяти самых дешевых товарных позиций уменьшить количество книг на складе на единицу, а цену – на 5 %.

Оператор REPLACE работает как оператор insert, за исключением того, что старая запись с тем же значением индекса unique или primary keyперед внесением новой будет удалена. Если не используются индексы unique или primary key, то применение оператора replace не имеет смысла.
Синтаксис оператора REPLACE аналогичен синтаксису оператора insert:
REPLACE [INTO] имя_таблицы [(имя_столбца, ... )]
VALUES (выражение, ... )
В таблицу вставляются значения, определяемые в списке после ключевого слова VALUES. Задать порядок столбцов можно при помощи необязательного списка, следующего за именем таблицы. Как и оператор Insert, оператор replace допускает многострочный формат.
Практическая работа
При выполнении лабораторной работы необходимо для заданной предметной области средствами MySQL:
· заполнить согласованными данными таблицы БД;
· при необходимости исправить введенную информацию;
· составить отчет по лабораторной работе.
Рассмотрим следующие вопросы:
· выборка данных из одной таблицы с помощью оператора SELECT;
· использование в запросах операторов и встроенных функций MySQL.
Для выполнения запросов (извлечения строк из одной или нескольких таблиц БД) используется оператор SELECT. Результатом запроса всегда является таблица. Результаты запроса могут быть использованы для создания новой таблицы. Таблица, полученная в результате запроса, может стать предметом дальнейших запросов.
Общая форма оператора SELECT:
SELECT столбцы FROM таблицы
[WHERE условия]
[GROUP BY группа [HAVING групповые_условия] ]
[ORDER BY имя_поля]
[LIMIT пределы];
Оператор SELECT имеет много опций. Их можно использовать или не использовать, но они должны указываться в том порядке, в каком они приведены. Если требуется вывести все столбцы таблицы, необязательно перечислять их после ключевого слова select, достаточно заменить этот список символом *.
Список столбцов в операторе select используют, если нужно изменить порядок следования столбцов в результирующей таблице или выбрать часть столбцов.

