Оценка значимости параметров взаимосвязи
Получив оценки корреляции и регрессии, необходимо проверить их на соответствие истинным параметрам взаимосвязи.
Существующие программы для ЭВМ включают, как правило, несколько наиболее распространенных критериев. Для оценки значимости коэффициента парной корреляции рассчитывают стандартную ошибку коэффициента корреляции:
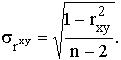
В первом приближении нужно, чтобы 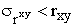 . Значимость rxy проверяется его сопоставлением с
. Значимость rxy проверяется его сопоставлением с 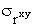 , при этом получают
, при этом получают
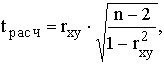
где tрасч – так называемое расчетное значение t-критерия.
Если tрасч больше теоретического (табличного) значения критерия Стьюдента (tтабл) для заданного уровня вероятности и (n-2) степеней свободы, то можно утверждать, что rxy значимо.
Подобным же образом на основе соответствующих формул рассчитывают стандартные ошибки параметров уравнения регрессии, а затем и t-критерии для каждого параметра. Важно опять-таки проверить, чтобы соблюдалось условие tрасч > tтабл. В противном случае доверять полученной оценке параметра нет оснований.
Вывод о правильности выбора вида взаимосвязи и характеристику значимости всего уравнения регрессии получают с помощью F-критерия, вычисляя его расчетное значение:
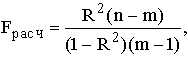
где n – число наблюдений;
m – число параметров уравнения регрессии.
Fрасч также должно быть больше Fтеор при v1 = (m-1) и v2 = (n-m) степенях свободы. В противном случае следует пересмотреть форму уравнения, перечень переменных и т.д.
Непараметрические методы оценки связи
Методы корреляционного и дисперсионного анализа не универсальны: их можно применять, если все изучаемые признаки являются количественными. При использовании этих методов нельзя обойтись без вычисления основных параметров распределения (средних величин, дисперсий), поэтому они получили название параметрических методов.
Между тем в статистической практике приходится сталкиваться с задачами измерения связи между качественными признаками, к которым параметрические методы анализа в их обычном виде неприменимы. Статистической наукой разработаны методы, с помощью которых можно измерить связь между явлениями, не используя при этом количественные значения признака, а значит, и параметры распределения. Такие методы получили название непараметрических.
Если изучается взаимосвязь двух качественных признаков, то используют комбинационное распределение единиц совокупности в форме так называемых таблиц взаимной сопряженности.
Рассмотрим методику анализа таблиц взаимной сопряженности на конкретном примере социальной мобильности как процесса преодоления замкнутости отдельных социальных и профессиональных групп населения. Ниже приведены данные о распределении выпускников средних школ по сферам занятости с выделением аналогичных общественных групп их родителей.
| Занятия родителей | Число детей, занятых в | Всего | |||
| Промышлен- ности и стро- ительстве | сельском хозяйстве | сфере обслужи- вания | сфере интел- лектуального труда | ||
| 1. Промышленность и строительство 2. Сельское хозяйство 3. Сфера обслуживания 4. Сфера интеллектульного труда | 40 34 16 24 | 5 29 6 5 | 7 13 15 9 | 39 12 19 72 | 91 88 56 110 |
| Всего | 114 | 45 | 44 | 142 | 345 |
Распределение частот по строкам и столбцам таблицы взаимной сопряженности позволяет выявить основные закономерности социальной мобильности: 42,9 % детей родителей группы 1 («Промышленность и строительство») заняты в сфере интеллектуального труда (39 из 91); 38,9 % детей. родители которых трудятся в сельском хозяйстве, работают в промышленности (34 из 88) и т.д.
Можно заметить и явную наследственность в передаче профессий. Так, из пришедших в сельское хозяйство 29 человек, или 64,4 %, являются детьми работников сельского хозяйства; более чем у 50 % в сфере интеллектуального труда родители относятся к той же социальной группе и т.д.
Однако важно получить обобщающий показатель, характеризующий тесноту связи между признаками и позволяющий сравнить проявление связи в разных совокупностях. Для этой цели исчисляют, например, коэффициенты взаимной сопряженности Пирсона (С) и Чупрова (К):
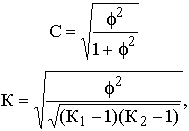
где f2 – показатель средней квадратической сопряженности, определяемый путем вычитания единицы из суммы отношений квадратов частот каждой клетки корреляционной таблицы к произведению частот соответствующего столбца и строки:
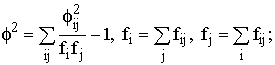
К1 и К2 – число групп по каждому из признаков. Величина коэффициента взаимной сопряженности, отражающая тесноту связи между качественными признаками, колеблется в обычных для этих показателей пределах от 0 до 1.
Построение таблиц взаимной сопряженности применимо не только к количественным, но и к качественным (атрибутивным признакам). Особенно часто качественные признаки, взаимосвязи между ними, их влияние на другие показатели, в том числе и количественные, приходится изучать при проведении различных социологических исследований путем опроса или анкетирования. В таких случаях о зависимости ответов на те или иные вопросы от других признаков единиц наблюдения судят исходя из комбинационного распределения единиц совокупности по двум атрибутивным (либо одному атрибутивному и одному количественному) признакам путем анализа таблицы взаимной сопряженности.