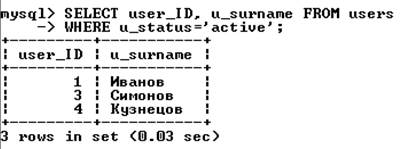
Условия выборки. Гораздо чаще встречается ситуация, когда необходимо изменить количество выводимых строк. Для выбора записей, удовлетворяющих определенным критериям поиска, можно использовать конструкцию WHERE.
В запросе можно использовать ключевое слово DISTINCT, чтобы результат не содержал повторений уже имеющихся значений, например:
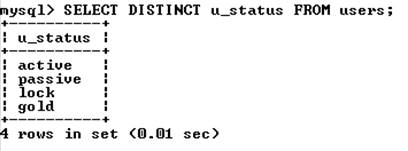
Сортировка. Результат выборки – записи, расположенные в том порядке, в котором они хранятся в БД. Чтобы отсортировать значения по одному из столбцов, необходимо после конструкции order by указать этот столбец, например:
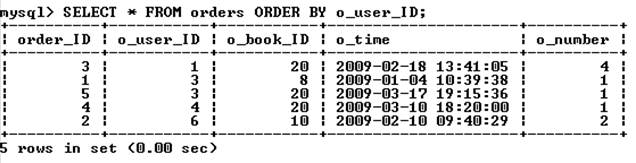
Сортировку записей можно производить по нескольким столбцам (их следует указать после слов order by через запятую). Число столбцов, указываемых в конструкции order by, не ограничено.
По умолчанию сортировка производится в прямом порядке (записи располагаются от наименьшего значения поля сортировки до наибольшего). Обратный порядок сортировки реализуется с помощью ключевого слова desc:
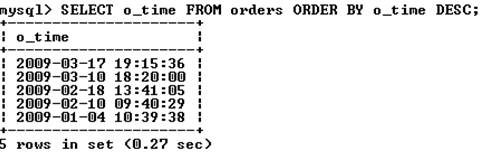
Для прямой сортировки существует ключевое слово asc, но так как записи сортируются в прямом порядке по умолчанию, данное ключевое слово опускают.
Ограничение выборки. Результат выборки может содержать тысячи записей, вывод и обработка которых занимают значительное время. Поэтому информацию часто разбивают на страницы и предоставляют ее пользователю частями. Постраничная навигация используется при помощи ключевого слова limit, за которым следует число выводимых записей. Следующий запрос извлекает первые 5 записей, при этом осуществляется обратная сортировка по полю b_count:
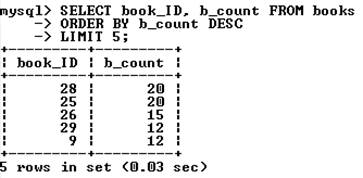
Для извлечения следующих пяти записей используется ключевое слово limit с двумя цифрами. Первая указывает позицию, начиная с которой необходимо вернуть результат, вторая цифра – число извлекаемых записей, например:
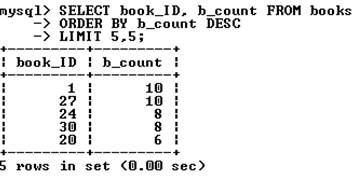
При определении смещения нумерация строк начинается с нуля (поэтому в последнем примере для шестой строки указано смещение 5).
Группировка записей. Конструкция GROUP ВУ позволяет группировать извлекаемые строки. Она полезна в комбинации с функциями, применяемыми к группам строк. Эти функции (табл. 6) называются агрегатами (суммирующими функциями) и вычисляют одно значение для каждой группы, создаваемой конструкцией group by. Функции позволяют узнать число строк в группе, подсчитать среднее значение, получить сумму значений столбцов. Результирующее значение рассчитывается для значений, не равных null (исключение – функция count(*)). Допустимо использование этих функций в запросах без группировки (вся выборка – одна группа).
Пример использования функции count( ), которая возвращает число строк в таблице, значения указанного столбца для которых отличны от NULL:

Таблица 6
| Обозначение | Описание |
| AVG ( [DISTINCT] expr) | Возвращает среднее значение аргумента expr. В качестве аргумента обычно выступает имя столбца. Необязательное слово distinct позволяет обрабатывать только уникальные значения столбца expr |
| COUNT ( ) | Подсчитывает число записей и имеет несколько форм. Форма COUNT (выражение) возвращает число записей в таблице, поле выражение для которых не равно null. Форма count(*) возвращает общее число строк в таблице независимо от того, принимает какое-либо поле значение null или нет. Форма COUNT (DISTINCT выражение1, выражение2, ... ) позволяет использовать ключевое слово distinct, которое позволяет подсчитать только уникальные значения столбца |
| MIN ( [DISTINCT] expr) | Возвращает минимальное значение среди всех непустых значений выбранных строк в столбце expr. Необязательное слово distinct позволяет обрабатывать только уникальные значения столбца expr |
| MAX ( [DISTINCT] expr) | Возвращает максимальное значение среди всех непустых значений выбранных строк в столбце expr. Необязательное слово distinct позволяет обрабатывать только уникальные значения столбца expr |
| STD (expr) | Возвращает стандартное среднеквадратичное отклонение в аргументе expr |
| STDDEV_SAMP (expr) | Возвращает выборочное среднеквадратичное отклонение в аргументе expr |
| SUM ( [DISTINCT] expr) | Возвращает сумму величин в столбце expr. Необязательное слово distinct позволяет обрабатывать только уникальные значения столбца expr |
Использование ключевого слова distinct с функцией count( ) позволяет вернуть число уникальных значений b_cat_ID в таблице books, например:

В SELECT-запросе столбцу можно назначить новое имя с помощью оператора as. Например, результату функции count( ) присваивается псевдоним total:

Использование функций в конструкции where приведет к ошибке. В следующем примере показана попытка извлечения из таблицы catalogsзаписи с максимальным значением поля cat_ID:
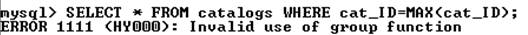
Решение задачи следует искать в использовании конструкции order by:

Для извлечения уникальных записей используют конструкцию group by с именем столбца, по которому группируется результат:
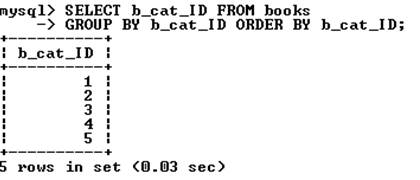
При использовании group by возможно использование условия where:

Часто при задании условий требуется ограничить выборку по результату функции (например, выбрать каталоги, где число товарных позиций больше 5). Использование для этих целей конструкции where приводит к ошибке. Для решения этой проблемы вместо ключевого слова whereиспользуется ключевое слово having, располагающееся за конструкцией group by:

Запрос, извлекающий уникальные значения столбца b_cat_ID, большие двух:

При этом в случае использования ключевого слова where сначала производится выборка из таблицы с применением условия и лишь затем группировка результата, а в случае использования ключевого слова having сначала происходит группировка таблицы и лишь затем выборка с применением условия. Допускается использование условия having без группировки group by.
Использование функций. Для решения специфических задач при выборке удобны встроенные функции MySQL. Большинство функций предназначено для использования в выражениях SELECT и WHERE. Существуют также специальные функции группировки для использования в выражении GROUP BY (см. выше).
Каждая функция имеет уникальное имя и может иметь несколько аргументов (перечисляются через запятую в круглых скобках). Если аргументы отсутствуют, круглые скобки все равно следует указывать. Пробелы между именем функции и круглыми скобками недопустимы.
Число доступных для использования функций велико, в приложениях приведены наиболее полезные из них.
Пример использования функции, возвращающей версию сервера MySQL:
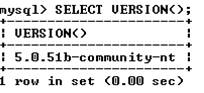
Отметим также возможность использования оператора SELECT без таблиц вообще. В такой форме SELECT можно использовать как калькулятор:
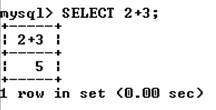
Можно вычислить любое выражение без указания таблиц, получив доступ ко всему разнообразию математических и других операторов и функций. Возможность выполнять математические расчеты на уровне SELECT позволяет проводить финансовый анализ значений таблиц и отображать полученные результаты в отчетах. Во всех выражениях MySQL (как в любом языке программирования) можно использовать скобки, чтобы контролировать порядок вычислений.
Операторы. Под операторами подразумеваются конструкции языка, которые производят преобразование данных. Данные, над которыми совершается операция, называются операндами.
В MySQL используются три типа операторов:
· арифметические операторы;
· операторы сравнения;
· логические операторы.
Арифметические операции.В MySQL используются обычные арифметические операции: сложение (+), вычитание (–), умножение (*), деление (/) и целочисленное деление DIV (деление и отсечение дробной части). Деление на 0 дает безопасный результат NULL.
Операторы сравнения. При работе с операторами сравнения необходимо помнить о том, что, за исключением нескольких особо оговариваемых случаев, сравнение чего-либо со значением NULL дает в результате NULL. Это касается и сравнения значения NULL со значением NULL:
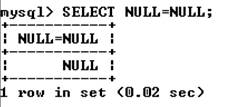
Корректнее использовать следующий запрос:
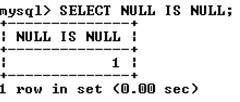
Поэтому следует быть предельно внимательными при работе с операторами сравнения, если операнды могут принимать значения NULL.