Простейшей формой таблицы взаимной сопряженности являются таблицы «четырех полей». В них по каждому признаку выделяется только две группы, чаще всего по альтернативному признаку.
Таблица 8.2.
Общий вид таблицы «четырех полей»
| Группа | 1 | 2 | Сумма |
| 1 | a | b | a+b |
| 2 | c | d | c+d |
| Сумма | a+c | b+d | a+b+c+d |
Для измерения тесноты связи между группировочными признаками в таблицах взаимной сопряженности используются коэффициент ассоциации, коэффициент контингенции, коэффициент взаимной сопряженности Пирсона, коэффициент взаимной сопряженности Чупрова.
Коэффициент ассоциации вычисляется по формуле
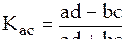 .
.
Если в одной из клеток отсутствует частота (т.е. равна нулю), то коэффициент ассоциации всегда будет равен по модулю 1. Во избежание такой ситуации следует использовать коэффициент контингенции:
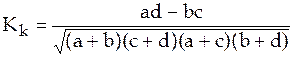 .
.
Коэффициент контингенции всегда меньше коэффициента ассоциации.
В социально-экономических исследованиях нередко встречаются ситуации, когда признак не выражается количественно, однако единицы совокупности можно упорядочить. Такое упорядочение единиц совокупности по значению признака называется ранжированием. Примерами могут быть ранжирование студентов (учеников) по способностям, любой совокупности людей по уровню образования, профессии, по способности к творчеству и т.д.
При ранжировании каждой единице совокупности присваивается ранг, т.е. порядковый номер. При совпадении значения признака у различных единиц им присваивается объединенный средний порядковый номер. Например, если у 5-й и 6-й единиц совокупности значения признаков одинаковы, обе получат ранг, равный (5 + 6) / 2 = 5,5.
Измерение связи между ранжированными признаками производится с помощью ранговых коэффициентов корреляции Спирмена (r) и Кендэлла (t). Эти методы применимы не только для качественных, но и для количественных показателей, особенно при малом объеме совокупности, так как непараметрические методы ранговой корреляции не связаны ни с какими ограничениями относительно характера распределения признака.
Для расчета коэффициента Спирмена значениям признаков  и
и 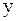 присваивают определенный ранг (
присваивают определенный ранг ( 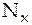 и
и 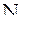 ) – порядковый номер в ранжированном ряду. Затем для каждой пары рангов находят их разность и осуществляется расчет коэффициента Спирмена по следующей формуле:
) – порядковый номер в ранжированном ряду. Затем для каждой пары рангов находят их разность и осуществляется расчет коэффициента Спирмена по следующей формуле:
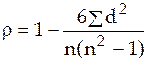 ,
,
где  – разность рангов признаков и ;
– разность рангов признаков и ;
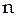 – число наблюдений.
– число наблюдений.
Для расчета коэффициента Кендэла значениям признаков и присваивают определенный ранг ( и ), причем ранги факторного признака располагают строго в порядке возрастания и параллельно записывают каждому значению соответствующее значение . Для каждого последовательно определяют число следующих за ним рангов, превышающих его значение, и число рангов, меньших по значению. Первые учитываются как баллы со знаком «+» (положительные баллы), вторые – как баллы со знаком «-» (отрицательные баллы).
Расчет коэффициента Кендэла производится по следующей формуле:
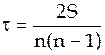 ,
,
где  – сумма положительных и отрицательных баллов;
– сумма положительных и отрицательных баллов;
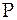 – сумма баллов со знаком «+»;
– сумма баллов со знаком «+»;
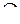 - сумма баллов со знаком «-»;
- сумма баллов со знаком «-»;
- число наблюдений.
Если число ранжируемых признаков больше двух, то для измерения тесноты связи между ними можно использовать коэффициент конкордации (множественный коэффициент ранговой корреляции), предложенный М.Кендэлом и Б.Смитом:
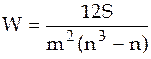 ,
,
где 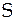 - сумма квадратов отклонений суммы рангов по
- сумма квадратов отклонений суммы рангов по  факторам от их средней арифметической:
факторам от их средней арифметической:
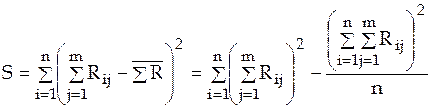 ;
;
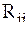 - ранг
- ранг 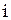 –го фактора у
–го фактора у 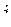 –й единицы:
–й единицы:
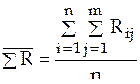 ;
;
– число признаков (факторов);
– число наблюдений.
Если ранги по отдельным признакам будут повторяться, т.е. будут присутствовать связанные ранги, то коэффициент конкордации рассчитывается с учетом числа повторяющихся (связанных) рангов по каждому фактору:
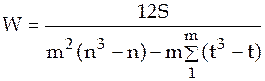 ,
,
где t – число одинаковых рангов по каждому признаку.
Дата добавления: 2019-09-02; просмотров: 415; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!