Наиболее часто используемые операторы сравнения приведены в табл. 7.
Логические операторы. MySQL поддерживает все обычные логические операции, которые можно использовать в выражениях. Логические выражения в MySQL могут принимать значения 1 (истина), 0 (ложь) или NULL.
Кроме того, следует учитывать, что MySQL интерпретирует любое ненулевое значение, отличное от NULL, как значение «истина». Основные логические операторы приведены в табл. 8.
Практическая работа № 4. Создание простых запросов на выборку.
Практическая работа
При выполнении лабораторной работы необходимо:
· для заданной предметной области построить два простых запроса на выборку с использованием операторов и функций MySQL;
· составить отчет по лабораторной работе.
Таблица 7
| Оператор | Значение |
| = | Оператор равенства. Возвращает 1 (истина), если операнды равны, и 0 (ложь), если не равны |
| <=> | Оператор эквивалентности. Аналогичен обычному равенству, но возвращает только два значения: 1 (истина) и 0 (ложь). NULL не возвращает |
| <> | Оператор неравенства. Возвращает 1 (истина), если операнды не равны, и 0 (ложь), если равны |
| < | Оператор «меньше». Возвращает 1 (истина), если левый операнд меньше правого, и 0 (ложь) – в противном случае |
| <= | Оператор «меньше или равно». Возвращает 1 (истина), если левый операнд меньше правого или они равны, и 0 (ложь) – в противном случае |
| > | Оператор «больше». Возвращает 1 (истина), если левый операнд больше правого, и 0 (ложь) – в противном случае |
| >= | Оператор «больше или равно». Возвращает 1 (истина), если левый операнд больше правого или они равны, и 0 (ложь) – в противном случае |
| n BETWEEN min AND max | Проверка диапазона. Возвращает 1 (истина), если проверяемое значение n находится между min и max, и 0 (ложь) – в противном случае |
| IS NULL и IS NOT NULL | Позволяют проверить, является ли значение значением NULL или нет |
| n IN (множество) | Принадлежность к множеству. Возвращает 1 (истина), если проверяемое значение n входит в список, и 0 (ложь) – в противном случае. В качестве множества может использоваться список литеральных значений или выражений или подзапрос |
Таблица 8
| Оператор | Пример | Значение |
| AND | n AND m | Логическое И: истина AND истина = истина, ложь AND любое = ложь. Все остальные выражения оцениваются как NULL |
| OR | n OR m | Логическое ИЛИ: истина OR любое = истина, NULL OR ложь = NULL, NULL OR NULL = NULL, ложь OR ложь = ложь |
| NOT | NOT n | Логическое НЕТ: NOT истина = ложь, NOT ложь = истина. NOT NULL = NULL |
| XOR | n XOR m | Логическое исключающее ИЛИ: истина XOR истина = ложь, истина XOR ложь = истина, ложь XOR истина = истина, ложь XOR ложь = ложь, NULL XOR любое = NULL, любое XOR NULL = NULL |
Переменные SQL и временные таблицы. Часто результаты запроса необходимо использовать в последующих запросах. Для этого полученные данные необходимо сохранить во временных структурах. Эту задачу решают переменные SQL и временные таблицы. Объявление переменной начинается с символа @, за которым следует имя переменной. Значения переменным присваиваются посредством оператора selectс использованием оператора присваивания := . Например:
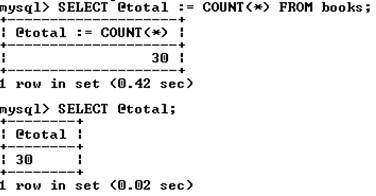
Объявляется переменная @total, которой присваивается число записей в таблице books. Затем в рамках текущего сеанса в последующих запросах появляется возможность использования данной переменной. Переменная действует только в рамках одного сеанса соединения с сервером MySQL и прекращает свое существование после разрыва соединения.
Переменные также могут объявляться при помощи оператора set:

При использовании оператора set в качестве оператора присваивания может выступать обычный знак равенства =. Оператор set удобен тем, что он не возвращает результирующую таблицу. Не рекомендуется одновременно присваивать переменной некоторое значение и использовать эту переменную в одном запросе.
Переменная SQL позволяет сохранить одно промежуточное значение. Когда необходимо сохранить результирующую таблицу, прибегают к временным таблицам. Создание временных таблиц осуществляется при помощи оператора CREATE temporary table, синтаксискоторого ничем не отличается от синтаксиса оператора CREATE table.
Временная таблица автоматически удаляется по завершении соединения с сервером, а ее имя действительно только в течение данного соединения. Это означает, что два разных клиента могут использовать временные таблицы с одинаковыми именами без конфликта друг с другом или с существующей таблицей с тем же именем.
Рассмотрим следующие вопросы:
· использование объединений в запросах к нескольким таблицам;
· создание вложенных запросов.
В реальных приложениях часто требуется использовать сразу несколько таблиц БД. Запросы, которые обращаются одновременно к нескольким таблицам, называются многотабличными или сложными запросами.
Абсолютные ссылки на базы данных и таблицы. В запросе можно прямо указывать необходимую БД и таблицу. Например, можно представить ссылку на столбец u_surname из таблицы users в виде users.u_surname. Аналогично можно уточнить БД, таблица из которой упоминается в запросе. Если необходимо, то вместе с БД и таблицей можно указать и столбец, например:

При использовании сложных запросов это позволяет избежать двусмысленности при указании источника необходимой информации.
Использование объединений для запросов к нескольким таблицам. Хорошо спроектированная реляционная БД эффективна из-за связей между таблицами. При выборе информации из нескольких таблиц такие связи называют объединениями.
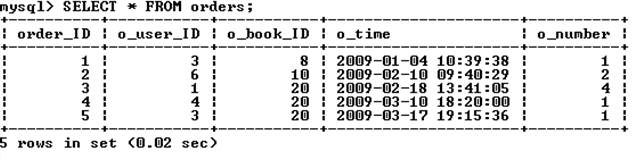
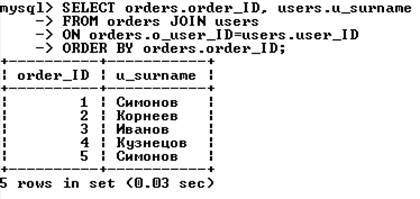
В качестве примера объединения двух таблиц рассмотрим запрос, извлекающий из БД book фамилии покупателей вместе с номерами сделанных ими заказов:
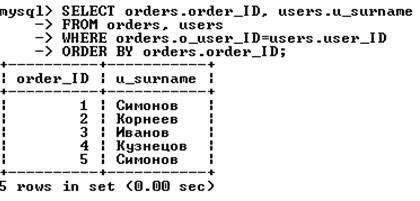
Выражение WHERE важно с точки зрения получения результата. Набор условий, используемых для объединения таблиц, называют условием объединения. В данном примере условие связывает таблицы orders и users по внешним ключам.
Объединение нескольких таблиц аналогично объединению двух таблиц. Например, необходимо выяснить, какому каталогу принадлежит товарная позиция из заказа, сделанного 10 февраля 2009 г. в 09:40:29:
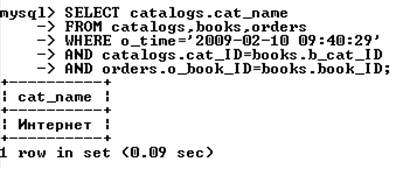
Самообъединение таблиц. Можно объединить таблицу саму с собой (когда интересуют связи между строками одной и той же таблицы). Пусть нужно выяснить, какие книги есть в каталоге, содержащем книгу с названием «Компьютерные сети». Для этого необходимо найти в таблице books номер каталога (b_cat_ID) с этой книгой, а затем посмотреть в таблице books книги этого каталога.
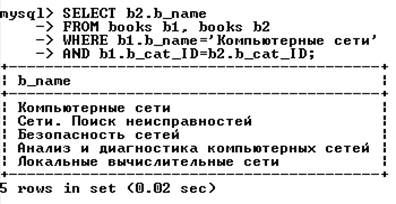
В этом запросе для таблицы books определены два разных псевдонима (две отдельных таблицы b1 и b2, которые должны содержать одни и те же данные). После этого они объединяются, как любые другие таблицы. Сначала ищется строка в таблице b1, а затем в таблице b2 – строки с тем же значением номера каталога.
Основное объединение. Набор таблиц, перечисленных в выражении FROM и разделенных запятыми, – это декартово произведение (полное или перекрестное объединение), которое возвращает полный набор комбинаций. Добавление к нему условного выражения WHERE превращает его в объединение по эквивалентности, ограничивающее число возвращаемых запросом строк.
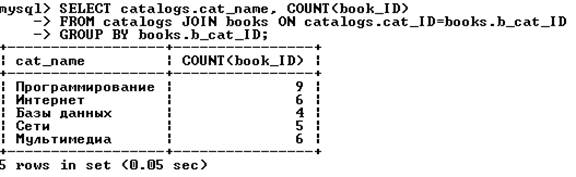
Вместо запятой в выражении FROM можно использовать ключевое слово JOIN. В этом случае вместо WHERE лучше использовать ключевое слово ON:
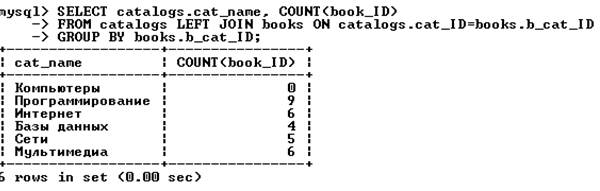
Вместо JOIN с тем же результатом можно использовать CROSS JOIN (перекрестное объединение) или INNER JOIN (внутреннее объединение). Пример запроса, выдающего число товарных позиций в каталогах:
Допустим, происходит расширение ассортимента и в списке каталогов появляется новый каталог «Компьютеры»:
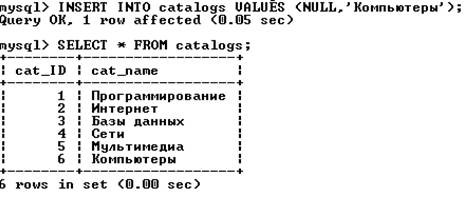
Предыдущий запрос не отразит наличие нового каталога (таблица books не содержит записей, относящихся к новому каталогу). Выходом является использование левого объединения (таблица catalogs должна быть левой таблицей):
Пусть нужно вывести список покупателей и число осуществленных ими покупок, причем покупателей необходимо отсортировать по убыванию числа заказов:
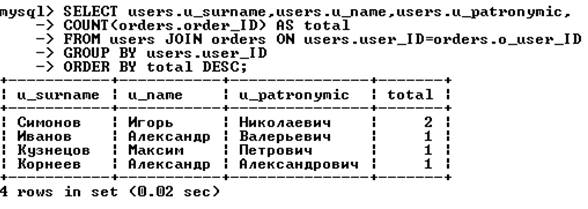
В список не входят покупатели, которые не сделали ни одной покупки. Чтобы вывести полный список покупателей, необходимо вместо перекрестного объединения таблиц users и orders использовать левое объединение (левой таблицей должна быть таблица users):
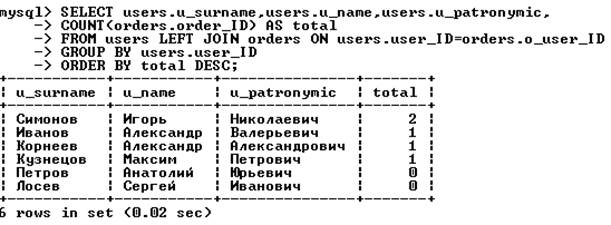
Вложенный запрос. Позволяет использовать результат, возвращаемый одним запросом, в другом запросе. Так как результат возвращает только оператор select, то в качестве вложенного запроса всегда выступает SELECT-запрос. В качестве внешнего запроса может выступать запрос с участием любого SQL-оператора: select, insert, update, delete, create table и др.
Пусть требуется вывести названия и цены товарных позиций из таблицы books для каталога «Базы данных» таблицы catalogs:

Получить аналогичный результат можно при помощи многотабличного запроса, но имеется ряд задач, которые решаются только при помощи вложенных запросов. Вложенный запрос может применяться не только с условием WHERE, но и в конструкциях DISTINCT, GROUP BY, ORDER BY, LIMIT и т. д. Различают:
· вложенные запросы, возвращающие одно значение;
· вложенные запросы, возвращающие несколько строк.
В первом случае вложенный запрос возвращает скалярное значение или литерал, которое используется во внешнем запросе (подставляет результат на место своего выполнения). Например, необходимо определить название каталога, содержащего самую дорогую товарную позицию:

Наиболее часто вложенные запросы используются в операциях сравнения в условиях, которые задаются ключевыми словами WHERE, HAVINGили ON.
Однако следующий вложенный запрос вернет ошибку:
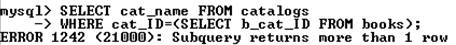
Чтобы выбрать строки из таблицы catalogs, у которых первичный ключ совпадает с одним из значений, возвращаемых вложенным запросом, следует воспользоваться конструкцией IN:

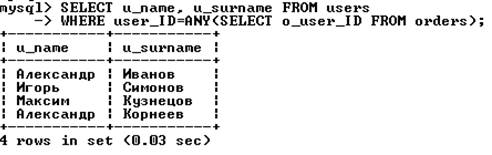
Ключевое слово ANY может применяться с использованием любого оператора сравнения. Используется логика ИЛИ, т. е. достаточно, чтобы срабатывало хотя бы одно из многих условий. Запрос вида WHERE X > ANY (SELECT Y …) можно интерпретировать как «где X больше хотя бы одного выбранного Y». Соответственно, запрос вида WHERE X < ANY (SELECT Y …) интерпретируется как «где X меньше хотя бы одного выбранного Y». Рассмотрим запрос, возвращающий имена и фамилии покупателей, совершивших хотя бы одну покупку:
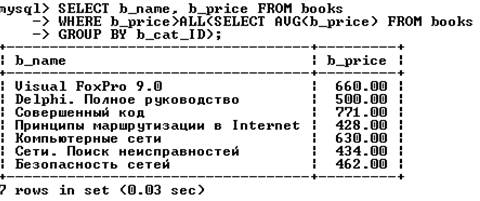
Ключевое слово ALL также может применяться с использованием любого оператора сравнения, но при этом используется логика И, то есть должны срабатывать все условия. Запрос вида WHERE X > ALL (SELECT Y …) интерпретируется как «где X больше любого выбранного Y». Соответственно, запрос вида WHERE X < ALL (SELECT Y …) интерпретируется как «где X меньше, чем все выбранные Y». Рассмотрим запрос, возвращающий все товарные позиции, цена которых превышает среднюю цену каждого из каталогов:
Результирующая таблица, возвращаемая вложенным запросом, может не содержать ни одной строки. Для проверки этого факта могут использоваться ключевые слова EXISTS и NOT EXISTS.
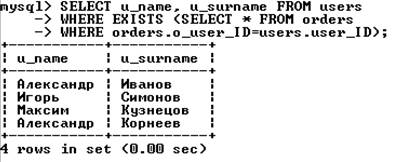
Запрос, формирующий список покупателей, совершивших хотя бы одну покупку, можно записать следующим образом:
Дата добавления: 2019-11-16; просмотров: 434; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!